Supermemory 소개
Supermemory는 대화가 끝날 때마다 맥락이 사라지는 문제를 풀기 위해, 대화에서 사실을 추출해 영속적으로 저장하는 AI 메모리 및 컨텍스트 엔진입니다. 대부분의 LLM 기반 도구는 한 세션이 끝나면 사용자가 누구인지, 무엇을 작업하고 있었는지를 잊어버립니다. supermemory는 이 망각을 별도의 메모리 계층으로 보완해, 대화에서 중요한 사실을 자동으로 뽑아내고 사용자 프로필을 구축하며, 시간이 지나며 바뀌거나 서로 모순되는 정보를 갱신하고, 기한이 지난 정보는 자동으로 잊는 방식으로 동작합니다.
Supermemory 개발팀은 자신들을 메모리 엔진과 그 주변의 플러그인 및도구를 만드는 리서치 랩으로 소개합니다. 이들이 강조하는 핵심 구분은 "Memory is not RAG" 입니다. 일반적인 RAG(검색 증강 생성)는 문서 조각을 검색해 돌려주는 무상태(stateless) 방식이라 누구에게나 같은 결과를 줍니다. 반면 메모리는 사용자에 관한 사실을 시간 축 위에서 추출하고 추적합니다. 예를 들어 "방금 샌프란시스코로 이사했다" 라는 문장이 "뉴욕에 산다" 라는 이전 정보를 대체한다는 것을 이해합니다. supermemory는 두 방식을 한 쿼리에서 함께 돌려, 지식 베이스 검색과 개인화된 컨텍스트를 동시에 제공합니다.

