
LFM2.5와 LFM2.5 Retrievers 소개
Liquid AI가 2026년 들어 엣지(edge) 환경을 겨냥한 소형 모델 제품군을 빠르게 확장하고 있습니다. 먼저 350M 파라미터의 범용 언어 모델 LFM2.5-350M을 내놓아 자기보다 두 배 이상 큰 모델을 여러 벤치마크에서 앞질렀고, 이어서 같은 백본 위에 올린 두 개의 다국어 검색(retrieval) 모델 LFM2.5-Embedding-350M과 LFM2.5-ColBERT-350M을 공개했습니다. 세 모델 모두 노트북, 스마트폰, 심지어 라즈베리파이에서도 돌아갈 만큼 작으면서, 11개 언어를 빠르고 안정적으로 처리합니다.
이 글의 목적은 단순히 새 모델 출시 소식을 전하는 것이 아닙니다. Liquid AI의 모델은 우리가 흔히 보는 트랜스포머(Transformer) 기반 거대 언어 모델과는 설계 철학과 내부 구조가 상당히 다릅니다. 그래서 이 글에서는 Liquid Foundation Models(LFM) 라는 모델군이 무엇인지, 어떤 구조로 어떻게 빠른 속도를 얻는지, 그리고 그 장단점은 무엇인지부터 차근차근 살펴본 뒤, LFM의 두 번째 세대인 LFM2와 그 개선판인 LFM2.5, 마지막으로 검색에 특화된 LFM2.5 Retrievers까지 이어서 설명합니다. LFM을 처음 접하는 분이라도 이 글 하나로 전체 그림을 잡을 수 있도록 구성했습니다.
핵심을 한 문장으로 요약하면 이렇습니다. LFM은 "엣지 기기에서 빠르고 가볍게 도는 것"을 최우선 목표로 두고, 어텐션 위주의 일반적인 트랜스포머 대신 단거리 합성곱과 소수의 어텐션을 섞은 하이브리드 구조를 하드웨어 제약 아래에서 직접 탐색해 만든 모델군입니다. 그리고 LFM2.5 Retrievers는 이 생성용 디코더 백본을 검색용 양방향 인코더로 개조한 첫 사례입니다.
Liquid Foundation Models(LFM)이란 무엇인가
LFM을 만든 Liquid AI는 MIT CSAIL에서 출발한 스타트업으로, 창업자와 핵심 연구진(Ramin Hasani, Mathias Lechner, Alexander Amini, Daniela Rus)은 이른바 리퀴드 신경망(Liquid Neural Networks) 연구로 알려진 사람들입니다. 리퀴드 신경망은 예쁜꼬마선충(C. elegans) 같은 생물 신경계에서 영감을 받아, 뉴런의 상태가 시간에 따라 연속적으로 변하는 미분방정식으로 표현되는 모델입니다. 대표적으로 Liquid Time-constant Networks와 폐형식 연속시간 모델(Closed-form Continuous-time, CfC)이 있으며, 이 계열을 상태공간 모델(State Space Model)과 결합한 Liquid-S4 같은 연구로 이어졌습니다. "Liquid"라는 이름은 여기에서 비롯되었습니다.
이러한 학술적 뿌리에서 출발한 Liquid AI는 거대한 클라우드 모델 경쟁에 뛰어드는 대신, 온디바이스(on-device) 배포 라는 다른 방향을 택했습니다. 즉, 데이터센터의 GPU가 아니라 사용자의 손에 있는 휴대폰, 노트북, 자동차, IoT 기기에서 직접 추론을 돌리는 것을 1차 목표로 삼습니다. 이런 환경에서는 모델의 정확도뿐 아니라 지연 시간(latency) 과 메모리 사용량(peak memory) 이 똑같이 중요한 제약 조건이 됩니다. 아무리 똑똑해도 스마트폰에서 답변이 느리게 나오거나 메모리가 부족해 실행조차 안 된다면 쓸모가 없기 때문입니다.
그래서 LFM의 설계 철학은 엣지 우선(edge-first) 으로 요약됩니다. Liquid AI는 아키텍처, 사전학습(pre-training), 사후학습(post-training)을 따로따로 최적화하지 않고, "기기의 지연 시간과 메모리 한도를 지키면서 다운스트림 품질을 최대화한다"는 하나의 목표 아래 셋을 함께 설계(co-design)합니다. 이 글에서 다루는 LFM2는 그 두 번째 세대이며, LFM2.5는 LFM2 백본을 그대로 유지하면서 학습량과 사후학습을 강화한 개선판입니다.
엣지 우선 설계의 핵심: LFM2 아키텍처
LFM2의 가장 큰 특징은 우리가 익숙한 "어텐션을 매 층마다 쌓는 트랜스포머"가 아니라는 점입니다. LFM2의 모든 설계 결정은 2025년 11월 공개된 LFM2 기술 보고서(arXiv:2511.23404)에 상세히 담겨 있으며, 아래에서는 그 핵심을 풀어 설명합니다.
사람이 고르지 않고 하드웨어가 고른 구조: 하드웨어 인 더 루프 탐색
최근의 효율적인 아키텍처들은 보통 세 가지 재료를 섞습니다. (1) Mamba 같은 상태공간 모델이나 선형 어텐션(linear attention) 같은 대안적 시퀀스 연산자, (2) 단거리 합성곱(short convolution), 그리고 (3) 품질을 보전하기 위한 소량의 표준 소프트맥스 어텐션(softmax attention)입니다. 문제는 "이 재료들을 어떤 비율로, 어떤 순서로 쌓아야 엣지에서 가장 좋은가"를 사람의 직관으로 정하기 어렵다는 데 있습니다.
Liquid AI는 이 선택을 하드웨어 인 더 루프 아키텍처 탐색(hardware-in-the-loop architecture search) 으로 풀었습니다. 후보 구조들을 실제 엣지 하드웨어에서 같은 런타임으로 돌려 지연 시간과 메모리를 측정하고, 동시에 내부 평가셋으로 품질을 측정한 뒤, 품질과 속도와 메모리의 파레토 경계(Pareto frontier)에 남는 구조만 다음 단계로 진출시키는 방식입니다. Liquid AI의 초기 학술 프로토타입인 STAR가 복잡도(perplexity)나 캐시 크기 같은 대리 지표로 탐색했던 것과 달리, LFM2는 처음부터 "실제 다운스트림 점수"와 "실제 기기에서 측정한 첫 토큰 생성 시간(TTFT)·지연·메모리"를 목표 함수로 삼았다는 점이 핵심입니다.
이 탐색이 크기별로 반복해서 골라낸 답은 의외로 단순했습니다. 대부분의 층은 값싼 게이트 단거리 합성곱(gated short convolution) 블록으로 채우고, 장거리 정보가 필요한 검색 능력을 위해 소수의 그룹 쿼리 어텐션(GQA) 블록만 끼워 넣는 최소 하이브리드(minimal hybrid) 입니다. 여기에 상태공간이나 선형 어텐션 같은 연산자를 더 추가해 봐도, 같은 기기 성능 예산 안에서는 품질이 나아지지 않고 오히려 기기 지표만 나빠졌다고 합니다.
