
prime-rl 0.6.0 소개
최근 대규모 언어 모델(Large Language Model, LLM)의 성능을 끌어올리는 핵심 동력은 사전 학습(pre-training)의 규모 확장에서 사후 학습(post-training), 그중에서도 강화 학습(Reinforcement Learning, RL) 으로 빠르게 옮겨가고 있습니다. 단순히 정답이 주어진 데이터로 모델을 미세조정(fine-tuning)하는 것을 넘어, 모델이 실제로 도구를 호출하고 코드를 실행하며 환경과 상호작용하는 에이전틱 강화학습(Agentic RL) 이 프런티어 모델의 추론(reasoning) 능력을 결정짓는 단계가 된 것입니다. 문제는 이 과정이 엄청나게 비싸고 까다롭다는 데 있습니다. 1조(1T) 파라미터급 모델을 SWE(소프트웨어 엔지니어링) 같은 장기 과제(long-horizon task)로 강화학습하려면, 학습기(trainer)와 추론기(inference) 양쪽을 동시에 굴리면서 수천 개의 GPU에서 발생하는 모든 비효율을 짜내야 합니다.
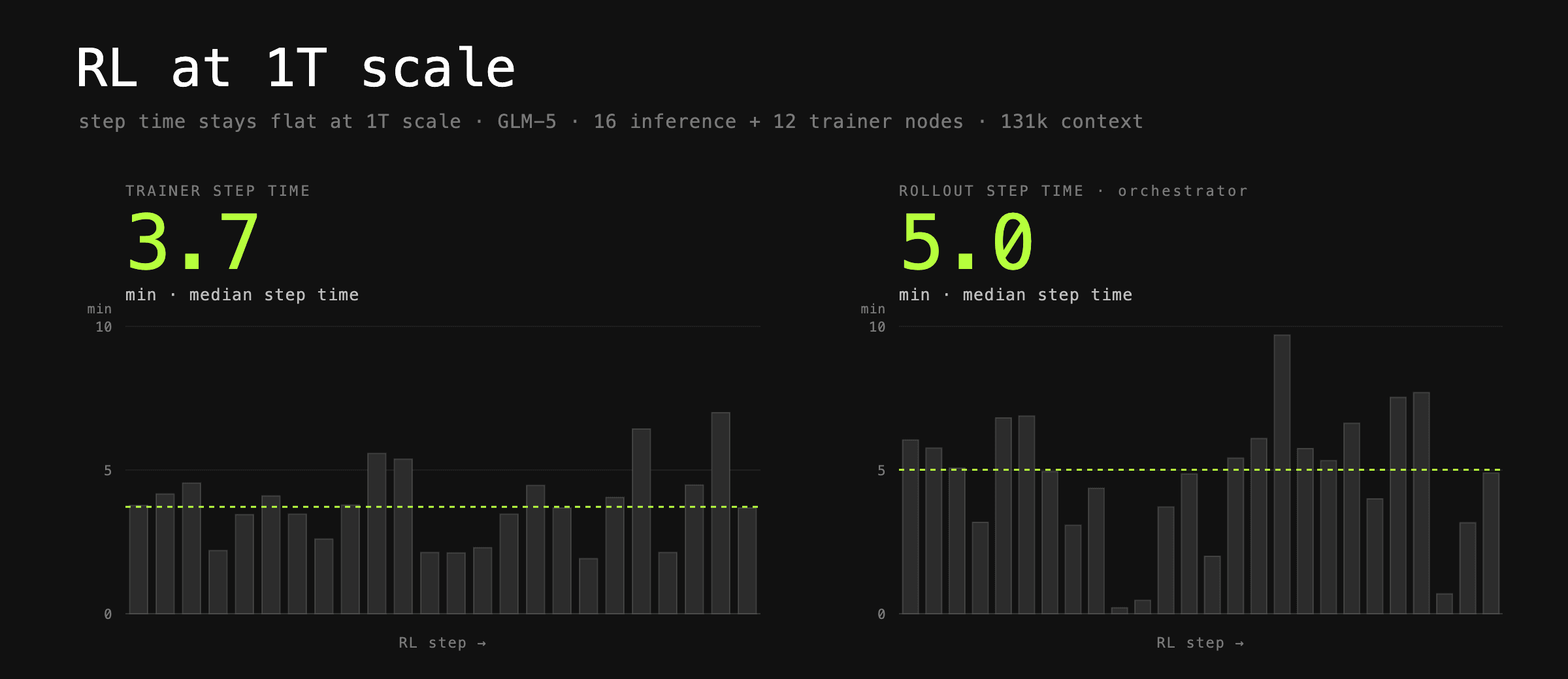
Prime Intellect가 공개한 prime-rl 0.6.0 버전은 바로 이 문제를 정면으로 다룹니다. 이 릴리스의 목표는 "1조 파라미터 규모의 모델을 무거운 에이전틱 워크로드 위에서 최고 효율로 학습"하는 것입니다. Prime Intellect 팀이 제시하는 대표 성과는 다음과 같습니다. GLM-5를 SWE 과제로, 최대 131k 시퀀스 길이에서 5분 미만의 스텝 시간(step time), 256개 롤아웃(rollout)의 배치 크기로, 단 28개의 H200 노드만으로 학습할 수 있다는 것입니다. 위 히어로 이미지의 두 막대 그래프는 학습기 스텝 시간 중앙값이 3.7분, 오케스트레이터 기준 롤아웃 스텝 시간 중앙값이 5.0분으로, RL 스텝이 진행되어도 1T 규모에서 시간이 폭증하지 않고 평탄하게 유지된다는 점을 보여줍니다.
이번 글에서는 prime-rl이 이런 성과를 내기까지 적용한 최적화를 추론과 학습 양쪽으로 나누어 깊이 있게 살펴봅니다. 저정밀도(low-precision) 추론과 학습, 프리필(prefill)과 디코드(decode)를 분리한 추론 배치, 와이드 전문가 병렬화, 라우터 리플레이까지가 주요 주제입니다. 본문은 GLM-5.1을 예시 모델로 삼지만, 이 최적화들은 Kimi-K2.7-Code나 NVIDIA Nemotron-3-Ultra-550B처럼 어떤 대규모 혼합 전문가(Mixture-of-Experts, MoE) 모델에도 그대로 적용됩니다. 참고로 GLM-5.1 학습은 Slurm 클러스터에서 uv 기반 단일 명령으로 시작할 수 있습니다.
uv run rl @ examples/glm5_llmd/rl.toml --output-dir /shared/outputs/glm5-llmd
비동기 RL이라는 설계 철학
prime-rl은 처음부터 효율적인 에이전틱 사후 학습을 위해 설계되었고, 그 핵심에는 비동기 강화학습(Asynchronous RL) 이 있습니다. 에이전틱 과제는 긴 꼬리(long-tail) 분포의 이상치(outlier)를 자주 만들어냅니다. 특히 장기 코딩 과제에서는 하나의 롤아웃이 몇 시간씩 걸리기도 합니다. 만약 이 느린 롤아웃이 모두 끝날 때까지 정책 업데이트(policy update)를 미룬다면, 그동안 GPU는 놀게 되고 전체 성능이 떨어집니다. 비동기 RL은 이 문제를, 학습기에서 옵티마이저 스텝이 끝나는 즉시 추론 정책을 갱신하도록 허용함으로써 해결합니다. 이렇게 학습기와 추론기를 분리(disaggregate)하면 두 시스템을 서로 독립적으로 최적화할 수 있습니다.

