
Gemma 4 12B 소개
Google DeepMind가 2026년 6월 3일, Gemma 4 모델군의 새로운 중간 크기 모델인 Gemma 4 12B를 공개했습니다. 이 모델은 엣지 기기용 E4B와 상위 26B Mixture-of-Experts(MoE) 모델 사이의 간극을 메우는 위치에 있으며, 16GB VRAM 또는 통합 메모리를 갖춘 일반 노트북에서 로컬로 실행할 수 있는 크기로 26B 모델에 근접한 추론 성능을 제공하는 것을 목표로 합니다. Gemma 4 모델군 전체에 대한 소개는 PyTorchKR의 Gemma 4 공개 소식 게시물을 참고해주세요.
이번 공개에서 가장 주목할 부분은 인코더 없는(Encoder-free) 통합 아키텍처입니다. 기존의 멀티모달 모델들은 이미지와 오디오를 처리하기 위해 별도의 비전 인코더와 오디오 인코더를 두고, 이들이 변환한 표현(representation)을 언어 모델에 전달하는 구조를 사용해 왔습니다. 이러한 분리형 인코더는 지연 시간을 늘리고 메모리 사용량을 증가시키는 요인이었습니다. Gemma 4 12B는 이 인코더들을 제거하고 비전과 오디오 입력이 LLM 백본으로 직접 흘러 들어가도록 학습되었으며, 모델명의 "Unified"가 바로 이 구조를 가리킵니다. 또한 Gemma 모델군에서 오디오 입력은 그동안 E2B, E4B 같은 경량 엣지 모델에만 제공되었는데, Gemma 4 12B는 네이티브 오디오 입력을 지원하는 첫 번째 중간 크기 모델이기도 합니다.
Google에 따르면 Gemma 4 모델군은 개발자 커뮤니티의 호응에 힘입어 공개 이후 누적 1억 5천만 다운로드를 넘어섰습니다. 이번 12B 모델은 Apache 2.0 라이선스로 공개되어 사전 학습(pre-trained) 및 지시 조정(instruction-tuned) 체크포인트를 Hugging Face와 Kaggle에서 바로 받을 수 있습니다.
핵심 특징 요약:
- 인코더 없는 통합 아키텍처: 별도의 멀티모달 인코더 없이 비전, 오디오 입력이 단일 디코더 전용 트랜스포머로 직접 투입됩니다.
- 26B에 근접한 추론 성능: 표준 벤치마크에서 상위 26B MoE 모델에 근접한 성능을 절반 이하의 메모리 사용량으로 달성합니다.
- 노트북에서 실행: 16GB VRAM 또는 통합 메모리만으로 로컬 실행이 가능합니다.
- Multi-Token Prediction(MTP) 드래프터 동봉: 로컬 추론 지연 시간을 줄이기 위한 전용 MTP 드래프터 모델이 함께 제공됩니다.
- 개방형 생태계 지원: Apache 2.0 라이선스와 함께 주요 개발 도구 전반에서 곧바로 사용할 수 있습니다.
Gemma 4 모델군에서의 위치: 다섯 가지 크기와 12B Unified
Gemma 4는 고성능 휴대폰부터 노트북, 서버까지 폭넓은 환경에 배포할 수 있도록 다섯 가지 크기로 제공됩니다. 모든 모델은 로컬 슬라이딩 윈도우 어텐션과 전역(global) 어텐션을 교차 배치하는 하이브리드 어텐션 구조를 사용하며, 256K 토큰까지의 컨텍스트 윈도우와 140개 이상 언어에 대한 다국어 지원을 갖추고 있습니다.