게이트 단거리 합성곱 블록과 GQA
LFM2 밀집(dense) 모델은 이 최소 하이브리드를 그대로 구현합니다. 다수를 차지하는 게이트 단거리 합성곱 블록(gated short convolution block) 은 입력에 따라 곱셈 게이팅을 적용한 깊이별(depthwise) 단거리 1D 합성곱입니다. 입력 시퀀스 \mathbf{h} \in \mathbb{R}^{L \times d} 를 선형 사상 \mathrm{Linear}: \mathbb{R}^{d} \to \mathbb{R}^{3d} 으로 세 갈래 (\mathbf{B}, \mathbf{C}, \tilde{\mathbf{h}}) 로 나눈 뒤, 깊이별 합성곱 \mathrm{Conv}_k 와 원소별 곱(\odot)으로 게이팅하고 출력 사상으로 마무리하는, 개념적으로 다음과 같은 형태입니다:
이 연산자는 가까운 위치의 토큰들끼리 정보를 섞는 데 특화되어 있고, 무엇보다 CPU에서 캐시 활용이 매우 좋아 빠르게 돕니다. 이것이 Hyena나 Mamba 같은 최신 효율 블록 안에 들어 있는 단거리 성분과 본질적으로 닮아 있는데, LFM2의 발견은 "장거리를 담당할 어텐션 몇 개만 있으면, 굳이 선형 어텐션이나 상태공간 가지를 더 붙이지 않아도 이 단거리 합성곱만으로 충분하다"는 것입니다.
장거리 의존성은 소수의 그룹 쿼리 어텐션(Grouped-Query Attention, GQA) 블록이 맡습니다. GQA는 키와 값을 여러 헤드가 공유하게 하여 KV 캐시 트래픽을 줄이면서도 다중 헤드 쿼리의 표현력은 유지하는 기법입니다. 위치별 MLP는 SwiGLU를 쓰고, 모든 층은 RMSNorm으로 정규화하며, 어텐션 블록은 RoPE와 QK-Norm을 사용합니다. 토크나이저는 65,536개 어휘의 바이트 수준 BPE로, 영어뿐 아니라 한국어, 일본어, 아랍어, 스페인어, 프랑스어, 독일어의 인코딩 효율과 JSON 같은 구조화된 형식을 고려해 학습되었습니다.
LFM2 제품군과 학습 파이프라인
LFM2는 단일 모델이 아니라 하나의 백본에서 파생된 제품군입니다. 350M부터 2.6B까지의 밀집 모델과, 총 8.3B 파라미터 중 1.5B만 활성화되는 전문가 혼합(Mixture-of-Experts, MoE) 모델 LFM2-8B-A1B가 있으며, 모두 32K 컨텍스트를 지원합니다. 여기에 시각 언어 모델 LFM2-VL, 음성 모델 LFM2-Audio, 그리고 검색용 LFM2-ColBERT가 같은 백본 위에 올라가고, 데이터 추출이나 함수 호출, RAG 같은 특정 작업에 맞춘 LFM2-Nanos 시리즈도 파생됩니다.
| 구분 | 내용 |
|---|---|
| 밀집 모델 | 350M, 700M, 1.2B, 2.6B (모두 32K 컨텍스트) |
| MoE 모델 | LFM2-8B-A1B (총 8.3B, 활성 1.5B, 층당 32개 전문가 중 Top-4 선택) |
| 멀티모달 | LFM2-VL (시각 언어), LFM2-Audio (실시간 음성 대화) |
| 검색 | LFM2-ColBERT, LFM2.5 Retrievers (Embedding, ColBERT) |
| 작업 특화 | LFM2-Nanos (데이터 추출, 함수 호출, RAG, 수학 추론) |
작은 모델이 큰 모델 수준의 품질을 내려면 학습 기법이 정교해야 합니다. LFM2는 사전학습 단계에서 표준 다음 토큰 예측에 더해, 7B 교사 모델(LFM1-7B)로부터 온도 적용 분리형 Top-K 지식 증류(decoupled, tempered Top-K knowledge distillation) 를 사용합니다. 교사 분포 전체가 아니라 토큰별 상위 32개 로짓만 증류하는데, 단순히 잘린 분포에 KL 발산을 적용하면 지지집합 불일치(support mismatch)로 학습이 불안정해집니다. 이를 막기 위해 KL을 (1) 상위 K개 집합에 들어갈 총 확률 질량을 맞추는 이항 항과 (2) 그 안에서 갖는 상대 확률을 맞추는 조건부 항으로 분해하고, 온도는 조건부 항에만 적용합니다. 또한 12개 모델 앙상블이 각 문제를 맞혔는지로 난이도를 매겨 쉬운 예제부터 어려운 예제로 진행하는 커리큘럼 학습(curriculum learning) 을 적용합니다.
사후학습은 세 단계로 이뤄집니다. 먼저 약 539만 개 샘플로 지도 미세조정(Supervised Fine-Tuning, SFT) 을 거쳐 대화 템플릿과 지시 따르기 능력을 익히고, 이어서 오프라인 데이터와 SFT 체크포인트가 생성한 온폴리시(on-policy) 샘플로 선호도 정렬(preference alignment) 을 수행하며, 마지막으로 여러 후보 모델을 체계적으로 합치는 모델 병합(model merging) 으로 강건성을 끌어올립니다.
LFM 아키텍처의 장점과 한계
이러한 설계가 주는 장점은 분명합니다.
-
CPU에서 빠른 속도: LFM2 밀집 모델은 비슷한 크기의 모델 대비 CPU에서 프리필(prefill)과 디코드(decode) 모두 최대 약 2배 빠릅니다. 게이트 단거리 합성곱이 CPU 캐시와 잘 맞기 때문입니다.
-
메모리 효율: 어텐션 층을 최소화해 KV 캐시 부담이 작고, 양자화(quantization) 변형이 함께 제공되어 저사양 기기에서도 실행됩니다.
-
확장성 있는 제품군: 350M부터 MoE까지 하나의 백본으로 품질과 지연과 메모리 목표를 폭넓게 커버하며, MoE 모델은 1.5B 수준의 디코드 비용으로 3~4B급 품질을 냅니다.
반면 한계도 분명히 존재합니다. LFM2.5-350M 같은 소형 모델은 데이터 추출, 함수 호출, 지시 따르기에는 강하지만 수학, 코드, 창작 글쓰기에는 권장되지 않습니다. 350M이라는 크기 자체가 담을 수 있는 지식과 추론 깊이를 제한하기 때문입니다. 또한 단거리 합성곱 위주의 구조는 어텐션 전용 모델보다 검색 집약적(retrieval-intensive) 장거리 작업에서 본질적으로 불리할 수 있는데, LFM2는 소수의 GQA 층을 끼워 이 약점을 보완하는 절충을 택했습니다. 즉 LFM은 "모든 작업에서 최고"를 노리는 모델이 아니라, "정해진 기기 예산 안에서 실용적인 작업을 가장 빠르게"라는 분명한 목표를 가진 모델입니다.
LFM2 아키텍처 더 알아보기
LFM2.5-350M: 두 배 큰 모델을 능가하는 350M
LFM2.5-350M은 기존 LFM2-350M의 개선판으로, 사전학습 토큰을 10T에서 28T로 크게 늘리고 대규모 강화학습(Reinforcement Learning)을 추가했습니다. 그 결과 도구 사용, 데이터 추출, 구조화된 출력에서 특히 강한, 엣지에서 이뤄지는 대규모 데이터 처리와 함수 호출에 최적화된 모델이 되었습니다.