기능적으로 supermemory는 메모리 추출, 사용자 프로필, 하이브리드 검색, 외부 데이터 커넥터, 멀티모달 파일 처리를 하나의 API로 묶은 컨텍스트 스택입니다. 벡터 DB 설정이나 임베딩 파이프라인, 청킹 전략을 직접 구성하지 않아도 되도록 이 과정을 내부에서 처리하는 것이 설계의 출발점입니다. 호스팅 플랫폼뿐 아니라 단일 바이너리로 로컬에서 완전히 오프라인 실행하는 경로도 함께 제공합니다.
Supermemory의 동작 방식
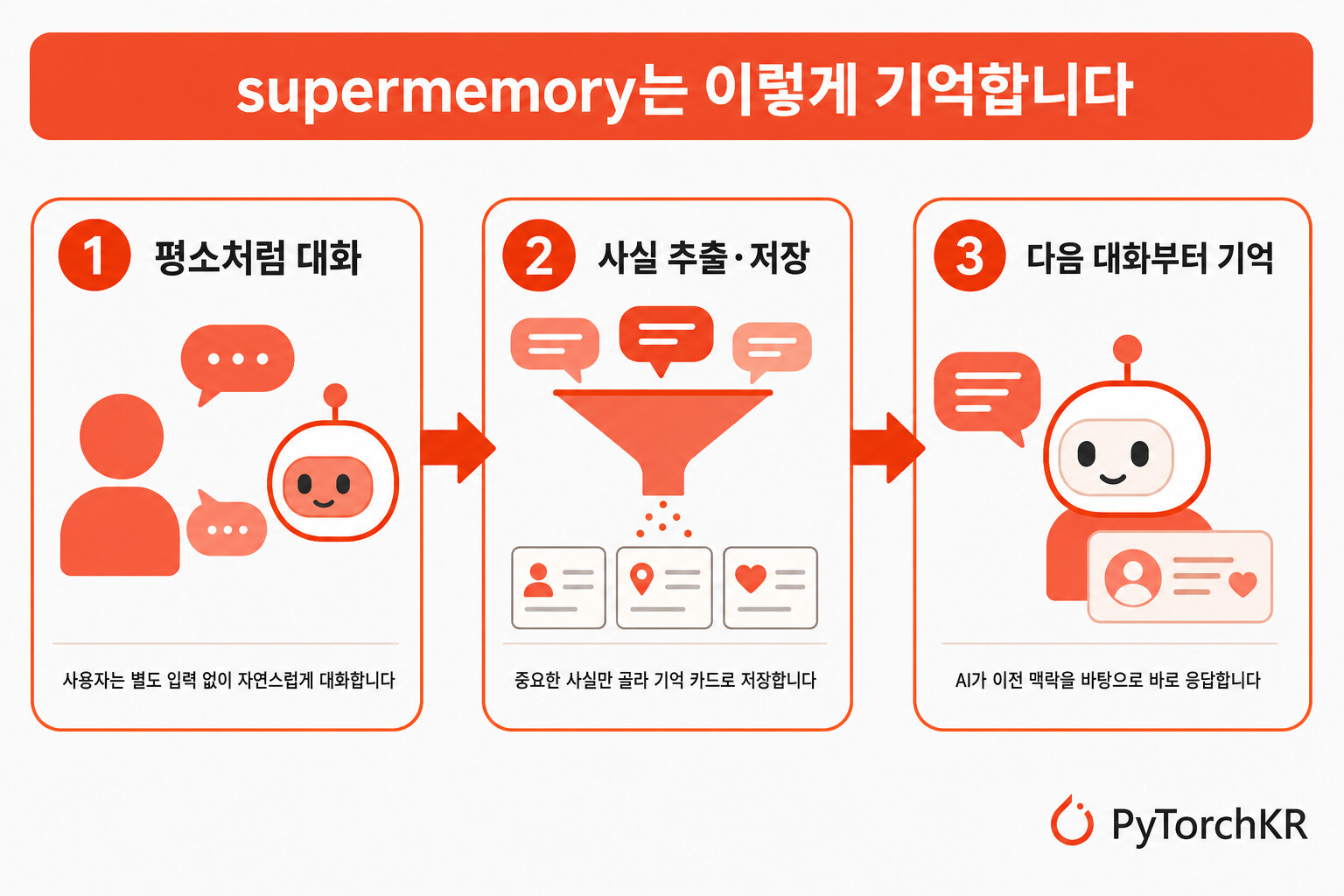
설치한 뒤 supermemory는 백그라운드에서 다음 세 단계로 동작합니다. 먼저 사용자가 평소처럼 AI와 대화하며 선호나 진행 중인 프로젝트, 겪고 있는 문제를 자연스럽게 언급합니다. 그러면 supermemory가 그중 의미 있는 사실·선호·프로젝트 맥락만 추려 저장하고, 단순한 잡음은 영구 기억으로 만들지 않습니다. 다음 대화부터는 AI가 사용자가 무엇을 작업 중인지, 어떤 방식을 선호하는지, 이전에 무엇을 논의했는지를 이미 알고 있는 상태로 시작합니다.
기억은 프로젝트(project) 라는 컨테이너 태그로 구분됩니다. 덕분에 업무용과 개인용 맥락을 분리하거나, 클라이언트·저장소 단위로 기억을 나눠 관리할 수 있습니다. 기한이 있는 임시 사실(예: "내일 시험이 있다")은 날짜가 지나면 만료되고, 모순되는 정보는 자동으로 정리됩니다.