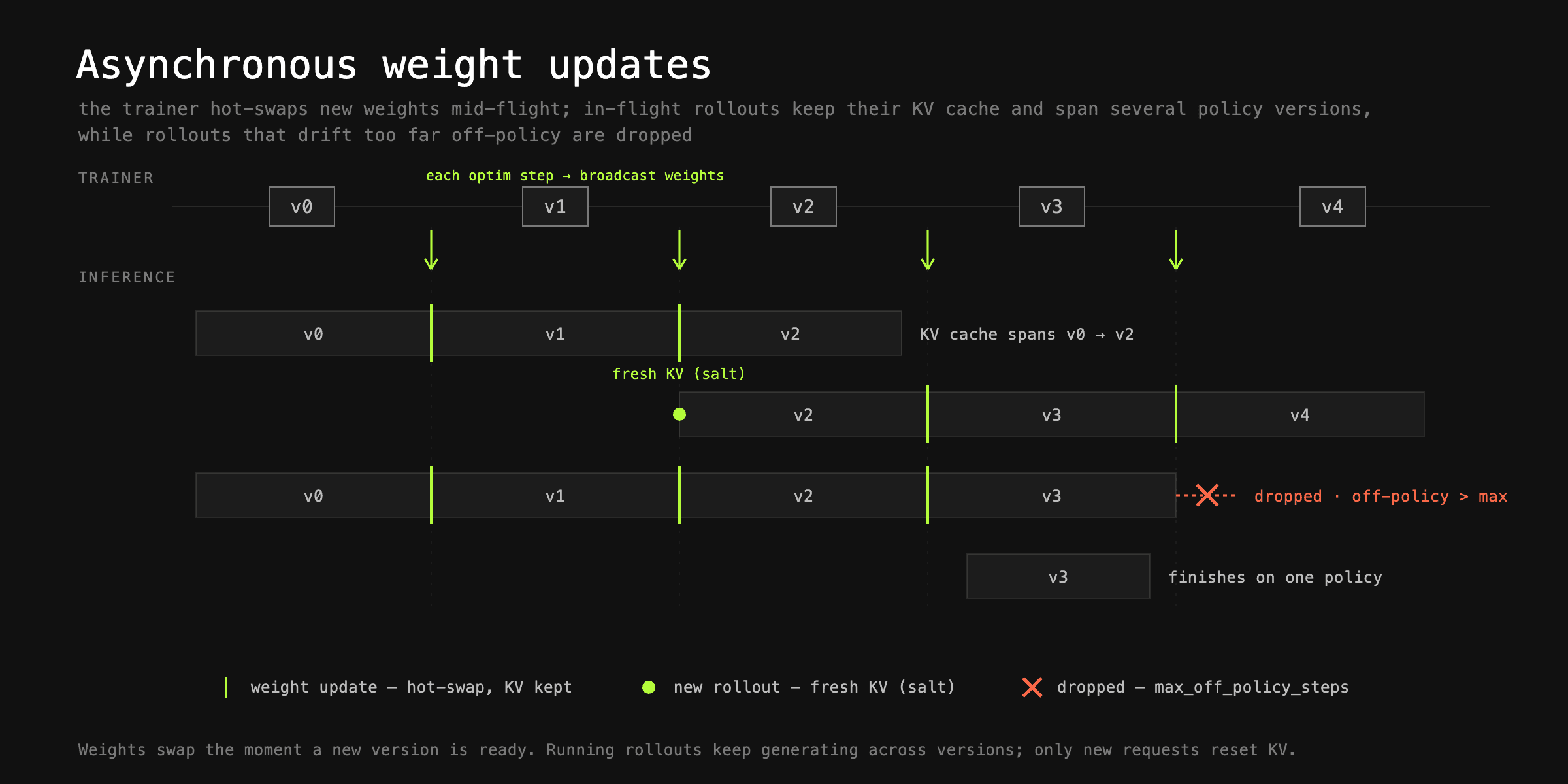
물론 학습기와 추론기 사이에는 본질적인 동기화 지점이 하나 존재합니다. 바로 정책 업데이트입니다. 롤아웃 정책은 각 옵티마이저 스텝 이후 새 가중치(weight)로 갱신됩니다. prime-rl은 새 가중치 세트가 준비되는 즉시 이를 반영합니다. 이때 추론 속도를 떨어뜨리지 않기 위해, 이미 디스패치된 롤아웃에 대해서는 활성 프리픽스 캐시(prefix cache)를 초기화하지 않습니다. 그 결과 이런 롤아웃은 여러 버전의 정책이 생성한 토큰으로 구성되고, KV 캐시(KV cache) 역시 여러 버전이 섞이게 됩니다. 다만 새로 시작하는 롤아웃은 기존 롤아웃과 프리픽스를 공유하더라도 자신만의 KV 캐시를 다시 채우는데, 이를 강제하기 위해 KV 캐시 솔트(salt)를 사용합니다. 마지막으로, 너무 오래된 정책으로 생성된 요청은 폐기되며, 이 허용 범위는 max_off_policy_steps 값으로 제어합니다.
이러한 상호작용은 시스템 최적화 관점에서 흥미로운 문제를 만들어냅니다. 학습기와 추론기라는 두 개의 시스템을 서로 호환 가능한 상태로 유지하면서, 어떻게 각각을 최대로 최적화할 것인가 하는 문제입니다. 이어지는 두 절에서는 이 두 시스템을 하나씩 해부하며 어떤 최적화가 들어갔는지 살펴봅니다. 비슷한 결의 RL 인프라 해부가 궁금하다면, 데이터 파이프라인부터 RL 인프라까지 프런티어 모델 학습 전 과정을 다룬 MAI-Thinking-1 기술 보고서 정리도 함께 참고할 만합니다.
추론(Inference) 시스템 최적화
추론은 RL 학습 수명 주기에서 가장 결정적인 부분입니다. 모델이 환경과 상호작용하며 롤아웃을 만들어내고, 그 롤아웃이 평가되어 보상(reward)을 받는 지점이 바로 추론이기 때문입니다. 일부 기능은 이미 추론 프레임워크에 존재하지만, 그렇지 않은 것들에 대해 Prime Intellect 팀은 vLLM, NVIDIA Dynamo 같은 프레임워크와 긴밀히 협업하고 있습니다. 목표는 하나입니다. 검증되고 사용하기 쉬운 레시피와 함께, 커뮤니티에 최고 성능의 추론을 제공하는 것입니다.
추론 처리량을 끌어올리는 FP8 추론
추론 처리량(throughput)은 보통 RL 시스템 전체의 병목입니다. 그리고 추론 처리량은 프리필과 디코드 양쪽 배치에서 정밀도를 낮출수록 큰 이득을 봅니다. prime-rl은 FP8 추론을 적극적으로 활용하며, 여기에 DeepEP와 DeepGEMM의 최적화된 커널을 결합하여 더 낮은 지연(latency)과 더 높은 처리량을 달성합니다. 두 라이브러리는 모두 DeepSeek가 공개한 것으로, MoE 모델의 전문가 통신과 행렬 곱(GEMM)을 저정밀도로 가속하는 데 특화되어 있습니다.
지연이 아니라 처리량을 노리는 와이드 전문가 병렬화
추론 성능을 다루는 다른 글들에서는 사용자에게 최고의 상호작용성을 주기 위해 지연 최소화에 초점을 맞추는 경우가 많습니다. 그러나 RL은 다릅니다. RL의 주된 관심사는 지연을 어느 정도 묶어두되 처리량을 최대화하는 것입니다.
