Sakana Fugu 소개
Sakana AI가 2026년 6월 22일, 여러 개의 최첨단 LLM을 하나의 모델처럼 다룰 수 있게 해 주는 새로운 제품 Sakana Fugu 를 공개했습니다. Fugu는 멀티 에이전트 오케스트레이션 시스템 전체를 단일 기반 모델(foundation model)로 포장한 제품으로, 사용자는 단 하나의 OpenAI 호환 API 엔드포인트에 요청을 보내기만 하면 됩니다. 내부에서는 Fugu가 작업의 성격을 판단해 직접 답하거나, 여러 전문 모델로 구성된 팀을 동적으로 편성하고 조율해 복잡하고 여러 단계로 이뤄진 문제를 풀어냅니다.
여기서 핵심은 Fugu 자체가 하나의 언어 모델(Language Model) 이라는 점입니다. Fugu는 에이전트 풀(agent pool) 안의 다양한 LLM을 언제, 어떻게 호출할지를 학습한 모델이며, 필요하면 자기 자신을 재귀적으로 호출하기도 합니다. 즉, 외부에서 보면 사용자는 그저 모델 하나를 부르고 있지만, 내부에서는 협조하는 전문가 집단이 일을 나눠서 처리하고 있는 구조입니다. 이를 통해 특정 벤더 한 곳에 종속되지 않으면서도, 또 전통적인 멀티 에이전트 시스템을 직접 구축하는 복잡함을 떠안지 않으면서도, 프론티어급 성능의 집단 지성(collective intelligence)을 워크플로우에 곧장 연결할 수 있습니다.
Sakana AI는 이전부터 진화 기반 접근과 집단 지성을 일관되게 탐구해 온 연구소입니다. 과학 연구 자동화를 시도한 The AI Scientist, 특이값(singular value) 단위로 가중치를 조정해 스스로 적응하는 Transformer², 시간 축에서 사고를 전개하는 Continuous Thought Machine, 그리고 최대 8시간 자율 추론으로 전략 리서치를 수행하는 첫 상용 제품 Sakana Marlin까지, Fugu는 이러한 흐름의 연장선 위에 놓여 있습니다. 이번 글에서는 출시 발표와 함께 공개된 기술 보고서(Technical Report)의 내용까지 함께 살펴보겠습니다.
더 큰 모델을 넘어서: 새로운 확장 축이 된 오케스트레이션
지난 몇 년간 AI의 진보는 주로 규모의 확장으로 이뤄졌습니다. 더 거대한 단일 모델을, 더 많은 데이터로 학습시키는 방식입니다. 그러나 현실 세계의 어려운 작업은 어느 한 벤치마크로 환원되지 않는 다양한 지식과 기술을 동시에 요구합니다. 따라서 최고의 성능을 끌어내려면 어떤 모델을 쓸지 판단하고, 계획과 실행 같은 작업을 위임하며, 모델별 강점을 결합하되 약점은 우회하는 집단 지성이 필요하다는 것이 Sakana AI의 관점입니다.
Sakana AI는 이러한 오케스트레이션을 단순한 기술적 최적화를 넘어 지정학적이고 운영상의 과제로도 바라봅니다. 조직이나 국가가 중요 인프라, 금융, 행정을 단 한 회사의 API에 의존하는 것은 현실적인 취약점이 될 수 있다는 것입니다. 실제로 발표문은 Anthropic의 Fable 및 Mythos 모델에 부과된 수출 규제를 예로 들며, 규제 경계와 외교 정책의 변화에 따라 접근 권한이 하룻밤 사이에 달라질 수 있다고 지적합니다. Sakana AI는 교체 가능한 에이전트 풀 위에서 동작하는 Fugu가 이러한 집중 위험에 대한 현실적인 대비책이 될 수 있으며, 특정 공급자가 접근을 제한하더라도 Fugu가 그 중단을 동적으로 우회한다고 설명합니다. 이러한 관점에서 이들은 오케스트레이션을 AI 주권(AI Sovereignty) 을 뒷받침하는 청사진으로 제시합니다.
이 방향성의 기술적 토대는 Sakana AI의 ICLR 2026 채택 논문 두 편입니다. 진화된 LLM 코디네이터를 다룬 Trinity 와, 자연어로 에이전트를 오케스트레이션하는 법을 학습하는 Conductor 가 그것이며, Fugu와 Fugu Ultra는 각각 이 두 연구를 제품화한 결과물입니다.
흥미로운 관점은 보고서가 Fugu를 거시적 수준의 모델 병합(model merging) 으로 본다는 점입니다. Sakana AI는 과거 진화적 모델 병합(Evolutionary Model Merge)처럼 여러 모델의 가중치를 직접 섞어 능력을 합치는 연구를 해 왔습니다. Fugu는 가중치를 평균 내거나 레이어를 꿰매는 대신, 프론티어 모델을 블랙박스 에이전트로 두고 행동 수준(behavioral level) 에서 그 능력을 조합합니다. 이 거시적 접근 덕분에 파라미터 접근이나 아키텍처 호환성이 필요 없고, 그래서 폐쇄형 프론티어 모델이나 서로 다른 공급자의 모델, 나아가 사용자별 제약 조건까지 하나의 시스템으로 엮을 수 있습니다.
Sakana Fugu란 무엇인가
Sakana Fugu는 단일 모델처럼 동작하는 멀티 에이전트 시스템입니다. 사용자가 하나의 엔드포인트로 요청을 보내면 Fugu가 처리 방식을 스스로 결정합니다. 단독으로 푸는 것이 충분하면 그대로 답하고, 더 높은 수준의 대응이 필요하면 전문 모델 팀을 편성해 연계합니다. 모델 선택, 위임, 검증, 종합이라는 과정을 모두 내부에서 관리하기 때문에, 멀티 에이전트 시스템 특유의 복잡함이 사용자의 코드까지 흘러들어오지 않습니다.
이것이 가능한 이유는 Fugu가 언제 위임해야 하는지, 에이전트들이 어떻게 소통해야 하는지, 그리고 각자의 결과물을 어떻게 하나의 신뢰할 수 있는 답으로 합쳐야 하는지 를 사람이 정한 규칙이 아니라 학습으로 습득했기 때문입니다. 기존의 멀티 에이전트 시스템 상당수가 고정된 통신 패턴이나 단일 단계 라우팅에 의존하는 것과 달리, Fugu는 그 자체가 질의마다 적응적으로 판단하는 학습된 오케스트레이터(learned orchestrator)라는 점에서 차별화됩니다.
