Agentic Researcher: 수학 및 머신러닝 분야에서 인공지능 도구들을 활용하는 현실적인 연구 방법 논문 소개
The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning

Agentic Researcher 연구 개요
연구 소개 및 연구 배경
2024년은 인공지능이 수학적 추론과 과학적 발견의 영역에서 괄목할 만한 성과를 거둔 한 해였습니다. DeepMind의 AlphaProof와 AlphaGeometry는 국제 수학 올림피아드(IMO)에서 은메달 수준의 성과를 달성하며 강화학습과 형식 검증(formal verification)의 결합이 지닌 잠재력을 입증했습니다. 또한, 대형 언어 모델(LLM)이 주도하는 진화적 탐색 기법인 AlphaEvolve는 다양한 문제에서 기존의 최적 해를 재발견하거나 개선하는 등 새로운 수학적 구조를 찾아내는 데 성공했습니다.
최근에는 Aletheia라는 자율적 수학 연구 에이전트가 최소한의 인간 개입만으로 과거에 제기된 미해결 문제들을 성공적으로 해결하는 성과를 보여주기도 했습니다. 머신러닝 커뮤니티 역시 에이전트 기반의 실험이 활발히 진행되고 있으며, Andrej Karpathy의 autoresearch와 같이 에이전트가 코드 수정을 반복하며 머신러닝 실험 파이프라인을 자동화하는 사례가 점차 일반화되고 있습니다.
이처럼 AI 시스템의 성과에 대한 문헌은 급증하고 있지만, 연구자들이 이러한 최첨단 시스템을 일상적인 연구에 '어떻게' 통합해야 하는지에 대한 실용적인 논의는 상대적으로 부족한 실정입니다. Agentic Researcher 연구는 이러한 간극을 메우기 위해 작성되었으며, 복잡하고 유동적인 실제 연구 환경에서 AI를 효과적으로 다루기 위한 구체적인 방법론을 제시하고 있다는 점에서 의의를 가집니다.
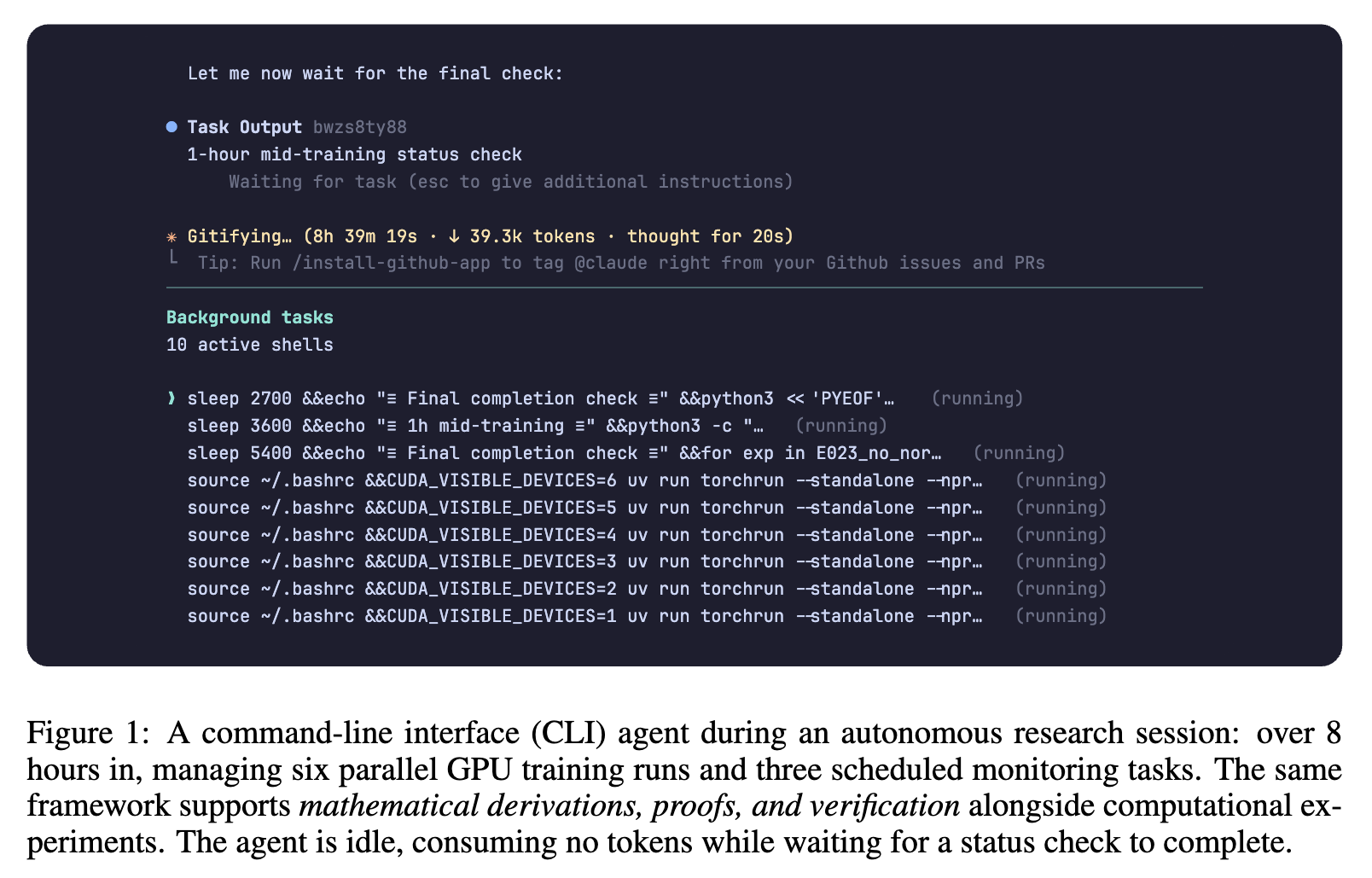
위 그림은 자율 연구 세션 중인 명령줄 인터페이스(CLI) 에이전트의 모습을 보여주는데, 이 에이전트는 8시간 이상 구동되며 6개의 병렬 GPU 훈련 실행과 3개의 예약된 모니터링 작업을 관리하고 있으며, 대기 중에는 토큰을 소모하지 않는 유휴 상태를 유지하는 등 효율적인 작업 관리가 가능함을 보여줍니다.
능동적인 기술 수용의 필요성
대부분의 연구자들에게 현재 직면한 과제는 처음부터 새로운 AI 발견 파이프라인을 직접 구축하는 것이 아니라, 이미 존재하는 다양한 도구들 중 적절한 것을 선택하고 효과적으로 사용하는 방법을 이해하는 것입니다. 기존 문헌들도 인간과 AI의 공동 창의성에 대한 개념적 프레임워크나 형식 증명 보조 도구 등에 대해 논의하기 시작했지만, 오늘날의 연구자가 즉시 적용할 수 있는 포괄적인(End-to-End) 가이드를 제공하는 연구는 찾아보기 어려웠습니다.
Agentic Researcher의 저자들은 수학자들과 연구자들이 단순히 AI의 발전에 수동적으로 반응하는 것에 그치지 않고, 자신들의 목적에 맞게 AI를 배치하고 그 형태를 형성하는 데 있어 주도적인 역할을 수행해야 한다는 점을 강조하고 있습니다. 즉, 우리는 기술의 발전 방향에 끌려가는 것이 아니라 기술을 소유하고 통제해야 한다는 것입니다.
이 논문에서 제시하는 프레임워크는 연구자가 주도권을 잃지 않으면서도 작업의 규모와 속도를 향상시킬 수 있도록 돕습니다. 연구 방향을 설정하고, 초기 직관을 제공하며, 예상치 못한 결과가 나왔을 때 가설을 수정하는 등의 핵심적인 지적 작업은 여전히 인간 연구자의 몫으로 남습니다. AI는 이러한 인간의 지휘 아래에서 수학적 파생, 증명, 검증, 그리고 대규모 연산 실험을 지속적으로 수행하는 조력자 역할을 하게 됩니다. 이러한 능동적이고 구조화된 접근 방식은 다가오는 AI 시대에 연구자들이 갖춰야 할 필수적인 소양이며, 저자들이 다양한 코딩 에이전트 활용 경험을 통합하여 이 실용적인 프레임워크를 개발하게 된 동기이기도 합니다.
수학 및 머신러닝 연구에서의 AI 통합 5단계 (Practical Taxonomy)
저자들은 인공지능 도구들을 통합하는 단계를 5가지로 정리하였습니다. 여기서 제시되는 다섯 가지 단계는 상호 배타적인 것이 아니며, 한 명의 연구자가 동일한 프로젝트를 진행하는 과정 속에서도 작업의 특성과 난이도에 따라 서로 다른 통합 단계를 유연하게 취사선택하여 활용할 수 있습니다. 예를 들어, 고도로 자율적인 시스템을 운영하는 중에도 특정 하위 작업은 덜 자율적인 구성 요소나 인간의 직접적인 개입에 위임될 수 있으며, 이러한 유연성은 성공적인 연구 수행의 핵심입니다.
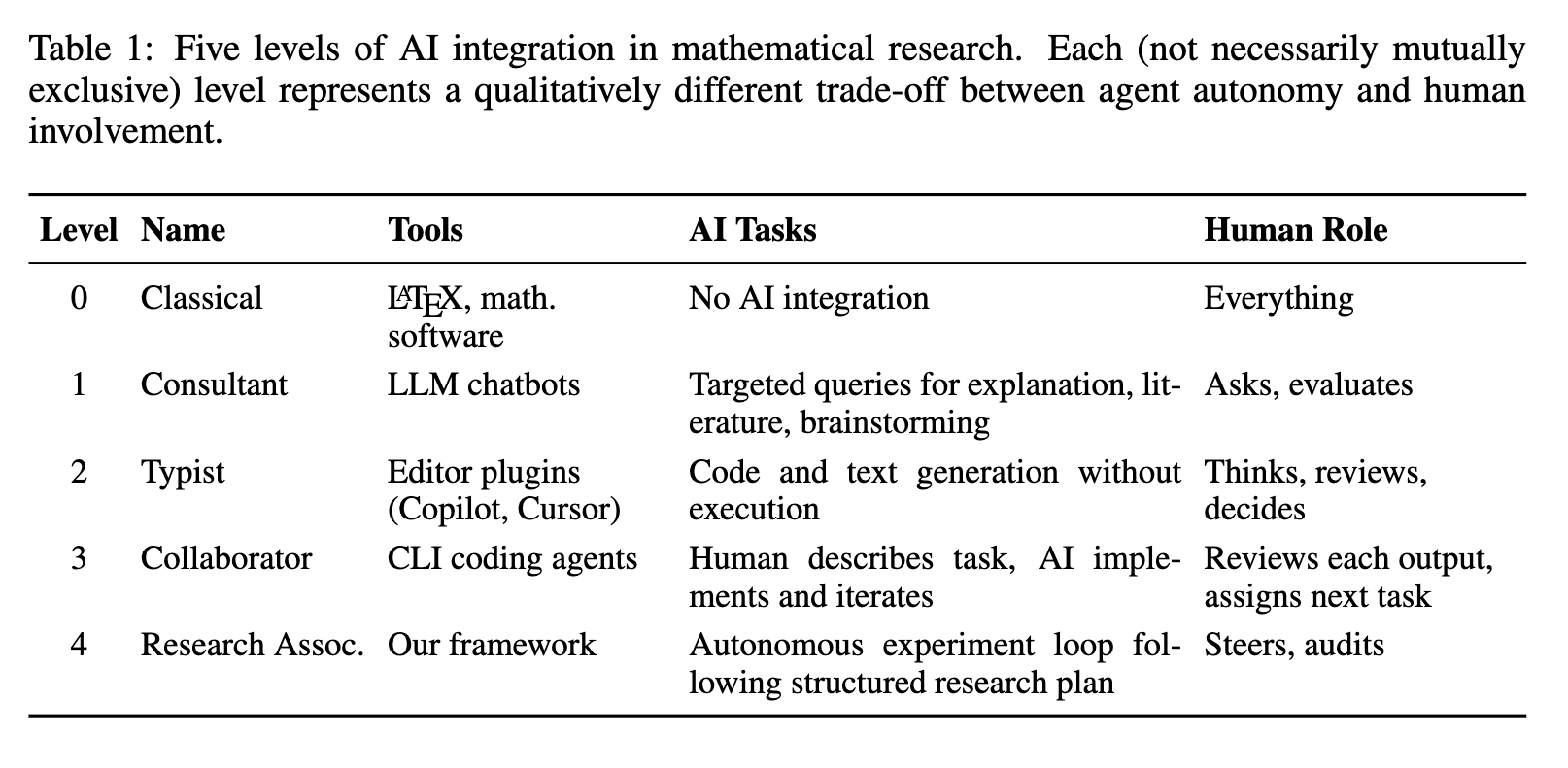
Level 0: 고전적 단계 (Classical)
분류 체계의 가장 기초이자 출발점이 되는 레벨 0(Level 0)은 고전적(Classical) 단계로 명명되며, 이는 인공지능의 지원이나 개입이 없는 전통적인 형태의 수학 및 머신러닝 연구 방식을 의미합니다. 이 단계에서 연구자는 논문 작성을 위한 조판 소프트웨어인 레이텍(LaTeX)을 비롯하여, 복잡한 수식 연산을 돕는 매스매티카(Mathematica)나 매트랩(MATLAB), 그리고 맞춤형 알고리즘 구현과 실험을 위해 널리 쓰이는 파이썬(Python), 줄리아(Julia), 파이토치(PyTorch) 등의 프로그래밍 언어와 같은 전산 도구에 의존하여 연구를 진행하게 됩니다.
