
Meta-Harness 연구 개요: LLM 하네스를 자동으로 최적화하는 시스템
LLM 성능의 숨겨진 변수, 하네스(Harness)
최근 대규모 언어 모델(LLM)의 활용이 급속히 확대되면서, 모델의 성능을 좌우하는 요소에 대한 이해도 깊어지고 있습니다. 흥미로운 점은 동일한 LLM이라도 어떤 하네스(harness) 를 사용하느냐에 따라 같은 벤치마크에서 최대 6배의 성능 차이가 발생한다는 것입니다. 하네스란 모델 주변을 감싸는 코드로, 어떤 정보를 저장하고, 검색하고, 모델에 제시할지를 결정하는 모든 로직을 의미합니다. 프롬프트 구성, 문맥 관리, 검색 전략, 메모리 업데이트 등이 모두 하네스의 영역입니다.
이렇게 모델이 실제로 동작할 때 어떤 정보를 저장하고, 무엇을 검색하며, 어떤 형식으로 컨텍스트를 보여줄지를 결정하는 하네스(harness) - 즉, 모델 주변의 실행 코드가 최종 성능에 결정적인 역할을 하고 있음에도 불구하고, 하네스 엔지니어링은 여전히 대부분 수작업에 의존하고 있습니다. 개발자가 실패 사례를 검토하고, 휴리스틱을 조정하며, 소수의 설계안을 반복적으로 수정하는 방식입니다. 그렇다면 이 과정 자체를 자동화할 수는 없을까요?
Meta-Harness의 핵심 아이디어는 바로 "하네스 엔지니어링도 탐색 문제다"라는 관점에서 출발합니다.
기존 텍스트 최적화 방법의 한계
하네스 최적화를 자동화하려는 시도로 가장 먼저 떠오르는 것은 텍스트 최적화(text optimization) 방법론들입니다. ProTeGi, TextGrad, OPRO, GEPA, AlphaEvolve/OpenEvolve, Feedback Descent 같은 방법들은 이전 시도에서 얻은 피드백을 활용해 프롬프트나 텍스트 아티팩트를 반복적으로 개선합니다.
하지만 이 방법들은 하네스 엔지니어링에 적합하지 않습니다. 핵심적인 문제는 피드백을 지나치게 압축한다는 점입니다. 어떤 방법은 현재 후보만 참조하고(Self-Refine, OPRO, TextGrad), 어떤 방법은 스칼라 점수에만 의존하며(AlphaEvolve), 또 어떤 방법은 짧은 템플릿이나 LLM이 생성한 요약으로 피드백을 제한합니다(GEPA, Feedback Descent). 기존 방법들이 최적화 단계당 사용하는 문맥은 100 에서 30{,}000 토큰 수준에 불과합니다.
하네스는 긴 시간 축에 걸쳐 동작합니다. 무엇을 저장할지, 언제 검색할지, 어떻게 제시할지에 대한 하나의 결정이 여러 추론 단계 이후의 행동에 영향을 미칠 수 있습니다. 압축된 피드백으로는 하류 실패를 초기 하네스 결정까지 추적하는 데 필요한 정보가 사라져 버립니다.
발상의 전환: 파일시스템을 통한 풍부한 경험 접근
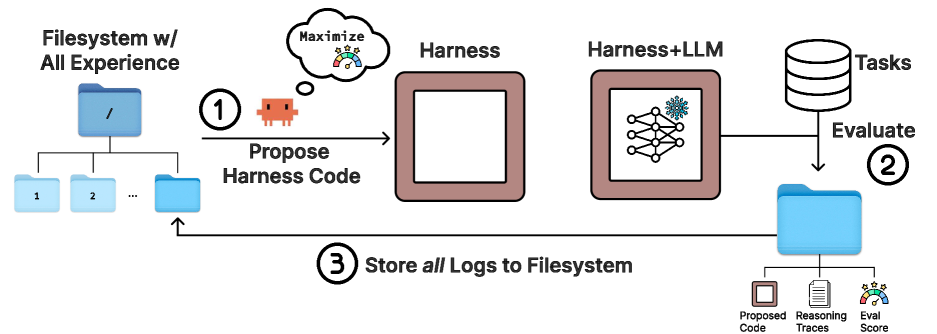
MIT의 Omar Khattab과 Stanford의 Chelsea Finn이 제안한 Meta-Harness 는 이 문제를 근본적으로 다른 방식으로 접근합니다. 핵심 아이디어는 마치 숙련된 개발자가 이전 실험 기록을 직접 뒤져보며 문제를 진단하듯, 코딩 에이전트에게 파일시스템을 통해 이전 모든 후보의 소스 코드, 실행 트레이스, 점수에 대한 선택적 접근 권한을 부여하는 것입니다.
