Mooncake 소개
Mooncake는 Moonshot AI의 LLM 서비스 Kimi를 떠받치는 서빙 플랫폼으로, "KVCache를 중심에 둔 분리형 아키텍처(KVCache-centric Disaggregated Architecture)"를 핵심으로 삼습니다. 대규모 LLM 서비스에서 가장 큰 비용은 입력을 한 번에 처리하는 프리필(prefill) 단계와 토큰을 하나씩 생성하는 디코드(decode) 단계가 서로 다른 자원 특성을 가지면서도 같은 GPU에 묶여 있다는 데서 발생합니다. Mooncake는 이 두 단계를 분리하고, 그 사이를 잇는 KVCache를 일급 시민으로 끌어올려 전체 처리량을 끌어올립니다.
Mooncake의 기술 보고서는 USENIX FAST 2025에서 발표되어 최우수 논문상(Best Paper Award)을 받았습니다. 저자들은 모든 요청을 처리한다고 가정하는 기존 연구와 달리, 과부하 상황을 정면으로 다루기 위해 예측 기반 조기 거절(prediction-based early rejection) 정책을 설계했다고 설명합니다. 보고서에 따르면 Mooncake는 긴 컨텍스트 시나리오에서 특히 강점을 보이며, 일부 시뮬레이션 환경에서는 SLO를 지키면서도 기준 방식 대비 최대 525%까지 처리량을 늘렸고, 실제 워크로드에서는 Kimi가 75% 더 많은 요청을 처리할 수 있게 했습니다.
현재 Mooncake는 핵심 구성요소인 전송 엔진(Transfer Engine)과 Mooncake Store가 오픈소스로 공개되어 있으며, 2026년 2월 PyTorch 생태계(PyTorch Ecosystem)에 공식 합류했습니다. vLLM, SGLang, TensorRT-LLM 같은 주요 추론 스택에 통합되어 KV 캐시 전송과 분산 저장 백엔드로 쓰이고 있습니다. 본 게시물에서는 Mooncake의 분리형 아키텍처, 네 가지 핵심 구성요소, 전송 성능, 설치 방법, 그리고 생태계 통합 현황을 정리합니다.
Mooncake의 KVCache 중심 분리형 아키텍처

Mooncake는 프리필 클러스터와 디코드 클러스터를 분리하고, GPU 클러스터에서 충분히 활용되지 못하던 CPU·DRAM·SSD 자원을 모아 분리된 KVCache 풀(disaggregated KVCache pool)을 구성합니다. 위 다이어그램에서 보듯 프리필 풀(Prefill Pool)과 디코드 풀(Decoding Pool)은 각자의 GPU/VRAM과 페이지드 KVCache를 가지며, 그 아래 CPU/DRAM/SSD 계층의 분산 KVCache 풀이 두 풀을 가로질러 캐시를 공유합니다. 풀 사이의 데이터 이동은 중앙의 KVCache Transfer Engine이 RDMA로 처리합니다.
이 구조의 두뇌는 KVCache 중심 스케줄러입니다. 그림 왼쪽의 KVCache 중심 컨덕터(KVCache-centric Conductor)는 캐시 인식 프리필 스케줄러, KVCache 밸런스 스케줄러, 부하 분산 디코드 스케줄러로 나뉘어, 전체 유효 처리량을 최대화하면서 지연 관련 SLO를 만족시키는 방향으로 요청을 배치합니다. 프리필 단계는 TTFT(첫 토큰까지의 시간) SLO를 지키며 캐시 재사용을 극대화하는 것을, 디코드 단계는 TBT(토큰 간 시간) SLO를 지키며 처리량을 극대화하는 것을 목표로 삼습니다.
이러한 분리 덕분에 프리필과 디코드 자원을 독립적으로 확장할 수 있습니다. 실제로 Mooncake는 128대의 H200 GPU에서 PD 분리와 대규모 전문가 병렬(expert parallelism)을 적용해 Kimi K2를 배포했고, 이때 프리필 22.4만 토큰/초, 디코드 28.8만 토큰/초의 처리량을 달성한 것으로 보고되었습니다.
