
slime 소개
최근 대규모 언어 모델(LLM)의 발전은 사전 학습(Pre-training)을 넘어 강화학습(RL) 기반의 사후 학습(Post-training) 단계에서 패러다임의 전환을 맞이하고 있습니다. 특히 DeepSeek R1이나 OpenAI의 o1 모델처럼 복잡한 추론 능력을 극대화하기 위해 강화학습의 규모를 키우는 RL Scaling이 핵심 기술로 떠오르고 있습니다. 이러한 흐름 속에서 칭화대 KEG 연구실 및 Zhipu AI와 깊은 연관이 있는 THUDM(Tsinghua University Data Mining) 그룹이 RL 확장을 위한 LLM 사후 학습 프레임워크인 slime을 오픈소스로 공개했습니다.
slime은 크게 두 가지 핵심 기능을 제공합니다. 첫 번째는 고성능 학습(High-Performance Training) 으로, 대규모 분산 학습 프레임워크인 NVIDIA의 Megatron-LM과 고성능 추론 엔진인 SGLang을 매끄럽게 연결하여 다양한 모드에서 효율적인 학습을 지원합니다. 두 번째는 유연한 데이터 생성(Flexible Data Generation) 으로, 사용자 정의 데이터 생성 인터페이스와 서버 기반 엔진을 통해 연구자와 개발자가 원하는 형태의 학습 데이터 생성 워크플로우를 자유롭게 구성할 수 있도록 돕습니다.
slime 프레임워크는 단순히 실험적인 프로젝트에 그치지 않고, 실제로 최고 수준의 성능을 자랑하는 Z.ai(Zhipu AI)의 GLM-4.7, GLM-4.6, GLM-4.5 모델 개발에 기반이 된 공식 강화학습 프레임워크입니다. 모델 추론과 학습이라는 두 가지 무거운 시스템을 분리하고(Decoupled), 비동기적으로 처리함으로써 강화학습 시 발생하는 병목 현상을 획기적으로 줄여줍니다.
slime의 아키텍처 개요
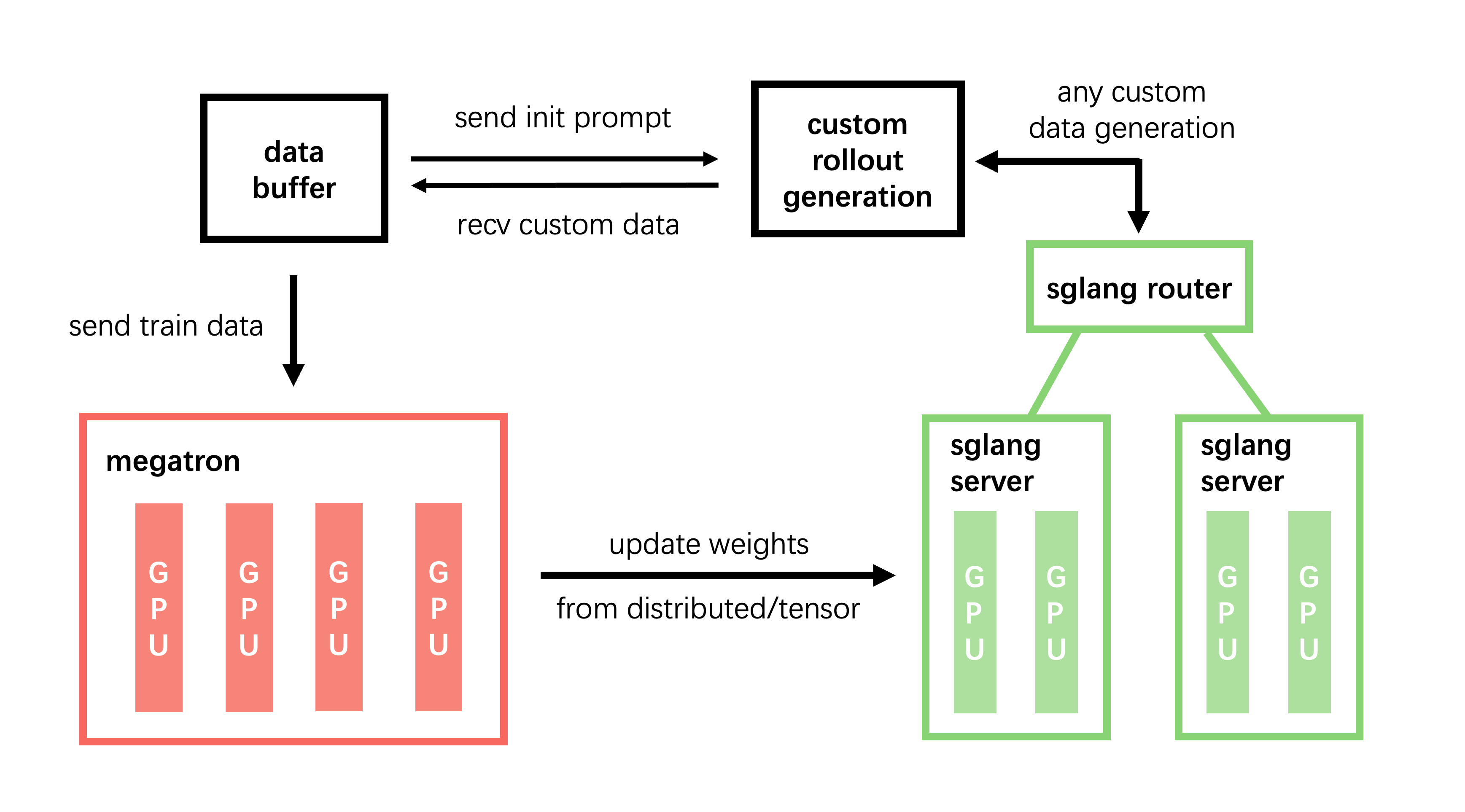
slime의 아키텍처는 강화학습 특유의 '생성(Rollout)'과 '학습(Training)' 단계를 최적화하기 위해 크게 세 가지 모듈로 나뉘어 설계되었습니다:
-
Training 모듈 (Megatron 기반): Training 모듈은 메인 학습 프로세스를 담당합니다. Data Buffer로부터 학습 데이터를 읽어와 모델의 가중치를 업데이트하며, 학습이 완료된 후에는 변경된 파라미터를 Rollout 모듈로 동기화(Synchronization)하여 최신 정책(Policy) 모델이 다음 생성 단계에 반영되도록 합니다.
-
Rollout 모듈 (SGLang + Router 결합): Rollout 모듈은 SGLang의 강력한 추론 처리량을 활용하여 새로운 데이터를 생성합니다. 환경으로부터 얻는 보상(Rewards)이나 검증기(Verifier)의 출력 결과 등 RL 학습에 필요한 궤적(Trajectories)을 생성한 뒤, 이를 Data Buffer에 저장합니다.
