
VibeVoice 소개
음성 AI 기술이 빠르게 발전하고 있지만, 텍스트를 음성으로 변환하는 TTS(Text-to-Speech) 와 음성을 텍스트로 변환하는 ASR(Automatic Speech Recognition) 의 두가지 태스크(task)는 오랜 시간 동안 완전히 분리된 시스템으로 발전해 왔습니다. 이러한 파편화된 접근 방식은 통합 대화형 AI 시스템을 구축하려는 개발자들에게 시스템 복잡도 증가와 지연 시간(Latency) 문제라는 큰 장벽으로 작용했습니다. 마이크로소프트 리서치(Microsoft Research)가 새롭게 공개한 VibeVoice는 이 두 가지 핵심 작업을 단일 프레임워크 아래 매끄럽게 통합하여 음성 AI의 새로운 패러다임을 제시하는 오픈소스 모델 패밀리입니다.

VibeVoice의 가장 큰 의의는 연속적인 음향 표현을 활용하여 기존 모델들의 구조적 한계를 극복했다는 점입니다. 7.5Hz라는 매우 낮은 프레임 레이트(ultra-low frame rate)로 작동하는 연속 음성 토크나이저(Continuous Speech Tokenizer)를 기반으로 하여, 연산 효율성을 극대화하면서도 고품질의 음향 데이터를 유지합니다. 이 프레임워크 내에서 VibeVoice는 최대 60분의 긴 오디오를 한 번에 인식할 수 있는 ASR 모델과 300ms(밀리초) 이하의 초저지연을 달성한 경량 실시간 TTS 모델 등을 포괄적으로 제공합니다.
또한, VibeVoice는 자연어의 문맥과 의미를 깊이 있게 파악하기 위해 강력한 성능을 입증한 오픈소스 대형 언어 모델(LLM)인 Qwen2.5를 기반 모델로 채택했습니다. 이를 통해 대화의 흐름과 감정선을 이해하는 수준 높은 음성 합성과 정확한 전사가 가능해졌습니다. 다만, 기반 모델의 특성을 상속받기 때문에 Qwen2.5가 가진 데이터 편향성이 결과물에 일부 반영될 수 있다는 점을 마이크로소프트 측은 투명하게 명시하고 있으며, 상용 서비스 적용 시 개발자들의 주의가 필요합니다.
VibeVoice-ASR: 60분 장시간 음성 인식 모델 (7B)
VibeVoice-ASR은 70억 개(7B)의 파라미터를 갖춘 통합 Speech-to-Text 모델입니다. 가장 큰 특징은 단순히 음성을 텍스트로 받아쓰는 것을 넘어, 누가(화자 분리), 언제(타임스탬프), 무엇을 말했는지까지 한 번의 추론으로 모두 구조화하여 제공한다는 점입니다. 50개 이상의 언어를 안정적으로 처리하며, 사용자가 특정 도메인 용어나 고유명사를 쉽게 인식시킬 수 있는 맞춤형 핫워드(Customized Hotwords) 기능도 지원합니다.

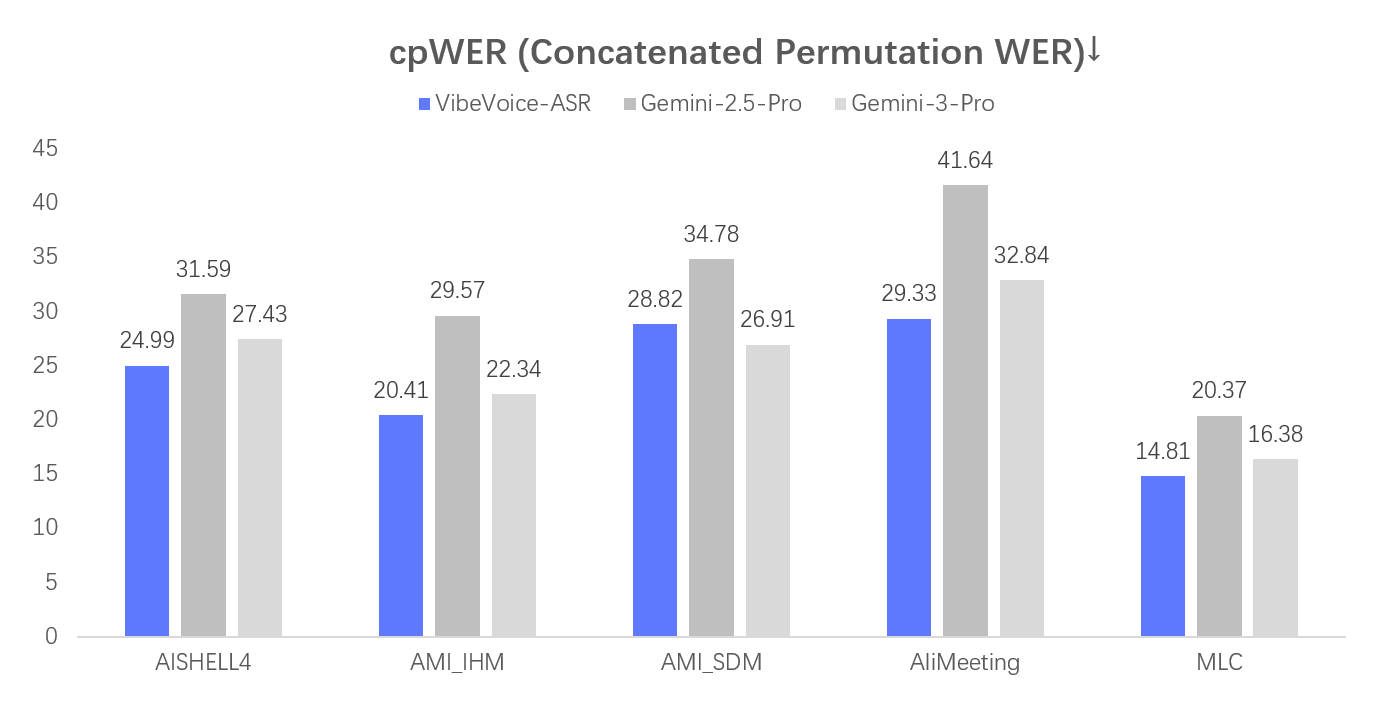

다음은 VibeVoice-ASR 모델을 가져와 사용하는 Python 코드 예시입니다:
# VibeVoice-ASR 기본 사용 예시 (Transformers 활용)
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
import librosa
# 1. 모델 및 프로세서 로드 (float16 캐스팅으로 VRAM 최적화)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
"microsoft/VibeVoice-ASR",
torch_dtype=torch.float16,
device_map="auto"
)
processor = AutoProcessor.from_pretrained("microsoft/VibeVoice-ASR")
# 2. 오디오 파일 로드 및 전처리 (16kHz 샘플링 레이트 권장)
audio, sr = librosa.load("meeting_audio.wav", sr=16000)
inputs = processor(audio, sampling_rate=sr, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# 3. 전사(Transcription) 결과 생성
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=500)
transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
print("전사 결과:", transcription[0])
또는, vLLM 프레임워크를 활용한 고성능 서빙이 가능해 실제 엔터프라이즈 환경에서의 대규모 배치 처리에 매우 적합합니다:
# vLLM을 통한 고성능 ASR 서빙
pip install vllm
vllm serve microsoft/VibeVoice-ASR --dtype float16
 VibeVoice-ASR 소개 및 사용 관련 문서
VibeVoice-ASR 소개 및 사용 관련 문서
VibeVoice-ASR 모델 파인튜닝 가이드
VibeVoice-ASR 모델 기술문서 (PDF)
https://github.com/microsoft/VibeVoice/blob/main/docs/VibeVoice-ASR-Report.pdf
 VibeVoice-ASR 모델 가중치 다운로드
VibeVoice-ASR 모델 가중치 다운로드
 VibeVoice-ASR 모델 사용해보기(Gradio)
VibeVoice-ASR 모델 사용해보기(Gradio)
VibeVoice-TTS: 90분 다화자 합성 모델 (1.5B)
VibeVoice-TTS는 15억 개(1.5B)의 파라미터를 가진 메인 음성 합성 모델로, 한 번의 실행으로 최대 90분 길이의 오디오를 생성할 수 있습니다. 특히 팟캐스트나 오디오북처럼 여러 명의 화자(최대 4명)가 교차로 등장하는 복잡한 대화 시나리오에서도 각 화자의 고유한 목소리 톤과 감정을 일관되게 유지하는 놀라운 능력을 보여주었습니다.