| 모델 | 파라미터 | 컨텍스트 | 지원 모달리티 | 비고 |
|---|---|---|---|---|
| E2B | 2.3B (유효) | 128K | 텍스트, 이미지, 오디오 | Per-Layer Embeddings 적용 |
| E4B | 4.5B (유효) | 128K | 텍스트, 이미지, 오디오 | Per-Layer Embeddings 적용 |
| 12B Unified | 11.95B | 256K | 텍스트, 이미지, 오디오 | 인코더 없는 통합 구조 |
| 26B A4B | 25.2B (활성 3.8B) | 256K | 텍스트, 이미지 | MoE, 전문가 128개 중 8개 활성 |
| 31B Dense | 30.7B | 256K | 텍스트, 이미지 | 모델군 최고 성능 |
26B A4B는 추론 시 3.8B 파라미터만 활성화되는 MoE 구조라 4B급 속도로 동작하는 반면, 12B Unified는 전체 파라미터를 사용하는 밀집(Dense) 모델이면서도 인코더 제거로 멀티모달 지연 시간을 줄인 것이 차별점입니다.
벤치마크로 보는 성능: 절반 이하의 메모리로 26B에 근접
Gemma 4 12B는 주요 벤치마크에서 상위 26B MoE 모델에 근접한 점수를 기록했으며, 전 세대인 Gemma 3 27B를 큰 폭으로 앞섰습니다. 아래는 지시 조정 모델 기준의 대표 벤치마크 결과입니다.
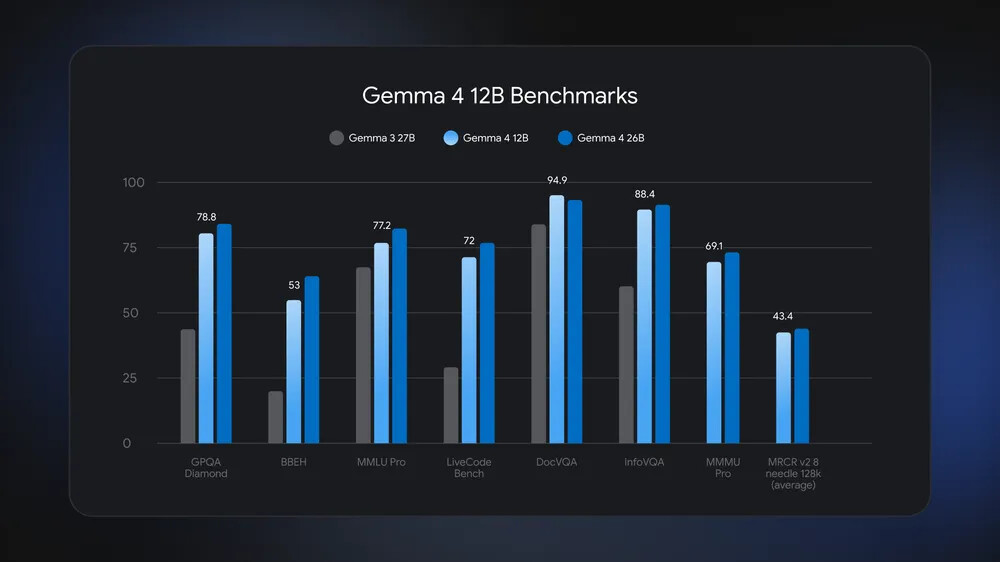
| 벤치마크 | Gemma 4 12B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| MMLU Pro | 77.2% | 82.6% | 69.4% | 67.6% |
| AIME 2026 (도구 미사용) | 77.5% | 88.3% | 42.5% | 20.8% |
| LiveCodeBench v6 | 72.0% | 77.1% | 52.0% | 29.1% |
| GPQA Diamond | 78.8% | 82.3% | 58.6% | 42.4% |
| MMMU Pro (비전) | 69.1% | 73.8% | 52.6% | 49.7% |
특히 수학 경시 문제인 AIME 2026에서 77.5%, 코딩 벤치마크인 LiveCodeBench v6에서 72.0%를 기록하여, 한 세대 전 27B 모델(각각 20.8%, 29.1%)과 비교하면 같은 크기 대역에서의 성능 향상 폭을 체감할 수 있습니다. 오디오 영역에서도 음성 번역 벤치마크 CoVoST에서 38.5점을 기록하여 E4B(35.54)를 앞섰습니다.