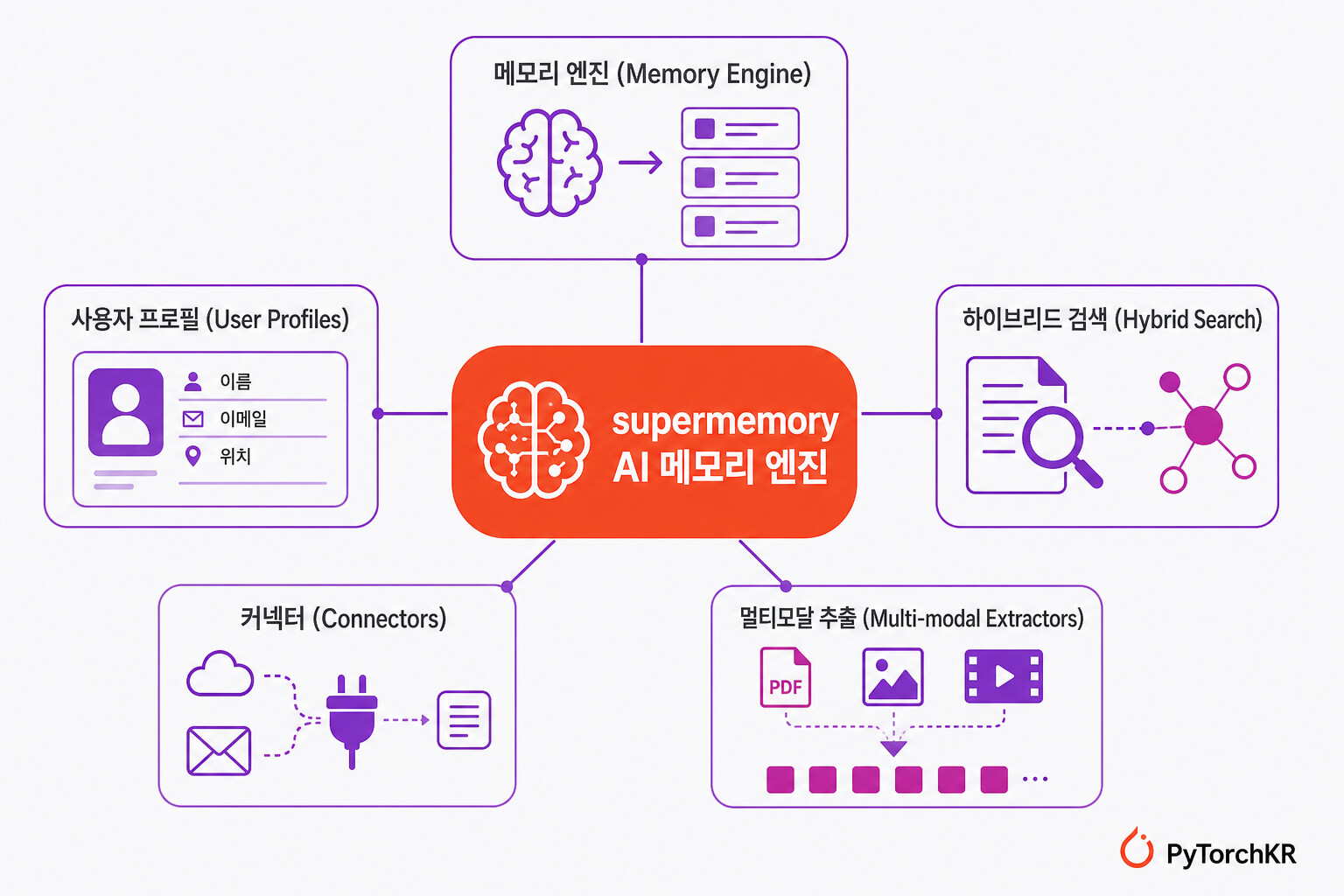
Supermemory가 묶어주는 다섯 가지 컨텍스트 스택
Supermemory는 AI 에이전트나 앱을 만들 때 필요한 컨텍스트 관련 기능을 하나의 API로 제공합니다. 핵심 구성요소는 다음과 같습니다.
- 메모리 엔진(Memory Engine): 대화에서 사실을 추출하고, 시간에 따른 변화와 모순을 처리하며, 만료된 정보를 자동으로 잊습니다.
- 사용자 프로필(User Profiles): 안정적인 장기 사실과 최근 활동을 합쳐 사용자별 컨텍스트를 자동으로 유지합니다. 한 번의 호출로 정적 프로필과 동적 프로필을 함께 받습니다.