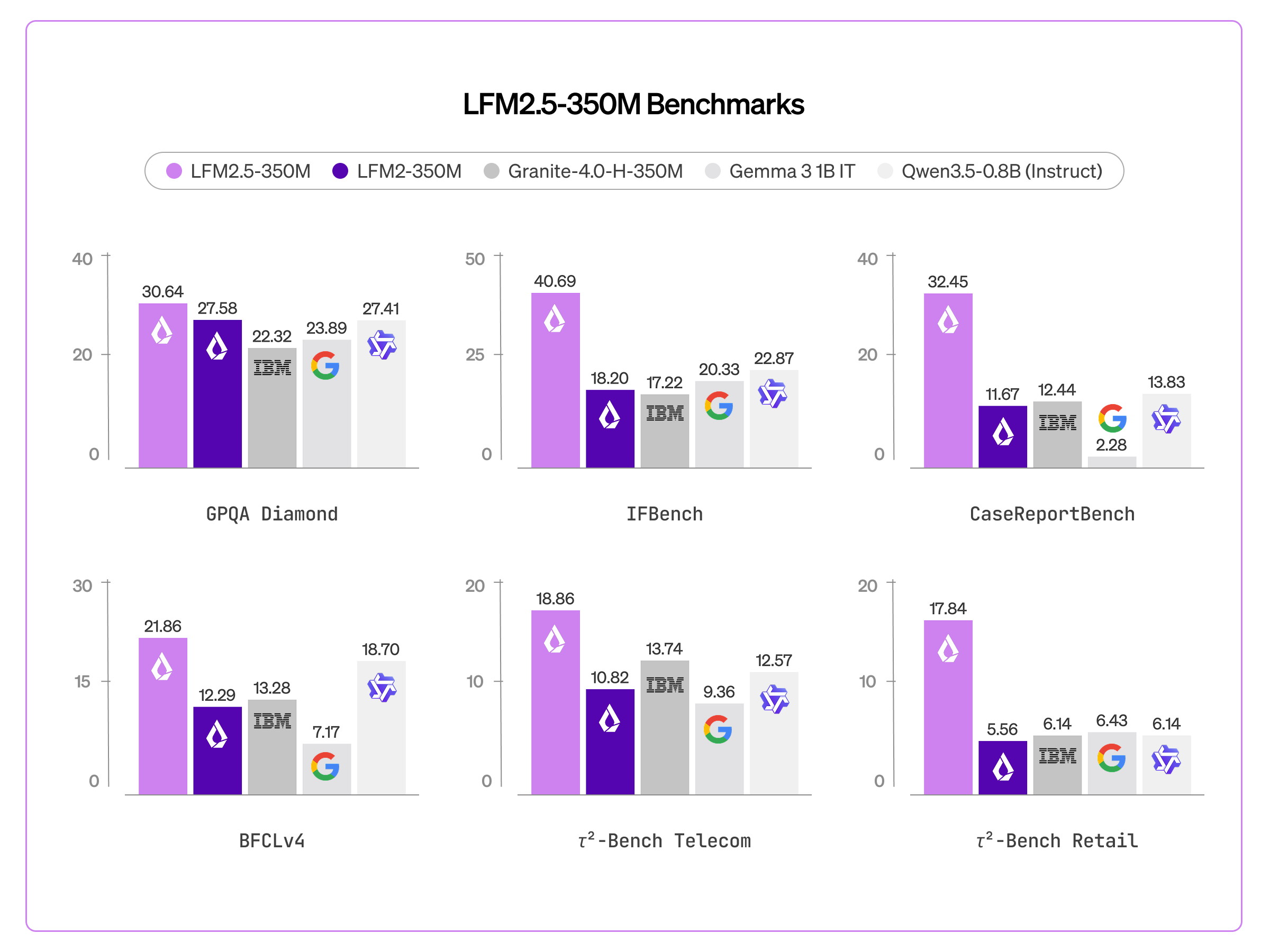
주목할 점은 이 350M 모델이 자기보다 두 배 이상 큰 모델들을 여러 벤치마크에서 앞선다 는 것입니다. 지식(GPQA Diamond 30.64, MMLU-Pro 20.01)과 지시 따르기(IFEval 76.96, IFBench 40.69, Multi-IF 44.92)는 물론, 데이터 추출(CaseReportBench 32.45)과 도구 사용(BFCLv3 44.11) 같은 응용 작업에서도 Granite 4.0, Qwen3.5-0.8B, Gemma 3 1B 등을 능가합니다. 특히 직전 세대인 LFM2-350M과 비교하면 세 능력이 크게 뛰었습니다.
| 능력 | LFM2-350M | LFM2.5-350M |
|---|---|---|
| 지시 따르기 (IFBench) | 18.20 | 40.69 |
| 데이터 추출 (CaseReportBench) | 11.67 | 32.45 |
| 도구 사용 (BFCLv3) | 22.95 | 44.11 |
다만 Liquid AI 스스로도 밝히듯, 이 모델은 수학, 코드, 창작 글쓰기에는 적합하지 않습니다. 대신 대규모 데이터 추출 파이프라인이나 가벼운 온디바이스 에이전트 파이프라인을 구동하는 데 이상적입니다.
어디서나 빠른 추론과 넓어진 파트너 생태계
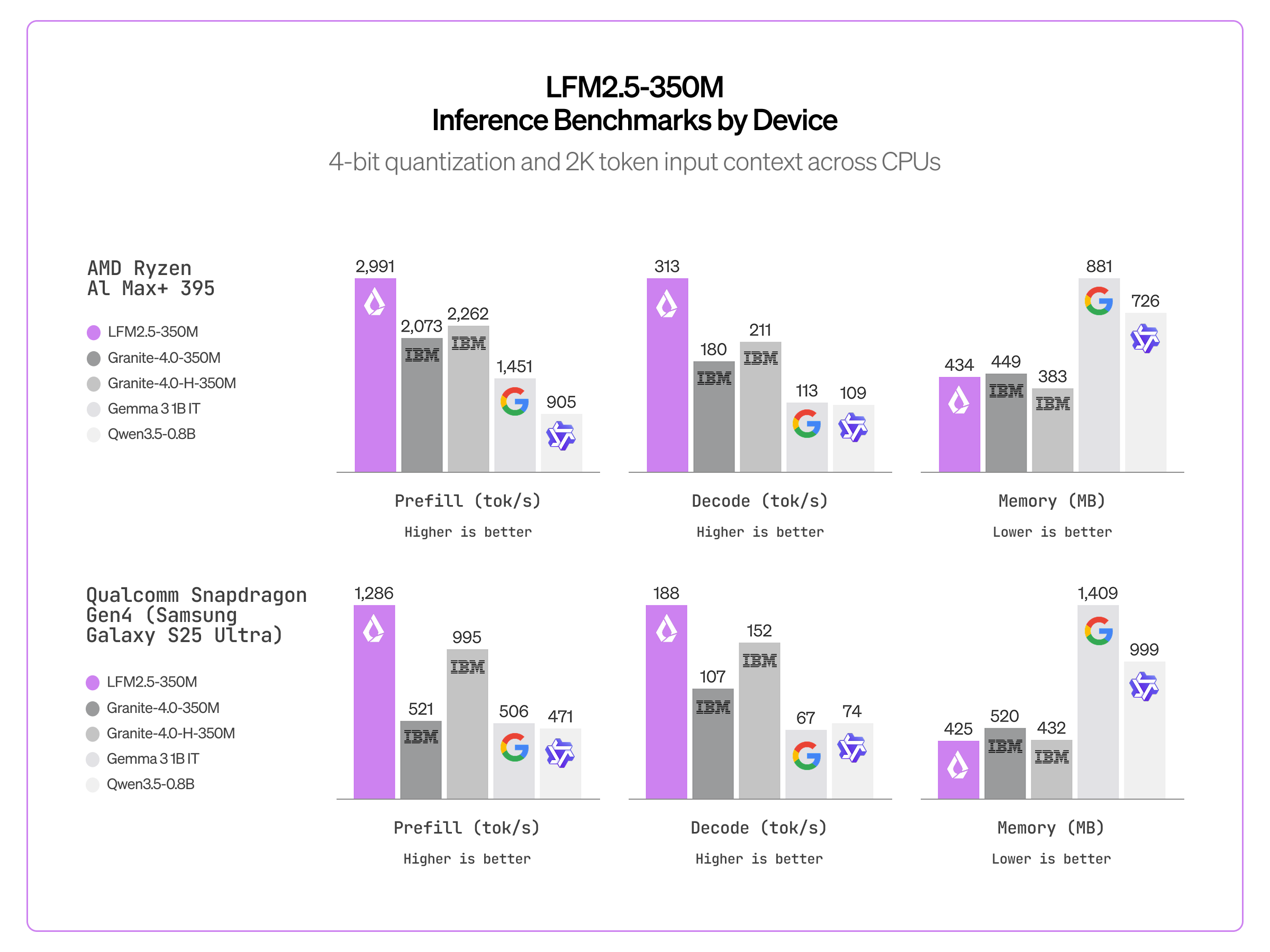
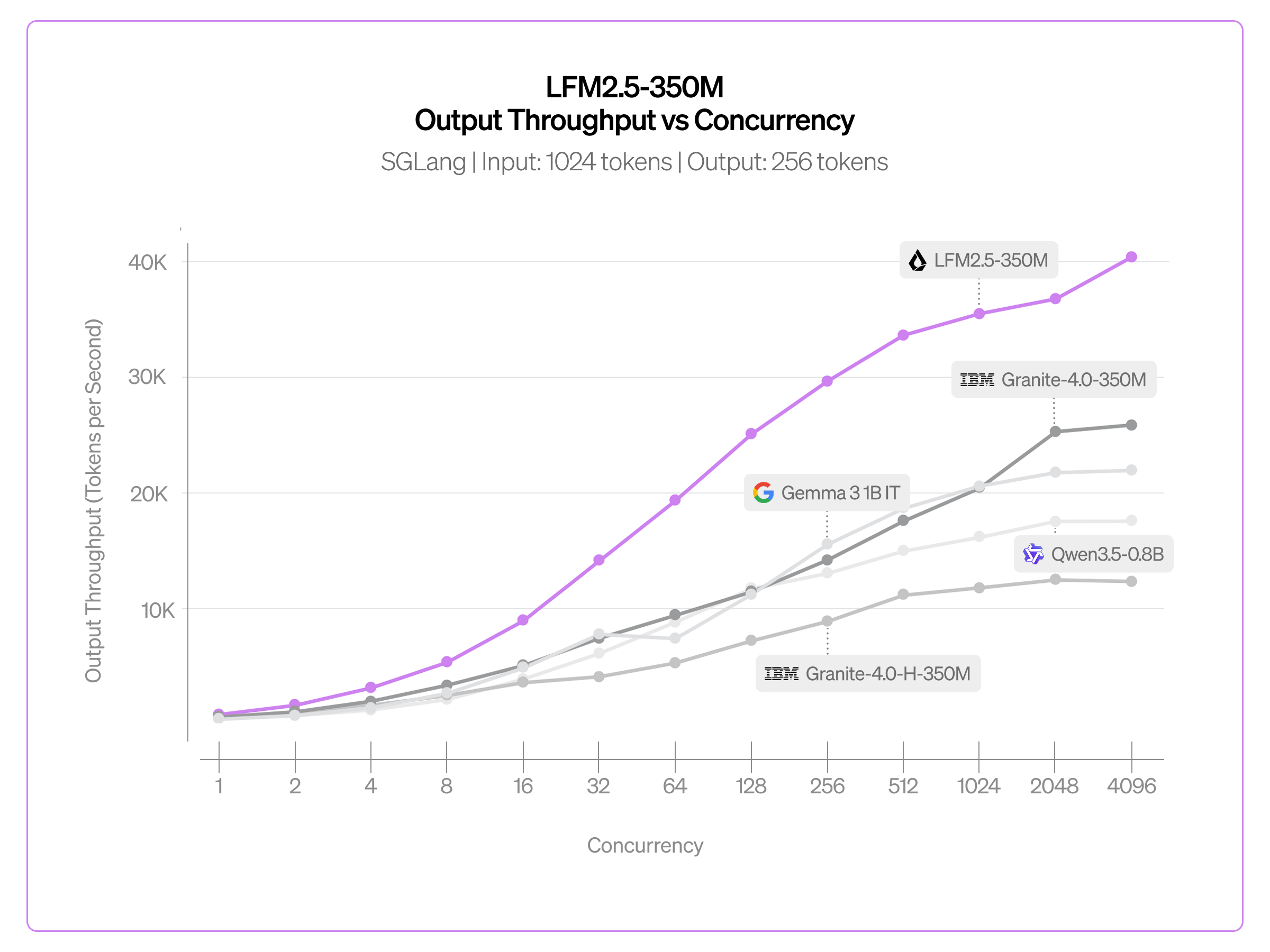
LFM2.5-350M의 진짜 강점은 어디서나 빠르게 돈다는 점입니다. 효율적인 LFM2 아키텍처 덕분에 CPU에서 비슷한 크기의 SSM 하이브리드(Granite-4.0-H-1B)나 게이트 델타 네트워크(Qwen3.5-0.8B)보다 확연히 빠르며, Cactus Compute의 엔진(int8)으로는 iPhone 13 Mini, Google Pixel 6a, 라즈베리파이 5처럼 300달러 이하의 기기에서도 잘 돕니다. GPU에서는 vLLM이나 SGLang으로 대규모 처리가 가능한데, 단일 NVIDIA H100에서 초당 4만 토큰이 넘는 출력 처리량(하루로 환산하면 35억 토큰 이상)을 달성합니다.