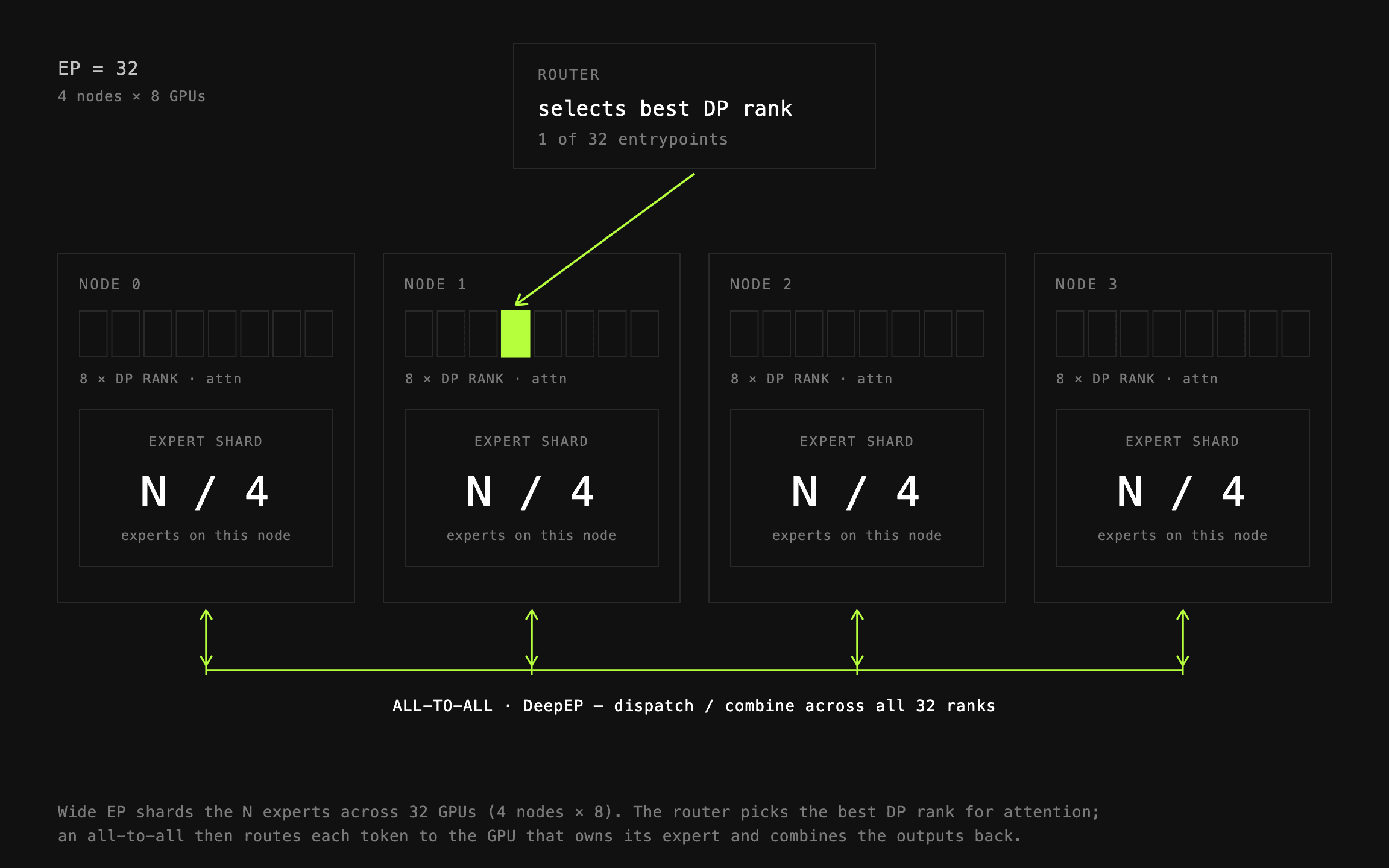
이 목표를 달성하는 가장 좋은 구성 중 하나가 와이드 전문가 병렬화(Wide Expert Parallelism, Wide EP), 즉 보통 32개 이상의 GPU에 걸치는 대규모 전문가 병렬화입니다. 처리량을 극대화하기 위해 prime-rl은 이 전략을 큰 데이터 병렬(data-parallel) 랭크와 결합합니다. 예를 들어 데이터 병렬 32와 묶으면, 각각 별도의 전문가를 보유하고 각각 별도의 엔드포인트로 동작하는 거대한 GPU 그룹이 만들어집니다. 동기화는 계층(layer)마다 디스패치(dispatch)와 컴바인(combine) 연산에서 각각 이루어집니다.
프리필과 디코드를 분리하는 P/D 분리(Disaggregation)
프리필 처리량은 에이전틱 롤아웃의 큰 병목입니다. 일부 모델과 환경 조합은 프리필 대 디코드 토큰 비율이 무려 4 대 1까지 치솟습니다. 만약 동일한 추론 워커가 프리필과 디코드 요청을 모두 처리한다면 종단 간(end-to-end) 지연이 늘어나, PipelineRL이 주는 이점을 크게 깎아먹게 됩니다.
앞서 언급했듯 RL의 우선순위는 지연 최소화가 아니라 추론 처리량 최대화입니다. 그런데 추론 배치가 프리필 요청에 압도당해 지연이 크게 늘어나면, 완료된 롤아웃들이 한꺼번에 몰리는 "그룹화(grouping)" 현상이 관찰됩니다. 이는 학습기 스텝과 추론기 스텝의 겹침(overlap)을 떨어뜨립니다.
prime-rl을 사용하면 프리필과 디코드를 분리(P/D Disaggregation) 하는 구성을 매끄럽게 적용할 수 있습니다. 프리필 워커와 디코드 워커를 분리하면, 긴 프리필 요청(긴 도구 출력 등)이 디코드 워커의 발목을 잡지 않으므로 디코드 워커가 예측 가능한 지연으로 진행할 수 있습니다. 그 결과 모델의 한 턴(turn)이 더 빨리 완료되고, 도구 호출이 샌드박스 실행에 더 빨리 도달하며, 이 주기가 때로는 수백 턴에 걸쳐 반복됩니다.
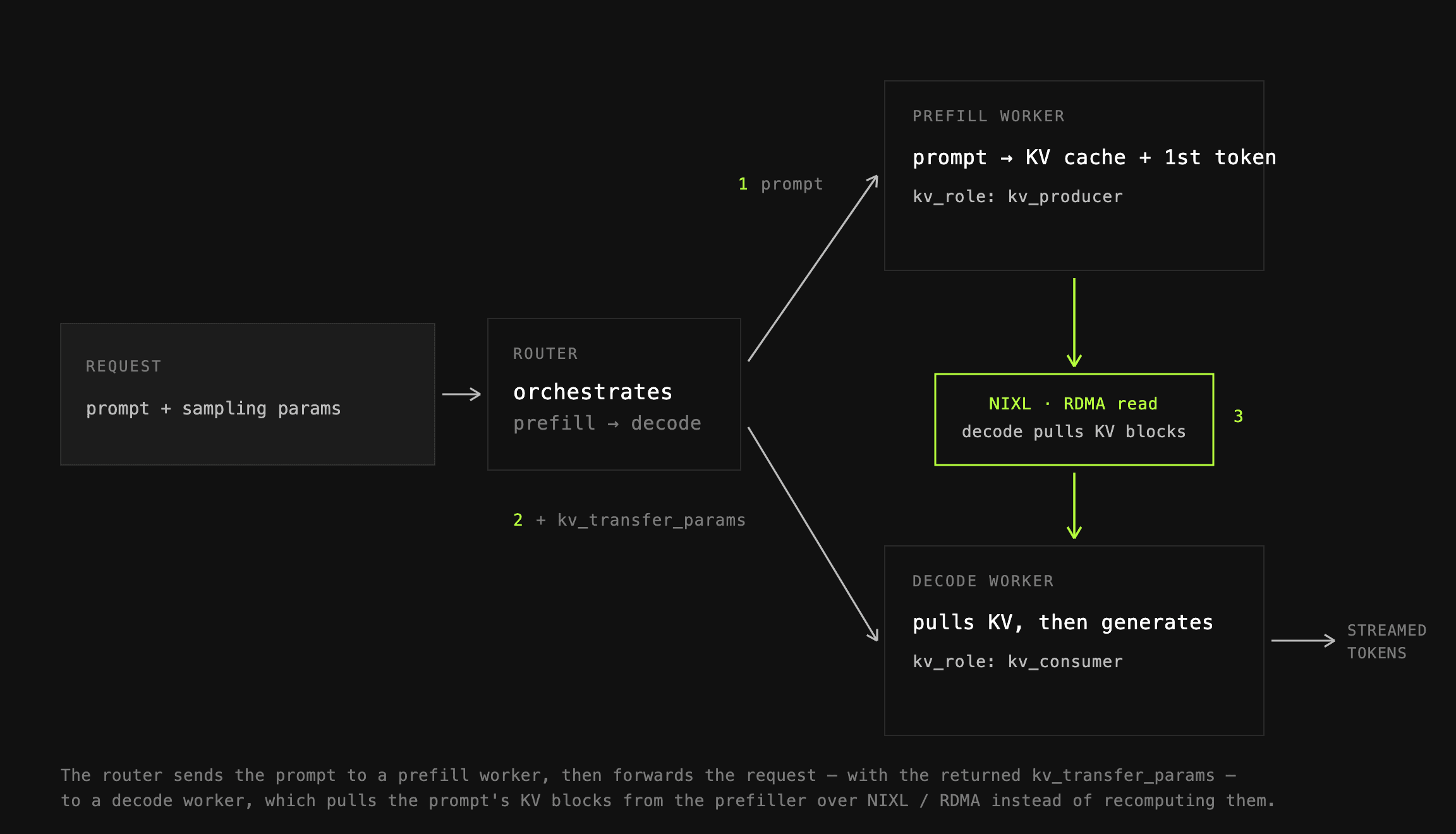
위 그림처럼, 라우터는 프롬프트를 먼저 프리필 워커(kv_role: kv_producer)로 보내 KV 캐시와 첫 토큰을 생성하게 하고, 반환된 kv_transfer_params 와 함께 요청을 디코드 워커(kv_role: kv_consumer)로 넘깁니다. 디코드 워커는 프롬프트의 KV 블록을 다시 계산하는 대신 NIXL과 RDMA를 통해 프리필 워커에서 직접 읽어옵니다.
