
LightMem 소개
LightMem은 대규모 언어 모델(LLM)이 장기적 맥락 이해와 지속적인 상호작용을 수행할 수 있도록 돕는 경량 메모리 증강 프레임워크(Memory-Augmented Generation Framework) 입니다. 기존의 메모리 시스템이 높은 계산 비용과 긴 처리 시간을 요구했던 한계를 극복하기 위해, LightMem은 인간의 기억 구조인 Atkinson–Shiffrin 모델(1968) 에서 영감을 받아 설계되었습니다. 이 모델은 인간의 기억이 감각 기억(sensory memory), 단기 기억(short-term memory), 장기 기억(long-term memory)으로 계층화되어 작동한다는 점에서 효율적 메모리 구조 설계의 모티브가 되었습니다.
대규모 언어 모델(LLM)은 뛰어난 추론 능력을 보여주지만, “고정된 컨텍스트 윈도우(fixed context window)” 제약 때문에 대화가 길어질수록 과거 정보를 잃는 ‘Lost in the Middle’ 문제를 겪습니다(Liu et al., 2023). 이를 해결하기 위해 등장한 기존 메모리 시스템들은 요약 기반 저장, RAG(Retrieval-Augmented Generation), 그래프 기반 메모리 구조 등을 사용하지만, 대부분 계산량이 많고 실시간 응답성이 떨어지는 문제가 있었습니다. LightMem은 이러한 비효율을 개선하여, 정확성과 효율성을 동시에 달성한 첫 메모리 프레임워크로 평가받고 있습니다.
"LightMem: Lightweight and Efficient Memory-Augmented Generation" (Fang et al., 2025) 연구는 LightMem이 GPT와 Qwen 백본 모델 기반 실험에서 QA 정확도 최대 10.9% 향상, 토큰 사용량 117배 감소, API 호출 횟수 159배 절감, 실행 시간 12배 단축이라는 결과를 보여주었다고 보고합니다. 이러한 결과는 LLM 기반 에이전트가 보다 장기적이고 일관된 대화를 수행할 수 있게 만들 중요한 진전으로 평가됩니다.
