
Stash 소개
현재 대부분의 LLM 기반 에이전트는 각 대화가 끝나면 모든 맥락을 잃어버립니다. 사용자가 이미 설명했던 프로젝트 구조, 이전 대화에서 합의했던 결정 사항, 반복적으로 발생하는 실패 패턴 — 이 모든 것이 세션이 종료되는 순간 사라집니다. 이 문제는 에이전트를 단순한 일회성 도우미로 제한하고, 진정한 지속적 협업자로 발전하지 못하게 막는 핵심 장벽입니다. 짧은 컨텍스트 창에 과거 대화를 억지로 집어넣는 방식은 토큰 비용을 급격히 높이고, 정작 중요한 현재 작업 정보가 들어갈 공간을 빼앗습니다.
Stash는 이 문제를 해결하기 위해 설계된 오픈소스 자기 호스팅(self-hosted) 영구 메모리 레이어입니다. 핵심 아이디어는 원시 관찰(raw observation)을 단계적으로 정제해 구조화된 지식으로 변환하는 것입니다. 에피소드(Episodes)는 사실(Facts)이 되고, 사실은 관계(Relationships)가 되고, 관계는 패턴(Patterns)이 되며, 패턴은 최종적으로 지혜(Wisdom)로 응축됩니다. 이 4단계 지식 압축 원칙이 Stash의 8단계 통합 파이프라인의 철학적 토대입니다. MCP(Model Context Protocol) 표준을 기반으로 구현되어 Claude Desktop, Cursor, Windsurf, Cline, Continue, OpenAI Agents, Ollama, OpenRouter 등 MCP 호환 클라이언트라면 어디서든 즉시 연동할 수 있습니다.
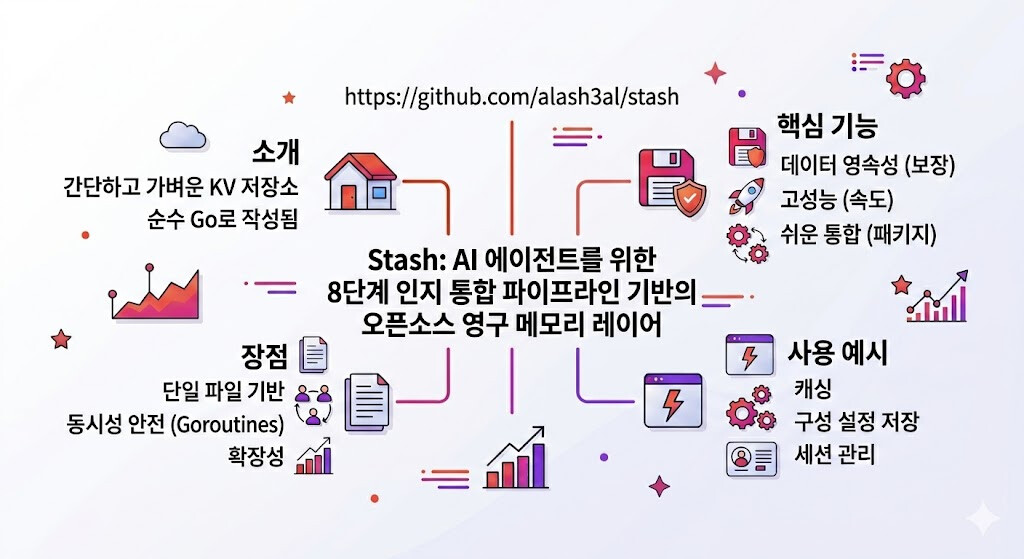
Stash는 PostgreSQL과 pgvector 확장을 저장 백엔드로 사용하며, Docker Compose 한 줄로 전체 인프라를 구동할 수 있습니다. 백그라운드에서 지속적으로 실행되는 통합 파이프라인이 새로운 에피소드를 분석해 데이터베이스를 자동으로 업데이트합니다. Apache 2.0 라이선스로 공개되어 있어 개인 및 상업적 목적 모두에서 자유롭게 사용할 수 있습니다.
Stash의 8단계 인지 통합 파이프라인
Stash의 핵심은 8단계로 구성된 지식 통합 파이프라인입니다. 각 단계는 직전 단계의 마지막 실행 이후 추가된 새로운 데이터만 처리하므로, 점진적으로 효율적인 방식으로 운용됩니다.
