
Memory Caching(MC) 소개
도서관에서 두꺼운 책 한 권을 통째로 외워서 시험을 본다고 상상해 봅시다. 책이 짧을 때는 머릿속에 다 담을 수 있지만, 수백 페이지가 넘어가면 앞부분의 세부 내용은 점점 희미해지고 결국 뒤죽박죽 섞여버립니다. 반면 책상 위에 책을 펼쳐두고 필요할 때마다 해당 페이지를 다시 펴 보는 사람은 아무리 책이 두꺼워져도 정확한 내용을 찾아낼 수 있습니다. 다만 매번 모든 페이지를 다시 훑어야 하니 시간이 오래 걸리지요.
이 논문은 시퀀스 모델링에서 오랫동안 이어져 온 이 두 방식 사이의 긴장을 다룹니다. Memory Caching(MC) 은 순환 신경망(Recurrent Neural Network, RNN)이 과거를 압축해 담는 고정 크기 메모리의 한계를 극복하기 위해, 시퀀스를 여러 세그먼트로 나누고 각 세그먼트의 메모리 상태(은닉 상태)를 체크포인트로 캐싱하는 단순하지만 효과적인 기법입니다. 이를 통해 RNN의 실질적인 메모리 용량이 시퀀스 길이에 따라 함께 커지도록 만들어, 고정 메모리 RNN의 O(L) 복잡도와 트랜스포머(Transformer)의 O(L^2) 복잡도 사이를 유연하게 보간(interpolate)하는 중간 지대를 제공합니다. Google Research, Cornell, USC의 공동 연구진이 제안했으며, 교신저자는 Titans, Atlas, Miras 등 최근의 테스트 시점 메모리(test-time memory) 연구를 이끌어 온 Ali Behrouz 입니다.
트랜스포머와 순환 모델, 그리고 메모리의 딜레마
트랜스포머(Transformer) 는 지난 몇 년간 시퀀스 모델링의 사실상 표준 백본으로 자리 잡았습니다. 그 성공의 핵심은 어텐션(attention) 모듈이 컨텍스트 길이에 따라 용량이 함께 커지는 연상 기억(associative memory)처럼 작동한다는 점에 있습니다. 과거의 모든 토큰을 키(Key)와 값(Value)으로 캐싱해 두기 때문에, 시퀀스의 어느 부분이든 직접 접근할 수 있어 검색(retrieval) 능력이 뛰어납니다. 하지만 이 방식은 모든 과거 토큰에 접근해야 하므로 O(L^2) 의 연산 복잡도와 막대한 추론 시점 메모리 사용량(KV 캐싱)이라는 대가를 치릅니다.
이러한 비효율을 해결하기 위해, 과거 데이터를 고정 크기의 메모리 상태로 압축하는 순환 신경망(RNN) 이 다시 주목받고 있습니다. Linear Attention(LA), RetNet, DeltaNet, Titans 같은 현대적 RNN들은 어텐션의 \exp(\cdot) 연산을 분리 가능한 커널 \phi(\cdot) 로 대체하여, 메모리를 O(L) 의 비용으로 갱신할 수 있는 효율적인 순환 형태로 재구성합니다. 그러나 이들의 근본적인 약점은 명확합니다. 점점 길어지는 시퀀스를 고정된 크기의 메모리에 압축해 담아야 하므로, 결국 과거 정보를 잊어버릴 수밖에 없습니다. 이 한계는 특히 검색 집약적(recall-intensive) 작업과 긴 컨텍스트 작업에서 치명적인 병목이 됩니다.
기존에도 이 격차를 메우려는 시도가 있었습니다. 하이브리드 모델(Hybrid Models) 은 전역 어텐션 블록과 메모리가 제한된 모듈(RNN, 슬라이딩 윈도우 어텐션 등)을 번갈아 배치해 검색 성능과 효율성을 절충했습니다. 또 다른 접근인 Log-Linear Attention 은 은닉 상태의 집합을 시퀀스 길이에 대해 로그 스케일로 늘리는 방식을 도입했지만, 단일 메모리가 매우 큰 초기 세그먼트(예: 16K 시퀀스에서 8K 토큰)를 통째로 압축하도록 강요받는 구조적 약점이 있었습니다. 결국 핵심 질문은 이것입니다. "순환 모델의 효율성을 유지하면서도, 어떻게 메모리 용량을 시퀀스 길이에 맞춰 키울 수 있을까?"