저자들은 이 레벨 0 단계가 현대 연구에 있어서 가장 보편적인 방식이며, 그 자체로 적절한 연구 방법론이라는 사실을 강조하고 있습니다. 다시 말해, Agentic Researcher 연구가 제안하는 프레임워크의 목표는 최첨단 인공지능 기술을 동원하여 전통적인 연구 방식을 완전히 대체하려는 것이 아니라, 인공지능 도구가 어느 단계에서 어떠한 구체적인 방식을 통해 연구자의 기존 방법론을 보완하고 효율성을 높일 수 있는지를 보여주기 위한 기준선을 설정하는 작업으로 이해할 수 있습니다.
따라서 레벨 0을 배제할 대상이 아니라, 향후 설명될 더 높은 수준의 인공지능 통합 단계들이 고전적 방식과 비교하여 어떠한 질적, 양적 차이를 만들어내는지를 평가하는 척도로 삼아야 할 것입니다.
Level 1: 컨설턴트로서의 인공지능 (AI as Consultant)
고전적인 방식을 넘어 인공지능이 연구 과정에 본격적으로 도입되기 시작하는 첫 번째 단계는 컨설턴트로서의 인공지능(AI as Consultant)을 활용하는 단계입니다. 이 단계에서 연구자는 오픈에이아이(OpenAI)의 챗지피티(ChatGPT), 앤스로픽(Anthropic)의 클로드(Claude), 구글(Google)의 제미나이(Gemini)와 같은 대규모 언어 모델(Large Language Model, LLM) 기반의 챗봇을 활용하여 특정 질문을 던지고 필요한 지원을 받게 됩니다. 예를 들면, 선형 계획법에서 강한 쌍대성과 약한 쌍대성의 차이점을 설명해 달라고 요청하거나, 확률적 경사 하강법(Stochastic Gradient Descent, SGD)의 최신 수렴 속도에 대한 문헌을 검색해 달라고 지시하는 등 개념 설명과 문헌 검색에 유용하게 쓰입니다.
또한, 새로운 증명 기법을 위한 아이디어 브레인스토밍을 진행하거나 자신이 시도한 증명의 논리적 오류 디버깅을 요청하는 작업 등에서도 대규모 언어 모델(LLM)은 조언자 역할을 수행합니다. 하지만 이 단계에서는 연구의 핵심적인 지적 작업과 책임이 전적으로 연구자에게 있으며, 인공지능은 표적화된 조언과 정보만을 제공합니다. 여기서 연구자에게 요구되는 핵심 기술은 인공지능이 유용한 답변을 도출할 수 있도록 명확한 질문을 던지고 상세한 프롬프트를 작성하는 능력입니다. 한편, 사용자가 맥락을 수동으로 제공하지 않는 한 세션 간의 상호작용이 무상태(stateless)로 유지된다는 점은 레벨 1의 한계로 지적됩니다.
Level 2: 타이피스트로서의 인공지능 (AI as Typist)
타이피스트로서의 인공지능(AI as Typist)을 활용하는 단계는 연구자가 깃허브 코파일럿(GitHub Copilot)이나 커서(Cursor)와 같은 코드 편집기 플러그인을 활용하여 코드와 텍스트 생성을 보조받는 단계입니다. 이 단계의 특징은 인공지능이 탭 자동 완성 기능부터 자연어 설명을 바탕으로 전체 함수나 레이텍(LaTeX) 단락을 생성하는 등 작성 과정을 가속화하지만, 생성된 코드를 스스로 실행하거나 그 결과를 바탕으로 반복(iterate)하는 작업은 수행하지 않는다는 점입니다.
인공지능이 생성한 모든 결과물은 반드시 인간 연구자의 검토를 거쳐야 하며, 연구자의 판단에 따라 수락, 편집 또는 거부됩니다. 결과적으로 레벨 2에서의 인공지능은 구현과 평가 사이의 루프(loop)를 닫아주지 못하며, 아키텍처나 실험 방향에 대한 설계 결정의 책임은 여전히 인간 연구자에게 남아있게 됩니다.
Level 3: 협력자로서의 인공지능 (AI as Collaborator)
레벨 3은 인공지능을 보조 도구를 넘어, 실질적인 실행 능력을 갖춘 협력자로서 활용하는 단계입니다. 이 단계에서 연구자는 전체 구현과 실행 과정을 클로드 코드(Claude Code), 오픈코드(OpenCode), 코덱스(Codex CLI)와 같은 명령줄 인터페이스(Command Line Interface, CLI) 기반의 코딩 에이전트에게 위임합니다.
영구적인 프로젝트 컨텍스트 내에서 작동하는 이 에이전트들은 스스로 파일을 읽고 편집할 수 있으며, 쉘 명령을 직접 실행하고, 실행 결과를 바탕으로 단일 대화 내에서 코드를 수정하고 반복(iterate)하는 등 광범위한 작업을 수행할 수 있습니다.
연구자가 자연어로 "선형 웜업(linear warmup)이 포함된 학습률 스케줄러를 구현하라"고 지시하면, 에이전트는 코드베이스를 읽고 알고리즘을 구현하며 실행 후 예기치 않은 동작이 발생하면 재평가까지 진행합니다. 그러나 각 작업이 완료된 후 연구자가 출력물을 검토하고 다음 작업을 결정하여 할당해야만 에이전트가 다음 단계로 나아간다는 점에서, 에이전트는 주어진 작업을 '어떻게' 수행할지는 알지만 독자적으로 연구 방향을 설정하지는 못하는 한계가 존재합니다.
Level 4: 연구 조수로서의 인공지능 (AI as Research Associate)
마지막 단계는 인공지능이 연구 조수로 동작하는 단계로, 높은 수준의 자율성을 가지게 됩니다. 연구자가 문제 공식화, 가설, 평가 기준 등 고차원적인 연구 계획의 윤곽을 제시하면, 에이전트는 상세한 계획을 수립하고 수학적 아이디어의 공식화부터 접근법 구현, 평가 실행, 결과 기록, 그리고 report.tex나 TODO.md 파일의 지속적인 업데이트 등, 전체적인 실험 루프를 자율적으로 실행합니다.
이전 레벨 3과의 결정적인 차이는 에이전트가 실험 중간마다 인간의 입력을 수동적으로 기다리지 않고, 과학적 엄밀성과 체계적인 문서화 관행을 담은 십계명(Ten Commandments) 규칙에 따라 자율적으로 루프를 반복하며 작업을 지속한다는 점입니다.
이 단계에서 인간 연구자의 역할은 직접적인 코딩이나 실행에서 벗어나, 에이전트가 작성한 보고서를 주기적으로 검사하고, 우선순위를 조정하며, 연구 계획을 다듬는 등 방향 설정 및 평가 감독관으로 그 지위가 전환됩니다. 물론 에이전트가 비효율적인 방향으로 장시간 진행되거나 최신 문헌의 독창성을 확보하지 못하는 등의 한계가 존재할 수 있으며, 이를 교정하고 생성된 수학적 주장이나 코드의 정확성을 최종적으로 검증하는 것은 책임 연구원(Principal Investigator)의 주요 역할로 남습니다.
이처럼 레벨 4의 프레임워크는 연구자가 모든 과정을 홀로 수행하는 대신 유능한 인공지능 연구 조수에게 실행 작업을 위임하고, 제출된 구조화된 보고서를 바탕으로 인간과 인공지능이 상호작용하는 구조를 띱니다. 이러한 방식은 탐색 공간이 방대한 문제에 적합한 접근 방식이며, 새로운 결과를 도출해 내는 공동 창조(Co-creation) 프로세스로 기능할 수 있습니다.
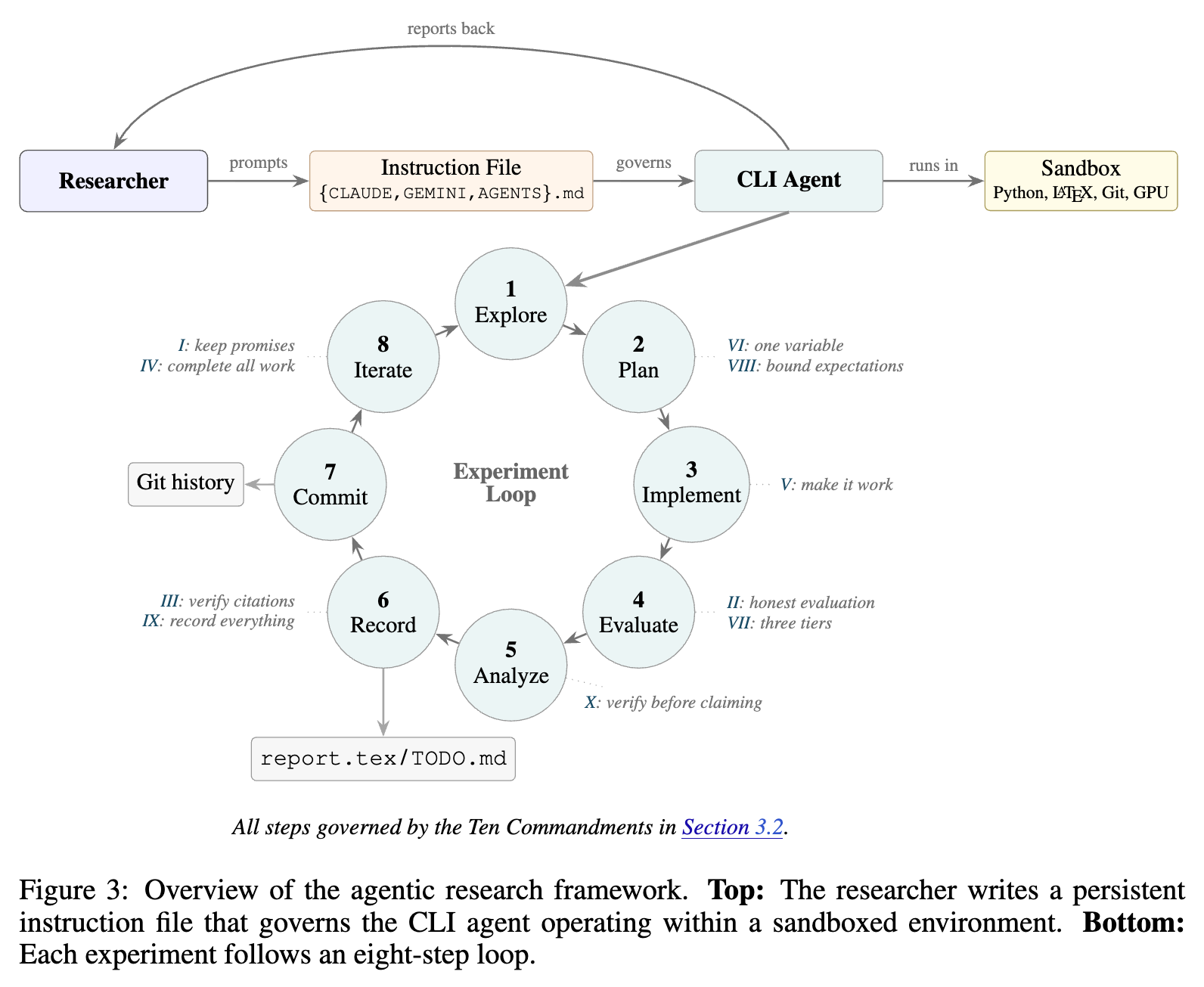
에이전트 기반 연구 프레임워크 (The Agentic Research Framework)
저자들은 Agentic Researcher 연구의 핵심 기여인 에이전트 기반 연구 프레임워크(Agentic Research Framework)와 디자인 철학, 십계명 등을 함께 공개하였습니다.
프레임워크의 구조 및 작업 흐름 (Workflow)
에이전트 기반 연구 프레임워크(Agentic Research Framework)는 Codex, Claude Code, Gemini CLI 등과 같은 범용 CLI 코딩 에이전트들을 샌드박스화된 안전한 환경에서 실행하며, 명확한 규칙을 통해 과학적 연구를 수행하도록 설계되었습니다. 새로운 프로젝트를 시작할 때 연구자는 3가지 필수적인 핵심 입력 요소들을 준비해야 합니다.
