
Perplexity가 공개한 임베딩 모델 pplx-embed 소개
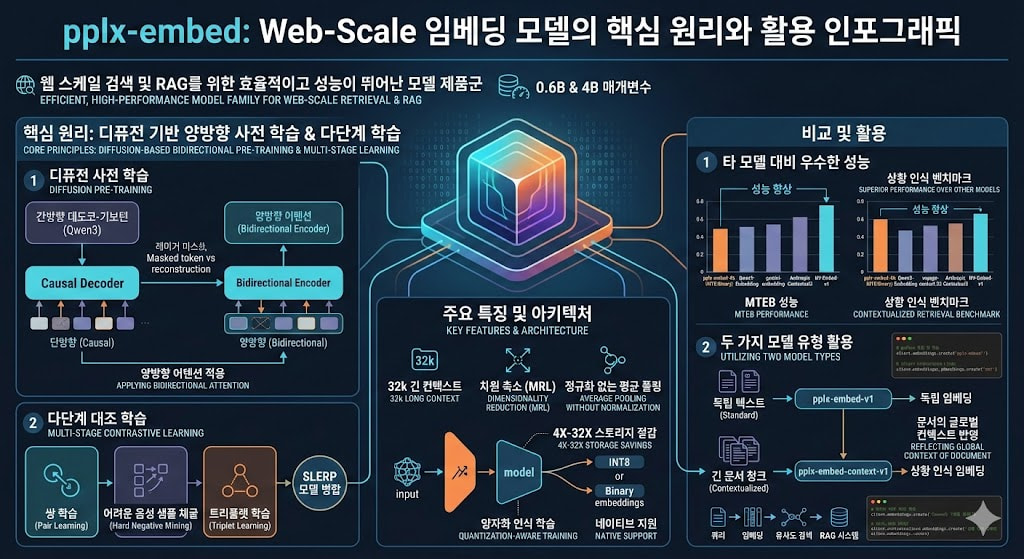
Perplexity에서 새롭게 공개한 텍스트 임베딩 모델 제품군인 pplx-embed는 웹 스케일의 방대한 실제 검색 환경과 검색 증강 생성 시스템을 최적화하기 위해 설계되었습니다. 이 모델 시리즈는 각각 6억 개와 40억 개의 매개변수를 가진 두 가지 규모로 제공되며, 독립적인 텍스트를 처리하는데 특화된 pplx-embed-v1 모델과 문서의 전체적인 맥락을 이해하여 청크 단위의 의미를 파악하는 pplx-embed-context-v1 모델로 나뉘어 출시되었습니다.
기존의 많은 임베딩 모델들이 텍스트 앞에 특정 지시어를 붙여야만 최적의 성능을 낼 수 있었던 것과 달리, 해당 제품군은 이러한 지시어 튜닝 과정을 배제하여 프롬프트 선택에 따른 오버헤드를 줄이고 인덱싱 파이프라인의 불안정성을 해소한 것이 특징입니다.
