
TokenSpeed 소개
LLM 추론 엔진(LLM Inference Engine)은 단순한 모델 서빙 도구를 넘어, 비용과 응답 시간을 좌우하는 인프라 핵심으로 자리 잡고 있습니다. vLLM, SGLang, TensorRT-LLM처럼 잘 알려진 추론 엔진은 각자 강점이 있지만, 에이전트형 워크로드(agentic workload)처럼 짧은 디코딩과 잦은 도구 호출이 반복되는 패턴에서는 스케줄링과 KV 캐시(KV cache) 관리, 통신 오버헤드의 비용이 빠르게 두드러집니다. 또한 사용자가 직접 텐서 병렬(tensor parallel)이나 시퀀스 병렬(sequence parallel)을 코드 수준에서 명시해야 하는 경우가 많아, 모델 구조가 바뀔 때마다 분산 로직을 다시 손봐야 하는 부담이 발생합니다. TokenSpeed는 이러한 한계를 정면으로 다루는 새 추론 엔진으로, "에이전트형 워크로드를 위한 빛의 속도 추론"을 목표로 설계된 오픈소스 프로젝트입니다.
TokenSpeed의 핵심 접근법은 컴파일 타임 정적 분석과 안전한 런타임 자원 관리를 결합한 것에 있습니다. 모델링 계층은 로컬 SPMD(Single Program Multiple Data) 설계를 따르며, 모듈 경계에 위치 지정 어노테이션을 붙이면 정적 컴파일러가 그에 맞는 집합 통신(collective communication) 코드를 자동으로 생성합니다. 그 결과 사용자는 직접 분산 로직을 작성하지 않아도, 모델 정의만으로 다중 GPU 병렬 추론을 얻을 수 있습니다. 스케줄러는 C++ 제어 평면(control plane)과 Python 실행 평면(execution plane)으로 나뉘어 있고, 요청 라이프사이클과 KV 캐시 소유권, 오버랩 타이밍을 유한 상태 머신(finite-state machine, FSM)으로 인코딩합니다. 또한 KV 자원의 안전한 재사용은 타입 시스템에 의해 컴파일 타임에 강제되어, 잘못된 재사용으로 인한 미묘한 메모리 충돌을 구조적으로 차단합니다.
기능 면에서 TokenSpeed는 TensorRT-LLM 수준의 성능과 vLLM 수준의 사용성을 동시에 추구합니다. 커널(kernel) 계층은 플러그형이며, 공개된 포터블 API와 중앙 레지스트리 위에 다층 커널 시스템이 구성되어 있고, 그중에는 NVIDIA Blackwell 아키텍처에서 에이전트 워크로드용으로 가장 빠른 부류에 속하는 MLA(Multi-head Latent Attention) 구현이 포함됩니다. 진입점은 SMG(Simple Multi-GPU) 통합 비동기 LLM(AsyncLLM)으로, CPU 측 요청 처리 오버헤드를 최소화하도록 설계되어 있습니다. 현재 공개된 버전은 Kimi K2.5 모델을 NVIDIA B200에서 재현하는 프리뷰 릴리스로, 더 많은 모델과 런타임 기능이 차차 본 메인 브랜치로 통합될 예정임을 명시하고 있습니다.

TokenSpeed의 아키텍처와 핵심 구성 요소
TokenSpeed는 추론 엔진을 구성하는 네 개의 계층을 명확히 분리하고, 각 계층의 책임을 코드 수준에서 강제합니다.
