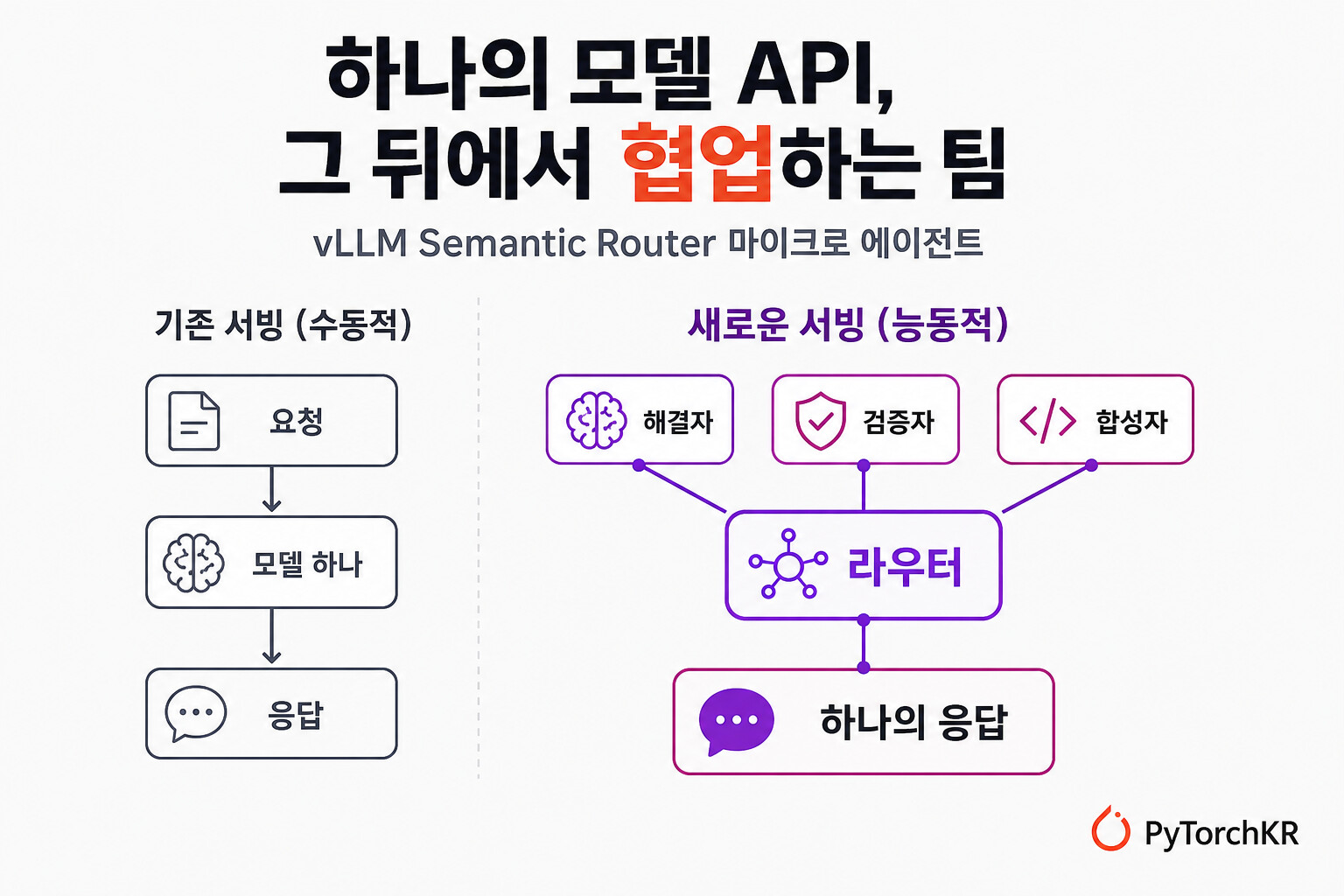
vLLM Semantic Router의 마이크로 에이전트 소개
지금 업계의 시선은 대부분 "다음 프론티어 모델은 무엇인가"에 쏠려 있습니다. 그러나 vLLM 팀이 공개한 이번 글은 더 흥미로운 층위가 모델 앞단에 있다고 말합니다. 바로 라우터(router) 입니다. 원문은 라우터가 점점 *AI 추론(inference)의 제어 평면(control plane)*이 되어가고 있다고 진단합니다. 라우터의 첫 임무는 실용적인 것이었습니다. 들어온 요청을 적절한 모델로 보내는 일이죠. 프로덕션 AI가 더 이상 한 개 모델로 돌아가는 세상이 아니기 때문에, 이 역할만으로도 의미가 큽니다. 라우터는 프론티어 모델이 필요한 요청과 오픈소스나 로컬 모델로 충분한 요청을 구분해 비용을 줄이고, 민감한 도메인을 더 엄격한 모델이나 필터로 보내 안전 정책을 실행 가능하게 만들며, 사적이거나 지연(latency)에 민감한 의도는 로컬에 두고 어려운 작업만 클라우드로 올려 보내는 식으로 클라우드와 엣지를 조율합니다.
이 글이 던지는 핵심 주장은 라우터의 다음 임무가 훨씬 더 흥미롭다는 것입니다. "라우터가 모델 자체를 더 좋게 만들 수 있다" 는 것이죠. 가중치를 바꾸지 않고, 모든 애플리케이션이 맞춤형 에이전트 그래프를 새로 만들게 하지 않고서 말입니다. 방법은 하나의 모델 API 호출을 서빙 계층 내부의 경계가 정해진 협업(bounded collaboration)으로 바꾸는 것입니다. 사용자는 여전히 모델 하나를 호출하지만, 그 안정적인 모델 정체성 뒤에서 라우터가 레시피를 고르고, 여러 워커에 팬아웃(fan-out)하고, 정족수(quorum)를 모으고, 불일치를 검증하고, 최종 답을 합성(synthesis)한 뒤, 출력 계약을 복구해 하나의 평범한 OpenAI 호환 응답을 돌려줍니다.
이 발상은 새로 등장한 것은 아닙니다. Sakana AI의 Fugu가 큰 반향을 일으킨 이유도 "모델은 하나의 표면(surface)이고, 그 표면 뒤에는 팀이 있을 수 있다" 는 단순하지만 강력한 아이디어를 상업 제품으로 만들었기 때문입니다. 그러나 vLLM Semantic Router의 비전은 추상화의 위치가 다릅니다. 협업이 하나의 상업용 엔드포인트나 애플리케이션 전용 에이전트 그래프 안에만 머물러서는 안 되며, 열린 서빙 기본 요소(open serving primitive) 가 되어야 한다는 것입니다. vLLM Semantic Router 프로젝트 자체에 관심이 있다면, 커뮤니티에 이미 정리된 vLLM Semantic Router 아키텍처 소개 글을 함께 참고하시면 전체 그림을 잡기 좋습니다. 이 글은 그 아키텍처 위에서 "라우터가 어떻게 능력을 구성하는가" 라는 한 단계 더 들어간 이야기를 다룹니다.