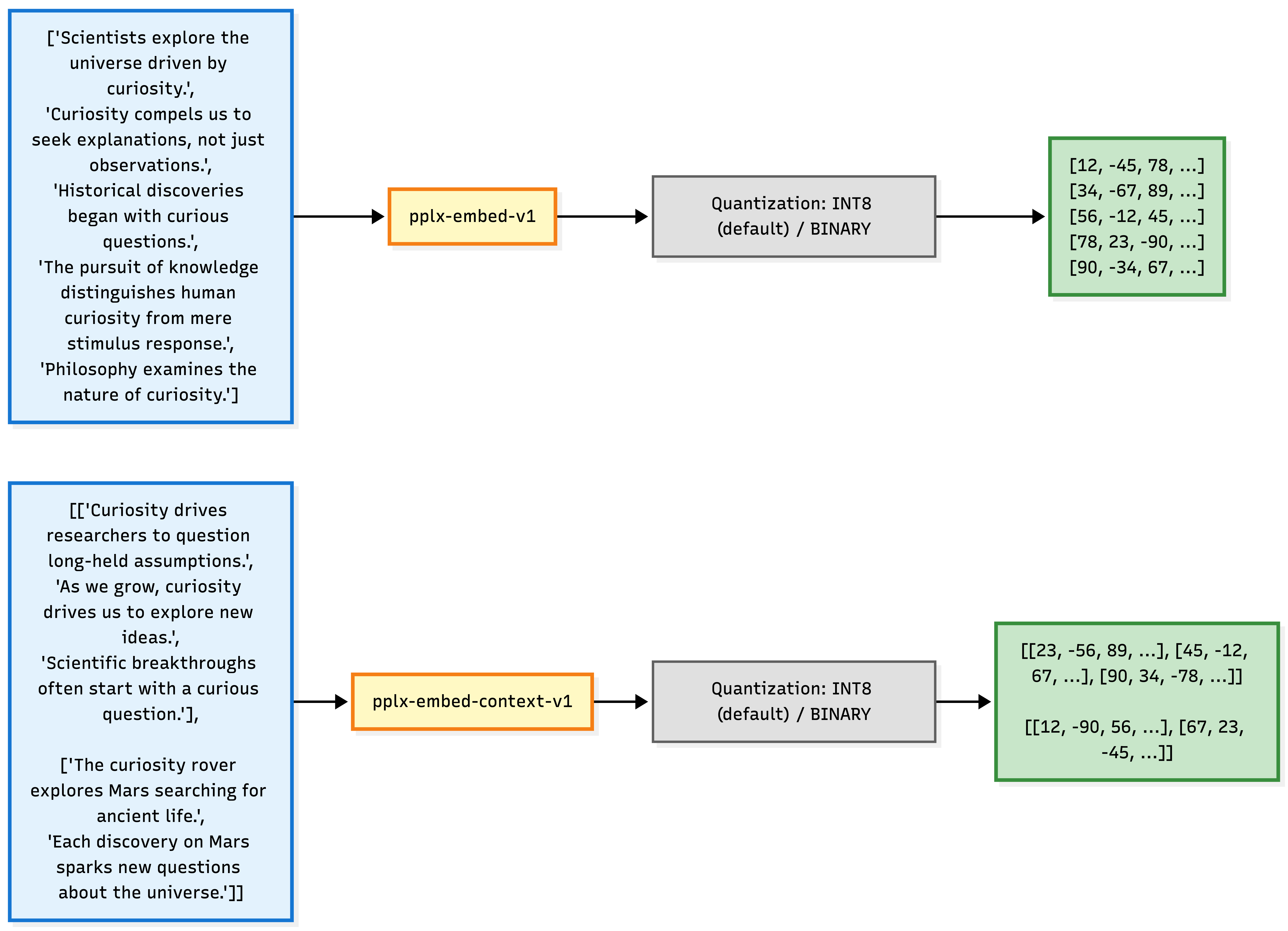
pplx-embed 모델들은 수십억 개의 웹 페이지를 처리하고 저장하는 데 발생하는 막대한 스토리지 비용 문제를 해결하기 위해, 양자화 인식 학습 기법을 적용하여 설계되었습니다. 사후에 압축하는 방식을 사용할 때 발생할 수 있는 성능 저하를 방지하기 위해 학습 단계에서부터 네이티브 INT8 및 이진 양자화 임베딩을 출력하도록 만들어졌으며, 이를 통해 32비트 부동소수점 대비 저장 공간을 각각 4배에서 최대 32배까지 절감할 수 있게 해줍니다.
또한, 최대 3만 2천 토큰의 긴 컨텍스트 윈도우를 지원하여 방대한 문서를 한 번에 처리할 수 있으며, 필요에 따라 차원 수를 축소할 수 있는 기법을 적용하여 사용자가 벡터 데이터베이스의 스토리지와 검색 속도를 유연하게 조절할 수 있도록 구현되었습니다.