-
Data Buffer 모듈: 마지막으로 Data Buffer 모듈은 두 시스템을 잇는 브릿지(Bridge) 역할을 수행합니다. 프롬프트 초기화, 사용자 정의 데이터 관리 및 Rollout 생성 방식 등을 조율하며, 비동기적인 에이전트 기반 강화학습(Agentic RL)이 원활하게 돌아갈 수 있도록 버퍼를 관리합니다.
또한, 사용자 편의성과 호환성을 극대화하기 위해 slime의 실행 인자는 세 가지 범주로 나뉘어 직관적으로 관리됩니다:
- Megatron 인자: Megatron 프레임워크에서 지원하는 모든 설정을 그대로 사용합니다. (예: 텐서 병렬 처리를 위한
--tensor-model-parallel-size 2) - SGLang 인자: 백엔드로 설치된 SGLang의 인자를 지원하며, 기존 옵션 앞에
--sglang-접두사를 붙여 사용합니다. (예: SGLang의 메모리 제한 옵션인--mem-fraction-static은--sglang-mem-fraction-static으로 전달) - slime 전용 인자: 프레임워크 고유의 버퍼링이나 라우팅 세부 설정들은
slime/utils/arguments.py에 정의되어 관리됩니다.
slime이 지원하는 주요 모델 아키텍처
slime은 Z.ai의 모델뿐만 아니라 현재 오픈소스 커뮤니티에서 가장 널리 쓰이는 최신 모델들을 공식적으로 지원하고 있습니다:
-
Zhipu AI (GLM 시리즈): GLM-4.5, GLM-4.6, GLM-4.7 등 (MoE 및 Dense 모델 포함)
-
Qwen 시리즈: 최신 Qwen3 시리즈 (Qwen3Next, Qwen3MoE, Qwen3) 및 Qwen2.5 시리즈
-
DeepSeek 시리즈: DeepSeek V3, V3.1, 그리고 최근 화제가 된 추론 모델인 DeepSeek R1
-
Llama 시리즈: Meta의 Llama 3
slime을 활용한 주요 연구 및 프로젝트
오픈소스 커뮤니티와 학계에서는 이미 slime의 강력한 처리량을 바탕으로 다양한 혁신적인 프로젝트를 진행하고 있습니다. 이 중, slime 프레임워크가 제공하는 강력한 학습 파이프라인을 각자의 목적에 맞춰 극대화한 5가지 프로젝트인 P1, RLVE, TritonForge, APRIL, qqr을 소개합니다.
###P1: 강화학습을 통한 물리 올림피아드 정복
P1은 전적으로 강화학습(RL)을 통해서만 학습된 오픈소스 물리 추론(Physics Reasoning) 모델 제품군입니다. P1 프로젝트는 slime을 RL 사후 학습 프레임워크로 채택하여 복잡한 물리 문제를 해결합니다.
