
SmolVLA 모델 소개
로봇이 실제 세계에서 사람처럼 유연하게 행동하기 위해서는, 시각적 정보를 이해하고, 자연어 지시를 해석하며, 이를 바탕으로 정확한 동작을 수행할 수 있는 능력이 필요합니다. 최근 인공지능 분야에서는 이러한 요구를 충족시키기 위한 비전-언어-행동(Vision-Language-Action, VLA) 모델이 주목받고 있습니다. 하지만 기존의 대부분 VLA 시스템은 대규모 사설 데이터셋과 고가의 하드웨어에 의존해왔고, 재현성도 떨어지며, 일반 연구자들이 접근하기엔 큰 장벽이 있었습니다.

Hugging Face는 이러한 한계를 극복하기 위해 ‘SmolVLA’라는 450M 규모의 소규모 오픈소스 VLA 모델을 발표했습니다. 이 모델은 일반 소비자 수준의 하드웨어에서도 실행 및 학습이 가능하며, 모두 공개된 커뮤니티 데이터셋만을 사용해 학습하였습니다. 특히, 소형화와 효율성에 초점을 맞춘 구조 덕분에 빠른 추론과 실시간 로봇 제어까지 지원합니다.
SmolVLA는 단순한 연구용 모델을 넘어서 실제 로봇 동작 환경에 바로 적용할 수 있도록 설계되었으며, 학습 코드, 사전 학습 모델, 평가 방식 모두 공개되어 있어 누구나 쉽게 사용할 수 있습니다. 또한, 비공식적으로 조립된 다양한 로봇 하드웨어에서도 동작하도록 설계되어 있어, 로봇 연구의 대중화에 기여할 수 있는 의미 있는 시도입니다.
SmolVLA 모델의 구조 및 주요 특징
SmolVLA는 4.5억여개의 파라미터(450M)로 구성된 소규모 모델로, CPU나 일반 GPU에서도 학습과 실행이 가능하도록 설계되었습니다. Hugging Face의 LeRobot 커뮤니티에서 공유된 오픈소스 로봇 데이터셋만을 이용해 사전 학습되었으며, 학습량은 기존 대형 VLA 모델의 10분의 1 수준에 불과하지만 성능은 동등하거나 더 우수합니다.
모델 아키텍처는 크게 두 부분으로 구성되어 있습니다. 첫째는 시각-언어-센서 데이터를 처리하는 Vision-Language Model(VLM), 둘째는 이 정보를 바탕으로 로봇 동작을 생성하는 Action Expert입니다. 특히 Action Expert는 Flow Matching Transformer 구조를 통해 연속적이고 비자기회귀적(non-autoregressive) 동작을 예측함으로써 빠르고 안정적인 제어를 실현합니다.