발상의 전환: 메모리를 캐싱한다
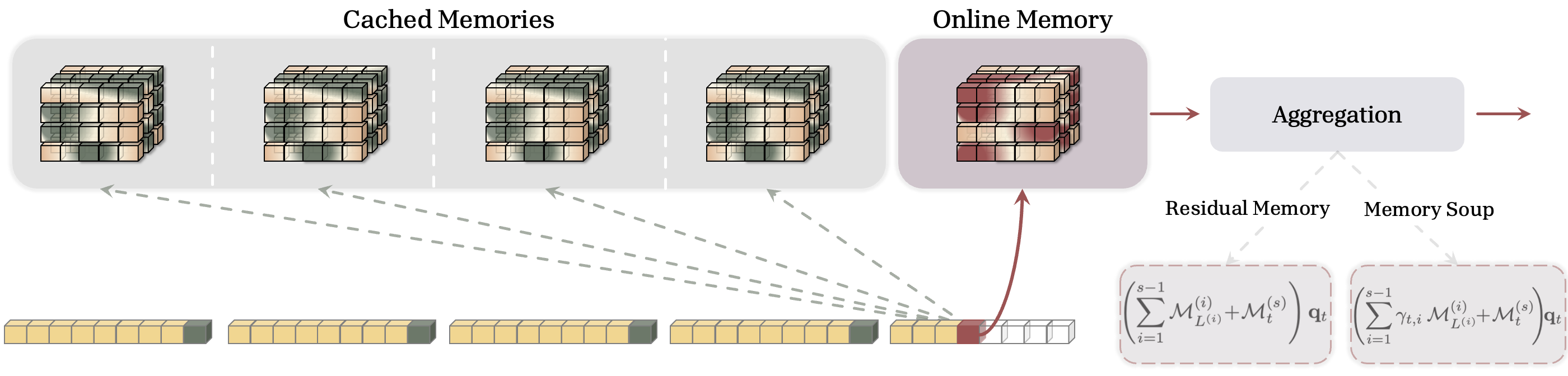
이 연구의 발상 전환은 트랜스포머와 RNN을 양극단이 아니라 하나의 연속선 위에 놓는 데서 출발합니다. RNN은 시퀀스 전체를 하나의 세그먼트로 보고 단일 메모리만 유지하는 극단(완전 압축, O(L))이고, 트랜스포머는 토큰 하나하나를 세그먼트로 보아 모두 캐싱하는 반대편 극단(압축 없음, O(L^2))입니다. Memory Caching 은 이 사이에 자리합니다. 시퀀스를 적당한 크기의 세그먼트로 쪼개고, 각 세그먼트를 압축한 메모리 상태의 마지막 체크포인트를 캐싱해 두는 것입니다.
이렇게 하면 현재 토큰의 출력을 계산할 때, 지금 갱신 중인 온라인 메모리(Online Memory) 뿐만 아니라 과거 세그먼트들의 캐시된 메모리(Cached Memories) 까지 모두 참조할 수 있습니다. 모델의 실질적 메모리가 시퀀스 길이에 따라 임의의 규모로 커질 수 있게 되는 것이지요. 핵심 아이디어를 수식으로 보면, 시간 t 의 출력 \mathbf{y}_t 는 다음과 같이 온라인 메모리 항과 캐시된 메모리 항의 합으로 표현됩니다.
여기서 흥미로운 점은 검색 과정의 변화입니다. 기존 RNN이 현재 메모리 상태 하나만으로 출력을 계산(\mathbf{y}_t = \mathcal{M}_t(\mathbf{q}_t) )했다면, MC는 쿼리 \mathbf{q}_t 에 대해 현재 메모리와 모든 캐시된 메모리에 대해 순방향 패스를 수행합니다. 이때 전체 복잡도는 O(NL) 이 되며, 여기서 N 은 세그먼트의 개수입니다(1 \leq N \leq L ). N=1 이면 캐싱할 메모리가 없어 단순 순환 모델이 되고, N=L 이면 모든 토큰이 개별 세그먼트가 되어 어텐션의 직관과 정확히 일치합니다. 즉 세그먼트 크기가 압축의 정도(검색 성능)와 연산 비용 사이의 트레이드오프를 조절하는 손잡이 역할을 하는 셈입니다.
네 가지 집계(Aggregation) 전략
MC의 진짜 설계 공간은 "캐시된 메모리들을 어떻게 현재 출력에 녹여낼 것인가" 라는 집계 함수 \texttt{Agg}(\cdot) 의 선택에 있습니다. 논문은 네 가지 변형을 제안합니다. (i) Residual Memory, (ii) Gated Residual Memory(GRM), (iii) Memory Soup, 그리고 (iv) Sparse Selective Caching(SSC)입니다. 이어지는 절에서는 이 네 가지를 차례로 살펴본 뒤, 이들과는 별개인 핵심 설계 축 하나를 추가로 다룹니다.
