
RLM(Recursive Language Models) 연구 소개
LLM 컨텍스트 크기의 한계
최근 GPT-4-128k, Claude 3-200k, Gemini 1.5-1M 등 LLM의 입력 문맥 길이(Context Window)는 기하급수적으로 늘어났습니다. 많은 개발자가 이를 "이제 모든 문서를 프롬프트에 넣으면 해결된다"는 신호로 받아들였지만, 실제 현업에서의 경험은 다릅니다. 문맥의 길이가 길어질수록 모델이 정보의 위치를 찾지 못하거나(Lost in the Middle), 상충하는 정보 간의 논리적 연결을 놓치는 현상이 종종 발생합니다.
연구자들은 이러한 현상을 문맥 부패(Context Rot) 라고 부릅니다. 이는 단순히 어텐션(Attention) 메커니즘의 산술적 한계 때문만이 아닙니다. 모델이 한 번의 순전파(Forward Pass)로 처리해야 할 정보의 밀도가 너무 높아지면서, 핵심 정보에 할당되어야 할 어텐션 스코어(Attention Score)가 희석되기 때문입니다.
지금까지는 이 문제를 해결하기 위해 크게 두 가지 접근법을 사용했습니다:
하나는 문맥 창 자체를 늘리는 초장문맥(Long-Context) 모델을 개발하는 것이고, 다른 하나는 필요한 정보만 검색해서 가져오는 RAG(Retrieval-Augmented Generation) 방법입니다. 하지만 Long-Context 모델은 앞서 언급한 문맥 부패(Context Rot) 문제와 더불어 추론 비용이 입력 길이의 제곱(O(N^2)) 또는 선형(O(N))으로 증가한다는 치명적인 단점이 있습니다.
RAG 시스템 또한 한계가 명확합니다. RAG는 사전에 정의된 조각(Chunk) 단위로 검색을 수행하므로, 문서 전체에 흩어진 정보를 종합하거나(예. 이 책의 전반적인 논조가 어떻게 변하는가?), 복잡한 다단계 추론이 필요한 질문(예. A 사건이 B 사건에 미친 간접적 영향은?)에는 취약합니다.
그 외에도 문맥을 요약(Context Compaction/Summarization)과 같은 기법들도 시도하였으나, 세부 정보가 손실될 위험이 크고 정보 밀도가 높은 작업에서는 제대로 동작하지 않는 경우가 많습니다.
RLM(Recursive Language Models) 연구 개요
RLM 연구진들은 이러한 딜레마를 해결하기 위해 근본적인 발상의 전환을 제안합니다. 문맥을 모델의 입력(Input) 으로 넣는 것이 아니라, 모델이 언제든 조회할 수 있는 외부 환경(Environment) 으로 보고 분리하는 것입니다. 모델은 전체 데이터를 한 번에 읽는 것이 아니라, 마치 우리가 램(RAM)보다 큰 데이터를 처리할 때 디스크에서 필요한 부분만 읽어와 처리하는 것처럼, RLM은 긴 텍스트를 외부 변수로 저장해두고 모델이 코드를 작성하여 그 내용을 엿보거나(peek), 분해(decompose)하고, 필요하다면 자기 자신을 재귀적으로 호출(recursive call)하며 처리하는 것입니다.
RLM은 이러한 방식의 추론 시간(Inference-time) 연산을 통해 모델의 물리적 컨텍스트 한계를 뛰어넘어 이론상 무한한 길이의 입력을 처리할 수 있으며, 기존 방식보다 훨씬 뛰어난 성능을 보여줍니다. 다음은 이러한 RLM을 적용하였을 때의 성능 변화를 보여줍니다:
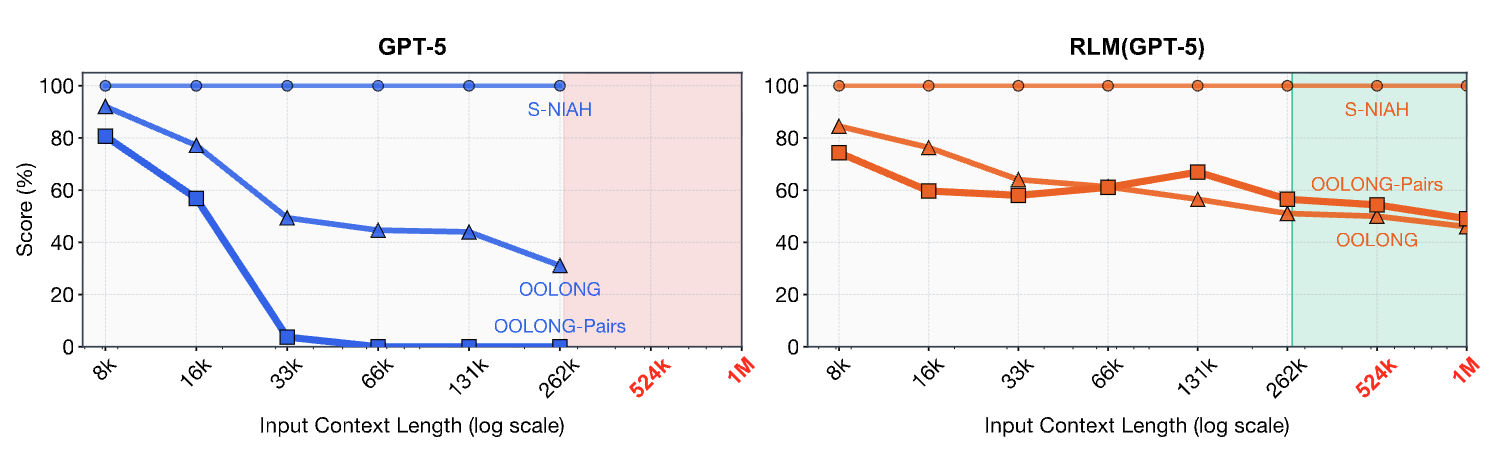
먼저 좌측 그래프를 보면, GPT-5 모델에 3가지 긴 문맥의 작업(long-context task)를 수행했을 때 문맥 길이가 늘어남에 따라 성능이 급격히 하강 곡선을 그리는 것을 확인할 수 있습니다. 하지만, 동일한 GPT-5 모델에 RLM 방법론을 적용한 우측 그래프의 경우, 문맥 길이가 늘어나더라도 성능 저하가 적은 것을 확인할 수 있습니다. 또한, GPT-5의 문맥 크기(context window)인 272K 토큰을 넘어서는 경우에도 1M 토큰까지의 입력까지도 유사한 성능으로 처리하고 있음을 확인할 수 있습니다.
