
Gemma 4 소개
구글 딥마인드(Google DeepMind)는 지난 밤, 자사의 가장 지능적이고 강력한 개방형 모델(Open Weights Models)인 Gemma 4 라인업을 공식 발표했습니다. 이 모델은 업계를 선도하는 Gemini 3을 기반으로 최신 연구 및 아키텍처를 동일하게 기반으로 구축되어, 파라미터 당 최고 수준의 지능(Intelligence-per-parameter)을 제공합니다.
기존의 단순한 챗봇이나 텍스트 생성의 역할을 넘어서 복잡한 논리 연산과 에이전트 기반 워크플로우(Agentic workflows)를 자체적으로 처리하도록 특수 목적으로 설계되었습니다. 사전 학습(Pre-trained) 및 명령어 미세조정(Instruction-tuned)이 완료된 오픈 웨이트(Open-weights) 형태로 제공되어 전 세계의 개발자와 연구자들이 자유롭게 접근할 수 있습니다. 이를 통해 개발자는 데이터, 모델, 인프라에 대한 완전한 제어권을 확보하며 완벽한 디지털 주권(Digital sovereignty)을 실현할 수 있습니다.

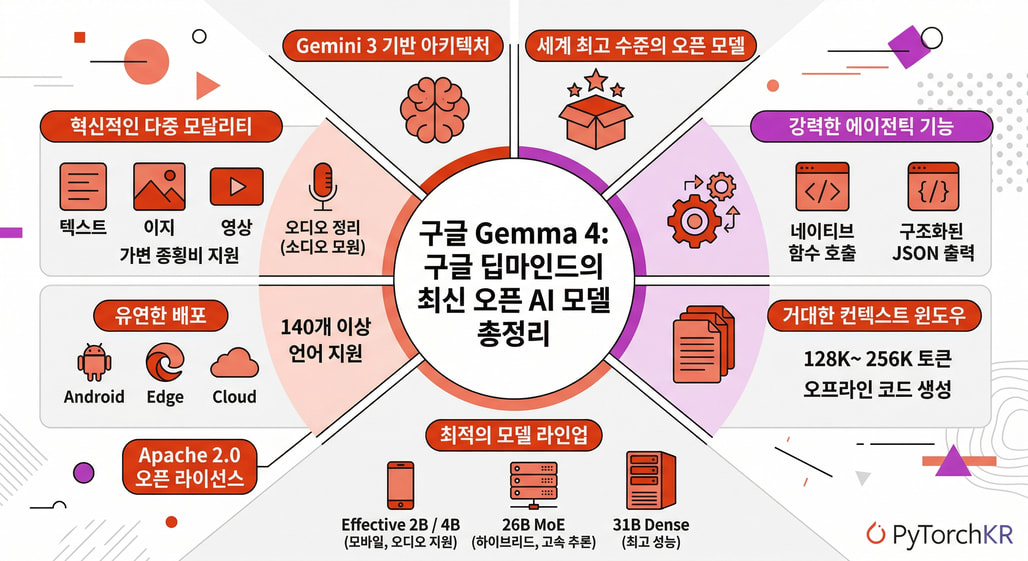
Gemma 4는 텍스트와 이미지뿐만 아니라 비디오와 오디오까지 다방면으로 처리할 수 있는 강력한 다중 모달리티(Multimodality)를 지원합니다. 모든 모델 라인업이 가변 종횡비(Variable aspect ratio)와 다양한 해상도를 기본적으로 지원하여 광학 문자 인식(OCR)이나 복잡한 차트 이해와 같은 고급 시각적 작업에서 탁월한 성능을 발휘합니다. 또한, 한국어를 포함하여 140개 이상의 폭넓은 언어를 지원하여 글로벌 애플리케이션 개발에 있어 언어의 장벽을 혁신적으로 낮추었습니다.
소형 모델 기준으로 128K, 대형 모델의 경우 최대 256K 토큰 규모의 컨텍스트 윈도우를 확보하여, 방대한 코드베이스나 거대한 문서 세트를 단 한 번의 프롬프트만으로 분석하고 이해할 수 있습니다. 이러한 다중 입력 방식을 바탕으로 고품질의 오프라인 코드 생성을 지원하며, 사용자의 로컬 워크스테이션을 강력한 AI 코드 어시스턴트로 탈바꿈시킵니다.