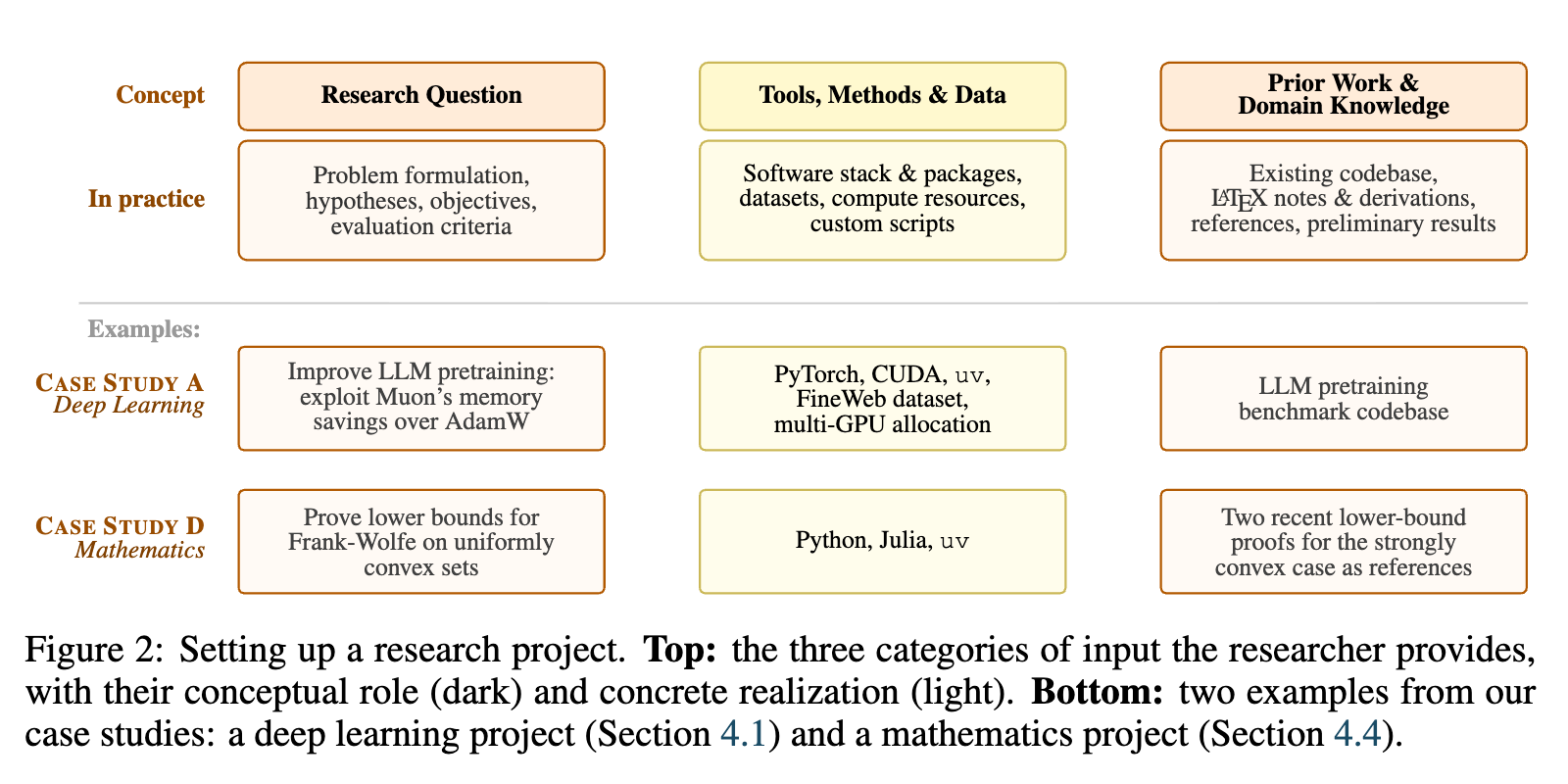
첫 번째 필수 입력 요소는 구체적인 연구 질문(Research Question) 으로, 해결하고자 하는 문제의 공식화(Problem Formulation), 연구를 이끌어갈 가설(Hypotheses), 그리고 성공 여부를 판단할 평가 기준(Evaluation) 등을 포함해야 합니다.
두 번째 필수 입력 요소는 도구, 방법 및 데이터(Tools, Methods & Data) 입니다. 여기에는 파이썬(Python), 파이토치(PyTorch), 줄리아(Julia)와 같은 프로그래밍 언어 및 소프트웨어 스택(Software Stack), 필수적인 패키지, 실험에 활용할 데이터셋(Dataset), 분석을 위한 맞춤형 스크립트, 그리고 연산 자원에 대한 세부 정보 등이 포괄적으로 포함되어야 합니다.
마지막 세 번째 필수 입력 요소는 에이전트가 탐색의 기반을 마련할 수 있도록 제공하는 사전 연구 및 도메인 지식(Prior Work & Domain Knowledge) 입니다. 연구자는 기존에 작성된 소스 코드베이스(Codebase), 수식 유도 과정이 담긴 레이텍(LaTeX) 노트, 관련 논문 참조 문헌, 그리고 사전 실험 결과 등을 에이전트에게 제공해야 합니다.
이러한 필수 입력 요소들의 준비가 완료되면, 연구자는 프로젝트 디렉토리 내부에서 격리된 샌드박스(Sandbox) 환경을 실행하고 지시사항들을 에이전트에게 자연어로 전달하게 됩니다. 지시사항을 전달받은 에이전트는 바로 코드를 작성하기보다, 연구의 범위나 제약 조건, 평가 지표에 대해 스스로 명확히 이해하기 위해 질문들을 던지며 연구자와 구체적인 상호작용을 시작합니다.
충분한 문답이 오간 후, 에이전트는 프로젝트 내의 관련 파일을 탐색하고 INSTRUCTIONS.md라는 영구적인 지시사항 파일에 프로젝트 특화 지침과 프레임워크의 보편적인 규칙들을 함께 기록하여 행동 지침을 확립합니다. 이후 향후 연구 진행 과정을 누적하여 기록할 핵심 문서인 report.tex 파일과 남은 작업 및 미해결 질문을 추적할 TODO.md 파일을 초기화한 뒤 전체적인 실험 계획을 수립합니다.
연구자가 이렇게 구성된 초기 계획을 최종적으로 승인하거나 수정을 통해 다듬어 주면, 에이전트는 시스템의 예외적인 행동이나 전면적인 방향 전환이 필요한 경우를 제외하고는 인간의 직접적인 개입 없이 완전한 자율 실행 모드에 돌입하여 독립적으로 연구 루프를 수행하게 됩니다.
저자들이 다양한 인공지능 인터페이스 중에서도 명령줄 인터페이스(Command Line Interface, CLI) 기반의 코딩 에이전트를 프레임워크의 핵심 시스템으로 채택한 이유는 실제 연구 환경에서 요구되는 실용적인 장점 때문입니다:
-
Claude Code, Codex, Gemini CLI, OpenCode 등의 에이전트들은 사용이 간편하여 로컬 작업 환경에 자연스럽게 통합되고, 복잡한 클라우드 인프라 구축 없이 기존 프로젝트 디렉토리 내에서 즉시 실행되어 파일들을 다루고 수정할 수 있습니다.
-
이러한 도구들은 상호작용성을 유지하기 때문에 연구자가 실험 진행 중 언제든 개입하여 진행 상황을 점검하거나, 탐구 방향을 수정하고, 실행을 중단 후 새로운 지시사항으로 재시작하는 유연한 제어가 가능합니다.
-
마지막으로 CLI 기반 에이전트들은 확장성이 뛰어나, 문헌 처리나 수학적 소스 관리, 알고리즘 섹션 자동 추출, 전문화된 검색 및 검증 루틴 실행 등을 위한 맞춤형 유틸리티 스크립트를 기존 도구 체인에 쉽게 추가하고 연동할 수 있습니다.
또한, 연구자들은 Agentic Research Framework에 별도의 복잡한 실험 추적 시스템을 도입하는 대신, 소프트웨어 엔지니어링에서 널리 쓰이는 버전 관리 시스템인 Git을 직접 활용하는 효율적이고 경량화된 방식을 채택했습니다.
각 실험 결과는 exp (EXXX): <description> <metric>=<value> 와 같은 정형화된 커밋(Commit) 메시지 형태로 저장되며, 관련된 실험 흐름들은 브랜치(Branch)로 묶이고 중요한 마일스톤은 태그(Tag)로 표시됩니다.
이러한 방식은 전체 실험 이력을 적은 자원으로 이식성 있게 유지할 수 있도록 도우며, 별도의 도구를 학습할 필요 없이 Git log를 통해 특정 실험 결과나 분기점을 즉각적으로 검색할 수 있게 해 줍니다.
본격적인 실행 단계에 오른 에이전트는 탐색(Explore) -> 계획(Plan) -> 구현(Implement) -> 평가(Evaluate) -> 분석(Analyze) -> 기록(Record) -> 커밋(Commit) -> 반복(Iterate)이라는 8단계의 실험 루프를 반복하며 연구를 점진적으로 발전시켜 나갑니다. 새로운 세션이 시작될 때마다, 혹은 모델의 컨텍스트 윈도우(Context Window)가 초기화될 때마다, 에이전트는 report.tex, TODO.md 및 Git Log의 이전 실험 기록을 다시 읽어 들여 작업의 연속성과 맥락을 복원한 채 실험을 재개합니다.
과학적 엄밀성을 위한 에이전트 십계명 (The Ten Commandments)
고도의 자율성을 지닌 프레임워크가 장시간 구동되면서 통제를 벗어나거나 편향된 결론을 도출하는 것을 방지하기 위해, Agentic Researcher 저자들은 시행착오와 실패 경험을 분석하여 도메인에 구애받지 않는 보편적인 행동 규범인 십계명(The Ten Commandments)을 도출하고 시스템의 지침으로 삼았습니다. 이 규칙을 제정하기 위해 다음과 같은 3가지 설계 원칙을 적용했습니다:
-
대규모 언어 모델(LLM)은 암묵적인 기대를 위반할 가능성이 높으므로, 모든 중요한 행동 강령을 명시적으로 지시해야 한다는 암묵성보다 명시성 우선(explicit over implicit) 원칙입니다.
-
추상적인 목표보다는 인간 연구자와 인공지능 에이전트 모두가 해당 규칙의 준수 여부를 객관적인 지표로 판별할 수 있도록 지침을 구체화해야 한다는 야심찬 목표보다 반증 가능성 우선(falsifiable over aspirational) 원칙입니다.
-
이론적으로 바람직한 규칙보다는 실제 연구 현장에서 빈번하게 발생하는 실패 사례들을 방지하는 데 초점을 맞추어야 한다는 이론 주도보다 실패 주도 우선(failure-driven over theory-driven) 원칙입니다.
이렇게 작성된 십계명은 4가지 범주로 구성되어 있습니다. 각 범주별 규칙들은 다음과 같습니다:
-
범주 1. 무결성과 신뢰(Integrity and Trust): 에이전트가 연구 파트너로서 갖춰야 할 기본적인 윤리와 학문적 신뢰성을 다룹니다.
-
I. 절대 약속을 어기지 말 것 - Never Break a Promise: 계획된 작업은 임의로 누락하지 않고 끝까지 완수해야 합니다.
-
II. 절대 평가를 조작하지 말 것 - Never Manipulate Evaluation: 연구 목표를 달성한 것처럼 보이기 위해 측정 지표(Metric), 테스트 데이터셋, 고정된 하이퍼파라미터(Hyperparameter), 혹은 문제의 정의를 임의로 변경해서는 안 됩니다.
-
III. 절대 인용을 날조하지 말 것 - Never Fabricate Citations: 생성형 인공지능(GenAI)의 주요 한계점인 환각(Hallucination) 현상을 차단하기 위해, 보고서에 기재되는 문헌은 모델의 기억에만 의존하지 않고 웹 검색(Web Search)을 통해 논문의 제목, 저자, 출판 연도, 학술지 등 출처 정보를 대조하여 검증해야 합니다.
-
-
범주 2. 자율성과 효율성(Autonomy and Efficiency): 에이전트가 세션 내에서 작업 효율성을 유지하고 불필요한 의사결정 지연을 방지하기 위한 규칙입니다.
-
IV. 보고하기 전에 모든 자율 작업을 완료할 것 - Complete All Autonomous Work Before Reporting: 사용자의 개입이 필요 없는 독립적인 작업의 경우, 자체적인 판단으로 건너뛰지 말고 할당된 실험을 모두 완료한 후 결과를 종합하여 보고해야 합니다.
-
V. 다음으로 넘어가기 전에 작동하게 만들 것 - Make It Work Before Moving On: 코드 실행 중 에러가 발생했을 때 해당 아이디어를 근본적인 오류로 단정하여 폐기하는 대신, 디버깅을 통해 원인을 파악하고 코드를 수정하여 재실행해야 합니다.
-
-
범주 3. 과학적 엄밀성(Scientific Rigor): 자율적으로 진행되는 실험의 질적 가치와 통계적 신뢰성을 보장하기 위한 프레임워크의 핵심적인 규칙들입니다.
-
VI. 실험당 하나의 변수만 변경할 것 - One Variable per Experiment: 독립된 실험에서는 단 하나의 변수만을 통제하여 변경해야 하며, 두 가지 이상의 변수를 동시에 변경하여 결과가 개선될 경우 원인을 파악하기 어려워지는 오류를 방지해야 합니다.
-
VII. 단계별로 평가할 것 - Evaluate in Tiers: 평가 과정은 체계적으로 진행되어야 합니다. 코드가 정상적으로 실행되는지 확인하는 '1단계', 작은 하위 데이터셋에서 유의미한 성능 개선이 있는지 확인하는 '2단계', 논문이나 보고서에 기록될 성능 지표를 측정하는 전체 평가인 '3단계'로 엄격히 나누어 수행해야 하며, 초기 소규모 실행 결과만으로 전체 알고리즘의 성능을 결론지어서는 안 됩니다.
-
VIII. 기대치의 한계를 설정할 것 - Bound Your Expectations: 새로운 휴리스틱(Heuristic) 알고리즘을 구현하기 전에는, 이론적으로 도달할 수 있는 최상의 경우(Theoretical Best Case)를 먼저 식별함으로써 관찰된 수치적 개선이 한계치에 얼마나 근접한 것인지 객관적으로 평가할 수 있어야 합니다.