출시 첫날부터 LEAP, llama.cpp, MLX, vLLM, SGLang, ONNX, OpenVINO 등 주요 추론 엔진을 지원하며, Hugging Face와 Playground에서 바로 써볼 수 있습니다.

하드웨어 파트너 생태계도 함께 넓어졌습니다. AMD의 Ryzen AI, Qualcomm Technologies의 Hexagon NPU(Zetic, RunAnywhere 협력), Intel의 OpenVINO, Apple Silicon(Mirai 엔진), 그리고 LM Studio가 첫날 지원에 합류했습니다. 커스터마이징 파트너인 Distil Labs는 스마트홈, 뱅킹, 터미널 등 실제 다중턴(multi-turn) 에이전트 워크플로우에 맞춰 LFM2.5를 미세조정해 도구 호출 정확도를 95% 이상으로 끌어올렸다고 합니다.
LFM2.5 Retrievers: 검색을 위한 첫 양방향 LFM
이제 이 글의 두 번째 주인공인 검색 모델로 넘어갑니다. LFM2.5 Retrievers는 위에서 설명한 LFM2.5-350M-Base 위에 올린 두 개의 다국어 검색 모델로, LFM 제품군 최초의 양방향(bidirectional) 멤버입니다. 제품 카탈로그, FAQ 지식베이스, 고객 지원 문서처럼 짧은 컨텍스트를 빠르고 저렴하게, 그리고 언어를 넘나들며 검색해야 하는 상황을 겨냥했으며, 기존 RAG 파이프라인의 드롭인 교체(drop-in replacement) 로 쓸 수 있습니다.
검색 모델이 왜 필요한지부터 짚어 보겠습니다. RAG(검색 증강 생성, Retrieval-Augmented Generation)이나 시맨틱 검색에서는 질의(query)와 문서(document)를 벡터로 바꿔 의미적으로 가까운 것을 찾습니다. 이때 임베딩 품질이 곧 검색 품질을 좌우하는데, 다국어와 언어 간(cross-lingual) 검색까지 잘 되면서도 엣지에서 돌 만큼 가벼운 모델은 드물었습니다. LFM2.5 Retrievers는 바로 이 빈자리를 노립니다.