기존 방법들이 피드백을 요약하거나 압축하여 고정된 프롬프트에 넣는 반면, Meta-Harness의 제안자(proposer)는 grep이나 cat 같은 표준 파일시스템 명령을 통해 필요한 정보를 직접 탐색합니다. 가장 까다로운 설정에서 제안자는 반복 당 중앙값 기준 82 개의 파일을 읽고, 단계당 20 개 이상의 이전 후보를 참조합니다. 단일 평가에서 최대 10{,}000{,}000 토큰의 진단 정보가 생성되는데, 이는 기존 텍스트 최적화 방법들의 최대 피드백 예산보다 약 1,000배나 큰 규모입니다.
Meta-Harness의 핵심 설계
하네스 최적화의 목표와 탐색 루프
Meta-Harness는 "하네스를 최적화하기 위한 하네스"입니다. 고정된 언어 모델 M 과 태스크 분포 \mathcal{X} 가 주어졌을 때, 기대 보상을 최대화하는 하네스 H^* 를 찾는 것이 목표입니다:
탐색 루프는 의도적으로 단순하게 설계되었습니다. 매 반복마다 제안자가 파일시스템을 조회하여 이전 하네스들의 코드, 점수, 실행 트레이스를 검토한 뒤, 새로운 하네스를 제안합니다. 평가된 하네스는 소스 코드, 점수, 실행 트레이스를 포함하는 디렉토리로 파일시스템에 저장됩니다. 진단과 제안 결정을 코딩 에이전트 자체에 위임함으로써, 고정된 탐색 휴리스틱에 의존하지 않습니다.
이 단순함은 의도적입니다. 코딩 에이전트가 더 강력해짐에 따라 Meta-Harness도 자동으로 향상될 수 있기 때문입니다. 실제 구현에서 제안자는 Claude Code와 Opus-4.6을 사용하며, 일반적인 실행에서 20 회 반복에 걸쳐 약 60 개의 하네스를 평가합니다.
고정된 기반 모델 (예: Claude, GPT-4o)
↓
[하네스 제안 에이전트 (Claude Code)]
- 새로운 하네스 변형 제안
- 기존 결과 분석 및 개선점 도출
↓
[하네스 평가 루프]
- 제안된 하네스로 태스크 수행
- 성능 지표 측정
- 결과를 제안 에이전트에 피드백
↓
최적화된 하네스 코드
코드 공간 탐색의 이점
하네스 최적화가 코드 공간에서 이루어진다는 점은 중요한 이점을 가져옵니다. 검색, 메모리, 프롬프트 구성 로직에 대한 작은 변경이 여러 단계 이후의 행동에 영향을 미칠 수 있어 로컬 탐색 휴리스틱이 잘 맞지 않는 문제인데, 실행 트레이스를 검토함으로써 제안자는 하네스가 왜 실패했는지, 어떤 초기 설계 선택이 실패에 기여했을 가능성이 있는지를 추론할 수 있습니다. 단순히 실패했다는 사실만 아는 것과는 질적으로 다릅니다.
또한 코딩 모델은 취약한 하드코딩 솔루션보다는 일관된 알고리즘을 제안하는 자연스러운 편향을 가지고 있어, 재사용 가능한 문맥 관리 절차 쪽으로 탐색이 편향됩니다. 이 행동 공간은 프론티어 코딩 어시스턴트가 학습된 읽기-쓰기-실행 워크플로우와 잘 정렬됩니다.
실행 트레이스 접근이 핵심 요소
Meta-Harness 연구자들은 제안자 인터페이스의 어떤 부분이 가장 중요한지를 분리하기 위해 세 가지 조건을 비교했습니다: (1) 점수만 제공하는 조건(scores-only), (2) 점수와 LLM 생성 요약을 제공하는 조건(scores-plus-summary), 그리고 (3) 실행 트레이스에 대한 전체 접근을 허용하는 Meta-Harness 인터페이스입니다.
