
jina-embeddings-v5-omni 소개
Jina AI가 텍스트 임베딩 전문 모델인 jina-embeddings-v5-text 시리즈를 확장하여, 텍스트, 이미지, 오디오, 비디오, PDF까지 모두 동일한 의미 공간에 매핑하는 옴니-모달 임베딩 모델군인 jina-embeddings-v5-omni 를 공개했습니다. 이번 공개에는 1.57B 규모의 jina-embeddings-v5-omni-small과 0.95B 규모의 jina-embeddings-v5-omni-nano 두 가지 변형이 포함되어 있으며, 함께 공개된 논문 "jina-embeddings-v5-omni: Geometry-preserving Embeddings via Locked Aligned Towers"에서는 이 모델의 기반 기법을 GELATO(Geometry-preserving Embeddings via Locked Aligned TOwers) 라는 이름으로 정리하고 있습니다.
기존의 멀티모달 임베딩 모델은 보통 텍스트와 비전, 오디오 인코더를 모두 끝에서 끝까지(end-to-end) 함께 학습시키는 방식을 사용해 왔습니다. LanguageBind나 NVIDIA의 Omni-Embed-Nemotron, LCO-Embedding 시리즈처럼 최근의 옴니-모달 임베딩 모델들도 모두 이 흐름 위에 있습니다. 그러나 이런 방식은 학습 비용이 매우 크고, 새 모달리티를 추가할 때마다 텍스트 임베딩 자체도 미세하게 바뀌어 버려서, 이미 구축해 둔 벡터 인덱스를 그대로 사용할 수 없다는 운영상의 문제가 있었습니다.

옴니-모달리티(Omni-Modality) 라는 단어가 점점 흔해지고 있지만, 실제 검색/RAG 파이프라인 관점에서 중요한 질문은 "기존에 잘 동작하던 텍스트 검색을 깨뜨리지 않고, 이미지/오디오/비디오를 같은 인덱스에 끼워 넣을 수 있는가" 입니다. jina-embeddings-v5-omni는 바로 이 지점을 정조준한 모델로, 텍스트 백본을 동결(freeze)한 채 비전/오디오 인코더와 텍스트 백본을 잇는 작은 프로젝터(Projector) 만 학습하여, "같은 입력은 v5-text와 정확히 동일한 임베딩을 만든다" 는 강력한 호환성 보장을 내세웁니다. 결과적으로 기존 v5-text 인덱스를 재구축하지 않고도, 이미지와 오디오, 비디오 검색을 그대로 얹을 수 있는 드롭인(drop-in) 업그레이드 경로를 제공합니다.
동결된 타워들의 조합: GELATO 아키텍처
GELATO의 핵심 아이디어는 단순합니다. 잘 학습된 텍스트 임베딩 모델을 그대로 두고, 사전 학습된 비전과 오디오 인코더를 옆에 붙인 뒤, 이들을 연결하는 작은 선형 프로젝터만 학습하는 것입니다. 텍스트 백본도, 비전 인코더도, 오디오 인코더도 모두 동결된 상태로 남고, 전체 가중치의 0.35%만이 학습 가능한 파라미터가 됩니다.
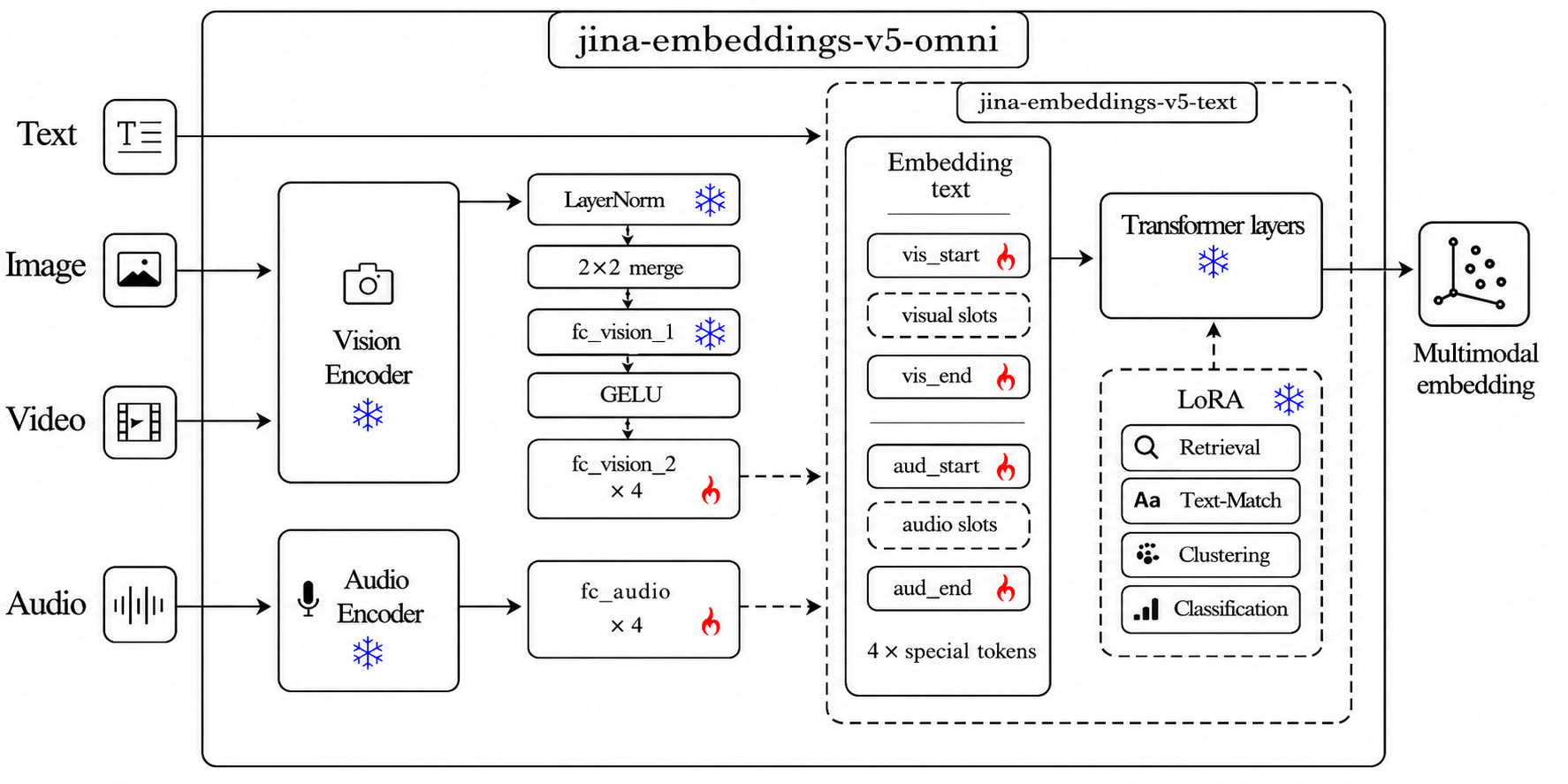
각 모달리티는 다음과 같이 처리됩니다:
-