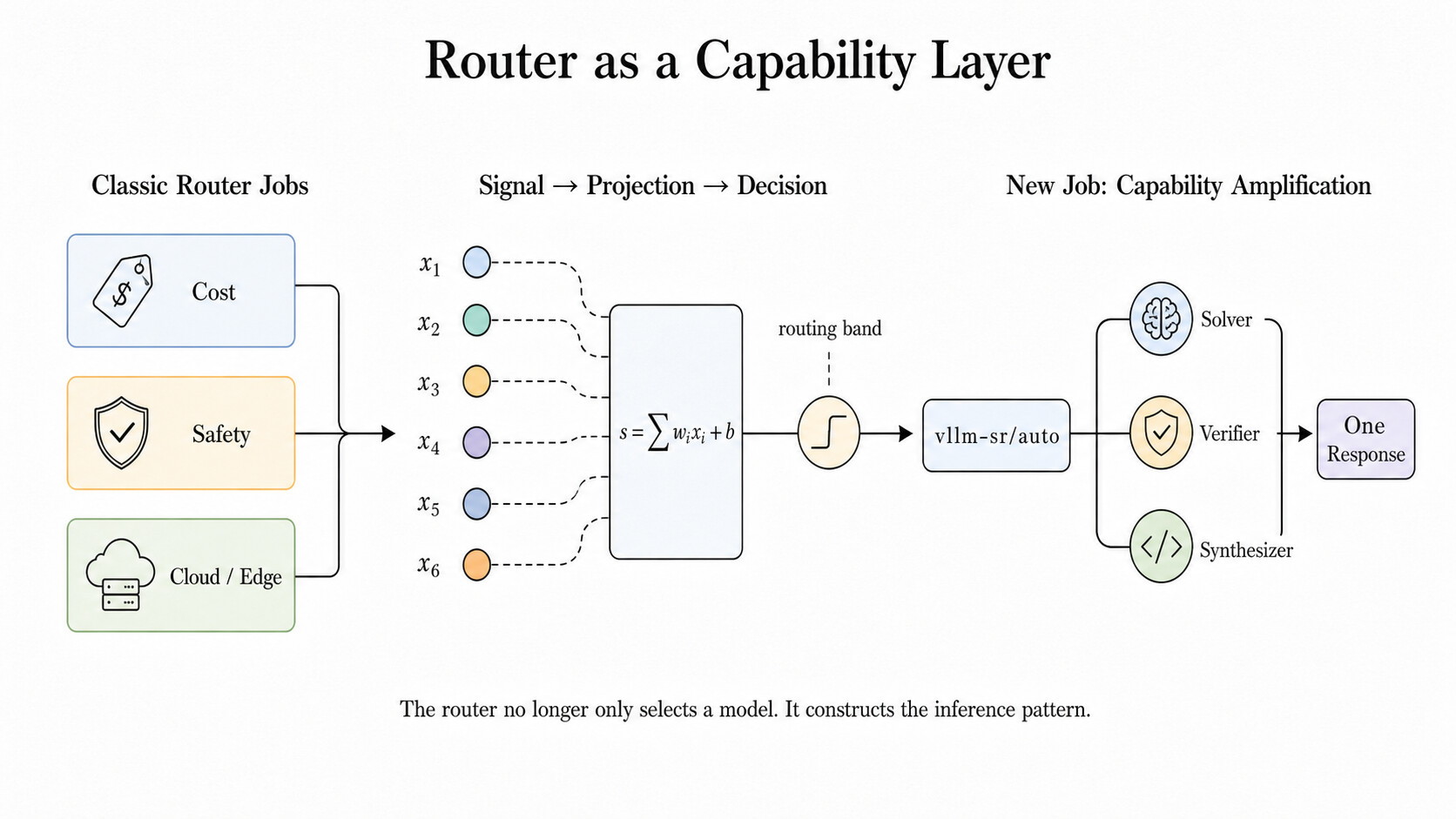
라우터가 모델 선택에서 능력 구성으로 진화하다
전통적인 라우터의 일은 비용, 안전, 클라우드/엣지 같은 운영 신호를 보고 "어느 모델로 보낼지"를 정하는 것이었습니다. vLLM Semantic Router는 여기에 한 층을 더 얹습니다. 요청에서 신호(signal)를 추출해 과제 형태(task-shape)나 위험 대역(risk band)으로 투영(projection)하고, 결정 규칙에 매칭한 뒤, 알고리즘을 고릅니다. 위 그림이 보여주듯 라우터는 여러 입력 신호 x_1, x_2, \dots, x_6 를 가중합 s = \sum_i w_i x_i + b 형태로 점수화하고, 이 점수를 라우팅 대역으로 변환합니다. 그렇게 선택된 알고리즘은 평범한 단일 모델 경로일 수도 있고, 여러 모델을 협업시키는 경로일 수도 있습니다. 원문 그림 하단의 표현을 빌리면, 라우터는 더 이상 모델을 고르기만 하는 것이 아니라 추론 패턴 자체를 구성합니다.
핵심은 복잡성을 노출하는 것이 아니라, 협업을 하나의 모델처럼 느껴지게 하는 것입니다. 사용자가 보내는 요청은 다음처럼 모델 이름 하나만 가리킵니다.
{
"model": "vllm-sr/auto",
"messages": [{"role": "user", "content": "..."}]
}
이 안정적인 모델 이름 뒤에서 라우터는 레시피를 선택하고, 워커에 팬아웃하고, 정족수를 모으고, 불일치를 검증하고, 최종 답을 합성하고, 출력 계약을 복구한 다음, 하나의 정상적인 OpenAI 호환 응답을 반환합니다. 위 그림의 오른쪽이 바로 이 "능력 증폭(capability amplification)" 단계로, vllm-sr/auto 라는 하나의 표면 뒤에서 해결자(Solver), 검증자(Verifier), 합성자(Synthesizer)가 협력해 단 하나의 응답(One Response)을 만들어냅니다.
오케스트레이션 흐름 더 알아보기
이 흐름을 이해하는 데 도움이 되는 연구 자료들을 모았습니다. Discourse에서 아래 링크는 자동으로 미리보기 카드로 렌더링됩니다.
Fugu Technical Report - Sakana AI가 제시한 "모델 = 표면, 뒤에는 팀" 아이디어의 기술 보고서
Conductor - 모델 협업 조율(coordination)을 다루는 논문
Trinity - 다중 모델 조율을 다루는 논문
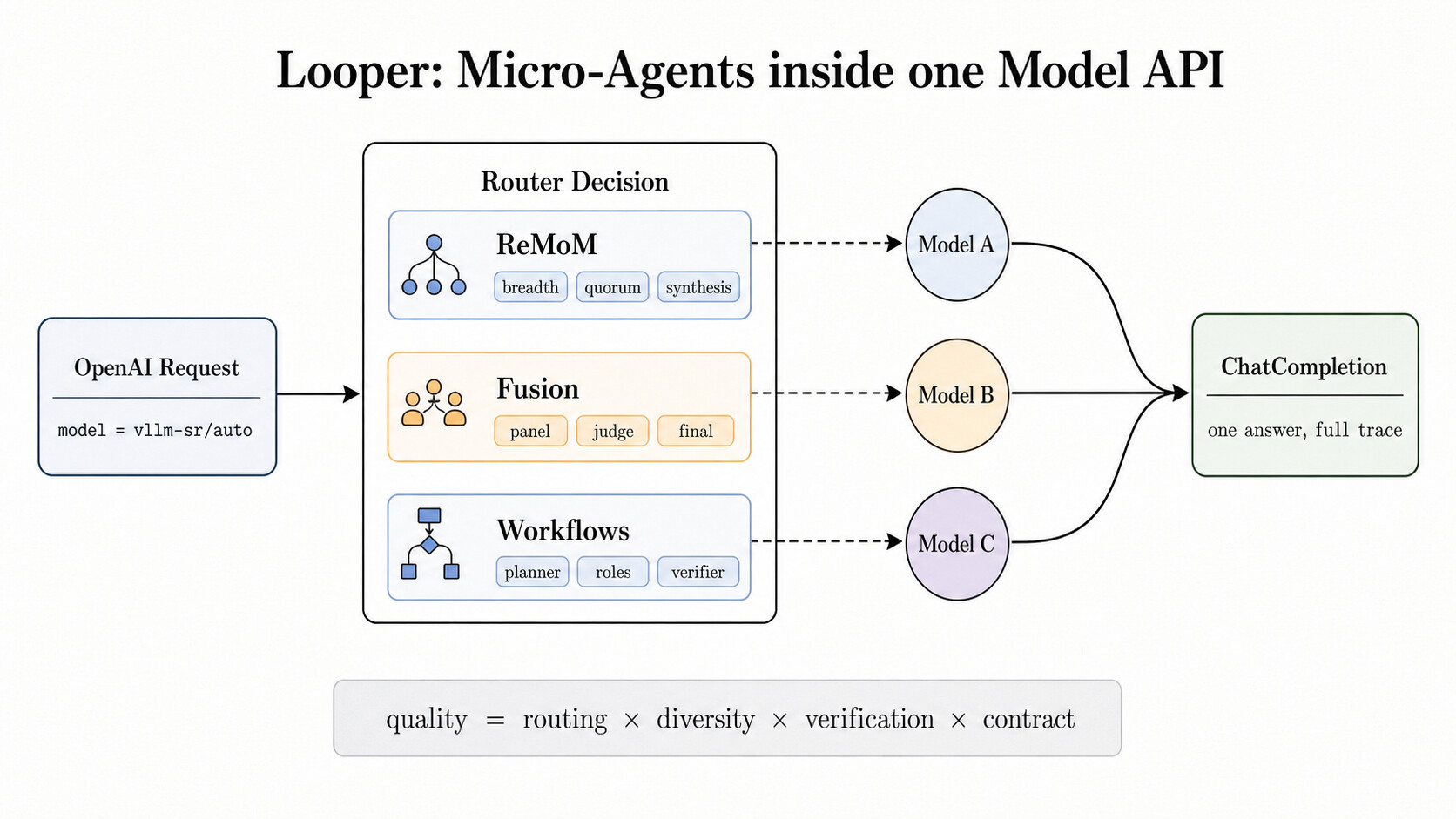
루퍼(Looper)는 마이크로 에이전트의 실행 런타임이다
vLLM Semantic Router에서 루퍼(Looper) 는 경계가 정해진 마이크로 에이전트(bounded micro-agent)를 실행하는 런타임입니다. 여기서 중요한 점은 루퍼가 "모델을 더 많이 호출하자" 는 구호가 아니라는 것입니다. 루퍼는 예산(budget), 토폴로지(topology), 추적(trace), 실패 정책(failure policy) 을 갖춘 작은 런타임입니다. 평범한 채팅 완성 요청이 라우터로 들어오면, 라우터는 신호를 추출하고 과제 형태나 위험 대역으로 투영한 뒤 결정을 매칭하고, 그에 맞는 알고리즘을 고릅니다.