RAG와 같은 현대의 검색 파이프라인에서 임베딩(Embedding)은 가장 앞단에서 수많은 문서를 걸러내는 1차 리트리버(Retriever) 역할을 수행합니다. 따라서 속도와 정확도, 그리고 비용 효율성이 모두 확보되어야 하는데, 0.6B 모델은 지연 시간이 짧고 가벼운 임베딩 생성을 목표로 하며, 4B 모델은 검색 품질을 끌어내는 데 초점을 맞추고 있습니다. 두 가지 변형 모두 다국어 처리 능력을 갖추고 있어 전 세계의 다양한 언어로 작성된 텍스트의 의미를 정확하게 벡터 공간에 매핑할 수 있으며, 평균 풀링 방식을 채택하여 전체 시퀀스의 맥락을 고르게 반영한 최종 임베딩 벡터를 산출합니다.
타사 검색 및 상황 인식 모델과의 성능 비교
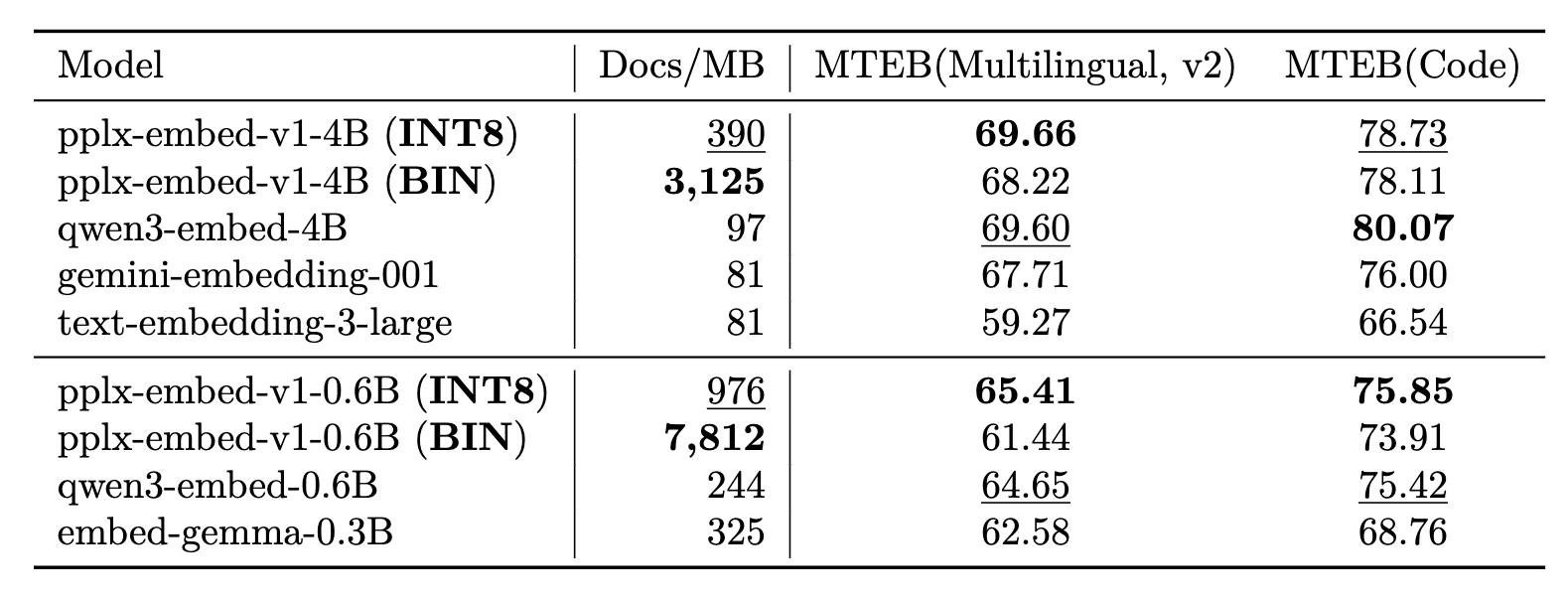
pplx-embed 모델 제품군은 다양한 공개 벤치마크와 내부 웹 스케일 평가에서 기존의 상용 및 오픈소스 모델들을 상회하는 성능을 입증했습니다.