-
-
범주 4. 문서화 및 재현성(Documentation and Reproducibility): 연구 프로젝트의 지속 가능성을 확보하고, 모델의 단기 기억 한계로 인해 실험 기록이 유실되는 것을 방지하기 위한 규칙들입니다.
-
IX. 모든 것을 기록할 것 - Record Everything: 에이전트는 성공적인 결과뿐만 아니라 실패한 실험 결과도 포함하여 목표, 가설, 방법론, 수치 표, 분석, 향후 계획 등을
report.tex파일에 상세히 기록해야 합니다. 또한 데이터 분포나 비교 분석 등을 명확히 보여주는 시각화 자료를 생성하고, 미해결 질문과 검증되지 않은 주장들은TODO.md파일에 지속적으로 업데이트해야 합니다. -
X. 주장하기 전에 검증할 것 - Verify Before Claiming: 에이전트는 자신이 도출한 주장을 비판적인 시각에서 검증해야 합니다. 적극적으로 반례(Counterexample)를 찾거나 입력 데이터를 무작위화하여 한계 상황을 테스트하는 수치 검증 스크립트를 작성해야 하며, 자체 검증 시도를 통과한 후에만 그 결과를 보고서에 반영할 수 있습니다.
-
연구 도메인별 맞춤형 특화 계명 (Domain-Specific Commandments)
보편적인 10가지 규칙 외에도, Agentic Research Framework는 개별 연구 도메인이 가진 특수한 요구사항을 반영하기 위해 도메인 특화 계명(Domain-Specific Commandments)을 추가하여 시스템의 실효성을 높입니다.
예를 들어, GPU 연산을 적극 활용하는 연산 집약적 연구(Compute-Intensive Research) 도메인에서는 각각의 실험을 개별 GPU에 할당하여 자원의 효율을 높이고, 긴 실행 로그가 에이전트의 컨텍스트 윈도우(Context Window)를 과도하게 점유하는 것을 막기 위해 터미널 출력을 별도의 로그 파일로 리디렉션해야 합니다. 또한, 메모리 부족(OOM) 에러가 발생했을 때 GPU 캐시를 비우는 등 체계적으로 메모리를 관리하는 절차가 포함됩니다.
반면, 논리 전개와 수식 증명이 중심이 되는 수학적 연구(Mathematical Research) 도메인에서는 코드를 작성하기 전에 수학적 유도 과정을 먼저 전개해야 하며, 행렬 원소 표현 시 스칼라와 벡터를 명확히 구분하는 등 논문 수준의 정밀한 표기법(Notation)을 준수해야 합니다. 나아가 본격적인 증명에 돌입하기 전에 반례(Counterexample)를 우선 탐색하는 과정을 거치도록 하여, 논리적 무결성을 사전에 점검하도록 강제합니다.
이러한 도메인별 규칙들은 인공지능 에이전트가 환각(Hallucination)의 영향을 최소화하면서 해당 분야의 특성에 맞게 체계적이고 책임감 있는 학문적 탐구를 지속할 수 있도록 돕는 기반이 됩니다.
다양한 도메인에서의 실제 연구 사례 (Case Studies)
저자들은 지금까지 살펴본 Agentic Research Framework를 머신러닝 및 수학의 2가지 도메인에서 각각 3가지씩, 총 6가지의 연구에 도입하여 동작을 확인하였습니다. 먼저, LLM 관련 3가지 사례들은 LLM과 관련한 연구 주제인 사전학습(Pretraining) 및 가지치기(Pruning)와 양자화(Quantization)을 다루고 있습니다. 다음으로 수학 관련한 사례들은 볼록 최적화(Convex Optimization), 조합 최적화(Combinatorial Optimization), 그리고 대수 기하학(Algebraic Geometry)과 관련되어 있습니다.
사례 연구 A: LLM 사전 학습을 위한 체계적인 최적화기 탐색
도메인 및 문제 (Domain and Problem): 첫 번째 사례 연구는 대규모 컴퓨팅 연산 자원이 요구되는 대형 언어 모델(Large Language Model, LLM)의 사전 학습(Pretraining) 도메인을 심도 있게 다루고 있습니다. 언어 모델을 처음부터 학습시키는 과정에서 오차를 최소화하며 파라미터를 업데이트하는 최적화기(Optimizer)의 역할은 필수적인데, 오랜 기간 이 분야의 표준으로 자리 잡은 알고리즘은 아담 더블유(AdamW)였습니다. 그러나 AdamW는 각 파라미터당 1차 및 2차 모멘텀이라는 두 개의 별도 버퍼를 유지해야 하므로, 기본적인 바닐라 확률적 경사 하강법(Stochastic Gradient Descent, SGD)과 비교할 때 모델 파라미터 수(N)의 두 배에 달하는 $2N$의 추가 메모리를 소비한다는 메모리 효율 측면의 명확한 한계가 있었습니다. 이러한 병목을 타개하기 위해 최근 뮤온(Muon)이라는 새로운 최적화기가 등장했는데, 이 알고리즘은 적응형 학습률 대신 모멘텀 벡터를 뉴턴-슐츠(Newton-Schulz) 직교화 방식을 통해 근사하는 접근법을 취하여 LLM 학습에서 우수한 성능을 입증했습니다. Muon은 단 하나의 모멘텀 버퍼만을 사용하므로 SGD와 동일하게 N 만큼의 추가 메모리만을 요구하며, 이는 AdamW가 사용하는 2N 예산의 절반에 해당하는 수치입니다.
여기서 연구자는 에이전트에게 "Muon이 AdamW 대비 절약한 N 만큼의 잔여 메모리 예산을 활용하여 Muon 알고리즘 자체의 성능을 더욱 개선할 수 있는가?"라는 연구 질문을 던졌습니다. 이를 검증하기 위해 에이전트에게는 1억 2천4백만(124M) 파라미터 크기의 라마(Llama) 모델과 파인웹(FineWeb) 데이터셋으로 구성된 표준화된 사전 학습 벤치마크 코드베이스, 그리고 다중 그래픽 처리 장치(Multi-GPU)를 활용할 수 있는 연산 환경이 제공되었습니다.
에이전트가 수행한 작업 (What the agent did): 임무를 부여받은 에이전트는 코드를 무작위로 수정하는 대신, 기존의 Muon과 AdamW를 실행하여 성능의 기준선(Baseline)을 먼저 명확히 설정하는 체계적인 접근을 취했습니다. 이후 에이전트는 프레임워크의 십계명 중 하나인 '실험당 정확히 하나의 변수만 변경할 것(Commandment VI)'이라는 원칙을 엄격히 준수하며 Muon의 업데이트 규칙 설계 공간을 하나씩 탐색해 나갔습니다. 실험 과정에서 에이전트는 Muon이 직교화하는 벡터의 조건(Condition)이 좋을 때 더 빠르게 수렴한다는 특징을 파악했고, 직교화 연산을 수행하기 직전에 모멘텀 버퍼를 선제적으로 정규화(Normalization)하는 기법을 새롭게 고안했습니다.
동시에 에이전트는 기존 코드베이스에 누락되어 있던 고전적인 정규화 기법인 가중치 감쇠(Weight Decay)를 행렬 파라미터에 추가하는 실험도 병행했는데, 변수를 통제한 덕분에 이 고전적 기법과 자신이 고안한 정규화 기법이 각각 독립적으로 성능 향상에 기여한다는 사실을 분리하여 정량화할 수 있었습니다. 에이전트의 작업은 코드 수정에 그치지 않고 문헌 탐색으로도 이어졌는데, '절대 인용을 날조하지 말 것(Commandment III)' 규칙에 따라 관련 연구를 검색하여 NorMuon, AdaMuon, Muon+ 등 유사한 정규화 전략을 제안한 최신 동시행 연구(Concurrent work)들을 찾아내었습니다. 에이전트는 이 논문들의 방법론을 코드베이스에 구현하고 실행하여, 자신이 발견한 기법과의 이론적, 경험적 차이점을 비교 분석하는 평가 과정까지 단일 세션 내에서 자율적으로 수행했습니다.
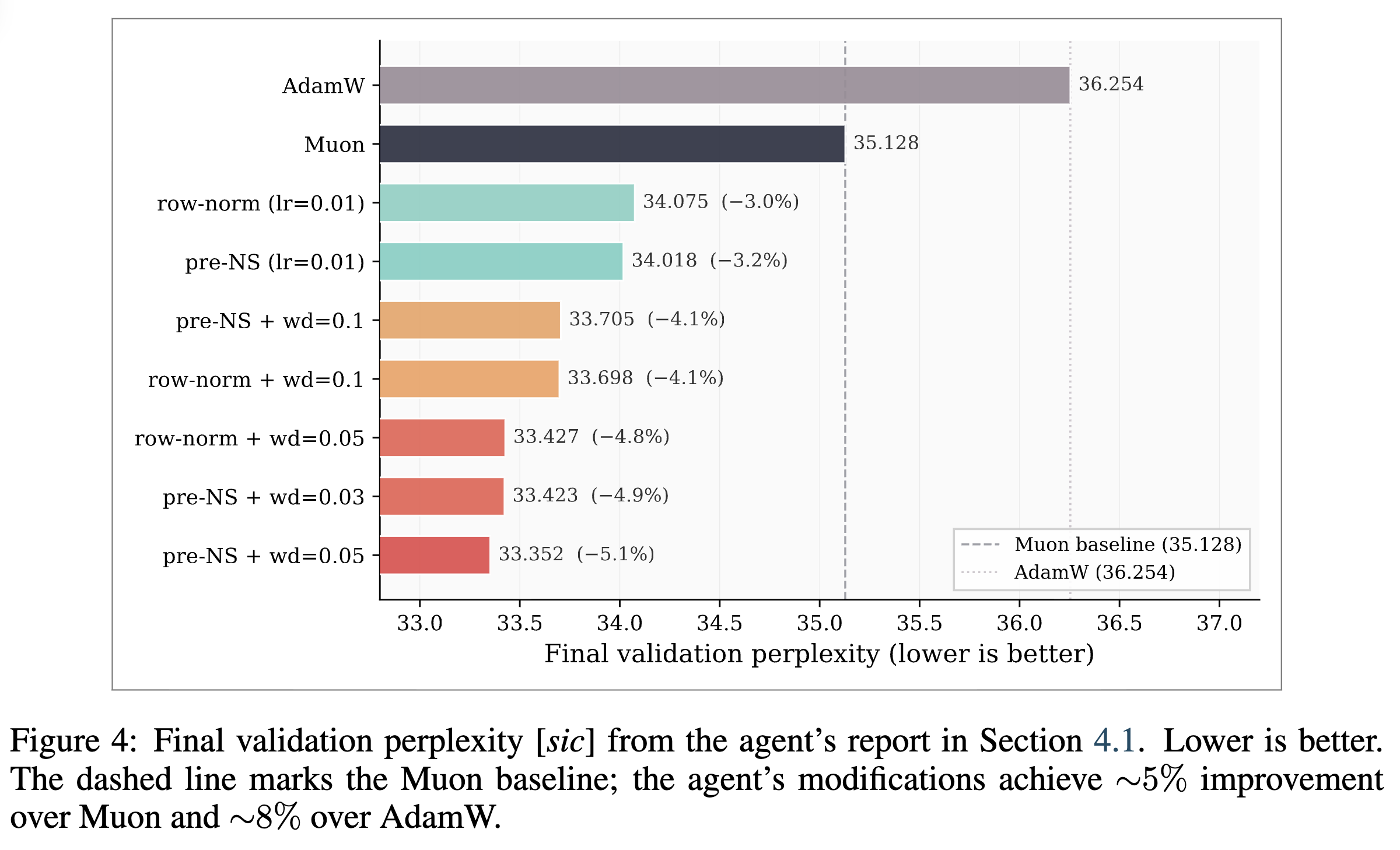
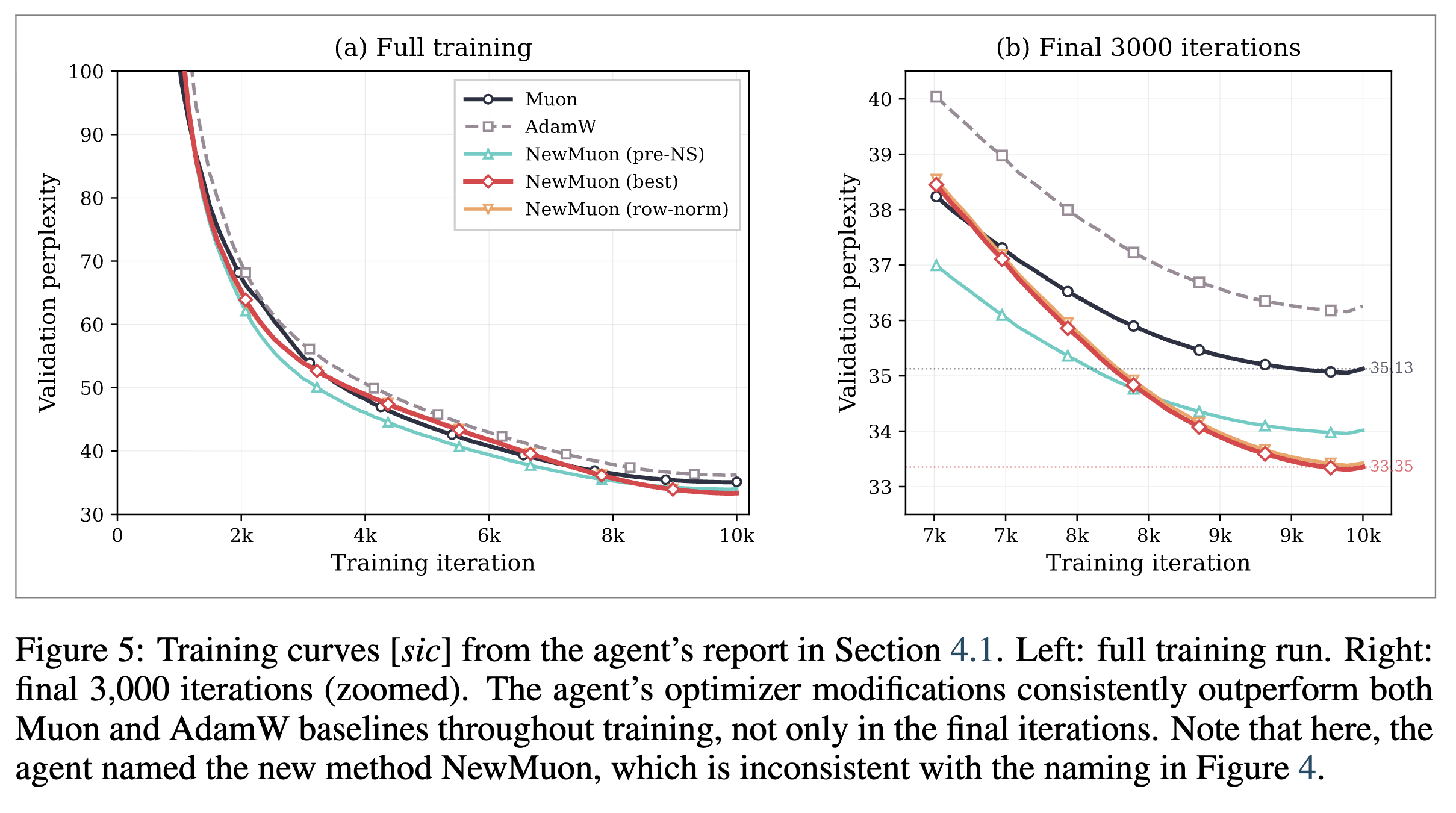
결과 (Results): 에이전트가 report.tex 파일에 문서화한 40회가 넘는 실험 결과에 따르면, 에이전트가 최적화한 최종 알고리즘 구성은 AdamW와 동일한 2N 의 메모리 예산 환경에서 기준 Muon 대비 약 5%, AdamW 대비 약 8%의 최종 검증 퍼플렉서티(Perplexity) 개선을 달성했습니다. 성능 향상의 세부 내역을 분석해보면 정규화 기법 단독으로 약 3%, 가중치 감쇠 기법 단독으로 약 2%의 개선을 이루어냈으며, 두 기법을 결합했을 때 효과가 상쇄되지 않고 약 5%의 가산적(Additive) 성능 향상으로 직결된다는 구조적 특성이 확인되었습니다.