아래 그림은 하나의 OpenAI 요청(model = vllm-sr/auto)이 라우터 결정 안에서 여러 루퍼 패턴(ReMoM, Fusion, Workflows)으로 분기되고, 여러 모델(Model A, B, C)을 거쳐 다시 하나의 ChatCompletion(one answer, full trace)으로 합쳐지는 모습을 보여줍니다. 그림 하단의 등식 quality = routing \times diversity \times verification \times contract 는 루퍼가 추구하는 품질이 라우팅, 다양성, 검증, 계약의 곱으로 결정된다는 점을 압축합니다.
현재 주요 루퍼 패턴은 다섯 가지입니다. 각각은 서로 다른 토폴로지와 정지 조건을 갖습니다.
| 패턴 | 토폴로지 | 핵심 메커니즘 | 적합한 과제 |
|---|---|---|---|
| Confidence | 순차 에스컬레이션 | 신뢰도 점수로 정지 또는 승급 | 비용 민감, 쉬운 요청이 다수일 때 |
| Ratings | 병렬 (동시성 상한) | 평점 가중 집계 | 앙상블, A/B 스타일 평가 |
| ReMoM | 넓이 우선 팬아웃 + 합성 | 정족수 충족 후 최종 합성 | 추론 분산이 큰 과제 |
| Fusion | 패널 → 심판 → 최종화 | 불일치를 증거로 활용 | 경쟁하는 경로가 있는 과제 |
| Workflows | 계획자 → 작업자 → 검증자 | 예산과 역할 경계 강제 | SWE형 다단계 과제 |
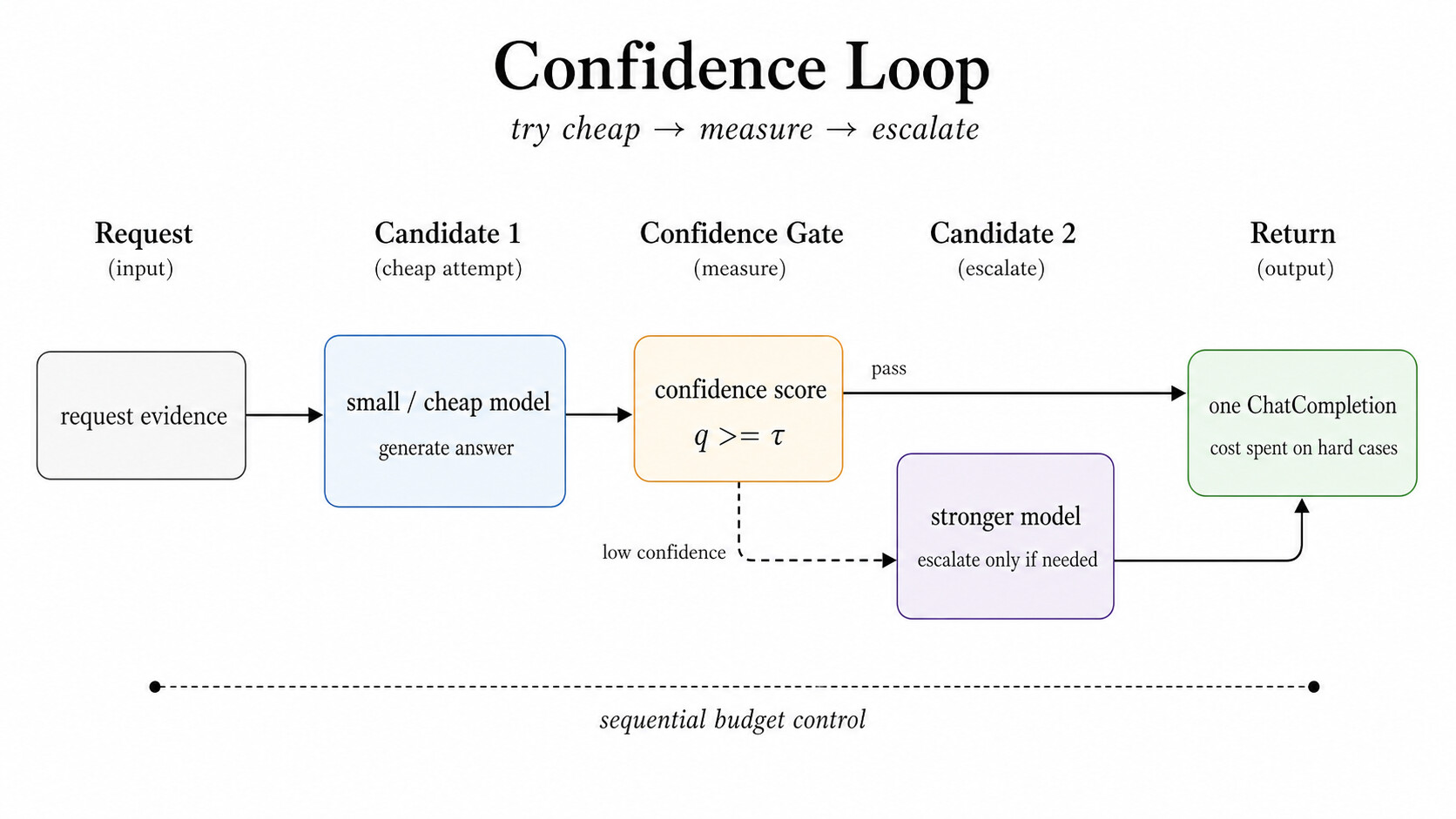
Confidence: 어려운 요청에만 비용을 쓰는 순차 에스컬레이션
Confidence 는 비용을 의식하는 루프입니다. 더 작거나 저렴한 후보로 먼저 시작한 뒤, 답이 멈춰도 될 만큼 충분히 자신 있는지를 평가합니다. 신뢰도 신호는 토큰 단위 로그 확률(log probability), 로그 확률 마진, 하이브리드 점수, 자기 검증(self-verification), 또는 AutoMix 스타일의 함의(entailment) 검증기에서 나올 수 있습니다.
점수가 임계값을 넘으면 라우터는 즉시 답을 반환합니다. 점수가 너무 낮으면 다음 후보로 에스컬레이션합니다. 아래 그림이 보여주듯, 저렴한 모델이 답을 생성하고 신뢰도 게이트 q \geq \tau 를 통과하면 그대로 반환(pass)하고, 신뢰도가 낮으면(low confidence) 더 강한 모델로 승급해 어려운 경우에만 비용을 쓰는(cost spent on hard cases) 구조를 만듭니다. 중요한 것은 에스컬레이션이 존재한다는 사실이 아니라, 에스컬레이션이 명시적인 라우터 정책이 된다는 점입니다. 임계값, 실패 동작, 정지 조건이 모두 눈에 보이고 조정 가능해집니다.
