
PersonaPlex 소개
실시간 음성 대화 AI는 최근 빠르게 발전하고 있지만, 기존 시스템들은 대부분 대화 참여자 한 쪽이 말하는 동안 상대방이 기다려야 하는 반이중(half-duplex) 방식으로 동작합니다. 사람과 사람 간의 자연스러운 대화에서는 서로가 동시에 말하거나 반응할 수 있는 전이중(full-duplex) 방식이 기본인데, 이를 AI로 구현하는 것은 지연 시간, 화자 분리, 맥락 유지 등 여러 기술적 도전이 동반됩니다. NVIDIA Research의 ADLR(Applied Deep Learning Research) 팀은 이 문제에 정면으로 도전하여, 낮은 지연 시간으로 실시간 양방향 음성 대화를 지원하는 PersonaPlex를 개발하고 오픈소스로 공개하였습니다.
PersonaPlex는 Moshi 아키텍처를 기반으로 하는 7B 파라미터 규모의 음성 대화(Speech-to-Speech) 모델입니다. Moshi는 풀-듀플렉스 음성 대화를 위해 설계된 파운데이션 모델로, PersonaPlex는 여기에 Helium LLM 백본(backbone)을 결합하여 캐릭터 일관성과 다양한 페르소나 제어 기능을 추가합니다. 특히 텍스트 기반 역할 프롬프트(role prompt)와 오디오 기반 음성 컨디셔닝(voice conditioning)을 동시에 활용하여, 같은 모델이 교사, 고객 서비스 담당자, 캐주얼한 대화 상대 등 다양한 역할을 자연스럽게 수행할 수 있습니다. 이 연구는 2026년 arXiv에 게재되었으며(arXiv:2602.06053), GitHub에 공개된 이후 7,800개 이상의 스타를 받으며 주목받고 있습니다.
PersonaPlex는 합성 대화(synthetic conversations)와 Fisher English Corpus의 실제 대화 데이터를 혼합하여 학습되었습니다. 합성 데이터는 고정된 어시스턴트 역할과 다양한 고객 서비스 시나리오를 포함하며, 실제 대화 데이터는 LLM이 자동으로 레이블링한 프롬프트와 함께 사용됩니다. 이러한 훈련 전략을 통해 모델은 학습 분포를 벗어난 새로운 역할과 주제에도 어느 정도 유연하게 대응할 수 있는 일반화 능력을 갖추게 됩니다.
PersonaPlex의 기존 음성 AI와 비교
| 특징 | PersonaPlex | 전통적 파이프라인(STT+LLM+TTS) | Moshi (원본) |
|---|---|---|---|
| 통신 방식 | 풀-듀플렉스 (실시간 양방향) | 반이중 (순차 처리) | 풀-듀플렉스 |
| 지연 시간 | 저지연 | 높음 (파이프라인 누적) | 저지연 |
| 페르소나 제어 | 텍스트 + 음성 컨디셔닝 | 텍스트 프롬프트만 | 제한적 |
| 음성 선택 | 16개 사전 제공 음성 | TTS 엔진 의존 | 제한적 |
| 파라미터 수 | 7B | 분리된 여러 모델 | 7B |
| 오픈소스 | 다양 |
기존의 STT(Speech-to-Text) → LLM 추론 → TTS(Text-to-Speech)로 이어지는 파이프라인 방식은 각 단계에서 지연이 누적되어 자연스러운 실시간 대화가 어렵습니다. PersonaPlex는 이 세 단계를 단일 End-to-End 모델로 통합하여 지연을 최소화하며, 동시에 사용자가 말하는 동안에도 모델이 반응할 수 있는 진정한 풀-듀플렉스 경험을 제공합니다.