Residual Memory와 Gated Residual Memory(GRM)
가장 단순한 집계 연산자는 덧셈입니다. 캐시된 메모리들을 메모리 상태 간의 잔차 연결(residual connection)처럼 그대로 더하는 것이지요. 이 방식은 마치 책을 읽으면서 중요한 페이지마다 포스트잇을 붙여두고, 새 페이지를 읽을 때 붙여둔 포스트잇들을 함께 들춰보는 것과 비슷합니다. 흥미롭게도 메모리 모듈이 엄격히 선형(즉 \mathcal{M} 이 행렬)인 경우, 이 단순 잔차 형태는 캐시된 메모리들을 미리 합산할 수 있어 수학적으로는 표준 고정 크기 메모리로 붕괴(collapse) 해 버립니다. 그럼에도 실험에서는 이 단순한 형태조차 순환 모델의 성능을 끌어올렸는데, 잔차 메모리가 먼 과거에 대한 접근을 강화하는 일종의 보존(retention) 연산자로 작동하기 때문입니다.
하지만 단순 잔차에는 한계가 있습니다. 모든 캐시된 메모리를 동등하게 취급하여, 현재 쿼리와의 관련성을 무시한다는 점입니다. 이를 보완하기 위해 입력에 의존하는 게이팅(gating)을 도입한 것이 Gated Residual Memory(GRM) 입니다. 각 세그먼트의 기여도를 조절하는 파라미터 0 \leq \gamma_t^{(i)} \leq 1 를 두어, \gamma_t^{(i)} \to 1 이면 해당 세그먼트의 기여가 커지고 \gamma_t^{(i)} \to 0 이면 작아지도록 만듭니다. 입력에 의존하는 이 파라미터 덕분에 GRM은 미리 계산해두거나 다음 토큰에 재사용할 수 없으며, 따라서 선형 메모리에서도 고정 메모리로 붕괴하지 않습니다.
여기서 한 가지 설계상의 통찰이 더해집니다. \gamma_t^{(i)} 를 단순히 입력 x_t 의 선형 투영으로만 정의하면, 이는 위치 기반 필터링에 그칩니다. 즉 i 번째 세그먼트의 내용이 무엇이든 상관없이 위치만으로 기여도가 정해지는 것이지요. 저자들은 이를 극복하기 위해 \gamma_t^{(i)} 를 입력 x_t 와 세그먼트 S^{(i)} 양쪽의 맥락에 의존하도록 만듭니다. 연결자(connector) 파라미터 \mathbf{u}_t = x_t W_{\mathbf{u}} 를 도입하고, 세그먼트의 평균 풀링(MeanPooling) 표현과의 유사도로 게이트 값을 정의한 뒤 softmax로 정규화합니다.
Memory Soup
두 번째 변형인 Memory Soup 는 순환 과정을 메타 학습(meta-learning)으로, 메모리 상태들을 체크포인트로 바라보는 관점에서 출발합니다. 이름에서 짐작되듯, 여러 미세조정(fine-tuning) 모델의 가중치를 평균 내어 성능을 높이는 Model Soups 에서 영감을 받았습니다. 핵심 아이디어는 캐시된 메모리들의 파라미터 자체를 데이터 의존적으로 결합하여, 토큰마다 자신만의 단일 메모리를 만들어 검색에 사용하는 것입니다. 각 토큰이 "자기 자신에게 맞춤화된 메모리를 직접 빚어내어 그로부터 필요한 정보를 검색한다" 고 해석할 수 있습니다.
여기서 중요한 구분이 생깁니다. 메모리 모듈이 선형일 때 Memory Soup는 GRM과 수학적으로 완전히 동일합니다. 가중치를 먼저 섞은 뒤 쿼리를 적용하는 것과, 개별 메모리에 쿼리를 적용한 뒤 출력을 앙상블하는 것이 선형성 덕분에 같아지기 때문입니다. 이 차이가 결정적으로 벌어지는 것은 DLA나 Titans 같은 깊은(deep) 비선형 메모리 모듈을 쓸 때입니다. 이 경우 Memory Soup는 파라미터를 보간하여 그 시점에 특화된 비선형 검색 함수를 새로 구성하므로, 단순히 출력을 더하는 GRM과는 본질적으로 다른 해를 제공합니다.