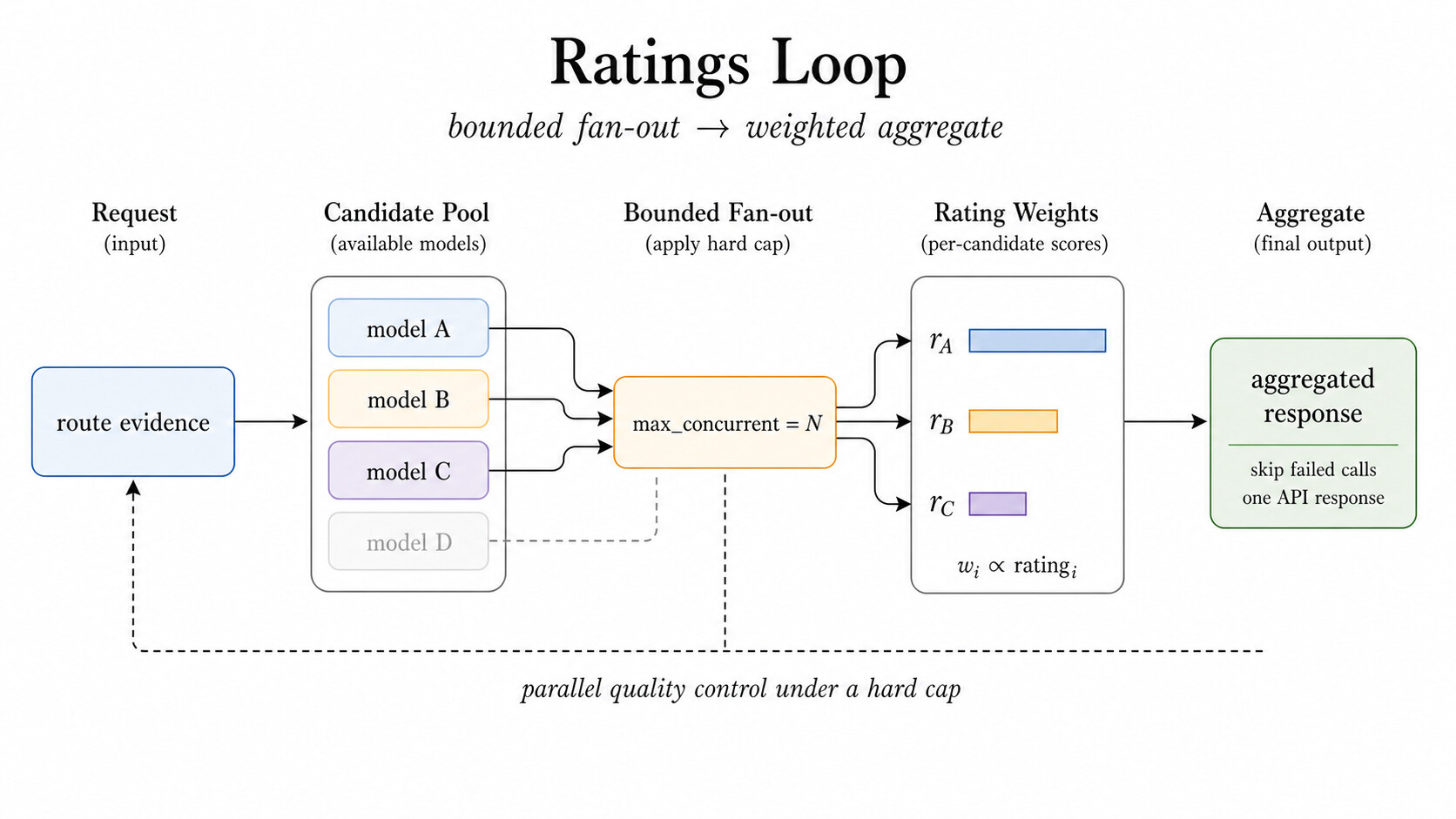
Ratings: 동시성 상한 아래에서의 병렬 품질
Ratings 는 통제된 앙상블(ensemble) 루프입니다. 여러 후보를 병렬로 띄우되, 설정된 max_concurrent 상한까지만 띄웁니다. 덕분에 모든 요청을 무한 팬아웃으로 바꾸지 않으면서도, 여러 모델의 관점에서 이득을 보고 싶은 경로에 적합합니다.
라우터는 성공한 응답을 모아 평점 인식(rating-aware) 집계를 적용하고, 실패는 경로 정책에 따라 처리합니다. 아래 그림처럼 여러 후보가 동시성 상한 아래에서 실행되고, 평점 가중치로 결과가 합쳐집니다. 실무에서 Ratings는 A/B 스타일 평가, 앙상블 전략, 그리고 운영자가 이미 후보별 품질 신호를 갖고 있는 경로에 잘 맞습니다.
ReMoM: 출력 계약을 지키는 넓이 우선 추론
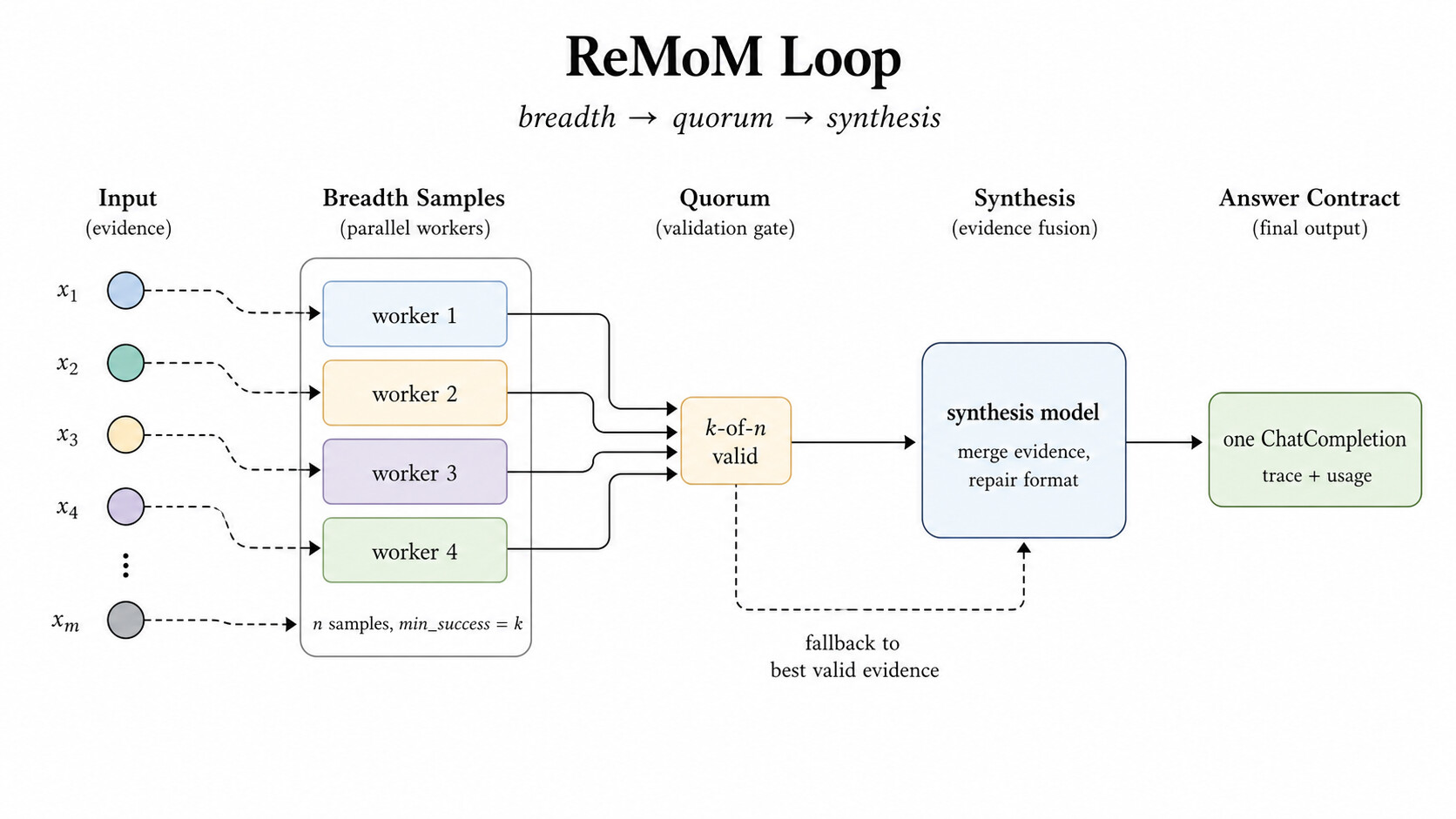
ReMoM(repeated mixture-of-model reasoning) 은 과제의 추론 분산이 크고, 답의 형식이 협업 과정에서 살아남아야 할 때 유용합니다. 여러 추론 시도를 팬아웃해 넓이(breadth)를 확보하고, 최소 성공 정족수를 기다린 다음, 합성 모델에게 증거를 병합해 요구된 출력 계약(output contract)으로 만들어 달라고 요청합니다. 이 발상은 여러 모델의 응답을 섞어 품질을 끌어올리는 Mixture-of-Agents 계열의 아이디어를 서빙 계층의 제어 가능한 형태로 가져온 것으로 볼 수 있습니다.