첫 번째 계층은 모델링 계층(Modeling layer)입니다. 사용자는 모델 모듈에 위치 지정 어노테이션(placement annotation)을 추가해 어떤 텐서가 어떤 디바이스에 어떻게 배치될지를 선언적으로 표시하고, 정적 컴파일러는 그 어노테이션을 분석해 필요한 all-reduce, all-gather, broadcast 같은 집합 통신 호출을 자동으로 삽입합니다. 사용자는 분산 로직을 직접 작성하지 않아도 텐서 병렬, 파이프라인 병렬 등 다양한 병렬화를 동일한 모델 정의에서 얻을 수 있습니다. 이러한 로컬 SPMD 설계는 PyTorch 사용자가 이미 익숙한 모듈 단위 작성 방식을 유지하면서, 분산 통신을 컴파일러가 책임지도록 만든 점이 특징입니다.
두 번째 계층은 스케줄러(Scheduler)입니다. C++ 제어 평면이 요청을 받고, Python 실행 평면이 실제 모델 호출을 수행하는 분리된 구조이며, 두 평면의 상호작용은 유한 상태 머신으로 모델링되어 있습니다. 요청은 도착, 프리필(prefill), 디코드(decode), KV 캐시 할당과 회수, 종료 등 명확한 상태로 표현되고, KV 캐시 자원 소유권은 Rust/C++ 스타일의 타입 시스템 기법으로 컴파일 타임에 보호됩니다. 그 결과 같은 KV 슬롯을 두 요청이 동시에 잡거나, 회수되지 않은 슬롯이 다음 요청에 흘러가는 식의 버그가 구조적으로 발생하기 어려운 형태가 됩니다.
세 번째 계층은 커널(Kernels)입니다. TokenSpeed의 커널 시스템은 포터블한 공개 API와 중앙 레지스트리를 갖추고 있어, 새로운 GPU 아키텍처나 새로운 어텐션 변형을 추가할 때 다른 부분을 건드리지 않고도 커널만 교체할 수 있도록 설계되어 있습니다. 특히 MLA(Multi-head Latent Attention) 구현은 NVIDIA Blackwell GPU 위에서 에이전트형 워크로드용으로 매우 빠른 부류에 속한다고 명시하고 있어, DeepSeek 계열 모델을 비롯한 MLA 기반 모델 운영에 최적화된 커널을 제공합니다.
네 번째 계층은 진입점(Entrypoint)입니다. SMG(Simple Multi-GPU)와 통합된 AsyncLLM 진입점은 CPU 측에서 발생하는 요청 변환과 라우팅 오버헤드를 줄이기 위해 비동기로 설계되어 있어, 짧은 디코딩이 잦은 에이전트형 워크로드에서 CPU가 병목이 되는 상황을 완화합니다.
TokenSpeed의 성능 비교: Kimi K2.5 on B200
TokenSpeed의 첫 공개 결과는 NVIDIA B200 GPU에서 Kimi K2.5 모델을 사용한 에이전트형 워크로드 측정입니다. README는 동일 워크로드에서 TokenSpeed와 TensorRT-LLM의 파레토 곡선(Pareto curve)을 비교한 차트를 제공하며, 두 엔진이 처리량(throughput)과 지연(latency) 사이에서 어떤 트레이드오프 곡선을 그리는지 한눈에 보여줍니다.