즉, RLM 연구는 긴 입력을 처리하는 것이 단순히 "기억력"의 문제가 아니라, 정보를 처리하는 "방식"의 문제임을 시사합니다.
RLM(Recursive Language Models) 방법론
환경(Environment)으로서의 문맥: 프롬프트 입력에서 영구적 변수로의 전환
RLM 아키텍처의 가장 큰 특징은 문맥 데이터(Context Data)를 바라보는 관점의 변화입니다. 일반적인 LLM이 사용자의 입력(Prompt)에 문맥(Context)을 더해 결과를 생성하는 Completion(Prompt + Context) 형태라면, RLM은 사용자의 입력(Prompt)에 대해 문맥(Context)을 환경으로 바라보고 처리하는 RLM(Prompt, Environment(Context)) 형태를 띱니다.
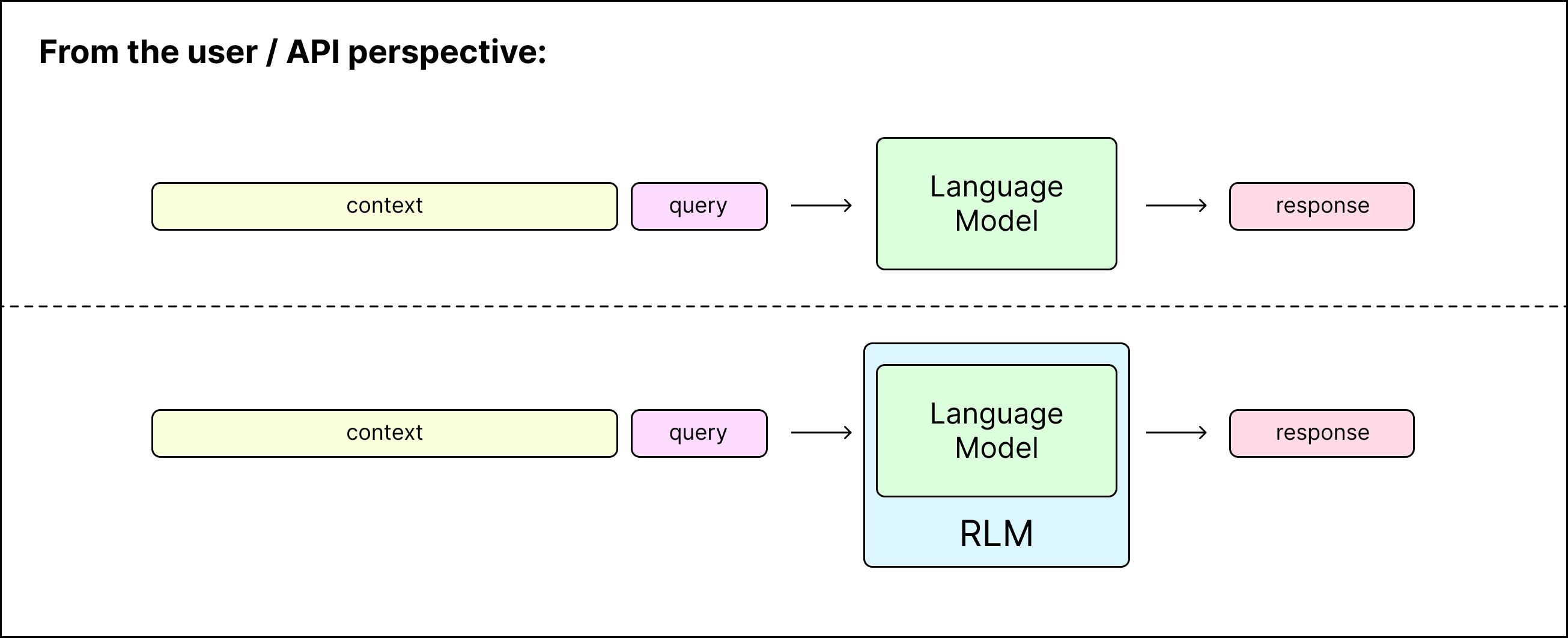
여기서 환경(Environment)은 구체적으로 Python REPL(Read-Eval-Print Loop) 상태를 의미합니다. 사용자가 제공한 거대한 문서나 데이터는 이 Python 환경 내에 문자열 변수나 객체(예: ctx) 형태로 로드됩니다. 이 변수(예. ctx)는 너무 거대하기 때문에 모델(Agent)이 이 변수에 직접 접근하거나 내용을 확인할 수는 없습니다.
대신, 모델은 이 문맥 변수에 접근할 수 있는 Python 코드를 생성하고, 실행하여 그 결과를 얻을 수 있습니다. 예를 들어, ctx의 길이를 알기 위해 print(len(ctx))를 실행하거나, 앞부분 100자를 읽기 위해 print(ctx[:100])을 실행하는 식입니다.