LightMem과 기존 메모리 시스템 비교
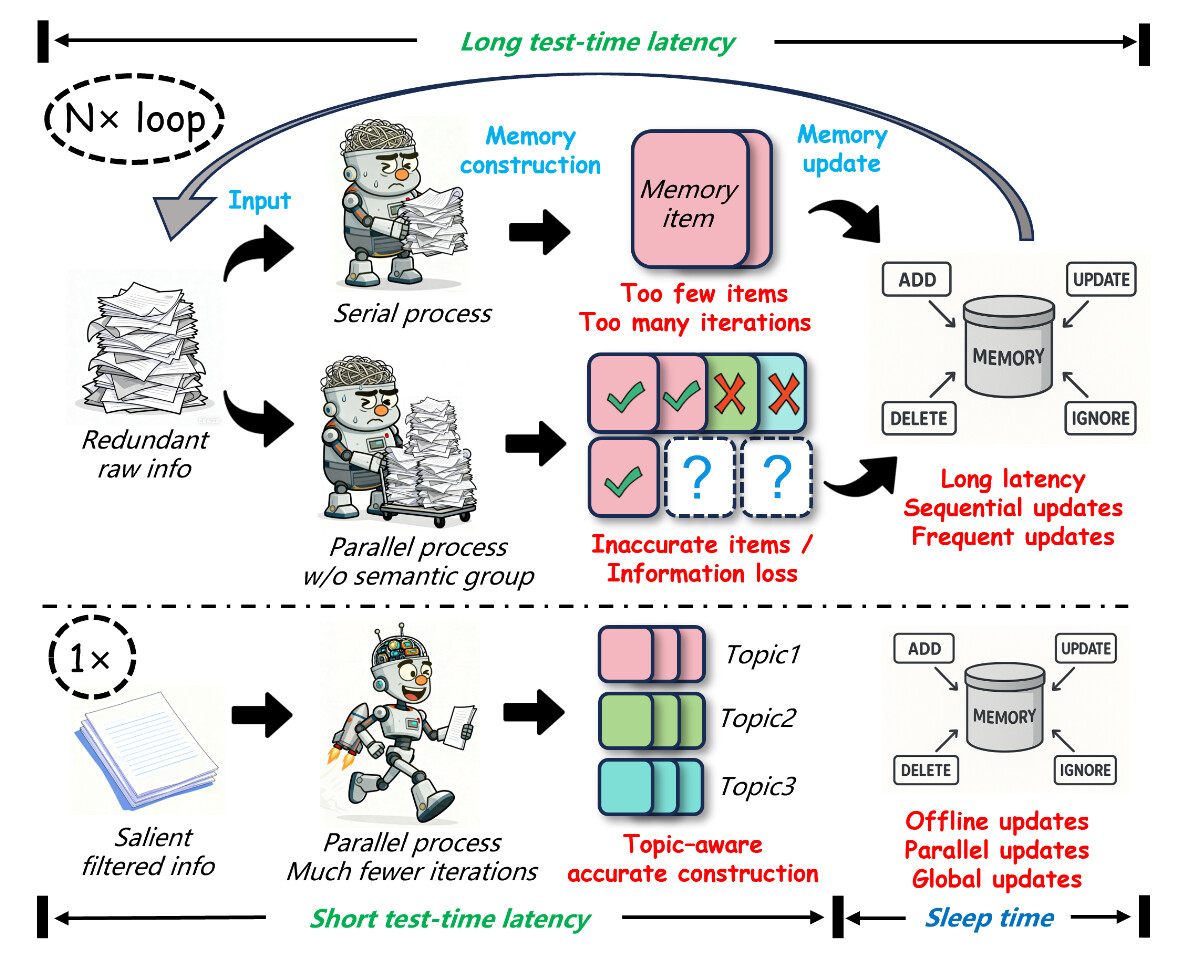
기존 LLM 메모리 시스템(예: LangMem, A-MEM, MemoryOS, Mem0)은 보통 “요약(summarization) - 저장(storage) - 업데이트(update)” 단계를 따르며, 대화 세션 단위로 데이터를 처리합니다. 그러나 이러한 방식은 불필요한 중복 정보 처리, 토픽 간 혼합(Semantic Entanglement), 실시간 업데이트로 인한 지연(latency) 문제를 갖고 있습니다.
LightMem은 이러한 문제를 해결하기 위해 다음과 같은 시도들을 하였습니다:
-
중복 정보로 인한 비효율성: 대화 데이터에는 불필요한 반복 표현과 비관련 정보가 많습니다.대부분의 메모리 시스템은 이를 그대로 요약(summary) 또는 벡터화하여 저장하므로, 토큰 낭비와 계산량 증가가 발생합니다.
-
고정된 문맥 단위(granularity)의 문제: 많은 시스템이 “대화 턴(turn)” 단위로 기억을 분할하지만, 실제 대화 주제는 턴 단위로 나뉘지 않습니다.결과적으로 **주제 혼합(topic entanglement)**이 발생하고, LLM이 문맥적 의미를 잃게 됩니다.
-
실시간 업데이트의 높은 지연(latency): 대부분의 시스템은 새로운 메모리를 “즉시 업데이트”합니다.이 과정은 모델 추론과 병행되어야 하므로 속도가 느려지고, 실시간 응답에 영향을 줍니다.
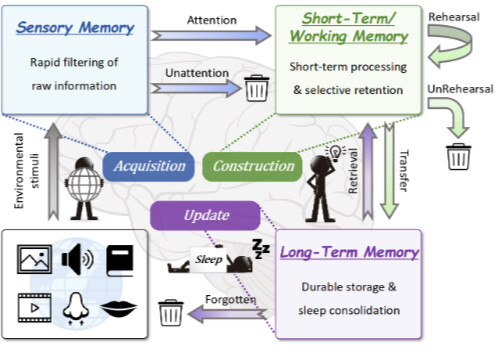
이러한 문제는 인간의 기억체계와 비교할 때 더욱 두드러집니다.