KV 캐시 관리: 동시성을 떠받치는 메모리 계층
처리량을 최대화하려면 높은 동시성(concurrency)이 필요하고, 높은 동시성에는 많은 KV 캐시 공간이 필요합니다. 공간이 부족하면 KV 캐시 스래싱(thrashing)과 낮은 프리픽스 캐시 적중률이 발생해 처리량이 떨어집니다. prime-rl은 추론 프레임워크의 최신 기능을 종단 간으로 지원하는데, 그중 하나가 KV 캐시 오프로딩(offloading) 입니다.
prime-rl은 vLLM 네이티브 오프로딩과 Mooncake를 모두 사용하여, CPU와 디스크로 이어지는 계층형(tiered) KV 캐시 오프로딩을 지원합니다. KV 캐시 공간이 늘어나면 동시성을 높일 수 있고, 그만큼 학습기 비용을 더 많이 상각(amortize)할 수 있습니다. 두 방식의 핵심 차이는 다음과 같습니다.
- vLLM 네이티브 오프로딩: 워커(DP 랭크)마다 단일 CPU/디스크 풀을 만드는 단순한 접근입니다. 이 캐시는 해당 워커만 다시 불러올 수 있습니다.
- Mooncake Store: 모든 클라이언트(노드)의 RAM과 디스크를 하나의 거대한 풀로 모으는 중앙 집중식 저장소로 동작합니다. 그 결과 어떤 노드의 어떤 추론 워커든 이 풀에 접근할 수 있어, 특히 더 정교한 라우팅 전략을 쓸 때 상당한 이점을 줍니다.
요청 라우팅(Request Routing)
이 모든 것을 하나로 묶으려면, 효율적인 프리픽스 재사용과 부하 인지(load-aware) 라우팅 등을 위해 추론 요청을 효율적으로 분배해야 합니다. prime-rl의 기본 라우팅 옵션은 vllm-router를 포크한 가볍고 최소한의 솔루션으로, 설정 부담을 최소화하면서도 강력한 성능을 냅니다. 요구사항에 따라 부하 분산, KV 캐시 재사용 등 원하는 목표에 맞춘 라우팅 전략을 직접 선택할 수도 있습니다.
대안으로 NVIDIA Dynamo 라우터도 드롭인(drop-in) 방식으로 지원합니다. 이를 통해 더 큰 규모의 실행을 위한 정교한 라우팅 전략을 개발하고 배포할 수 있습니다. 이런 전략들은 추론 워커가 보내는 실시간 지표(KV 캐시 재사용, 큐 깊이, KV 캐시 사용률, 현재 부하 등)를 종합해 각 워커에 점수를 매기고, 그 점수와 정책에 따라 워커를 선택합니다.
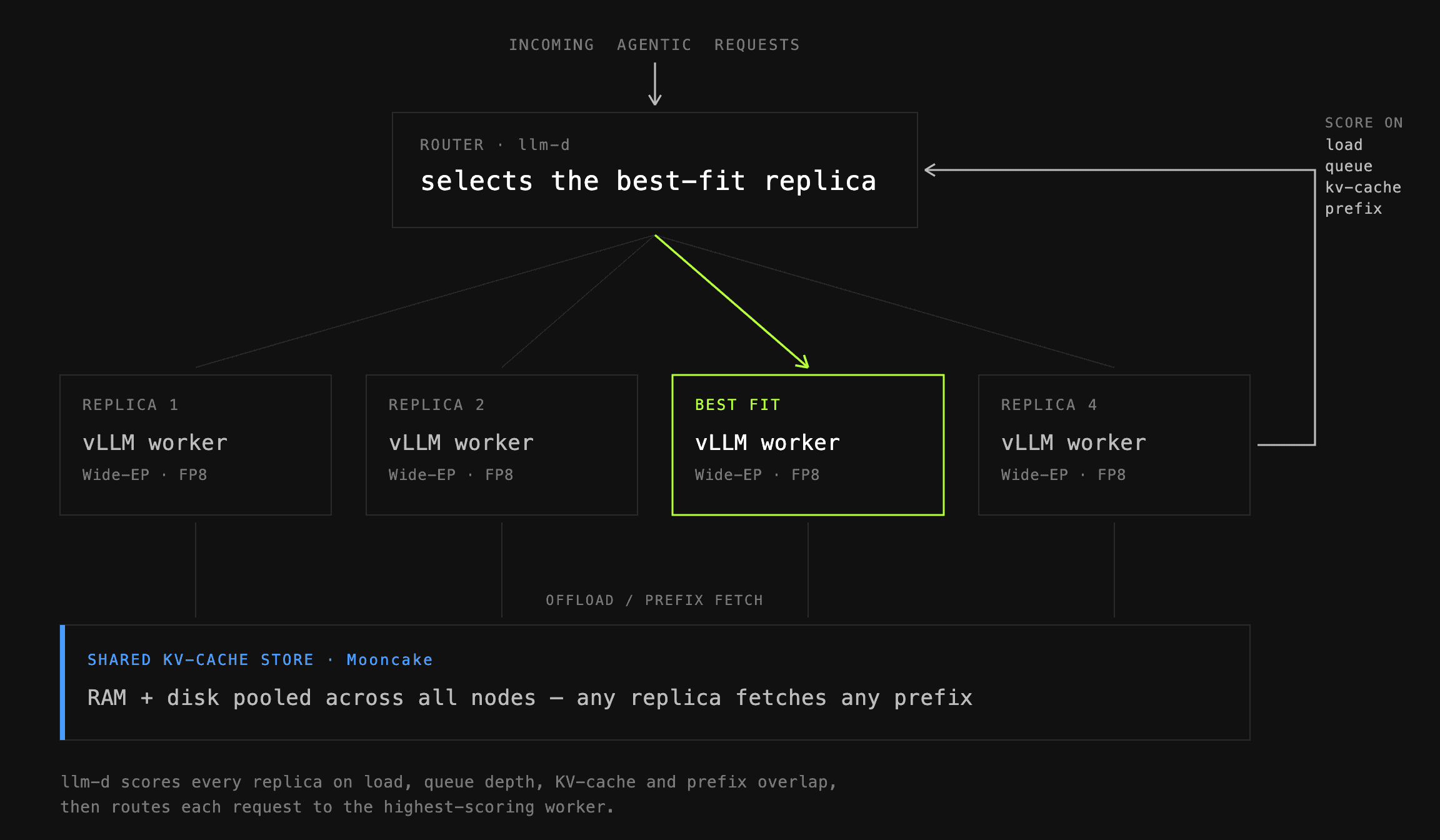
중앙 집중식 KV 캐시 오프로딩 계층 역할을 하는 Mooncake Store와 결합하면, 복제본(replica) 사이에서도 프리픽스 캐시 적중이 가능해지고, 부하를 공정하게 분산하면서 실시간 지표에 반응할 수 있습니다. Prime Intellect 팀은 라우팅 솔루션을 지속적으로 개선하기 위해 vLLM, Dynamo 팀과 적극적으로 협업하고 있습니다.