Fugu와 Fugu Ultra: 두 가지 모델
출시 시점에 Sakana Fugu는 워크로드에 맞춰 고를 수 있는 두 가지 모델로 제공되며, 둘 다 동일한 OpenAI 호환 API로 접근합니다.
-
Fugu: 강력한 성능과 낮은 지연 시간(latency)의 균형을 맞춘 모델로, 일상적인 작업의 기본값으로 적합합니다. 입력마다 단 하나의 워커(worker)를 선택하기 때문에 프론티어 모델을 직접 호출하는 것과 비슷한 응답 속도를 유지하면서도, 매번 그 입력에 가장 적합한 에이전트로 라우팅합니다. 코딩과 코드 리뷰를 위한 Codex 같은 도구는 물론 챗봇 등 인터랙티브 서비스에도 자연스럽게 들어맞습니다. 데이터, 프라이버시, 컴플라이언스 요건이 있는 팀이라면 특정 에이전트를 풀에서 제외할 수도 있습니다.
-
Fugu Ultra: 어렵고 여러 단계로 이뤄진 문제에서 답변 품질을 최대화하도록 조정된 모델로, 입력마다 더 두터운 전문 에이전트 풀을 구성해 연계합니다. 정확도와 깊이가 가장 중요한 상황을 위해 추가적인 지연 시간을 감수하는 선택지이며, 초기 사용자들은 AI 연구, 논문 재현, 사이버 보안 분석, 문헌 및 특허 조사처럼 부하가 큰 작업에 활용했습니다. 다만 Fugu Ultra는 전체 에이전트 풀을 활용해야 성능이 나오므로 풀이 고정되어 있으며, 특정 모델을 풀에서 제외하는 옵션은 Fugu에서만 제공됩니다.
Fugu는 어떻게 동작하는가: 학습된 오케스트레이터
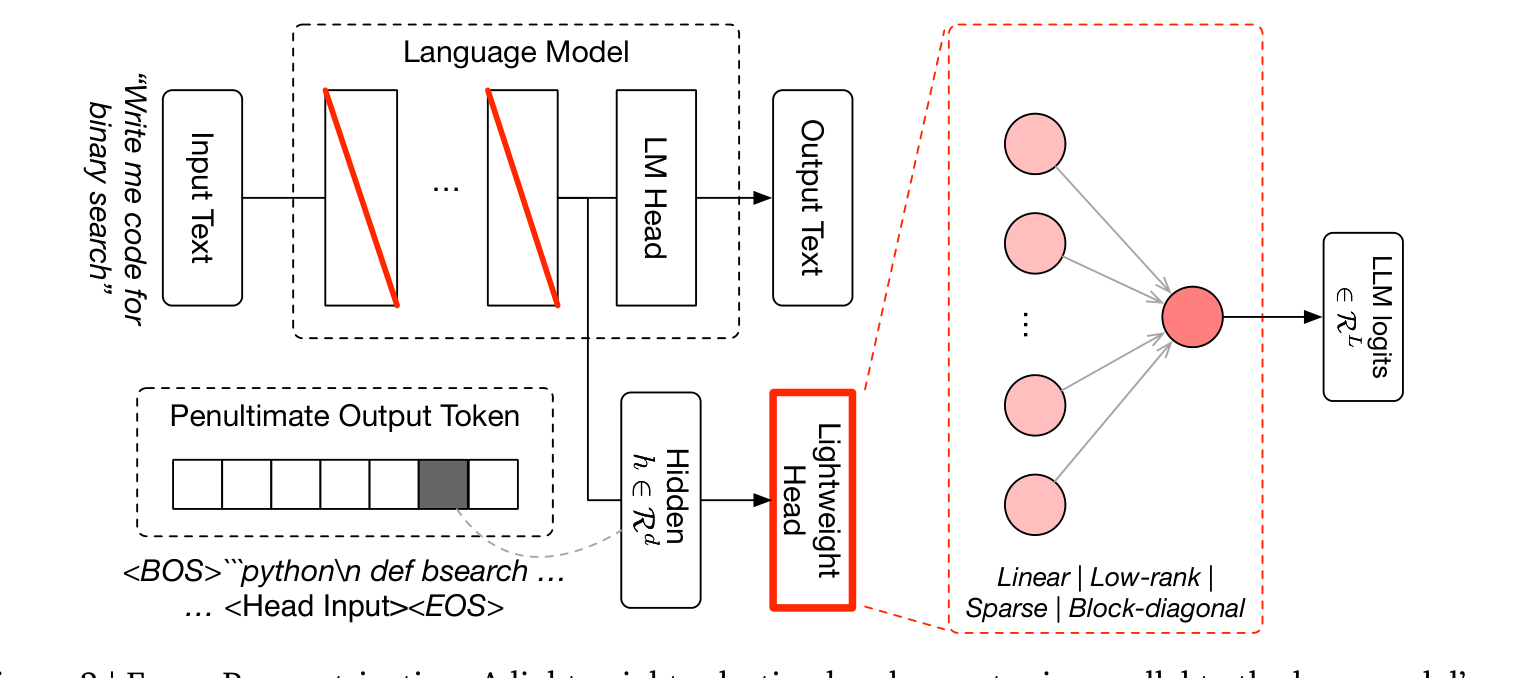
Fugu 는 Trinity를 토대로, 합리적인 지연 시간 안에서 빠르고 안정적인 라우팅을 내려야 하는 프로덕션 환경에 맞게 확장한 모델입니다. 핵심 설계는 사전 학습된 언어 모델을 백본으로 두고, 그 위에 LM 헤드와 병렬로 동작하는 경량 선택 헤드(lightweight selection head)를 붙이는 것입니다. 이 헤드는 백본의 은닉 상태 h \in \mathbb{R}^d 를 입력받아, 풀에 있는 워커 모델 수 L 만큼의 로짓을 출력합니다. 즉, 어떤 워커가 이 입력에 가장 적합한지를 점수로 매깁니다.