다음은 RLM의 동작 과정을 정리한 예시 그림입니다:
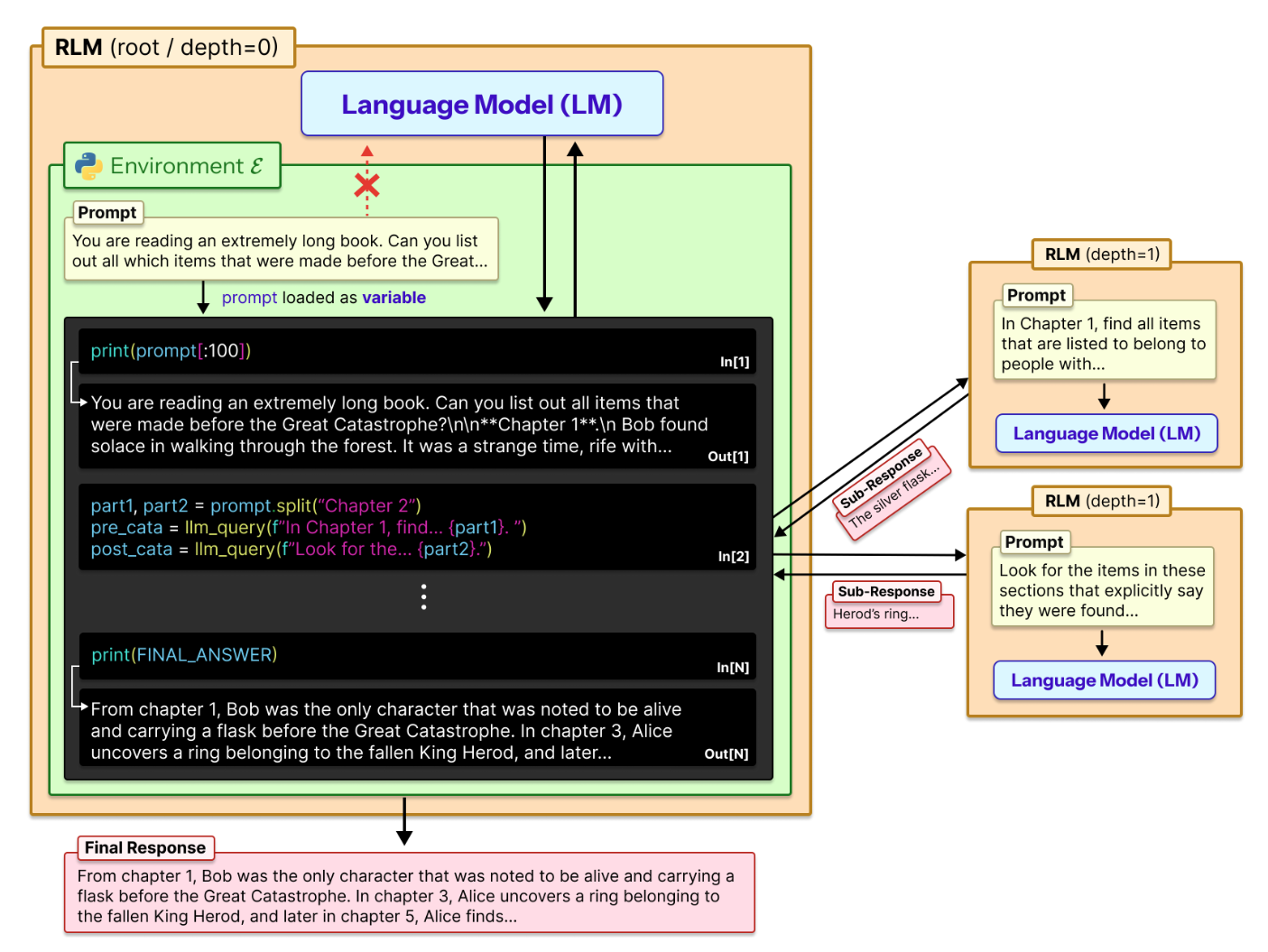
먼저 [RLM(root/depth=0)] 단계에서는 사용자의 긴 입력 프롬프트('You are reading an extremely long book. Can you list out all which ...')를 환경 변수(prompt)로 할당합니다. In[1]에서 Root LM은 입력 데이터를 파악하기 위해 print(prompt[:100]) 과 같은 코드를 생성 및 실행하여 입력 데이터의 앞부분을 확인하고 데이터의 구조를 파악합니다. In[2]에서는 데이터가 "Chapter"로 구분되어 있음을 확인한 모델은 prompt.split("Chapter ...") 와 같은 코드를 생성 및 실행하여 입력 텍스트(prompt)를 분할합니다.
이 후, 분할된 각 파트(part1, part2)에 대해 llm_query를 호출합니다. 이때 "1장에서는 ...를 찾아라"와 같은 구체적인 지시사항을 하위 모델에게 전달합니다. 이 호출은 새로운 [RLM (depth=1)] 인스턴스를 생성합니다. 하위 모델은 전달받은 텍스트 조각을 처리하여 "The silver flask"나 "Herod's ring"과 같은 중간 결과(Sub-Response)를 반환합니다.
In[N]에서는 Root LM은 이러한 중간 결과들을 모아서 최종 답변(FINAL_ANSWER)을 생성하고 출력합니다. 즉, RLM이 단순히 긴 텍스트를 읽는 것이 아니라, 코드를 통해 적극적으로 데이터를 탐색하고 구조화하여 처리하는 에이전트로서의 면모를 보여줍니다.