결과는 명확합니다. 점수만 제공한 경우 중앙값 34.6, 최고 41.3 의 정확도를 기록한 반면, 점수와 요약을 제공한 경우에는 중앙값 34.9, 최고 38.7 에 머물렀습니다. 반면 Meta-Harness는 중앙값 50.0, 최고 56.7 의 정확도를 달성했고, Meta-Harness의 중앙값 후보조차 다른 두 조건의 최고 후보를 앞질렀습니다. 요약은 진단적으로 유용한 세부 정보를 압축해 버림으로써 오히려 성능을 저하시킬 수 있다는 점을 보여줍니다.
실험 결과 및 성능 분석
Meta-Harness는 온라인 텍스트 분류, 수학 추론, 에이전트 코딩의 세 가지 도메인에서 평가되었습니다.
온라인 텍스트 분류
온라인 텍스트 분류 실험에서는 GPT-OSS-120B를 기본 모델로 사용하고, LawBench(215 클래스), Symptom2Disease(22 클래스), USPTO-50k(180 클래스)의 세 데이터셋에서 평가했습니다.
| 하네스 | USPTO | S2D | Law | 평균 정확도 | 문맥 토큰(K) |
|---|---|---|---|---|---|
| Zero-Shot | 12.0 | 63.2 | 7.0 | 27.4 | 0 |
| Few-Shot (8) | 14.0 | 67.9 | 21.0 | 34.3 | 2.0 |
| ACE | 16.0 | 77.8 | 29.0 | 40.9 | 50.8 |
| Meta-Harness | 14.0 | 86.8 | 45.0 | 48.6 | 11.4 |
Meta-Harness는 최신 문맥 관리 시스템인 ACE 대비 평균 7.7 포인트 향상된 정확도를 달성하면서도, 문맥 토큰은 4\times 적게 사용했습니다. 특히 LawBench에서는 29.0 에서 45.0 으로 16 포인트나 향상되었습니다.
기존 텍스트 옵티마이저(OpenEvolve, TTT-Discover)와의 비교에서 Meta-Harness는 0.1\times 의 평가 횟수만으로 동등한 성능에 도달했고, 최종 정확도는 10 포인트 이상 앞섰습니다. 즉, 기존 방법이 60 회 평가가 필요했던 성능을 Meta-Harness는 단 4 회 평가만에 달성한 것입니다. 이는 파일시스템을 통한 풍부한 경험 접근이 외부 루프에 최소한의 구조만 부과하는 설계가 효과적임을 보여줍니다.
Meta-Harness가 발견한 분류 하네스
Meta-Harness가 발견한 가장 강력한 분류 하네스인 Label-Primed Query 전략은 세 부분으로 구성된 단일 프롬프트를 구성합니다. 먼저 유효한 출력 레이블 목록을 보여주는 레이블 프라이머(label primer) 로 시작하고, 각 레이블당 쿼리와 관련된 예시 하나를 포함하는 커버리지 블록(coverage block) 을 추가하며, 마지막으로 서로 다른 레이블을 가진 유사한 예시들을 나란히 배치하는 대조 쌍(contrastive pairs) 을 포함합니다. 검색에는 TF-IDF 유사도와 쿼리 기반 파트너 선택을 사용합니다. 이 전략은 사람이 설계한 것이 아니라 탐색 과정에서 자동으로 발견된 것입니다.
검색 증강 수학 추론
올림피아드 수준의 수학 문제 풀이에서 검색(retrieval)이 도움이 될 수 있다는 이론적 근거는 명확합니다. 풀이 과정에는 재사용 가능한 증명 패턴이 포함되어 있기 때문입니다. 하지만 실제로는 단순한 검색이 추론 집약적인 수학 벤치마크에서 큰 효과를 보이지 못했습니다. 문제는 검색 자체가 아니라 올바른 검색 정책을 발견하는 것입니다.
연구팀은 500{,}000 개 이상의 풀이된 문제로 구성된 검색 말뭉치를 구축하고, Meta-Harness에 어려운 올림피아드 문제 세트를 제공하여 검색 전략이 탐색을 통해 자연스럽게 도출되도록 했습니다. 40 회 반복에 걸쳐 109 개의 후보 검색 하네스가 생성되었습니다.