인코더를 없앤 통합 아키텍처: 비전과 오디오가 LLM으로 직접 흐릅니다
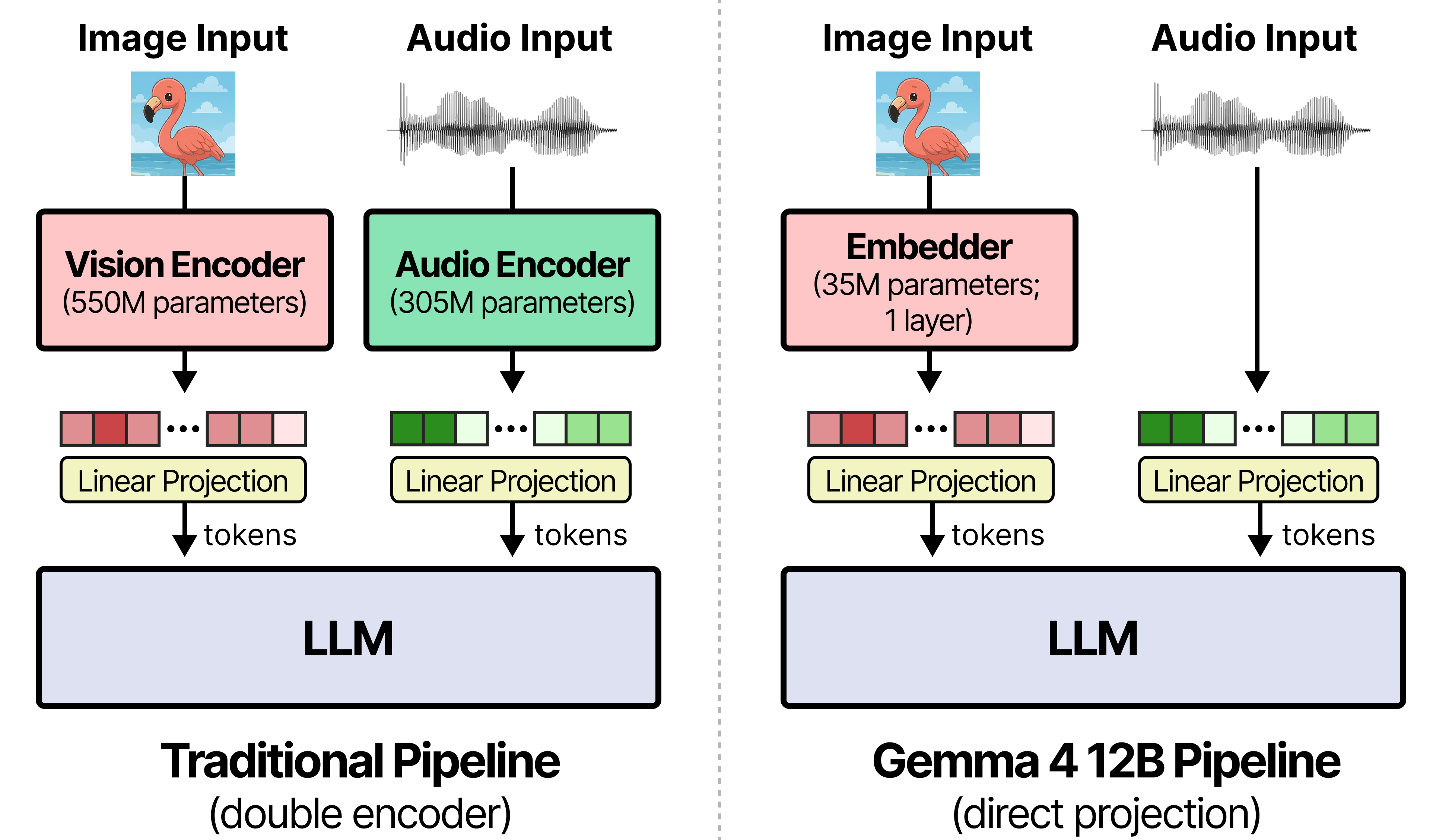
전통적인 멀티모달 모델은 고정(frozen)된 별도 인코더에 의존합니다. 실제로 다른 Gemma 4 모델들은 엣지 크기에서 150M, 중간 크기에서 550M 파라미터의 비전 인코더와 300M 파라미터의 오디오 인코더(E2B, E4B)를 사용합니다. 여러 개의 분리된 인코더로 멀티모달 입력을 전처리한 뒤 LLM에 전달하는 방식은 지연 시간 증가와 파편화된 메모리 사용이라는 비용을 수반합니다. Gemma 4 12B는 Gemma 4 31B Dense와 동일한 디코더 구조를 갖는 단일 디코더 전용 트랜스포머 하나로 이 문제를 해결합니다.
