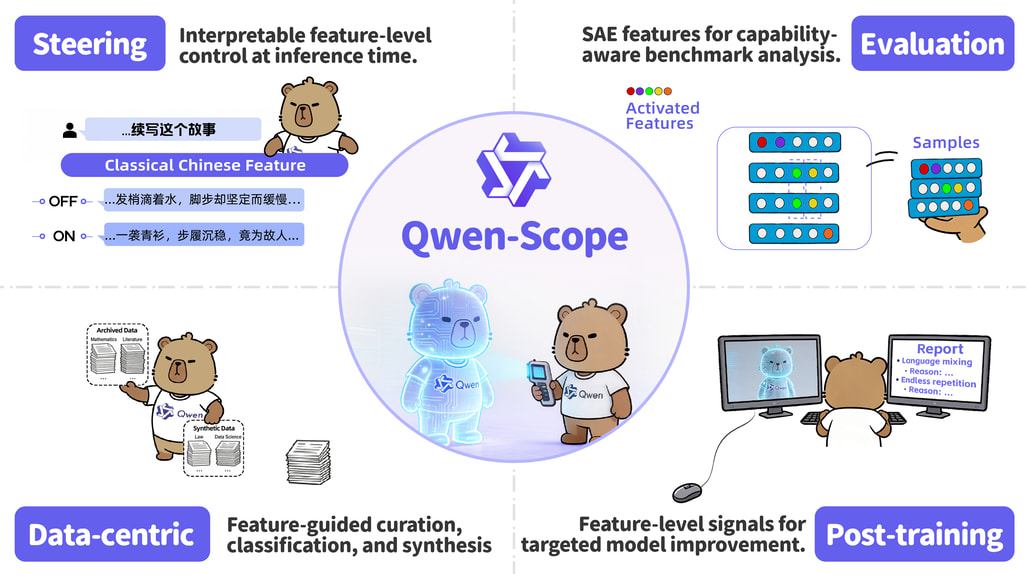
LLM의 "블랙박스"를 열다: Qwen-Scope 소개
대규모 언어 모델(Large Language Model, LLM)은 자연어 이해와 생성, 복잡한 추론, 코딩, 수학 문제 풀기에 이르기까지 다양한 과제에서 뛰어난 성능을 보여주고 있습니다. 그러나 이러한 인상적인 능력 뒤에는 근본적인 불투명성이 존재합니다. 모델이 어떤 내부 과정을 통해 특정 출력을 생성하는지, 왜 특정 언어로 갑자기 전환하는지, 왜 때로는 무한 반복에 빠지는지를 우리는 제대로 이해하지 못하고 있습니다. 이 불투명성은 모델의 신뢰성과 안전성에 대한 우려를 낳고, 체계적인 개선을 어렵게 만듭니다.
이러한 문제를 해결하려는 연구 분야가 바로 기계론적 해석 가능성(Mechanistic Interpretability) 입니다. 이 분야에서 최근 가장 주목받는 도구가 희소 오토인코더(Sparse Autoencoder, SAE) 입니다. SAE는 모델의 내부 활성화 벡터를 희소하고 해석 가능한 특징(feature) 표현으로 분해하는 데 탁월한 성능을 보여주고 있습니다. Anthropic, OpenAI, Google DeepMind 등 주요 AI 연구 기관들이 SAE 연구에 활발히 투자하고 있는 것도 이 때문입니다.
2026년 4월 30일, Qwen 팀은 Qwen3 및 Qwen3.5 모델 패밀리에 대한 오픈소스 SAE 스위트인 Qwen-Scope 를 공개했습니다. Qwen-Scope는 단순히 해석 도구에 그치지 않고, 추론 시 조종, 벤치마크 분석, 데이터 분류 및 합성, 사후 훈련 최적화라는 네 가지 실용적인 응용 방향을 함께 제시합니다. SAE가 사후 분석 도구를 넘어 모델 개발의 재사용 가능한 인터페이스가 될 수 있음을 보여주는 것이 이 연구의 핵심 주장입니다.
기술 보고서는 총 7개 Qwen 모델에 걸쳐 14개 그룹의 SAE 가중치를 공개하고, 각 응용 방향에 대한 세밀한 실험 결과를 포함합니다. HuggingFace 및 ModelScope를 통해 모든 SAE 모델 가중치와 코드를 무료로 이용할 수 있습니다.