Root LM과 Solver Loop: Python REPL을 매개로 한 상호작용 구조
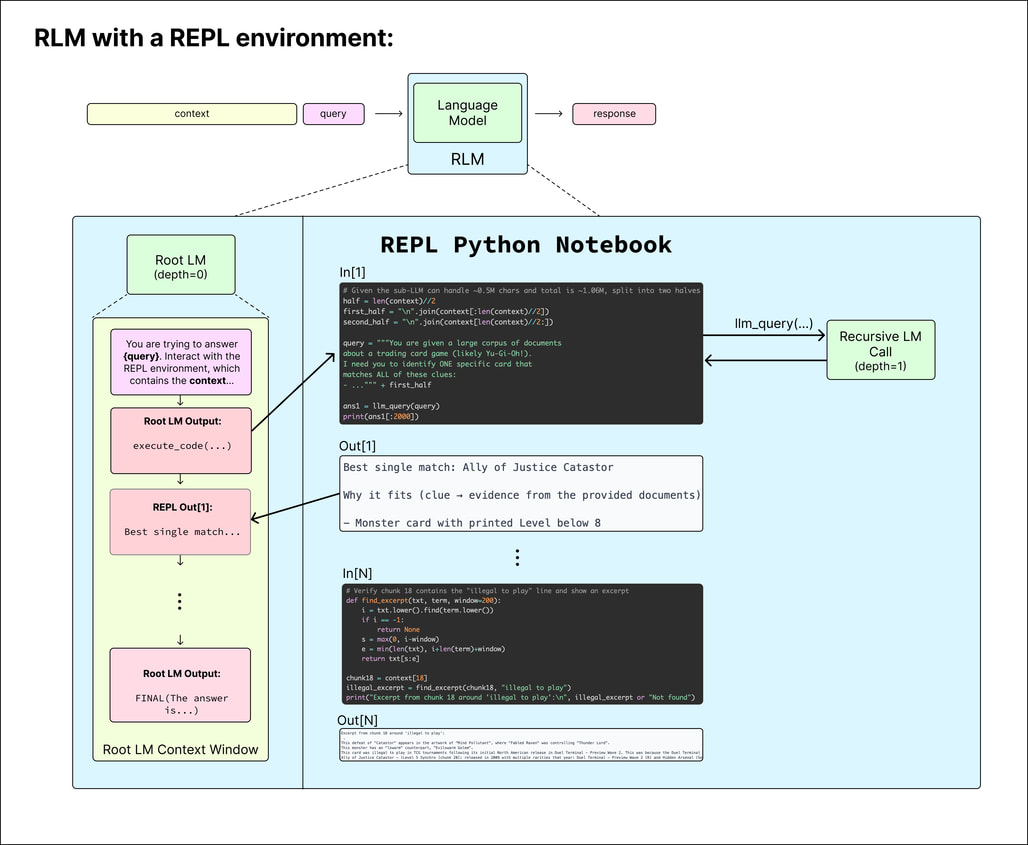
RLM 시스템의 중심에는 Root LM이 있습니다. 사용자의 질문이 들어오면 Root LM은 세션(Session)을 시작합니다. 이 세션은 전형적인 에이전트 루프(Agentic Loop)를 따릅니다. Root LM은 현재까지의 실행 기록(Trace)을 바탕으로 다음에 수행할 행동(Action)을 결정합니다. 이 행동은 주로 Python 코드 블록으로 출력됩니다. 생성된 코드는 연결된 Python 인터프리터에서 즉시 실행되고, 그 실행 결과(Observation)는 다시 텍스트 형태로 변환되어 Root LM의 프롬프트에 추가됩니다.
이 과정은 모델이 최종 답변(FINAL(answer))을 내놓을 때까지 반복됩니다. 중요한 점은 Root LM이 단순히 데이터를 읽는 것뿐만 아니라, 데이터를 가공하고 분석하는 코드도 작성할 수 있다는 점입니다. 예를 들어, 특정 키워드가 포함된 문장만 추출하는 정규표현식(Regex)을 작성하거나, 데이터의 통계를 내는 pandas 코드를 실행할 수도 있습니다. 이것이 RLM을 단순한 검색기가 아닌 추론 엔진(Reasoning Engine) 으로 만드는 핵심입니다.
재귀 호출 인터페이스 설계: llm_query 함수와 자연어 쿼리 처리
RLM 연구의 백미이자 RLM(Recursive Language Model)이라는 이름의 유래는 바로 재귀(Recursion) 구조입니다. Root LM이 Python 환경에서 사용할 수 있는 도구 중 가장 강력한 것이 바로 자기 자신을 호출하는 함수, 즉 llm_query(sub_context, sub_instruction)입니다.
Root LM은 주어진 문제를 해결하다가 문맥의 특정 부분에 대해 깊이 있는 이해가 필요하다고 판단하면, 해당 부분(sub_context)과 그 부분에 대해 수행해야 할 지시사항(sub_instruction)을 인자로 포함하여 llm_query 함수를 호출합니다.
상위 모델(Caller)이 하위 모델(Callee)을 호출하면, 하위 모델은 자신만의 독립적인 REPL 환경과 문맥을 할당받아 새로운 RLM 인스턴스로 동작합니다. 이 하위 모델 역시 필요하다면 또다시 자신을 호출할 수 있습니다. 이는 POSIX의 fork() 시스템 콜과 유사하며, 각 호출은 독립적인 메모리 공간(Context Window)을 가짐으로써 전체 시스템의 문맥 한계를 무한대로 확장합니다.
재귀 깊이 제어 및 종료 조건: 무한 루프 방지와 토큰 비용 최적화
재귀 알고리즘의 영원한 숙제는 종료 조건(Base Case)입니다. RLM 역시 모델이 계속해서 llm_query를 호출하며 무한 루프에 빠질 위험이 있습니다. 이를 방지하기 위해 구현 단계에서 몇 가지 안전장치를 마련해야 합니다.
첫째는 최대 재귀 깊이(Max Recursion Depth) 를 설정하여 일정 깊이 이상으로는 하위 모델을 호출할 수 없게 제한해야 합니다. RLM 연구에서는 깊이가 깊어질수록 더 강력한 모델을 쓰거나, 반대로 말단 노드(Leaf Node)에서는 가벼운 모델을 사용하여 단순 요약만 수행하게 하는 등의 전략을 언급하고 있습니다.
둘째는 토큰 예산(Token Budget) 관리입니다. 각 재귀 호출은 비용을 발생시키므로, 전체 작업에 사용할 수 있는 총 토큰 수를 설정하고 이를 소진하면 강제로 작업을 종료하거나 현재까지의 결과를 반환하도록 해야 합니다.
마지막으로, 모델의 프롬프트 시스템 메시지(System Message)에 "정보를 충분히 찾았다면 FINAL(답변)을 출력하여 종료하라"는 명확한 지침을 포함해야 합니다. 실제 코드에서는 모델의 출력을 파싱하여 FINAL 키워드가 감지되면 즉시 루프를 탈출하고 최종 답안을 사용자에게 반환하는 로직이 필수적입니다.
RLM 실험 설계 및 평가 지표
RLM 연구자들은 단순히 입력 텍스트의 길이를 늘리는 것뿐만 아니라, 문제의 '복잡도(Complexity)'가 증가함에 따라 모델의 성능이 어떻게 변화하는지를 측정 및 분석하기 위해 세심하게 벤치마크를 설계했습니다. 저자들은 유효 컨텍스트 윈도우가 작업의 난이도와 독립적일 수 없다는 가설을 세우고, 이를 검증하기 위해 정보 밀도와 처리 비용의 스케일링 법칙이 서로 다른 5가지의 벤치마크들을 선정했습니다.