여기서 중요한 점은 Fugu가 생성한 텍스트 가 아니라 로짓 만으로 결정을 내린다는 것입니다. 실제 프롬프팅과 작업 실행은 선택된 워커에게 위임되므로, 오케스트레이터는 비싼 자기회귀(autoregressive) 디코딩 과정을 거칠 필요 없이 이른 토큰 위치에서 은닉 상태를 계산하고 선택 헤드를 적용해 곧바로 질의를 워커로 보냅니다. 이 "결정 전용(decision-only)" 구조가 Fugu의 낮은 지연 시간과 이후 진화 기반 최적화를 실용적으로 만드는 핵심입니다. 또한 백본 전체를 미세조정(fine-tuning)하는 대신, Transformer²에서 이어지는 특이값 미세조정(singular-value fine-tuning)으로 선택된 가중치 행렬의 특이값 스케일만 학습해, 극도로 작은 학습 파라미터만으로 라우팅 표현을 적응시킵니다.
Fugu의 학습은 두 단계로 이뤄집니다. 먼저 단일 단계 작업에 대한 지도 미세조정(SFT) 단계에서, 검증 가능한 문제마다 풀의 모든 워커 모델을 실행해 보상을 측정하고, 이를 소프트맥스로 변환해 워커에 대한 소프트 타깃 분포 p_i(j) 를 만듭니다. 그런 다음 오케스트레이터가 이 분포를 따르도록 KL 발산(KL divergence)을 최소화합니다.
단일 정답 레이블을 분류하는 대신 성능 분포 전체를 학습하기 때문에, 비슷한 실력의 워커가 여러 개일 때도 선택이 더 견고해집니다. 이어 종단간(end-to-end) 작업에 대한 진화 전략 단계에서는 Claude Code, Codex 같은 실제 코딩 어시스턴트 환경에서 수집한 멀티턴 궤적으로 sep-CMA-ES를 적용해 오케스트레이터의 종단간 보상을 직접 최대화합니다. 이 단계는 도구 사용과 환경 피드백이 결과를 좌우하는 상황에서 워커의 실질적 역량을 학습하도록 돕습니다.
Fugu Ultra 는 Conductor 프레임워크를 토대로, 장기 함수 호출(function calling)과 멀티 에이전트 워크플로우를 적응형 에이전트 메모리로 다루도록 확장한 모델입니다. Conductor는 강화학습(Reinforcement Learning)으로 언어 모델이 에이전틱 워크플로우(agentic workflow) 를 직접 자연어로 설계하도록 학습시킵니다. 각 워크플로우 단계는 자연어 하위 작업(subtask), 그 작업을 맡을 워커 에이전트의 id, 그리고 이전 단계 중 어떤 결과를 워커의 컨텍스트에 넣을지를 가리키는 접근 목록(access list)으로 구성됩니다. 