Mooncake의 핵심 구성요소
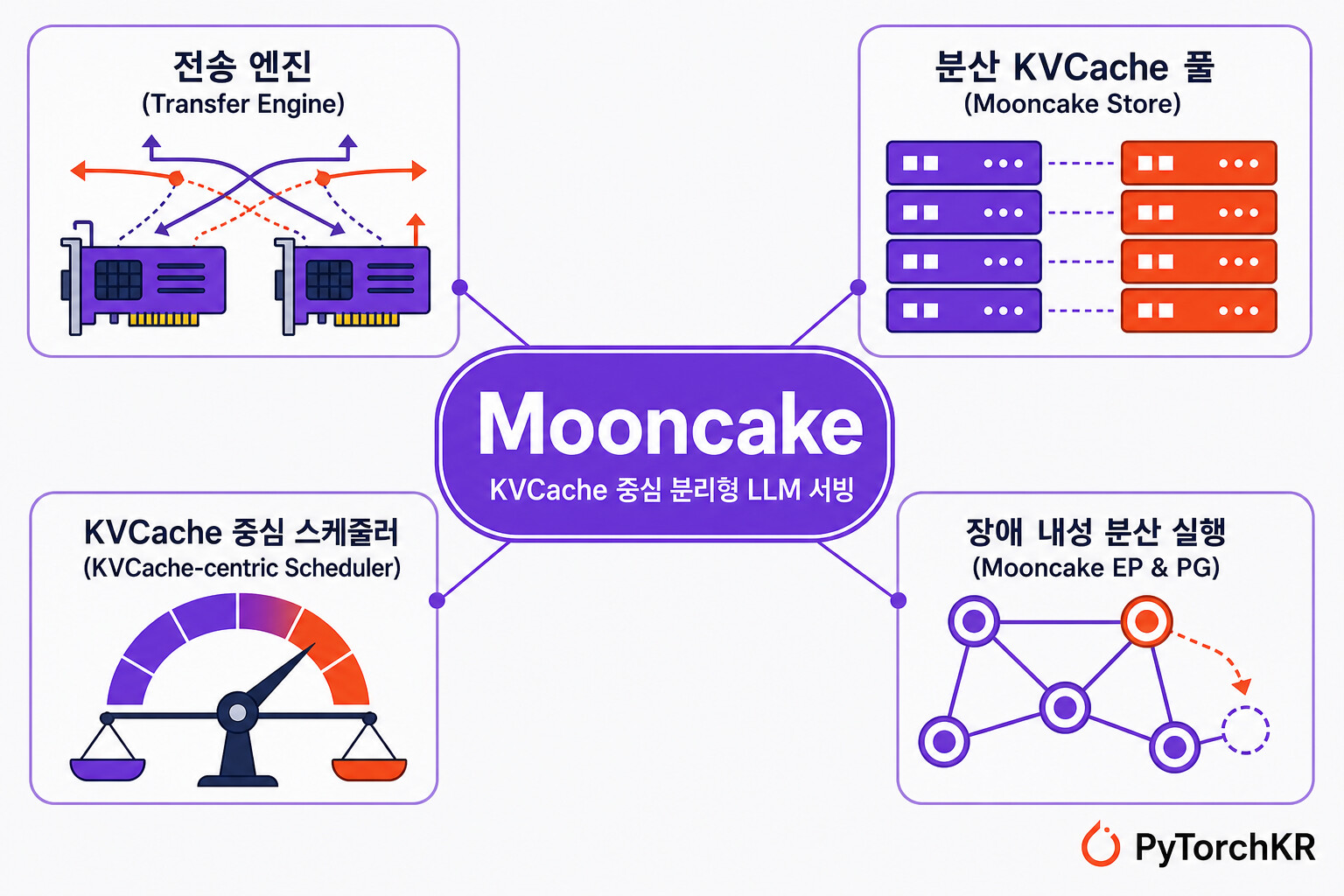
Mooncake는 텐서(Tensor)를 기본 데이터 단위로 삼는 풀스택 인프라를 지향하며, 크게 세 가지 구성요소로 이뤄져 있습니다.
전송 엔진(Transfer Engine) 은 Mooncake의 중심에 있는 고성능 데이터 전송 프레임워크입니다. 다양한 저장소·네트워크·가속기 환경에 걸친 배치(batched) 데이터 이동을 단일 인터페이스로 제공하며, 여러 RDMA NIC의 대역폭을 합치고(bandwidth aggregation) NUMA 친화도 등 토폴로지를 인식해 최적 경로를 고릅니다. 전송이 실패하면 자동으로 대체 경로를 시도하는 장애 복구 기능도 갖췄습니다. TCP, RDMA, AWS EFA, NVMe-oF, NVLink, CXL, Ascend 계열 등 폭넓은 전송 프로토콜과 가속기를 지원합니다.