비전 임베더(Vision Embedder, 35M 파라미터): 다른 중간 크기 Gemma 4 모델의 27개 비전 트랜스포머 레이어를 대체합니다. 원시 48x48 픽셀 패치를 단일 행렬 곱셈(matmul) 한 번으로 LLM 은닉 차원에 투영하고, X축과 Y축 행렬로 분해된 좌표 조회(factorized coordinate lookup)를 통해 공간 위치 정보를 입력에 직접 부착합니다.
오디오 파형 투영(Audio Wave Projection): 별도의 오디오 인코더를 완전히 제거했습니다(E2B와 E4B가 사용하는 12개 컨포머 레이어 생략). 원시 16kHz 오디오 신호를 40ms 프레임(각 640개 부동소수점)으로 잘라 LLM 입력 공간에 선형 투영합니다.
통합 파인튜닝의 이점: 비전, 오디오, 텍스트 입력이 완전히 동일한 가중치를 공유하기 때문에, 고정된 인코더를 별도로 함께 조정할 필요가 없습니다. Hugging Face Transformers나 Unsloth를 통한 LoRA 어댑터 또는 전체 파인튜닝이 한 번의 패스로 전체 멀티모달 루프를 갱신합니다.
이 구조에 대한 시각적 해설은 Maarten Grootendorst의 A Visual Guide to Gemma 4 12B와 공식 Developer Guide에서 더 자세히 볼 수 있습니다.
로컬에서 동작하는 에이전트: 코딩과 멀티모달 이해
Gemma 4 12B는 자동 음성 인식(ASR), 에이전트 추론, 화자 분리(diarization), 비디오 이해, 코딩 등 폭넓은 작업을 처리하며, 네이티브 함수 호출(function calling)과 시스템 프롬프트(system 역할)를 지원하여 에이전트 워크플로우에 바로 투입할 수 있습니다. 아래 영상은 llama.cpp로 로컬 서빙한 Gemma 4 12B가 OpenCode 같은 에이전트 하니스와 gemma-skills를 활용하여 이미지 처리용 Gradio 앱을 직접 코딩하는 데모입니다. 완성된 앱은 그 앱을 만든 것과 동일한 Gemma 4 12B 모델로 구동됩니다.
비디오는 초당 1프레임 기준 최대 60초, 오디오는 최대 30초까지 입력할 수 있으며, 이미지 입력은 70부터 1120까지 5단계의 가변 비주얼 토큰 예산(Visual Token Budget) 으로 해상도와 연산량을 조절할 수 있습니다. 분류나 영상 이해처럼 빠른 처리가 중요한 작업에는 낮은 예산을, OCR이나 문서 파싱처럼 세밀한 판독이 필요한 작업에는 높은 예산을 사용하는 방식입니다.