1단계: 에피소드 추출 (Fact Extraction): 원시 대화 에피소드에서 구체적인 사실과 관찰 내용을 추출합니다. "사용자가 Python 3.11을 사용한다", "프로젝트는 FastAPI 기반이다"와 같은 명시적 정보가 이 단계에서 구조화됩니다.
2단계: 관계 매핑 (Relationship Extraction): 추출된 사실들 사이의 관계를 식별합니다. 엔티티 간의 연결과 의존 관계가 그래프 구조로 표현됩니다.
3단계: 인과 추론 (Causal Link Detection): 사건과 결과 사이의 인과 관계를 파악합니다. "X를 시도했을 때 Y가 실패했다"는 패턴이 이 단계에서 기록됩니다.
4단계: 목표 추적 (Goal Tracking): 사용자와 에이전트가 추구하는 단기 및 장기 목표를 추적하고 진행 상황을 기록합니다.
5단계: 실패 패턴 인식 (Failure Pattern Recognition): 반복적으로 발생하는 오류나 막힌 지점을 식별합니다. 같은 실수를 반복하지 않도록 에이전트에 경고하는 데 활용됩니다.
6단계: 가설 검증 (Hypothesis Verification): 이전 대화에서 세운 가설이 이후 결과로 검증되거나 반증되었는지 추적합니다.
7단계: 신뢰도 감소 (Confidence Decay): 오랫동안 검증되지 않은 사실의 신뢰도를 점진적으로 낮춥니다. 오래된 정보가 현재 의사결정에 미치는 영향을 자동으로 조절합니다.
8단계: 지식 통합 (Knowledge Consolidation): 앞의 7단계 결과물을 결합해 응집력 있는 지식 베이스를 구성합니다. 에이전트가 질의할 때 가장 관련성 높은 지식을 효율적으로 검색할 수 있습니다.
Stash 아키텍처 및 기술 스택
Stash는 PostgreSQL + pgvector를 코어 저장소로 사용합니다. pgvector는 PostgreSQL의 벡터 검색 확장으로, 기존 관계형 데이터와 임베딩 벡터를 동일한 데이터베이스에서 관리할 수 있습니다. 이를 통해 키워드 기반 SQL 쿼리와 의미론적 벡터 유사도 검색을 함께 활용한 하이브리드 검색이 가능합니다.
에이전트 대화
↓
MCP 서버 (표준 인터페이스)
↓
에피소드 저장
↓
백그라운드 통합 파이프라인 (8단계)
1. 사실 추출 → 2. 관계 매핑 → 3. 인과 추론
4. 목표 추적 → 5. 실패 패턴 → 6. 가설 검증
7. 신뢰도 감소 → 8. 지식 통합
↓
PostgreSQL + pgvector 저장
↓
에이전트 쿼리 시 관련 지식 반환
공식 홈페이지(Stash — Persistent Memory for AI Agents)에서 추가적인 사용 예시와 설정 가이드를 확인할 수 있습니다.
Stash 설치 및 실행
Docker Compose를 사용하면 PostgreSQL, pgvector 마이그레이션, MCP 서버, 백그라운드 통합 파이프라인이 모두 한 명령으로 구동됩니다.
git clone https://github.com/alash3al/stash.git
cd stash
cp .env.example .env # OpenAI API 키 및 모델 설정
docker compose up
.env 파일에 API 키와 사용할 LLM 모델을 설정하면 모든 준비가 끝납니다. 이후 MCP 클라이언트 설정에서 Stash MCP 서버 엔드포인트를 등록하면 에이전트가 자동으로 메모리 도구를 사용하기 시작합니다. 로컬 LLM(Ollama 등)과 OpenRouter를 포함한 다양한 LLM 백엔드를 지원하므로, 클라우드 API 의존 없이 완전 로컬 환경에서도 운용할 수 있습니다.
라이선스
Stash 프로젝트는 Apache 2.0 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용, 수정, 배포할 수 있습니다.
 Stash 공식 홈페이지
Stash 공식 홈페이지
 Stash 프로젝트 GitHub 저장소
Stash 프로젝트 GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()