디코더를 인코더로: 양방향 패치
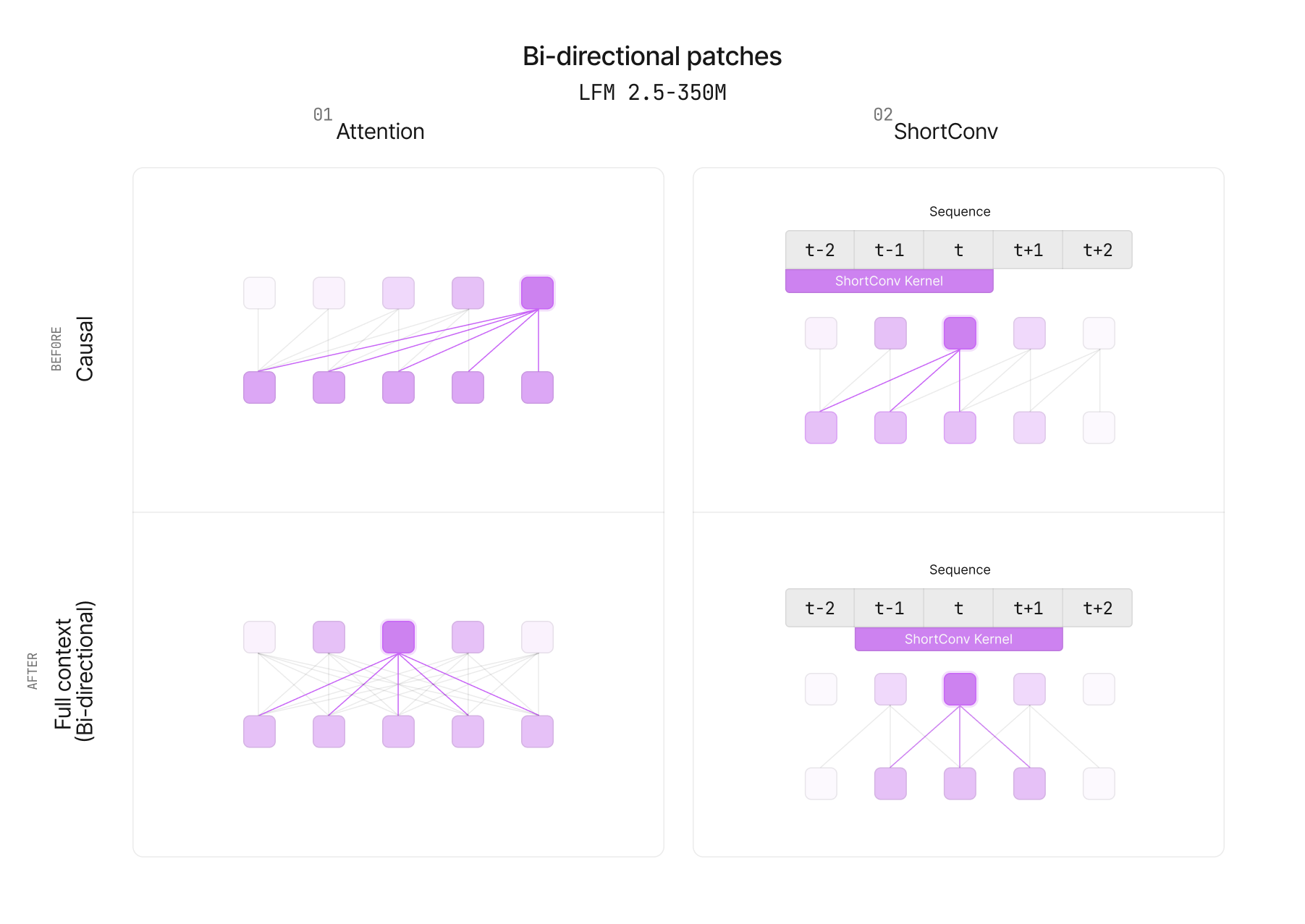
여기서 한 가지 구조적 전환이 일어납니다. 앞서 본 LFM2.5-350M은 글을 왼쪽에서 오른쪽으로 생성하는 인과적 디코더(causal decoder) 입니다. 즉 각 토큰은 자기 자신과 이전 토큰만 볼 수 있습니다. 이는 텍스트 생성에는 자연스럽지만, 문서 전체의 의미를 한 번에 파악해야 하는 검색에는 부자연스럽습니다.
Liquid AI는 LFM2 아키텍처에 작은 양방향 패치(bidirectional patches) 를 적용해 인과적 디코더를 양방향 인코더로 바꿨습니다. 구체적으로는 (1) 인과적 어텐션 마스크를 양방향 마스크로 교체해 모든 토큰이 좌우 문맥을 모두 볼 수 있게 하고, (2) LFM2의 단거리 합성곱을 비인과적(non-causal)으로 만들어 각 토큰 주변의 지역 정보를 과거뿐 아니라 양쪽에서 대칭적으로 섞도록 했습니다. 이렇게 하면 LFM2 백본의 효율은 유지하면서도 검색에 필요한 전체 문맥 표현을 얻을 수 있습니다.
임베딩(bi-encoder)과 ColBERT(late interaction)의 차이
같은 양방향 인코더를 공유하지만, 두 모델은 텍스트를 표현하는 방식이 다릅니다. 이 차이가 곧 두 모델의 성격을 가릅니다.
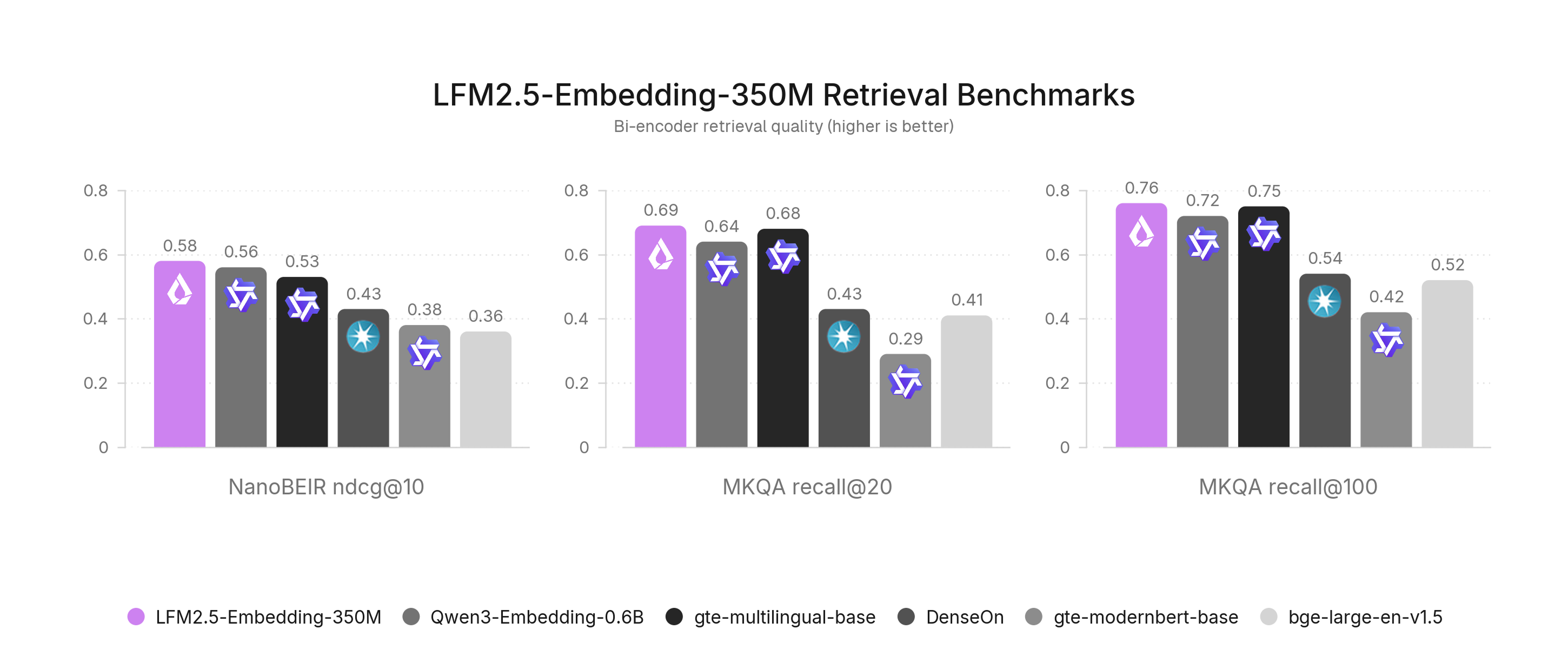
LFM2.5-Embedding-350M 은 밀집 바이인코더(dense bi-encoder) 입니다. 문서 하나를 CLS 풀링으로 단 하나의 1024차원 벡터로 압축하고, 질의 벡터와 코사인 유사도로 비교합니다. 인덱스가 가장 작고 검색이 가장 빨라, 속도와 저장 비용이 중요할 때 적합합니다.