비전(Vision): Qwen3.5 비전 인코더(small은 Qwen3.5-2B의 ViT, nano는 Qwen3.5-0.8B의 ViT)를 사용하며, 2x2 공간 병합(spatial merge)으로 4개의 인접 패치 토큰을 하나로 합쳐 토큰 수를 4배 줄입니다. 이는 Pixel Shuffle의 역방향(pixel-unshuffle) 재배열에 해당합니다. LayerNorm과 첫 번째 선형층
fc_vision_1은 동결한 채, 마지막 프로젝션 레이어(fc_vision_2)만 새로 초기화하여 텍스트 백본의 은닉 차원(small 1024, nano 768)에 매핑합니다. -
오디오(Audio): Qwen2.5-Omni 오디오 인코더를 사용하며, 단일
fc_audio레이어가 1280차원 출력을 텍스트 백본 차원으로 사영합니다. -
비디오(Video): 샘플링된 시각 프레임 시퀀스로 처리되며, 비디오에 오디오 트랙이 있으면 추출된 오디오 세그먼트가 앞쪽에 함께 붙습니다.
논문이 흥미롭게 짚는 지점은, 비전과 오디오 인코더로 bare SigLIP2나 Whisper-large-v3 같은 순수 지각(perceptual) 인코더가 아니라, 언어 정렬이 끝난 Qwen 멀티모달 인코더를 골랐다는 점입니다. Qwen3.5의 비전 인코더는 SigLIP2 계열에서 출발했지만 Qwen-VL 계열 학습을 통해 이미 텍스트와 정렬되어 있고, Qwen2.5-Omni의 오디오 인코더 역시 Whisper-large-v3에서 시작했지만 멀티모달 학습으로 언어 공간 정렬을 마쳤습니다. 사전 연구에서 시각/오디오 특징은 텍스트 조건 멀티모달 태스크로 전이되기 전에 명시적인 언어 공간 정렬이나 자연어 지도학습이 필요하다는 점이 보고되어 왔고, GELATO는 이 점을 받아들여 "이미 정렬된 인코더 + 작은 프로젝터" 라는 조합을 선택했습니다.
여기에 v5-text에서 상속된 네 가지 작업별 LoRA 어댑터(Low-Rank Adaptation) (검색, 텍스트 매칭, 분류, 클러스터링)가 결합되며, 각 작업 변형마다 별도의 프로젝터 가중치가 학습됩니다. 아키텍처는 완전히 모듈식이어서, 텍스트만 사용할 때는 비전/오디오 가중치를 아예 로딩하지 않아 메모리 풋프린트가 v5-text와 동일하고, 이미지만 쓰는 경우에는 오디오를 생략하는 식으로 필요한 모달리티만 골라 올릴 수 있습니다. 학습 가능한 파라미터의 정확한 구성은 fc_vision_2, fc_audio, 그리고 모달리티 구분자(delimiter) 토큰 임베딩 세 종류입니다. small은 비전과 오디오의 시작/끝 구분자를 모두 새로 학습하고, nano는 오디오 시작/끝 구분자만 학습합니다.
단일 시퀀스로 통합되는 모달리티 입력
GELATO에서 모든 입력은 하나의 토큰 시퀀스 로 직렬화됩니다. 텍스트는 평범한 텍스트 토큰으로 남고, 비텍스트 모달리티는 모달리티 구분자 사이에 자리표시자(placeholder) 토큰들이 들어가는 형태로 표현됩니다. 이미지는 다음과 같이 인코딩됩니다.