특히, 인간의 두뇌가 감각 기억 → 단기 기억 → 장기 기억으로 이어지는 계층적 구조를 통해 정보를 효율적으로 필터링, 정리, 보존하는 구조적 효율성에서 착안하여, LightMem을 설계 및 구현하였습니다.
LightMem 아키텍처
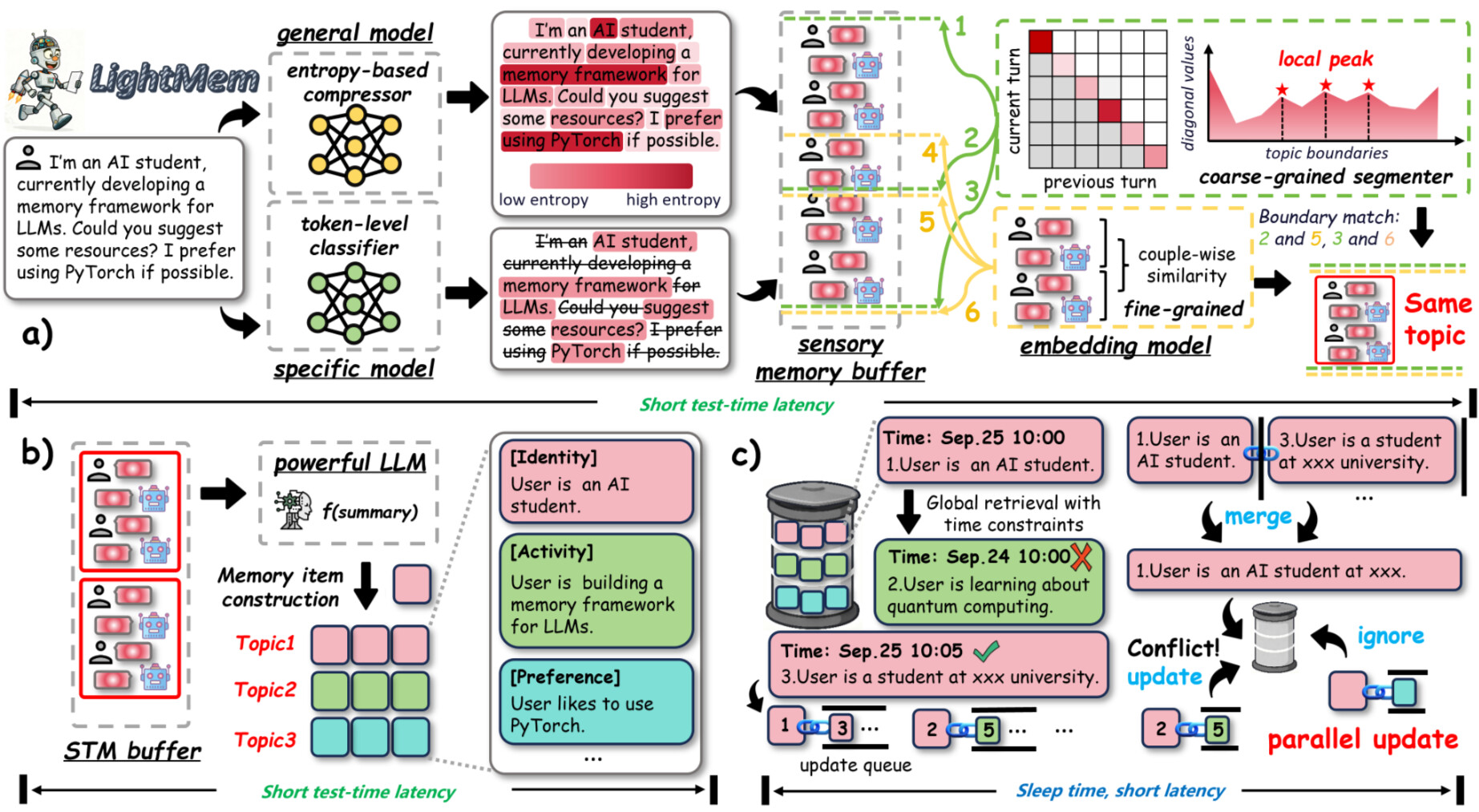
LightMem은 인간의 기억 과정을 모사하여, 입력 정보의 감각적 수용 → 단기적 처리 → 장기적 통합으로 이어지는 3단계의 계층형 메모리 구조를 갖습니다. 이러한 계층적 구조는 기존 LLM 메모리 시스템이 직면한 비효율적 중복 처리 및 실시간 업데이트 병목 문제를 해결하기 위해 설계되었습니다.
