Cheat on Content 소개
콘텐츠 크리에이터는 대부분 비슷한 루프 위에서 살아갑니다. 감으로 콘텐츠를 발행하고, 데이터를 보고 흥했는지 망했는지를 사후에 알고, 그 이유를 정확히 모른 채 다시 감으로 다음 콘텐츠를 만드는 식입니다. 1년에 200개 글을 써도 처음과 비슷한 수준에 머무르는 이유는 콘텐츠 제작 자체가 캘리브레이션(calibration) 실험으로 설계되어 있지 않기 때문입니다. Cheat on Content 는 이 루프를 "자기 자신만을 위한 운영 전문가"가 함께 도는 의도적 캘리브레이션 루프로 바꾸는 것을 목표로 한 오픈소스 프로젝트입니다.
이 프로젝트의 핵심은 모든 콘텐츠를 발행 전 점수화(score) → 결과를 보지 않고 예측(blind predict) → 발행 → T+3 일 회고(T+3 review) → 평가 공식(rubric) 진화의 다섯 단계 루프로 강제한다는 점입니다. 발행 전에 자기 평가 점수와 예측치를 텍스트로 남기고, 3일 뒤 실제 데이터와 대조하면서 어디서 얼마나 빗나갔는지를 정량적으로 확인합니다. 같은 방향의 오차가 세 번 연속 발생하면 평가 공식 자체를 갱신하도록 도구가 능동적으로 알려주고, 갱신된 공식은 모든 과거 샘플을 다시 채점해서 기존 공식보다 더 정확할 때만 통과시키는 안전장치까지 포함되어 있습니다.
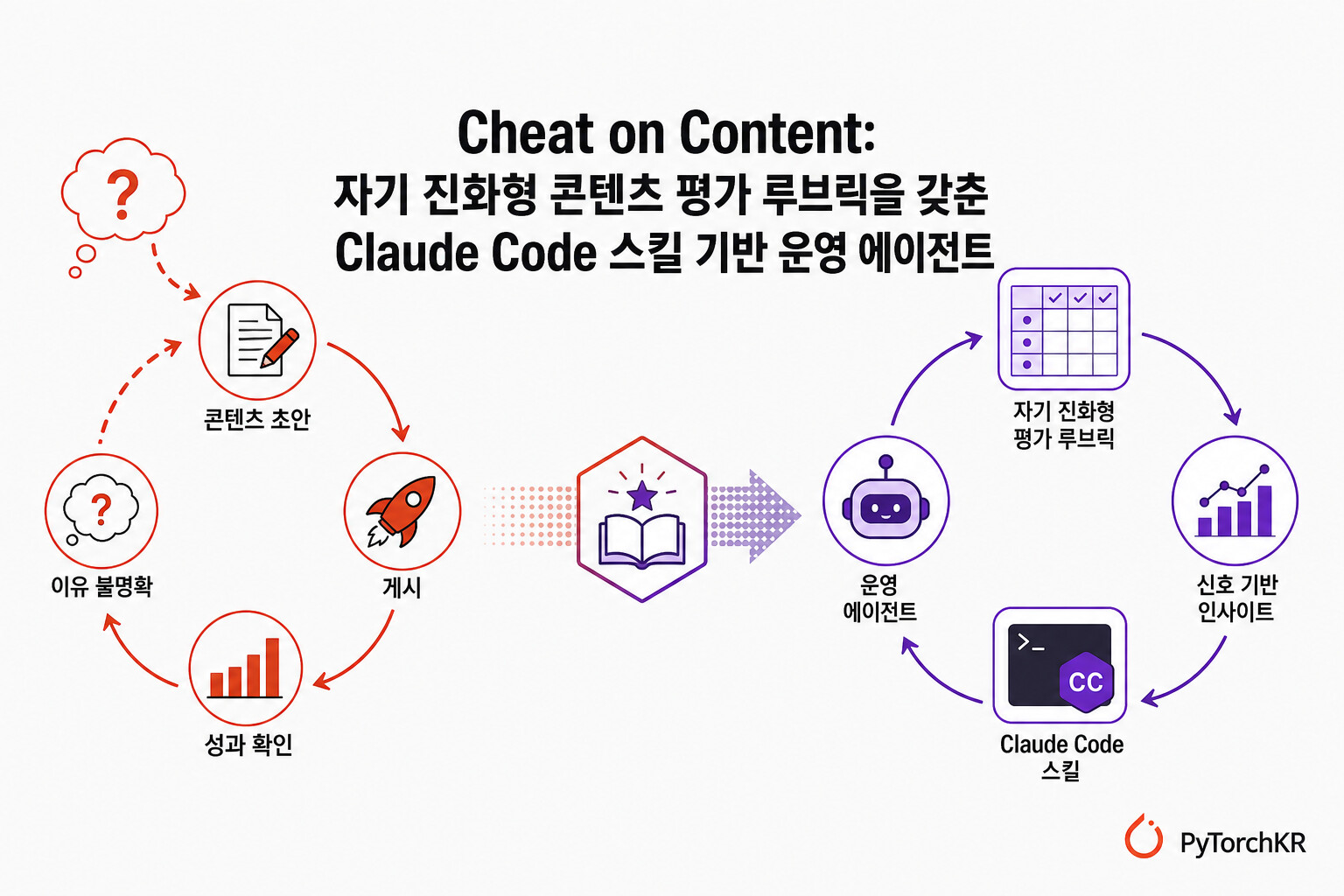
기술 스택 측면에서 Cheat on Content 는 Claude Code 의 Skills 시스템 위에 구현된 13개의 서브 스킬(sub-skill) 묶음입니다. 설치 시 ~/.claude/skills/ 에 13개의 스킬을 심볼릭 링크로 등록하기 때문에, 한 번만 설치하면 어떤 콘텐츠 프로젝트 디렉토리에서도 동일한 워크플로우를 재사용할 수 있습니다. ChatGPT 와 같은 범용 어시스턴트가 모든 사용자에게 동일한 평균적 답변을 주는 것과 달리, Cheat on Content 는 사용자의 과거 콘텐츠와 대상 계정에 점진적으로 맞춰지는 단일 계정 전용 운영 에이전트로 동작하는 것이 차별점입니다.