먼저 다국어 검색 성능을 평가하는 MTEB(Multilingual, v2) 에서 4B 모델이 INT8 양자화 상태로 평균 69.66%의 성능을 기록하며 Qwen3-Embedding-4B 모델과 gemini-embedding-001 모델의 수치를 넘어섰습니다.
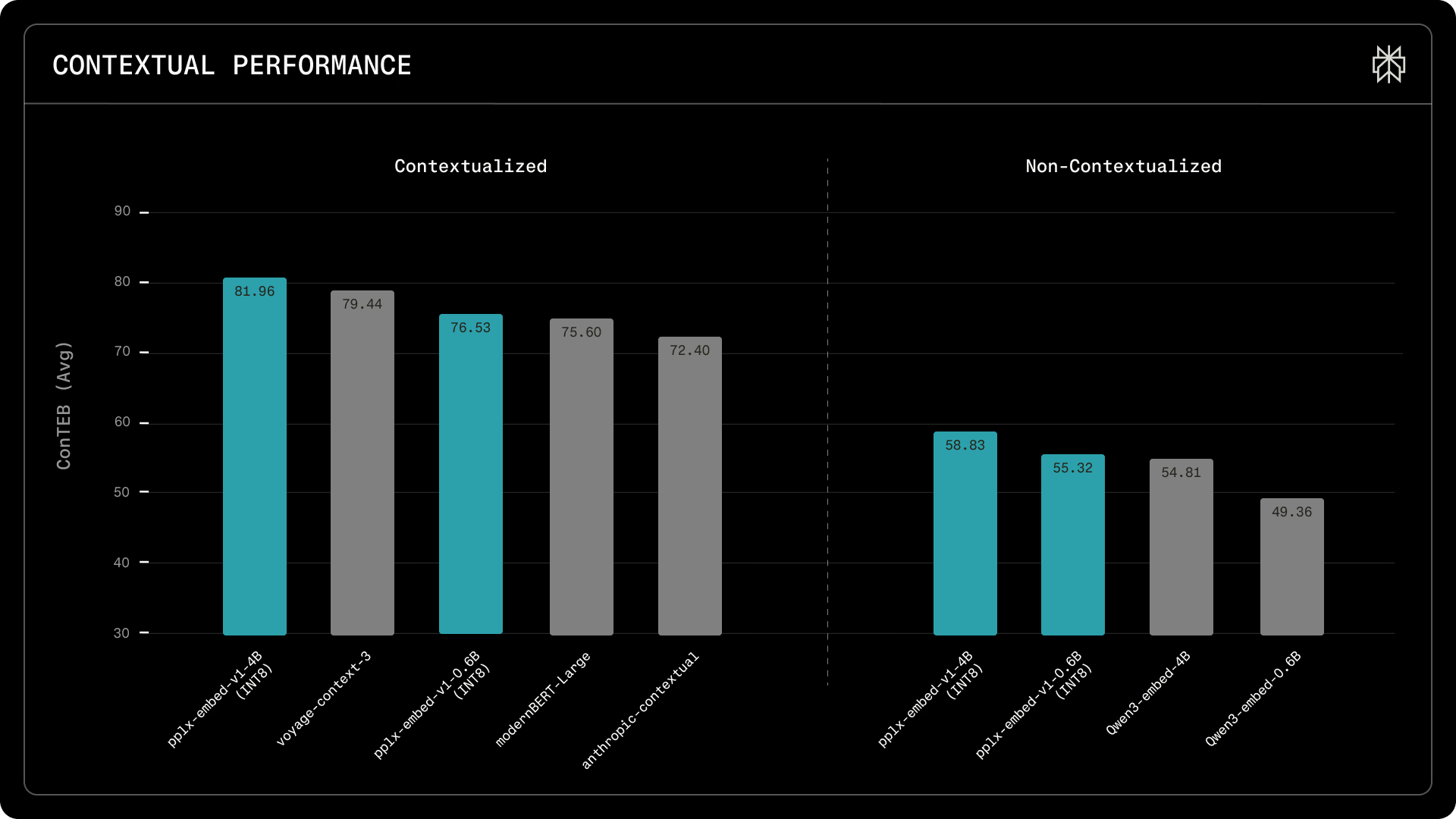
또한, 문서의 글로벌 컨텍스트를 반영하는 능력을 평가하는 상황 인식 리트리벌 벤치마크에서는 81.96%의 점수를 달성하여 voyage-context-32 및 Anthropic Contextual3와 같은 상황 인식 모델들을 앞질렀습니다.