각 계층은 서로 독립적이지만, 정보의 흐름이 점진적으로 정제되는 방향으로 연결되어 있습니다. 즉, 모델이 들어오는 정보를 그대로 저장하는 대신, 불필요한 부분을 걸러내고, 핵심적인 의미만 장기적으로 남기는 구조입니다.
Light1: 감각 기억(Sensory Memory)
LightMem의 첫 번째 단계는 인지 기반 감각 기억(Cognitive-inspired Sensory Memory) 모듈로, 입력된 대화나 문서를 처리하기 전에 정보 압축(pre-compression) 및 주제 분할(topic segmentation) 을 수행합니다. 즉, 이 단계에서는 마치 인간이 시각이나 청각으로부터 유입된 자극 중 중요하지 않은 것을 즉시 걸러내는 감각 기억과 같이 불필요한 정보를 제거하는 역할을 합니다.
먼저, 입력 문장은 LLMLingua-2 모델을 사용하여 토큰 단위로 분석됩니다. 각 토큰별로 보존 확률(retain probability)을 계산한 뒤, 이 보존 확률 값이 임계치(\tau)보다 낮으면 제거됩니다. 임계치는 설정된 압축 비율(r, 예: 0.6)에 따라 동적으로 결정됩니다. 이 과정은 일종의 정보량 기반 필터링으로, 높은 엔트로피(즉, 의미적 독립성이 강한) 토큰을 우선하여 보존도록 동작합니다.
이렇게 보존 확률이 낮은 토큰들을 제거하게 되면, 전체 입력의 50~70% 정도의 토큰이 제거되지만 의미적 일관성은 유지됩니다.
그 다음으로 수행되는 토픽 세분화(Topic Segmentation) 는 LightMem의 핵심 혁신 중 하나입니다. 기존 LLM 메모리 시스템이 턴(turn) 단위나 세션(session) 단위로 고정된 분할을 사용하는 것과 달리, LightMem은 “주제가 전환되는 지점(topic shift)”을 감지하기 위한 별도 모델을 통해 전환점을 감지하고 분리합니다.
이를 위해 Attention 행렬을 이용해 문장 간 어텐션(attention) 패턴을 계산하고, 이웃 문장 간 유사도가 급격히 감소하는 지점을 토픽 경계로 정의합니다.
