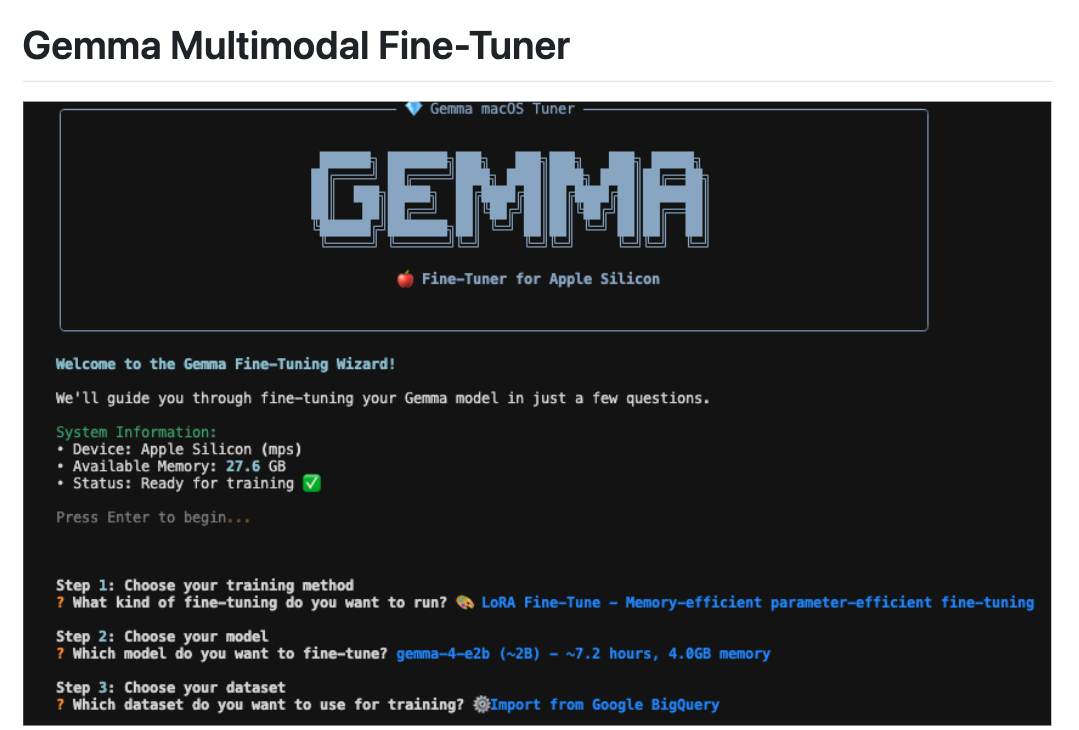
Gemma Multimodal Fine-Tuner 프로젝트 소개
대규모 언어 모델(Large Language Model)을 나만의 데이터로 파인튜닝(fine-tuning)하고 싶지만 NVIDIA GPU가 없다면 어떻게 해야 할까요? Apple Silicon Mac을 보유한 개발자와 연구자라면 이 고민에 익숙할 것입니다. Gemma Multimodal Fine-Tuner은 바로 이 문제를 해결하기 위해 만들어진 오픈소스 파인튜닝 프레임워크입니다.
PyTorch와 Metal Performance Shaders(MPS)를 기반으로, M1/M2/M3/M4/M5 등과 같은 Apple Silicon 기기에서 NVIDIA GPU 없이 Google의 Gemma 3n 및 Gemma 4 모델을 텍스트, 이미지, 오디오 세 가지 모달리티(modality)로 동시에 파인튜닝할 수 있습니다. 기존에는 멀티모달 LLM 파인튜닝이 클라우드 GPU 환경이나 고가의 NVIDIA 워크스테이션에서만 가능했지만, 이 프로젝트 덕분에 Mac 한 대로도 본격적인 멀티모달 파인튜닝 실험이 가능해집니다.