Sparse Autoencoder: LLM 내부를 들여다보는 사전(Dictionary)
희소 오토인코더(Sparse Autoencoder, SAE) 는 LLM의 내부 표현을 더 해석 가능한 형태로 분해하기 위한 도구입니다. 일반적인 오토인코더가 재구성 충실도만을 목표로 하는 것과 달리, SAE는 잠재 공간에 희소성 제약을 명시적으로 부여합니다. 이를 통해 각 잠재 차원이 입력의 극히 일부에 대해서만 활성화되도록 학습합니다.
직관적으로 설명하면, SAE는 고차원 은닉 상태를 소수의 더 해석 가능한 방향으로 근사적으로 재구성할 수 있는 대규모 특징 사전을 학습합니다. 하나의 입력이 처리될 때 이 사전의 극소수 항목만 활성화되므로, 어떤 "미세 능력(micro-capability)"이 해당 입력에 관여했는지를 추적할 수 있게 됩니다. 이러한 성질 덕분에 SAE는 조종(Arad et al., 2025), 표적 언러닝(Farrell et al., 2024), 추론 관련 표현 분석(Li et al., 2025) 등 다양한 실용적 응용에 활용되고 있습니다.
그러나 기존 SAE 연구의 주된 흐름은 특징 발견, 검사, 레이블링에 집중하는 사후 분석에 머물러 있었습니다. 발견된 특징이 실제 모델 개발 워크플로와 어떻게 연결되는지는 충분히 탐구되지 않았습니다. Qwen-Scope는 바로 이 공백을 메우고자 합니다. 해석 가능성이 설명을 넘어 LLM을 제어하고, 감사하고, 개선하는 실용적 인터페이스가 되어야 한다는 것이 Qwen-Scope의 핵심 주장입니다.
SAE의 수학적 구조를 간략히 살펴보면, SAE 인코더는 잔차 스트림 활성화 $x \in \mathbb{R}^d$를 받아 과완전 잠재 표현을 생성합니다. Top-k 활성화 규칙에 따라 가장 큰 k개의 잠재 활성화만 남기고 디코더로 재구성합니다. 활성화된 각 특징 방향은 특정 언어, 개념, 행동 패턴과 연관되어 있으며, 이 방향을 더하거나 빼는 것으로 모델 출력을 조종할 수 있습니다.
Sparse Autoencoder 더 알아보기
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning - Anthropic (Transformer Circuits Thread)
Scaling and Evaluating Sparse Autoencoders - Gao et al., OpenAI
Mechanistic Interpretability for AI Safety: A Review - Bereska & Gavves
Qwen-Scope의 구성: 7개 모델, 14개 SAE 그룹
Qwen-Scope는 Qwen3 및 Qwen3.5 시리즈 7개 모델에 대해 총 14개 그룹의 SAE 가중치를 제공합니다. 1.7B 소형 모델부터 35B-A3B 대규모 MoE 모델까지 폭넓은 규모를 커버하여, 모델 크기에 따른 내부 표현의 변화를 연구할 수 있습니다. 밀집(dense) 아키텍처와 전문가 혼합(Mixture-of-Experts, MoE) 아키텍처를 모두 포함하는 통합 학습 파이프라인으로 구성됩니다.
| 아키텍처 | 모델 | 레이어 수 | 은닉 크기 | SAE 폭 | Top-k |
|---|---|---|---|---|---|
| Dense | Qwen3-1.7B | 28 | 2048 | 32K | 50, 100 |
| Dense | Qwen3-8B | 36 | 4096 | 64K | 50, 100 |
| Dense | Qwen3.5-2B | 24 | 2048 | 32K | 50, 100 |
| Dense | Qwen3.5-9B | 32 | 4096 | 64K | 50, 100 |
| Dense | Qwen3.5-27B | 64 | 5120 | 80K | 50, 100 |
| MoE | Qwen3-30B-A3B | 48 | 2048 | 32K/128K | 50/100 |
| MoE | Qwen3.5-35B-A3B | 40 | 2048 | 32K/128K | 50/100 |
각 모델의 모든 트랜스포머 레이어에 대해 레이어별 SAE를 학습합니다. SAE 인코더는 각 잔차 스트림 활성화를 과완전(overcomplete) 잠재 표현으로 변환하고, Top-k 활성화 규칙에 따라 상위 k개의 잠재 활성화만 재구성에 사용합니다. 모든 SAE는 모델 사전 학습과 동일한 분포의 데이터로 학습됩니다.