학습과 추론의 불일치를 잡는 라우터 리플레이(Router Replay, R3)
학습기와 추론기의 불일치(mismatch)는 RL 학습을 조용히 망가뜨립니다. 이를 막기 위해 prime-rl은 라우터 리플레이(Router Replay), 줄여서 R3를 제공합니다. 이 기법은 추론 중에 내려진 라우팅 결정을 포착(capture)한 뒤, 학습기에서 그대로 다시 재생(replay)하는 방식으로 동작합니다. 그 결과 학습기와 추론기 사이의 KL 불일치(KL mismatch) 를 약 10배(an order of magnitude) 수준으로 줄여, 더 안정적인 학습으로 이어집니다.
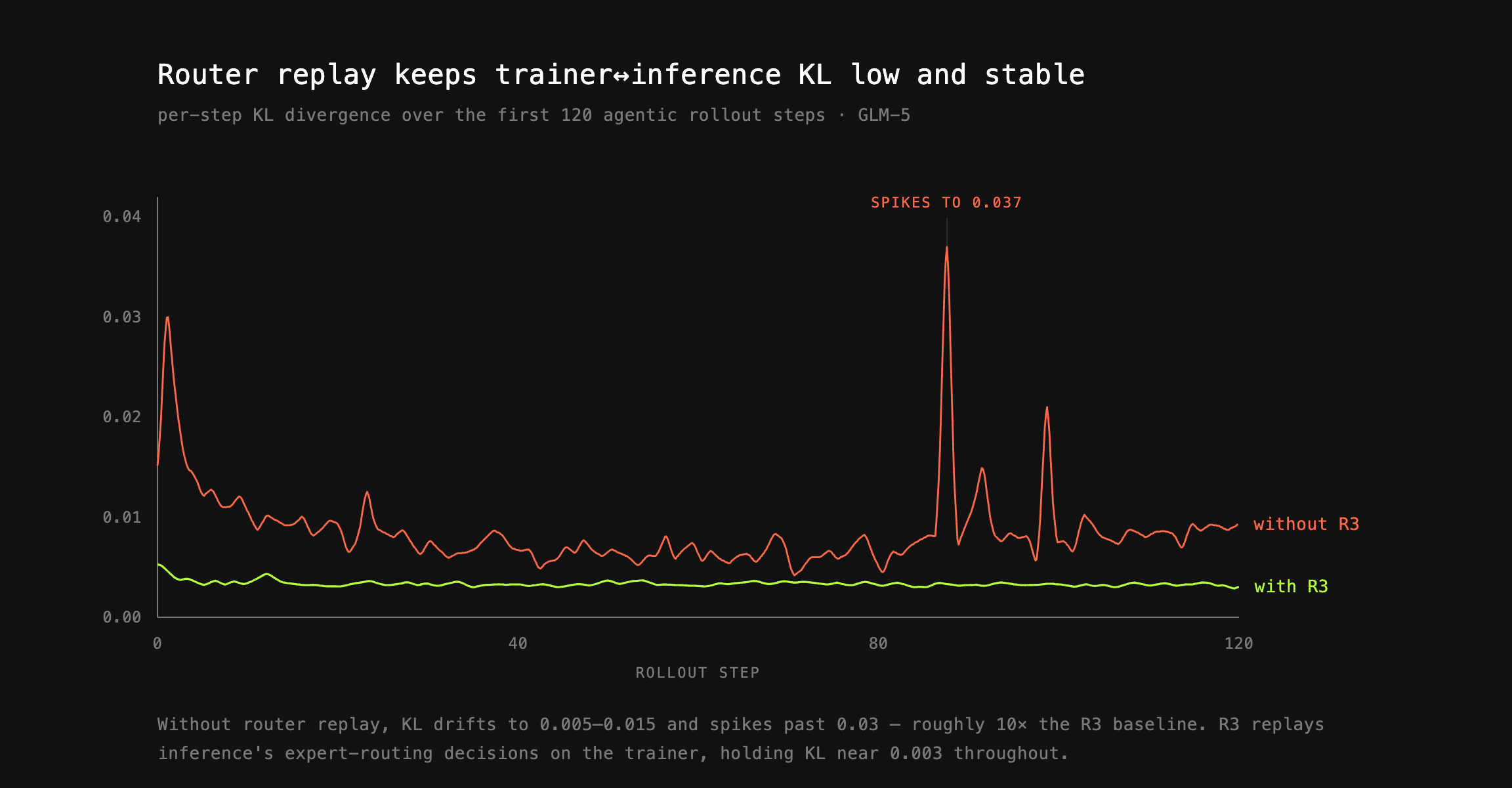
다만 이 기법이 공짜는 아닙니다. 대규모 배포에서는 라우팅된 전문가(routed-experts) 데이터가 초당 수십 기가비트(Gbps)에 달해, 처리 부담이 막대해집니다. 라우팅된 전문가는 [num_layers, top_k, seq_len] 형태의 거대한 페이로드로, 금세 수백 GB까지 불어나 Python 처리에 큰 부하를 줍니다. 응답을 Python 딕셔너리로 변환하는 것처럼 단순해 보이는 연산조차 이벤트 루프(event loop) 지연과 CPU 병목을 일으킬 수 있습니다. 이 오버헤드를 없애기 위해 prime-rl은 라우팅된 전문가를 불투명한(opaque) 페이로드로 취급하고, 유일한 처리를 고도로 최적화된 PyTorch 연산으로만 수행하여 CPU 부담을 줄입니다. 라우터 리플레이는 P/D 분리를 포함한 다른 추론 최적화와 완전히 호환되어, 프로덕션 수준의 스택을 손쉽게 배포할 수 있게 해줍니다.
추론 최적화 더 알아보기
-
고성능 LLM 추론 및 서빙 엔진 vLLM: GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs · GitHub
-
분산 추론 서빙 프레임워크 NVIDIA Dynamo: GitHub - ai-dynamo/dynamo: A Datacenter Scale Distributed Inference Serving Framework · GitHub
-
DeepSeek의 MoE를 위한 전문가 병렬 통신 라이브러리 DeepEP: GitHub - deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library · GitHub
-
DeepSeek의 FP8 GEMM 커널 라이브러리 DeepGEMM: GitHub - deepseek-ai/DeepGEMM: DeepGEMM: clean and efficient BLAS kernel library on GPU · GitHub
-
분산 KV 캐시 저장소 Mooncake: GitHub - kvcache-ai/Mooncake: Mooncake is the serving platform for Kimi, a leading LLM service provided by Moonshot AI. · GitHub
-
비동기 RL을 위한 파이프라인 기법, PipelineRL (arXiv 2509.19128): [2509.19128] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation
학습(Training) 시스템 최적화
prime-rl의 학습기는 torchtitan을 기반으로 합니다. torchtitan은 대규모 학습을 위한 고성능 PyTorch 네이티브 코드베이스로, Prime Intellect 팀은 FSDP, EP를 비롯한 다양한 추상화를 torchtitan에서 가져와 자신들의 학습기에 맞게 적응시키고 개선했습니다.
3차원 병렬화: FSDP, EP, CP
prime-rl은 주로 3차원 병렬화(3-D parallelism), 정확히는 FSDP, CP, EP에 의존합니다. 셋은 각각 고유한 사용처와 장단점을 갖기 때문에, 대규모 실행을 매끄럽게 돌리려면 이들을 적절한 비율로 조합해야 합니다. GLM-5 사례 연구에서는 세 가지를 모두 사용합니다.