P1 프로젝트에서 가장 눈에 띄는 점은 다단계 RL 훈련 알고리즘(Multi-stage RL training algorithm)을 도입했다는 것입니다. 이 알고리즘은 적응형 학습 가능성 조정(Adaptive learnability adjustment) 및 안정화 메커니즘을 통해 모델의 추론 능력을 점진적으로 향상시킵니다. 이러한 독창적인 훈련 패러다임을 통해 P1은 오픈소스 물리 추론 분야에서 획기적인 성능 향상(Breakthrough performance)을 달성했습니다. 단순히 정답을 맞히는 것을 넘어 물리적 법칙을 바탕으로 논리적으로 사고하는 과정을 강화학습으로 구현해 낸 훌륭한 사례입니다.
RLVE: 적응형 검증 가능 환경을 활용한 LM 강화학습 확장
RLVE는 절차적으로 문제를 생성하고, 알고리즘적으로 검증 가능한 보상(Algorithmically verifiable rewards)을 제공하는 검증 가능한 환경(Verifiable environments)을 사용하여 언어 모델(LM)의 강화학습 스케일을 확장하는 새로운 접근 방식을 제시합니다.
RLVE 시스템은 무려 400개의 검증 가능한 환경 전반에 걸친 공동 훈련(Joint training)을 수행합니다. 가장 핵심적인 특징은 학습이 진행됨에 따라 각 환경이 정책 모델(Policy model)의 현재 능력치에 맞춰 문제의 난이도 분포를 동적으로 적응(Dynamically Adapt)시킨다는 점입니다. 이를 통해 모델이 너무 쉽거나 불가능한 문제에 빠지지 않고, 항상 최적의 난이도에서 효율적으로 학습하여 추론 능력을 극대화할 수 있도록 돕습니다.
TritonForge: 커널 생성을 위한 에이전트 기반 RL 훈련 프레임워크
TritonForge는 slime이 제공하는 지도 미세조정(SFT) 및 강화학습(RL) 기능을 적극 활용하여, 최적화된 GPU 커널을 자동으로 생성하는 대규모 언어 모델을 훈련하는 에이전트 기반 프레임워크입니다.
TritonForge 프로젝트는 '단계 훈련 접근법(Two-stage training approach)'을 사용합니다. 먼저 지도 미세조정(SFT)을 통해 기본적인 코드 작성 능력을 학습시킨 후, 다중 턴 컴파일 피드백(Multi-turn compilation feedback)을 활용한 강화학습을 진행합니다.
즉, 모델이 코드를 작성하면 컴파일러가 이를 테스트하고 피드백을 주며 모델 스스로 코드를 개선하게 만듭니다. 그 결과, 범용적인 PyTorch 연산을 고성능을 자랑하는 Triton 커널 코드로 변환하는 데 있어 놀라운 성과를 거두었습니다.
APRIL: 능동적 부분 생성(Active Partial Rollouts)을 통한 RL 학습 가속화
APRIL은 강화학습 훈련에서 가장 큰 병목 현상을 일으키는 '생성(Rollout)' 단계를 가속화하기 위해 개발된 시스템 수준의 최적화 도구입니다. 이 최적화 기술은 slime 프레임워크와 매끄럽게 통합되어 동작합니다.
강화학습 훈련 시간의 90% 이상은 일반적으로 긴 꼬리(Long-tail) 형태의 데이터 생성 과정에서 소비됩니다. APRIL은 요청을 지능적으로 초과 프로비저닝(Over-provisioning)하고 부분적으로 완료된 생성물(Partial completions)을 능동적으로 관리하는 방식을 통해 이 병목 현상을 근본적으로 해결합니다. 컴퓨팅 리소스의 유휴 시간을 최소화하고 생성 속도를 극대화하여 훈련 효율성을 비약적으로 높인 시스템 엔지니어링의 정수입니다.
qqr: ArenaRL 및 MCP를 활용한 개방형 에이전트 확장
qqr (일명 hilichurl) 은 개방형 에이전트(Open-ended agents)를 진화시키기 위해 설계된 slime용 경량 확장 프로그램입니다. 에이전트들이 다양한 도구 환경에서 훈련될 때 발생하는 문제를 해결하기 위해 도입되었습니다.
qqr 도구는 토너먼트 기반의 상대적 순위 지정(Tournament-based relative ranking, 예: 시드 배정 싱글 엘리미네이션, 라운드 로빈 등)을 통해 식별력 붕괴(Discriminative collapse) 문제를 해결하는 ArenaRL 알고리즘을 구현했습니다.
또한, 최근 주목받고 있는 MCP(Model Context Protocol) 를 완벽하게 통합한 것도 특징적입니다. 결과적으로 slime의 처리량이 높은 훈련 기능을 활용하여, 표준화되고 분리된 도구 환경 속에서 에이전트들을 확장 가능하고 분산된 방식으로 진화시킬 수 있는 강력한 인프라를 제공합니다.
라이선스
slime 프레임워크는 Apache License 2.0으로 공개 및 배포 되고 있습니다.
 slime 프레임워크 공식 문서 사이트
slime 프레임워크 공식 문서 사이트
 slime 프레임워크 GitHub 저장소
slime 프레임워크 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()