Mooncake Store 는 전송 엔진 위에 구축된 분산 키-값 캐시 저장 엔진입니다. 추론 클러스터 전체에 걸쳐 재사용 가능한 KV 캐시와 모델 가중치를 저장·관리하며, 대형 객체 스트라이핑과 병렬 I/O, 종단 간 제로카피(zero-copy) 전송으로 여러 NIC의 대역폭을 끌어 씁니다. DRAM과 SSD/NVMe를 아우르는 다계층 캐시 구조를 지원하고, 객체별로 복제본 수나 소프트·하드 핀(pin) 같은 정책을 지정해 중요한 캐시를 보호할 수 있습니다.
Mooncake EP와 Process Group(PG) 은 대규모 MoE(Mixture-of-Experts) 추론을 위한 장애 내성 분산 실행 계층입니다. Mooncake EP는 DeepEP 스타일의 전문가 병렬 디스패치·결합 연산에 랭크 활성도(active_ranks) 인식을 더해 실패한 랭크를 우회하도록 하고, Mooncake PG는 torch.distributed 백엔드로 등록되어 all_gather 같은 집합 통신을 제공하면서 실패한 랭크를 감지·보고하고 전체 추론 서비스를 재시작하지 않고도 랭크를 복구합니다.
Mooncake Transfer Engine의 전송 성능
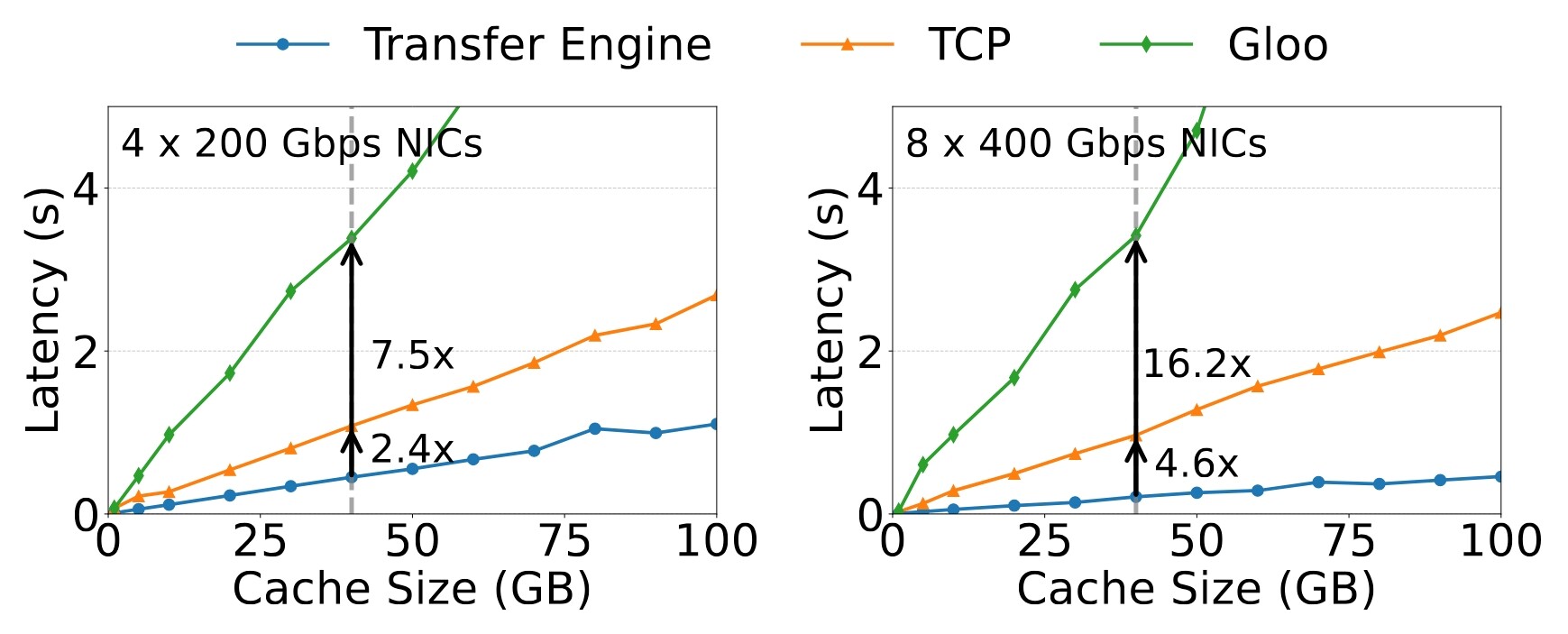
저자들은 40GB 데이터(LLaMA3-70B 모델에서 12.8만 토큰이 만드는 KVCache 크기에 해당)를 전송하는 실험을 제시합니다. 보고서에 따르면 전송 엔진은 4×200Gbps RoCE 네트워크에서 최대 87GB/s, 8×400Gbps에서 최대 190GB/s의 대역폭을 내며, 이는 TCP 프로토콜보다 각각 약 2.4배, 4.6배 빠른 수치입니다. 위 차트는 캐시 크기에 따른 전송 지연을 비교한 것으로, 전송 엔진(파란색)이 TCP(주황색)와 Gloo(초록색)보다 일관되게 낮은 지연을 유지하며 Gloo 대비로는 격차가 더 크게 벌어집니다.