완전 분할 데이터 병렬(Fully Sharded Data Parallel, FSDP): 기본이 되는 분산 전략입니다. 파라미터, 그래디언트, 옵티마이저 상태(optimizer state)를 데이터 병렬 랭크에 걸쳐 분할(shard)하고, 순전파와 역전파 동안 필요할 때만 모읍니다(gather). 1조 파라미터 이상의 모델에서는 전체 옵티마이저 상태나 파라미터의 메모리 발자국을 분산시키기 위해 필수적입니다. prime-rl은 PyTorch의 fully_shard(FSDP2)를 FSDP 구현으로 사용하는데, 이는 아래에서 다룰 다른 전략들과의 조합을 쉽게 만들어 줍니다.
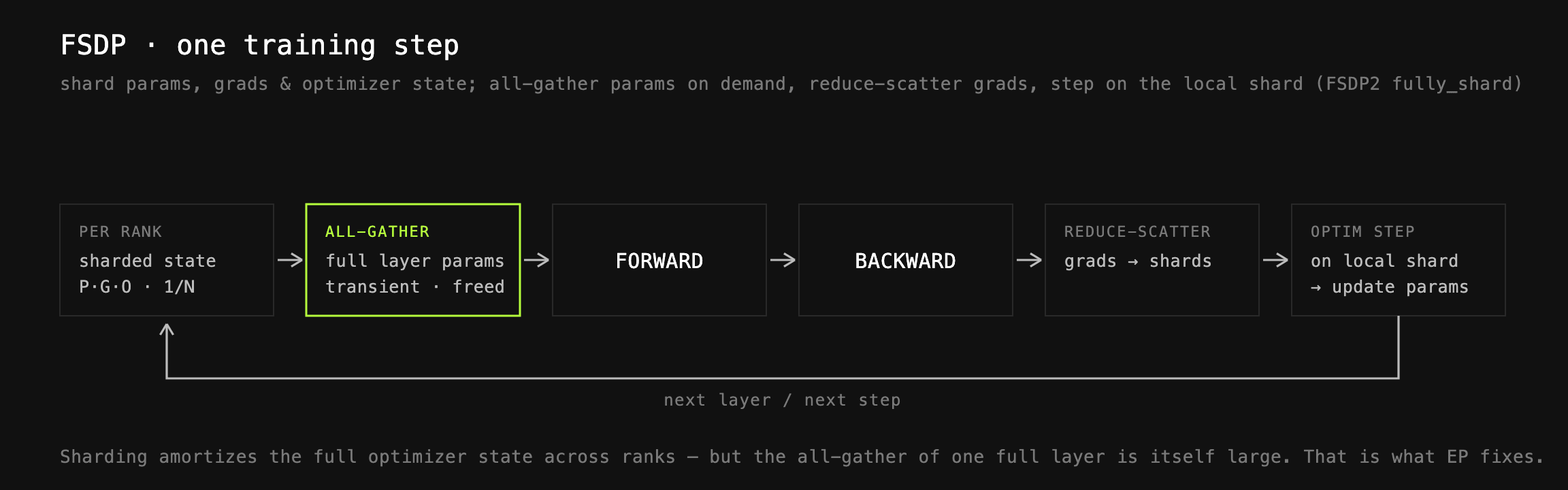
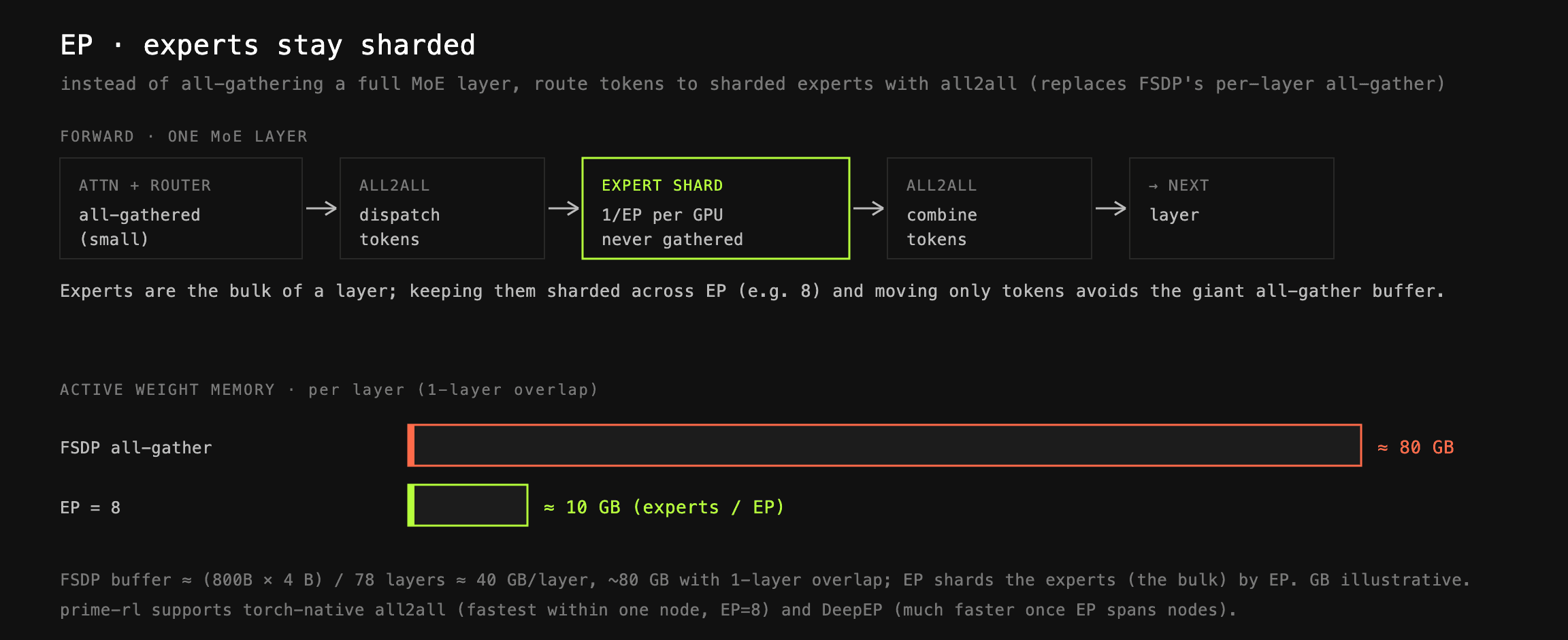
전문가 병렬화(Expert Parallelism, EP): FSDP를 적용해도 대형 모델 계층은 FSDP all-gather 이후 단일 GPU의 HBM에 담기에는 여전히 너무 큽니다. GLM-5는 78개 계층, 800B 파라미터를 갖는데, 마스터 가중치(master weight)를 float32로 두면 단일 계층 하나의 all-gather에 대략 다음과 같은 버퍼가 필요합니다.
여기에 FSDP가 한 계층을 미리 겹쳐 가져온다면, 활성 계층 가중치만으로 약 80GB의 메모리가 필요해집니다. 바로 이 지점에서 EP가 등장합니다. 전체 계층을 all-gather하는 대신, 별도의 내부 EP 차수(예: EP=8)를 두고 그 차원에서는 전문가를 모으지 않습니다. 대신 토큰을 all2all 프리미티브로 디스패치하고 컴바인합니다. 전문가가 계층 메모리 발자국의 대부분을 차지하므로, 이 방식은 활성 메모리를 크게 줄여줍니다.
prime-rl은 두 가지 EP 구성을 지원합니다. PyTorch 네이티브 all2all과 DeepEP입니다. 관찰에 따르면 단일 노드 EP 범위(예: EP=8)에서는 torch 네이티브가 약간 더 나은 처리량을 보이지만, EP가 노드를 가로지르면 처리량이 크게 떨어집니다. 이때는 DeepEP가 큰 차이로 더 빨라집니다.
컨텍스트 병렬화(Context Parallelism, CP): 131k 이상의 시퀀스 길이에서는 파라미터가 아니라 중간 활성값(intermediate activation)이 메모리 비용의 대부분을 차지합니다. 컨텍스트 병렬화는 시퀀스 차원을 랭크에 걸쳐 분할하여 GPU당 활성값을 줄입니다. prime-rl은 모든 커스텀 모델에 대해 컨텍스트 병렬화를 지원하며, 두 가지 방식을 제공합니다.