발견된 하네스는 각 문제를 조합론, 기하학, 정수론, 기본(대수 등)의 네 가지 경로 중 하나로 분류하는 4경로 BM25 프로그램입니다. 각 경로는 해당 분야에 특화된 검색, 재순위, 중복 제거 전략을 사용합니다. 예를 들어 조합론 경로는 BM25로 20 개 후보를 가져와 8 개로 중복 제거한 뒤 어휘 점수와 난이도로 재순위하여 상위 3 개를 반환하고, 기하학 경로는 고정된 NuminaMath 참조 1 개와 BM25 이웃 2 개를 반환합니다.
200 개의 미공개 IMO 수준 문제에서 평가한 결과, 발견된 하네스는 검색 없는 기준선 대비 평균 4.7 포인트 향상을 달성했습니다. 특히 탐색 과정에서 사용되지 않은 5 개의 모델(GPT-5.4-nano, GPT-5.4-mini, Gemini-3.1-Flash-Lite, Gemini-3-Flash 등) 전체에서 일관되게 성능이 향상되어, 발견된 하네스가 특정 모델에 과적합되지 않고 범용적으로 전이 가능함을 보여줍니다.
에이전트 코딩: TerminalBench-2
TerminalBench-2는 89 개의 어려운 태스크에서 LLM 에이전트의 장기적이고 완전 자율적인 실행 능력을 평가하는 벤치마크입니다. 여러 팀이 직접 최적화하고 있는 활발한 경쟁 벤치마크입니다.
| 하네스 (Opus 4.6) | 자동 | 통과율(%) |
|---|---|---|
| Claude Code | x | 58.0 |
| Terminus-KIRA | x | 74.7 |
| ForgeCode | x | 81.8 |
| Meta-Harness | v | \mathbf{76.4} |
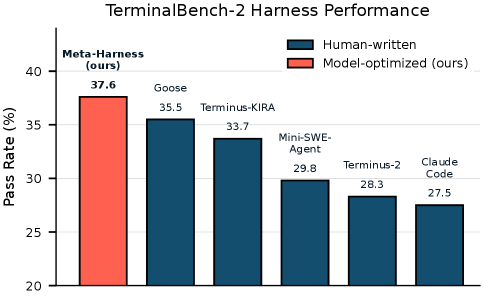
| 하네스 (Haiku 4.5) | 자동 | 통과율(%) |
|---|---|---|
| Claude Code | x | 27.5 |
| Terminus-KIRA | x | 33.7 |
| Goose | x | 35.5 |
| Meta-Harness | v | \mathbf{37.6} |
Opus 4.6에서 Meta-Harness는 76.4\% 통과율을 달성하여 수작업으로 설계된 Terminus-KIRA(74.7\%)를 능가하고 전체 Opus 4.6 에이전트 중 2 위를 기록했습니다. 더 약한 Haiku 4.5 모델에서는 개선 폭이 더 커서, 37.6\% 로 차선인 Goose(35.5\%)를 2.1 포인트 앞서며 Haiku 4.5 에이전트 중 1 위를 달성했습니다.
발견된 하네스의 핵심 수정 사항은 환경 부트스트래핑(environment bootstrapping) 입니다. 에이전트 루프가 시작되기 전에 샌드박스 환경의 스냅샷(작업 디렉토리, 사용 가능한 프로그래밍 언어와 버전, 패키지 매니저, 메모리 등)을 수집하여 초기 프롬프트에 주입합니다. 이를 통해 에이전트가 환경을 탐색하는 데 낭비하던 2~4 턴을 절약하고 즉시 생산적인 작업을 시작할 수 있습니다.
한계점 및 향후 전망
Meta-Harness는 세 가지 다양한 도메인에서 효과를 입증했지만, 현재 실험은 특히 강력한 하나의 코딩 에이전트 제안자(Claude Code)에 의존하고 있습니다. 제안자 에이전트의 종류에 따른 효과 차이에 대한 폭넓은 연구는 향후 과제로 남아 있습니다. 또한 현재 설계에서는 모델 가중치는 고정된 상태에서 하네스만 최적화하고 있는데, 하네스와 모델 가중치를 함께 진화시키는 것도 자연스러운 다음 단계가 될 수 있습니다.