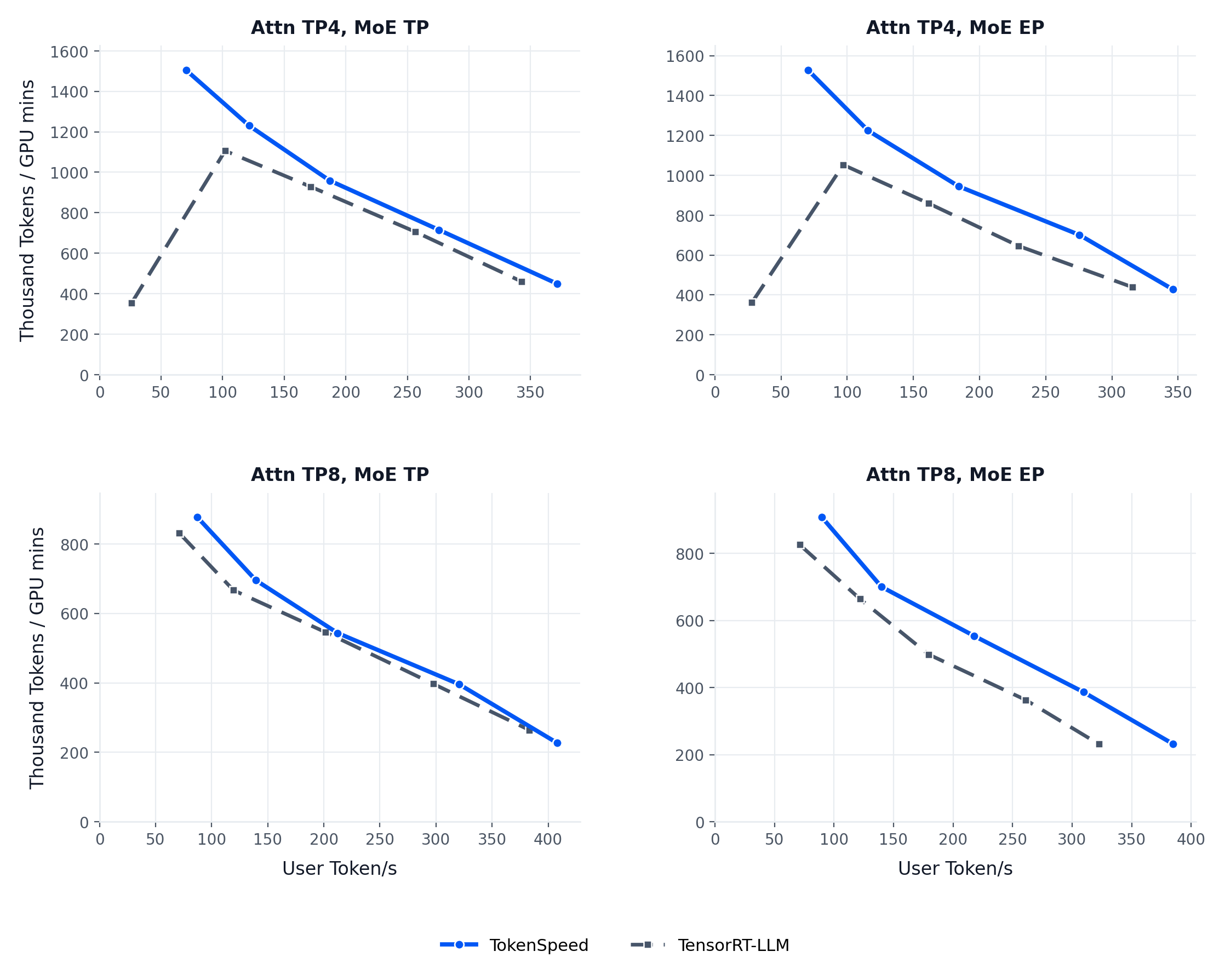
자세한 측정 환경과 분석은 TokenSpeed 공식 블로그(https://lightseek.org/blog/lightseek-tokenspeed.html)에서 다루며, README에서는 본 프리뷰 릴리스가 위 결과를 재현(reproduce)하기 위한 용도임을 명시하고 있습니다. 진행 중인 작업으로는 Qwen 3.6, DeepSeek V4, MiniMax M2.7 등 모델 커버리지 확장, Prefill-Decode 분리(PD), Expert-Parallel Load Balancing(EPLB), KV store, Mamba 캐시, VLM, 메트릭 수집 같은 런타임 기능, 그리고 Hopper 및 MI350 최적화 등의 플랫폼 작업이 함께 언급되어 있어, 공개된 부분이 아직 일부에 불과함을 시사합니다.