<|vision_start|> <|image_pad|> × N <|vision_end|>
오디오는 <|audio_start|> 와 <|audio_end|> 사이에 K개의 <|audio_pad|> 가 들어가고, 비디오는 프레임마다 <|vision_start|> ... <|video_pad|> × S_f ... <|vision_end|> 블록을 이어 붙입니다. 비디오에 오디오 트랙이 있으면 오디오 시퀀스 \mathbf{s}_{\text{aud}} 가 비디오 시퀀스 \mathbf{s}_{\text{vid}} 앞에 연결되어 \mathbf{s}_{\text{aud}} \| \mathbf{s}_{\text{vid}} 형태가 됩니다. 인코더가 만든 임베딩이 이 자리표시자 위치를 그대로 덮어쓰고, 텍스트 백본은 자신이 익숙한 토큰 시퀀스를 입력으로 받게 되는 셈입니다. 텍스트와 멀티모달이 섞인 입력에서도, 텍스트 구간과 모달리티 세그먼트가 문서 순서대로 그대로 이어 붙기 때문에 별도의 융합 모듈이 필요 없습니다.
v5-omni-small 및 v5-omni-nano 비교
이번에 공개된 두 모델의 핵심 사양은 다음과 같습니다.
| 항목 | jina-embeddings-v5-omni-small | jina-embeddings-v5-omni-nano |
|---|---|---|
| 기반 텍스트 모델 | jina-embeddings-v5-text-small (Qwen3-0.6B) | jina-embeddings-v5-text-nano (EuroBERT-210m) |
| 전체 파라미터 | 약 1.56B | 약 1.04B |
| 학습 가능 파라미터 | 약 18M 프로젝터 (0.35%) | 약 7M 프로젝터 (0.35%) |
| 지원 모달리티 | 텍스트, 이미지, 오디오, 비디오, PDF | 텍스트, 이미지, 오디오, 비디오, PDF |
| 임베딩 차원 | 1024 | 768 |
| Matryoshka 차원 | 32, 64, 128, 256, 512, 768, 1024 | 32, 64, 128, 256, 512, 768 |
| 최대 시퀀스 길이 | 32,768 토큰 | 8,192 토큰 |
| 비전 인코더 | Qwen3.5-2B의 ViT | Qwen3.5-0.8B의 ViT |
| 오디오 인코더 | Qwen2.5-Omni 오디오 인코더 | Qwen2.5-Omni 오디오 인코더 |
| 작업(Task) | 검색, 텍스트 매칭, 분류, 클러스터링 | 검색, 텍스트 매칭, 분류, 클러스터링 |
| 라이선스 | CC BY-NC 4.0 | CC BY-NC 4.0 |
두 모델 모두 Matryoshka Representation Learning 기반의 차원 절단(truncation)을 지원하여, 검색 단계에 따라 임베딩 크기를 동적으로 줄여 사용할 수 있습니다. 텍스트와 이미지, 오디오 임베딩은 작은 차원으로 잘라도 품질이 비교적 잘 보존되는 반면, 비디오 임베딩은 작은 차원에서 품질 저하가 좀 더 큽니다.
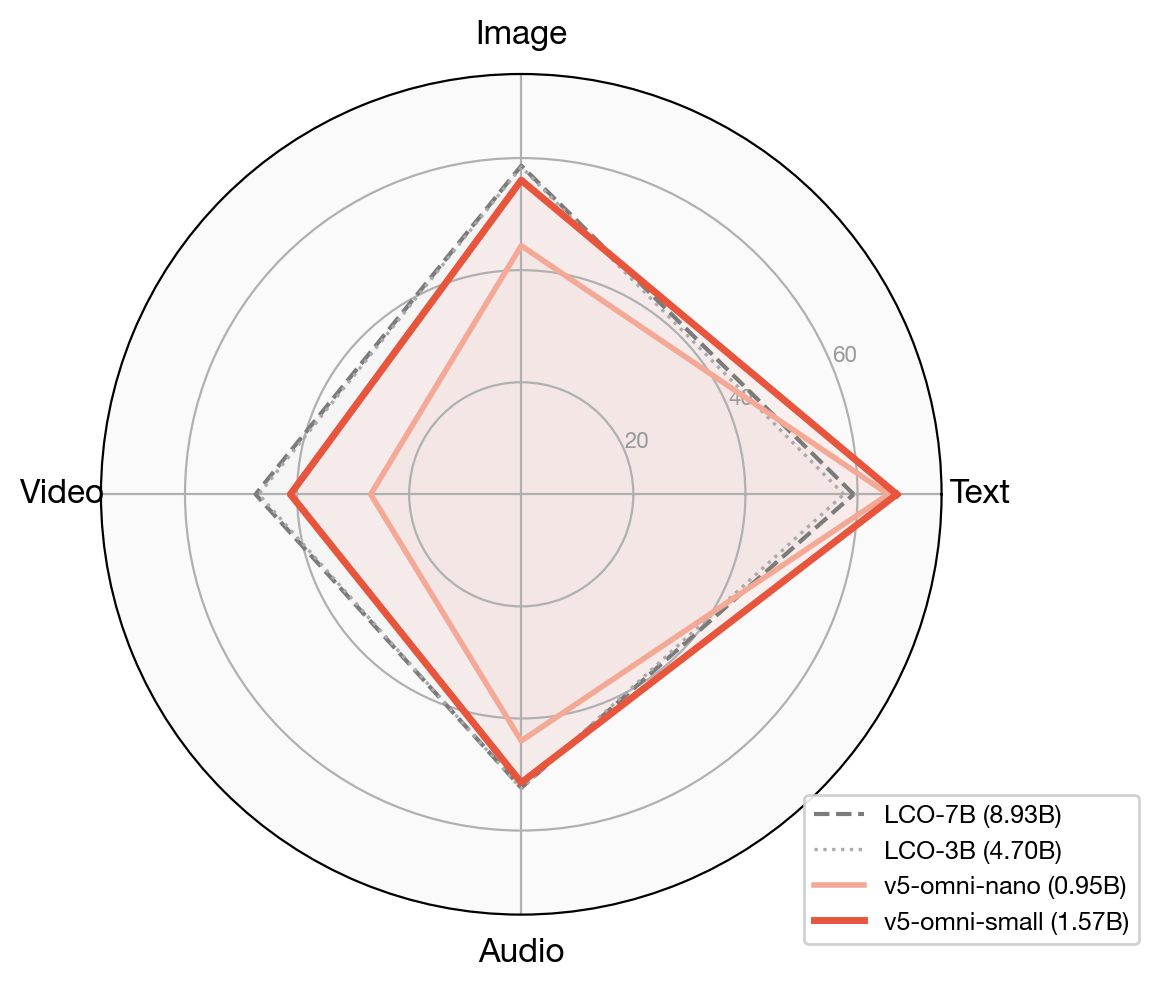
5.7배 적은 파라미터로 따라잡는 성능
평가 결과의 핵심은 "적은 학습으로 큰 모델만큼 한다" 는 점입니다. v5-omni-small은 네 가지 모달리티 평균에서 53.93점을 기록하여, 약 5.7배 더 큰 LCO-Embedding-Omni-7B(54.43점)와 거의 동일한 수준을 보입니다. v5-omni-nano도 단 0.95B 파라미터로 LanguageBind(1.14B)를 평균 +8.9점 차이로 앞섭니다.