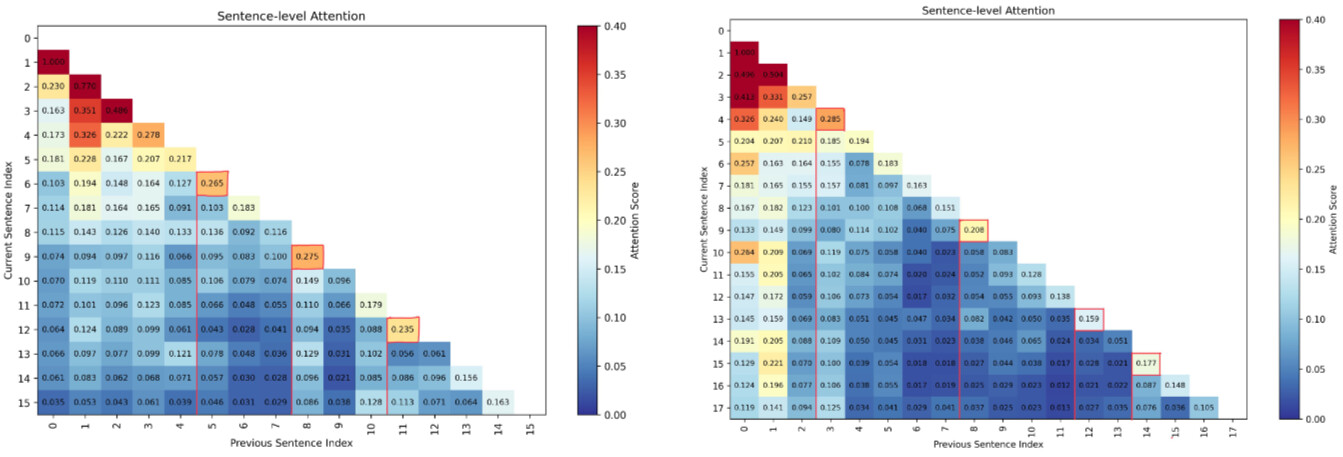
Attention 기반 경계 후보(B_1)와 임베딩 유사도 기반 경계(B_2)를 교차시켜 얻은 교집합( B = B_1 \bigcap B_2 )이 최종 세분화 지점으로 사용됩니다. 이 때, B_1 및 B_2 는 다음과 같습니다:
여기서 M 은 대화 턴의 총 개수를 의미할 수 있으며, M \in R^{n \times n} 는 n 번째 턴과 M_{i,j} 번째 턴 사이의 어텐션 스코어를 나타냅니다. 즉, B_1 은 M_{k,k-1} 번째 턴이 바로 이전 k 번째 턴에 부여하는 어텐션 스코어를 나타내며, 이 값은 연속적인 턴들 간의 의미론적 연속성을 반영합니다. sim(s_{k−1},s_k) 는 k-1 번째 턴 s_{k-1} 과 k 번째 턴 s_k 사이의 의미론적 유사성(semantic similarity) 을 계산한 값입니다.
결과적으로 감각 기억(Sensory Memory) 단계에서는 입력 데이터를 의미적으로 압축된 토픽 단위의 조각(topic-level chunks) 으로 변환하며, 이후의 단기 기억 모듈이 더 작은 비용으로 효과적인 처리를 수행할 수 있도록 합니다. 이러한 과정들을 통해 약 50~80% 수준의 압축에서도 성능 저하 없이 의미 정보를 유지할 수 있음을 실험적으로 입증했습니다.
Light2: 주제 인식 단기 기억(Topic-Aware Short-Term Memory)
LightMem의 두 번째 단계는 단기 기억(STM, Short-Term Memory) 입니다. 이 모듈은 Sensory Memory에서 전달된 토픽별 조각들을 {topic, message turns} 형태로 임시로 저장합니다. 이 때,message turn 은 {user_i, model_i} 로, i 번째의 사용자 메시지와 모델의 응답을 포함하고 있습니다. 즉, Light1의 감각 기억(Sensory Memory)으로부터 넘어온 주제별 대화를 STM 버퍼에 일시적으로 저장합니다.
