
OmniVoice 소개
음성 합성(Text-to-Speech, TTS) 기술은 최근 몇 년간 눈부신 발전을 이루어 왔습니다만, 대부분의 모델은 영어 또는 소수의 고자원 언어에 집중되어 있어 전 세계 언어 다양성을 충분히 반영하지 못한다는 한계가 있었습니다. 또한 특정 화자의 목소리를 복제하거나 세밀하게 조절하는 기능은 대규모 학습 데이터와 복잡한 파이프라인을 필요로 했습니다.
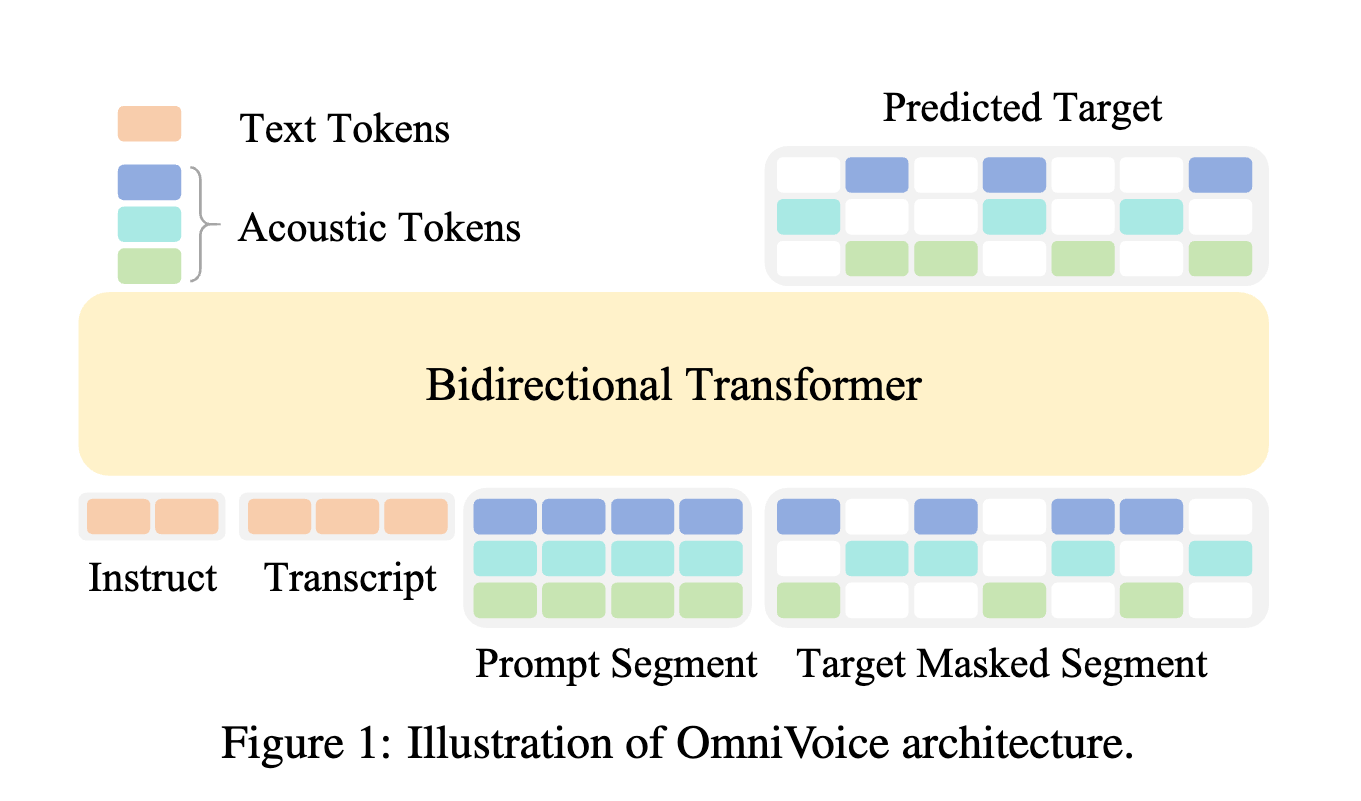
이러한 맥락에서 k2-fsa 팀이 공개한 OmniVoice는 단순화된 확산 언어 모델(Diffusion Language Model) 아키텍처를 기반으로 600개 이상의 언어를 지원하며, 제로샷(zero-shot) 음성 복제와 음성 디자인을 동시에 제공하는 오픈소스 TTS 시스템입니다. OmniVoice는 현재 공개된 제로샷 TTS 모델 중 가장 광범위한 언어 커버리지를 목표로 설계되었으며, PyPI를 통해 손쉽게 설치하고 활용할 수 있다는 점에서 실용성이 높습니다.
OmniVoice의 가장 큰 특징 중 하나는 뛰어난 추론 속도입니다. 실시간 배율 지수(Real-Time Factor, RTF)가 0.025에 불과하여 실시간 대비 40배 빠른 속도로 음성을 생성할 수 있습니다. 이는 단순한 수치가 아니라, 배치 처리나 실시간 응용 서비스에서 실질적으로 활용 가능한 수준의 성능을 의미합니다. 모델은 ArXiv 논문(2604.00688)과 함께 HuggingFace에 모델 가중치와 데모 스페이스가 공개되어 있어, 연구자부터 실무 개발자까지 폭넓게 활용할 수 있습니다.