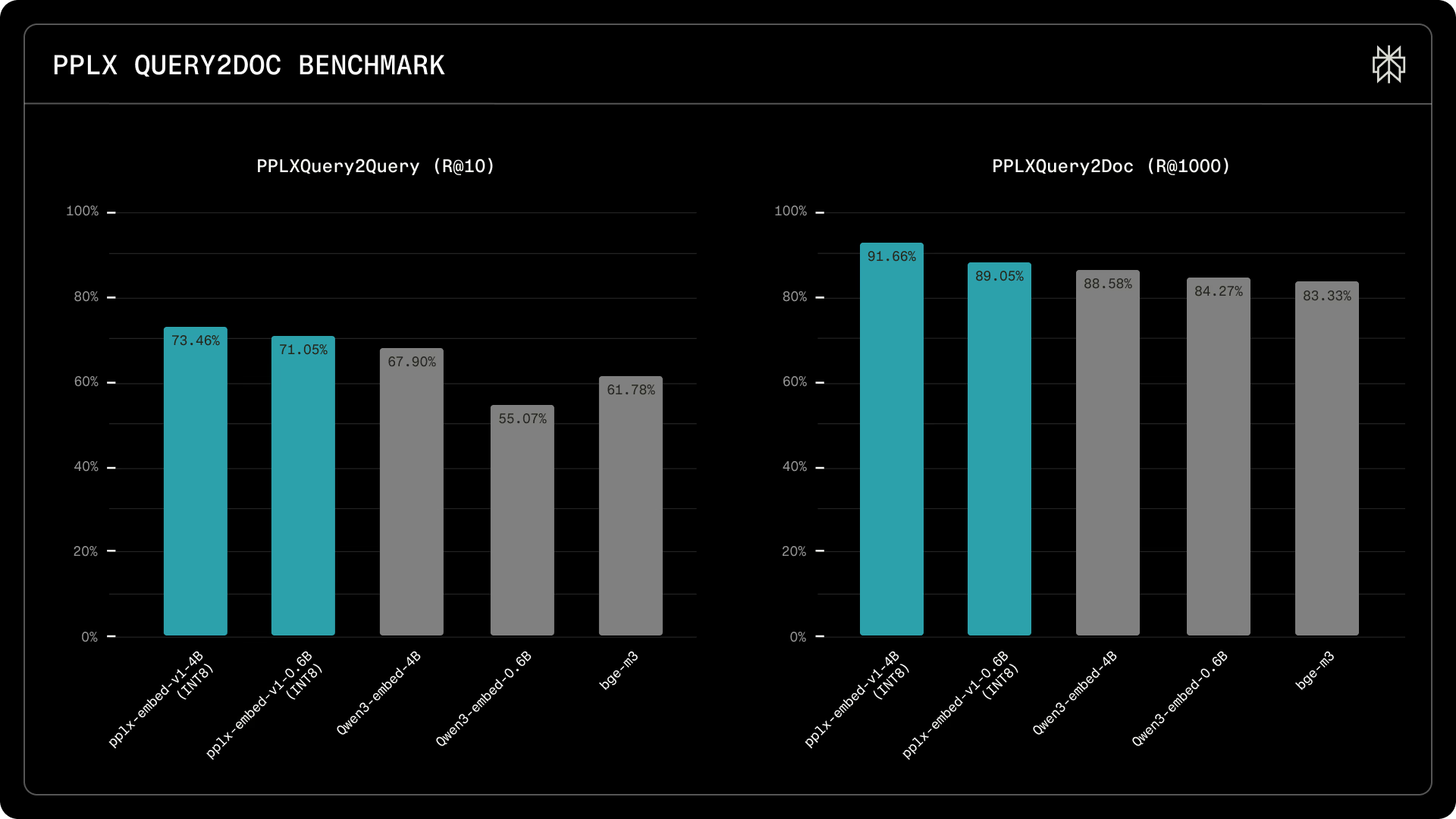
더불어 대규모 API 말뭉치(Corpus)에서 관련 도구를 사전 필터링하는 능력을 측정하는 평가에서도 70억 개 이상의 매개변수를 가진 NV-Embed-v1이나 GritLM-7B보다 높은 정확도를 기록하여 효율적인 아키텍처임을 증명했습니다.