LiteRT-LM 기반 온디바이스 배포와 macOS 데스크톱 앱
이번 출시와 함께 LiteRT-LM 기반의 데스크톱 통합도 함께 공개되었습니다. 모바일용이었던 Google AI Edge Gallery 앱이 처음으로 데스크톱 플랫폼으로 확장되어, Apple Silicon GPU에서 Gemma 4 12B를 완전히 오프라인으로 실행할 수 있습니다. 채팅 안에서 과학 차트를 작성하고 실행하는 샌드박스 Python 실행 루프도 포함되어 있습니다. 함께 공개된 Google AI Edge Eloquent macOS 앱은 Gemma 4 12B로 음성 편집(Voice Edit) 대화형 입력을 지원합니다.
litert-lm serve 명령으로 Gemma 4 12B를 OpenAI 호환 로컬 API 서버로 띄울 수도 있습니다. 메모리 내 상태 비저장 프리픽스 캐싱(stateless prefix caching)으로 컨텍스트 히스토리를 매칭하여 프리필(prefill) 지연을 우회하므로, Continue, Aider, OpenCode 같은 기존 통합 도구를 그대로 연결할 수 있습니다.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
# Start the OpenAI-compatible server
litert-lm serve
시작하기: Transformers 예제와 생태계 지원
Hugging Face Transformers 최신 버전에서 바로 사용할 수 있습니다. 새로 도입된 AutoModelForMultimodalLM 클래스로 모델을 불러오고, enable_thinking 인자로 단계별 추론(thinking) 모드를 켜고 끌 수 있습니다.
from transformers import AutoProcessor, AutoModelForMultimodalLM
MODEL_ID = "google/gemma-4-12B-it"
# Load model
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForMultimodalLM.from_pretrained(
MODEL_ID,
dtype="auto",
device_map="auto"
)
# Prompt
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a short joke about saving RAM."},
]
# Process input
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
enable_thinking=False
).to(model.device)
input_len = inputs["input_ids"].shape[-1]
# Generate output
outputs = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=False)
# Parse output
processor.parse_response(response)
권장 샘플링 파라미터는 temperature=1.0, top_p=0.95, top_k=64이며, 멀티모달 입력 시 이미지는 텍스트보다 앞에, 오디오는 텍스트보다 뒤에 배치하는 것이 가장 좋은 성능을 냅니다. Transformers 외에도 LM Studio, Ollama, llama.cpp, MLX, SGLang, vLLM 등 주요 추론 스택이 출시와 동시에 지원되며, 프로덕션 배포는 Cloud Run이나 GKE를 통해 가능합니다. 자세한 사용법은 공식 개발자 문서와 퀵스타트 노트북을 참고해주세요. 이 외에도 공식 Gemma Cookbook 저장소에서 멀티모달 입력 처리, 파인튜닝, 앱 통합 등 다양한 예제 노트북을 제공하고 있으며, 에이전트가 Gemma 모델을 활용해 개발할 수 있도록 돕는 공식 스킬 모음인 Gemma Skills 저장소도 함께 공개되었습니다.
라이선스
Gemma 4 12B는 Apache 2.0 라이선스로 배포되고 있어, 연구 목적은 물론 상업적 용도로도 자유롭게 사용 및 수정이 가능합니다.
 Gemma 4 12B 공식 발표 블로그
Gemma 4 12B 공식 발표 블로그
 Gemma 4 12B Developer Guide
Gemma 4 12B Developer Guide
 Gemma 4 12B Hugging Face 모델 및 컬렉션
Gemma 4 12B Hugging Face 모델 및 컬렉션
 Gemma Skills GitHub 저장소
Gemma Skills GitHub 저장소
Gemma Cookbook GitHub 저장소
더 읽어보기
-
Google DeepMind, 모바일 기기부터 클라우드까지 사용 가능한, 통합 멀티모달 모델 Gemma 4 공개
-
Gemma 4와 Pi Coding Agent로 완전히 로컬에서 실행하는 코딩 에이전트 만들기 (feat. LM Studio)
-
Gemma Multimodal Fine-Tuner: Apple Silicon Mac에서 PyTorch와 MPS로 Gemma 4 멀티모달 모델을 파인튜닝하는 오픈소스 도구
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()