ReMoM의 특징은 실패에 강하다는 점입니다. 합성이 실패하더라도 앞선 워커들이 유효한 증거를 만들어 두었다면, 경로가 API 오류로 무너지지 않습니다. 아래 그림처럼 넓이, 정족수, 합성, 폴백(fallback)이 모두 서빙 시점의 제어 장치로 다뤄지므로, 최선의 유효 증거로 폴백해 정상 응답을 돌려줄 수 있습니다.
Fusion: 불일치를 신호로 바꾸는 패널-심판-최종화
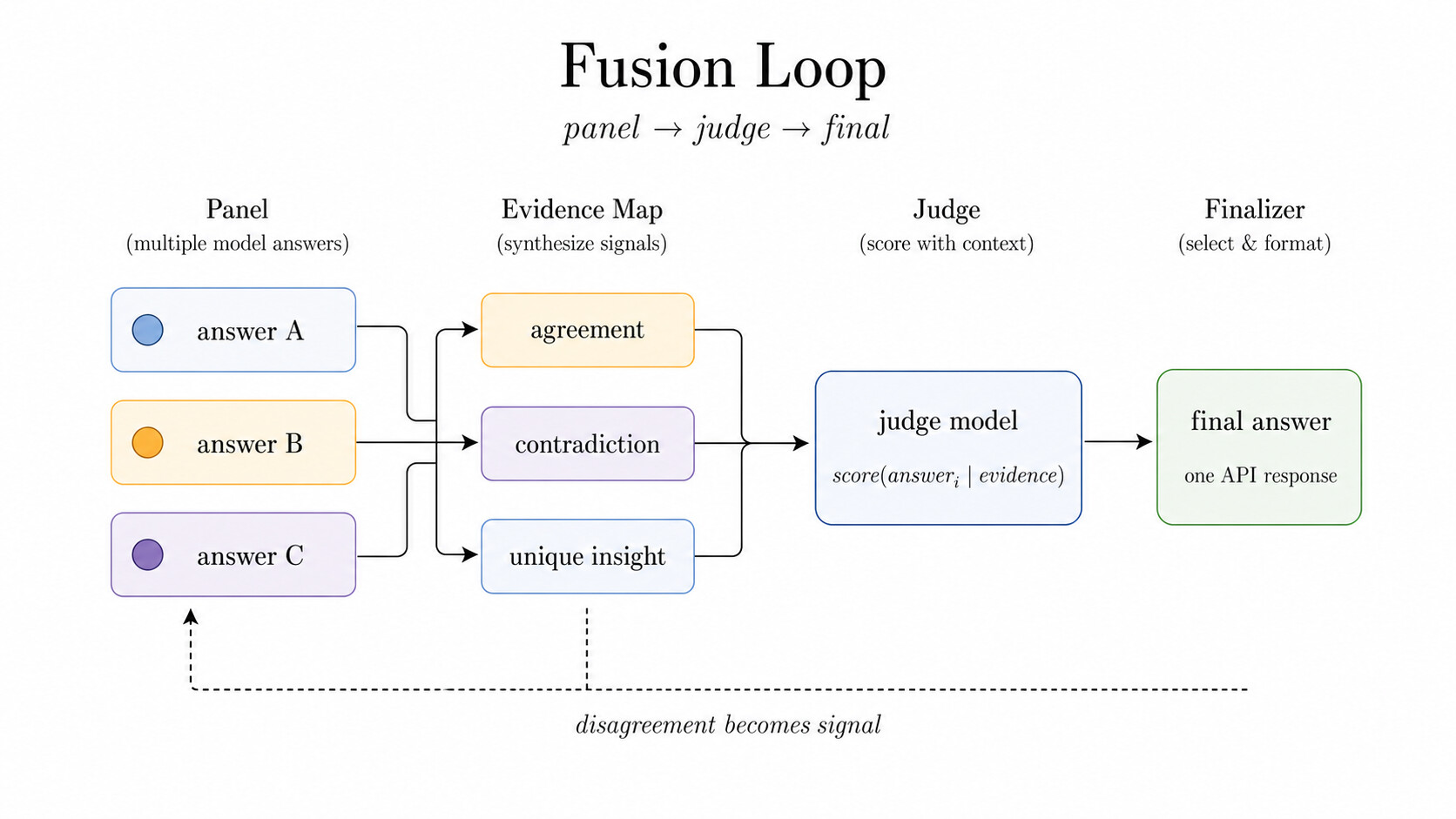
Fusion 은 다른 전제에서 출발합니다. 때로 유용한 대상은 평균적인 답이 아니라 불일치의 구조라는 것입니다. 독립적인 패널의 답들이 증거가 되고, 심판(judge)은 합의(agreement), 모순(contradiction), 고유한 통찰(unique insight)을 함께 봅니다. 그런 뒤 최종화기(finalizer)가 추적(trace)을 API 뒤로 접어 넣은 채 하나의 답을 반환합니다. 심판 단계는 각 답을 증거에 비추어 score(answer_i \mid evidence) 형태로 평가합니다.
아래 그림에서 답 A, B, C가 합의/모순/고유 통찰이라는 증거 지도(evidence map)로 정리되고, 심판 모델이 이를 점수화한 뒤 최종 답 하나로 수렴하는 흐름을 볼 수 있습니다. 그림 하단의 불일치가 신호가 된다(disagreement becomes signal) 는 문구가 Fusion의 본질입니다. 이 패턴은 그럴듯하게 경쟁하는 경로가 여러 개일 때, 예컨대 어려운 객관식 추론, 장문의 전문가 판단, 또는 하나의 자신만만한 답이 오히려 취약할 수 있는 정답형 과제에서 특히 유용합니다.