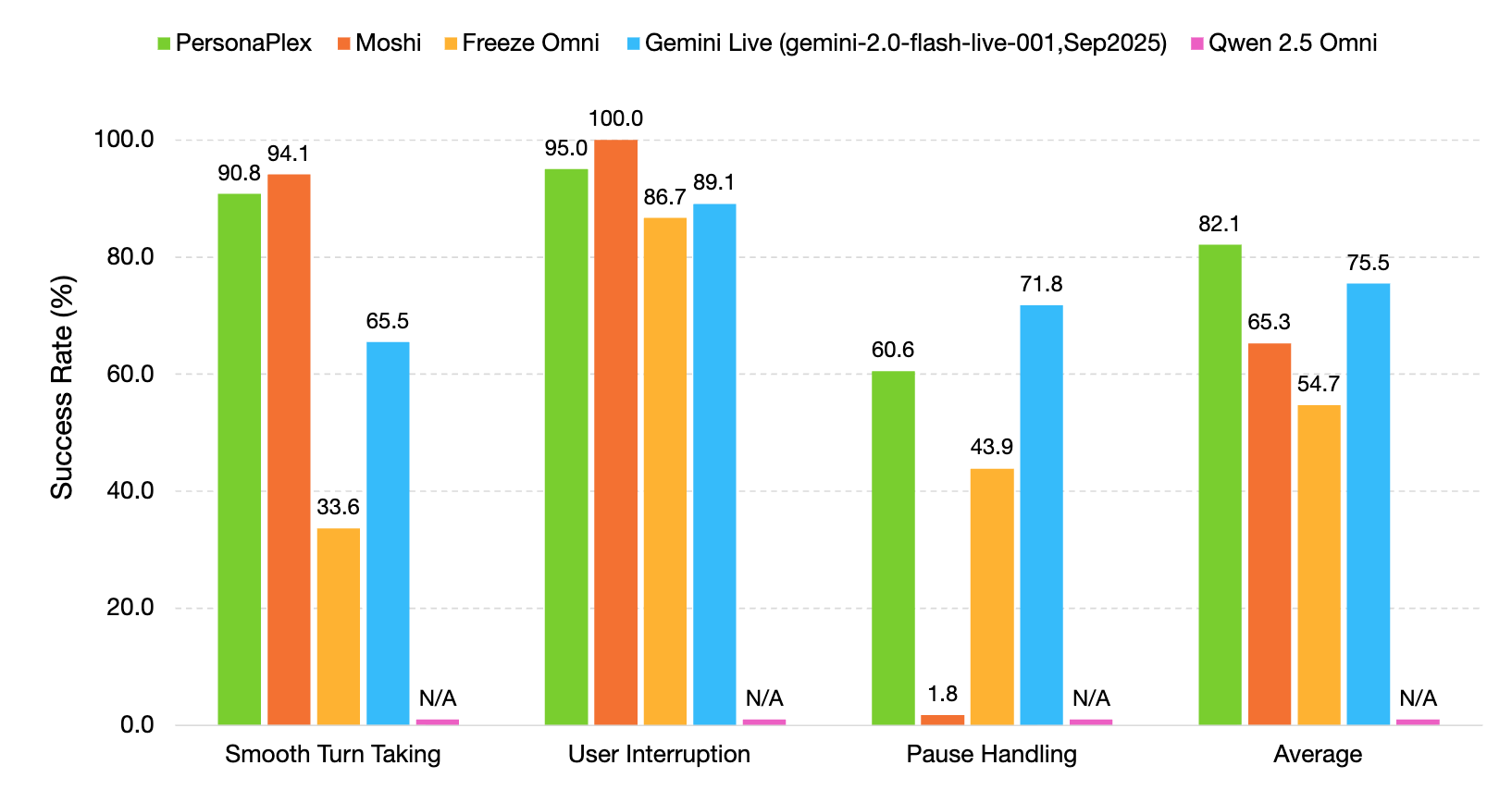
PersonaPlex의 주요 특징
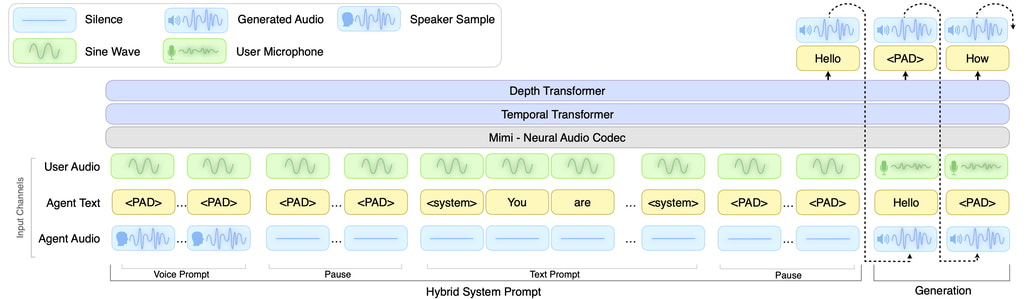
텍스트 기반 페르소나 제어: 텍스트 역할 프롬프트를 통해 모델의 성격과 역할을 동적으로 설정할 수 있습니다. "당신은 현명하고 친근한 교사입니다. 명확하고 흥미로운 방식으로 질문에 답하거나 조언을 제공하세요."와 같은 프롬프트를 통해 어시스턴트의 행동 방식을 세밀하게 조정할 수 있으며, 고객 서비스, 캐주얼 대화, 특정 주제 전문가 등 다양한 시나리오에 맞게 역할을 바꿀 수 있습니다.