먼저, 가장 기본적인 벤치마크인 S-NIAH (Single Needle-in-a-Haystack) 입니다. S-NIAH는 RULER 벤치마크를 따르는 것으로, 방대한 텍스트 더미 속에서 특정 문구인 '바늘(needle)' 하나를 찾아내는 과제입니다. 입력 텍스트가 아무리 길어져도 찾아야 할 정답은 하나뿐이므로, 이 작업의 처리 복잡도는 입력 길이에 대해 상수 시간(O(1))의 관계를 가집니다. 최신 프론티어 모델들은 대부분 이 테스트를 무난하게 통과합니다.
다음으로, 실제 에이전트 환경과 유사한 BrowseComp-Plus (1K documents) 벤치마크가 사용되었습니다. 이는 OpenAI의 DeepResearch와 유사한 환경을 가정하여, 1,000개의 문서(약 830만 토큰 분량) 내에서 멀티 홉(Multi-hop) 추론을 통해 정답을 찾아야 하는 질의응답 과제입니다. S-NIAH와 달리 여러 문서에 흩어진 정보를 조합해야 하므로 난이도가 높지만, 여전히 정답 도출에 필요한 핵심 문서의 수는 제한적이기에 비교적 효율적인 처리가 가능합니다.
여기에 더해, 텍스트의 모든 부분을 꼼꼼히 읽고 처리해야 하는 고밀도 작업인 OOLONG 벤치마크가 포함되었습니다. OOLONG은 입력된 텍스트의 거의 모든 줄을 읽고 의미론적으로 변환한 뒤 집계해야 하는 작업으로, 입력 길이에 비례하여 처리 비용이 선형적으로 증가(O(N))하는 특성을 가집니다.
추가적으로 RLM 연구자들은 이보다 훨씬 어려운 OOLONG-Pairs라는 새로운 작업을 고안했습니다. 이는 데이터 항목들 간의 모든 '쌍(Pair)' 관계를 분석하고 집계해야 하는 과제로, 입력 길이의 제곱에 비례하는 2차 복잡도(O(N^2))를 가지며 현존하는 LLM들에게 높은 난이도를 선사합니다.
마지막으로, LongBench-v2 CodeQA 벤치마크가 중요한 한 축을 담당합니다. 이는 대규모 코드 저장소(Code Repository)를 이해하고 다지선다형 질문에 답해야 하는 과제입니다. 단순한 텍스트 검색을 넘어 코드 파일 간의 의존성, 클래스 상속 관계, 설정 파일의 구조 등을 파악해야 하므로 실제 소프트웨어 엔지니어링 환경과 매우 유사한 복잡성을 띱니다. 파일의 개수나 코드의 양이 늘어날수록 모델이 파악해야 할 문맥적 정보가 기하급수적으로 늘어나기 때문에, 앞서 언급한 합성 데이터셋(Synthetic datasets)과는 또 다른 차원의 실전형 난이도를 제공합니다.
비교 실험을 위한 베이스라인으로는 현재 가장 강력한 폐쇄형 모델인 GPT-5와 개방형 모델인 Qwen3-Coder-480B가 선정되었습니다. 연구팀은 이 모델들을 단순히 사용하는 경우(Base Model)와, 기존의 긴 문맥 처리 방식인 요약 에이전트(Summary Agent), 그리고 코드 실행과 검색 도구를 사용하는 CodeAct 에이전트와 비교하였습니다. 특히 RLM의 경우, 재귀적 호출 기능을 뺀 단순 REPL 활용 버전(RLM without sub-calls)을 별도로 실험하여 재귀 호출이 성능에 미치는 영향을 구체적으로 분석했습니다.
RLM 실험 결과 및 성능 분석
실험 결과, RLM은 단순히 긴 입력을 처리하는 것을 넘어, 높은 복잡도를 갖는 문제에서도 좋은 성능을 발휘함을 확인할 수 있었습니다.
앞서 살펴본 것과 같이, 위 그래프는 입력 컨텍스트의 길이와 작업 복잡도에 따른 성능 저하를 시각적으로 잘 보여줍니다. GPT-5 베이스 모델은 단순한 S-NIAH 작업에서는 긴 길이에서도 성능을 유지했지만, 복잡한 OOLONG이나 OOLONG-Pairs 작업에서는 컨텍스트 길이가 조금만 늘어나도 성능이 급격히 하락하여 0점에 수렴하는 모습을 보였습니다. 반면, RLM을 적용한 GPT-5는 모델의 물리적 한계를 훌쩍 뛰어넘는 100만 토큰 이상의 입력에서도, 그리고 복잡한 작업에서도 완만한 성능 저하를 보이며 강력한 일관성을 유지했습니다.