- 하이브리드 검색(Hybrid Search): RAG와 메모리를 한 쿼리에서 함께 검색해, 지식 베이스 문서와 개인화된 맥락을 동시에 반환합니다.
- 커넥터(Connectors): Google Drive, Gmail, Notion, OneDrive, GitHub, 웹 크롤러 등 외부 데이터를 실시간 웹훅으로 동기화합니다.
- 멀티모달 추출기(Multi-modal Extractors): PDF, 이미지(OCR), 영상(전사), 코드(AST 기반 청킹)를 업로드하면 검색 가능한 청크로 처리합니다.
사용자 프로필은 "무엇을 물어봐야 할지 알아야 검색되는" 기존 메모리 방식과 달리, 모든 사용자에 대해 프로필을 자동으로 유지한다는 점이 차이입니다. 정적 프로필(profile.static)에는 "Acme의 시니어 엔지니어", "다크 모드 선호", "Vim 사용" 같은 장기 사실이, 동적 프로필(profile.dynamic)에는 "인증 마이그레이션 작업 중" 같은 최근 맥락이 담깁니다. 한 번의 호출로 두 프로필을 약 50ms 안에 받아 시스템 프롬프트에 주입하면, 에이전트가 상대가 누구인지를 즉시 인지한 상태로 시작합니다.
코드 없이 Supermemory를 앱으로 바로 쓰기
직접 개발하지 않아도 됩니다. supermemory는 코드 없이 무료로 쓸 수 있는 소비자용 앱을 함께 제공해, 대화마다 영속적인 메모리 그래프를 쌓아 줍니다. 앱(https://app.supermemory.ai)에는 노바(Nova) 라고 부르는 에이전트가 내장되어 있어 메모리를 직접 검색하거나 정리할 수 있고, 브라우저 확장 프로그램으로 평소 쓰는 웹 도구에서 바로 기억을 남길 수도 있습니다. 개발자라면 아래의 SDK·로컬 실행·MCP 경로를 그대로 이어서 보면 됩니다.
Supermemory API로 개발하기
supermemory는 npm과 PyPI로 SDK를 제공합니다.
npm install supermemory # 또는: pip install supermemory
저장과 프로필 조회는 다음과 같이 한 번의 호출로 처리합니다.
import Supermemory from "supermemory";
const client = new Supermemory();
// 대화 내용을 저장
await client.add({
content: "User loves TypeScript and prefers functional patterns",
containerTag: "user_123",
});
// 사용자 프로필 + 관련 메모리를 한 번의 호출로 조회
const { profile, searchResults } = await client.profile({
containerTag: "user_123",
q: "What programming style does the user prefer?",
});
// profile.static → ["Loves TypeScript", "Prefers functional patterns"]
// profile.dynamic → ["Working on API integration"]
// searchResults → 유사도 순으로 정렬된 관련 메모리
검색은 기본값인 하이브리드 모드(searchMode: "hybrid")에서 RAG와 메모리를 한 쿼리로 함께 조회하고, searchMode: "memories" 로 메모리만 조회할 수도 있습니다. Vercel AI SDK, LangChain, LangGraph, OpenAI Agents SDK, Mastra, Agno, Claude Memory Tool, n8n 등 주요 AI 프레임워크용 래퍼도 함께 제공해, 기존 모델 호출을 withSupermemory 로 감싸 메모리를 붙이는 방식도 지원합니다.