Cheat on Content와 일반 LLM 어시스턴트의 차이
이 프로젝트는 단순히 "AI 가 글을 대신 써주는" 도구가 아니라 "AI 가 사용자의 판단을 더 정확하게 만드는" 도구를 지향합니다. 이를 위해 평가 공식 자체가 사용자의 데이터로부터 진화하도록 설계되어 있습니다.
감각의 정량화(quantified intuition): 다른 콘텐츠 도구가 영감을 주거나 글을 대신 써주는 데 초점을 맞춘다면, Cheat on Content 는 사용자가 가지고 있는 감각을 점수와 예측이라는 정량적 형태로 기록하게 합니다. 글은 여전히 사용자가 쓰지만, 자신의 직관이 어디서 맞고 어디서 틀리는지를 측정 가능한 형태로 만듭니다.
범용 LLM 대비 단일 계정 특화: 범용 LLM 의 답변은 전체 인터넷의 평균에서 추론되며 같은 질문에 어제와 오늘 다른 답을 줄 수 있습니다. Cheat on Content 는 평가 공식 자체가 사용자의 과거 데이터에서 역으로 도출되며, 새 콘텐츠가 발행될 때마다 사용자의 계정에 대한 이해를 갱신합니다.
자동 진화하는 루브릭: 평가 기준은 정적인 체크리스트가 아니라 시간에 따라 갱신되는 작업 도구입니다. 충분히 의미가 사라진 관찰 항목은 삭제되고, 흡수된 규칙은 새로운 평가 기준으로 통합됩니다. 사용자가 잊고 있어도 도구가 동일 방향 오차의 누적을 감지해 갱신을 권유합니다.
사후 자기 정당화 방지: 평가 공식을 갱신할 때는 새로운 공식으로 모든 과거 샘플을 다시 채점하여 기존 공식보다 누적 오차가 더 작아야 통과시키며, 별도 모델로 한 번 더 교차 검증합니다. 사용자가 자신에게 유리한 방향으로 공식을 임의로 바꾸는 것을 막기 위한 일종의 정당성 게이트(integrity gate)에 해당합니다.
Cheat on Content의 다섯 단계 캘리브레이션 루프
루프의 각 단계는 별도의 서브 스킬로 분리되어 있고, 셸에서 자연어로 호출하면 해당 스킬이 실행됩니다.
1단계 점수화(Score): 점수화 scripts/<...>.md 형태로 호출하면 현재 평가 공식에 따라 콘텐츠 초안의 후보 점수를 계산합니다. 어떤 신호가 점수에 어떻게 기여했는지가 함께 기록됩니다.
2단계 블라인드 예측(Blind predict): 예측 시작 scripts/<...>.md 명령으로 발행 결과(예: 도달, 좋아요, 저장 등)에 대한 예측을 미리 적어 두고 결정 로그(decision log)에 저장합니다. 데이터 수집 이후 자기 정당화를 방지하기 위해 발행 전에 미리 적어 두는 것이 핵심입니다.
3단계 발행(Publish): 실제 발행이 일어나면 버퍼(buffer)와 큐(queue)가 갱신되어 어떤 콘텐츠가 회고를 기다리고 있는지 추적됩니다. 모든 회의(session) 시작 시 훅(hook)이 자동으로 회고 대기 항목과 상위 후보를 보고하기 때문에 별도로 상태를 묻지 않아도 됩니다.
4단계 T+3 일 회고(T+3 review): 발행 후 3 일 시점에 실제 데이터를 회수해 예측치와 대조하고, 어떤 신호가 과대 또는 과소 평가되었는지 정리합니다. 동일한 방향의 오차가 세 번 연속 발생하면 자동으로 평가 공식 갱신이 권유됩니다.