- 링 어텐션(Ring Attention): 배치가 모델 순전파 전체에 걸쳐 시퀀스 단위로 분할됩니다. 핵심 어텐션에 도달하면 각 랭크는 자신의 Q, K, V 샤드를 보유한 채, 다른 랭크의 K와 V를 링(ring) 형태로 주고받으며 처리합니다.
- 율리시스(Ulysses): 링 어텐션과 마찬가지로 데이터가 순전파 전체에서 시퀀스 길이로 분할됩니다. 어텐션에 도달하면 all2all 연산이 레이아웃을 시퀀스 분할에서 헤드(head) 분할로 뒤집고, 어텐션이 헤드 차원에 걸쳐 계산됩니다. 계산이 끝나면 또 한 번의 all2all로 레이아웃을 되돌립니다. 이 방식은 선형 어텐션(linear attention)이나 Mamba 같은 비표준 어텐션 대부분과 잘 맞아 prime-rl의 기본값입니다.
다만 예외가 있는데, GLM-5가 사용하는 DSA(DeepSeek Sparse Attention) 가 그렇습니다. 율리시스와 링 어텐션 모두로 병렬화할 수 없는 어텐션을 가진 모델에 대해서는, prime-rl은 커스텀 컨텍스트 병렬 구현을 직접 작성하며 GLM-5가 그 사례입니다. 이 구현은 시퀀스를 분할한 채로 투영(projection)을 계산하고, 그 뒤 K와 V를 모읍니다. K와 V는 잠재 공간(latent space)으로 투영되어 있어 이 수집은 저렴합니다. 이렇게 인덱서(indexer)가 전체 시퀀스를 볼 수 있게 하고, 전역 시퀀스에 대한 희소 인덱스를 계산한 뒤 그 인덱스 위에서 핵심 어텐션을 수행합니다. DSA는 고정된 top_k 를 갖기 때문에 이 비용도 고정됩니다(KV의 메모리 비용은 앞서 말했듯 무시할 수준입니다). 결과적으로 이 방식은 어텐션 계층당 단 한 번의 all-gather 집합 통신만으로 끝나, 비용을 최소로 유지합니다.
세 가지 컨텍스트 병렬화 방식을 정리하면 다음과 같습니다.
| 방식 | 분할 전략 | 어텐션 계산 방식 | 적합한 경우 |
|---|---|---|---|
| 링 어텐션(Ring Attention) | 순전파 전체에서 시퀀스 분할 유지 | 각 랭크가 자신의 Q, K, V 샤드를 갖고 다른 랭크의 K, V를 링 형태로 순환시키며 계산 | 표준 어텐션 |
| 율리시스(Ulysses) | 시퀀스 분할 후 어텐션 시점에 헤드 분할로 전환 | all2all로 레이아웃을 뒤집어 헤드 차원에서 어텐션 계산 (prime-rl 기본값) | 선형 어텐션, Mamba 등 비표준 어텐션 |
| 커스텀 CP (GLM-5 DSA) | 시퀀스 분할을 유지한 채 K, V만 수집 | 인덱서가 전역 희소 인덱스를 계산하고 어텐션 계층당 all-gather 1회로 처리 | 율리시스와 링으로 병렬화할 수 없는 DSA |
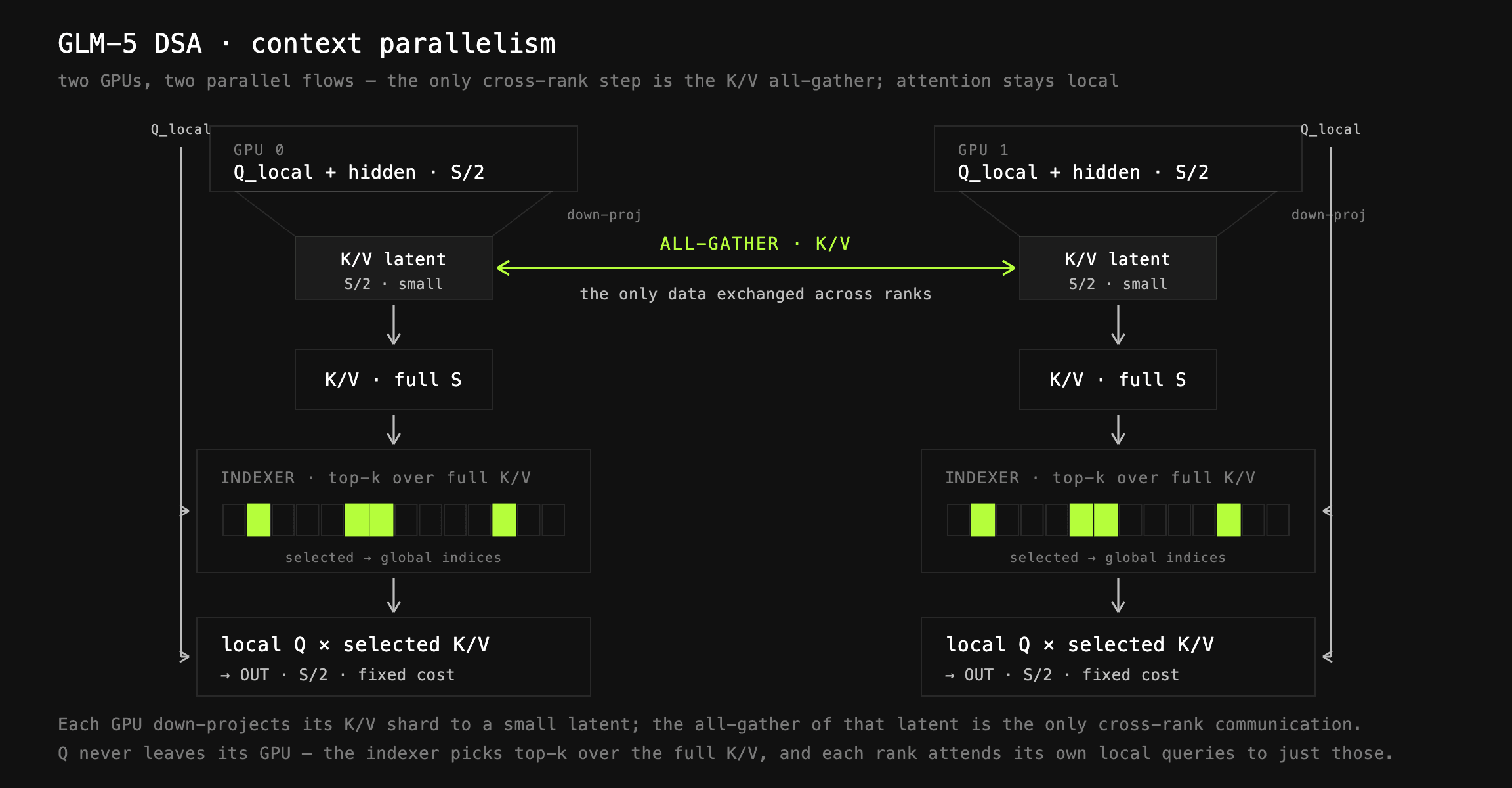
GLM-5의 DSA를 위한 커스텀 커널
DSA를 효율적으로 계산하기 위해, prime-rl은 참조 구현을 기반으로 자신들의 필요에 맞게 적응시킨 커스텀 커널을 사용합니다. 이 커널은 빠른 순전파와 역전파를 모두 제공합니다.
학습과 추론을 같은 정밀도로 묶는 FP8 학습
앞서 강조했듯, 학습기와 추론기의 불일치는 학습을 해칠 수 있습니다. 이를 막기 위해 prime-rl은 DeepGEMM 커널을 사용하여, DeepSeek V3가 제안한 블록 스케일(block-scaled) FP8을 수행합니다. 흔한 통념과 달리 이 방식은 양자화(quantization) 오버헤드 때문에 처리량을 크게 늘리지는 않습니다(특정 구성은 예외). 그러나 학습기와 추론기가 이제 같은 정밀도를, 경우에 따라서는 같은 커널까지 사용하게 되므로 둘 사이의 KL 불일치를 크게 줄입니다. 이것이 다시 더 안정적인 학습으로 이어집니다.