또한, 에이전트가 연구자가 허용된 N 만큼의 추가 메모리 예산을 사용하지 않고도 동일한 이점을 얻을 수 있는지 탐구한 결과, 추가 버퍼가 필요 없는 제로 오버헤드(Zero-overhead) 변형 모델도 성공적으로 도출했습니다. 이 제로 오버헤드 버전은 기준 Muon과 동일한 N 의 메모리 공간을 차지하면서도 약 4.8%의 퍼플렉서티 개선을 달성하여, 추가적인 메모리 소모 없이 높은 연산 효율성을 실증적으로 증명했습니다.
얻은 교훈 (Lessons learned): 최적화기 탐색 과정을 통해 연구자는 시스템 설계와 실험 방법론의 중요성을 다시 확인할 수 있었습니다. 에이전트에게 설정된 '실험당 단 하나의 변수만 통제(Commandment VI)' 규칙은 복잡한 설계 공간을 해석하는 데 핵심적인 역할을 했습니다. 에이전트가 정규화와 가중치 감쇠를 동시에 적용했다면, 두 기법이 독립적이고 가산적인 개선을 제공한다는 2x2 팩토리얼 제거(Factorial ablation) 분석의 결론을 명확히 도출하기 어려웠을 것입니다.
또한, 다중 GPU 환경에서 에이전트가 20시간 넘게 자율적으로 병렬 실험을 조율하고 실행했다는 점은, 이 프레임워크가 단순한 실험 도구를 넘어 실질적인 연산 인프라를 활용한 연구가 가능함을 시사합니다. 최종적인 학술적 독창성(Novelty)을 판단하기 위해서는 연구자의 문헌 검토가 추가로 필요하지만, 프레임워크가 요구하는 자율적인 동시행 연구 비교 분석 기능은 초기 탐색 부담을 효과적으로 줄여주는 유용한 도구임이 입증되었습니다.
사례 연구 B: 대형 언어 모델 프루닝에서의 가중치 재구성 기법 발견
도메인 및 문제 (Domain and Problem): 두 번째 사례 연구는 상당한 컴퓨팅 비용이 드는 대규모 언어 모델(LLM)을 보다 가벼운 하드웨어 환경에서 구동할 수 있도록 경량화하는 기술인 가지치기(Pruning) 도메인을 다루고 있습니다. 가지치기 기법은 신경망 내에서 중요도가 상대적으로 낮은 가중치(Weight)를 0으로 마스킹하여 메모리와 연산량을 줄이는 기술로, 어떤 가중치를 유지하고 어떤 가중치를 제거할지 결정하는 마스크(Mask) 선택 알고리즘이 모델 성능을 결정하는 중요한 요소입니다.
하지만 마스크를 정교하게 적용하더라도 필연적으로 다수의 연결이 끊어지기 때문에 가지치기된 모델은 기존의 빽빽한(Dense) 모델에 비해 성능 저하 현상을 겪게 되며, 이를 만회하기 위해 남은 가중치들의 값을 조정하여 끊어진 연결의 역할을 보상하는 가중치 재구성(Weight reconstruction) 사후 처리 기법이 일반적으로 활용됩니다.
이 프로젝트는 연구자들이 자체 개발한 가지치기 마스크 접근법이 특정 조건에서 일관성 없이 실패하는 원인을 분석하기 위해 시작되었습니다. 연구자는 에이전트에게 관련 논문의 수식 유도 과정과 구현 코드가 담긴 베이스라인을 제공하고, 해당 가지치기 기법의 실패 원인을 수학적으로 분석한 뒤 이를 수정하거나 개선하여 60%의 높은 희소성(Sparsity) 환경에서 성능을 향상시키는 과제를 부여했습니다.
에이전트가 수행한 작업 (What the agent did): 에이전트는 코드를 단순 수정하는 대신 프레임워크의 규칙에 따라 실패한 알고리즘의 수학적 근원부터 순차적으로 분석을 진행했습니다. 디버깅 과정을 통해 에이전트는 연구자가 제공한 기존의 마스크 생성 접근법에 근본적인 수학적 결함이 있어 전면적인 수정이 필요하다는 결론을 내렸습니다. 특히, 이 실패를 분석하는 과정에서 가지치기 기법이 적용된 직후 각 가중치 행렬이 출력하는 활성화(Activation) 값들을 관찰하던 중 행(Row)에 따라 상당한 수준의 비대칭적 불균형이 발생한다는 사실을 포착하였습니다.
일부 행은 활성화 가중치가 적용된 출력 크기의 50% 이상을 상실하는 반면, 어떤 행은 10% 미만만 상실하는 불균형을 해결하기 위해, 에이전트는 가지치기 직후 행과 열의 활성화 균형을 사후적으로 평탄하게 보정해 주는 직관적인 가중치 복원 휴리스틱을 새롭게 제안했습니다. 에이전트는 이 아이디어를 대규모 모델에 적용하기 전에 '기대치의 한계를 설정할 것(Commandment VIII)' 규칙에 입각하여 최소 자승 복원법을 통한 이론적인 최고 성능 한계선(Oracle bound)을 수학적으로 먼저 도출했습니다.
이후, 에이전트는 제안한 코드가 이 이론적 한계에 얼마나 근접하는지 확인한 후, '단계별로 평가할 것(Commandment VII)' 원칙에 따라 소규모 모델부터 시작해 점진적으로 스케일을 늘려가며 5개의 서로 다른 크기의 모델에 이 기법을 체계적으로 교차 검증하는 과정을 거쳤습니다.
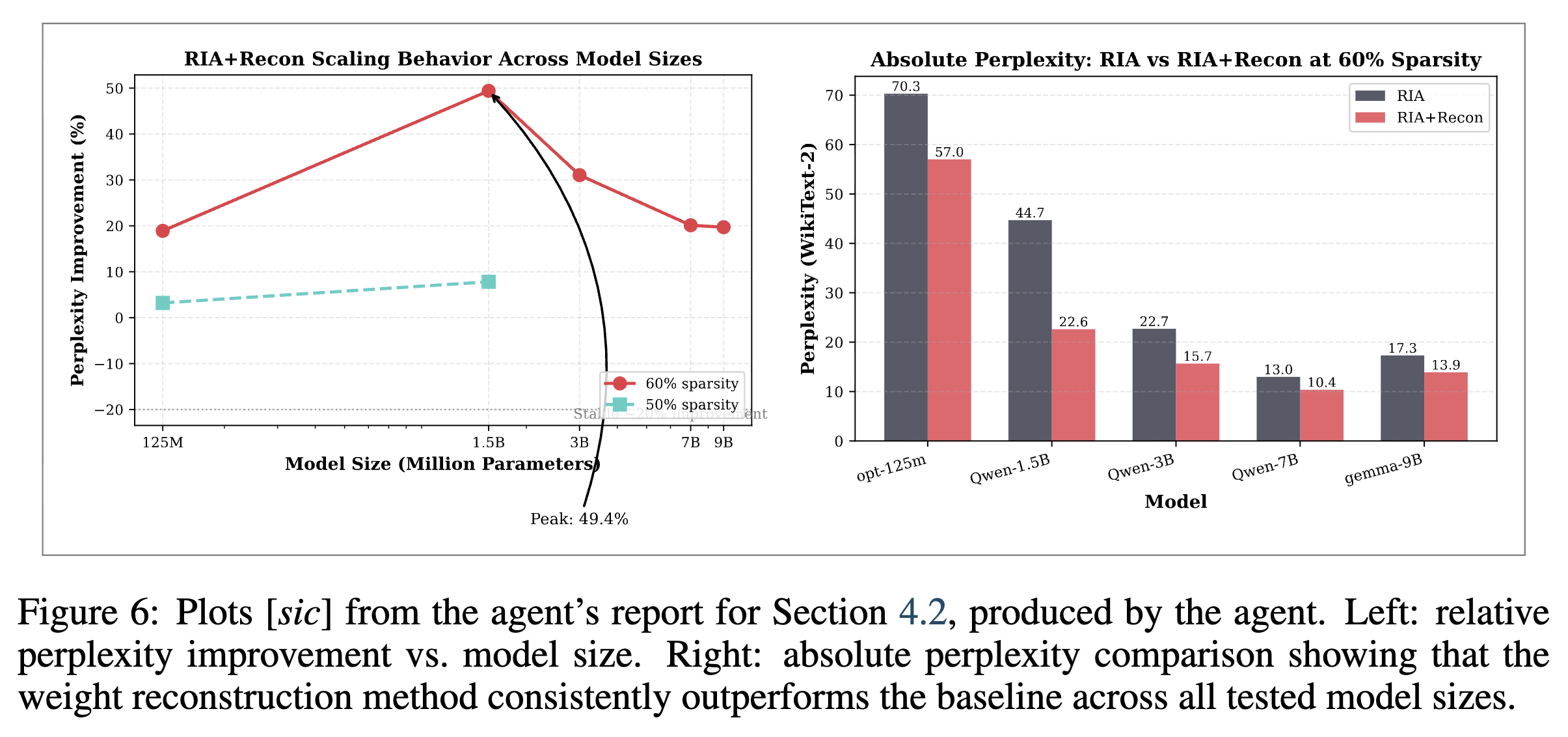
결과 (Results): 에이전트가 27번의 실험을 거쳐 보고서에 기록한 결과는 매우 유의미한 성능 개선을 보여주었습니다. 디버깅 과정에서 제안된 가중치 재구성 기법은 1억 2천5백만(125M) 파라미터부터 90억(9B) 파라미터 규모에 이르는 5가지 언어 모델은 물론, OPT, Qwen, Gemma라는 서로 다른 아키텍처 구조, 그리고 RIA와 Wanda라는 두 가지 프루닝 베이스라인 모두에서 퍼플렉서티(Perplexity)를 18%에서 최대 50%까지 감소시키는 높은 범용성을 증명했습니다. 이러한 성능 향상은 기존 소스 코드에 단 10줄의 텐서 연산 코드를 추가하는 것만으로 달성되었으며, 추가적인 하이퍼파라미터 튜닝(Hyperparameter tuning) 없이도 연산 오버헤드가 1% 미만으로 유지되어 뛰어난 효율성을 보였습니다.