Supermemory 플러그인(Plugin)
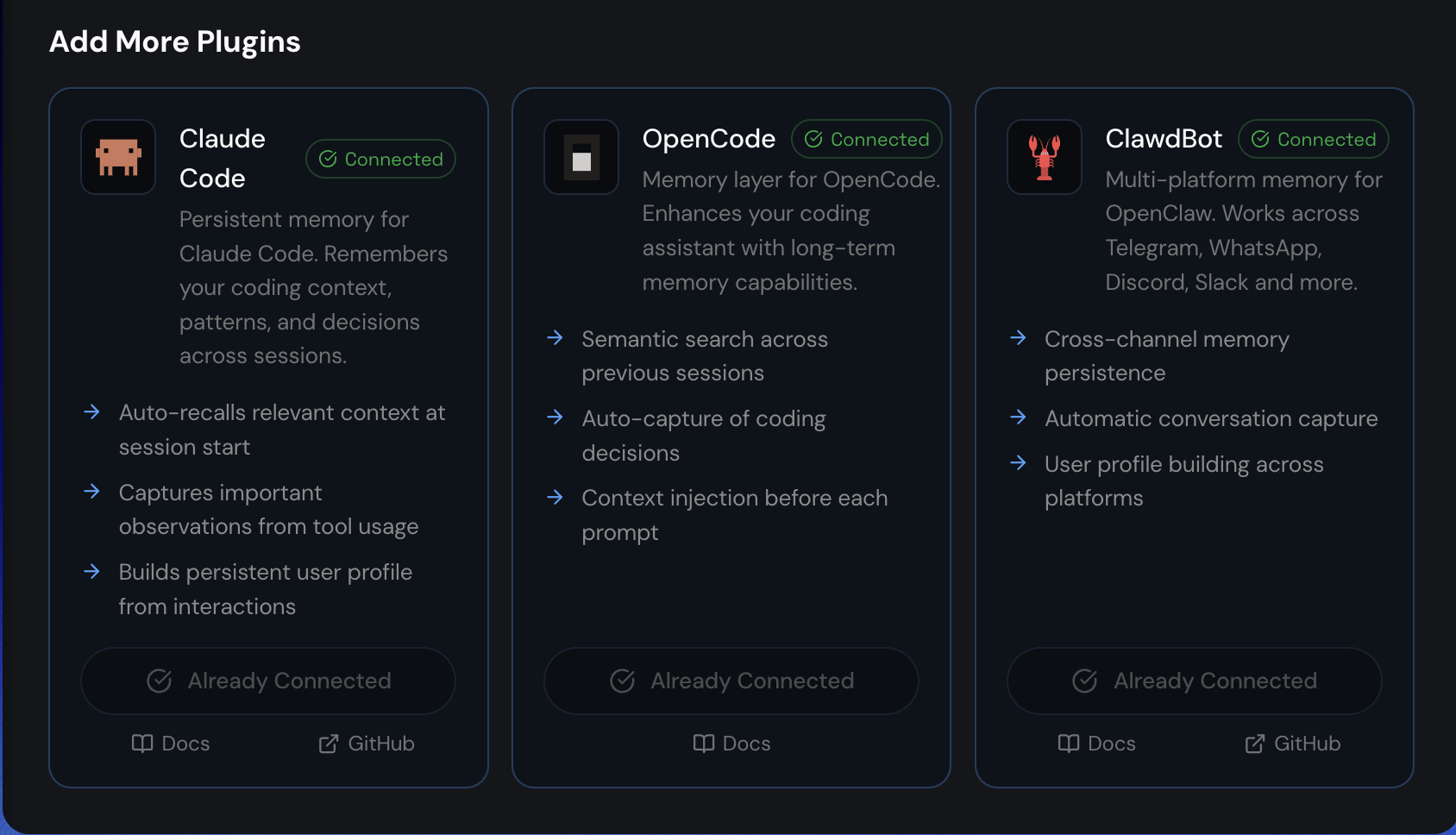
Claude Code, OpenCode, OpenClaw, Hermes에서 Supermemory를 플러그인으로 사용할 수도 있습니다. 각 플러그인은 supermemory API를 기반으로 구현되었으며, 아래 저장소에서 각 오픈소스들을 확인 및 사용하실 수 있습니다:
- Openclaw plugin: GitHub - supermemoryai/openclaw-supermemory: OpenClaw Supermemory lets to have long-term memory and recall for your openclaw agent. · GitHub
- Claude code plugin: GitHub - supermemoryai/claude-supermemory: Enable Claude Code to learn in real-time, update it's knowledge, and grow with you, using supermemory. · GitHub
- OpenCode plugin: GitHub - supermemoryai/opencode-supermemory: Supermemory plugin for OpenCode · GitHub
- Hermes agent (Supermemory memory provider): GitHub - NousResearch/hermes-agent: The agent that grows with you · GitHub
Supermemory를 직접 실행하기
호스팅 플랫폼을 쓰지 않고 자신의 머신에서 직접 실행할 수도 있습니다. 단일 바이너리로 설치하고 별도 설정 없이 서버를 띄웁니다.