효율성과 성능을 위한 설계
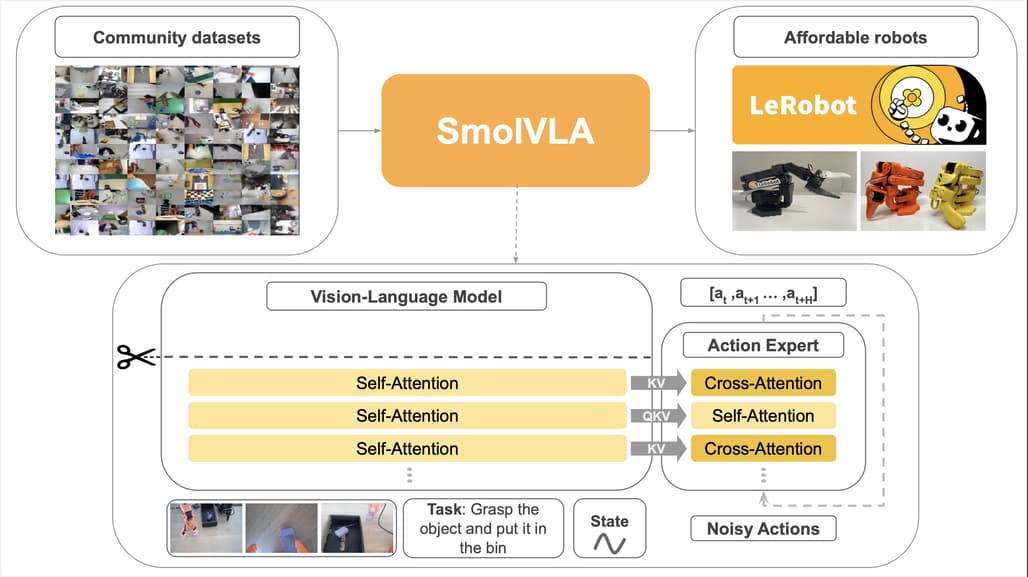
SmolVLA는 경량화를 위해 세 가지 기술적 설계를 채택했습니다. 첫째, 각 이미지 프레임을 최대 64개의 시각 토큰으로 압축하여 추론 속도를 향상시켰습니다. 둘째, 비전 모델의 상위 절반 계층은 건너뛰는 방식을 통해 추론 비용을 절감했습니다. 셋째, 행동 전문가에서는 자기-어텐션과 교차-어텐션 계층을 교차적으로 배치하여, 인식 기반 정밀성과 시간적 부드러움을 동시에 확보했습니다.
비동기 추론(Asynchronous Inference)
SmolVLA의 가장 큰 장점 중 하나는 비동기 추론을 기본 지원한다는 점입니다. 기존의 동기 방식은 하나의 동작이 끝난 후 다음 동작을 계산하므로 반응 속도가 늦습니다. 반면 비동기 방식은 현재 동작이 실행되는 동안 다음 동작을 동시에 계산하여, 반응 속도와 연속성이 크게 향상됩니다. 이로 인해 실제 환경에서의 작업 성공률이 약 30% 빨라지고, 같은 시간 안에 두 배 이상의 작업을 수행할 수 있습니다.
커뮤니티 데이터셋의 활용

SmolVLA는 기존처럼 대형 사설 데이터셋에 의존하지 않고, Hugging Face 커뮤니티에서 공유된 공개 로봇 데이터셋만으로 학습되었습니다. 데이터는 다양한 환경, 카메라 시점, 동작 유형을 포함하고 있으며, 실제 사용 환경을 잘 반영한 것이 특징입니다. 텍스트 지시문과 카메라 명칭의 표준화 작업도 병행하여 학습 품질을 향상시켰습니다. 커뮤니티 데이터셋은 다소 적은 양(1천만 프레임)이지만, 다양성 측면에서는 훨씬 뛰어난 특성을 지니고 있습니다.