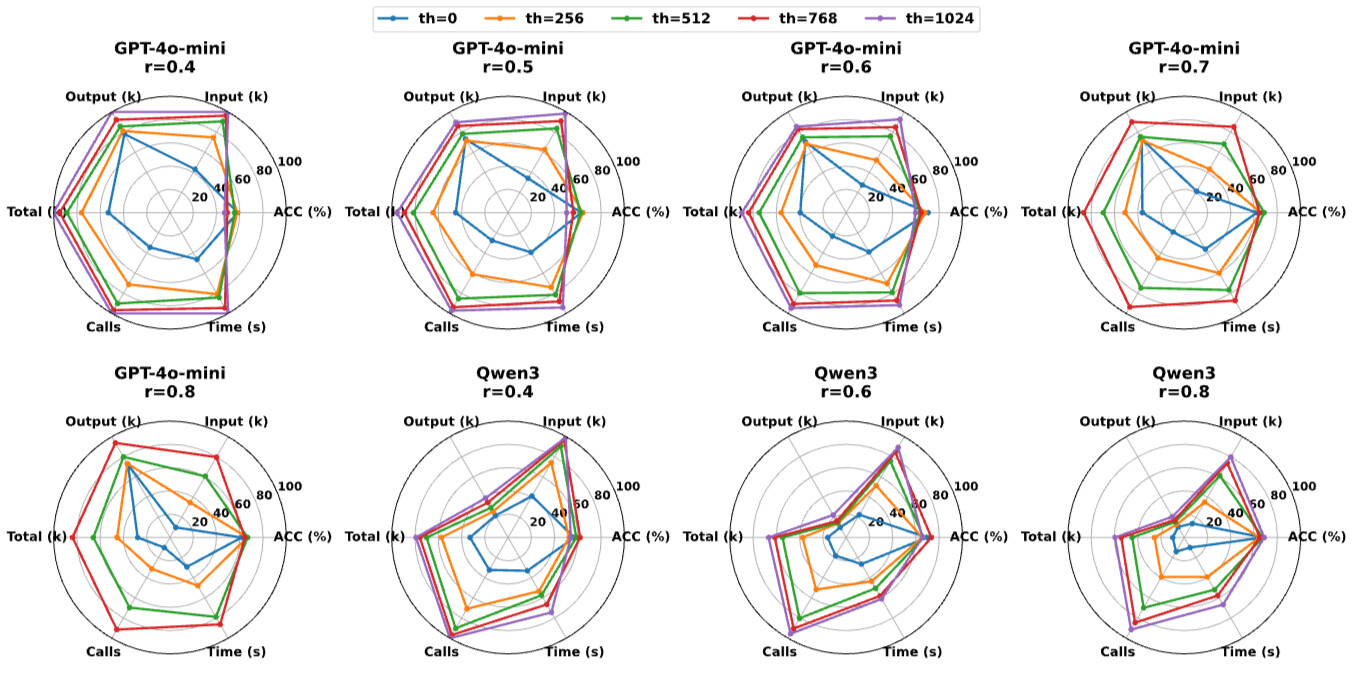
이후, 대화가 진행됨에 따라 새로운 주제 및 대화들이 단기 기억(STM) 버퍼에 쌓이게 되는데, STM 버퍼에 쌓인 토큰의 수가 미리 설정해둔 임계값(Preset Threshold, 예: 512 tokens, 1024 tokens 등)에 도달하면, LightMem은 LLM을 호출하여 해당 주제 블록에 그동안 쌓아놨던 대화들을 요약(Summary)한 뒤, 벡터 임베딩 형태로 변환하여 장기 기억(LTM, Long-Term Memory)으로 옮깁니다.
이러한 요약은 LLM 함수 f_{sum} 을 통해 수행되며, STM 버퍼 내의 각 {topic, message turns} 구조에 대해 요약 sum_i 를 생성하는 것으로 표현할 수 있습니다. 정리하면 다음과 같은 구조로 메모리 항목이 생성됩니다:
즉, 사용자의 요청 user_i 과 모델의 응답 model_i 으로 구성된 토픽 세그먼트 S_i 를 LLM에 입력으로 제공하여 각 토픽 세그먼트를 요약한 결과 sum_i 를 생성합니다. 이후, 이러한 요약 결과에 대해 임베딩 e_i 을 생성한 뒤 Light1의 토픽 세분화(Topic Segmentation) 결과로 얻은 토픽 topic 및 사용자의 요청 user_i, 모델 응답 model_i 을 함께 묶어 장기 기억(LTM)에 저장될 i 번째 메모리 항목 Entry_i 를 정의합니다.
지금까지 설명한 것과 같이, 주제에 따른 입력 세분화(Topic-constrained Input Granularity) 방식을 사용하게 되면 대화들의 요약의 정확도를 유지하면서도 동일한 주제를 묶어서 요약하게 됩니다. 즉, 대화마다 요약을 수행하거나 전체 세션 요약 대비 API 호출을 최소화하면서 일관된 추론을 할 수 있도록 돕습니다.