이 설계 덕분에 단순한 best-of-N이나 순차적 체인부터 임의의 트리 구조 토폴로지까지 다양한 협업 구조를 자유롭게 만들어낼 수 있습니다. 학습에는 GRPO가 쓰이며, 보상은 워크플로우의 형식 적합성과 최종 정답 일치 여부로 결정됩니다.
Fugu Ultra는 Gemini 3.1 Pro, Claude Opus 4.8, GPT-5.5를 포함한 프론티어 LLM 풀을 대상으로, 최대 5단계까지의 에이전틱 워크플로우를 설계하도록 학습되었습니다. 멀티 에이전트 환경에서 함수 호출을 다루기 위해 두 가지 메커니즘이 핵심적입니다. 하나는 워크플로우 내 에이전트 격리(intra-workflow agent isolation) 로, 먼저 환경과 상호작용한 에이전트가 이후 모든 에이전트의 경로를 고정해 버리는 "오케스트레이션 붕괴(orchestration collapse)"를 막기 위해 각 에이전트가 다른 에이전트의 행동을 오직 접근 목록을 통해서만 관찰하도록 합니다. 다른 하나는 지속적 공유 메모리(persistent shared memory) 로, 멀티턴 대화의 진행 상태에 대해서는 에이전트들이 메모리를 공유하게 해 동일한 도구 호출을 반복하지 않도록 합니다. 즉, 현재 워크플로우 안에서는 서로 격리하되 대화 전체의 맥락은 공유하는 균형을 잡는 셈입니다.
벤치마크 성능
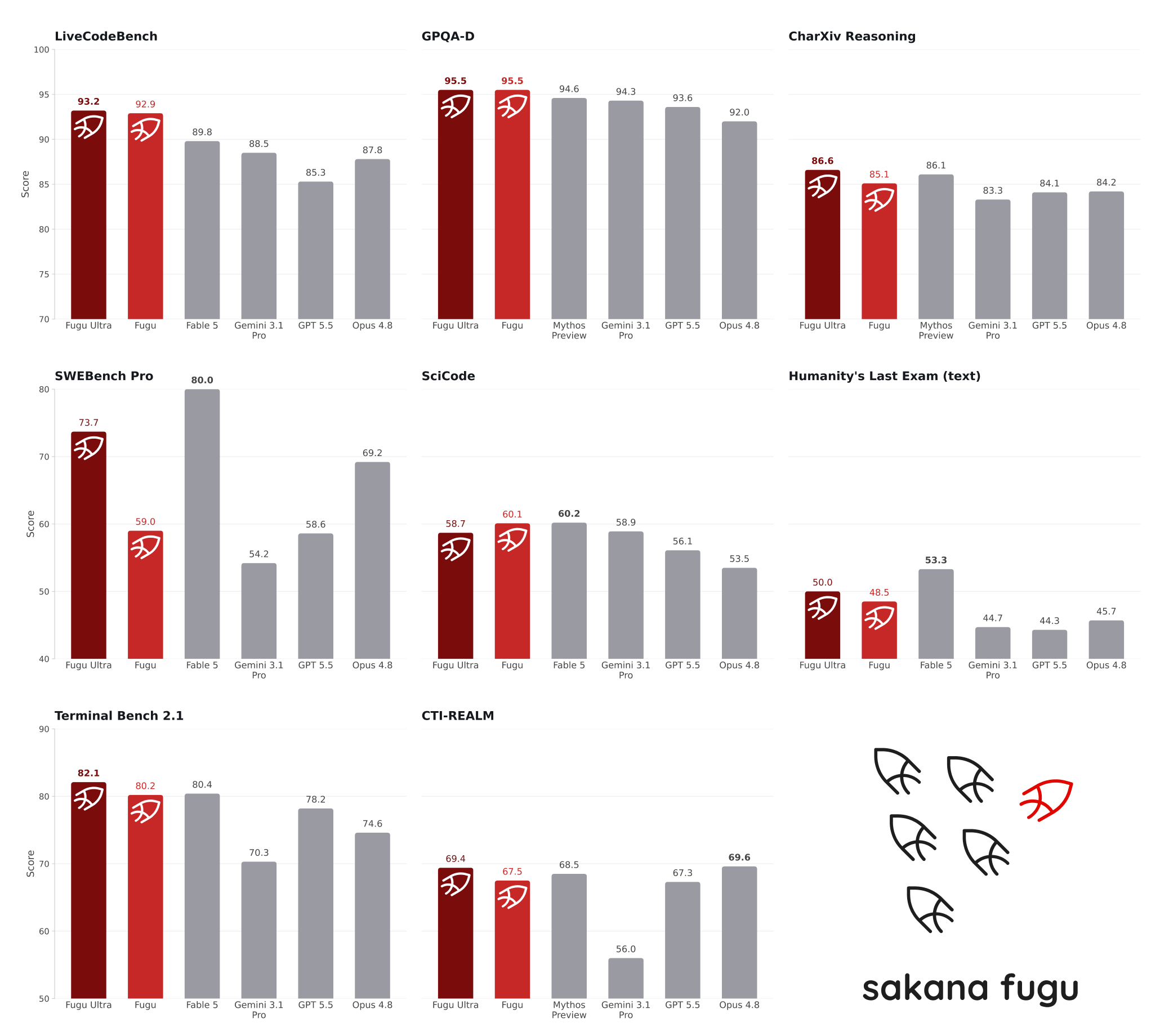
Sakana AI는 Fugu 모델이 자신이 오케스트레이션하는 기반 모델들(Gemini 3.1 Pro, Claude Opus 4.8, GPT-5.5)을 같은 조건에서 비교했을 때, 코딩과 소프트웨어 엔지니어링, 과학적 추론, 장기 컨텍스트 등 다양한 영역에서 개별 SOTA 모델을 넘어선다고 보고합니다. 특히 Fugu Ultra는 일반에 공개되지 않은 Claude Fable 5와 Mythos Preview와도 어깨를 나란히 하는 수준이라고 설명합니다(두 모델은 공개되지 않았으므로 Fugu의 에이전트 풀에는 포함되지 않습니다).
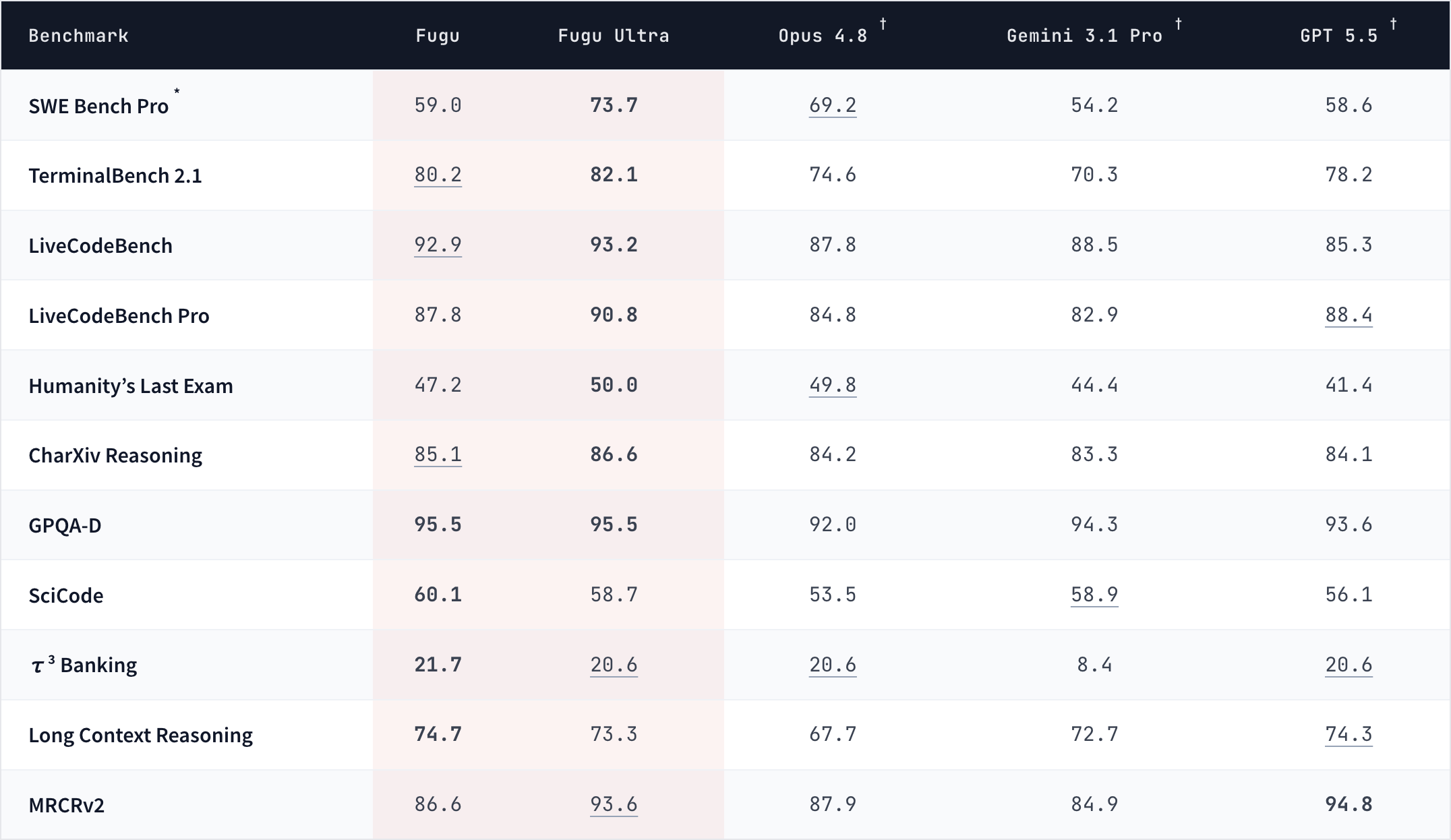
기술 보고서의 모델 카드(Table 1)에 따르면 주요 결과는 다음과 같습니다. 굵은 글씨가 최고 점수입니다.