Gemma 4 모델은 활용 목적과 가용 하드웨어 환경에 맞추어 유연하게 배포될 수 있도록 세심하게 크기가 조정되었습니다. 전 세계 수십억 대의 안드로이드(Android) 스마트폰부터 엣지 디바이스, 소비자용 랩톱 GPU는 물론, 클라우드 인프라와 고성능 워크스테이션에 이르기까지 거의 모든 환경에서 고효율의 추론(Inference)이 가능합니다.
특히, 구글 클라우드(Google Cloud)의 Cloud Run 환경에서는 96GB의 vGPU 메모리를 갖춘 NVIDIA RTX PRO 6000 (Blackwell)과 같은 최상위 서버리스 GPU를 활용하여 대규모 워크로드를 매끄럽게 소화할 수 있습니다. 결과적으로 엔터프라이즈 기업과 주권(Sovereign) 조직들은 엄격한 보안 요건과 규정을 완벽하게 준수하면서도 최첨단 AI 기술을 안전하게 도입할 수 있게 되었습니다.
Gemma 3와의 비교
직전 세대인 Gemma 3 역시 140개 이상의 폭넓은 언어를 지원하고 함수 호출 기능을 갖추었으며, 128K의 방대한 컨텍스트 윈도우를 제공하여 업계에 큰 반향을 일으켰습니다. 하지만 이번 Gemma 4 라인업은 이전 버전을 단순히 개선한 것을 넘어 다음과 같은 기술적인 대도약을 이뤄냈습니다:
-
완전한 멀티모달리티 통합 및 오디오/비디오 지원: Gemma 3가 주로 텍스트와 이미지 처리에 집중했다면, Gemma 4는 라인업 내의 모든 모델이 영상(Video) 입력을 직접 처리합니다. 더욱 혁신적인 점은 소형 모델인 E2B와 E4B가 별도의 음성 변환기(STT/TTS) 없이도 네이티브 오디오(Audio) 입력을 직접 이해하여 모바일 기기에서의 실시간 음성 인식 및 번역 성능을 극적으로 끌어올렸다는 것입니다.
-
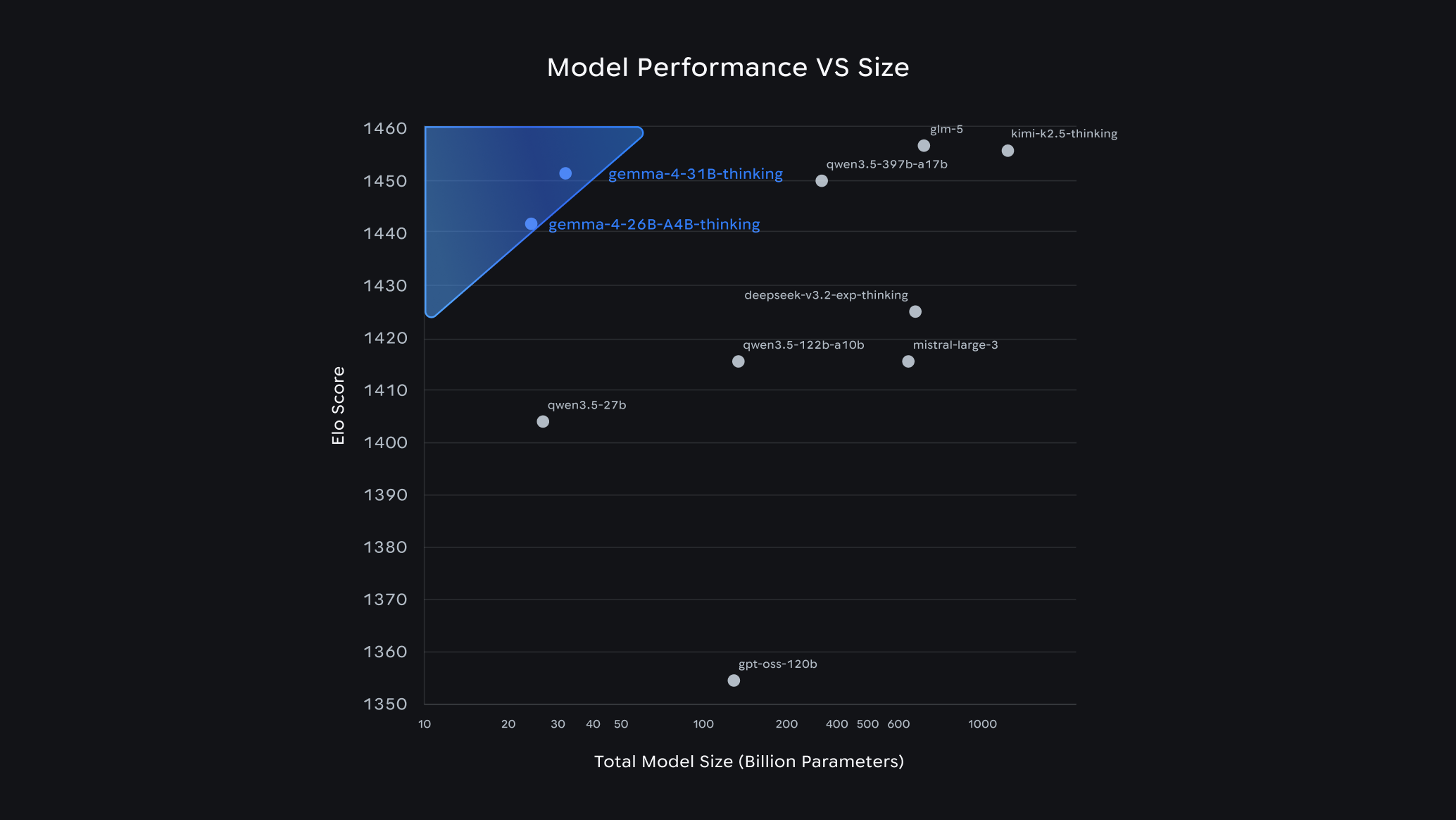
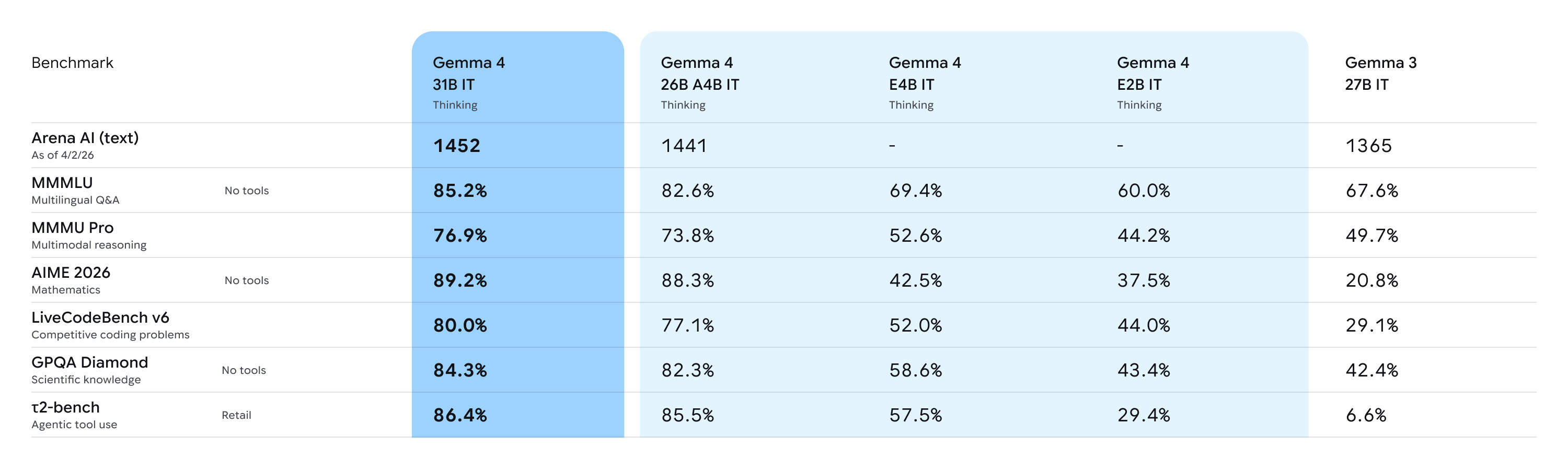
압도적인 컨텍스트 확장과 벤치마크 성능: 최대 컨텍스트 윈도우가 128K에서 256K로 두 배나 확장되어, 방대한 코드베이스나 복잡한 엔터프라이즈 문서를 한 번의 프롬프트만으로 손실 없이 분석할 수 있습니다. 특히 31B 파라미터 모델의 경우, 전 세계 오픈 모델의 성능을 평가하는 Arena AI 텍스트 리더보드에서 3위에 오르며 자신보다 20배 이상 큰 거대 모델들을 압도하는 저력을 증명했습니다.