Gemma Multimodal Fine-Tuner 프로젝트의 핵심은 LoRA(Low-Rank Adaptation) 기법을 활용한 파라미터 효율적 파인튜닝(Parameter-Efficient Fine-Tuning, PEFT)입니다. 모델 전체를 다시 학습하는 대신, 소수의 추가 파라미터만 학습하여 특정 도메인이나 작업에 모델을 적응시킵니다.
덕분에 16GB RAM의 MacBook Air에서도 Gemma 3n E2B(약 2B 파라미터) 모델을 학습시킬 수 있으며, 32GB 이상의 RAM이 탑재된 MacBook Pro나 Mac Studio에서는 더 큰 E4B 모델도 안정적으로 실행됩니다.
Gemma Multimodal Fine-Tuner이 지원하는 모달리티 및 모델
| This | MLX-LM | Unsloth | axolotl | |
|---|---|---|---|---|
| Fine-tune Gemma (text-only CSV) | ||||
| Fine-tune Gemma image + text (caption / VQA CSV) | ||||
| Fine-tune Gemma audio + text | ||||
| Runs on Apple Silicon (MPS) | ||||
| Stream training data from cloud | ||||
| No NVIDIA GPU required |
Gemma Multimodal Fine-Tuner이 지원하는 학습 가능한 모달리티는 세 가지입니다:
첫째로 이미지+텍스트 LoRA는 이미지 캡셔닝(captioning)과 시각적 질의응답(Visual Question Answering, VQA) 작업을 지원합니다. 이미지 파일과 텍스트 레이블을 CSV 형식으로 제공하면 Gemma 4의 비전 인코더와 언어 디코더를 함께 LoRA로 적응시킵니다.
둘째로 오디오+텍스트 LoRA는 Apple Silicon 네이티브(native)로 동작하는 자동 음성 인식(Automatic Speech Recognition, ASR) 적응 학습을 제공합니다. Gemma 3n과 Gemma 4에 포함된 USM(Universal Speech Model) 오디오 타워를 파인튜닝하여 특정 도메인이나 언어에 최적화된 음성 인식 모델을 만들 수 있습니다.
셋째로 텍스트 전용 LoRA는 지시 튜닝(instruction tuning)과 완성 모드(completion mode) 두 가지 방식을 지원합니다.
Gemma Multimodal Fine-Tuner가 지원하는 모델은 다음과 같습니다:
Model key (in config/config.ini) |
Hugging Face base_model |
Notes |
|---|---|---|
gemma-4-e2b-it |
google/gemma-4-E2B-it |
Gemma 4 instruct, ~2B — requires requirements/requirements-gemma4.txt (see Installation) |
gemma-4-e4b-it |
google/gemma-4-E4B-it |
Gemma 4 instruct, ~4B — requires Gemma 4 stack |
gemma-4-e2b |
google/gemma-4-E2B |
Gemma 4 base — requires Gemma 4 stack |
gemma-4-e4b |
google/gemma-4-E4B |
Gemma 4 base — requires Gemma 4 stack |
gemma-3n-e2b-it |
google/gemma-3n-E2B-it |
Gemma 3n instruct, ~2B — default on the base pip install -e . pin |
gemma-3n-e4b-it |
google/gemma-3n-E4B-it |
Gemma 3n instruct, ~4B |
[model:커스텀이름] 섹션에 group = gemma를 설정하면 다른 E2B–E4B 체크포인트도 추가할 수 있어 확장성이 높습니다.