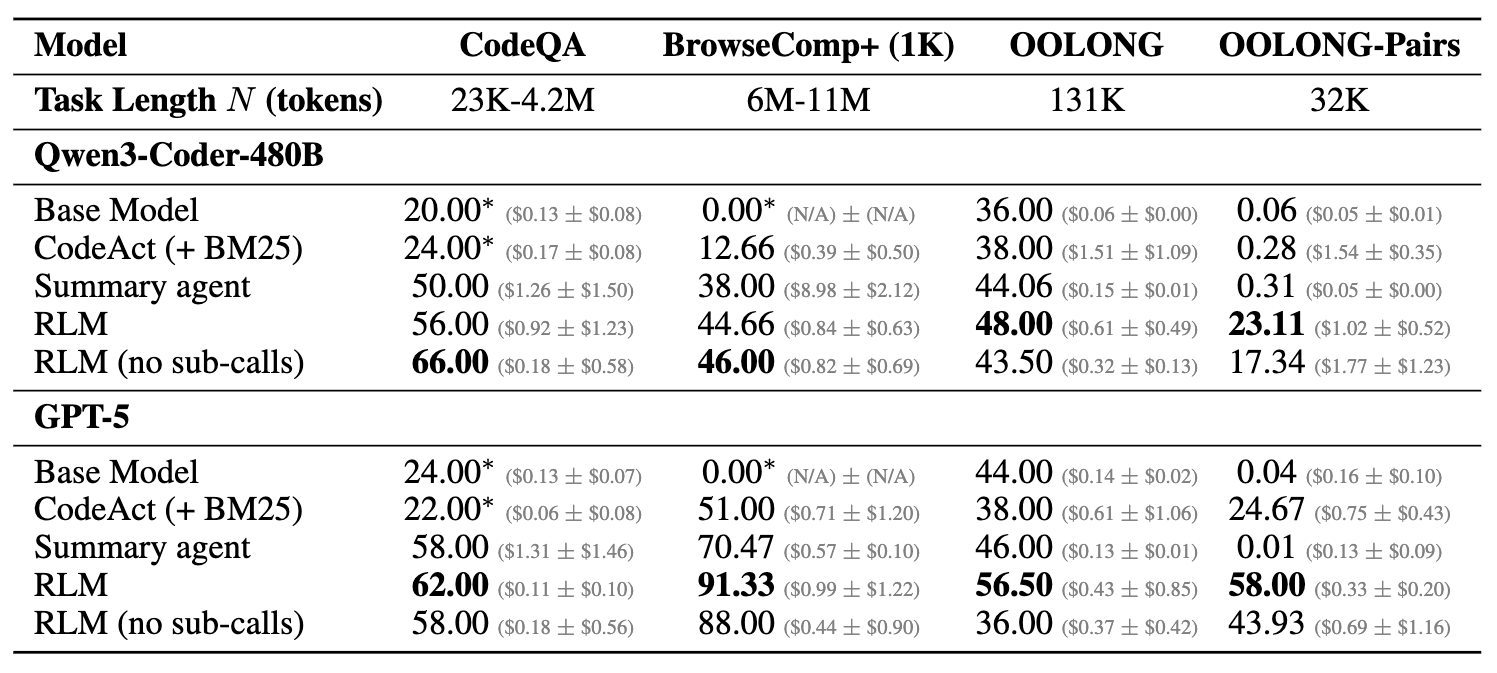
구체적인 수치를 보면 RLM의 성능 우위를 더욱 명확하게 확인할 수 있습니다. 특히 LongBench-v2 CodeQA 벤치마크에서 RLM의 활약이 두드러집니다. Qwen3-Coder-480B 모델을 기준으로 베이스 모델은 20.00점, CodeAct 에이전트는 24.00점에 그친 반면, RLM은 56.00점을 기록하며 두 배 이상의 성능 향상을 이뤄냈습니다.
흥미로운 점은 Qwen3 모델의 경우 재귀 호출(sub-calls)을 사용하지 않고 REPL 환경만 사용한 버전이 66.00점으로 더 높은 점수를 기록했다는 것인데, 이는 모델의 코딩 능력에 따라 최적의 전략이 달라질 수 있음을 시사합니다. GPT-5를 사용한 경우에도 베이스 모델(24.00점)이나 CodeAct(22.00점)보다 RLM(62.00점)이 압도적으로 높은 점수를 기록했습니다.
대규모 문서 처리 능력을 평가하는 BrowseComp-Plus에서도 RLM은 독보적이었습니다. 베이스 모델들은 6백만~1천 1백만 토큰에 달하는 입력을 아예 처리하지 못했지만, RLM(GPT-5)는 **91.33%**라는 놀라운 정확도를 기록했습니다. 이는 검색(Retrieval)에 의존하는 CodeAct 방식(51.00%)이나, 내용을 압축하여 처리하는 요약 에이전트(70.47%)를 크게 상회하는 결과입니다.
가장 난이도가 높은 OOLONG-Pairs 작업 결과는 RLM의 진가를 증명합니다. 기존의 베이스 모델들과 다른 에이전트 방식들이 거의 0점에 가까운 점수를 기록하며 전멸한 가운데, RLM(GPT-5)는 유일하게 **58.00%**의 F1 점수를 달성하며 문제를 해결해냈습니다. 이는 RLM이 단순히 정보를 검색하는 것을 넘어, 방대한 데이터를 체계적으로 분해하고 연산하는 '추론' 능력을 갖추었음을 의미합니다.
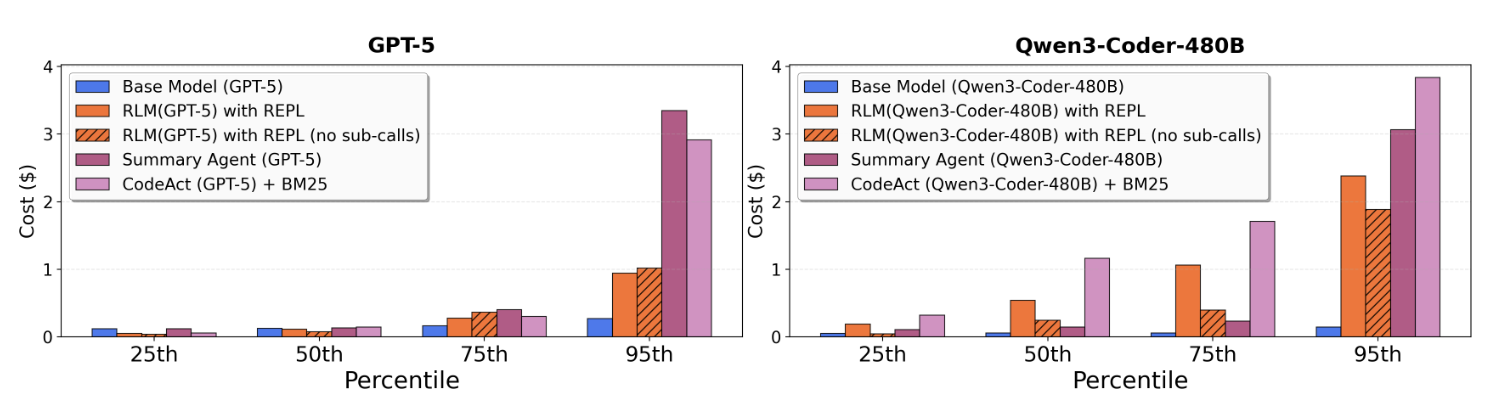
비용 효율성 측면에서도 RLM은 긍정적인 결과를 보여주었습니다. 연구진들이 수행한 비용 분석 결과에 따르면, RLM은 필요한 부분만 선택적으로 읽고 처리(Selective viewing)하는 전략 덕분에 전체 텍스트를 모두 처리해야 하는 요약 에이전트보다 훨씬 저렴한 비용으로 더 높은 성능을 냈습니다. 물론 실행 과정에서 재귀 호출이 깊어지거나 길어질 경우 비용이 증가하는 꼬리(Tail) 현상이 관찰되기도 했지만, 평균적으로는 성능 대비 매우 합리적인 비용 구조를 가짐을 확인했습니다.