디퓨전 기반 사전 학습과 다단계 대조 학습 아키텍처
모델의 근간을 이루는 아키텍처는 기존 언어 모델의 한계를 극복하기 위해 디퓨전 노이즈 제거 목적 함수를 활용하는 접근법을 취하고 있습니다. 개발진은 오픈소스 모델인 Qwen3 기반 모델을 시작점으로 삼아, 단방향으로만 토큰을 예측하는 인과적 디코더(Causal Decoder)의 주의력 마스크(Attention Mask)를 비활성화했습니다.
대신 무작위로 마스킹된 토큰을 양방향 컨텍스트를 모두 활용하여 재구성하도록 강제하는 디퓨전 학습을 약 2,500억 개의 다국어 토큰에 대해 진행했습니다. 이러한 방식은 텍스트의 앞뒤 문맥을 동시에 이해하는 양방향 인코더로 모델을 변환시켜 주며, 후속 대조 학습이 시작되기 전부터 풍부한 양방향 의미론을 내재화하게 만들어 검색 작업에서 1% 포인트 이상의 실질적인 성능 향상을 이끌어냅니다.
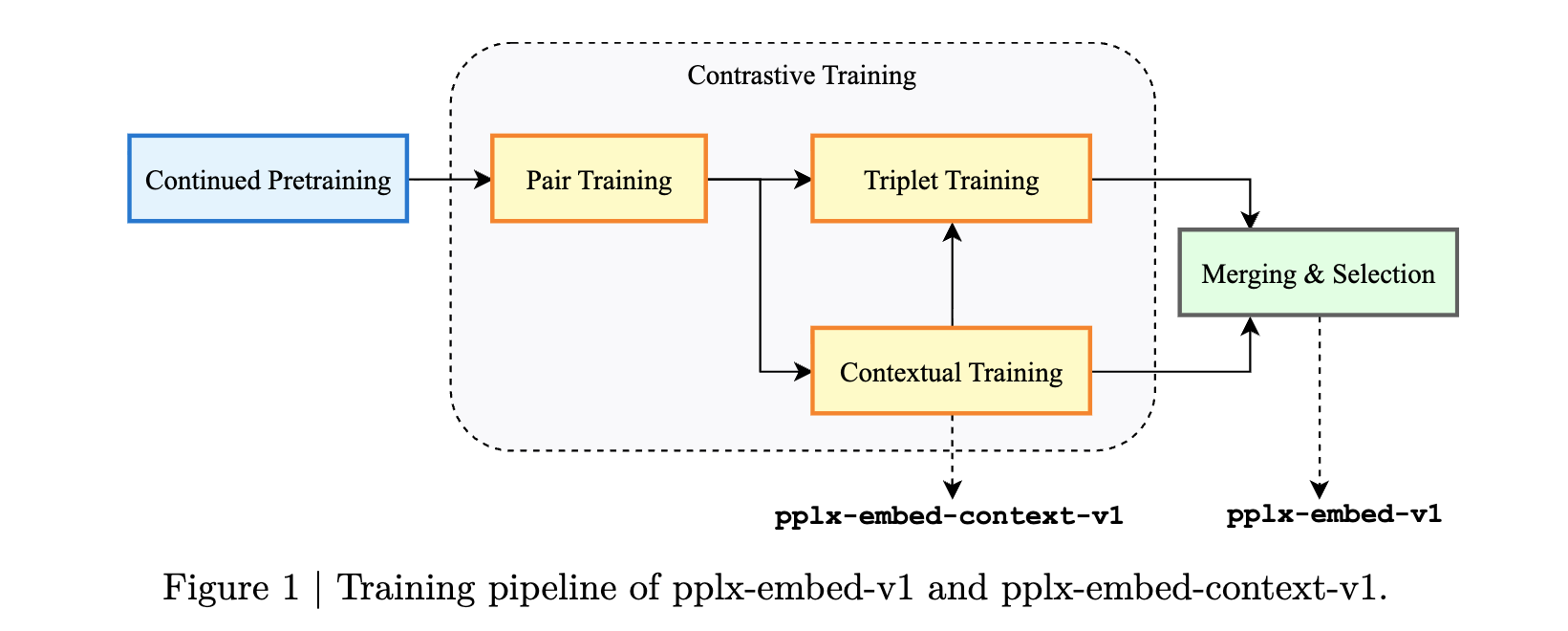
사전 학습을 마친 모델은 검색 품질을 극대화하기 위해 세 가지 단계로 세분화된 대조 학습(Contrastive Training) 파이프라인을 거치게 됩니다:
첫 번째 단계인 쌍 학습(Pair Training) 단계에서는 배치 내 음성 샘플을 활용하여 쿼리와 문서 간의 기본적인 의미론적 정렬을 확립합니다. 이때 배치 크기가 커짐에 따라 긍정 샘플과 거의 동일한 의미를 지닌 가짜 음성 샘플이 학습 신호를 훼손하는 것을 방지하기 위해, 유사도 기반 마스킹 기법을 도입하여 영어, 이중 언어, 다국어 순으로 점진적으로 학습을 전개합니다.
두 번째로 상황 인식 학습(Contextual Training) 단계에서는 청크 단위의 의미를 전체 문서 수준의 컨텍스트와 연결하는 방법을 모델에 가르치며, 이 과정을 통해 상황 인식 전용 모델인 pplx-embed-context-v1이 산출됩니다.