Gemma Multimodal Fine-Tuner의 아키텍처
프로젝트의 핵심 컴포넌트 구조는 다음과 같습니다:
gemma_tuner/
├── cli_typer.py ← 메인 CLI 진입점 (gemma-macos-tuner)
├── core/
│ └── ops.py ← prepare → finetune → evaluate → export 라우팅
├── scripts/
│ └── finetune.py ← Gemma 특화 훈련 로직으로의 라우터
├── utils/
│ └── device.py ← MPS/CUDA/CPU 선택 및 메모리 관리
└── wizard/ ← Rich 기반 인터랙티브 설정 UI
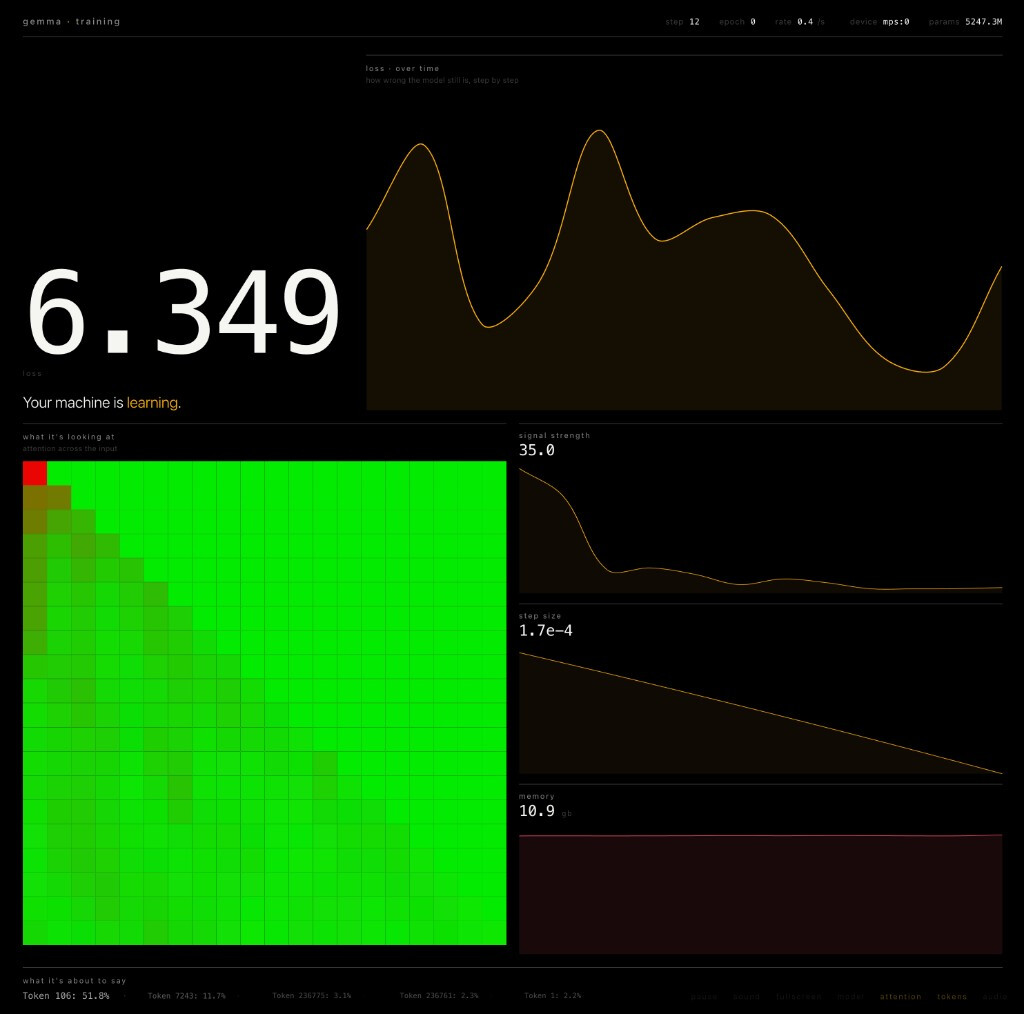
학습 결과는 output/{id}-{profile}/ 디렉터리에 저장되며, metadata.json, metrics.json, 체크포인트, LoRA 어댑터 아티팩트를 포함합니다. evaluate 명령으로 훈련된 어댑터의 성능을 평가하고, export 명령으로 LoRA 가중치를 기반 모델에 병합(merge)하여 Hugging Face/SafeTensors 형식으로 내보낼 수 있습니다.