Workflows: 예산 아래에서 움직이는 역할 시스템
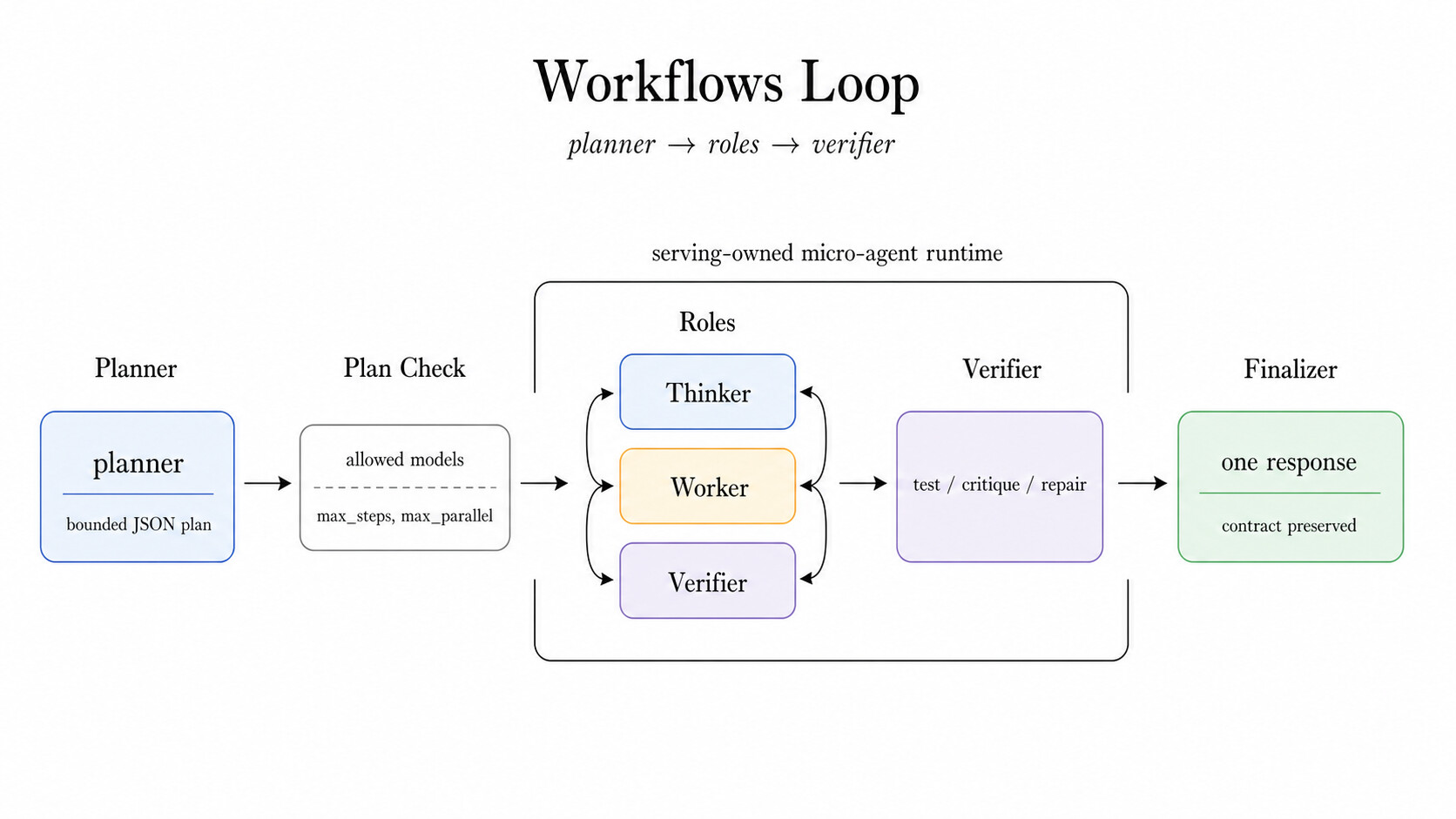
Workflows 는 가장 에이전트다운 패턴인 동시에 가장 엄격한 경계가 필요한 패턴입니다. 이 패턴은 미리 정해진 고정 역할(static roles)로 구성할 수도 있고, 동적 계획자(dynamic planner)가 직접 계획을 세우게 할 수도 있으며, 경계가 정해진 워커 단계를 실행한 뒤 최종 응답을 합성합니다. 계획자(planner)는 허용된 워커 모델만 고를 수 있고, 그 계획은 검증됩니다. 각 단계는 최대 단계 수, 최대 병렬도, 타임아웃, 오류 정책으로 제한되며, 최종 응답은 여전히 출력 계약을 만족해야 합니다.
SWE(소프트웨어 엔지니어링) 스타일 과제에서 이는 라우터가 계획자, 패처(patcher), 검증자(verifier), 최종화기를 표현하되 애플리케이션이 맞춤형 에이전트 스택을 직접 소유하지 않게 한다는 뜻입니다. 프로덕션 서빙에서 이 구분은 결정적입니다. 루프는 강력하지만, 여전히 인프라에 의해 통제됩니다. 아래 그림처럼 Workflows는 라우터에게 무한히 자율적인 에이전트가 아니라 경계가 정해진 역할 시스템을 부여합니다.
Auto 레시피: 하나의 모델 이름, 여러 루프
공개 표면은 여전히 vllm-sr/auto 라는 모델 이름 하나로 유지됩니다. 내부적으로 라우터는 신호와 투영을 사용해 요청에 맞는 루프를 고릅니다. 난이도, 위험, 계약 압력(contract pressure), 지연, 비용은 프롬프트 속 주석이 아니라 *라우팅 사실(routing fact)*이며, 이 사실들이 Confidence, Ratings, ReMoM, Fusion, Workflows 또는 폴백 경로를 선택합니다.
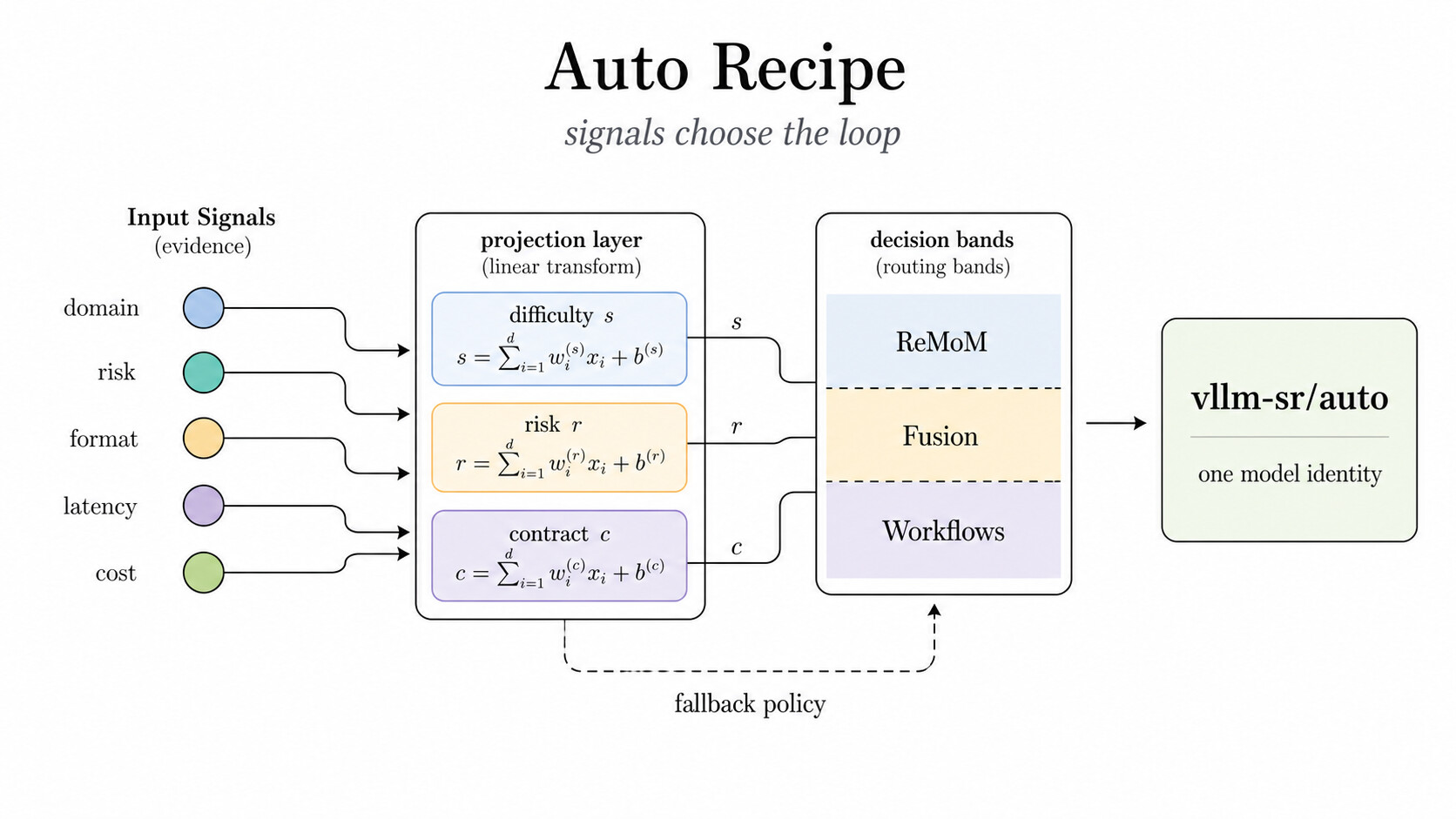
이것이 바로 "앱 로직으로서의 에이전트" 와 "서빙 런타임으로서의 마이크로 에이전트" 의 차이입니다. 후자에서는 라우터가 예산, 정책, 토폴로지, 추적, 실패 모드를 모두 통제합니다.