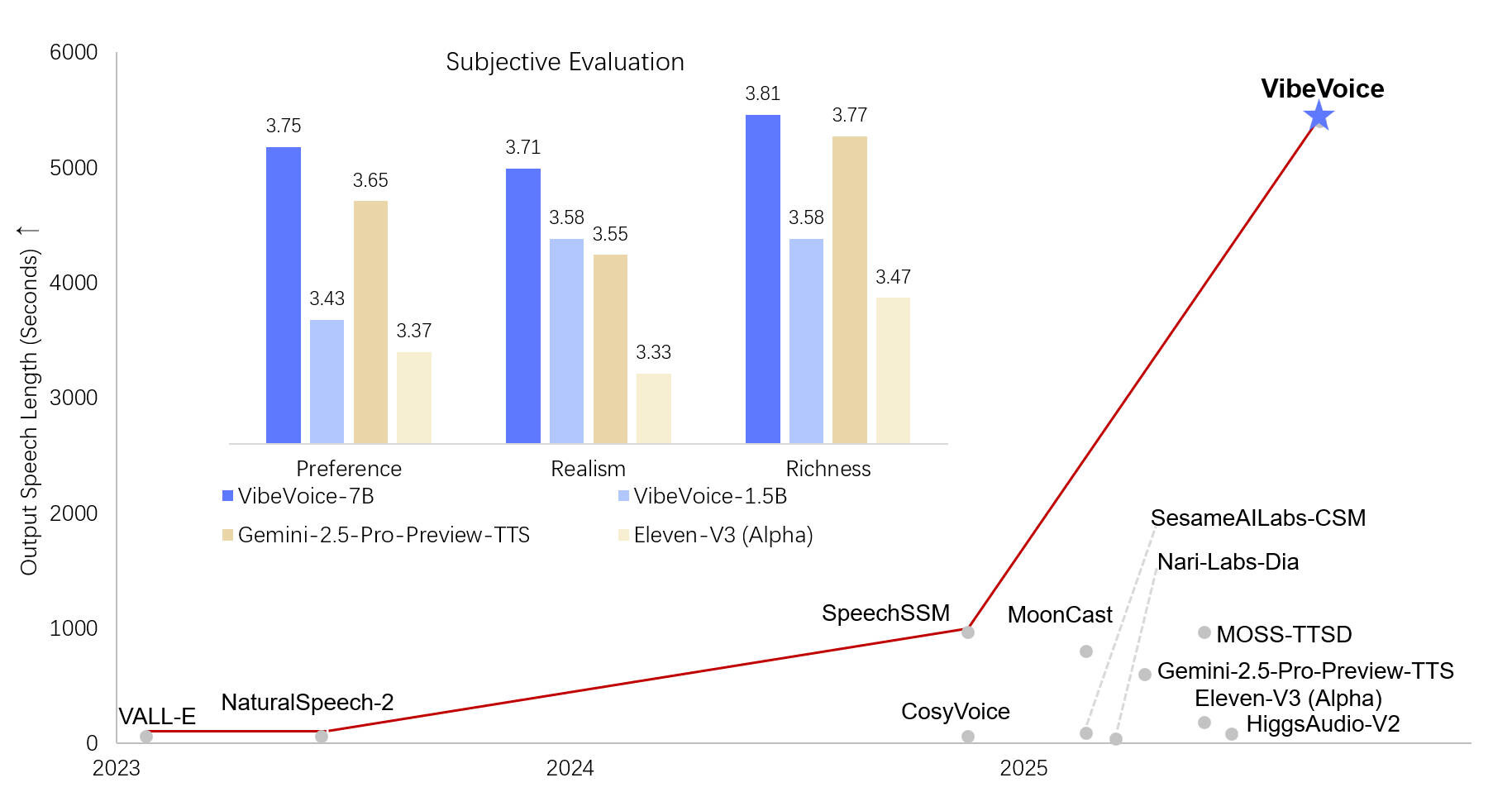
하지만 마이크로소프트는 딥페이크 및 음성 피싱 등 악용 가능성을 우려하여, 2025년 9월 책임 있는 AI(Responsible AI) 원칙에 따른 내부 검토를 거쳐 해당 1.5B 모델의 소스 코드를 메인 저장소에서 임시로 제거한 상태입니다. 현재 ASR 모델과 0.5B Realtime 모델은 완전히 공개되어 자유롭게 사용할 수 있지만, 1.5B TTS 모델에 대해서는 충분한 안전성 테스트가 선행되지 않은 상용 서비스 적용을 강력히 권고하지 않고 있습니다.