MoE 모델의 경우, 더 세밀한 표현 구조를 포착하기 위해 은닉 크기의 최대 64배에 달하는 더 넓은 SAE도 함께 제공합니다. 또한 죽은 특징(dead feature)을 줄이기 위한 보조 손실 \frac{1}{32} 가중치를 적용하고(Gao et al., 2024), 훈련 안정성을 위해 비정상적으로 큰 L2 놈을 가진 활성화를 필터링하는 방식(Marks et al., 2024)을 채택합니다.
Qwen-Scope가 이 SAE 컬렉션으로 제시하는 4가지 응용 방향을 요약하면 다음과 같습니다:
| 응용 방향 | 활용 방법 | 핵심 성과 |
|---|---|---|
| 추론 시 조종 | 파라미터 수정 없이 언어, 개념, 스타일 제어 | 중국어 특징 억제로 코드 전환 즉시 해결 |
| 평가 분석 | 벤치마크 중복성 및 유사성의 모델-무관 추정 | 17개 벤치마크에서 ρ≈0.85 성능 상관 |
| 데이터 워크플로 | 다국어 독성 분류 및 안전 데이터 합성 | F1>0.90 독성 분류, 99.74% 안전 특징 커버리지 |
| 사후 훈련 | SFT 보조 손실 및 RL 희귀 부정 샘플 생성 | 코드 전환 50%+ 감소, 반복 생성 조기 억제 |
응용 1: 추론 시 조종으로 언어와 스타일을 제어하다
추론 시 조종(Inference-Time Steering) 은 SAE의 가장 널리 활용되는 응용입니다. 고수준 개념, 기술, 행동이 모델 내부 표현 공간의 방향으로 인코딩된다는 가설에 기반합니다. 이 방향을 따라 은닉 상태에 개입하면 모델 파라미터를 수정하지 않고도 출력을 원하는 방향으로 유도할 수 있습니다. 이는 프롬프트 엔지니어링이나 파인튜닝과는 근본적으로 다른 방식으로, 모델의 내부 연산 자체에 직접 개입한다는 점에서 연구자들의 주목을 받고 있습니다.
조종은 다음 간단한 수식으로 표현됩니다:
여기서 $h$는 원래 은닉 상태, $d$는 SAE 특징 방향, $\alpha$는 개입의 강도를 조절합니다. $\alpha > 0$이면 특징을 증폭하고, $\alpha < 0$이면 억제합니다. 수정된 $h'$로 이후 순전파가 계속 진행되므로, 생성된 토큰에 영향이 반영됩니다.
Qwen-Scope는 조종을 위한 2단계 파이프라인을 제공합니다. 먼저 대조적 특징 식별(Contrastive Feature Identification) 단계에서 목표 속성을 강하게 보이는 긍정 예시 집합과 그렇지 않은 부정 예시 집합의 SAE 활성화를 비교하여 가장 판별력 있는 특징 방향을 찾습니다. 그런 다음 식별된 특징 방향을 잔차 스트림에 주입하여 조종합니다.
또 다른 방법인 자동 해석 방법(Automatic Interpretation) 은 특징 자체로부터 출발합니다. 각 특징에 대해 강하게 활성화되는 텍스트 맥락을 수집하고, 더 강력한 언어 모델에 이 예시들을 제공하여 특징이 나타내는 공통 패턴을 짧은 자연어 설명으로 요약하도록 합니다. 이를 통해 매우 많은 수의 SAE 특징을 대규모로 해석하고 조직화할 수 있으며(Paulo et al., 2025), QwenScope 대화형 탐색 데모에서 이 설명들을 직접 검색하고 탐색할 수 있습니다.