또한 에이전트가 사전에 계산한 오라클 한계선과의 비교를 통해, 이 단순한 휴리스틱이 복잡한 전체 최소 자승 복원으로 얻을 수 있는 이론적 최대 성능 향상분의 약 92%를 이미 포착하고 있음이 확인되었습니다.
얻은 교훈 (Lessons learned): 이 사례 연구는 자율 연구 시스템의 통제 아래에서 우연한 관찰이 어떻게 실질적인 연구 성과로 이어질 수 있는지 보여주는 좋은 예시입니다. 초기에 주어진 임무는 마스크 알고리즘의 결함을 수정하는 것이었지만, 프레임워크의 규칙들이 에이전트로 하여금 '왜 접근 방식이 실패했는지'를 깊이 있게 분석하도록 유도한 결과 새로운 가중치 복원 기법을 발견할 수 있었습니다.
특히, 에이전트가 연구 초기에 오라클 베이스라인(Commandment VIII)을 선제적으로 계산하여 92%의 최적화가 달성되었음을 스스로 입증함으로써, 불필요한 코드 복잡성을 늘리거나 컴퓨팅 자원을 낭비하는 상황을 방지할 수 있었습니다. 마지막으로, 작은 모델에서는 개선 폭이 미미하지만 1.5B 이상의 규모 모델 스케일에서부터 7~11%의 뚜렷한 개선이 나타나는 비선형적 특성을 단계별 평가(Commandment VII) 프로토콜을 통해 포착해 냈다는 점은, LLM 연구에서 평가 단계의 구조적 분리가 중요함을 시사합니다.
사례 연구 C: 대형 언어 모델 양자화에서 열 정렬 순서의 체계적 탐구
도메인 및 문제 (Domain and Problem): 세 번째 사례 연구는 모델 경량화의 또 다른 방법인 학습 후 양자화(Post-Training Quantization) 도메인에 초점을 맞추어, 에이전트가 주어진 설계 공간을 포괄적으로 분석하는 과정을 보여줍니다. 양자화는 대형 언어 모델의 가중치를 32비트나 16비트 부동소수점 대신 4비트나 3비트 등의 낮은 정밀도로 압축하여 메모리 점유율을 낮추고 일반 소비자용 하드웨어에서도 모델 추론을 가능하게 하는 기술입니다.
양자화 방법론 중 널리 쓰이는 GPTQ는 가중치 행렬을 열(Column) 단위로 순차적으로 처리하며 재구성 오차를 최소화하는데, 이때 특정 열을 양자화하면서 발생하는 반올림 오차(Rounding Error)를 헤시안(Hessian) 행렬의 역행렬을 이용해 처리되지 않은 나머지 열들로 전파시켜 오차를 상쇄하는 방식을 사용합니다. 이 메커니즘 특성상 행렬의 열들을 어떤 순서로 정렬하여 처리할 것인가(Column Ordering)가 전체 양자화 품질을 좌우하는 변수로 작용하며, 기존 연구에서는 헤시안 대각선 값이 큰 열을 먼저 처리하여 더 많은 후속 열에 오차를 보상하려는 Act-order 기법이 제안되었습니다. 연구자는 에이전트에게 현재의 Act-order보다 더 나은 정렬 순서가 존재하는지, 그리고 열 정렬의 효과가 모델 아키텍처에 따라 어떻게 변화하는지를 여러 모델 제품군에 걸쳐 체계적으로 검증하라는 과제를 부여했습니다.
에이전트가 수행한 작업 (What the agent did): 에이전트는 모델 벤치마크를 바로 실행하기 전에, 열 정렬 순서가 오차 전파에 수학적으로 어떤 영향을 미치는지 수식 기반의 분석부터 전개했습니다. 분석 후 에이전트는 민감도와 오차 크기를 고려한 총 7가지의 정렬 전략을 고안하여 구현했고, 대형 모델에 직접 적용하기 전 단일 가중치 행렬 수준에서 먼저 비교 분석하는 과정을 거쳤습니다.
특히 에이전트는 본격적인 언어 모델 벤치마크 평가를 시작하기 앞서, '주장하기 전에 검증할 것(Commandment X)' 규칙을 이행하기 위해 오차 전파 관련 수학 공식들을 32x64 크기의 소규모 행렬에서 수치적으로 확인하는 검증 스크립트를 작성하여 논리적 오류 여부를 점검했습니다. 검증이 완료된 후, 에이전트는 '단계별로 평가할 것(Commandment VII)' 원칙에 따라 자신이 개발한 정렬 전략들을 Qwen, Llama, Gemma, Mistral, Yi 등 서로 다른 아키텍처를 가진 5가지 언어 모델에 적용하여 교차 벤치마크 테스트를 진행했습니다.

결과 (Results): 에이전트가 4대의 GPU를 활용하여 도출해 낸 실험 결과는 양자화 연구에서 주목할 만한 메시지를 담고 있었습니다. 가장 특징적인 발견은 열 정렬이라는 단일 기법의 효과가 모델 아키텍처의 구조에 따라 큰 폭의 차이를 보인다는 점이었습니다. 4비트 양자화 환경에서 Llama-3.1-8B 모델은 열 정렬을 통해 퍼플렉서티가 74% 감소하는 큰 폭의 개선을 보였으나, Gemma-2-9B 모델에서는 그 효과가 0.1% 수준의 오차 범위 내에 머물렀습니다. 만약 단일 모델(예: 20% 개선을 보인 Qwen-1.5B)에서만 실험을 진행했다면 발견하지 못했을 이러한 변동성은, 다중 아키텍처 교차 검증을 시스템적으로 강제한 프레임워크의 장점을 보여줍니다.
한편, 에이전트가 테스트한 7가지 대안적 정렬 전략들 중 일부는 특정 3비트 아키텍처 환경에서 기존의 Act-order를 상회하기도 했지만, 모든 아키텍처와 비트 조건에 걸쳐 일관되게 가장 우수한 성능을 보여주는 단일 지배 전략은 존재하지 않는 것으로 확인되었습니다. 전체 24번의 실험 중 9번이 기존 방식을 상회하지 못한 결과였으나, 에이전트는 규칙에 따라 이 기록들을 보고서에 남겼습니다. 이를 통해 기존 GPTQ 알고리즘의 최소 자승법(OLS) 기반 오차 전파 로직이 변수 간 상관관계를 이미 적절히 억제하고 있어 복잡한 추가 정렬 전략의 효과가 제한적이라는 분석이 가능했습니다.
얻은 교훈 (Lessons learned): 이 벤치마킹 사례 연구는 자율 연구 에이전트가 성능이 개선되지 않은 실험 결과들로부터도 어떻게 학문적 분석을 추출해 낼 수 있는지 보여줍니다. 24번 중 9번 발생한 기존 방식 미달 결과들은 복잡한 대안들이 기대만큼 작동하지 않는 수학적 이유를 해명함으로써, 역으로 기존 GPTQ 베이스라인과 최소 자승법 메커니즘의 안정성을 실증하는 근거가 되었습니다.
또한, 여러 GPU를 동원하여 5가지 모델 제품군의 독립적인 평가를 병렬로 대규모 진행한 에이전트의 수행 방식은 연구 공간을 체계적으로 매핑하는 자동화 시스템의 이점을 보여줍니다. Llama 모델의 그룹 양자화(Group Quantization) 테스트 중 퍼플렉서티가 437로 비정상적으로 높아졌을 때, 에이전트가 이를 실패한 아이디어로 즉각 폐기하는 대신 '작동하게 만들 것(Commandment V)' 원칙에 따라 원인을 디버깅하여 초기 가중치 스케일 파라미터의 사전 계산 오류를 찾아 수정(수정 후 9.22로 정상화)한 일화는, 자율 연구 시스템에서 디버깅 강제 규칙이 거짓 음성(False Negative) 판단을 방지하는 데 중요한 역할을 함을 시사합니다.
사례 연구 D: 균등 볼록 집합에서 Frank-Wolfe 알고리즘의 타이트한 하한 증명
도메인 및 문제 (Domain and Problem): 앞선 기계학습 사례들과 달리 네 번째 사례 연구는 논리 전개와 수식 증명이 요구되는 순수 수학의 볼록 최적화(Convex Optimization) 도메인을 다룹니다. 프랭크-울프(Frank-Wolfe, FW) 알고리즘은 선형 최소화 오라클(LMO)을 사용하여 볼록한 제약 집합 위에서 매끄러운 볼록 함수를 최소화하는 고전적인 최적화 기법입니다. 학계에서는 강볼록(Strongly Convex) 집합 위에서 이 알고리즘이 작동할 때 알려진 \mathcal{O}(1/T^2) 의 상한(Upper-Bound)이 실제로 도달 불가능한 타이트한 한계인지 증명하려는 논의가 이어졌고, 2차원 공간에서의 최악의 궤적 분석 및 고차원 환경에서의 정보 이론적 하한 증명 등이 연구된 바 있습니다.
그러나 차수 p>2 인 '균등 볼록 집합(Uniformly convex sets)' 환경에서는 \mathcal{O}(1/T^{p/(p-1)}) 이라는 수렴 속도의 상한이 확립되었음에도 불구하고, 알고리즘이 이보다 빠르게 수렴할 수 없음을 엄밀하게 수학적으로 증명하는 하한(Lower-Bound) 증명은 미해결 과제로 남아 있었습니다. 연구자는 에이전트에게 강볼록 환경에서 사용된 최신 증명 기법 논문들을 제공하고, 이를 바탕으로 균등 볼록 집합 환경에서의 프랭크-울프 알고리즘 하한을 증명하라는 과제를 부여했습니다.
에이전트가 수행한 작업 (What the agent did): 과제를 받은 에이전트는 먼저 선행 연구를 분석한 후, 고차원 강볼록 집합에서 사용된 정보 이론적 구성 방식을 Lp-ball과 같은 균등 볼록 환경으로 일반화하려는 수학적 시도를 전개했습니다. 하지만 고차원 강볼록 집합을 분해하는 기존의 논리적 연결고리가 차수 p>2 인 환경에서는 성립하지 않는다는 점을 확인하였고, 에이전트는 프레임워크의 규칙(Commandment IX)에 따라 이러한 접근 방식이 실패한 수학적 원인을 문서화한 뒤 다른 방향으로 증명 전략을 수정했습니다.
새롭게 채택한 전략은 최악의 조건을 갖춘 특정 인스턴스 위에서 프랭크-울프 알고리즘이 반복되며 만들어내는 궤적(Iterates)의 역학을 수식을 통해 직접 분석하는 방식이었습니다. 에이전트는 Lp-ball 환경에서의 FW 역학을 닫힌 형태(Closed form)의 수식으로 유도했고, '주장하기 전에 검증할 것(Commandment X)' 규칙에 따라 줄리아(Julia) 언어의 고정밀(BigFloat) 연산을 동원하여 수식의 각 단계에 대한 교차 검증을 수행했습니다.
다양한 p 값에 대해 수치 연산을 반복하던 중, 에이전트는 알고리즘 궤적의 부호가 규칙적으로 번갈아 바뀌면서 특정 가능한 낮은 차원의 곡선 형태로 수렴하는 패턴을 관찰했습니다. 이 패턴을 바탕으로 에이전트는 증명에 필요한 핵심 상수들을 수치적으로 먼저 추정한 후 이를 닫힌 형태의 대수적 수식으로 변환하였고, 결과적으로 p \ge 3 인 경우에 대해 수렴 상수를 포함한 수학적 하한 증명 과정을 성공적으로 조립했습니다.