Light3: 수면 기반 장기 기억(Long-Term Memory with Sleep-Time Update)
LightMem의 세 번째 단계는 장기 기억(Long-Term Memory, LTM) 입니다. 장기 기억에는 이전 단계에서 생성한 주제별 요약 및 임베딩 정보가 계속적으로 쌓이며, 이 정보들은 LightMem의 수면 기반 오프라인 업데이트(Sleep-time Offline Update) 메커니즘에 따라 관리됩니다.
세부적으로는, 실시간으로 들어오는 정보는 기존 메모리를 덮어쓰거나 삭제하지 않고 그대로 장기 기억(LTM)에 추가하여 중복을 일시적으로 허용합니다. 이러한 Soft Update 방식은 실시간으로 상호 작용(Test-time) 중에 별다른 지연 시간(latency)을 발생시키지 않으면서 최신 정보를 반영할 수 있습니다.
이렇게 쌓아둔 새로운 정보들은 모델이 추론을 수행하지 않는 동안(모델의 '수면 시간') 장기 기억(LTM)에 쌓인 전체 메모리들을 대상으로 병렬 정제(Parallel Consolidation)을 수행합니다. 이 때 전체 메모리를 시간 순으로 정렬한 다음, 유사도 검색(Similarity Retrieval)을 통해 의미적으로 중복되거나 모순된 항목을 병합하는 방식으로 정제를 수행합니다. 또한 새로운 항목이 오래된 항목보다 더 최신의 타임스탬프(Later Timestamp)를 가지는 경우에만 기존의 데이터를 업데이트 할 수 있습니다.
이러한 과정을 통해 장기 기억(LTM)은 모델의 응답 속도에 영향을 주지 않으면서도 메모리를 최신 상태로 유지할 수 있으며, 불필요한 중복을 제거하는 과정을 거쳐 저장 공간을 절약할 수 있습니다. 뿐만 아니라, 오프라인 상태에서 각 메모리 항목을 병렬적으로 업데이트하는 방식으로 기존의 순차적인 접근 대비 1.67 ~ 12.45배 빠르게 처리할 수 있습니다.

예를 들어, 사용자가 “도쿄 여행 계획”에 대한 대화를 한 뒤, 이어서 “교토 기차표”를 물어보는 경우, LightMem은 이전 도쿄 정보가 삭제되지 않고 두 개의 맥락이 모두 저장되어 “도쿄 여행 + 교토 문의”라는 상위 주제 수준으로 자연스럽게 통합됩니다.
LightMem 설치 및 사용 예시
현재 LightMem은 저장소를 복제(clone)하여 소스 코드로부터의 설치만 가능하며, Python 3.10 환경을 권장합니다. 다음과 같은 단계를 따라서 진행해주세요:
# 저장소 복제
git clone https://github.com/zjunlp/LightMem.git
cd LightMem
# 가상환경 생성 (선택)
conda create -n lightmem python=3.10 -y
conda activate lightmem
# 의존성 설치
unset ALL_PROXY
pip install -e .
위 방식은 개발자에게 적합하며, -e 옵션을 통해 LightMem 소스코드 변경 시 즉시 반영됩니다.
PyPI 등록은 현재 준비 중입니다. 향후 배포가 완료되면 pip install lightmem 과 같은 방식으로 간편하게 설치할 수 있습니다.
LightMem 사용 예시(Examples)
LightMem의 사용은 매우 단순한 Python 인터페이스를 통해 이루어집니다. 메모리 객체 생성부터 추가, 업데이트, 검색까지의 전체 예시를 단계적으로 살펴보겠습니다.
먼저, LightMem을 적용할 LLM 사용 환경을 구성하고, LightMem을 초기화합니다.