오디오 기반 음성 컨디셔닝: 16개의 사전 제공 음성 임베딩(NATF0~3, NATM0~3, VARF0~4, VARM0~4)을 통해 음성의 특성을 선택할 수 있습니다. 자연스러운(Natural) 카테고리와 다양한(Variety) 카테고리로 나뉘며, 각각 남성/여성 음성을 포함합니다. 음성 임베딩과 텍스트 프롬프트를 조합하면 같은 페르소나를 다른 음성으로 표현하거나 다른 페르소나를 같은 음성으로 제어하는 등 세밀한 조합이 가능합니다.
CPU 오프로딩: GPU 메모리가 제한적인 환경을 위해 모델 레이어를 GPU와 CPU에 분산하는 CPU 오프로드(CPU offload) 모드를 지원합니다. accelerate 패키지를 추가 설치하면 --cpu-offload 플래그만으로 활성화할 수 있어, 소비자 GPU 환경에서도 PersonaPlex를 실행할 수 있습니다.
오프라인 평가 모드: 실시간 서버 없이 사전 녹음된 WAV 파일을 입력으로 받아 출력 음성을 생성하는 오프라인 평가 모드도 제공됩니다. 이를 통해 다양한 프롬프트와 음성 조합을 실험하거나 재현 가능한 벤치마크를 수행할 수 있습니다.
PersonaPlex 설치 및 사용법
사전 요구사항
Opus 오디오 코덱 라이브러리를 먼저 설치해야 합니다:
# Ubuntu/Debian
sudo apt-get install libopus-dev
# Fedora/RHEL
sudo dnf install opus-devel
설치
# 저장소 클론
git clone https://github.com/NVIDIA/personaplex.git
cd personaplex
# moshi 패키지 설치
pip install moshi/.
# Blackwell GPU (RTX 50 시리즈 등) 사용 시 CUDA 13.0 빌드 설치
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
# Hugging Face 토큰 설정 (모델 라이선스 수락 후)
export HF_TOKEN=<YOUR_HUGGINGFACE_TOKEN>
Hugging Face에서 nvidia/personaplex-7b-v1 모델의 라이선스를 먼저 수락해야 다운로드가 가능합니다.
실시간 서버 실행
# SSL 인증서 자동 생성 후 서버 시작
SSL_DIR=$(mktemp -d)
python -m moshi.server --ssl "$SSL_DIR"
# CPU 오프로딩 활성화 (메모리 부족 시)
python -m moshi.server --ssl "$SSL_DIR" --cpu-offload
서버가 시작되면 브라우저에서 https://localhost:8998에 접속하여 실시간 음성 대화를 바로 체험할 수 있습니다. 원격 서버에서 실행 중이라면 해당 서버의 IP와 포트로 접근합니다.
오프라인 평가
# 기본 오프라인 평가 (음성 조건만)
HF_TOKEN=<TOKEN> python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "output.wav" \
--output-text "output.json"
# 텍스트 프롬프트 추가 (페르소나 제어)
HF_TOKEN=<TOKEN> python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--text-prompt "You are a wise and friendly teacher." \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "output_teacher.wav" \
--output-text "output_teacher.json"
출력 JSON 파일에는 생성된 텍스트 전사(transcription)가 포함되어, 음성 출력과 함께 텍스트 내용도 확인할 수 있습니다.
라이선스
PersonaPlex의 코드는 MIT 라이선스로 공개되어 있어 자유롭게 사용 및 수정이 가능합니다. 단, 모델 가중치는 NVIDIA Open Model License가 적용되므로 상업적 활용 전에 해당 라이선스 조건을 별도로 확인해야 합니다.
 PersonaPlex 인터랙티브 데모
PersonaPlex 인터랙티브 데모
 PersonaPlex 논문
PersonaPlex 논문
 PersonaPlex 프로젝트 GitHub 저장소
PersonaPlex 프로젝트 GitHub 저장소
 PersonaPlex 모델 다운로드
PersonaPlex 모델 다운로드
더 읽어보기
-
VibeVoice: 60분 장시간 음성 인식(ASR)과 실시간 TTS를 통합한 Microsoft의 오픈소스 음성 AI 모델 패밀리
-
Qwen3-TTS: 500만 시간의 학습 데이터, 12Hz 초저지연 토크나이저로 완성한 오픈소스 Omni-Audio 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()