-
새로운 아키텍처 도입: 단일 밀집(Dense) 신경망으로만 구성되었던 과거와 달리, 이번 버전에서는 26B 크기의 혼합 전문가(Mixture of Experts) 아키텍처를 새롭게 도입하여 메모리 효율성과 추론 속도의 최적점을 완벽하게 구현했습니다.
Gemma 4 상세 분석 및 주요 특징

목적과 환경에 맞춘 4가지 맞춤형 모델 라인업
Gemma 4는 개발자가 배포하려는 하드웨어 환경과 가용 자원, 그리고 해결하고자 하는 문제의 복잡도에 맞추어 가장 효율적인 옵션을 선택할 수 있도록 설계되었습니다.
-
Effective 2B (E2B): 최대의 처리 속도와 극단적으로 낮은 지연 시간(Low-latency)을 목표로 최적화된 초경량 모델입니다. 상위 모델인 E4B보다 최대 3배 빠른 추론 속도를 자랑하며, 4-bit 양자화(Quantization)를 적용할 경우 약 5GB의 RAM만으로도 안드로이드 기기나 라즈베리파이 같은 엣지 환경에서 부드럽게 구동됩니다.
-
Effective 4B (E4B): E2B의 빠른 속도를 유지하면서도 더 높은 수준의 추론 능력과 복잡한 작업 처리를 요구하는 모바일 환경에 적합하도록 균형을 맞춘 모델입니다.
-
26B Mixture of Experts (MoE / 26B-A4B): 총 260억 개의 파라미터를 보유하고 있지만, 추론 시에는 필요한 특정 전문가 모듈(약 38억 개 파라미터)만 선택적으로 활성화하는 MoE 모델입니다. 방대한 지식을 유지하면서도 연산 속도를 비약적으로 높여 Arena AI 6위를 기록했습니다.
-
31B Dense: Gemma 4 라인업의 플래그십 모델로 가장 높은 밀도의 지능을 제공합니다. 고사양 워크스테이션이나 클라우드 GPU(예: Google Cloud Run 환경)에 최적화되어 있으며, 복잡한 로직 설계 및 고품질 오프라인 코드 생성을 완벽하게 수행합니다.
차세대 멀티모달 및 시각/청각 정보 처리 역량
Gemma 4는 텍스트를 넘어 현실 세계의 다양한 시각 및 청각 데이터를 하나의 프롬프트 내에서 매끄럽게 융합하여 분석합니다:
-
가변 해상도 이미지 및 비디오 네이티브 처리: 4개의 모든 모델 라인업이 고정되지 않은 다양한 해상도와 종횡비의 이미지 및 비디오(MP4, WebM 파일)를 기본적으로 지원합니다. 특히 복잡한 구조의 광학 문자 인식(OCR)과 수치가 혼재된 차트 해석에 있어 업계 최고 수준의 정확도를 보여줍니다.
-
에지 디바이스 특화 네이티브 오디오 (E2B & E4B): 모바일에 특화된 두 소형 모델은 오디오 파형을 즉각적으로 이해하여 자동 음성 인식(ASR)과 실시간 다국어 음성 번역 작업을 로컬 환경에서 지연 없이 수행해 냅니다.
-
다국어 능력: 전 세계 140개 이상의 언어를 유창하게 처리합니다.
아키텍처 및 메모리 최적화
-
확장된 컨텍스트 윈도우: 모델에 따라 128K에서 최대 256K에 달하는 방대한 토큰 길이를 지원합니다.
-
p-RoPE 아키텍처 적용: 긴 컨텍스트를 처리할 때 발생하는 메모리 병목 현상을 해결하기 위해, 전역 레이어(Global layers)에 Unified Keys and Values를 도입하고 Proportional RoPE (p-RoPE) 기술을 적용하여 메모리 효율을 극대화했습니다.
로컬 에이전트 생태계 구축 (Agentic Workflows)
이번 Gemma 4 공개의 핵심 테마 중 하나는 단순히 질문에 답하는 것을 넘어, 스스로 문제를 분해하고 외부 도구를 사용하는 자율 AI 시스템(Agentic AI System)의 구축입니다:
-
Android Studio와 결합된 로컬 코딩: Gemma 4는 Android Studio 내부에 완벽히 통합되어 로컬 최우선(Local-first) AI 코드 어시스턴트로 작동합니다. 클라우드에 민감한 소스코드를 전송할 필요 없이, 오프라인 상태에서도 레거시 코드의 리팩토링이나 새로운 기능의 반복적인 구축을 모델이 직접 수행합니다.