TokenSpeed PyTorch 사용 의사 코드
TokenSpeed는 사용자가 분산 통신을 직접 작성하지 않도록 하기 위해, PyTorch 모듈 정의에 위치 지정 어노테이션을 추가하는 방식으로 분산 추론 모델을 정의합니다. 다음은 README와 공식 문서의 설명을 바탕으로 정리한 PyTorch 의사 코드입니다.
import torch
import torch.nn as nn
# TokenSpeed의 placement annotation을 통해 텐서 병렬을 선언
from tokenspeed.placement import shard, replicate
class MLAAttention(nn.Module):
"""Multi-head Latent Attention block for agentic workloads."""
def __init__(self, hidden_dim: int, num_heads: int, latent_dim: int):
super().__init__()
# 가중치를 head 차원으로 분할 (텐서 병렬의 시드)
self.q_proj = shard(nn.Linear(hidden_dim, num_heads * latent_dim), dim=0)
self.k_proj = shard(nn.Linear(hidden_dim, num_heads * latent_dim), dim=0)
self.v_proj = shard(nn.Linear(hidden_dim, num_heads * latent_dim), dim=0)
# 출력은 모든 디바이스에 복제하여 reduce 직후 사용
self.o_proj = replicate(nn.Linear(num_heads * latent_dim, hidden_dim))
def forward(self, x: torch.Tensor, kv_cache) -> torch.Tensor:
q, k, v = self.q_proj(x), self.k_proj(x), self.v_proj(x)
# KV 자원은 타입 시스템이 추적하므로, 잘못된 재사용은 컴파일 타임 오류
attn = mla_kernel(q, k, v, kv_cache)
return self.o_proj(attn)
# AsyncLLM 진입점을 통해 비동기 요청 처리
from tokenspeed import AsyncLLM
llm = AsyncLLM.from_pretrained(
"kimi-k2.5",
placement="auto", # 자동 배치
backend="blackwell", # B200 커널 선택
)
async for token in llm.generate("Use the python tool to ..."):
print(token, end="", flush=True)
위 코드의 shard, replicate는 모듈 경계에 적용되는 위치 지정 어노테이션이며, 정적 컴파일러는 이를 분석해 필요한 집합 통신을 자동으로 삽입합니다. 사용자 입장에서는 forward에 일반 PyTorch 모듈을 작성하듯이 코드를 짜면 되고, 실제로 실행될 때는 분산 환경에 맞게 컴파일된 커널이 호출됩니다.
TokenSpeed 설치 및 시작하기
TokenSpeed는 현재 프리뷰 단계로, 공식 문서 사이트에서 설치와 서버 실행, 모델 레시피, 서버 파라미터, 병렬 실행 옵션 등에 대한 가이드를 제공합니다. README에서는 다음의 시작점을 권장합니다.
- Docs Index
- Getting Started
- Launching a Server
- Model Recipes
- Server Parameters
- Compatible Parameters
- Parallelism
README는 본 프리뷰 릴리스를 프로덕션 배포에 사용하지 말 것을 명시하고 있으며, 이는 새 런타임 설계와 기술 방향을 보여주기 위한 데모 성격임을 강조합니다. 따라서 현재 시점에서는 Kimi K2.5 on B200 재현, MLA 커널 성능 측정, 컴파일러 기반 SPMD 모델링 실험 등 연구·평가 용도로 사용하는 것이 적절합니다.
TokenSpeed 라이선스
TokenSpeed는 MIT 라이선스로 공개되어 있어, 개인 및 상업적 목적으로 자유롭게 사용·수정·배포할 수 있습니다. 다만 의존하는 NVIDIA 드라이버, CUDA, 모델 가중치(예: Kimi K2.5)의 라이선스 조건은 별도로 확인해야 합니다.
 TokenSpeed 공식 홈페이지
TokenSpeed 공식 홈페이지
 TokenSpeed 문서 사이트
TokenSpeed 문서 사이트
 TokenSpeed 프로젝트 GitHub 저장소
TokenSpeed 프로젝트 GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()