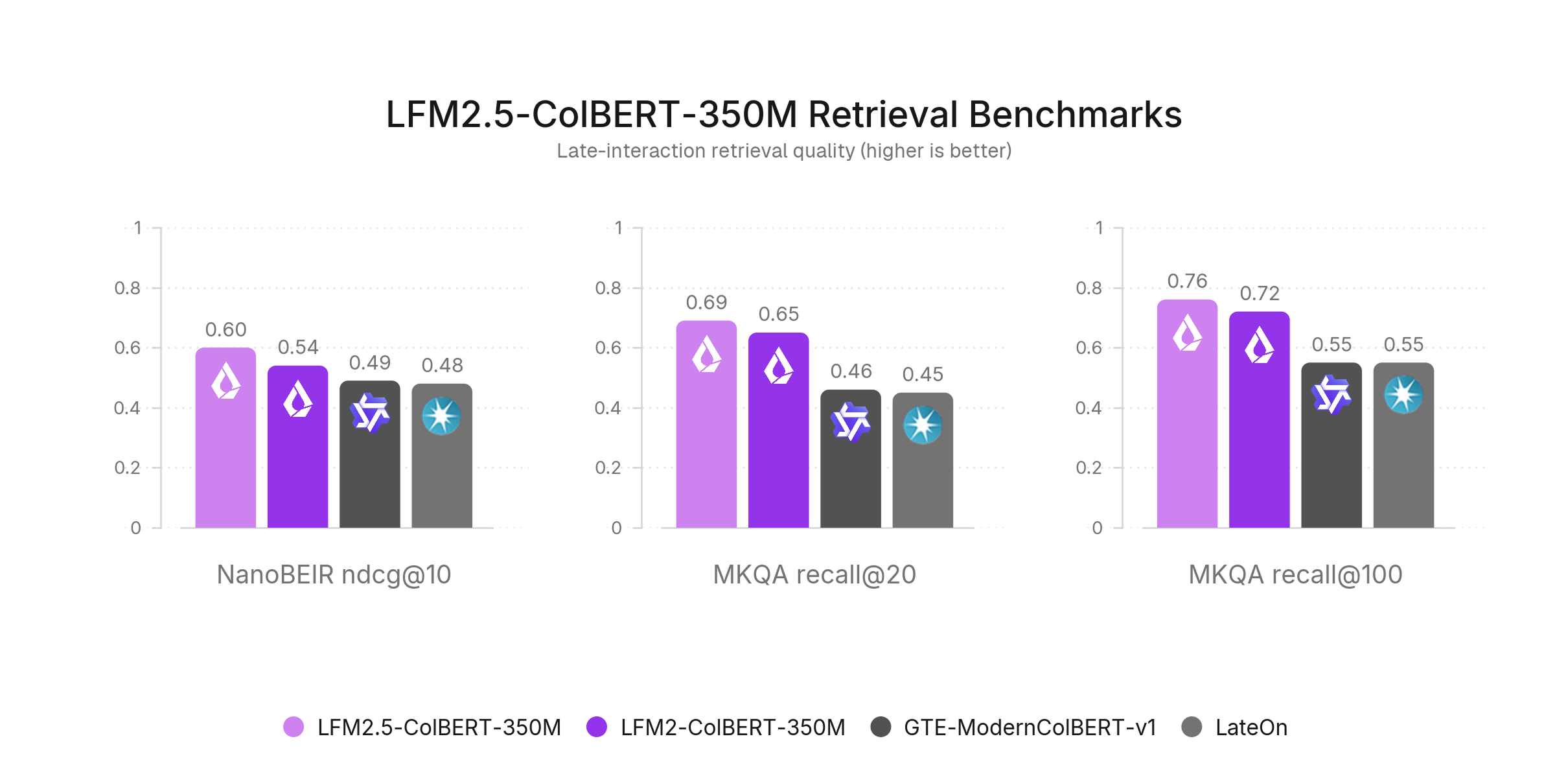
LFM2.5-ColBERT-350M 은 레이트 인터랙션(late interaction) 모델입니다. 문서를 하나의 벡터가 아니라 토큰마다 128차원 벡터로 표현하고, 질의의 각 토큰이 문서의 토큰들과 가장 잘 맞는 짝을 찾아 그 유사도를 합산하는 MaxSim 연산으로 점수를 매깁니다. 단어 단위로 정밀하게 매칭하므로 정확도와 일반화가 더 좋지만, 토큰 수만큼 벡터를 저장해야 하므로 인덱스가 커집니다. 저장 공간보다 정확도가 중요할 때 고르면 됩니다.
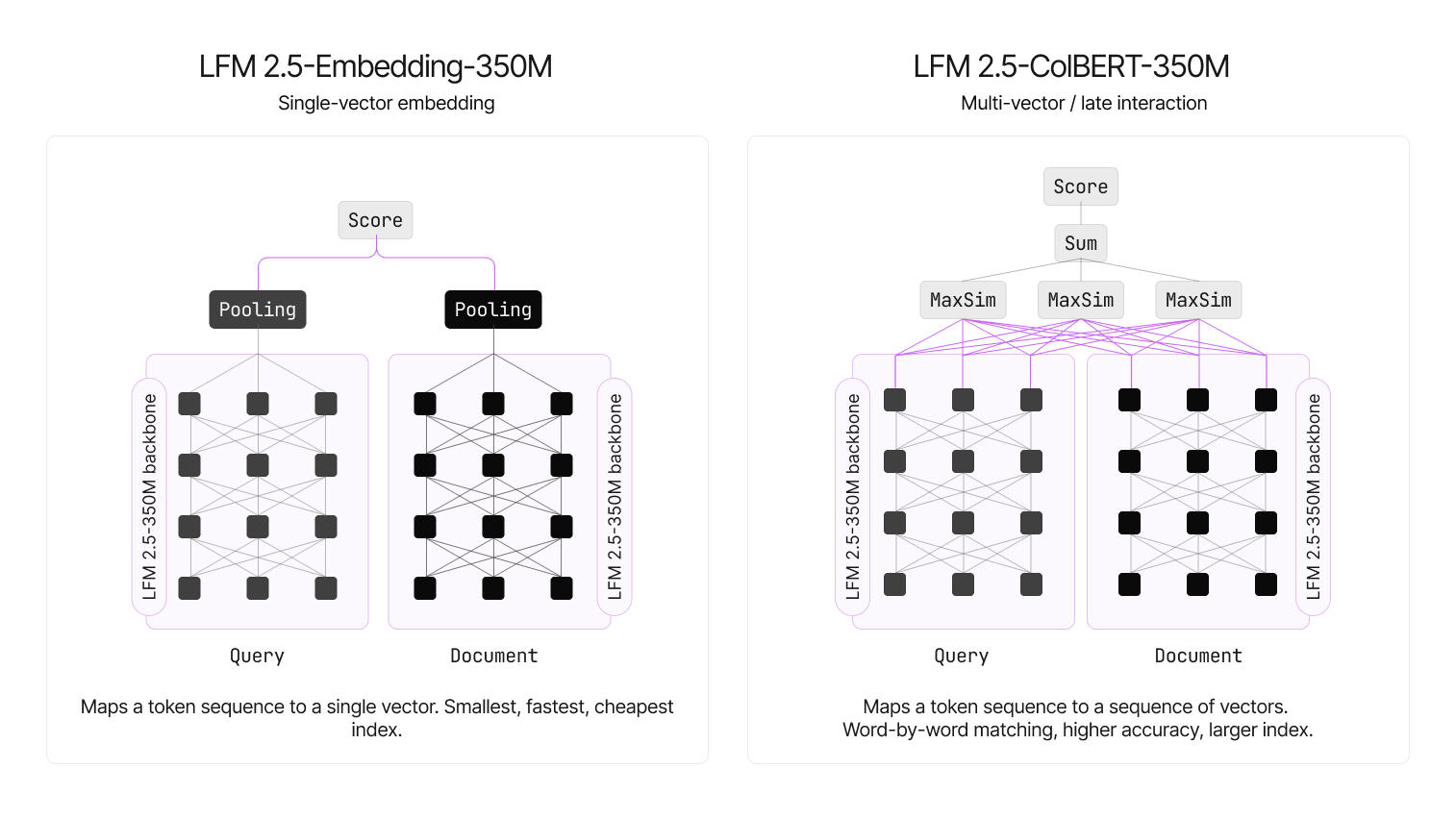
두 모델의 사양을 정리하면 다음과 같습니다.