Sparse Selective Caching(SSC)
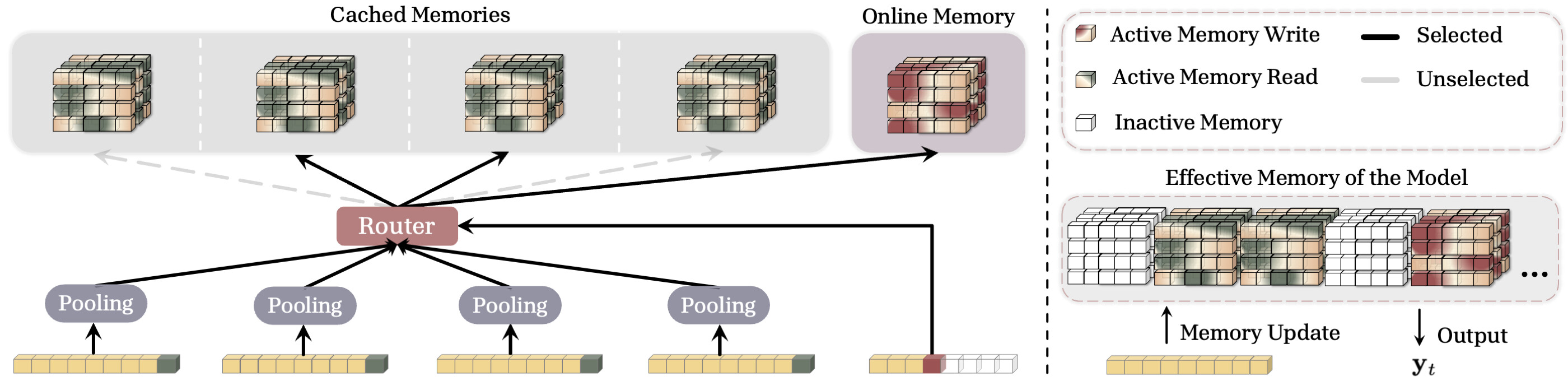
앞선 변형들은 모든 과거 캐시 메모리를 참조하므로, 초장문 시퀀스에서는 상당한 메모리 오버헤드를 유발할 수 있습니다. Sparse Selective Caching(SSC) 는 각 토큰이 맥락에 따라 캐시된 메모리의 부분집합만 선택하도록 하여 효율을 개선합니다. 전문가 혼합(Mixture of Experts, MoE) 에서 영감을 받아, 토큰과 각 세그먼트 맥락 사이의 유사도를 측정하는 라우터(router)를 두는 것이 핵심입니다.
각 세그먼트 S^{(i)} 에 대해 관련성 점수 \mathbf{r}_t^{(i)} 를 계산한 뒤, 라우터는 가장 관련성이 높은 k 개의 캐시 메모리를 \texttt{Top-}k 로 선택합니다. 현재 온라인 메모리와 함께 이 선택된 메모리들만으로 검색을 수행하지요. 이 방식의 실용적 장점은 분명합니다. 세그먼트의 MeanPooling 표현은 미리 계산해둘 수 있으므로 관련성 점수 계산과 Top-k 선택이 병렬화 가능하고, 무엇보다 캐시된 메모리 상태 전체를 가속기(GPU, TPU)에 올려둘 필요 없이 "선택된" 메모리만 로드하면 됩니다. 덕분에 학습과 추론 양쪽에서 메모리 소비를 크게 줄일 수 있습니다.
SSC는 하나의 희소 통합 메모리(sparse unified memory) 로 해석할 수도 있습니다. 각 토큰이 메모리 쓰기(저장)에는 일부 파라미터를, 검색에는 더 넓은 부분집합의 파라미터를 활성화하는 구조로 보는 것이지요. 이렇게 하면 메모리가 (1) 과거 메모리와 간섭 없이 정보를 저장하고, (2) 적응적이고 효율적으로 정보를 검색할 수 있게 됩니다.
체크포인트를 캐싱할까, 독립 압축기를 쓸까?
마지막으로 논문은 미묘하지만 중요한 설계 선택을 짚습니다. 우리가 캐싱하는 것이 하나의 메모리가 학습되어 온 체크포인트인지, 아니면 각 세그먼트를 독립적으로 압축하는 별개의 메모리 모듈인지의 문제입니다.
- 최적화 관점: 연상 기억을 학습시키는 과정으로 보면, 시퀀스의 토큰들은 학습 데이터 샘플입니다. 과거 지식을 잊지 않도록 학습(최적화) 과정의 체크포인트를 캐싱하며, 각 세그먼트의 메모리는 이전 세그먼트의 마지막 상태에서 이어서 시작합니다(\mathcal{M}_0^{(s)} = \mathcal{M}_{L^{(s-1)}}^{(s-1)} ).
- 압축 관점: 캐시된 메모리가 해당 세그먼트 정보의 압축된 대표여야 한다고 보면, 세그먼트 간 간섭을 피하기 위해 각 세그먼트마다 이전과 독립적인 초기 상태에서 출발하는 별개의 메모리를 사용합니다.
저자들은 이 두 선택이 각자의 장단점을 가진다고 관찰하며, 이를 절제 연구(Ablation Study)에서 검증합니다.
이론적 통찰: 어텐션과 하이브리드 모델을 다시 보다
MC 프레임워크의 매력적인 점은, 이미 잘 알려진 구조들을 자신의 특수한 경우로 재발견한다는 데 있습니다. 세그먼트 크기를 1로 두고 값이 없는(value-less) 벡터값 순환 메모리에 MC를 적용하면, 입력의 선형 투영으로 게이팅된 어텐션 블록인 게이트 전역 소프트맥스 어텐션(gated global softmax attention) 이 그대로 복원됩니다. 즉 어텐션조차 "과거 입력을 캐싱하도록 강제하는 모듈" 로 바라볼 수 있다는 관점을 제공합니다.