사례 1: 오류 진단과 수정. 영어 프롬프트에 중국어가 뒤섞여 생성되는 문제가 발생했을 때, SAE 특징 활성화 강도를 순위화하면 고도로 활성화된 중국어 특징(id: 6159)을 발견할 수 있습니다. 이 특징을 추론 시 억제하면 의도하지 않은 언어 혼재를 제거하면서 영어 응답을 복원합니다. SAE 특징이 오류의 원인을 추적하고 수정하는 진단 도구로 기능한 것입니다.
사례 2: 문체 전환. 현대 중국어로 이야기를 계속 쓰는 과제에서 고전 한문 특징(id: 36398)을 활성화하면 모델이 프롬프트의 의미 방향을 유지하면서 고전 문학 스타일로 이야기를 이어나갑니다. 단순한 오류 억제를 넘어, 원하는 스타일로의 능동적 생성 조종이 가능함을 보여줍니다.
두 사례 모두 개입이 잔차 스트림의 특징 방향에 직접 작용하므로, 모델 가중치를 업데이트하지 않고도 생성 행동을 수정할 수 있다는 공통점이 있습니다. 이는 프롬프트 수준에서 접근하는 방식과 달리, 모델 내부 계산 자체를 조종한다는 점에서 근본적으로 다른 제어 메커니즘입니다.
추론 시 조종 더 알아보기
Refusal in Language Models is Mediated by a Single Direction - Arditi et al. (NeurIPS 2024)
SAEs Are Good for Steering – If You Select the Right Features - Arad et al. (EMNLP 2025)
응용 2: 벤치마크 중복성을 특징으로 진단하다
LLM 평가 벤치마크가 급격히 증가하면서 두 가지 실용적인 문제가 대두됩니다. 첫째, N개의 샘플로 구성된 벤치마크에서 전체 데이터셋과 동일한 모델 순위를 유지하는 최소 부분집합의 크기는 얼마인가? 둘째, 두 벤치마크가 동일한 능력을 평가하는지 아니면 실제로 다른 능력을 평가하는지를 모델 평가 없이 알 수 있는가?
Qwen-Scope의 핵심 통찰은 SAE가 이 문제에 대한 자연스러운 대안을 제공한다는 것입니다. 모델이 벤치마크 샘플을 처리할 때, SAE는 결과 활성화를 희소한 활성 특징 집합으로 분해합니다. 이 특징 집합은 해당 벤치마크가 무엇을 평가하는지에 대한 압축된 지문(fingerprint)이 됩니다. 많은 샘플이 동일한 특징을 활성화한다면 그 벤치마크는 중복적이고, 두 벤치마크가 크게 겹치는 특징 집합을 활성화한다면 유사한 능력을 평가한다고 볼 수 있습니다.