| 특징 | LFM2.5-Embedding-350M | LFM2.5-ColBERT-350M |
|---|---|---|
| 유형 | 밀집 바이인코더 (문서당 1벡터) | 레이트 인터랙션 (토큰당 1벡터) |
| 파라미터 | 약 354M | 약 353M |
| 백본 | LFM2.5-350M-Base + 양방향 패치 | LFM2.5-350M-Base + 양방향 패치 |
| 층 구성 | 17층 (합성곱 10 + 어텐션 6 + 풀링 1) | 17층 (합성곱 10 + 어텐션 6 + Dense 1) |
| 컨텍스트 | 32,768 토큰 (문서 512) | 32,768 토큰 (문서 512, 질의 32) |
| 출력 | 1024차원 CLS 벡터 | 토큰당 128차원 |
| 유사도 | 코사인(Cosine) | MaxSim |
| 라이선스 | LFM Open License v1.0 | LFM Open License v1.0 |
지원 언어는 영어, 스페인어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 아랍어, 스웨덴어, 노르웨이어, 일본어, 한국어 총 11개입니다.
3단계 학습 레시피
두 모델은 동일한 3단계 레시피로 학습되었습니다. (1) 영어 대규모 대조 학습(contrastive pretraining)으로 검색의 기본기를 다지고, (2) 강력한 교사 모델로부터 11개 언어 전체에 대한 다국어·언어 간 증류(distillation)를 수행하며, (3) 어렵게 채굴한 부정 예제(hard-mined negatives)로 최종 미세조정합니다. 이 단계 구조는 LightOn의 LateOn과 DenseOn 릴리스에서도 영감을 받았습니다. 흥미롭게도 언어 간 검색은 레이트 인터랙션 구조에서 더 자연스럽게 발현되기 때문에, Embedding 모델이 ColBERT보다 언어 간 데이터를 조금 더 받습니다. 학습 데이터는 내부 큐레이션 데이터와 오픈소스 영어 검색 데이터셋을 결합하고, LLM 기반 번역으로 다국어·언어 간 쌍을 확장해 만들었습니다.
11개 언어 전반의 검색 성능
평가는 두 축으로 이뤄집니다. 언어 내 다국어 검색은 NanoBEIR Multilingual Extended로, 언어 간 오픈도메인 QA는 MKQA-11로 측정합니다. 두 벤치마크 모두에서 LFM2.5 Embedding과 ColBERT는 동급 최고 수준의 성능을 보였습니다.
NanoBEIR Multilingual Extended (NDCG@10, 11개 언어 평균):
| 모델 | 유형 | 평균 | 한국어(ko) |
|---|---|---|---|
| LFM2.5-ColBERT-350M | late | 0.605 | 0.590 |
| LFM2.5-Embedding-350M | dense | 0.577 | 0.563 |
| Qwen3-Embedding-0.6B | dense | 0.556 | 0.530 |
| LFM2-ColBERT-350M | late | 0.540 | 0.527 |
| gte-multilingual-base | dense | 0.528 | 0.494 |
MKQA-11 (Recall@20, 언어 간 검색):
| 모델 | 유형 | 평균 | 한국어(ko) |
|---|---|---|---|
| LFM2.5-ColBERT-350M | late | 0.694 | 0.640 |
| LFM2.5-Embedding-350M | dense | 0.691 | 0.630 |
| gte-multilingual-base | dense | 0.675 | 0.563 |
| LFM2-ColBERT-350M | late | 0.646 | 0.558 |
| Qwen3-Embedding-0.6B | dense | 0.638 | 0.543 |
두 모델 모두 영어에 치우치지 않고 11개 언어 전반에서 고르게 경쟁력 있는 점수를 유지한다는 점이 인상적입니다. 참고로 Liquid AI는 전체 BEIR와 NanoBEIR 영어 점수가 매우 높은 상관(거의 일정하게 약 15% 차이)을 보여, 학습 반복 시 NanoBEIR를 전체 BEIR의 실용적 대리 지표로 사용했다고 밝혔습니다.
밀리초 단위의 추론 속도
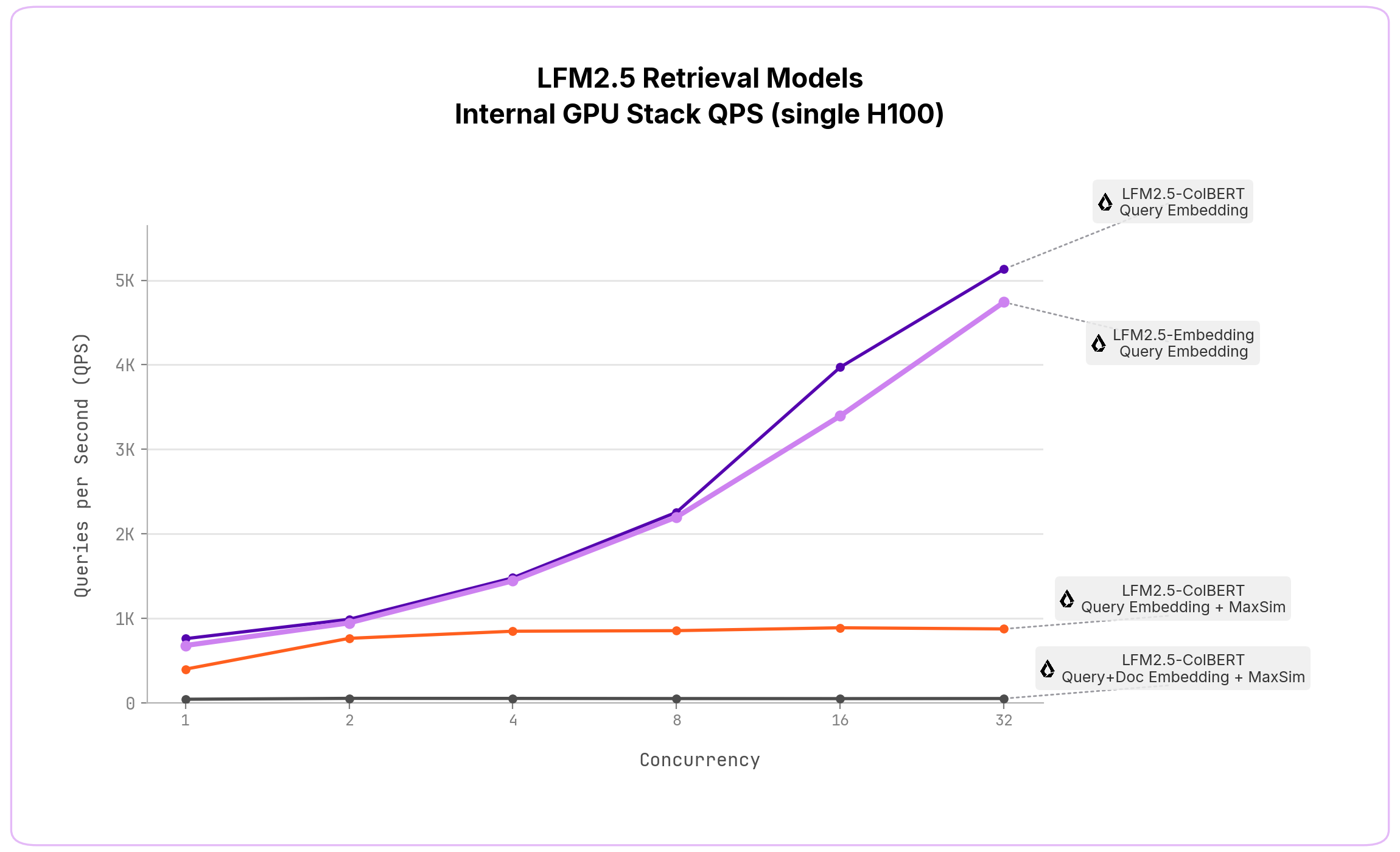
검색은 사용자 경험에서 지연 시간이 곧 생명입니다. LFM2.5 Retrievers는 llama.cpp로 MacBook M4 Max에서 문서가 캐시된 경우 질의 임베딩을 p50 기준 7~8ms에 처리하며, 이동성을 위해 LFM2.5-ColBERT-350M-GGUF와 LFM2.5-Embedding-350M-GGUF도 함께 공개되어 CPU, 노트북, 엣지 기기에서 거의 무료에 가까운 비용으로 돌릴 수 있습니다. 대규모 엔터프라이즈 배포를 위한 내부 GPU 스택에서는 H100 기준 질의 임베딩을 p50 1.3~1.5ms까지 낮춥니다.