OmniVoice의 세 가지 음성 생성 모드
OmniVoice는 크게 세 가지 방식으로 음성을 생성할 수 있습니다. 첫 번째는 음성 복제(Voice Cloning) 모드로, 참조 음성 파일을 제공하면 해당 화자의 목소리로 원하는 텍스트를 읽어줍니다. 두 번째는 음성 디자인(Voice Design) 모드로, 성별, 나이, 음조, 억양, 방언, 속삭임 효과 등 속성을 텍스트로 지정하여 새로운 목소리를 생성할 수 있습니다. 세 번째는 자동 음성 생성(Auto Voice) 모드로, 참조 음성이나 속성 지정 없이도 텍스트만 입력하면 자동으로 적절한 목소리로 음성을 생성합니다. 이 세 모드는 아래와 같이 Python API를 통해 간결하게 사용할 수 있습니다.
from omnivoice import OmniVoice
model = OmniVoice.from_pretrained("k2-fsa/OmniVoice", device_map="cuda:0")
# 음성 복제: 참조 음성 파일과 텍스트 제공
audio = model.generate(
text="Hello, this is a test of zero-shot voice cloning.",
ref_audio="ref.wav",
ref_text="Transcription of the reference audio."
)
# 음성 디자인: 속성 텍스트로 목소리 설계
audio = model.generate(
text="Hello, this is a test of zero-shot voice design.",
instruct="female, low pitch, british accent"
)
# 자동 생성: 텍스트만으로 음성 생성
audio = model.generate(text="This is a sentence without any voice prompt.")
음성 복제 시 ref_text를 직접 제공하지 않아도, Whisper ASR을 통해 자동으로 참조 텍스트를 인식할 수도 있습니다. 음성 디자인에서 지원하는 속성으로는 성별(남성/여성), 나이(어린이/성인/노인), 음조(높음/중간/낮음), 스타일(속삭임 등), 영어 억양(미국/영국/호주/인도 등), 중국어 방언 등이 있습니다.
OmniVoice의 고급 기능
OmniVoice는 단순한 텍스트-음성 변환을 넘어 다양한 고급 기능을 제공합니다. 비언어적 표현(Non-verbal Elements) 기능을 통해 텍스트 내에 [laughter], [sigh], [sniff] 등의 태그를 삽입하면 웃음, 한숨, 코웃음 소리를 자연스럽게 삽입할 수 있습니다. 발음 제어 기능은 중국어의 경우 핀인(Pinyin)과 성조 번호를, 영어의 경우 CMU 발음사전 형식을 사용하여 특정 단어의 발음을 교정할 수 있습니다. 이 밖에도 생성 파라미터를 통해 확산 반복 횟수(num_step), 말하기 속도(speed), 출력 길이(duration) 등을 세밀하게 조절할 수 있습니다.
커맨드라인 도구도 세 가지 방식으로 제공됩니다. omnivoice-demo는 Gradio 기반의 웹 인터페이스를 실행하고, omnivoice-infer는 단일 샘플 추론에, omnivoice-infer-batch는 다중 GPU를 활용한 배치 추론에 사용됩니다. 특히 배치 처리 시 JSONL 형식의 입력 파일을 사용하여 대규모 음성 생성 작업을 효율적으로 처리할 수 있습니다.
OmniVoice 설치 방법
OmniVoice는 PyPI를 통해 간단히 설치할 수 있습니다. PyTorch 2.8.0 이상(NVIDIA GPU 또는 Apple Silicon 모두 지원)을 사전에 설치한 뒤 아래 명령어를 실행하면 됩니다.
pip install omnivoice
또는 소스에서 직접 설치하거나 UV 패키지 매니저를 사용할 수도 있습니다.
# GitHub 소스에서 설치
pip install git+https://github.com/k2-fsa/OmniVoice.git
# UV 패키지 매니저 사용
git clone https://github.com/k2-fsa/OmniVoice.git
cd OmniVoice
uv sync
웹 데모 인터페이스를 실행하려면 다음 명령어를 사용하면 됩니다.
omnivoice-demo --ip 0.0.0.0 --port 8001
라이선스
이 프로젝트는 Apache 2.0 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용, 수정, 배포할 수 있습니다.
 OmniVoice 데모
OmniVoice 데모
 OmniVoice 문서 사이트
OmniVoice 문서 사이트
 OmniVoice 논문
OmniVoice 논문
 OmniVoice 프로젝트 GitHub 저장소
OmniVoice 프로젝트 GitHub 저장소
 OmniVoice 모델 다운로드
OmniVoice 모델 다운로드
더 읽어보기
-
VibeVoice: 60분 장시간 음성 인식(ASR)과 실시간 TTS를 통합한 Microsoft의 오픈소스 음성 AI 모델 패밀리
-
KG-Whisper: 키워드 가이드(KG)를 통한 음성 인식(ASR) 최적화 구현 프로젝트 (feat. @hyuk님)
-
Cohere, HuggingFace Open ASR 리더보드 1위를 차지한 오픈소스 음성 인식 모델 Transcribe 공개
-
Google DeepMind, 모바일 기기부터 클라우드까지 사용 가능한, 통합 멀티모달 모델 Gemma 4 공개
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()