-
ADK 및 구조화된 도구 호출(Tool Calling): 모델 내부에 구조화된 JSON 출력 기능과 함수 호출(Function Calling) 기능이 기본적으로 정교하게 학습되어 있습니다. 구글의 에이전트 개발 키트(Agent Development Kit, ADK)와 결합하면 누구나 손쉽게 외부 API와 연동되는 강력한 자율 에이전트를 개발할 수 있습니다.
빠르고 유연한 오픈소스 생태계 통합 (Hugging Face & Unsloth)
Gemma 4는 구글 자체 클라우드뿐만 아니라 Hugging Face 생태계 및 Unsloth Studio와의 긴밀한 협력을 통해 오픈소스 개발자들이 가장 친숙한 방식으로 모델에 접근할 수 있도록 돕습니다.
MacOS 및 GGUF/MLX 환경 설정 예시: Unsloth가 제공하는 스크립트를 통해 MacOS의 MLX 환경에서도 최적화된 Gemma 4를 단 몇 줄의 터미널 명령어로 빠르게 로드하고 테스트해 볼 수 있습니다.
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/install_gemma4_mlx.sh | sh
source ~/.unsloth/unsloth_gemma4_mlx/bin/activate
이외에도 허깅페이스 허브를 통해 원본 google/gemma-4-31B-it 모델은 물론, 엔비디아가 상업적 배포를 위해 고도로 양자화한 nvidia/Gemma-4-31B-IT-NVFP4 버전 등 다양한 선택지를 자유롭게 활용할 수 있습니다.
Gemma 4 성능 벤치마크
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B (no think) |
|---|---|---|---|---|---|
| Reasoning & Knowledge | |||||
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| AIME 2026 no tools | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| Tau2 (average over 3) | 76.9% | 68.2% | 42.2% | 24.5% | 16.2% |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 21.9% | 19.3% |
| MMMLU | 88.4% | 86.3% | 76.6% | 67.4% | 70.7% |
| Coding | |||||
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| HLE no tools | 19.5% | 8.7% | - | - | - |
| HLE with search | 26.5% | 17.2% | - | - | - |
| Vision | |||||
| MMMU Pro | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% |
| OmniDocBench 1.5 (edit distance) | 0.131 | 0.149 | 0.181 | 0.290 | 0.365 |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% | 46.0% |
| MedXPertQA MM | 61.3% | 58.1% | 28.7% | 23.5% | - |
| Audio | |||||
| CoVoST | - | - | 35.54 | 33.47 | - |
| FLEURS (lower is better) | - | - | 0.08 | 0.09 | - |
| Long Context | |||||
| MRCR v2 8 needle 128k (average) | 66.4% | 44.1% | 25.4% | 19.1% | 13.5% |
Gemma 4 Good Challenge
구글은 개발자 커뮤니티가 기술을 통해 긍정적인 사회적 변화를 이끌어 낼 수 있도록 Kaggle에서 Gemma 4 Good Challenge를 개최합니다. 이 대회를 통해 개발자들은 의미 있는 제품을 구축하고 혁신적인 아이디어를 경쟁할 수 있습니다.
Gemma 4 시작하기
Gemma 4 모델은 대중적으로 사용되는 Hugging Face의 최신 transformers 라이브러리를 통해 즉각적으로 사용할 수 있습니다. Gemma 4 모델을 사용하기 위해서는 먼저 아래 의존성 설치가 필요합니다:
pip install -U transformers torch accelerate
또한, Google DeepMind의 공식 gemma JAX 라이브러리를 통해서도 모델을 로드하고 미세 조정(Fine-tuning)할 수 있습니다. JAX 환경을 구성한 후 아래와 같이 설치합니다.
pip install gemma
다음과 같이 직접 Hugging Face TRL 라이브러리를 사용한 Vertex AI에서의 파인튜닝을 위한 예시도 제공하고 있으니, 참고해주세요:
그 외에도 Unsloth Studio를 사용하여 직접 로컬에서 GUI 기반으로 파인튜닝을 시도하거나, Google Colab에서 파인튜닝을 진행해볼 수도 있습니다:
 Gemma 공식 홈페이지
Gemma 공식 홈페이지
 Google DeepMind의 Gemma 4 출시 블로그
Google DeepMind의 Gemma 4 출시 블로그
HuggingFace의 Gemma 4 출시 블로그
 Gemma 4 모델 다운로드
Gemma 4 모델 다운로드
 Gemma 프로젝트 GitHub 저장소
Gemma 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()