RLM의 창발적 행동 패턴 (Emergent Patterns)
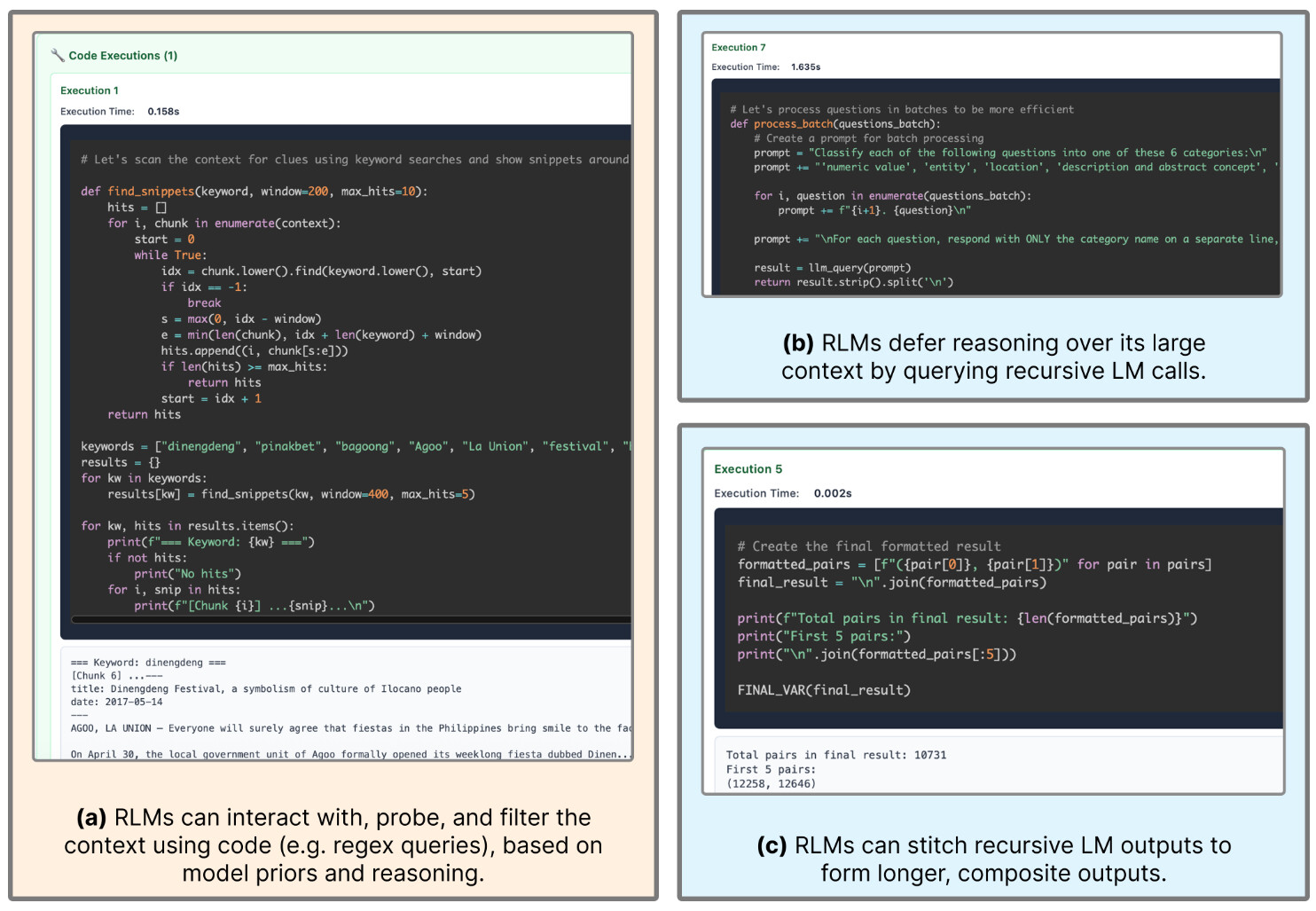
RLM은 별도의 파인 튜닝 없이도 추론 전략의 변경만으로 매우 지능적인 행동 패턴들을 보여주었습니다. RLM 연구자들은 이를 창발적(Emergent) 행동이라 이름 붙이고 4가지 주요 유형들을 분석했습니다:
첫번째로 관찰된 패턴은 코드 실행을 통한 정보 필터링과 사전 지식 활용(Filtering input information using code execution based on model priors) 입니다. 모델은 거대한 입력 프롬프트를 무작정 읽는 대신, 파이썬의 정규표현식(RegEx, Regular Expression) 기능을 활용하여 중요한 키워드가 포함된 부분만을 효율적으로 발췌(filtering)했습니다. 예를 들어 축제(festival)에 대한 정보를 찾을 때, 프롬프트에 없더라도 특정 지명(예. La Union)이 연관되어 있음을 추론하고 이를 포함된 문단을 먼저 코드로 찾아낸 뒤, 그 부분에 대해서만 LLM이 독해를 수행하는 방식입니다. 이는 사람이 두꺼운 책에서 색인을 통해 필요한 페이지를 찾는 것과 유사한 전략으로, RLM이 단순한 기계적 검색기가 아니라, 문맥을 이해하고 능동적으로 단서를 찾아나가는 에이전트임을 보여줍니다.