더 나아가, 최근 인기 있는 하이브리드 모델(순환 압축기 + 전역 어텐션)이 왜 잘 작동하는지에 대한 설명도 제시합니다. 압축기 층의 출력을 어텐션의 입력으로 넘기는 흔한 레시피는, 세그먼트 크기가 1이고 메모리 체크포인트를 캐싱하는 MC와 (단순화된 형태에서) 동등합니다. 이는 하이브리드 모델이 결국 순환 모델의 실질적 메모리 용량을 키우는 장치였음을 시사합니다. 한 걸음 더 나아가 MC는 \mathbf{q}_t = \mathds{1} 라는 제약을 넘어, 쿼리마다 어텐션의 입력 시퀀스를 다르게 구성하는 애드혹 어텐션(ad-hoc attention) 으로 일반화할 수 있습니다. 사전에 고정된 토큰 시퀀스가 아니라, 모델이 쿼리 \mathbf{q}_t 에 맞춰 자신만의 입력 시퀀스를 빚어내는 것이지요.
반면 깊은 메모리(deep memory) 에 MC를 적용하면 하이브리드 변형과 전혀 겹치지 않는 새로운 아키텍처 부류가 탄생합니다. 메모리가 2층 MLP일 때 각 토큰은 벡터나 행렬이 아닌 텐서로 표현되며, 쿼리에 따라 같은 토큰의 맥락과 표현이 달라질 수 있습니다. 일반 지식을 인코딩하는 초기 편향항 \mathcal{M}_0^{(i)} 자체가 신경망이므로, 서로 다른 쿼리에 대한 검색 결과에 미치는 영향도 동일하지 않습니다.
세그먼트화가 용량과 복잡도에 미치는 영향
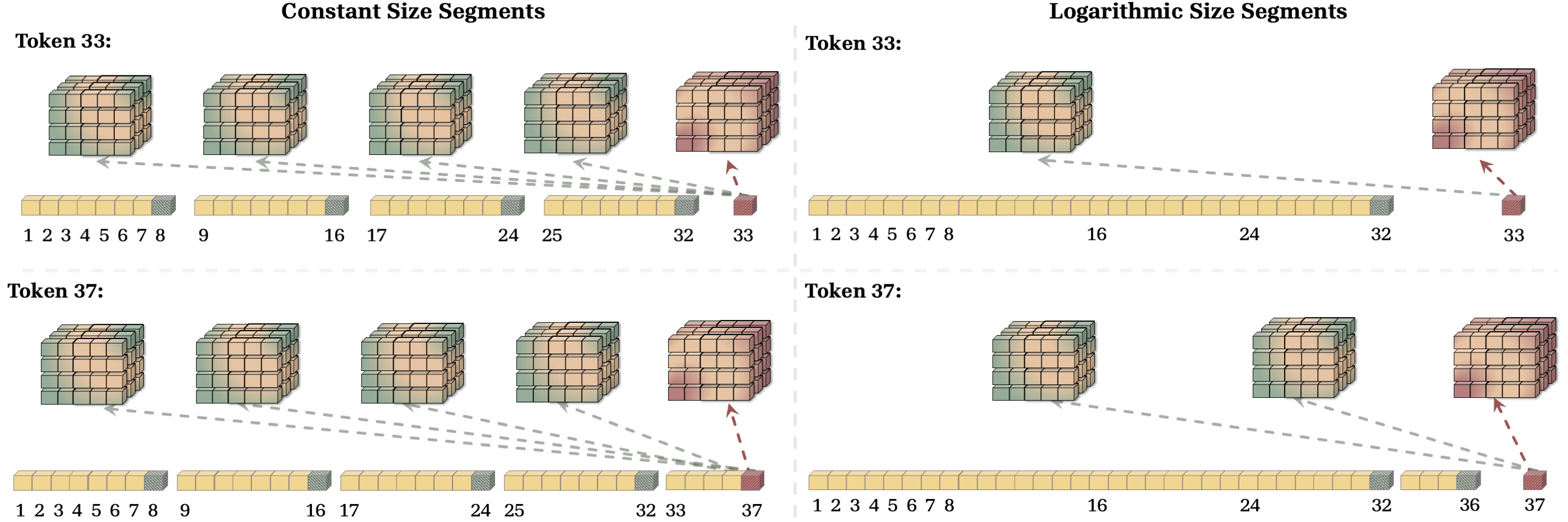
세그먼트화는 MC의 가장 중요한 설계 선택 중 하나입니다. 세그먼트 길이는 압축의 정도와 연산 비용 사이의 트레이드오프를 직접 결정합니다. 길이가 C = \frac{L}{N} \geq 2 인 균등 세그먼트를 쓰면 연산 비용은 O(p \times \frac{L^2}{C}) 가 되어, 트랜스포머와 같은 형태이지만 더 작은 상수항을 가져 효율이 좋아집니다. 또 다른 방식은 시퀀스를 로그 스케일로 분할하는 것입니다. 예를 들어 길이 37 = (100101)_2 의 시퀀스는 길이 32, 4, 1 의 세 세그먼트로 나뉘며, 이때 N 의 최댓값은 \log_2(L) 이 되어 복잡도가 O(p \times L\log(L)) 로 떨어집니다.