VibeVoice-TTS 소개 및 사용 관련 문서
VibeVoice-TTS 모델 기술문서 (PDF)
https://arxiv.org/pdf/2508.19205
VibeVoice-TTS 모델 가중치 다운로드
VibeVoice-Streaming: 실시간 스트리밍 TTS 모델 (0.5B)
VibeVoice-Streaming(또는 VibeVoice-Realtime)은 0.5B 파라미터의 경량 모델로, 스트리밍 텍스트 입력을 받아 실시간으로 음성을 합성합니다. 첫 음절이 출력되기까지의 지연 시간(First-Chunk Latency)이 약 300ms로, 실시간 대화형 애플리케이션에 적합합니다. 최대 약 10분 길이의 음성을 안정적으로 생성하며, 11종의 영어 음성는 물론, 한국어를 포함하여 9개 언어(DE, FR, IT, JP, KR, NL, PL, PT, ES)를 지원합니다. Google Colab 데모를 통해 별도 설치 없이 즉시 체험할 수 있으며, Hugging Face의 Transformers 라이브러리를 통해 사용할 수 있습니다.
# VibeVoice-Realtime 스트리밍 TTS 예시
from transformers import pipeline
import soundfile as sf
# 파이프라인 초기화
tts = pipeline(
"text-to-speech",
model="microsoft/VibeVoice-Realtime-0.5B",
device="cuda",
)
# 스트리밍 음성 합성
text = "안녕하세요. VibeVoice 실시간 음성 합성 테스트입니다."
result = tts(text)
# 음성 파일 저장
sf.write("output.wav", result["audio"], result["sampling_rate"])
print(f"음성 파일 생성 완료: {len(result['audio'])/result['sampling_rate']:.1f}초")
VibeVoice-Streaming 소개 및 사용 관련 문서
VibeVoice-Streaming 모델 가중치 다운로드
VibeVoice-Streaming 모델 사용해보기(Google Colab)
VibeVoice의 오픈소스 현황
VibeVoice 프로젝트의 공개 상태는 모델마다 다릅니다. ASR 모델과 Realtime TTS 모델은 완전히 오픈소스로 공개되어 있으나, 1.5B 규모의 메인 TTS 모델(VibeVoice-TTS)은 2025년 9월에 책임 있는 AI(Responsible AI) 검토를 이유로 코드가 제거된 상태입니다. Microsoft는 딥페이크 등의 악용 가능성에 대한 우려를 명시하고 있으며, "상용 또는 실제 환경에서의 추가 테스트 없는 사용을 권장하지 않는다"는 주의 사항을 공지하고 있습니다. VibeVoice-ASR은 ICLR 2026 Oral 발표 논문을 기반으로 하며, Vibing이라는 macOS/Windows 음성 입력 도구에 이미 실제로 적용되어 있습니다.
VibeVoice 모델 비교
| 모델 | 파라미터 | 주요 기능 | 최대 길이 | 모델 가중치 | 오픈소스 |
|---|---|---|---|---|---|
| VibeVoice-ASR | 7B | 음성 인식, 화자 분리, 핫워드 | 60분+ | ||
| VibeVoice-TTS | 1.5B | 다화자 합성, 감정 표현 | 90분 | ||
| VibeVoice-Realtime | 0.5B | 실시간 스트리밍 TTS | ~10분 |
라이선스
VibeVoice는 MIT 라이선스로 공개되어 있어 자유롭게 사용하고 수정할 수 있습니다. 단, 딥페이크 생성 등 악의적인 사용은 금지되며, 연구 및 상업적 활용 전에 충분한 테스트와 윤리적 검토가 권장됩니다. Qwen2.5 기반 모델에서 상속된 잠재적 편향에 대해서도 공식 문서에서 경고하고 있습니다.
 VibeVoice 공식 프로젝트 페이지
VibeVoice 공식 프로젝트 페이지
 VibeVoice 프로젝트 GitHub 저장소
VibeVoice 프로젝트 GitHub 저장소
더 읽어보기
-
VoxCPM: 토크나이저 없이 작동하는, 0.5B 규모의 고품질 AI 음성 생성 및 복제를 위한 영어/중국어 TTS 모델
-
Step-Audio: 오디오 이해와 생성이 통합된, 다국어 대화 및 감정 표현이 가능한 음성 모델에 대한 연구
-
Lightning-SimulWhisper: Apple Silicon용 초고속 실시간 로컬 음성 인식 엔진 (feat. Whisper)
-
Cohere, HuggingFace Open ASR 리더보드 1위를 차지한 오픈소스 음성 인식 모델 Transcribe 공개
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()