| 벤치마크 | Fugu Ultra | Fugu | Claude Opus 4.8 | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|---|---|---|
| SWE Bench Pro | 73.7 | 59.0 | 69.2 | 54.2 | 58.6 |
| Terminal Bench 2.1 | 82.1 | 80.2 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | 93.2 | 92.9 | 87.8 | 88.5 | 85.3 |
| LiveCodeBench Pro | 90.8 | 87.8 | 84.8 | 82.9 | 88.4 |
| Humanity's Last Exam | 50.0 | 47.2 | 49.8 | 44.4 | 41.4 |
| CharXiv Reasoning | 86.6 | 85.1 | 84.2 | 83.3 | 84.1 |
| GPQA Diamond | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 |
| SciCode | 58.7 | 60.1 | 53.5 | 58.9 | 56.1 |
| \tau^3 Banking | 20.6 | 21.7 | 20.6 | 8.4 | 20.6 |
| Long Context Reasoning | 73.3 | 74.7 | 67.7 | 72.7 | 74.3 |
| MRCRv2 | 93.6 | 86.6 | 87.9 | 84.9 | 94.8 |
흥미로운 점은 입력마다 단 하나의 모델만 고르는 Fugu조차 Terminal Bench에서 풀 안의 최고 단일 모델인 GPT-5.5(78.2)를 80.2로 앞선다는 것입니다. 단일 모델만 선택하는 시스템이 그 풀의 어떤 단일 모델보다 높은 점수를 낸다는 것은, 어떤 입력에 어떤 모델을 붙일지 에 대한 판단 자체가 새로운 성능을 만들어낸다는 의미입니다. Sakana AI는 이를 두고 지능적 오케스트레이션이 학습 연산을 키우지 않고도 성능을 확장하는 또 하나의 축 이 될 수 있다는 근거로 제시합니다.
오케스트레이션은 실제로 어떤 모습인가: 빌드, 디버그, 토론
위 벤치마크 숫자 뒤에는 Fugu가 입력에 따라 협업 구조 자체를 바꾸는 세밀한 적응이 숨어 있습니다. 기술 보고서는 이 과정을 들여다본 분석을 제시하는데, 먼저 Fugu가 작업 종류에 따라 어떤 모델에 일을 맡기는지를 보면 그 적응성이 분명히 드러납니다.
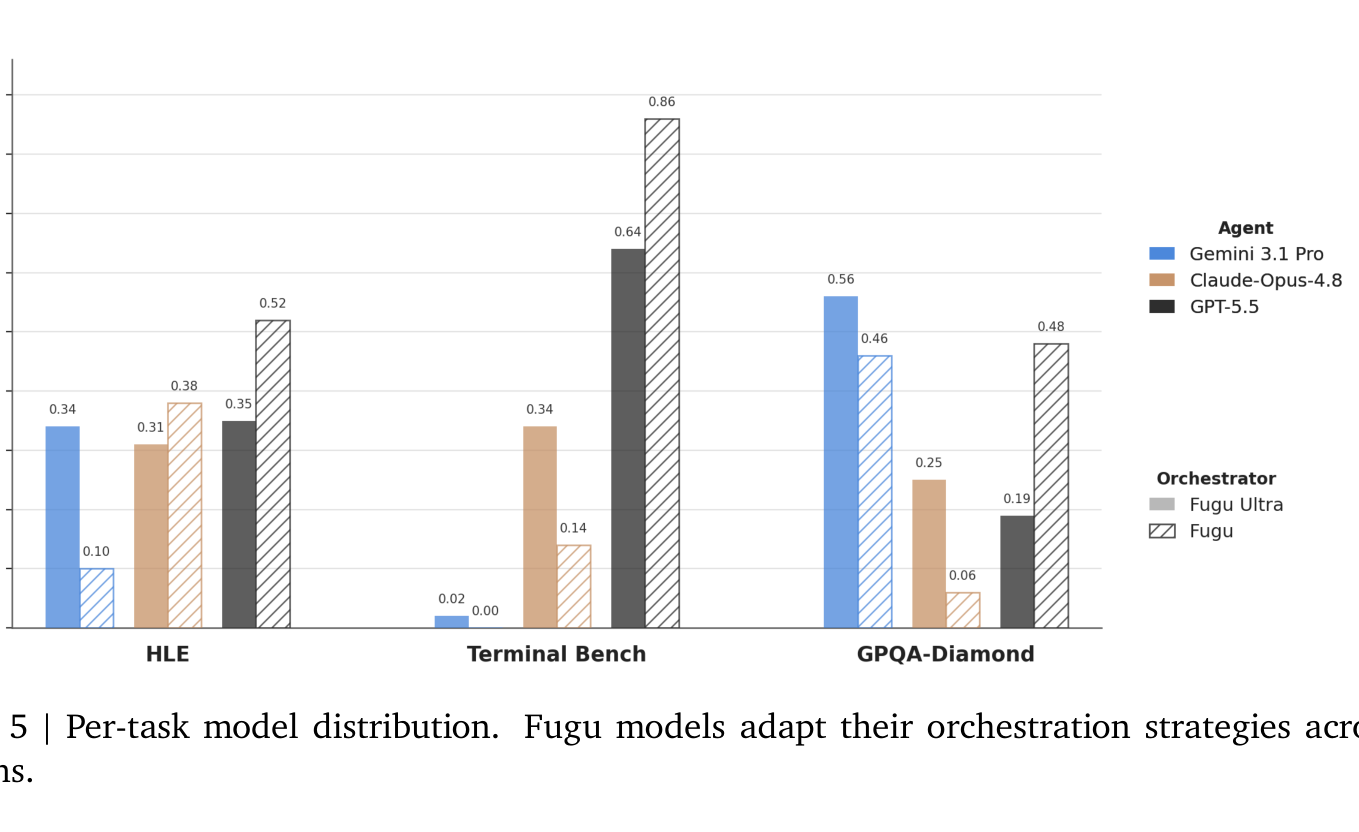
위 그림은 HLE, Terminal Bench, GPQA Diamond 세 작업에서 Fugu가 각 모델을 얼마나 호출했는지를 보여줍니다. 코딩 중심의 Terminal Bench에서는 분포가 GPT-5.5로 크게 쏠리고, 과학 지식이 핵심인 GPQA Diamond에서는 SOTA인 Gemini 3.1 Pro로 무게가 옮겨가며, 다학제적인 HLE에서는 세 모델에 비교적 고르게 분산됩니다. 세부적으로도 수학 문제는 GPT-5.5로, 화학과 생물 문제는 Gemini로 라우팅되는 식으로, 각 모델의 SOTA 영역에 작업이 배분되는 패턴이 일관되게 나타났습니다.