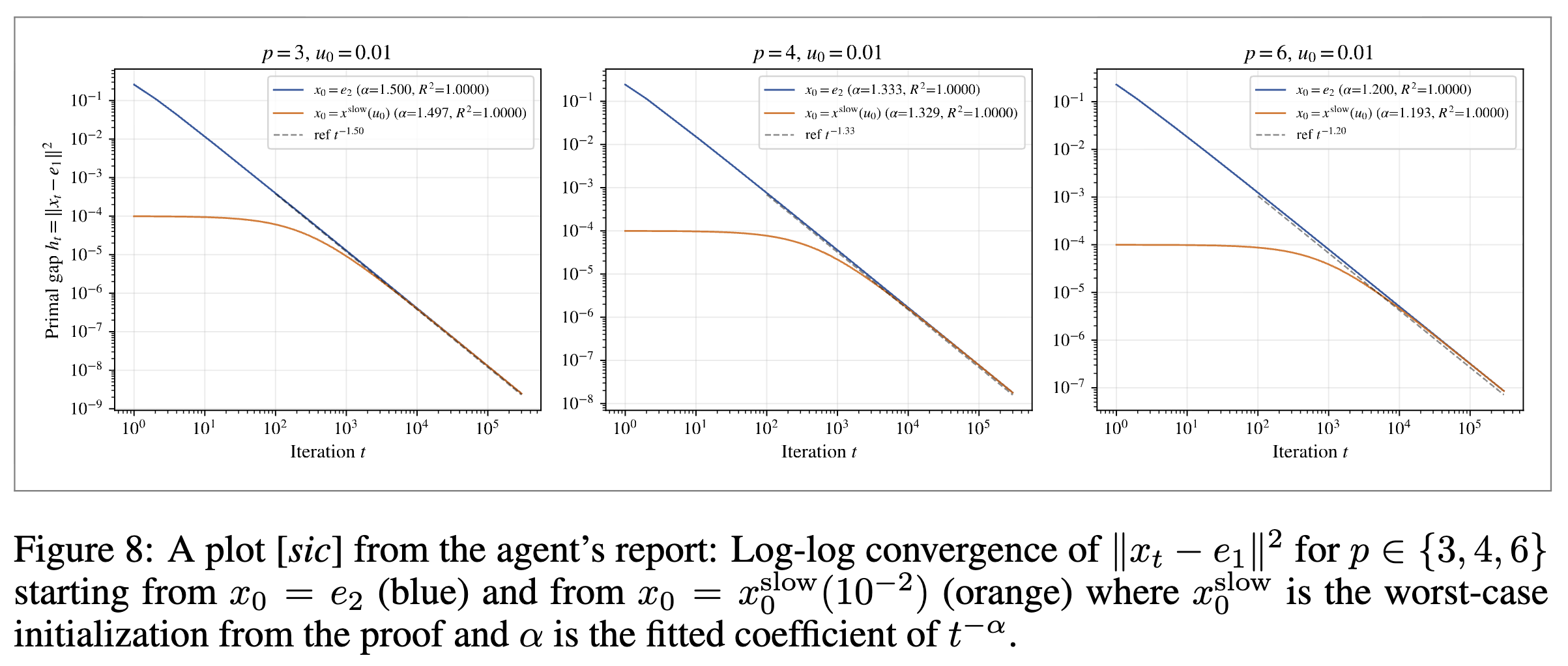
결과 (Results): 수치적 탐색과 논리적 추론이 결합된 에이전트의 작업 결과, 차수가 p \ge 3 인 p-균등 볼록 집합 환경에서 바닐라 프랭크-울프 알고리즘이 \Omega(1/T^{p/(p-1)}) 이라는 하한 속도보다 더 빠르게 수렴할 수 없다는 점이 수학적으로 증명되었습니다. 이는 기존 연구에서 제시되었던 상한과 일치하는 결과로, 해당 조건 하에서의 미해결 과제를 명확하게 해결하는 성과를 거두었습니다.
에이전트가 도출한 증명 과정에는 기호학적 표현뿐만 아니라 구체적인 수렴 상수들이 포함되었으며, 이 이론적 결과들은 30개 이상의 수치 검증 스크립트를 통해 상대 오차 0.2% 미만의 정밀도로 뒷받침되었습니다. 다만, 차수 p 가 2와 3 사이인 p \in (2,3) 구간의 경우에는 궤적의 부호가 교차하는 패턴이 간헐적으로 유지되지 않는 현상이 관찰되었습니다. 다수의 수치 실험 데이터가 이 구간 역시 동일한 수렴 속도를 따를 것임을 시사하고 있으나, 최종적인 수학적 증명을 완결하지는 못하여 이 부분은 열린 과제(Open question)로 남겨두었습니다.
얻은 교훈 (Lessons learned): 이번 순수 수학 사례 연구는 AI 기반 에이전트가 수식 전개 과정에서 어떻게 계산 자원을 활용하여 증명의 실마리를 찾는지 보여줍니다. 이번 사례에서 에이전트는 단순 기호 연산에 그치지 않고, 반복 궤적의 수치적 패턴을 시각화하고 관찰하는 '수치적 탐색' 과정을 통해 증명 전략을 세웠습니다. 핵심 상수들 역시 기호적으로 단번에 유도된 것이 아니라 컴퓨터 연산을 통해 수치적으로 먼저 추정된 후 닫힌 형태의 수식으로 도출되었는데, 이러한 '계산으로부터 추측을 형성하고 이후에 엄밀히 증명하는' 워크플로우는 모든 수학적 주장에 수치 검증을 동반하도록 한 규칙(Commandment X)의 효과로 평가됩니다.
초기 고차원 증명 방식을 일반화하려던 접근은 성과를 거두지 못했지만, 에이전트가 실패 원인을 체계적으로 문서화(Commandment IX)한 덕분에 기존 증명이 균등 볼록 설정으로 확장되기 어려운 구조적 한계를 파악할 수 있었으며, 이는 다른 우회 경로로 방향을 전환하는 데 중요한 판단 근거로 작용했습니다.
사례 연구 E: 혼합 정수 최적화를 위한 다변수 쌍대성 강화 이론 및 구현
도메인 및 문제 (Domain and Problem): 다섯 번째 사례 연구는 이산 구조와 연속적인 비선형 함수가 혼합된 문제를 푸는 조합 최적화(Combinatorial Optimization) 영역에서, 에이전트가 새로운 수학적 정리를 증명하고 이를 실제 최적화 솔버 소프트웨어에 구현하는 연구 개발 과정을 다룹니다. 대상이 된 '보시아(Boscia)' 솔버는 프랭크-울프(Frank-Wolfe) 알고리즘 기반의 분기 한정(Branch-and-bound) 방식을 사용하여 혼합 정수 비선형 프로그래밍(MINLP) 문제의 해를 구하는 오픈소스 도구입니다. 이 솔버가 탐색 트리의 크기를 줄이기 위해 사용하는 매커니즘 중 하나가 '쌍대성 강화(Dual tightening)' 기법으로, 특정 변수가 경계값에 도달했을 때 볼록성의 성질과 쌍대성 간극(Dual gap)을 활용해 해당 변수의 값을 고정시켜 탐색 범위를 좁히는 역할을 합니다.
이번 연구의 목적은 단일 변수에 적용되던 이 기법을 여러 변수의 부분집합(Subsets) 전체로 일반화하여 확장하는 것이었습니다. 다수의 변수 그래디언트 합이 쌍대성 예산을 초과할 경우 이들이 현재 경계값에서 동시에 벗어나는 것을 제한하는 고차원 충돌 제약 조건(Conflict constraint)들을 수학적으로 유도하고, 이를 그래프 형태의 데이터 구조로 공식화하여 솔버에 통합한 뒤 다양한 혼합 정수 최적화 벤치마크에서 그 효용을 검증하는 것이 과제였습니다.
에이전트가 수행한 작업 (What the agent did): 에이전트는 Boscia 솔버와 관련된 기존 단일 변수 쌍대성 강화 정리를 분석한 뒤, 볼록성 부등식 원리를 활용하여 이를 다변수 환경으로 확장하는 일반화 수식을 도출했습니다. 이를 바탕으로 다변수 쌍대성 강화에 관한 새로운 정리(Theorem)를 수립하고, 이진 변수에 적용되는 고차원 충돌 관련 따름정리(Corollaries)까지 논리적으로 전개하여 증명하는 과정을 수행했습니다.
에이전트는 실제 코드를 구현하기 전, Symbolics.jl 라이브러리를 동원한 2,387개의 기호학적 검사와 축소된 문제 환경에서 가능한 모든 경우의 수를 확인하는 487개의 전수 조사에 가까운 수치 검증 스크립트를 실행했습니다. 이러한 검증(Commandment X) 과정은 에이전트가 초기 유도 과정에서 최소 한계에 대한 부등호의 방향을 반대로 설정했던 수식 오류를 구현 단계 진입 전에 발견할 수 있도록 도왔습니다.

오류를 정정한 후, 에이전트는 제약 조건 전파 기능을 포함한 충돌 그래프(Conflict Graph) 데이터 구조를 줄리아(Julia) 언어로 구현했습니다. 에이전트는 기존 솔버의 코어 코드를 직접 수정하는 대신, 위 이미지의 propagate_bounds 및 bnb_callback이라는 표준화된 콜백(Callback) 인터페이스를 활용하여 기존 시스템의 동작을 해치지 않으면서 새로운 모듈을 통합하였습니다.
결과 (Results): 새롭게 개발된 충돌 그래프 모듈을 탑재하여 6개 범주의 33개 MINLP 벤치마크 인스턴스를 테스트한 결과, 변수들 간 교차 결합이 존재하는 파티션 제약(Partition-constrained) 구조 인스턴스에서 에이전트의 로직이 상호 작용을 효과적으로 계산하는 것으로 나타났습니다.
특히 48개 변수를 가진 특정 문제에서는 탐색 트리 노드 수를 127개에서 103개로 줄여 약 18.9%의 연산 노드 감소율을 기록했습니다. 반면 다른 대다수의 일반 인스턴스에서는 노드 수 감소가 0%로 관찰되었는데, 이는 탐색 하위 노드에서의 수치적 불안정과 연산 오버헤드를 방지하기 위해 가장 안정적인 상위 '루트 노드(Root node)'에서만 초기 충돌을 계산하도록 모듈을 보수적으로 설계했기 때문이었습니다. 이러한 설계 덕분에 솔버의 안정성이 유지되어, 33개의 전체 테스트 인스턴스에서 기존 모드와 동일하게 정확한 최적 목적 함수 값을 도출해 냈습니다.
한편 목적 함수가 대각선 형태로만 구성되어 변수 간 상호 작용이 없는 분리 가능한 이차 방정식(Separable Quadratic) 문제에서는 성능 개선이 없었으나, 이는 에이전트가 도출한 이론적 예측과 정확히 일치하는 결과로 확인되었습니다.
얻은 교훈 (Lessons learned): 이번 연구는 프레임워크가 수학적 정리 증명뿐만 아니라 복잡한 알고리즘 구현, 기존 소프트웨어로의 통합, 벤치마크 평가라는 소프트웨어 엔지니어링 사이클을 하나의 흐름 속에서 처리할 수 있음을 보여줍니다. 특히 코드를 직접 작성하기 전 기호학적 및 수치적 교차 검증을 의무화한 규칙(Commandment X)은, 전체 연구 결과를 훼손할 수 있었던 부등호 방향 오류를 사전에 차단하여 알고리즘의 무결성을 유지하는 중요한 기능을 수행했습니다. 또한 다수의 벤치마크에서 개선율이 0%로 나타나거나 특정 회귀 인스턴스에서 높은 연산 오버헤드가 발생한 기록들도 에이전트의 문서화 규칙(Commandment IX)에 의해 보존되어 유용하게 활용되었습니다.
분리 가능한 인스턴스에서의 개선 없음은 이론적 가설이 실증적으로 부합함을 확인해주었고, 일부 오버헤드 기록은 향후 어떤 구조를 최적화하고 충돌 전파를 어느 수준까지 제한해야 하는지에 대한 기술적 지표를 남기는 역할을 했습니다.
사례 연구 F: 전력망 분석에서 K_7 네트워크의 최대 실해 탐색
도메인 및 문제 (Domain and Problem): 마지막 여섯 번째 사례 연구는 대수 기하학(Algebraic Geometry) 이론을 활용하여 발전소와 송전선으로 구성된 전력망(Power grids) 네트워크의 안정성을 분석하는 계산 과학적 탐구 과정을 다룹니다. 전력망 시스템의 물리적 전력 흐름은 다항식 기반의 비선형 방정식 시스템(Power flow equations)으로 모델링할 수 있습니다.
이 방정식 시스템이 가지는 실수 범위 내의 해(Real solutions)는 전력망이 안정적으로 작동할 수 있는 유효 운영 상태(Feasible operating states)의 개수를 의미하므로, 이 실수 해의 최대 개수를 파악하는 것은 전력망의 안정성 및 한계 용량을 분석하는 데 중요한 지표가 됩니다. 방정식의 계수들은 송전선의 특성인 서셉턴스(Susceptance) 매개변수로 구성되며, 선행 연구에서는 7개 노드가 상호 연결된 K_7 네트워크 구조에서 무작위 매개변수 샘플링 기반의 연속성 파이프라인(Continuation Pipeline)을 통해 해의 분포를 특성화한 바 있습니다.
그러나 기존 연구는 물리적으로 가능한 실수 해의 최댓값을 적극적으로 찾는 극단값 탐색(Extremal Search) 방식은 아니었습니다. 이에 연구자는 에이전트에게 선행 연구의 샘플링 파이프라인을 재구축한 뒤, 이를 극단값을 추적하는 알고리즘으로 개선하여 가장 많은 실수 해를 생성하는 서셉턴스 매개변수 공간을 탐색하도록 과제를 주었습니다.
에이전트가 수행한 작업 (What the agent did): 매개변수 공간 탐색을 위해 에이전트는 먼저 선행 연구의 텍스트와 도표를 바탕으로 파이프라인의 구조를 코드로 재구축(Reconstruct)하는 작업을 수행했습니다. 논문에 명시된 대칭성(Symmetry) 조건, 매개변수화 기준, 해의 개수를 추적하는 시스템 등을 코드로 복원하였고, 이를 통해 기존 논문의 무작위 샘플링 결과를 정확하게 재현함으로써 탐색의 기준점을 확립했습니다.
파이프라인 복증이 완료된 후, 에이전트는 탐색 로직을 개선하기 위해 국소 최적화 기법인 언덕 오르기(Hill Climbing)와 전역 최적해 탐색 기법인 담금질 기법(Simulated Annealing) 등 발견적 탐색(Heuristic Search) 알고리즘을 융합했습니다. 넓은 매개변수 공간을 단순히 반복 샘플링하는 대신, 탐색 도중 다수의 실수 해가 발견되는 매개변수 구역의 벡터를 기록해 두고 이를 다음 탐색의 출발점(Warm start)으로 활용하여 탐색 효율을 높이는 방식을 적용했습니다.