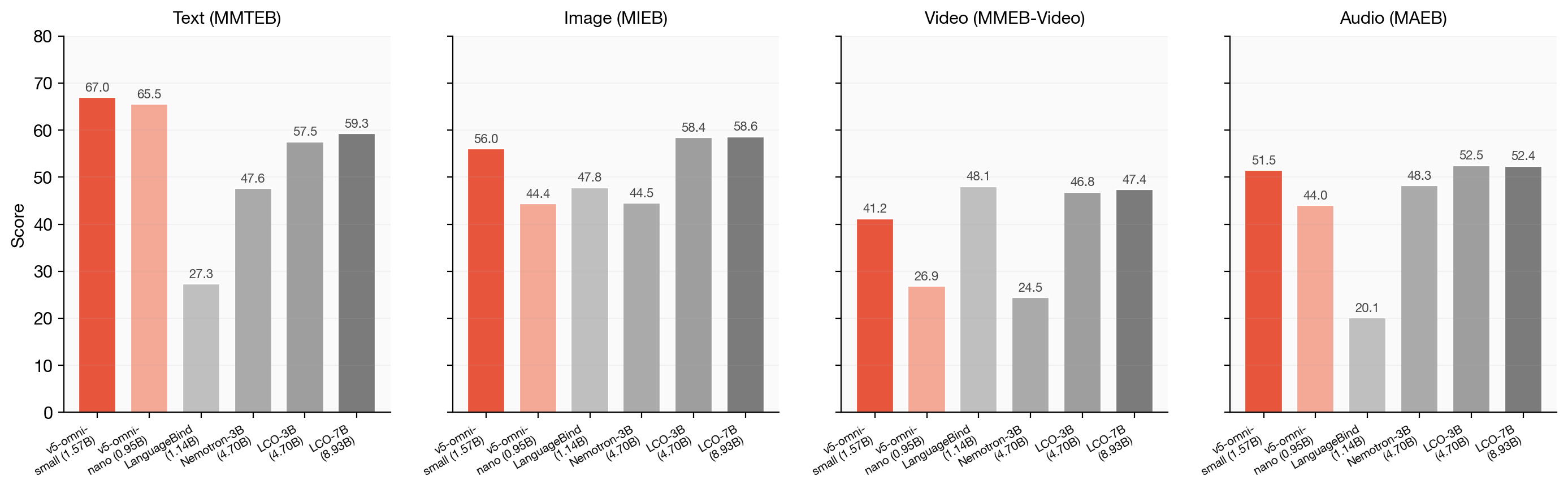
모달리티별로 살펴보면 다음과 같습니다:
-
텍스트(MMTEB, 67.0): 모든 옴니 모델 중 1위로, 사실상 jina-embeddings-v5-text-small의 품질을 그대로 상속합니다.
-
이미지(MIEB, 56.05): 이미지 분류 68.55점, 이미지 클러스터링 84.57점으로 전체 모델 중 최고 수준입니다.
-
오디오(MAEB, 51.46): LCO-7B(52.37)에 근접하며, 오디오 분류 55.89점으로 전 모델 최고 점수입니다.
-
비디오(MMEB-Video, 41.20): LCO-7B(47.41)와의 격차가 남아 있는 영역으로, 시간축 추론(temporal reasoning)이 끝-끝(end-to-end) 학습에서 더 큰 이득을 받는 부분으로 분석됩니다.