이러한 적응은 단순한 모델 선택을 넘어 협업 구조로도 이어집니다. 보고서가 든 대표적인 패턴은 빌드와 디버그(build and debug) 입니다. Terminal Bench에서 vectorops 패키지를 호스팅하는 PyPI 서버를 구축하는 과제에서, Fugu Ultra는 먼저 GPT-5.5를 빌더로 투입해 서버를 만들게 한 뒤 Claude Opus 4.8을 디버거로 붙였습니다. Opus는 GPT가 pypiserver 대신 평범한 정적 http.server를 썼다는 점, 손으로 만든 wheel이 zipfile 기반이라 취약하다는 점, Debian-slim 환경을 제대로 다루지 못했다는 점 등을 짚어냈고, 이 발견을 다시 GPT에게 전달해 빌드를 완성하게 했습니다. 코딩 강점을 가진 GPT와 디버깅 강점을 가진 Opus를 단계마다 번갈아 쓴 것입니다.
또 다른 패턴은 토론과 종합(debate and aggregation) 입니다. Fugu Ultra는 질문마다 자연어로 트리 구조의 협업 토폴로지를 만들어내는데, 흥미롭게도 종합을 맡는 모델(aggregator)을 작업 성격에 맞춰 바꿉니다. 게임 트리비아처럼 틈새 지식이 필요한 HLE 문제에서는 Gemini를 트리의 최상단에 두어 두 개의 독립적인 시도를 종합하게 했고, 칼라비-야우 다양체의 불변량을 계산하는 수학 문제에서는 GPT를 최상단에 두어 Gemini와 Opus가 한 정수를 두고 벌인 의견 차이를 스펙트럼 함수로 재유도해 해소하게 했습니다. 보고서는 최종 종합자를 항상 고정된 한 모델로 두는 기존 멀티 에이전트 시스템과 달리, 종합자 자체를 작업에 맞게 동적으로 바꾸는 적응성 이 Fugu의 성능을 끌어내는 핵심이라고 설명합니다.
세 번째는 분야를 가로지르는 전문가 투입(bringing in a specialist) 입니다. FEAL류 암호 함수에서 키를 복원하는 공격 코드를 작성하는 Terminal Bench 과제에서, Fugu Ultra는 사이버 보안에 강한 Opus에게 1차 선택 평문 공격을 맡긴 뒤, GPT-5.5를 수학 전문가로 투입해 암호를 비트 단위로 추적하며 공격에 필요한 차분 상수를 처음부터 다시 유도하게 했습니다. 사이버 보안, 엔지니어링, 수학이라는 서로 다른 분야의 강점을 한 작업 안에서 결합한 사례입니다.
벤치마크 너머: 실제 작업에서의 Fugu
Sakana AI는 벤치마크 점수만으로는 다 담기지 않는 길고 복잡한 실제 워크플로우에서 Fugu의 가치가 가장 뚜렷하게 드러난다고 강조합니다. 기술 보고서는 정성 평가를 위해 여러 도메인의 종단간 작업을 제시하는데, 그중 자율 ML 연구가 대표적입니다.
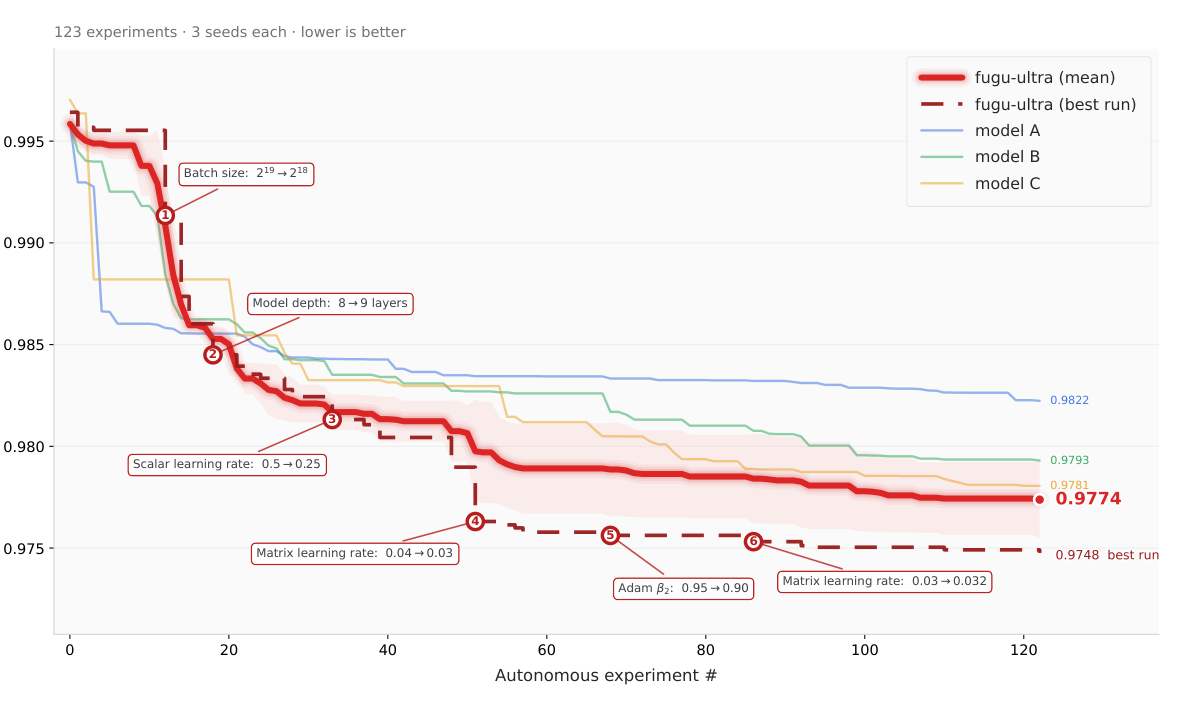
위 그래프는 Andrej Karpathy의 AutoResearch 프레임워크에서, 에이전트가 작은 GPT의 학습 레시피를 자율적으로 개선하는 실험입니다. 학습 코드를 반복적으로 수정하고 실험을 돌려 검증 bits-per-byte(BPB, 낮을수록 좋음)를 낮춘 변경만 남기는 방식으로, 단일 H100 GPU에서 약 14시간 동안 123회의 실험을 수행했습니다. Fugu Ultra(굵은 빨간 선)는 배치 크기, 모델 깊이, 학습률, 옵티마이저 설정에 이르기까지 스스로 개선점을 찾아내며, 최종적으로 가장 낮은 평균 BPB인 0.9774를 기록해 세 개의 프론티어 모델 베이스라인(0.9781, 0.9793, 0.9822)을 모두 앞섰습니다. Sakana AI는 이를 두고 여러 강력한 모델을 오케스트레이션하면 에이전트형 ML 연구에서 단일 프론티어 모델을 능가할 수 있음을 시사한다고 설명합니다.