다만 로그 세그먼트화는 효율적인 만큼 대가가 따릅니다. 먼 과거의 토큰에 대해 훨씬 낮은 해상도를 제공하므로, 검색 집약적 작업에서는 능력이 제한됩니다. 위 그림이 보여주듯, 로그 분할은 너무 긴 부분 시퀀스(메모리 오버플로 위험)나 너무 짧은 부분 시퀀스(내부 루프에서 메모리가 제대로 최적화되지 못함)를 만들어낼 수 있습니다.
실험 결과 및 성능 분석
저자들은 개념 증명(proof of concept)으로 Linear Attention, SWLA(Sliding Window Linear Attention, c=2 ), 깊은 메모리 모듈인 DLA(Deep Linear Attention) 와 Titans(LMM) 의 네 가지 순환 구조에 MC를 적용해 평가했습니다. 실험 설정은 대체로 Log-Linear Attention 연구를 따랐으며, FineWeb과 Long-Data-Collections를 혼합한 데이터로 760M(30B 토큰)과 1.3B(100B 토큰) 규모의 모델을 학습했습니다.
언어 모델링과 상식 추론
언어 모델링과 상식 추론 벤치마크(Table 1)에서 세 가지 핵심 관찰이 나왔습니다.
첫째, DLA, Titans, SWLA를 각각의 MC 강화 버전과 비교하면, 모든 MC 변형이 다양한 다운스트림 작업과 평균 성능에서 일관된 개선을 보였습니다. 둘째, MC는 어텐션과 순환 모델의 (희소) 하이브리드로 해석할 수 있는데, MC 강화 모델은 하이브리드(Samba)와 트랜스포머 같은 어텐션 기반 모델까지 능가하며 순환 모델의 제한된 메모리 문제에 더 강력한 해법을 제공했습니다. 셋째, MC의 상수 크기 세그먼트화가 Log-Linear++ 방식보다 더 나은 결과를 냈으며, 변형들 중에서는 GRM과 SSC가 우수했습니다.
1.3B 모델 기준 평균 점수를 보면, Titans(LMM) 의 56.82 가 GRM을 적용하자 58.33 으로 올랐고(+1.51 ), 같은 규모의 Log-Linear++(57.19 )와 트랜스포머 기반 하이브리드인 Samba(54.46 )도 넘어섰습니다. DLA 역시 53.72 에서 GRM 적용 후 55.96 으로, SWLA 는 52.55 에서 54.60 으로 상승했습니다. 선형 메모리(SWLA)부터 깊은 메모리(DLA, Titans)까지 기반 구조의 종류와 무관하게 MC가 일관되게 향상을 가져온다는 점이 눈에 띕니다.
| 모델 (1.3B / 100B 토큰) | Wiki. ppl \downarrow | LMB. ppl \downarrow | 평균 Acc. \uparrow |
|---|---|---|---|
| Transformer++ | 17.92 | 17.73 | 53.19 |
| SWLA | 18.47 | 16.23 | 52.55 |
| SWLA + GRM (= Soup) | 18.51 | 15.95 | 54.60 |
| DLA | 16.31 | 12.29 | 53.72 |
| DLA + GRM | 16.08 | 12.10 | 55.96 |
| Titans (LMM) | 15.60 | 11.41 | 56.82 |
| Titans + Log-Linear++ | 15.49 | 11.38 | 57.19 |
| Titans + GRM | 15.37 | 11.29 | 58.33 |
Needle-In-A-Haystack: 긴 컨텍스트 검색
MC의 진가가 가장 극적으로 드러나는 곳은 긴 컨텍스트 검색 작업인 Needle-in-a-Haystack(NIAH) 입니다(Table 2). MC 강화 DLA와 Titans는 기본 모델을 일관되게 능가했으며, 특히 긴 컨텍스트에서 Log-Linear 방식을 크게 앞질렀습니다. Log-Linear가 단일 메모리에 매우 큰 초기 세그먼트를 압축하도록 강요받는 반면, MC는 압축 부담을 여러 메모리에 효과적으로 분산하기 때문입니다.