이 단계에서는 LLM, 임베딩 모델, 저장소(Qdrant 등), 압축 모듈 등을 지정할 수 있습니다. 이후, LightMemory.from_config() 를 통해 초기화에 필요한 구성 정보(config 객체)를 바탕으로 메모리 객체가 초기화됩니다:
import os, datetime
from lightmem.memory.lightmem import LightMemory
from lightmem.configs.base import BaseMemoryConfigs
LOGS_ROOT = "./logs"
RUN_TIMESTAMP = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
RUN_LOG_DIR = os.path.join(LOGS_ROOT, RUN_TIMESTAMP)
os.makedirs(RUN_LOG_DIR, exist_ok=True)
API_KEY='YOUR_API_KEY'
API_BASE_URL=''
LLM_MODEL=''
EMBEDDING_MODEL_PATH='/your/path/to/models/all-MiniLM-L6-v2'
LLMLINGUA_MODEL_PATH='/your/path/to/models/llmlingua-2-bert-base-multilingual-cased-meetingbank'
config_dict = {
"pre_compress": True,
"pre_compressor": {
"model_name": "llmlingua-2",
"configs": {
"llmlingua_config": {
"model_name": LLMLINGUA_MODEL_PATH,
"device_map": "cuda",
"use_llmlingua2": True,
},
}
},
"topic_segment": True,
"memory_manager": {
"model_name": "openai",
"configs": {
"model": LLM_MODEL,
"api_key": API_KEY,
"max_tokens": 16000,
"openai_base_url": API_BASE_URL
}
},
"index_strategy": "embedding",
"text_embedder": {
"model_name": "huggingface",
"configs": {
"model": EMBEDDING_MODEL_PATH,
"embedding_dims": 384,
"model_kwargs": {"device": "cuda"},
},
},
"embedding_retriever": {
"model_name": "qdrant",
"configs": {
"collection_name": "my_long_term_chat",
"embedding_model_dims": 384,
"path": "./my_long_term_chat",
}
},
"logging": {
"level": "DEBUG",
"file_enabled": True,
"log_dir": RUN_LOG_DIR,
}
}
lightmem = LightMemory.from_config(config_dict)
이후, 아래의 메모리 추가(Add Memory) 예시를 살펴보겠습니다. 아래 코드는 대화 내용을 LightMem에 저장하는 예시로, 앞에서 초기화한 LightMem 객체의 add_memory()를 호출하여 수행합니다. 먼저, 세션의 시간 정보를 각 메시지에 추가(timestamp)하여 turn_messages 객체를 구성한 뒤, force_segment 및 force_extract 매개변수를 True로 설정하여 토픽 단위 세분화 및 요약 정보를 함께 추출할 수 있습니다:
session = {
"timestamp": "2025-01-10",
"turns": [
[
{"role": "user", "content": "My favorite ice cream flavor is pistachio, and my dog's name is Rex."},
{"role": "assistant", "content": "Got it. Pistachio is a great choice."}
],
]
}
for turn_messages in session["turns"]:
timestamp = session["timestamp"]
for msg in turn_messages:
msg["time_stamp"] = timestamp
store_result = lightmem.add_memory(
messages=turn_messages,
force_segment=True,
force_extract=True
)
다음으로는 메모리의 오프라인 업데이트입니다. 이 과정은 저장한 메모리를 일정한 기준(scrore_threshold)에 따라 재정비하고 업데이트합니다. ‘Offline Update’ 모드는 배치 단위 업데이트로 처리 효율을 높이며, 실시간 동기화를 원할 경우 ‘Online Update’ 방식도 지원합니다.
lightmem.construct_update_queue_all_entries()
lightmem.offline_update_all_entries(score_threshold=0.8)
마지막으로 저장해둔 메모리에서 사용자의 질문과 의미적으로 유사한 정보를 검색하는 예시 코드입니다. 기본적으로 임베딩 기반의 검색(Embedding)을 사용하며, 필요 시 키워드 기반(Context) 또는 혼합(Hybrid) 전략으로 검색할 ㅜㅅ 있습니다.
question = "What is the name of my dog?"
related_memories = lightmem.retrieve(question, limit=5)
print(related_memories)
라이선스
LightMem 프로젝트는 MIT License로 배포되고 있습니다. 상업적 이용, 수정, 재배포 모두 허용됩니다.
 LightMem 논문: Lightweight and Efficient Memory-Augmented Generation
LightMem 논문: Lightweight and Efficient Memory-Augmented Generation
 LightMem 프로젝트 GitHub 저장소
LightMem 프로젝트 GitHub 저장소
https://github.com/zjunlp/LightMem
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()