또 다른 흥미로운 사례는 고전 일본어 가나 서간(仮名消息)의 읽기 순서 복원입니다. 문자를 지면에 흩어 배치하는 "흩어쓰기(散らし書き, chirashigaki)" 형식 탓에 고문서에 익숙한 사람조차 읽는 순서를 가려내기 어려운데, 정해진 방법도 공개 벤치마크도 존재하지 않는 문제입니다. 각 모델에 문자의 바운딩 박스와 대략적인 읽기 규칙을 주고 읽기 순서를 출력하는 코드를 작성하게 했을 때, Fugu Ultra는 정규화 편집 거리(NED) 기준 0.776으로, 가장 강한 프론티어 베이스라인(0.642)을 포함한 모든 모델을 앞섰습니다. 위 그림에서 초록색이 전문가의 정답 경로, 빨간색이 예측 경로인데, Fugu Ultra(가운데)는 흩어진 글자를 거의 정확히 따라가는 반면 베이스라인(아래)은 지면을 어지럽게 건너뜁니다.
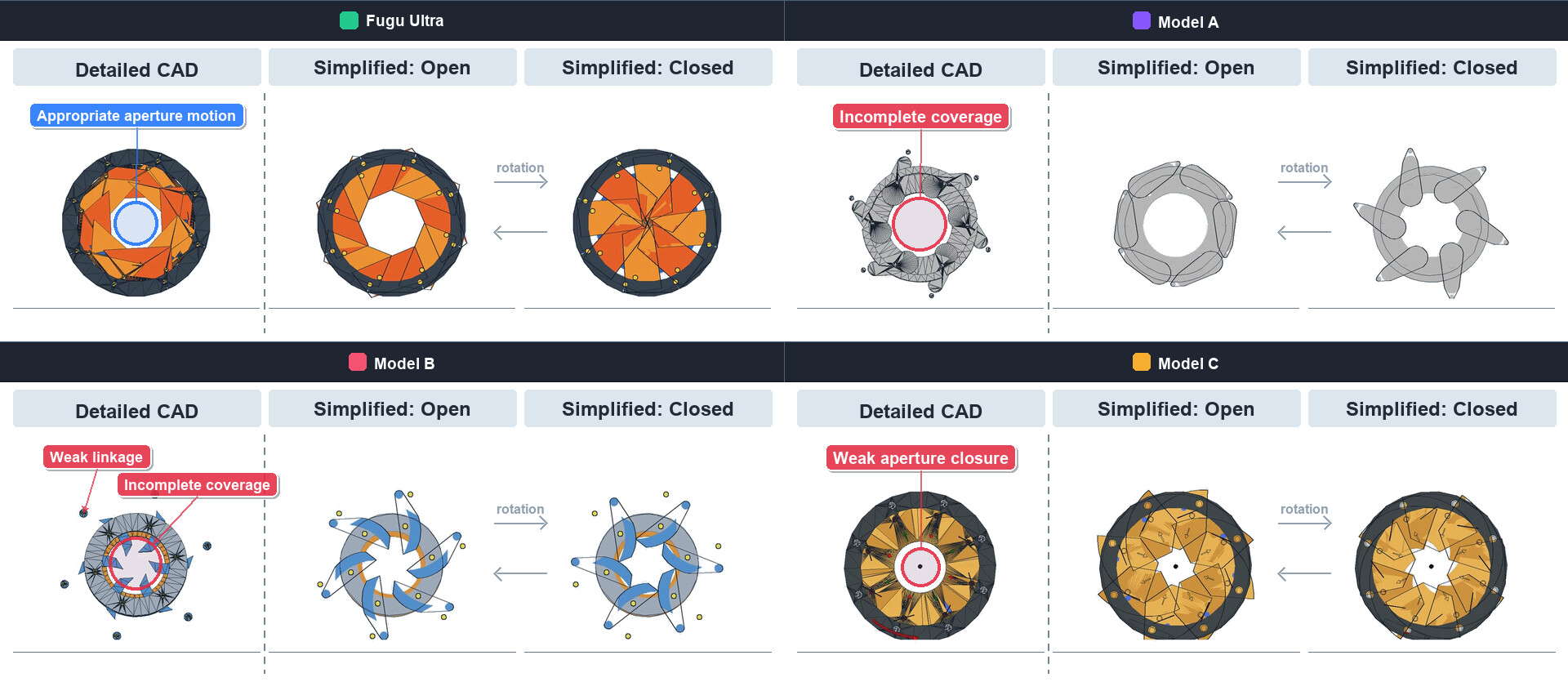
세 번째 사례는 카메라 조리개처럼 여러 날개가 연동해 중앙 구멍을 여닫는 기계식 아이리스(mechanical iris)를 CAD로 설계하는 작업입니다. Fugu Ultra가 생성한 설계(맨 왼쪽 위)는 날개가 외측 핀을 축으로 회전하며 조리개를 명확히 개폐하는 반면, 다른 모델들의 설계에서는 틈이 생기거나 링크 기구가 약하고 조리개가 충분히 닫히지 않는 문제가 나타났습니다. 이 외에도 보고서는 3개의 프론티어 모델과 2100-Elo의 Stockfish 엔진을 상대로 한 블라인드(blindfold) 체스에서 Fugu가 모두 체크메이트로 이긴 사례, 50주 윈도우 주식 트레이딩에서 평균 +19.43%의 수익률로 다른 프론티어 모델(모두 +15% 미만)을 앞선 사례 등을 함께 제시합니다.
이러한 정성 평가는 약 500명이 참여한 베타 프로그램의 피드백과도 맞닿아 있습니다. 초기 사용자들이 남긴 평가 일부를 옮기면 다음과 같습니다.
"코드 리뷰에서 Fugu Ultra는 GPT-5.5보다 확연히 낫습니다. 답변이 포괄적이고, 다른 모델이 놓치는 버그까지 찾아냅니다. 다른 도구가 약 3건의 문제를 지적할 때 Fugu는 20건 이상을 잡아냈습니다. 이제 제 모든 리뷰는 이 모델로 돌립니다."