Mooncake 설치 및 사용법
Mooncake는 고속 RDMA 네트워크를 전제로 설계·최적화되었습니다. TCP 단독 전송도 지원하지만, 저자들은 RDMA 네트워크 환경에서 평가할 것을 강하게 권장합니다. 실행 전에 Mellanox OFED 같은 RDMA 드라이버·SDK, Python 3.10, 그리고 CUDA 빌드를 쓸 경우 CUDA 12.1 이상이 필요합니다.
가장 간단한 사용법은 pip로 전송 엔진 패키지를 설치하는 것입니다. 환경에 맞는 휠을 고릅니다.
# CUDA < 13.0
pip install mooncake-transfer-engine
# CUDA >= 13.0
pip install mooncake-transfer-engine-cuda13
# 비 CUDA 환경
pip install mooncake-transfer-engine-non-cuda
# NPU 환경
pip install mooncake-transfer-engine-npu
소스에서 직접 빌드하려면 의존성 설치 스크립트와 표준 CMake 흐름을 따릅니다.
git clone https://github.com/kvcache-ai/Mooncake.git
cd Mooncake
sudo bash dependencies.sh
mkdir build && cd build
cmake ..
make -j
sudo make install # vLLM/SGLang에서 바로 쓰려면 (선택)
커스텀 가속기 백엔드, Docker 배포, NVMe-oF·EFA·CXL, Rust 바인딩 같은 고급 빌드 옵션은 Mooncake 공식 빌드 가이드에 정리되어 있습니다.
Mooncake의 생태계 통합
대부분의 사용자는 Mooncake를 직접 호출하기보다 추론 엔진의 백엔드로 사용합니다. vLLM은 MooncakeConnector로 프리필·디코드 분리 서빙에서 KV 캐시 블록을 전송하고, MooncakeStoreConnector로 인스턴스별로 고립돼 있던 KV 캐시를 클러스터 단위 공유 풀로 확장합니다. 후자는 해시 기반 프리픽스 캐싱으로 중복 프리필 연산을 줄여, 반복되는 프리픽스가 많은 에이전트·멀티턴 서빙 시나리오에서 특히 효과적입니다.
SGLang에서는 PD 분리 서빙의 전송 백엔드, HiCache의 다계층 KV 캐시 저장소, 장애 내성 전문가 병렬 추론, 멀티모달 파이프라인 데이터 이동, RL 학습용 RDMA 가중치 동기화 등 여러 지점에 깊게 통합되어 있습니다. 이 밖에도 전송 엔진은 TensorRT-LLM의 PD 분리 추론에서 KV 캐시 전송에 쓰이는 등 LLM 추론 스택 전반에서 채택되고 있습니다.
Mooncake의 라이선스
Mooncake는 Apache License 2.0으로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용할 수 있습니다.
 Mooncake 논문 (USENIX FAST 2025)
Mooncake 논문 (USENIX FAST 2025)
 Mooncake 공식 문서 사이트
Mooncake 공식 문서 사이트
 Mooncake 프로젝트 GitHub 저장소
Mooncake 프로젝트 GitHub 저장소
더 읽어보기
-
TokenSpeed: 에이전트형 워크로드를 위한 빠른 LLM 추론 엔진 (feat. Kimi K2.5, NVIDIA Blackwell)
-
Club-3090: RTX 3090 GPU에서 vLLM, llama.cpp, SGLang으로 LLM을 서빙하는 커뮤니티 레시피 모음
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()