만능 루프는 없다: 레시피는 과제의 모양을 따른다
평가 작업에서 얻은 가장 중요한 교훈은 "하나의 알고리즘이 항상 이긴다"가 아니라 정반대였습니다. "가장 좋은 루프는 과제의 모양을 따른다(The best loop is task-shaped)" 는 것입니다. GPQA-Diamond는 엄격한 객관식 답 보존을 원하고, LiveCodeBench는 실행 가능한 코드와 숨은 테스트에 대한 견고함을 원합니다. Humanity's Last Exam(HLE)은 불일치 해소와 정확한 정답 형식을 원하고, SWE형 과제는 계획자, 패처, 검증자, 최종화기를 필요로 합니다.
그래서 vllm-sr/auto 는 "항상 가장 큰 루프를 돌려라" 를 뜻해서는 안 됩니다. "이 과제에 맞는 레시피를 선택하라" 를 뜻해야 합니다. 아래 그림은 신호와 투영이 어떻게 벤치마크의 모양에 맞는 협업 패턴을 고르는지 보여줍니다.
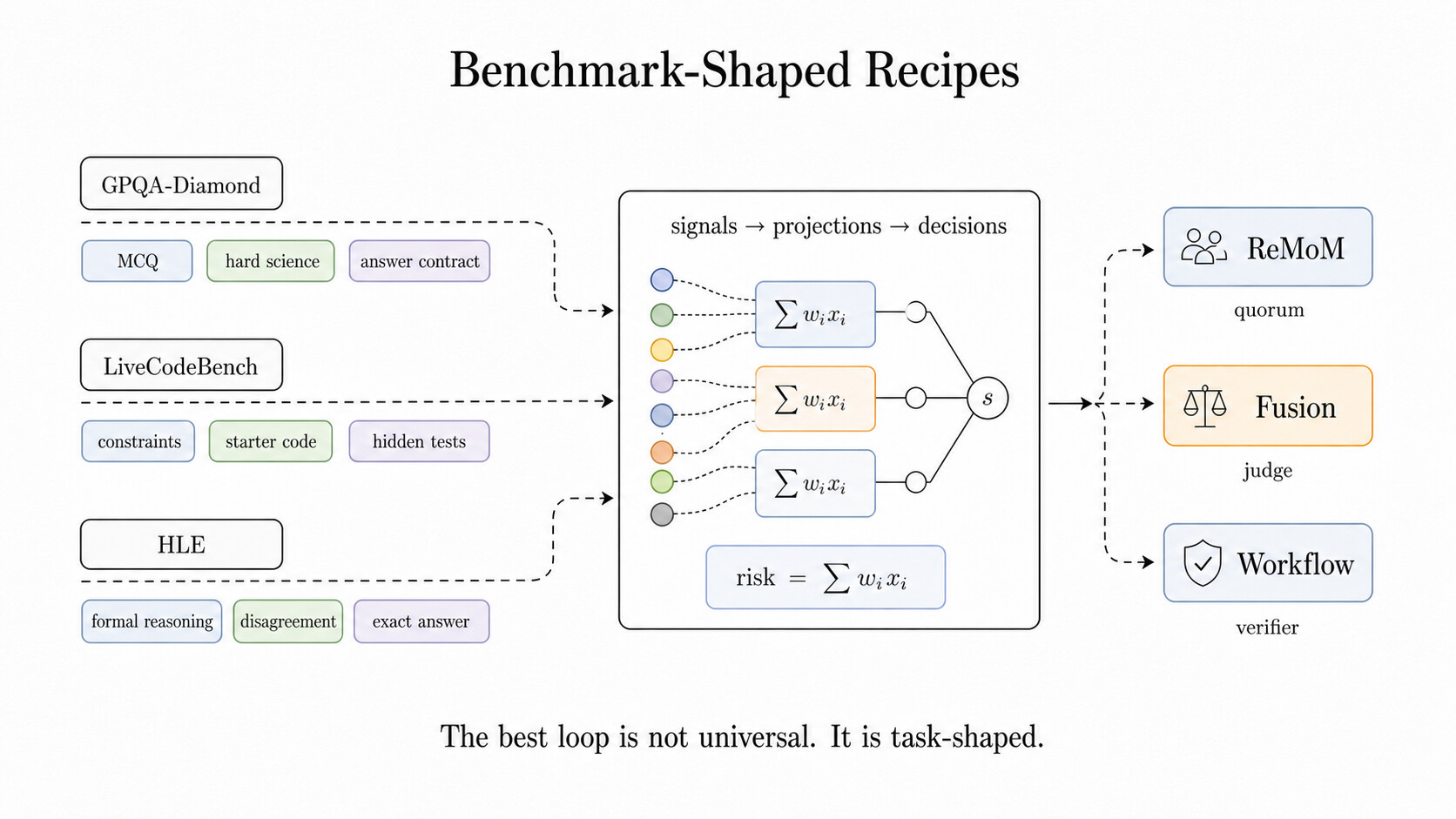
vLLM 팀의 레시피에서 이 "모양"은 명시적입니다.
-
GPQA-Diamond 는 어려운 과학 객관식 프롬프트를 엄격한
ANSWER: X보존이 적용된 ReMoM 레시피로 라우팅합니다. -
LiveCodeBench 는 코드 형태의 루프를 고르기 전에 제약 조건, 스타터 코드, 표준 입력, 부동소수점 허용 오차, 타임아웃 위험, 숨은 테스트 위험을 먼저 살핍니다.
-
HLE 는 형식적 추론(formal reasoning), 불일치 위험, 긴 컨텍스트, 정확한 정답 압력을 감지한 뒤 더 깊은 ReMoM, 더 작은 Fusion, 또는 폴백 경로 중에서 선택합니다.
이것이 라우터 측 협업이 단순한 프롬프트 엔지니어링 이상인 이유입니다. 프롬프트는 한 부분일 뿐이며, 레시피는 모델 풀, 모델 역할, 추론(reasoning) 강도, 동시성, 정족수, 타임아웃, 합성 모델, 폴백 정책, 출력 계약, 관측(observability) 라벨까지 함께 정의합니다.
스코어카드는 증명이지, 이야기의 전부가 아니다
vLLM 팀은 현재의 폐쇄형 모델 레시피를 세 가지 어려운 벤치마크에서 평가했습니다. 이 수치들이 유용한 이유는, 이 아이디어가 단지 미학적인 것만은 아님을 보여주기 때문입니다. 아래 스코어카드에서 VSR은 vLLM Semantic Router(VSR)를 가리킵니다. VSR Closed 는 폐쇄형(closed) 모델 백엔드만 사용하는 레시피를, VSR Hybrid 는 더 높은 위험의 심판, 복구, 합성, 폴백이 필요한 자리에 더 강한 폐쇄형 모델을 섞어 쓰는, 오픈 모델과 폐쇄형 모델을 혼합한 레시피를 뜻합니다.