Gemma Multimodal Fine-Tuner 설치 및 사용법
Gemma Multimodal Fine-Tuner 설치를 및 사용을 위해서는 Python 3.10 이상, macOS 12.3 이상(Native-ARM64용 Python), 16GB 이상의 RAM이 필요합니다. CUDA는 선택 사항입니다.
# 1. Python 3.12 가상 환경 생성
brew install python@3.12
python3.12 -m venv .venv
source .venv/bin/activate
# 2. arm64 아키텍처 확인
python -c "import platform; print(platform.machine())"
# arm64 출력 → 정상
# 3. PyTorch 설치 (MPS 지원 포함)
pip install torch torchaudio
# 4. 패키지 설치
pip install -e .
# 5. Hugging Face 인증 (Gemma 모델 접근 필요)
huggingface-cli login
# 6. Gemma 4 지원 추가 설치 (선택)
pip install -r requirements/requirements-gemma4.txt
설치 후에는 저장소에 포함된 샘플 텍스트 데이터셋(16개 훈련 + 5개 검증 예시)으로 바로 실행해볼 수 있습니다:
# 인터랙티브 위저드 실행
gemma-macos-tuner wizard
# 또는 직접 파인튜닝
gemma-macos-tuner finetune sample-text
학습 데이터 형식
모든 학습 데이터는 data/datasets/<이름>/train.csv와 validation.csv 파일로 제공합니다:
텍스트 지시 튜닝 (프롬프트는 손실에서 마스킹):
id,prompt,response
1,"Translate to French: Good morning.","Bonjour."
2,"What is the capital of Japan?","Tokyo."
이미지 캡셔닝:
id,image_path,caption
1,images/receipt_001.jpg,"Total: $42.18, paid in cash"
오디오+텍스트 (16kHz 모노 WAV 형식):
id,audio_path,text,language,duration
1,audio/sample_001.wav,"the quick brown fox...",en,2.4
주요 CLI 명령어
gemma-macos-tuner prepare <dataset-profile> # 데이터셋 준비
gemma-macos-tuner finetune <profile> # 파인튜닝 실행
gemma-macos-tuner evaluate <profile-or-run> # 성능 평가
gemma-macos-tuner export <run-dir-or-profile> # LoRA 병합 후 내보내기
gemma-macos-tuner runs list # 실행 이력 조회
gemma-macos-tuner wizard # 인터랙티브 설정 UI
Apple Silicon 최적화 팁
MPS를 최대한 활용하기 위해 bf16 사용을 권장하며, 메모리 안정성을 위해 어텐션 모드는 eager로 강제 설정됩니다. 디버깅 후에는 PYTORCH_ENABLE_MPS_FALLBACK=1 환경 변수를 해제하여 무음 CPU 폴백(fallback)을 방지하는 것이 중요합니다. python -m gemma_tuner.scripts.gemma_preflight 명령으로 시스템 점검을, python -m gemma_tuner.scripts.gemma_profiler --model google/gemma-3n-E2B-it로 메모리 예상치를 미리 확인할 수 있습니다.
라이선스
Gemma Multimodal Fine-Tuner 프로젝트는 MIT 라이선스로 공개되어 있습니다. 단, 학습 시 사용하는 모델 및 학습 데이터는 각 모델 및 학습 데이터의 라이선스를 따릅니다.
 Gemma Multimodal Fine-Tuner 프로젝트 GitHub 저장소
Gemma Multimodal Fine-Tuner 프로젝트 GitHub 저장소
더 읽어보기
-
Google DeepMind, 모바일 기기부터 클라우드까지 사용 가능한, 통합 멀티모달 모델 Gemma 4 공개
-
mlx-vlm: M5와 같은 Apple Silicon에 최적화된 MLX 기반 시각-언어 모델(VLM) 추론 및 파인튜닝 도구
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()