마지막 단계인 트리플렛 학습(Triplet Training) 단계는 채굴된 어려운 음성 샘플을 활용하는 단계로, 의미가 비슷하지만 사용자의 의도와는 관련이 없는 문서들 사이의 경계를 정밀하게 다듬습니다.
최종적인 범용 리트리벌 모델인 pplx-embed-v1은 이러한 다단계 학습의 결과물들을 단순히 폐기하지 않고, 상황 인식 모델의 체크포인트와 트리플렛 학습을 마친 체크포인트를 구면 선형 보간법인 SLERP(Spherical Linear Interpolation) 을 사용하여 병합함으로써 탄생합니다. 이 병합 과정을 통해 모델은 청크 수준의 세밀한 의미 파악 능력과 문서 전체를 아우르는 글로벌 검색 능력을 모두 보유하게 됩니다.
상황 인식 임베딩과 표준 임베딩의 활용 방법 및 예시 코드
pplx-embed 모델 제품군은 사용 사례에 따라 명확히 구분하여 적용할 때 최상의 결과를 얻을 수 있습니다. 먼저, 검색 쿼리나 개별적인 문장, 또는 서로 연관성이 없는 독립적인 문서를 인덱싱할 때는 표준 모델(pplx-embed-v1)을 사용하는 것이 적합합니다.
반면, 하나의 긴 문서를 여러 개의 단락이나 섹션으로 나누어 저장하는 RAG 파이프라인에서는 청크들이 서로 동일한 문맥을 공유하므로 상황 인식 모델(pplx-embed-context-v1)을 활용해야 합니다.
상황 인식 모델(pplx-embed-context-v1)을 API로 호출할 때는 동일한 문서에서 추출된 청크들을 원본 문서에 등장하는 순서대로 하나의 내부 배열에 담아 전달해야 하며, 모델은 이 순차적인 흐름을 바탕으로 문서 인식 임베딩을 생성합니다. 생성된 임베딩은 정규화되지 않은 INT8 또는 이진 데이터이므로, 유사도를 계산할 때는 내적이나 유클리드 거리가 아닌 코사인 유사도나 해밍 거리를 반드시 사용해야 합니다.