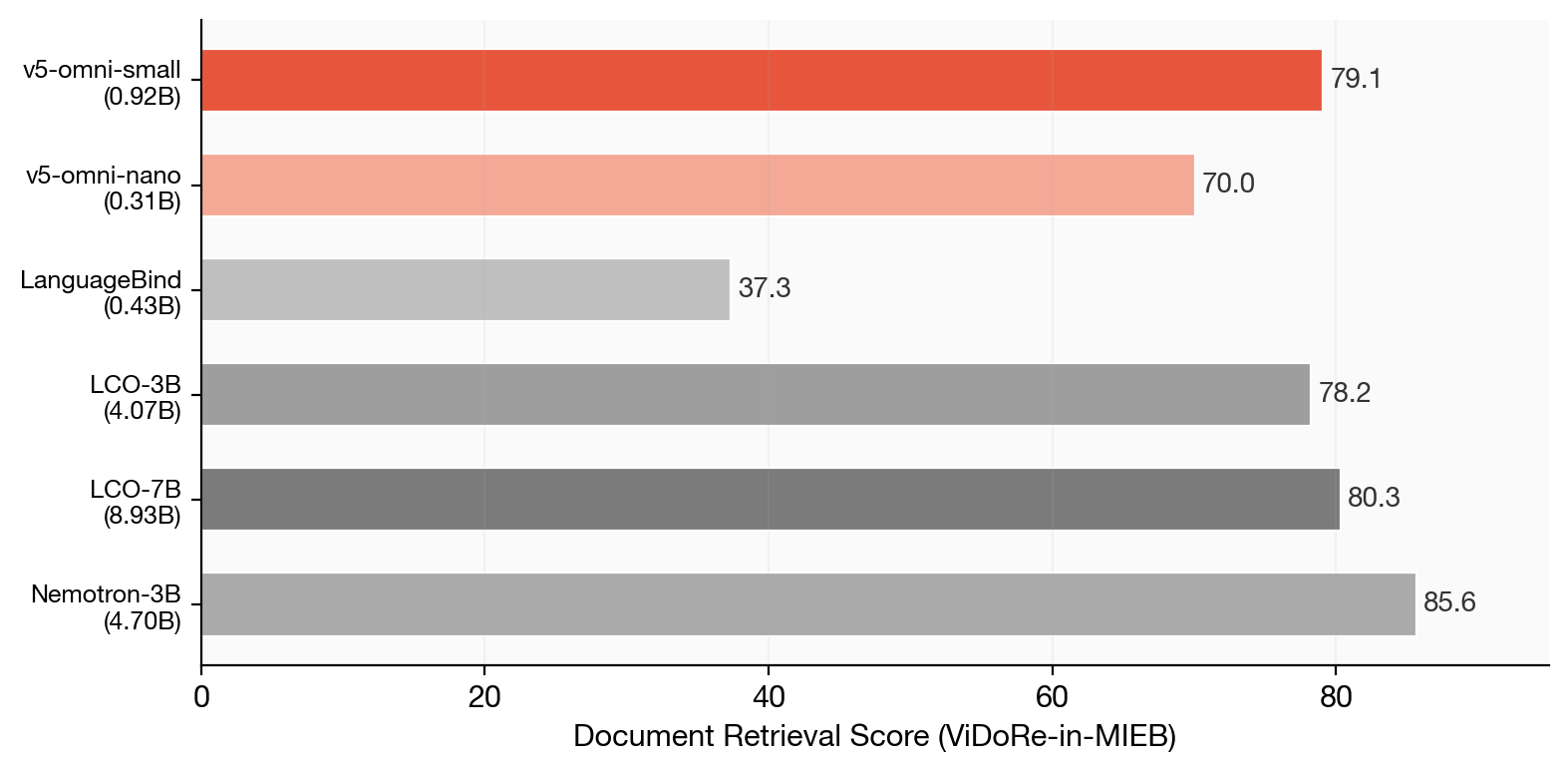
13개 세부 태스크 단위로 보면, v5-omni-small은 자신의 3~9배 크기의 오픈 가중치 베이스라인을 다음 항목들에서 능가합니다. 이미지 분류(68.55 vs 64.30), 이미지 클러스터링(84.57 vs 83.24), 오디오 분류(55.89 vs 53.39)가 대표적인 승리 영역입니다. 반면 비디오 검색(27.82 vs 58.73)과 구성적 비전 추론/VQA(44.23 vs 53.40)는 후속 작업으로 남아 있는 격차입니다.
특히 실무에서 자주 쓰이는 PDF/문서 페이지 검색(ViDoRe-in-MIEB 부분) 에서는 v5-omni-small이 활성 텍스트+이미지 0.92B 파라미터만으로 79.08점을 기록하여, 4.07B 규모의 LCO-3B(78.24)를 앞섰습니다. v5-omni-nano도 단 0.31B 활성 파라미터로 70.05점을 내며, LanguageBind(37.33)를 크게 웃돕니다. Nemotron-3B가 85.64로 선두를 차지하고 있지만, 약 5.1배의 파라미터를 사용한다는 점을 함께 고려해야 합니다.
학습: 양방향 InfoNCE와 Matryoshka 손실
프로젝터 학습은 양방향 인-배치 InfoNCE(In-Batch InfoNCE) 손실을 Matryoshka 표현 학습(Matryoshka Representation Learning) 과 결합한 형태로 진행됩니다. 배치 안의 페어 (\ell_i, r_i) 에 대해 두 임베딩의 첫 k 차원 코사인 유사도를 온도 \tau = 0.02 로 스케일한 분포를 만들고, 좌→우와 우→좌 양방향의 음의 로그우도를 평균한 다음, 여러 절단 차원 k 에 대해 합산합니다.
여기서 small은 \mathcal{K}_{\mathrm{Small}} = \{32, 64, 128, 256, 512, 768, 1024\}, nano는 \mathcal{K}_{\mathrm{Nano}} = \{32, 64, 128, 256, 512, 768\} 의 절단 차원 집합을 사용합니다. 모든 절단 차원에서 동시에 의미 있는 거리가 유지되도록 학습하기 때문에, 추론 단계에서 사용자가 임의의 차원으로 잘라도 정확도 손실이 적습니다.
학습 하이퍼파라미터는 AdamW(\beta_1 = 0.9, \beta_2 = 0.999, weight decay 0.01), 그래디언트 클리핑 \|\nabla\|_2 \leq 1, 학습률 2 \cdot 10^{-4} 에 500스텝 선형 워밍업, bf16 혼합 정밀도, NVIDIA H100 4장 분산 데이터 병렬, 글로벌 배치 크기 256입니다. 검색, 분류, 클러스터링, 텍스트 매칭 네 가지 태스크 변형 각각에 대해 동일한 데이터 혼합으로 15,000 옵티마이저 스텝씩 별도 학습이 수행됩니다.