가장 까다로운 UUID 기반 검색(S-NIAH-3)의 16K 컨텍스트에서, DLA는 4.0 점에 그쳤지만 GRM을 더하자 18.2 점으로 4\times 이상 뛰어올랐습니다. Titans 역시 같은 조건에서 21.2 점에서 32.2 점으로 상승했고, 숫자 검색(S-NIAH-2)의 16K에서는 75.4 점에서 88.2 점으로 개선되었습니다.
| S-NIAH-2 (숫자, Acc.) | 4K | 8K | 16K |
|---|---|---|---|
| DLA | 79.6 | 42.6 | 28.2 |
| DLA + GRM | 94.6 | 82.8 | 54.8 |
| Titans (LMM) | 99.6 | 84.6 | 75.4 |
| Titans + GRM | 99.8 | 96.6 | 88.2 |
In-context 검색, LongBench, MQAR
In-context 검색 작업(SWDE, NQ, DROP, FDA, SQuAD, TQA 등)은 순환 신경망에게 가장 도전적인 벤치마크입니다(Table 3). 이 영역에서는 여전히 트랜스포머가 최고 정확도를 기록했지만, MC 변형들은 경쟁력 있는 성능으로 트랜스포머와의 격차를 좁히면서 최첨단 순환 모델을 능가했습니다. 긴 컨텍스트 이해를 평가하는 LongBench(Table 4)에서도 모든 MC 강화 변형이 기본 RNN 대비 성능 향상을 보였는데, 이 역시 늘어난 메모리 용량 덕분으로 분석됩니다. 다중 쿼리 연상 검색(MQAR) 에서는 MC 변형들이 Atlas 같은 최첨단 모델과 비교해 차원당 최고 성능을 달성했습니다.
효율성: 두 세계의 장점을 모두
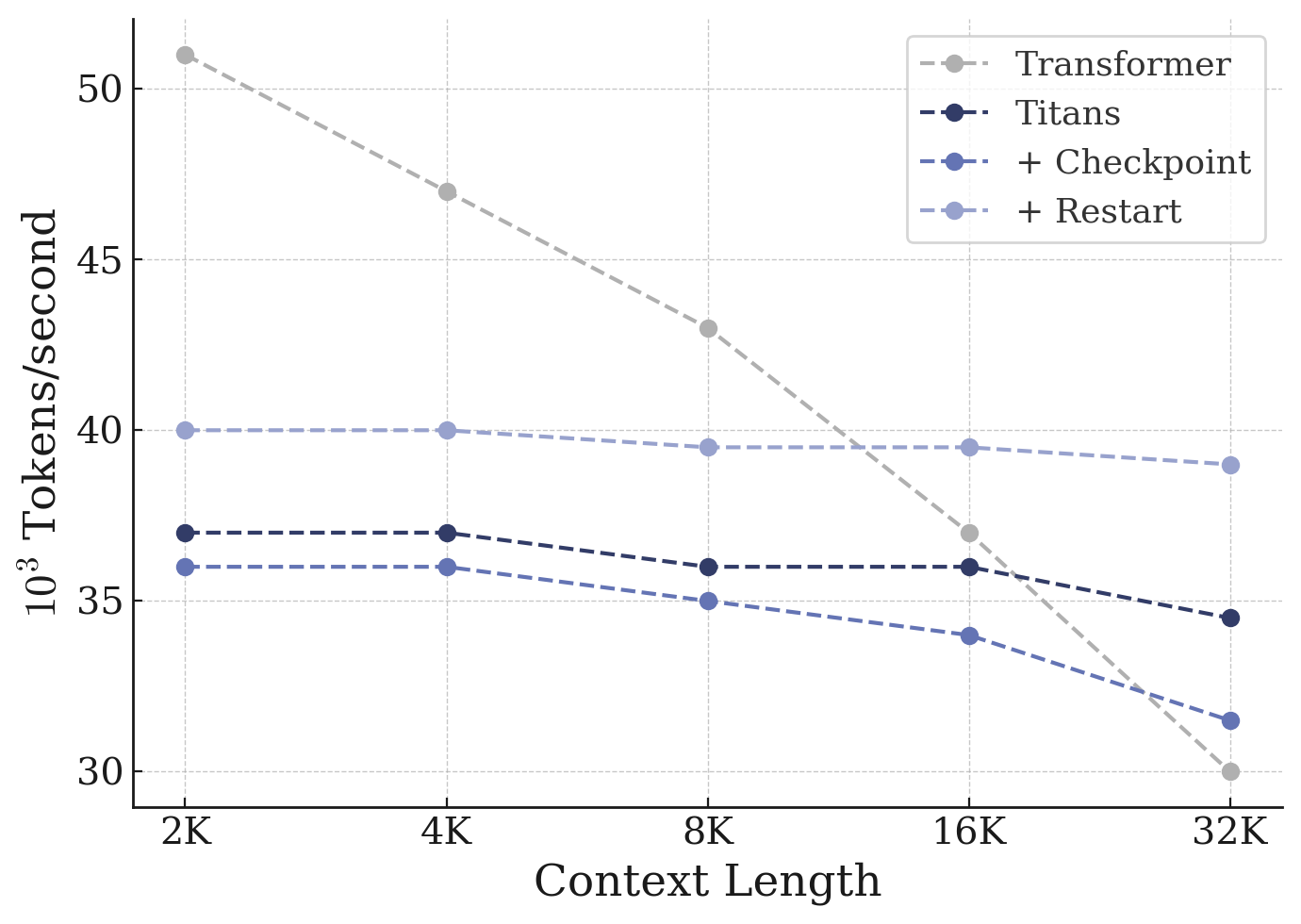
그렇다면 이 모든 성능 향상이 효율성을 희생한 대가일까요? 학습 처리량을 측정한 결과(Figure 4), MC 변형들은 트랜스포머와 RNN 사이의 중간 지대를 차지했습니다. 트랜스포머의 처리량은 컨텍스트 길이가 2K에서 32K로 늘어남에 따라 초당 약 51\text{K} 토큰에서 30\text{K} 토큰으로 가파르게 떨어졌지만, MC 변형들은 거의 일정한 처리량을 유지했습니다. 그 결과 긴 컨텍스트로 갈수록 MC 변형이 트랜스포머보다 더 빨라지는 역전이 일어납니다.