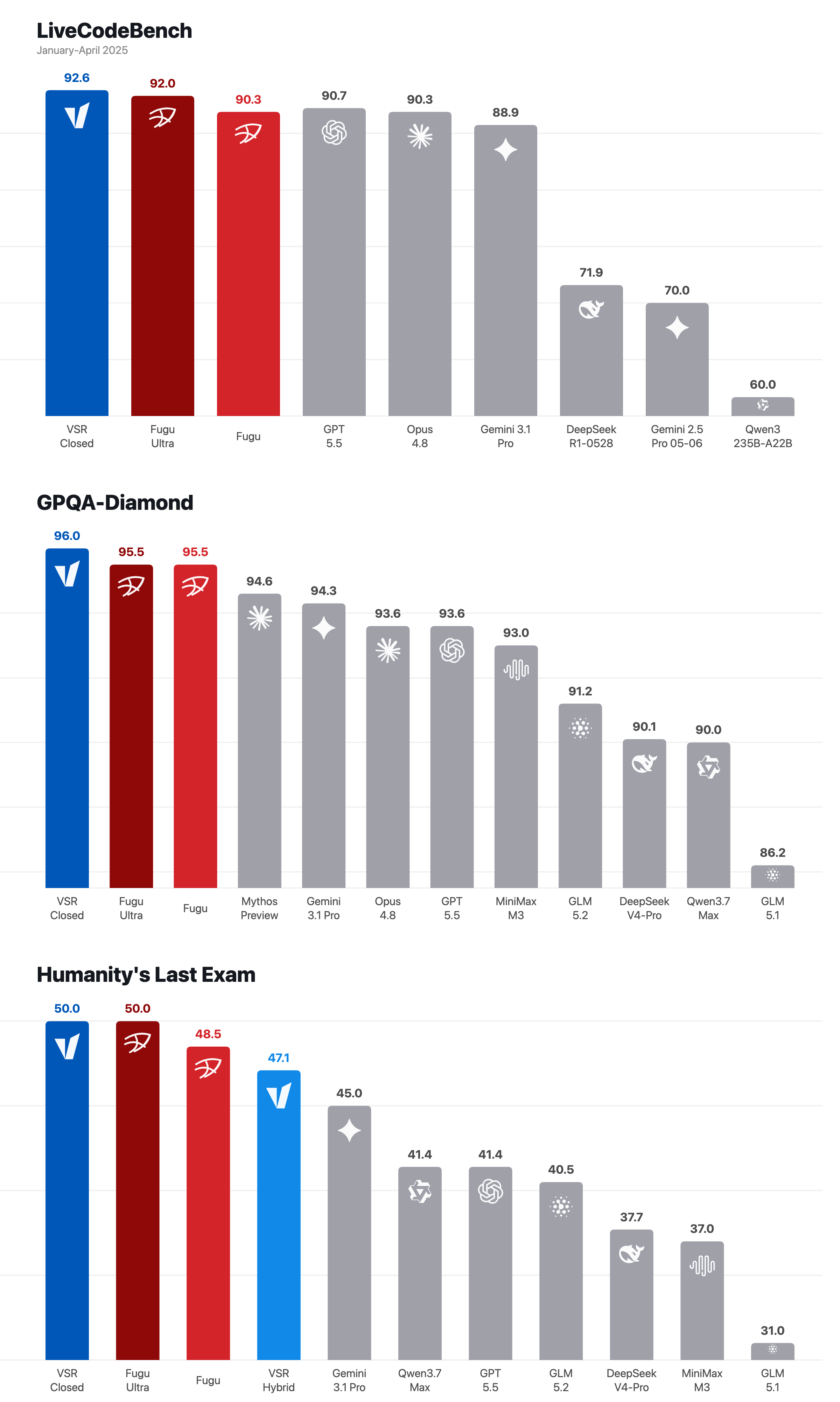
| 벤치마크 | VSR 행 | 점수 | 비교 대상 (원문 스코어카드 기준) |
|---|---|---|---|
| LiveCodeBench (2025년 1~4월) | VSR Closed | 92.6 | Fugu Ultra 92.0, Fugu 90.3, GPT-5.5 90.7, Opus 4.8 90.3 |
| GPQA-Diamond | VSR Closed | 96.0 | Fugu Ultra 95.5, Fugu 95.5, Gemini 3.1 Pro 94.3, GPT-5.5 93.6 |
| Humanity's Last Exam | VSR Closed | 50.0 | Fugu Ultra 50.0, Fugu 48.5, Gemini 3.1 Pro 45.0 |
| Humanity's Last Exam | VSR Hybrid | 47.1 | GLM-5.2 40.5, Qwen3.7 Max 41.4, GPT-5.5 41.4 |
다만 이 스코어카드는 조심스럽게 읽어야 합니다. 이것은 "모든 요청이 항상 모든 폐쇄형 모델을 써야 한다" 는 주장이 아닙니다. 그건 잘못된 제품일 것입니다. 진짜 주장은, 라우터가 소유한 협업이 그 아래 놓인 개별 호출들보다 더 강한 모델 정체성을 만들어낼 수 있다는 것입니다. 하나의 API 표면을 유지하면서도 프론티어 단일 모델 베이스라인을 이기거나 따라잡을 수 있다는 뜻입니다.
이것이 실제 제품의 모양입니다.
-
사용자는 모델 이름 하나만 봅니다.
-
운영자는 레시피를 통제합니다.
-
시스템은 클라이언트 연동을 바꾸지 않고도 개선될 수 있습니다.
-
오픈 모델과 폐쇄형 모델이 같은 서빙 추상화 아래에서 함께 참여할 수 있습니다.
벤치마크 더 알아보기
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
LiveCodeBench - 오염되지 않은(contamination-free) 코드 생성 평가
Humanity's Last Exam
모델 서빙의 다음 단계: 수동적 스택에서 능동적 인프라로
이 글의 마지막 메시지는 서빙 스택 자체의 성격 변화입니다. 과거의 서빙 스택은 수동적이었습니다. 모델 이름을 받아 백엔드로 요청을 보내면 끝이었죠. 다음 서빙 스택은 능동적입니다. 이 스택은 들어온 요청을 두고 다음과 같은 질문을 던집니다.
-
이 요청에 대해 우리는 어떤 증거를 갖고 있는가?
-
이 요청은 어떤 품질, 비용, 지연, 안전 대역에 속하는가?
-
모델 하나로 충분한가?
-
충분하지 않다면, 어떤 협업 패턴을 돌려야 하는가?
-
어떤 답 계약(answer contract)을 보존해야 하는가?
-
어느 제공자가 느리거나 틀렸을 때 무슨 일이 일어나야 하는가?
-
전체 추적(trace)을 보존하면서 어떻게 깔끔한 응답 하나를 노출할 것인가?
이것은 애플리케이션 접착제(application glue)가 아니라 인프라입니다. 마이크로 에이전트가 라우터에 속해야 하는 이유는, 라우터가 이미 마이크로 에이전트에게 필요한 것들을 소유하고 있기 때문입니다. 모델 별칭, 제공자 정책, 자격 증명, 비용 메타데이터, 신호, 결정, 재시도, 타임아웃, 추적, 그리고 OpenAI 호환 응답 의미론까지 말입니다. 라우터 측 협업이라는 같은 흐름은 커뮤니티에서도 꾸준히 다뤄져 왔습니다. 예컨대 실행 피드백으로 라우팅을 진화시키는 Agent-as-a-Router 연구나, 에이전트 친화적 라우터를 표방하는 ClawRouter 같은 사례가 같은 방향을 가리킵니다.
정리: 프론티어 모델이라는 말의 두 가지 의미
vLLM 팀은 "프론티어 모델" 이라는 표현이 이제 두 가지를 뜻하기 시작했다고 말합니다. 하나는 *체크포인트(checkpoint)*이고, 다른 하나는 *시스템 경계(system boundary)*입니다. 최근의 오케스트레이션 물결이 이 방향을 눈에 보이게 만들었고, vLLM Semantic Router는 이 능력이 서빙 계층에서 프로그래밍 가능하고, 관측 가능하며, 열려 있어야 한다는 데 거는 베팅입니다.
다음 모델 경쟁은 여전히 더 좋은 모델을 포함하겠지만, 동시에 더 좋은 라우터를 포함할 것입니다. 언제 비용을 아끼고, 언제 안전을 강제하고, 언제 엣지에 머물고, 언제 클라우드로 가고, 언제 하나의 요청을 작고 규율 잡힌 팀으로 바꿀지를 아는 라우터 말입니다. 그것이 모델 API 안에 들어온 마이크로 에이전트가 약속하는 바입니다.
원문 블로그는 MBZUAI, McGill University, Mila, Agentic Intelligence Lab의 연구진, 특히 Xue Liu 교수와 Bowei He 박사와의 라우터 측 모델 협업에 관한 연구 협업 및 논의를 바탕으로 작성되었습니다. 개별 기여자로는 Huamin Chen, Yincheng Ren이 참여했으며, AMD의 Andy Luo와 Haichen Zhang이 AMD GPU 기반 평가를 지원했습니다. 스코어카드가 특정 가속기에 종속되지 않고 검증되었다는 점은, 이 접근이 특정 하드웨어가 아니라 서빙 인프라 수준에서 작동하는 일반적 기법임을 뒷받침합니다.
 Micro-Agent: Beat Frontier Models with Collaboration inside Model API 원문 블로그
Micro-Agent: Beat Frontier Models with Collaboration inside Model API 원문 블로그
 vLLM Semantic Router GitHub 저장소
vLLM Semantic Router GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()