실제 검색/RAG 환경을 반영한 학습 데이터 혼합
학습 데이터는 모달리티별로 입력 토큰 점유율(token share) 기준으로 다음과 같이 구성됩니다.
| 모달리티 | 데이터 유형 | 토큰 점유율 |
|---|---|---|
| 이미지 | 자연 사진(natural photos) | 35.5% |
| 이미지 | 의료 이미지(medical imagery) | 30.3% |
| 이미지 | 문서/OCR(documents & OCR) | 23.7% |
| 이미지 | 제품 카탈로그(product catalog) | 5.3% |
| 이미지 | 차트/다이어그램(charts & diagrams) | 3.6% |
| 이미지 | UI/스크린샷(UI & screenshots) | 1.6% |
| 오디오 | 음악(music) | 55.0% |
| 오디오 | 환경음(environmental sounds) | 25.5% |
| 오디오 | 영어 음성(English speech) | 14.2% |
| 오디오 | 다국어 음성(multilingual speech) | 3.1% |
| 오디오 | 동물 소리(animal sounds) | 1.9% |
| 오디오 | 감정 음성(emotional speech) | 0.2% |
이미지 데이터의 절반 이상이 문서, OCR, 차트, 스크린샷 같은 텍스트가 풍부하거나 레이아웃이 복잡한 이미지로 채워져 있다는 점이 눈에 띕니다. 이는 실제 기업 검색이나 RAG 시스템이 마주하는 데이터, 즉 PDF 스캔본이나 인포그래픽처럼 레이아웃과 OCR 품질이 검색 결과를 좌우하는 자료를 의식적으로 비중 있게 포함시킨 설계입니다. 오디오 측에서는 음악과 환경음이 전체 토큰의 80%를 차지하여, 음성 위주의 일반 오디오 인코딩보다 훨씬 폭넓은 사운드 카테고리에서 임베딩이 의미를 갖도록 유도합니다.
프로젝터만 학습하는 효율적인 학습 전략
GELATO 학습 전략의 가장 직접적인 이점은 학습 비용입니다.
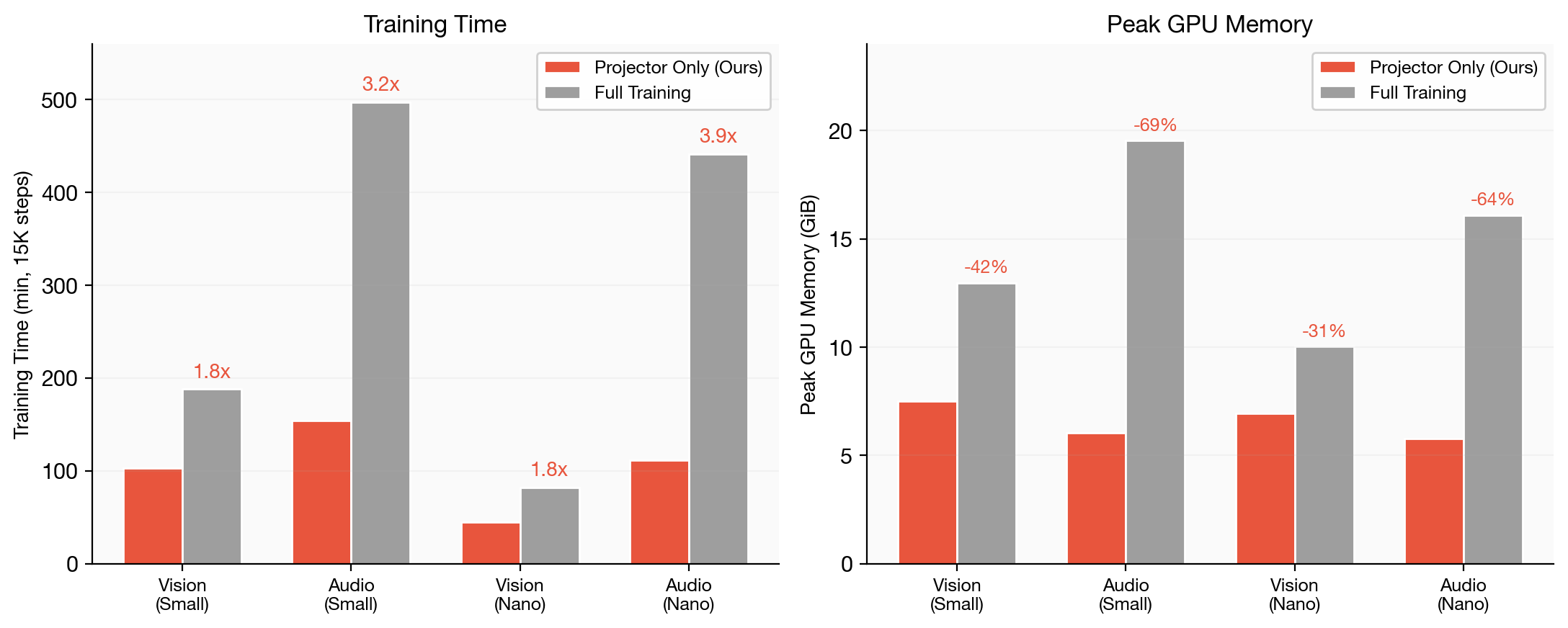
H100 4장을 사용한 비교에서, 프로젝터만 학습하는 방식은 전체 파라미터 학습 대비 1.8~3.9배 빠르고, GPU 메모리는 42~64% 적게 사용합니다. 특히 오디오 프로젝터 학습은 small 모델에서 154분으로 끝나며, 같은 조건의 전체 학습(497분)보다 3.2배 빠릅니다. nano 모델에서는 112분 대 441분으로 3.9배 격차가 벌어집니다. 프로즌 인코더에 대한 그래디언트와 옵티마이저 상태를 저장할 필요가 없기 때문에 메모리 절약이 크게 발생합니다.