| 모델 | 단계 | p50 (M4 Max) | p50 (H100) |
|---|---|---|---|
| LFM2.5-Embedding-350M | 질의 임베딩 | 7.3 ms | 1.5 ms |
| LFM2.5-ColBERT-350M | 질의 임베딩 | 8.1 ms | 1.3 ms |
| LFM2.5-ColBERT-350M | 질의 임베딩 + MaxSim | 8.2 ms | 2.5 ms |
직접 써보기
LFM2.5-Embedding-350M 은 sentence-transformers로 바로 쓸 수 있습니다. 질의와 문서에 각각 query:, document: 비대칭 프롬프트를 붙여야 하는데, 이는 모델이 그렇게 학습되었기 때문이며 생략하면 검색 품질이 조용히 떨어집니다.
from sentence_transformers import SentenceTransformer
# Load the model (trust_remote_code applies the bidirectional patches)
model = SentenceTransformer(
"LiquidAI/LFM2.5-Embedding-350M",
trust_remote_code=True,
)
queries = ["What is the capital of France?"]
documents = [
"Paris is the capital and largest city of France.",
"Tokyo is the capital of Japan.",
]
# Encode with the matching prompt name; normalize so the dot product == cosine similarity
q_emb = model.encode(queries, prompt_name="query", normalize_embeddings=True)
d_emb = model.encode(documents, prompt_name="document", normalize_embeddings=True)
scores = q_emb @ d_emb.T # shape: (n_queries, n_documents)
LFM2.5-ColBERT-350M 은 PyLate로 인덱싱과 검색을 수행하며, 효율적 유사도 검색을 위해 FastPLAID 인덱스를 사용합니다.
from pylate import indexes, models, retrieve
# Step 1: Load the ColBERT model (trust_remote_code applies the bidirectional patches)
model = models.ColBERT(
model_name_or_path="LiquidAI/LFM2.5-ColBERT-350M",
trust_remote_code=True,
)
model.tokenizer.pad_token = model.tokenizer.eos_token
# Step 2: Initialize the PLAID index
index = indexes.PLAID(index_folder="pylate-index", index_name="index", override=True)
# Step 3: Encode and index the documents
documents_embeddings = model.encode(
["document 1 text", "document 2 text"],
is_query=False, # these are documents, not queries
)
index.add_documents(documents_ids=["1", "2"], documents_embeddings=documents_embeddings)
기존 1차 검색 파이프라인 위에서 재순위화(reranking)만 하고 싶다면 인덱스를 만들지 않고 PyLate의 rank 함수를 쓸 수도 있습니다. 도구 선택(tool selection)에 ColBERT를 활용하는 데모 스페이스도 공개되어 있어, 에이전트가 적절한 도구를 고르는 용도로도 응용할 수 있습니다. 두 모델 모두 자신의 데이터로 미세조정하면 도메인 특화 검색 품질을 더 높일 수 있으며, 특히 Embedding 모델은 표준 sentence-transformers 학습 루프가 그대로 동작합니다.
보너스: 효율적 아키텍처를 향한 Liquid의 연구, Grafting
LFM이 "하드웨어 제약 아래에서 효율적인 구조를 찾는다"는 철학을 가진다는 점은, Liquid AI의 또 다른 연구 Grafting에서도 드러납니다. 스탠퍼드, Together AI, UC 샌디에이고, 노스웨스턴, Google DeepMind, Salesforce Research와 협력한 이 연구는, 새 아키텍처를 처음부터 학습하는 막대한 비용 대신 사전학습된 모델을 발판 삼아 구조를 편집 하자는 발상입니다.

대상은 이미지·영상 생성에 널리 쓰이는 디퓨전 트랜스포머(Diffusion Transformer, DiT)입니다. 그래프팅은 (1) 원래 연산자의 기능을 새 연산자로 옮기는 활성값 증류(activation distillation)와 (2) 여러 연산자를 교체할 때 누적되는 오차를 줄이는 경량 미세조정의 두 단계로 작동합니다. 이를 통해 멀티헤드 어텐션(MHA)이나 MLP를 합성곱·선형 어텐션 같은 다른 연산자로 교체하면서도 품질을 보전합니다. 실제로 DiT-XL/2에서 원본의 2% 미만 학습 연산량(8×H100에서 24시간 이내)으로 FID 2.38~2.64의 하이브리드 구조를 얻었고, 2048×2048 해상도 PixArt-Σ에서는 1.43배 빠른 모델을 GenEval 점수 2% 미만 손실로 만들었으며, 트랜스포머 블록을 병렬화해 깊이를 28층에서 14층으로 절반으로 줄이는 구조 개편까지 성공했습니다. 거대 모델 시대에 아키텍처 탐색의 문턱을 낮추는, LFM의 효율 지향 철학과 같은 결의 연구입니다.
라이선스
LFM2.5-350M과 LFM2.5 Retrievers(Embedding, ColBERT)는 모두 LFM Open License v1.0 으로 공개된 오픈 웨이트(open-weight) 모델입니다. 다운로드, 미세조정, 배포가 가능하며, 정확한 이용 조건은 Hugging Face의 LiquidAI 조직 페이지에서 각 모델 카드의 라이선스 항목을 확인하시기 바랍니다.
 LFM2.5 Retrievers 소개 블로그
LFM2.5 Retrievers 소개 블로그
LFM2.5-350M 소개 블로그
LFM2 기술 보고서 (arXiv)
 LFM2.5 Retrievers 모델
LFM2.5 Retrievers 모델
더 읽어보기
-
Perplexity, 웹 스케일 검색을 위한, 양방향 디퓨전 어텐션을 적용한 다국어 임베딩 모델 pplx-embed 2종 공개
-
Cactus: 스마트폰, 웨어러블 기기 등에서의 On-Device AI를 위한 고성능 추론 엔진 및 커널 라이브러리
-
Hugging Face, 최대 400배 빠른 CPU 기반 정적 임베딩(Static Embedding) 모델 공개 (feat. Sentence Transformers)
-
Embedding Explorer: 로컬 데이터를 사용하여 여러가지 임베딩 모델들을 평가하고 비교하는 오픈소스
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()