출처: 소프트웨어 엔지니어, 코딩 및 코드 리뷰
"출력 품질 자체는 최상위 프론티어 모델과 동등하지만, Fugu는 긴 세션 내내 페르소나 안정성이 유난히 강했습니다. 다른 모델이라면 정체성이 흔들릴 상황에서도 자신을 유지했죠. 에이전트 제품에서는 이것이 단순한 벤치마크 점수보다 더 중요할 수 있습니다."
출처: 엔터프라이즈 플랫폼 기업 임원, 오케스트레이션 품질
"범위를 좁힌 지시 하나만 주었더니, Fugu는 정찰부터 XSS/SQLi 점검, 인증 검토, 그리고 증거와 재시험 절차를 갖춘 깔끔한 보고서 작성까지 보안 평가를 처음부터 끝까지 수행했습니다. 그러면서도 지정한 범위를 벗어나지 않았고 파괴적인 동작도 피했습니다."
출처: 사이버 보안 엔지니어, 보안 평가 분석
"약 20편의 논문과 여러 특허에 걸친 특허 동향 분석은 보통 3~4일 걸리는 작업입니다. Fugu로는 몇 시간 만에 완전한 분석을 얻었고, 거기에는 제가 혼자서는 결코 발견하지 못했을 논문 간의 연결까지 포함되어 있었습니다."
출처: 연구자(기업), 리서치 및 자율성
"하나의 단순한 요청에서 출발해 Fugu는 거의 4시간 동안 자율적으로 작업했습니다. 논문을 읽고, 구현하고, 학습과 평가를 거쳐 부족한 점을 분석했죠. 어떤 CUDA 작업에서는 단일 세션으로 100배 이상의 속도 향상을 달성했습니다."
출처: 연구자, 논문 재현
가격과 접근성
Sakana Fugu는 출시 시점부터 일반 제공되며, 구독 플랜과 종량제(pay-as-you-go) 플랜 모두에서 Fugu와 Fugu Ultra를 함께 이용할 수 있습니다. 모든 접근은 OpenAI 호환 API를 통하므로, 기존 클라이언트나 코딩 하네스를 Fugu 엔드포인트로 향하게 하는 것만으로 SDK 마이그레이션 없이 사용할 수 있습니다.
| 플랜 | 가격 | 특징 |
|---|---|---|
| Standard | $20/월 | 가벼운 일상 이용, 소규모 실험 |
| Pro | $100/월 | Standard의 10배 사용량, 주간 집중 작업 |
| Max | $200/월 | Standard의 20배 사용량, 장시간 고부하 워크로드 |
| 종량제(Fugu) | 기반 모델 표준 레이트 | 여러 에이전트가 동작해도 요금을 쌓지 않고 최상위 모델 기준 단일 레이트 |
종량제(Fugu Ultra, fugu-ultra-20260615) |
입력 $5 / 출력 $30 / 캐시 입력 $0.50 (100만 토큰당) | 272K 토큰 초과 시 $10 / $45 / $1.00 적용 |
종량제 플랜의 과금 방식이 특히 독특합니다. Fugu는 사용한 모든 모델의 요금을 합산하는 것이 아니라, 활성화된 에이전트 풀에 대한 단일 블렌드 레이트로 과금됩니다. 즉, 풀에 모델 A, B, C가 있어도 그중 최상위 모델의 레이트 하나만 지불하며, 에이전트를 늘려도 청구액이 곱해지지 않습니다. 또한 2026년 7월 말까지 구독하면 가입한 등급의 두 번째 달을 무료로 제공합니다. 다만 EU(유럽연합) 및 EEA(유럽경제지역) 회원국에는 서비스가 제공되지 않으며, 그 외 지역도 통신 환경이나 현지 규제에 따라 이용이 제한될 수 있습니다.
한 가지 유의할 점은, Fugu가 선택하는 구체적인 모델과 이들을 조율하는 방식은 독자 기술로 공개되지 않는다는 것입니다. 라우팅 정보가 설계상 노출되지 않으므로, Fugu는 오픈소스 모델이 아니라 폐쇄형 상용 제품으로 이해하는 편이 정확합니다.
시사점과 향후 전망
Fugu가 제시하는 핵심 메시지는 역량을 기존 모델들의 조합으로 증폭할 수 있다면, AI의 진보가 더 이상 가장 큰 학습 실행에 대한 접근성에만 의존하지 않아도 된다 는 것입니다. 새로운 프론티어 모델이 등장할 때마다 그것을 에이전트 풀에 편입하고, 약 2주간의 학습과 평가를 거쳐 갱신된 Fugu 모델로 사용자에게 그 이득을 전달한다는 계획은, 모델을 파라미터 수준이 아니라 행동 수준에서 합성한다는 발상의 자연스러운 귀결입니다.
물론 이 접근에는 검증해야 할 지점도 남아 있습니다. 라우팅 정보가 공개되지 않는다는 점은 재현성과 감사 가능성 측면에서 한계가 될 수 있고, 벤치마크 점수 상당 부분이 모델 제공사 자체 보고값에 기반한다는 점도 독립적인 검증을 기다릴 부분입니다. 그럼에도 오케스트레이션을 하나의 독립된 확장 축으로 정식화하고, 이를 단일 API라는 단순한 인터페이스로 묶어 제품화했다는 점에서 Fugu는 멀티 에이전트 시스템 연구와 실제 활용 사이의 거리를 좁히는 흥미로운 시도입니다. 멀티 에이전트 오케스트레이션에 관심이 있다면 Anthropic의 멀티 에이전트 연구 시스템이나 AI 에이전트 프로토콜 가이드와 함께 살펴보시길 권합니다.
 Sakana Fugu 출시 발표 블로그
Sakana Fugu 출시 발표 블로그
 Sakana Fugu 제품 페이지
Sakana Fugu 제품 페이지
 Sakana Fugu Technical Report
Sakana Fugu Technical Report
더 읽어보기
-
Learning to Orchestrate Agents in Natural Language with the Conductor (ICLR 2026)
-
Sakana AI의 첫 상용 제품, 최대 8시간 자율 추론으로 전략 리서치를 수행하는 Sakana Marlin 출시
-
Transformer²: 자기 적응형 LLM(Self-Adaptive LLMs)에 대한 연구 (feat. Sakana AI)
-
AI 에이전트 프로토콜 개발자 가이드: MCP부터 A2A, UCP, AP2, A2UI, AG-UI까지 (feat. Google)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()