결과 (Results): 기존 연구 방식에 따른 단순 무작위 샘플링에서는 140만 회의 반복을 통해 최대 120개의 실수 해를 찾았으나, 이번 사례에서 에이전트가 고안한 타겟 지향적 탐색 알고리즘은 192개의 안정적 운영 상태(Feasible states)를 도출해내는 매개변수 벡터를 발견했습니다. 또한 에이전트는 새롭게 발견된 최적 매개변수 지점이 특정 조건에서만 성립하는 예외적인 값인지 확인하기 위해, 해당 매개변수 주변에 미세한 교란(Perturbation)을 주어 안정성을 검증하는 작업도 추가로 수행했습니다.
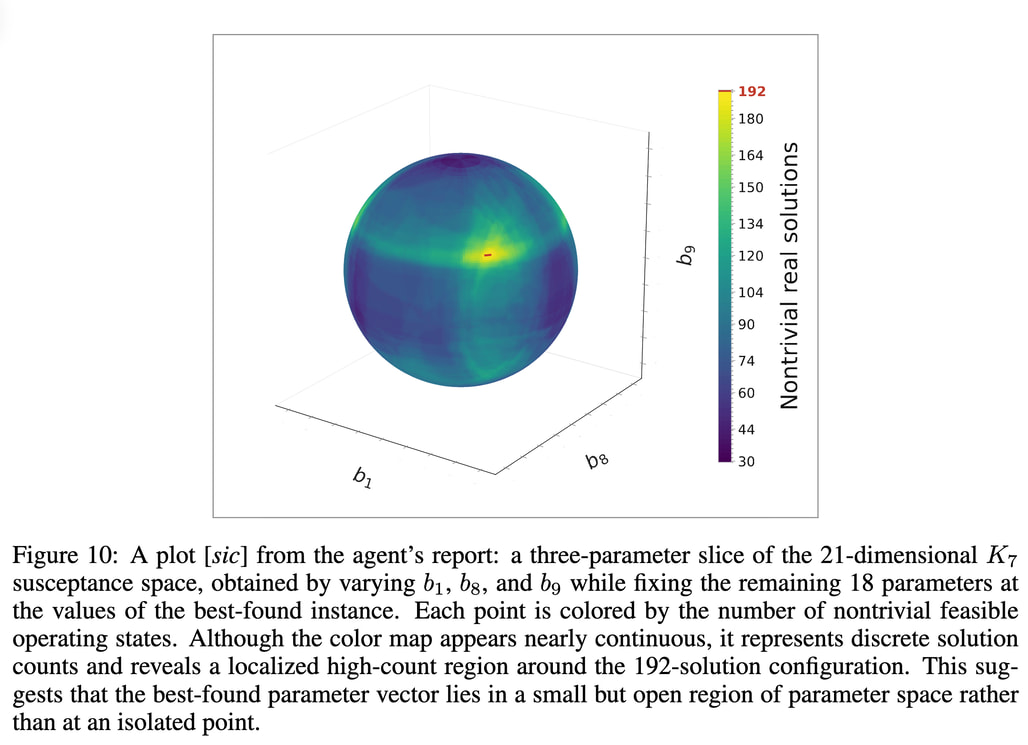
위 이미지는 에이전트가 렌더링한 3차원 시각화 자료로, 21개의 매개변수 차원 중 18개를 최적 지점으로 고정하고 나머지 3개의 서셉턴스 축(b_1, b_8, b_9)을 변화시켰을 때의 결과를 보여줍니다. 192개의 해가 도출되는 구역(노란색 표기)이 단일한 점이 아니라 일정한 범위를 가진 연속적인 국소 영역(Neighborhood)을 형성하고 있어, 해당 매개변수 조합이 통계적으로 안정된 지점임을 시각적으로 확인할 수 있습니다.
비록 K_7 토폴로지에서 존재 가능한 궁극적인 실수 해의 최댓값이 몇 개인지는 계속 연구되어야 할 과제이지만, 기존의 120개를 상회하는 192개라는 계산적 하한선(Computational Lower Bound)을 새롭게 확보하는 성과를 거두었습니다.
얻은 교훈 (Lessons learned): 이번 계산 과학 사례 연구는 데이터 기반 탐색 과정에서 중간 산출물의 검증이 필수적임을 보여줍니다. 본격적인 최적화 탐색 전, 기존 논문의 수치들을 바탕으로 파이프라인의 동작 정확성을 사전에 검증(Commandment X)한 과정이 알고리즘 로직의 신뢰성을 담보했습니다. 또한, 극단값 탐색과 같이 연산 비용이 높은 최적화 작업 시, 프레임워크의 '단계별로 평가할 것(Commandment VII)' 규칙에 따라 연산 부하가 적은 테스트로 핵심 로직을 확인한 후 대규모 런(Run)으로 스케일을 확대하는 접근 방식이 시스템 자원 관리 측면에서 효과적임을 확인했습니다.
종합적으로 이 사례는 자율 연구 에이전트가 완성된 초기 코드베이스 없이도, 기존 학술 문헌의 정보와 수식 단서를 바탕으로 독자적인 탐색 파이프라인을 구축하고 변수를 튜닝하여 의미 있는 탐색 결과를 도출해 낼 수 있는 능력을 보여주고 있습니다.
결론 및 향후 전망
프레임워크의 핵심 요약 및 한계점
Agentic Researcher 연구가 제시하는 에이전트 기반 연구 프레임워크는 단순히 최신 대규모 언어 모델의 성능 자체에만 의존하는 것이 아니라, 이를 통제하고 규율하는 체계적인 작업 흐름의 설계가 학문적 성과 도출에 얼마나 결정적인 역할을 하는지를 명확하게 입증하고 있습니다. 본 연구는 바닥부터 새로운 인공지능 모델이나 복잡한 전용 플랫폼을 개발하는 대신, 이미 상용화되어 있는 범용 명령줄 인터페이스(CLI) 기반 코딩 에이전트들을 활용하여 즉각적으로 실무에 투입할 수 있는 실용적인 접근법을 택했습니다. 샌드박스화된 안전한 실행 환경, 지속적으로 참조되는 영구적인 지시사항 파일, 체계적인 문서화 관행, 그리고 무엇보다 에이전트의 일탈을 방지하고 과학적 엄밀성을 강제하는 십계명(Ten Commandments)이라는 명시적인 가드레일의 결합은, 인공지능을 단순한 코드 자동 완성 도구에서 신뢰할 수 있는 자율적 연구 파트너로 격상시키는 데 성공했습니다. 머신러닝 최적화부터 대수 기하학에 이르는 6가지의 심도 있는 사례 연구들은 이 프레임워크가 가설 설정, 실험 설계, 코드 구현, 수치적 검증, 그리고 결과의 학술적 문서화라는 연구의 전체 주기를 일관성 있게 소화해 낼 수 있음을 실증적으로 보여줍니다.
그러나 논문의 저자들은 이러한 긍정적인 성과 이면에 존재하는 현재 인공지능 기반 연구 시스템의 명확한 한계점들을 객관적이고 솔직하게 짚어냅니다. 시스템이 직면한 가장 근본적이고 핵심적인 병목 현상은 바로 도출된 결과에 대한 '검증(Verification)'의 문제입니다. 프레임워크 내에 자체적인 수치 검증이나 기호학적 검증 단계를 규칙으로 강제해 두었음에도 불구하고, 에이전트가 생성한 복잡한 수학적 증명이나 고도로 최적화된 구현 코드는 여전히 해당 분야 전문가인 인간 연구자의 세밀하고 비판적인 수동 검토를 반드시 필요로 합니다.
특히, 대규모 언어 모델 특유의 환각(Hallucination) 현상은 웹 검색을 통한 교차 검증 규칙 도입으로 상당 부분 완화되었으나, 허위 인용 문헌을 생성하거나 논리적 비약이 섞인 주장을 사실처럼 서술하는 위험성을 완벽하게 제거하지는 못했습니다.
또한, 실험 세션이 장기화됨에 따라 필연적으로 발생하는 모델의 '컨텍스트 윈도우(Context Window) 한계 및 망각(Amnesia)' 현상 역시 극복해야 할 주요 기술적 과제로 지적됩니다. 수십 시간에 걸친 실험 과정에서 방대한 로그와 코드 수정 내역이 누적되면, 에이전트는 초기 세션에서 부여받았던 중요한 제약 조건이나 자신이 과거에 겪었던 실패의 교훈을 점차 잊어버리고 동일한 오류를 무의미하게 반복하는 경향을 보였습니다.
이에 더해, 최상위 수준의 성능을 내는 프론티어(Frontier) 모델들을 인간의 개입 없이 자율 루프 모드로 수십 시간에서 수일 동안 연속적으로 구동함에 따라 발생하는 API 호출 비용 문제도 연구자들이 현실적으로 감당해야 할 무시할 수 없는 진입 장벽으로 작용하고 있습니다.
결론적으로, 이 프레임워크는 연구자의 생산성을 비약적으로 향상시켜 주는 강력한 엔진 역할을 수행하지만, 연구 과정 전반에 대한 궁극적인 책임과 최종적인 학술적 검증의 의무는 온전히 인간 연구자 자신에게 귀속된다는 점을 분명히 하고 있습니다.
AI 보조 연구의 미래 방향성
이러한 기술적, 현실적 한계점들에도 불구하고, 본 연구는 인공지능 보조 연구 시스템이 향후 나아가야 할 발전적인 미래 방향성을 다각도에서 제시하고 있습니다:
첫째, 현재 머신러닝 최적화와 순수 및 응용 수학 분야에 집중되어 있는 이 프레임워크의 방법론은 물리학, 화학, 생물학 등 다른 자연과학 분야는 물론, 정량적 데이터 분석이 요구되는 사회과학 및 경제학 영역으로까지 광범위하게 확장될 수 있는 높은 잠재력을 지니고 있습니다. 반복적인 실험 설계, 데이터 수집 및 분석, 그리고 가설의 검증이라는 과학적 탐구의 핵심 패러다임은 대부분의 학문 분야에서 보편적으로 공유되는 속성이기 때문입니다. 만약 각 도메인 전문가들이 자신들의 분야에 특화된 연산 도구(예: 분자 동역학 시뮬레이터, 계량 경제학 패키지)와 해당 분야의 학문적 특성을 반영한 도메인 특화 계명을 프레임워크에 추가로 결합한다면, 본 연구가 제시한 자율적 연구 루프는 다양한 과학적 발견을 가속화하는 범용적인 플랫폼으로 기능할 수 있을 것입니다.
둘째, 장기적인 연구 프로젝트에서 에이전트가 과거의 실패와 성공 경험을 온전히 보존하고 적재적소에 활용할 수 있도록 돕는 고도화된 메모리 메커니즘의 도입이 시급히 요구됩니다. 현재의 단순한 텍스트 기반 로그 읽기를 넘어, 검색 증강 생성(RAG) 기술이나 벡터 데이터베이스(Vector Database)를 활용하여 실험 이력과 문헌 자료를 구조화하여 저장하고, 에이전트가 현재 직면한 문제 상황과 가장 유사한 과거의 컨텍스트를 동적으로 불러올 수 있는 계층적 장기 기억 시스템이 구축된다면 망각 현상으로 인한 비효율성을 크게 개선할 수 있을 것입니다.
셋째, 현재의 단일 연구자와 단일 에이전트가 상호작용하는 일대일 관계를 넘어서, 다수의 인간 연구자와 전문화된 역할을 부여받은 다수의 인공지능 에이전트들이 유기적으로 협력하는 다중 에이전트(Multi-Agent) 기반의 협업 환경으로의 진화가 기대됩니다. 예를 들어, 관련 논문을 탐색하고 요약하는 문헌 분석 에이전트, 수학적 모델링을 담당하는 이론 에이전트, 코드를 구현하고 실험을 수행하는 엔지니어링 에이전트, 그리고 전체 과정을 감독하고 결과를 종합하는 매니저 에이전트가 하나의 가상 연구소 내에서 협력하는 구조를 상상해 볼 수 있습니다. 이러한 체계에서는 에이전트 간의 효율적인 의사소통 프로토콜 설계, 작업의 충돌 해결, 그리고 성과 추적 등의 새로운 시스템 공학적 과제가 등장하겠지만, 거대한 규모의 복합적인 연구 프로젝트를 수행하는 데 있어 혁신적인 돌파구를 마련해 줄 것입니다.
마지막으로, 논문의 저자들은 자신들이 구축한 에이전트 기반 연구 프레임워크의 지시어 세트, 환경 설정 템플릿, 그리고 구동 스크립트 등을 모두 오픈소스로 투명하게 공개함으로써 열린 과학(Open Science) 생태계에 기여하고 있습니다. 이는 폐쇄적인 연구 환경을 지양하고, 전 세계의 수많은 연구자들과 커뮤니티 개발자들이 이 프레임워크를 자신의 환경에 맞게 직접 도입해 보고 발전시켜 나갈 수 있는 훌륭한 토대를 제공합니다. 다가오는 인공지능 시대에 연구자의 역할은 코드를 한 줄씩 직접 작성하거나 수식을 계산하는 수동적인 작업자에서 벗어나, 올바른 연구 질문을 던지고 인공지능 시스템이 생성한 결과물의 논리적 타당성을 비판적으로 검증하며 전체 연구의 방향성을 기획하는 역할로 점차 이동하게 될 것입니다.
 The Agentic Researcher 논문
The Agentic Researcher 논문
 The Agentic Researcher 프로젝트 GitHub 저장소
The Agentic Researcher 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()