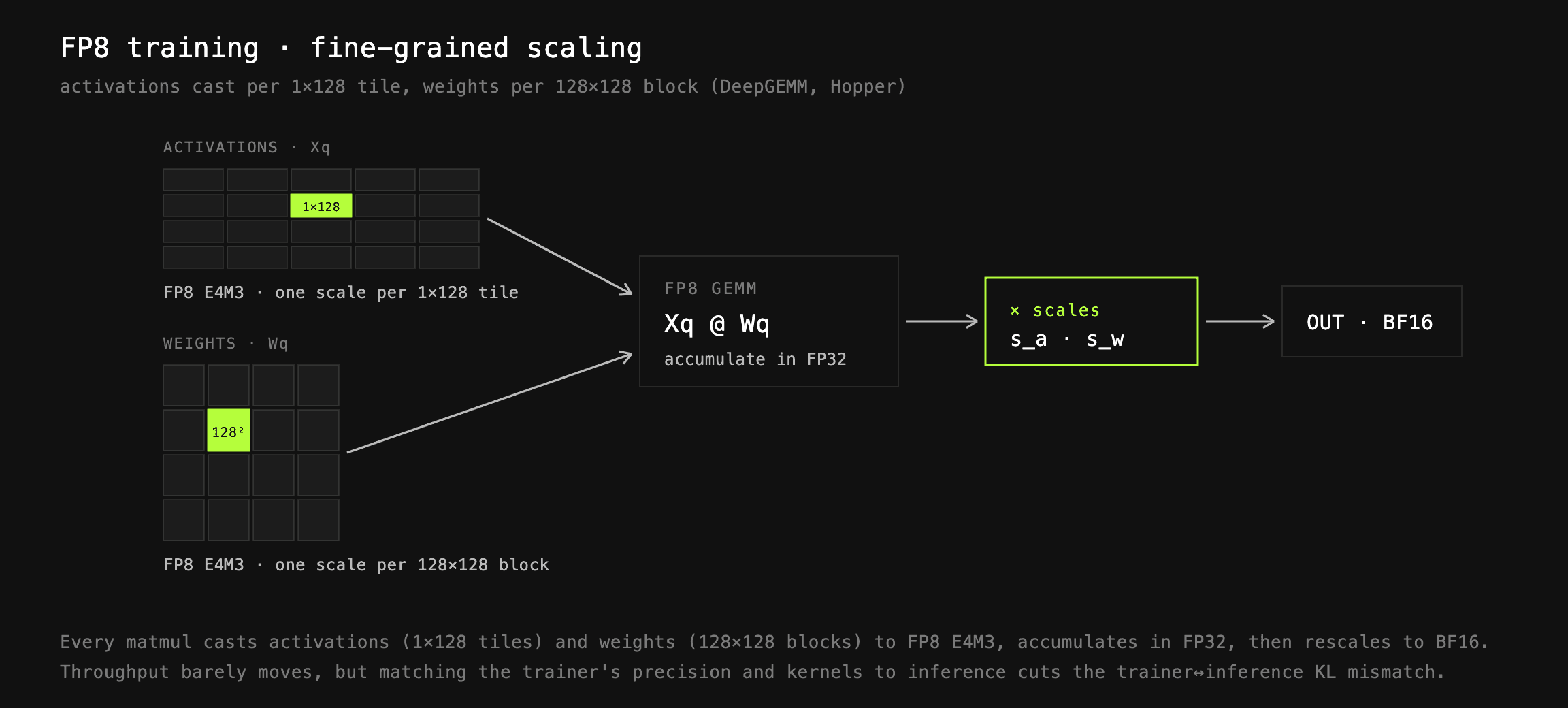
학습 최적화 더 알아보기
torchtitan: 대규모 학습을 위한 PyTorch 네이티브 코드베이스
PyTorch FSDP2 (fully_shard) 공식 문서
DeepSeek-V3 기술 보고서: 블록 스케일 FP8 학습 (arXiv 2412.19437)
향후 작업
Prime Intellect 팀은 RL 엔진의 성능을 더 끌어올릴 방법을 계속 탐색하고 있습니다. 추론 측면에서는 vLLM, Dynamo, llm-d와, 학습기 측면에서는 PyTorch와 적극적으로 협업하면서, 추측 디코딩(speculative decoding), NVFP4 학습 및 추론 같은 기법과 더불어 결함 내성(fault tolerance), 탄력적 확장(elastic scaling), 거대 모델의 1초 미만 학습기와 추론기 간 가중치 전송 같은 인프라 개선을 연구하고 있습니다.
이 모든 방향은 하나의 공통된 신념으로 수렴합니다. 대규모 에이전틱 RL에서는 규모가 커질수록 모든 오버헤드의 출처가 중요해진다는 것입니다. 실제로 효율적인 RL 스택을 만든다는 것은 학습과 추론에 그치지 않고, 요청 라우팅, 가중치 브로드캐스트(weight broadcasting), 진행 중 가중치 업데이트(in-flight weight updates), 환경(environment), 코드 실행 샌드박스 등 폭넓은 구성 요소를 개별적으로도, 또 하나의 응집된 시스템으로도 함께 최적화해야 하는 과제입니다. 성공은 이 시스템들이 어떻게 상호작용하는지를 이해하고, 병목을 찾아내며, 스택 전체에 걸쳐 끈질기게 효율을 밀어붙이는 데서 나옵니다.
결론: 효율이 곧 경쟁력인 대규모 RL
prime-rl 0.6.0이 보여주는 것은, 1조 파라미터 규모의 에이전틱 강화학습이 더 이상 소수의 거대 연구소만의 전유물이 아니라는 점입니다. 비동기 RL이라는 설계 철학 위에, FP8 추론과 학습, 와이드 전문가 병렬화, 프리필과 디코드 분리, 라우터 리플레이, 3차원 병렬화 같은 최적화를 하나의 일관된 시스템으로 엮음으로써, 28개 H200 노드라는 비교적 현실적인 자원으로도 GLM-5급 모델을 SWE 과제에서 학습할 수 있게 되었습니다.
특히 주목할 점은, 이 스택이 PyTorch와 torchtitan이라는 오픈소스 학습 생태계와 vLLM, Dynamo 같은 추론 생태계를 적극적으로 끌어와 결합하고, 그 개선을 다시 커뮤니티로 환원하는 방식으로 만들어졌다는 것입니다. 대규모 RL이 점점 더 프런티어 모델의 핵심 동력이 되는 흐름 속에서, prime-rl처럼 학습과 추론 양쪽의 비효율을 끝까지 짜내는 오픈소스 스택은 오픈소스 모델의 사후 학습 경쟁력을 결정짓는 중요한 한 축이 될 것으로 보입니다. RL 학습 프레임워크의 더 넓은 지형이 궁금하다면 LLM을 위한 강화학습을 민주화하려는 rLLM 프로젝트나 Open-AgentRL 같은 사례도 함께 살펴보시기를 권합니다.
 RL at 1T Scale 소개 블로그
RL at 1T Scale 소개 블로그
 prime-rl GitHub 저장소
prime-rl GitHub 저장소
더 읽어보기
-
MAI-Thinking-1 기술 보고서: 데이터 파이프라인부터 RL 인프라까지, 프런티어 모델 학습의 전 과정을 해부한 '힐 클라이밍 머신' (feat. Microsoft AI)
-
Open-AgentRL: LLM 에이전트 강화를 위한 통합 오픈소스 프레임워크 (feat. RLAnything & DemyAgent)
-
DeepSeek-R1, 지도학습 기반 파인튜닝(SFT) 대신, 강화학습(RL)으로 추론 능력을 개선하여 추론 능력을 강화한 대규모 언어 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()