두번째 패턴은 조각을 쪼갠 뒤 재귀적 하위 호출을 통한 문제 분해(Chunking and recursively sub-calling LMs) 입니다. 특히 OOLONG과 같이 정보 밀도가 높은 작업이나 LongBench-v2 CodeQA와 같이 구조적인 이해가 필요한 작업에서 이 패턴이 두드러졌습니다. 예를 들어, 거대한 코드 저장소를 분석해야 할 때 모델은 파일 단위나 디렉터리 단위로 텍스트를 분할(Chunking)하고, 각 부분에 대해 "이 코드 파일이 문제의 기능과 관련이 있는가?"를 묻는 하위 작업(Sub-task)을 생성하여 자기 자신을 재귀적으로 호출하여 정보를 추출했습니다. 그리고 각 호출에서 얻은 단서들을 변수에 모아 최종적으로 정답을 추론해냈습니다. 특히 정보 밀도가 높은 작업에서 RLM은 이러한 방식을 통해 전체 텍스트를 꼼꼼하게 훑어보고(Linear scan), 필요한 정보를 빠짐없이 수집하는 전략을 취합니다. 이는 복잡한 문제를 '분할 정복(Divide and Conquer)' 알고리즘으로 해결하는 모습과 정확히 일치합니다.
세번째 패턴은 작은 문맥를 활용한 답변 검증(Answer verification through sub-LM calls with small contexts) 입니다. RLM은 답을 도출한 후 즉시 출력하지 않고, 종종 하위 모델을 호출하여 **'이 답이 정말 맞는지 확인해줘'**라고 요청하는 모습을 보입니다. 이 때 중요한 점은, 검증을 수행하는 하위 모델에게는 전체 텍스트가 아닌 검증에 필요한 핵심 텍스트 조각(Small Contexts) 만을 입력으로 준다는 것입니다. 이는 긴 문맥에서 발생할 수 있는 컨텍스트 부패(Context Rot) 문제를 방지하고 검증의 정확도를 높이는 매우 효과적인 전략입니다. 실제 사례(논문의 Example B.1 참고)에서 RLM은 날짜나 이름과 같은 세부 정보를 확인하기 위해 별도의 하위 호출을 생성하여 정답을 확신하는 모습을 보였습니다. 하지만 모든 검증이 성공적인 것은 아니었습니다. Qwen3-Coder의 경우(논문의 Example B.3 참고), 이미 정답을 찾아놓고도 불필요하게 5번이나 검증을 반복하다가 결국 오답을 선택하는 과잉 검증(Redundant verification)의 부작용을 보이기도 했습니다.
마지막으로 변수를 통한 긴 출력 생성 및 검증(Passing recursive LM outputs through variables for long output tasks) 패턴도 흥미롭습니다. 모델의 출력 토큰 제한으로 인해 한 번에 생성할 수 없는 긴 답변을 만들어야 할 때, RLM은 하위 모델들이 생성한 부분적인 답변들을 리스트 형태의 변수에 차곡차곡 저장했습니다. 그리고 마지막에 join 함수를 사용하여 이들을 하나의 긴 문자열로 합쳐서 출력했습니다. 또한, 일부 실행 경로에서는 모델이 답을 도출한 후 즉시 출력하지 않고, 다시 하위 모델을 호출하여 '이 답이 논리적으로 타당한지 검증하라'는 지시를 내리는 자기 검증(Self-verification) 행동을 보이기도 했습니다. 이를 통해 RLM은 베이스 모델의 출력 길이 제한을 사실상 무력화하고, 이론상 무한한 길이의 텍스트를 생성할 수 있는 능력을 갖추게 됩니다.
한계점 및 향후 연구 방향
RLM은 혁신적인 성과를 보여주었지만, 여전히 개선해야 할 과제들이 남아 있습니다. 가장 큰 문제는 실행 속도와 비용의 변동성입니다. 현재 RLM의 구현은 모든 재귀 호출이 동기식(Synchronous)으로 순차적으로 이루어지기 때문에, 작업이 복잡해질수록 전체 실행 시간이 길어질 수 있습니다. 저자들은 향후 비동기(Asynchronous) 호출이나 병렬 처리를 도입하면 이 문제를 획기적으로 개선할 수 있을 것으로 전망합니다.
또한 모델 간의 행동 차이도 해결해야 할 과제입니다. GPT-5는 비교적 효율적으로 재귀 호출을 관리한 반면, Qwen3-Coder 모델은 때때로 지나치게 세세하게 작업을 분할하여 수천 번의 불필요한 호출을 발생시키는 경우가 있었습니다. 이는 현재의 모델들이 RLM 방식으로 작동하도록 훈련받지 않았기 때문에 발생하는 비효율성입니다. 저자들은 이를 해결하기 위해, 모델이 언제 텍스트를 읽고, 언제 코드를 실행하며, 언제 하위 모델을 호출해야 하는지를 명시적으로 학습시키는 RLM 특화 학습(Training for RLMs) 이 필요하다고 제안합니다.
결론
지금까지 살펴본 Recursive Language Models 연구는 LLM의 컨텍스트 한계를 극복하기 위해 프롬프트를 '읽어야 할 텍스트'가 아닌 '프로그래밍 가능한 환경 변수'로 재정의하는 패러다임 전환을 시도했습니다. 이 시도는 LongBench-v2 CodeQA와 같은 실전형 코드 분석 과제부터 OOLONG-Pairs와 같은 극악의 난이도를 가진 추론 과제에 이르기까지, 기존 모델들이 해결하지 못했던 영역에서 압도적인 성능 향상을 이끌어냈습니다.
RLM은 LLM을 단순한 텍스트 생성기에서 거대한 정보를 능동적으로 탐색하고 구조화하여 처리하는 진정한 의미의 '컴퓨팅 에이전트'로 진화시킬 수 있는 강력한 가능성을 보여주었습니다. 앞으로 모델 자체가 이러한 재귀적 사고 과정을 내재화하는 방향으로 발전한다면, 우리는 곧 무한에 가까운 정보를 자유자재로 다루는 인공지능을 만나게 될 것입니다.
 Recursive Language Models (RLM) 논문
Recursive Language Models (RLM) 논문
Recursive Language Models (RLM) 소개 블로그
 Recursive Language Models 공식 GitHub 저장소
Recursive Language Models 공식 GitHub 저장소
논문이 제안한 RLM을 실제로 적용할 수 있도록 설계된 확장 가능한 범용 추론 라이브러리 저장소입니다:
Recursive Language Models 공식 GitHub 저장소: 학습 및 프로토타이핑용
RLM의 핵심 아이디어를 가장 단순한 형태로 구현한 교육용 또는 프로토타이핑용 저장소입니다:
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()