특히 SSC 변형은 두 세계의 장점을 모두 취했습니다. 앞서 살펴본 다양한 다운스트림 작업에서 다른 변형들과 동등하거나 더 나은 성능을 내면서도, 원래의 기본 모델 대비 최소한의 오버헤드만 추가했기 때문입니다.
절제 연구(Ablation Study)
마지막으로 저자들은 MC 프레임워크의 설계 선택들을 검증했습니다(Table 5). 첫째, 게이트 \gamma 를 입력만의 함수로 둘지 아니면 블록의 맥락까지 반영할지의 선택은 평균 성능에 유의미한 개선을 가져왔습니다. 둘째, 게이팅을 제거하면 설계가 잔차 메모리로 붕괴하는데, 이 단순한 형태조차 모델 성능을 끌어올렸습니다. 셋째, 선형 메모리 모듈을 사용했을 때 놀랍게도 MC는 메모리 구조와 표현력에 대해 더 강건한 성능을 보였습니다. 모든 설계 선택이 MC의 효과에 긍정적으로 기여한다는 결론입니다.
한계점 및 향후 전망
저자들은 결론에서 솔직한 태도를 보입니다. 이 논문의 많은 선택은 메모리 캐싱이라는 아이디어 자체의 효과를 더 분명하게 드러내기 위해 결과 모델을 최대한 단순하게 유지하는 방향으로 이루어졌습니다. 실험 또한 일부 베이스라인에 대한 개선임을 분명히 하며, MeanPooling이나 Top-k 라우팅 같은 구성 요소들이 의도적으로 단순하게 설계되었음을 인정합니다. 향후 연구에서 더 표현력 있는 풀링이나 라우팅 메커니즘을 도입하면 성능을 한층 끌어올릴 여지가 있습니다.
그럼에도 이 연구가 던지는 메시지는 분명합니다. 트랜스포머와 RNN을 메모리 용량이라는 단일 축 위의 양극단으로 통합하고, 그 사이를 자유롭게 조절할 수 있는 손잡이를 제공한다는 점입니다. 고정 메모리라는 RNN의 근본적 약점을 구조를 바꾸지 않고도 캐싱이라는 단순한 장치로 완화할 수 있으며, 더 나아가 하이브리드 모델과 어텐션이 왜 작동하는지에 대한 통일된 관점까지 제시합니다. 효율성과 검색 능력 사이의 오랜 줄다리기에서, Memory Caching은 둘 중 하나를 포기하는 대신 그 사이를 설계 가능한 연속체로 바꾸어 놓은 의미 있는 이정표라 할 수 있습니다.
 Memory Caching: RNNs with Growing Memory 논문
Memory Caching: RNNs with Growing Memory 논문
Transformers have been established as the de-facto backbones for most recent advances in sequence modeling... We introduce Memory Caching (MC), a simple yet effective technique that enhances recurrent models by caching checkpoints of their memory states.
Titans: Learning to Memorize at Test Time 논문 (관련 연구)
Atlas: Learning to Optimally Memorize the Context at Test Time 논문 (관련 연구)
더 읽어보기
-
LightMem: LLM 및 AI Agent를 위한 효율적인 경량 메모리 프레임워크에 대한 연구 및 라이브러리
-
MAI-Thinking-1 기술 보고서: 데이터 파이프라인부터 RL 인프라까지, 프런티어 모델 학습의 전 과정을 해부한 '힐 클라이밍 머신' (feat. Microsoft AI)
-
사고 패치(Thought Patching): 프롬프트를 가중치로 바꾸는 모델 편집에 대한 연구 (feat. Google)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()