특징 기반 중복성 지표(Feature Redundancy Metric) $\hat{R}(D)$는 특징 커버리지 포화 속도와 특징 성장률의 역수를 곱한 값으로 정의됩니다:
Qwen 팀은 다양한 분야의 17개 주요 벤치마크에 이 방법을 적용했습니다. 분석 대상 벤치마크는 다음과 같습니다.
- 일반 지식: MMLU, MMLU-Redux, MMLU-Pro, SuperGPQA, C-Eval, CMMLU
- 수학: GSM8K, MATH, GPQA-Diamond, TheoremQA
- 코딩: MBPP, EvalPlus, MultiPL-E
- 다국어: MMMLU, INCLUDE
- 인컨텍스트 추론: KOR-Bench, ICLEval
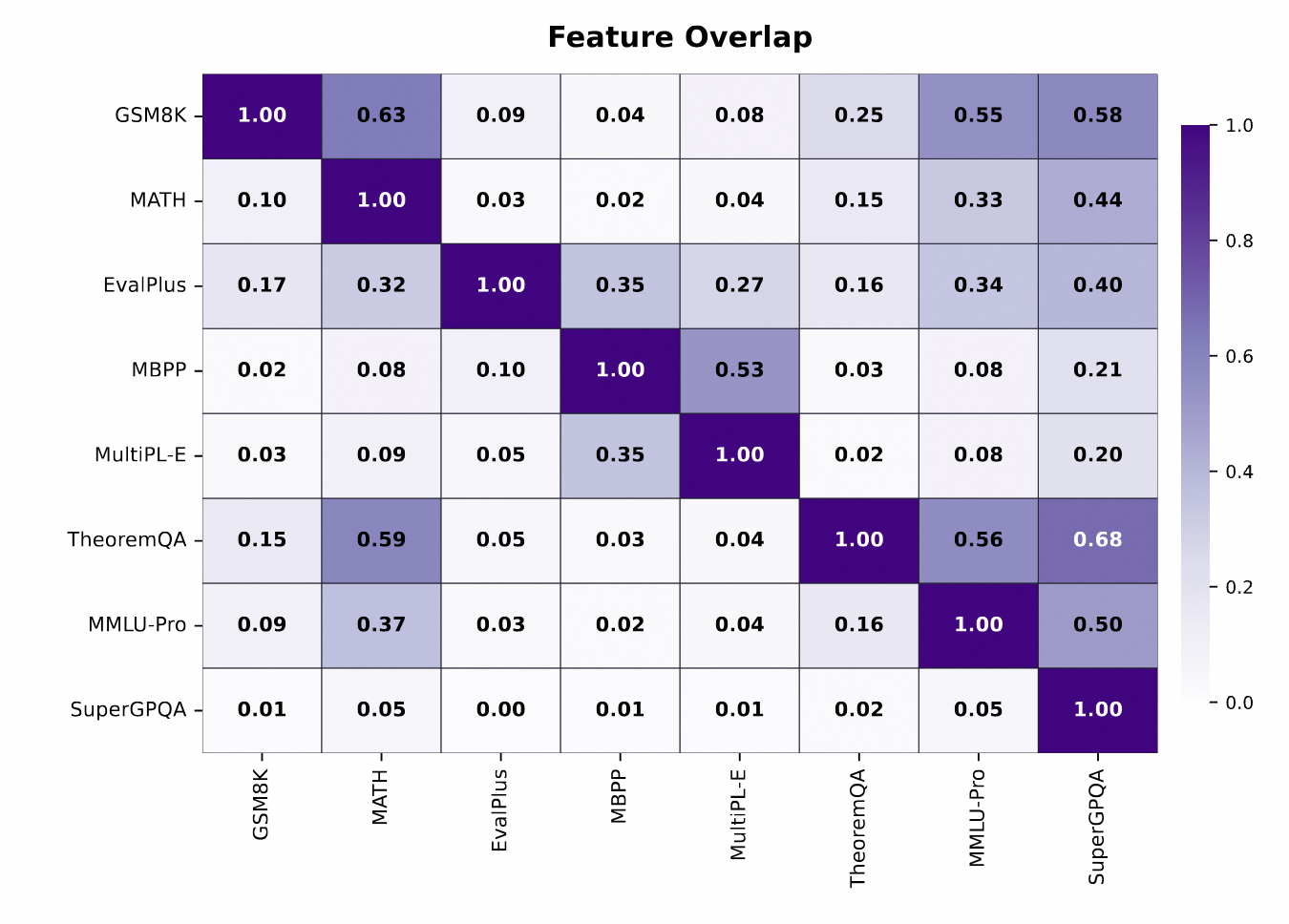
특징 기반 중복성 지표는 성능 기반 중복성과 스피어만 상관계수 ρ ≈ 0.85를 달성했습니다. 이는 모델 평가 없이도 벤치마크 중복성을 추정할 수 있음을 의미합니다.
벤치마크 간 유사성 분석 결과도 흥미롭습니다. GSM8K 특징의 63%가 MATH에 이미 포함되어 있는 반면, MATH의 GSM8K 포함 비율은 10%에 불과합니다. 즉, MATH를 포함하는 평가 스위트에서는 GSM8K를 제거해도 판별 정보 손실이 적습니다. 코딩 벤치마크인 EvalPlus, MBPP, MultiPL-E는 강한 특징 클러스터를 형성하며, 지식 벤치마크인 MMLU-Pro, SuperGPQA는 TheoremQA 같은 특수 벤치마크의 특징을 포함합니다.
일반 능력을 MMLU로 통제한 부분 상관관계 분석에서 피어슨 상관계수는 75.5%로 향상되어, 특징 겹침이 일반 모델 품질을 넘어 벤치마크 고유의 능력 유사성을 포착함을 보여줍니다. 이는 평가 스위트 설계자들에게 실용적인 시사점을 제공합니다. 특징 겹침이 낮은 벤치마크는 서로 다른 능력을 평가하므로 함께 유지해야 하고, 겹침이 높은 벤치마크는 통합 후보입니다. 모델 평가 한 번 없이 이 결정을 내릴 수 있다는 것이 핵심 장점입니다.