curl -fsSL https://supermemory.ai/install | bash
# 또는
npx supermemory local
supermemory-server
첫 실행 시 내장된 supermemory 그래프 엔진과 로컬 임베딩, 자격 증명을 설정하고 API 키를 출력합니다. 이후 문서·메모리·사용자 프로필·하이브리드 검색을 포함한 Memory API 전체가 http://localhost:6767 에서 동작하며, SDK에서는 baseURL 한 줄만 바꾸면 됩니다. OpenAI, Anthropic, Gemini, Groq 등 OpenAI 호환 엔드포인트라면 어떤 모델이든 연결할 수 있고, Ollama(gpt-oss:20b)를 가리키면 데이터가 머신 밖으로 나가지 않는 완전 오프라인 모드로 쓸 수 있습니다. 모든 데이터는 ./.supermemory 디렉토리 한 곳에 보관됩니다.
Supermemory의 벤치마크 성적
supermemory는 AI 메모리 분야의 세 가지 주요 벤치마크에서 최상위 성적을 보고하고 있습니다. 아래 수치는 프로젝트가 README에 공개한 결과입니다.
| 벤치마크 | 측정 항목 | 결과 |
|---|---|---|
| LongMemEval | 지식 갱신을 포함한 세션 간 장기 기억 | 81.6% — 1위 |
| LoCoMo | 긴 대화에서의 사실 회상(단일·다중 홉, 시간, 적대적) | 1위 |
| ConvoMem | 개인화 및 선호 학습 | 1위 |
또한 메모리 제공자를 표준화된 방식으로 비교하기 위한 오픈소스 프레임워크 MemoryBench도 함께 공개했습니다. supermemory, Mem0, Zep 등을 같은 조건에서 비교할 수 있도록 만든 도구로, README의 벤치마크 섹션에서 실행 명령과 사용법을 확인할 수 있습니다.
Supermemory를 AI 클라이언트에 붙이기 (MCP)
supermemory는 MCP(Model Context Protocol) 서버를 함께 제공해, 호환되는 AI 어시스턴트에 영속 메모리를 붙일 수 있습니다.
npx -y install-mcp@latest https://mcp.supermemory.ai/mcp --client claude --oauth=yes
claude 자리에 cursor, windsurf, vscode 등 사용하는 클라이언트를 넣으면 됩니다. 이때 AI는 정보를 저장·삭제하는 memory, 쿼리로 메모리를 검색하는 recall, 대화 시작 시 전체 프로필을 주입하는 context 도구를 사용하게 됩니다. supermemory는 Claude Code, OpenCode, OpenClaw, Hermes용 플러그인도 오픈소스로 공개하고 있으며, 예를 들어 Claude Code용 supermemory 플러그인을 통해 구현을 확인할 수 있습니다.
라이선스
supermemory는 MIT 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용할 수 있습니다.
 Supermemory 공식 홈페이지
Supermemory 공식 홈페이지
 Supermemory 문서 사이트
Supermemory 문서 사이트
 Supermemory 프로젝트 GitHub 저장소
Supermemory 프로젝트 GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()