이 접근에서 흥미로운 점은, "전체 모델을 끝에서 끝까지(End-to-End) 학습해야만 의미 있는 멀티모달 임베딩이 가능하다" 는 일반적인 통념을 정면으로 부정한다는 것입니다. 강한 텍스트 인코더가 이미 존재한다면, 비전과 오디오를 작은 프로젝터로 붙이는 비용은 거의 무료에 가깝다는 것이 v5-omni의 메시지입니다.
무엇을 동결하고 무엇을 학습해야 하는가: 어블레이션 연구
논문은 GELATO가 의존하는 두 가지 설계 선택, 즉 "어떤 프로젝터 층을 학습할지" 와 "인코더를 갱신할지 말지" 를 어블레이션으로 검증합니다.
비전 어블레이션에서는 다섯 가지 구성을 비교했습니다. 결과를 간단히 요약하면 다음과 같습니다.
fc_vision_2만 학습 (실제 채택): nDCG@10 0.158fc_vision_1+fc_vision_2함께 학습: 0.153 (오히려 약간 낮음)fc_vision_1+fc_vision_2+ 비전 인코더 전체 동시 학습 (학습률을 20배 낮춤): 0.079 (명백히 해로움)- 두 단계 학습으로 인코더까지 풀어준 변형: 0.159 (단 0.001 개선)
비전 인코더 자체를 푸는 순간 정렬이 무너지면서 성능이 절반 가까이 떨어진다는 점은, "이미 언어 정렬된 인코더는 다시 손대지 않는다" 는 GELATO의 핵심 가설을 강하게 뒷받침합니다. 0.001 정도의 한계 이득을 위해 네 가지 태스크 변형 각각에 두 단계 학습과 별도 어댑터를 유지하는 비용은 정당화되지 않으므로, 공개 모델은 가장 단순한 프로즌 타워 레시피를 유지합니다.
오디오 어블레이션에서는 세 가지 구성을 비교했습니다.
fc_audio만 학습 (실제 채택): 평균 0.398fc_audio+ 오디오 인코더 동시 학습: 0.367 (낮음)- 두 단계로
fc_audio학습 후 오디오 인코더까지 풀어준 변형: 0.419 (+0.022 개선)
흥미롭게도 오디오의 경우 2단계로 인코더까지 푸는 방식이 명확한 이득을 보였습니다. 다만 단순함을 위해 공개 모델은 단일 단계 동결 레시피를 유지하며, 오디오 인코더 적응은 향후 학습 단계의 유망한 후보 로 남겨두었다고 밝히고 있습니다.
Matryoshka 보존성 어블레이션에서는 임베딩을 어디까지 잘라도 검색 품질이 유지되는지를 측정했습니다. 텍스트와 이미지는 32차원까지 줄여도 0.18~0.21 nDCG@10 정도만 잃고, 오디오는 256차원까지는 점수가 거의 유지되지만 비디오는 작은 차원에서 훨씬 크게 떨어집니다. 운영 관점에서 이미지/오디오 검색은 매우 공격적인 차원 축소가 가능하지만, 비디오 검색에서는 768~1024 같은 전체 차원을 유지하는 편이 안전하다는 실용적인 가이드를 줍니다.
시작하기: 인덱스 재구축 없이 멀티모달로 확장
기존에 jina-embeddings-v5-text 인덱스를 사용 중이라면, v5-omni는 텍스트 입력에 대해 바이트 수준에서 동일한 벡터 를 생성하므로 기존 인덱스를 재구축할 필요가 없습니다. 새로운 이미지/오디오/비디오 데이터만 같은 필드에 같은 인덱스로 적재(ingest)하면 됩니다.
Elasticsearch (Elastic Inference Service)
Elasticsearch의 Elastic Inference Service를 사용하면 별도의 모델 서빙 없이 옴니 모델을 그대로 활용할 수 있습니다. semantic_text 인덱스를 생성하면 EIS가 인덱싱과 검색 단계에서 자동으로 올바른 LoRA 어댑터를 선택합니다.
PUT multimodal-semantic-index
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": ".jina-embeddings-v5-omni-small"
}
}
}
}
같은 필드에 텍스트, 이미지(base64 data URI), 오디오, 비디오를 함께 적재하고, 단일 텍스트 쿼리로 모든 모달리티를 가로질러 검색할 수 있습니다.
// Ingest text
POST multimodal-semantic-index/_doc
{
"content": "'Kraft Dinner' is what Canadians call macaroni and cheese when prepared from a kit."
}
// Ingest an image (base64)
POST multimodal-semantic-index/_doc
{
"content": "data:image/png;base64,iVBORw0KGgoAAAAN..."
}
// Cross-modal search
GET multimodal-semantic-index/_search
{
"query": {
"semantic": {
"field": "content",
"query": "Was bedeutet 'Kraft Dinner' für Kanadier?"
}
}
}
Jina Search Foundation API
Jina Search Foundation API를 사용하면 HTTP 한 번으로 멀티모달 임베딩을 얻을 수 있습니다.