사용자는 Perplexity API를 통해 요청을 보내거나, 오픈소스 라이브러리인 SentenceTransformers 및 Transformers를 활용하여 로컬 환경에서 직접 모델을 구동할 수 있습니다.
[![]() 주의 사항
주의 사항![]() ]:
]: pplx-embed 모델들은 정규화되지 않은(unnormalized) INT8 임베딩을 출력합니다. 따라서 벡터 검색 및 유사도 측정 시 내적(Inner Product)이나 L2 거리(L2 Distance)를 사용하면 잘못된 결과가 나올 수 있으므로, 반드시 코사인 유사도(Cosine Similarity)를 사용 해야 합니다.
다음은 Python 환경에서 공식 API 클라이언트를 사용하여 표준 임베딩을 생성하는 구체적인 예시 코드입니다:
from perplexity import Perplexity
client = Perplexity()
documents = [
"Python is a versatile programming language",
"Machine learning automates analytical model building",
"The Eiffel Tower is located in Paris, France"
]
# 표준 모델(`pplx-embed-v1`)을 활용하여 독립적인 문서들의 임베딩 생성
doc_response = client.embeddings.create(
input=documents,
model="pplx-embed-v1-4b"
)
# API 응답에서 생성된 임베딩 벡터를 추출합니다.
# 반환된 벡터는 정규화되지 않은 상태이므로 후속 비교 시 코사인 유사도를 사용해야 합니다.
for emb in doc_response.data:
print(emb.embedding)
상황 인식 모델(pplx-embed-context-v1)을 사용할 때는 데이터 구조를 중첩 배열 형태로 구성하여 API에 전달해야 하며, 검색을 수행할 쿼리 역시 동일한 상황 인식 모델을 통해 임베딩해야 호환성을 유지할 수 있습니다.
다음은 상황 인식 임베딩 모델(pplx-embed-context-v1)을 호출하여 문맥이 연결된 문서 청크들을 처리하는 Python 예시 코드입니다:
from perplexity import Perplexity
client = Perplexity()
# 동일한 문서에서 파생된 청크들을 순서대로 묶어 하나의 내부 배열로 구성합니다.
nested_chunks = [
[
"Curiosity begins in childhood with endless questions about the world.",
"As we grow, curiosity drives us to explore new ideas and challenge assumptions."
]
]
# 상황 인식 전용 모델(`pplx-embed-context-v1`)을 호출합니다.
context_response = client.contextualized_embeddings.create(
input=nested_chunks,
model="pplx-embed-context-v1-4b"
)
# 검색 쿼리를 임베딩할 때도 단일 요소를 가진 중첩 배열 형태로 감싸서 동일한 모델을 사용합니다.
query = "How does curiosity change as we grow?"
query_response = client.contextualized_embeddings.create(
input=[[query]],
model="pplx-embed-context-v1-4b"
)
 pplx-embed 모델 소개 블로그
pplx-embed 모델 소개 블로그
 pplx-embed 모델 다운로드
pplx-embed 모델 다운로드
| Model | Dimensions | Context | MRL | Quantization | Instruction | Pooling |
|---|---|---|---|---|---|---|
pplx-embed-v1-0.6B |
1024 | 32K | Yes | INT8/BINARY | No | Mean |
pplx-embed-v1-4B |
2560 | 32K | Yes | INT8/BINARY | No | Mean |
pplx-embed-context-v1-0.6B |
1024 | 32K | Yes | INT8/BINARY | No | Mean |
pplx-embed-context-v1-4B |
2560 | 32K | Yes | INT8/BINARY | No | Mean |
pplx-embed 논문: Diffusion-Pretrained Dense and Contextual Embeddings
 pplx-embed 모델 사용법
pplx-embed 모델 사용법
표준 임베딩 모델(pplx-embed-v1) 사용 문서
상황 인식 임베딩 모델(pplx-embed-context-v1) 사용 문서
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()