이 연구의 결과는 머신러닝에서 반복적으로 나타나는 패턴을 반영합니다. 탐색 공간이 접근 가능해지면 강력한 범용 에이전트가 수작업 솔루션을 능가할 수 있다는 것입니다. Richard Sutton이 "The Bitter Lesson"에서 지적했듯이, 사람이 설계한 세부 로직보다 범용적 탐색이 결국 더 효과적일 수 있습니다. Meta-Harness는 이 통찰을 하네스 엔지니어링이라는 새로운 영역에 적용하여, 코딩 에이전트의 발전과 함께 자동으로 강해지는 시스템의 가능성을 보여줍니다. 발견된 하네스는 읽기 쉽고, 전이 가능하며, 몇 시간의 탐색만으로 생성됩니다. 이는 하네스 엔지니어링의 자동화가 단순한 비용 절감이 아니라, 사람이 놓칠 수 있는 새로운 전략의 발견으로 이어질 수 있음을 시사합니다.
Meta-Harness의 두 가지 레퍼런스 구현
Meta-Harness 연구진들은 GitHub 저장소에 두 가지 레퍼런스 구현을 공유하였습니다. 아래 예시들은 GitHub 저장소를 복제(clone)하여 곧바로 활용해볼 수 있습니다.
텍스트 분류 + 메모리 시스템 탐색
cd reference_examples/text_classification
uv sync
# 반복 횟수 1회로 실행 (빠른 테스트)
uv run python meta_harness.py --iterations 1
# 더 많은 반복으로 최적화
uv run python meta_harness.py --iterations 10
이 구현에서 Meta-Harness는 텍스트 분류 정확도를 높이기 위한 최적의 메모리 시스템 아키텍처를 자동으로 탐색합니다. 각 반복(iteration)마다 제안 에이전트가 새로운 메모리 시스템 변형을 코드로 작성하고, 실제 분류 태스크에서 성능을 평가한 뒤 결과를 다음 반복의 입력으로 사용합니다.
Terminal-Bench 2.0 + 스캐폴드 진화
cd reference_examples/terminal_bench_2
uv sync
uv run bash scripts/run_eval.sh agents.baseline_kira:AgentHarness full 1 1 -i extract-elf
Terminal-Bench 2.0은 터미널 환경에서 AI 에이전트의 실제 능력을 평가하는 벤치마크입니다. 이 구현에서 Meta-Harness는 에이전트가 터미널 태스크를 수행하는 방식 자체(스캐폴드)를 진화시킵니다. 어떤 도구를 어떤 순서로 호출할지, 중간 결과를 어떻게 저장할지, 오류 발생 시 어떻게 복구할지 등의 전략을 자동으로 최적화합니다.
Meta-Harness를 활용한 커스텀 도메인 적용
레퍼런스 구현의 구조를 따라 새로운 도메인에 Meta-Harness를 적용할 수 있습니다:
from meta_harness import MetaHarness, HarnessEvaluator
# 1. 도메인별 평가 함수 정의
class MyEvaluator(HarnessEvaluator):
def evaluate(self, harness_code: str) -> float:
# harness_code를 실행하고 성능 점수 반환
result = run_harness(harness_code, self.test_cases)
return result.accuracy
# 2. Meta-Harness 실행
mh = MetaHarness(
proposer="claude-code", # 하네스 제안 에이전트
evaluator=MyEvaluator(),
iterations=20, # 탐색 반복 횟수
initial_harness="path/to/initial_harness.py"
)
# 3. 최적화 실행
best_harness = mh.optimize()
print(f"최적 하네스 성능: {best_harness.score:.3f}")
 Meta-Harness: End-to-End Optimization of Model Harnesses 논문
Meta-Harness: End-to-End Optimization of Model Harnesses 논문
 Meta-Harness 프로젝트 홈페이지
Meta-Harness 프로젝트 홈페이지
 Meta-Harness 프로젝트 GitHub 저장소
Meta-Harness 프로젝트 GitHub 저장소
더 읽어보기
-
OpenHarness: Claude Code보다 44배 가벼운 Python 기반 오픈소스 AI 에이전트 하네스 프레임워크 (feat. HKUDS)
-
DeerFlow v2: 리서치, 코딩, 창작 등의 작업을 위한 오픈소스 SuperAgent Harness (feat. ByteDance)
-
Agentic Researcher: 수학 및 머신러닝 분야에서 인공지능 도구들을 활용하는 현실적인 연구 방법에 대한 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()