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "jina-embeddings-v5-omni-small",
"task": "retrieval.query",
"dimensions": 1024,
"input": ["What does this image show?"],
"images": ["data:image/png;base64,..."]
}'
Hugging Face / sentence-transformers
직접 호스팅이 필요한 경우에는 sentence-transformers 라이브러리로 Hugging Face Hub 모델을 불러올 수 있습니다.
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer(
"jinaai/jina-embeddings-v5-omni-small-retrieval",
model_kwargs={"dtype": torch.bfloat16},
)
# Text embedding (identical to v5-text)
text_emb = model.encode("What is knowledge distillation?", prompt_name="query")
# Image embedding
from PIL import Image
img = Image.open("photo.jpg")
img_emb = model.encode(img)
# Cross-modal similarity
similarity = model.similarity(text_emb, img_emb)
시사점: 합성(Composition)이 재학습(Retraining)을 이긴다
v5-omni가 보여주는 결과는 멀티모달 임베딩 설계 관점에서 몇 가지 분명한 메시지를 던집니다.
첫째, "텍스트 인코더가 가장 어려운 부분이고, 일단 좋은 텍스트 인코더가 있다면 다른 모달리티는 가벼운 프로젝터로 얹는 비용이 거의 무료에 가깝다" 는 가설이 실증적으로 뒷받침되었습니다. 0.35%의 가중치만 학습하여 5~7배 큰 모델과 어깨를 나란히 한다는 점은, 멀티모달 임베딩 연구가 더 큰 통합 모델로 가는 방향뿐 아니라, 강한 단일 모달 백본을 동결한 채 결합하는 방향에도 충분한 가능성이 있음을 보여줍니다.
둘째, 운영 관점에서 "이미 구축된 텍스트 인덱스를 그대로 두고 멀티모달 검색을 얹을 수 있다" 는 점은 실무자에게 매우 매력적입니다. 새로운 모달리티 도입이 인덱스 재구축이라는 큰 마이그레이션 비용을 동반하는 경우가 많았던 점을 생각하면, 동일 벡터 보장은 단순한 편의 기능이 아니라 실제 도입 비용을 크게 낮추는 핵심 차별점입니다.
셋째, 남아 있는 격차도 분명합니다. 비디오 검색과 구성적 비전 추론처럼 시간축과 복잡한 상호작용을 다루는 영역에서는 여전히 끝-끝 학습 기반 모델이 앞서며, 이는 향후 GELATO 계열 접근이 단순한 프로젝터 외에 어떤 학습 가능 구성 요소를 추가해야 할지를 시사합니다. 오디오 어블레이션에서 인코더 미세조정이 명확한 이득을 보였다는 점, 그리고 다중 모달리티 프로젝터를 동시에 학습하는 방향이 향후 과제로 언급된다는 점은 GELATO가 정적인 결과물이 아니라 발전 중인 학습 레시피 임을 보여줍니다.
넷째, XM3600 다국어 이미지-언어 평가와 CommonVoiceMini21/FLEURS 다국어 오디오 검색에서, v5-omni-small이 영어가 아닌 언어들에서 베이스라인 평균 대비 비교적 강한 성능을 보였다는 점도 주목할 만합니다. v5-text가 이미 보유한 다국어 텍스트 임베딩 품질을 그대로 상속하면서, 동결 인코더 위에 얹은 프로젝터가 이 다국어 정렬을 깨뜨리지 않았다는 의미이기 때문입니다. 한국어를 포함해 비영어 환경에서 멀티모달 검색을 구축하려는 경우 의미 있는 신호입니다.
마지막으로, v5-omni 모델의 라이선스가 CC BY-NC 4.0으로 비상업적 용도로 제한된다는 점은 도입 전 반드시 확인해야 합니다. 연구나 내부 프로토타입 단계에서는 자유롭게 활용 가능하지만, 상업적 서비스에 적용하려면 Jina AI 라이선싱 문의가 필요합니다.
 jina-embeddings-v5-omni 소개 블로그
jina-embeddings-v5-omni 소개 블로그
 GELATO 논문: jina-embeddings-v5-omni: Geometry-preserving Embeddings via Locked Aligned Towers
GELATO 논문: jina-embeddings-v5-omni: Geometry-preserving Embeddings via Locked Aligned Towers
 jina-embeddings-v5-omni Hugging Face 컬렉션
jina-embeddings-v5-omni Hugging Face 컬렉션
 Jina AI 홈페이지
Jina AI 홈페이지
라이선스
jina-embeddings-v5-omni 모델은 CC BY-NC 4.0 라이선스에 따라 배포되며, 출처를 표시하면 비상업적 용도로 자유롭게 이용할 수 있습니다. 상업적 사용을 원하는 경우 Jina AI와의 별도 라이선스 협의가 필요합니다.
더 읽어보기
-
EmbeddingGemma: Google이 공개한, On-Device Embedding을 위한 308M 규모의 소형 모델
-
E5-V, Multimodal LLM을 활용한 범용 임베딩 프레임워크(Universal Embedding Framework)
-
BidirLM, 기존의 LLM을 오픈소스 옴니모달 양방향 인코더(Omni-modal Bidirectional Encoder)로 변환하는 레시피와 모델 공개
-
Perplexity, 웹 스케일 검색을 위한, 양방향 디퓨전 어텐션을 적용한 다국어 임베딩 모델 pplx-embed 2종 공개
-
Hugging Face, 최대 400배 빠른 CPU 기반 정적 임베딩(Static Embedding) 모델 공개 (feat. Sentence Transformers)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()