실험 결과
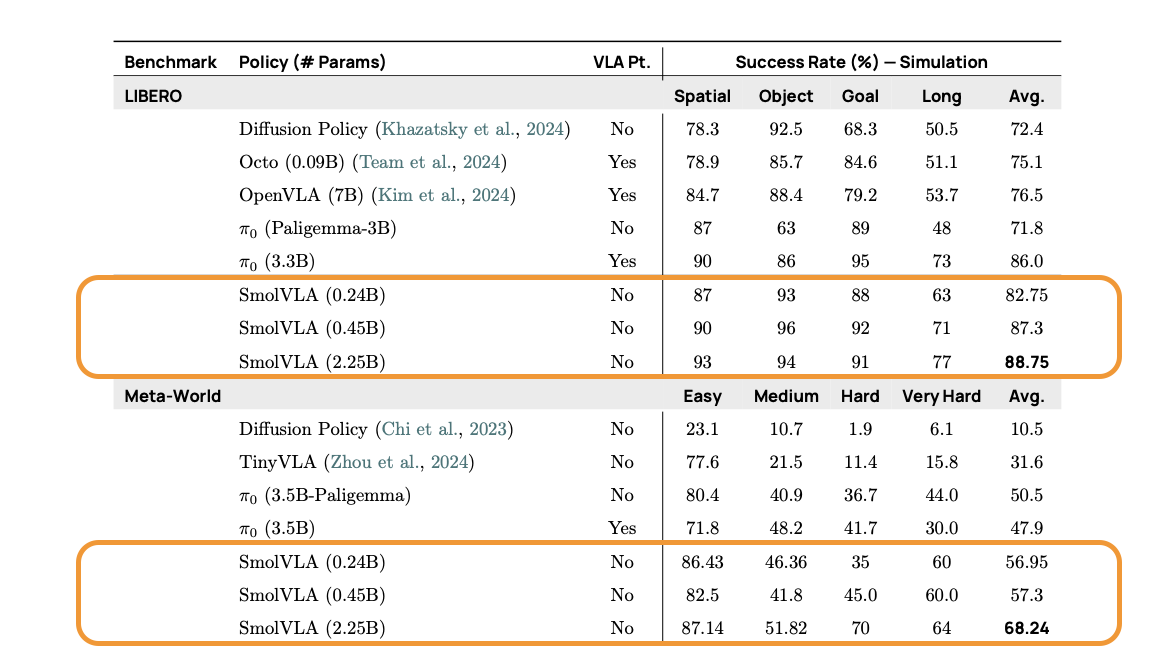
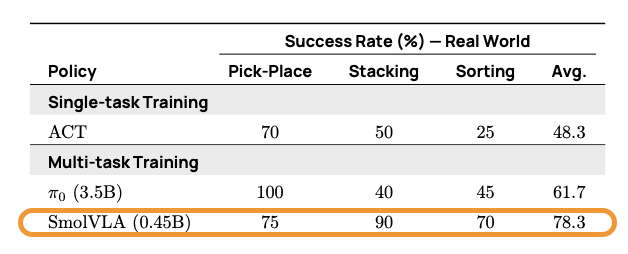
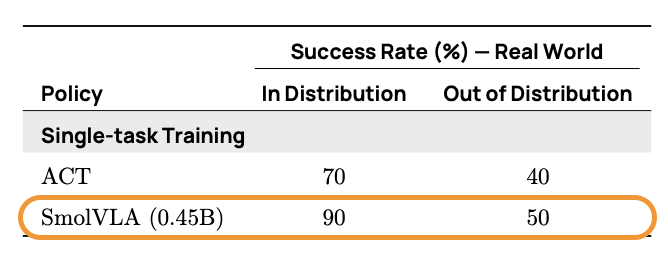
SmolVLA는 시뮬레이션(LIBERO, Meta-World)과 실제 로봇 환경(SO100, SO101) 모두에서 기존 대형 모델(ACT 등)을 능가하거나 유사한 성능을 보였습니다. 특히 저용량 데이터 학습 환경이나 빠른 반응이 필요한 실제 환경에서는 뛰어난 일반화 성능을 나타냈습니다. 비동기(Async) 추론 환경에서는 평균 작업 시간이 약 30% 단축되고, 정해진 시간 안에 수행 가능한 작업 수가 두 배로 증가하는 효과도 확인되었습니다.
 SmolVLA 소개 블로그
SmolVLA 소개 블로그
 SmolVLA Base 모델
SmolVLA Base 모델
SmolVLA 논문: A Vision-Language-Action Model for Affordable and Efficient Robotics
 SO-100/101 학습 및 평가를 위한 하드웨어
SO-100/101 학습 및 평가를 위한 하드웨어

더 읽어보기
-
SmolLM v2, On-Device에 최적화된 소규모 언어 모델(SLM) (feat. HuggingFace)
-
Open Computer Agent: Hugging Face의 새로운 AI 에이전트 프로젝트 (feat. smolagent)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()