5단계 평가 공식 진화(Evolve rubric): 새 공식이 모든 기존 샘플을 더 정확하게 설명할 때만 채택되며, 별도의 LLM 으로 교차 검증합니다. 추가로 의미가 흐려진 관찰 항목과 흡수된 규칙은 평가 공식에서 제거되어 항상 현재 시점에서 가장 유용한 항목들만 남깁니다.
이 외에도 상태, 핫 토픽 수집, 소재 찾기, 루브릭 갱신, 대상 계정 찾기 같은 보조 스킬이 함께 제공되어 일상적인 콘텐츠 운영을 같은 워크플로우 위에서 수행할 수 있습니다.
Cheat on Content의 Claude Code 스킬 호출 의사코드
이 프로젝트는 Claude Code 의 Skills 시스템을 활용하기 때문에, 사용자는 자연어 명령으로 스킬을 호출하지만 그 내부에서는 결정 로그와 데이터 파일이 일관된 스키마로 관리됩니다. 다음은 회고 단계의 동작을 PyTorch 학습 루프와 비유적으로 정리한 의사코드 예시입니다.
# 발행된 콘텐츠에 대한 T+3 일 회고를 평가 공식 학습 단계로 해석
def review_after_t3(rubric, decision_log, fetched_metrics):
# 1) 사전에 기록된 예측과 실제 측정치 비교
pred = decision_log["blind_prediction"] # 발행 직전에 적어둔 예측
truth = fetched_metrics # T+3 일에 수집된 실제 결과
error = compute_signed_error(pred, truth) # 신호별 오차 (방향 포함)
# 2) 오차의 방향성을 누적해 같은 방향 3연속이면 진화 트리거
rubric.history.append(error)
if same_direction_streak(rubric.history) >= 3:
candidate_rubric = propose_rubric_update(rubric, recent_signals=...)
# 3) 모든 과거 샘플에 새 공식을 다시 적용
if score_all_history(candidate_rubric) < score_all_history(rubric):
# 4) 별도 LLM 으로 교차 심사 — 자기 자신을 속이는 갱신을 막음
if cross_model_audit(candidate_rubric, decision_log):
rubric = candidate_rubric
# 5) 의미를 잃은 관찰 항목과 흡수된 규칙은 정리
rubric = prune_stale_observations(rubric)
return rubric
이는 머신러닝의 학습 루프와 매우 닮아 있습니다. 예측-측정-오차-갱신의 사이클을 사람의 직관에 적용하는 셈이고, 평가 공식이 일종의 모델이 되며 콘텐츠 제작자는 이 모델의 데이터 큐레이터(data curator)로 동작합니다.
Cheat on Content 설치 및 사용법
# 1) 저장소 클론
git clone https://github.com/XBuilderLAB/cheat-on-content.git
cd cheat-on-content
# 2) 설치 스크립트 실행 (~/.claude/skills 에 13개 서브 스킬 등록)
bash install.sh
# 버전을 고정하고 싶으면 심볼릭 링크 대신 복사 설치
# bash install.sh --copy
# 제거 시: bash uninstall.sh (콘텐츠 데이터는 유지)
# 3) 콘텐츠 프로젝트 디렉토리에서 Claude Code 시작
cd /path/to/your-content-project
claude # Claude Code CLI
# 4) Claude Code 안에서 자연어로 초기화
> 초기화 cheat-on-content
# 5개의 yes/no 질문으로 온보딩 완료
저자는 효과를 최대화하기 위해 5~10개의 대상 계정 샘플을 미리 import 할 것을 권장하며, 그렇지 않으면 초기 약 5개 콘텐츠의 예측 정확도가 ±50% 수준에 머물 수 있다고 안내합니다. 즉 도구의 가치를 끌어올리는 데이터 작업은 사용자의 몫이며, 도구는 그 데이터를 평가 공식으로 정제하는 역할을 합니다.
라이선스
Cheat on Content 프로젝트는 MIT 라이선스로 공개되어 있어 상업적 활용, 사내 도구로의 통합, 비공개 변형 모두 허용됩니다. README 의 표현을 빌리면, 평가 공식이 사용자에게 진화하는 자산이라는 점은 주된 가치 제안이며 라이선스는 이를 가로막지 않습니다.
 Cheat on Content 프로젝트 GitHub 저장소
Cheat on Content 프로젝트 GitHub 저장소
더 읽어보기
-
Anthropic, Claude에 업무 방식과 조직 환경에 맞게 직접 커스터마이징할 수 있는 Claude Agent용 Skills 기능 출시
-
Claude Code Templates: 즉시 사용할 수 있는 Claude Code 도구들을 제공하는 오픈소스 CLI 도구 및 템플릿 라이브러리 (feat. aitmpl.com)
-
Everything Claude Code: Anthropic x Forum Ventures 해커톤 우승자가 정리한, Claude Code 실전 설정 및 가이드
-
Claude Code Showcase: Anthropic의 Claude Code 활용을 위한 설정 및 워크플로우 템플릿 프로젝트
-
Planning with Files: Markdown 파일을 에이전트의 작업 기억으로 사용하는 Manus의 동작 방식을 Claude에 적용한 Skill
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()