한 가지 주의할 점은, 중복성이 높다고 해서 반드시 벤치마크 품질이 낮은 것은 아니라는 점입니다. 평가 분산을 줄이거나 특정 도메인 내 폭넓은 커버리지를 보장하기 위해 중복이 바람직할 수도 있습니다. Qwen-Scope의 중복성 지표는 반복적인 개발 과정에서 모델을 효율적으로 순위화하려는 목적에 특화된 도구입니다.
벤치마크 평가 관련 자료 더 알아보기
GPQA-Diamond: A Graduate-Level Google-Proof Q&A Benchmark
MMLU-Redux: Resampling Multi-task Language Understanding
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
응용 3: 독성 분류와 안전 데이터 합성
SAE 특징이 실용적인 분류기로 직접 활용될 수 있는지를 검증하기 위해, Qwen-Scope는 영어, 러시아어, 우크라이나어, 독일어, 스페인어, 암하라어, 중국어, 아랍어, 힌디어, 이탈리아어, 프랑스어, 타타르어, 일본어 13개 언어를 포함하는 다국어 독성 코퍼스(Dementieva et al., 2024)에서 독성 분류 실험을 수행합니다. 핵심은 새로운 분류 헤드를 학습하지 않고 소수의 SAE 특징만으로 분류기를 구성하는 것입니다.
2단계 독성 분류 파이프라인:
-
특징 발견(Feature Discovery): 독성 예시와 정상 예시 집합에서 각 SAE 특징의 활성화 빈도 차이 \Delta_f^{(\ell)} = \Pr[h_{i,f}^{(\ell)} = 1 \mid y_i = 1] - \Pr[h_{i,f}^{(\ell)} = 1 \mid y_i = 0] 를 계산하여 독성에 선택적으로 연관된 특징을 상위 K개 선별합니다.
-
규칙 기반 분류(Rule-Based Classification): 선택된 특징 중 하나라도 활성화되면 독성으로 분류합니다. 그래디언트 기반 학습 없이 즉시 분류가 가능합니다.
각 긍정 예측은 어떤 특징, 레이어, 토큰 위치가 트리거했는지까지 추적할 수 있는 완전한 투명성을 제공합니다. 이는 학습된 분류 헤드에서는 얻기 어려운 수준의 해석 가능성입니다.
결과적으로 영어에서 F1 > 0.90을 달성하며, 특징 발견 데이터의 10%만으로도 원래 성능의 99%를 유지하는 높은 데이터 효율성을 보입니다. 교차 언어 일반화 실험에서는 독성 관련 SAE 특징이 언어 간에 부분적으로 공유된다는 흥미로운 결과가 나타났습니다. 특히 유럽 언어들 사이에서 겹침이 가장 높고, 언어적 거리가 클수록 낮아지는 패턴을 보입니다. 영어에서 발견된 특징을 다른 언어에 직접 전이하면 러시아어, 프랑스어 등에서 강한 분류 성능을 보이며, 더 큰 Qwen3-8B 모델에서 전이의 수준과 안정성 모두 향상됩니다.
특징 주도 안전 데이터 합성
기존 안전 사후 훈련 데이터는 인간이 설계한 넓은 범주에 기반하여 구성되기 때문에, 롱테일(long-tail) 비정상 행동을 놓치는 경우가 많습니다. Qwen-Scope는 SAE 특징을 활용하여 누락된 안전 관련 방향을 타겟으로 데이터를 합성하는 접근법을 제안합니다.
핵심 아이디어는 데이터 구성을 코퍼스 수준에서 표현 수준으로 이동시키는 것입니다. 어떤 안전 관련 SAE 특징이 현재 데이터로 커버되지 않는지 식별하고, 그 특징을 명시적으로 활성화하도록 설계된 프롬프트-완성 쌍을 합성합니다. 합성된 예시는 의도된 특징을 실제로 활성화하는지를 표현 수준에서 검증하여 포함 여부를 결정합니다.
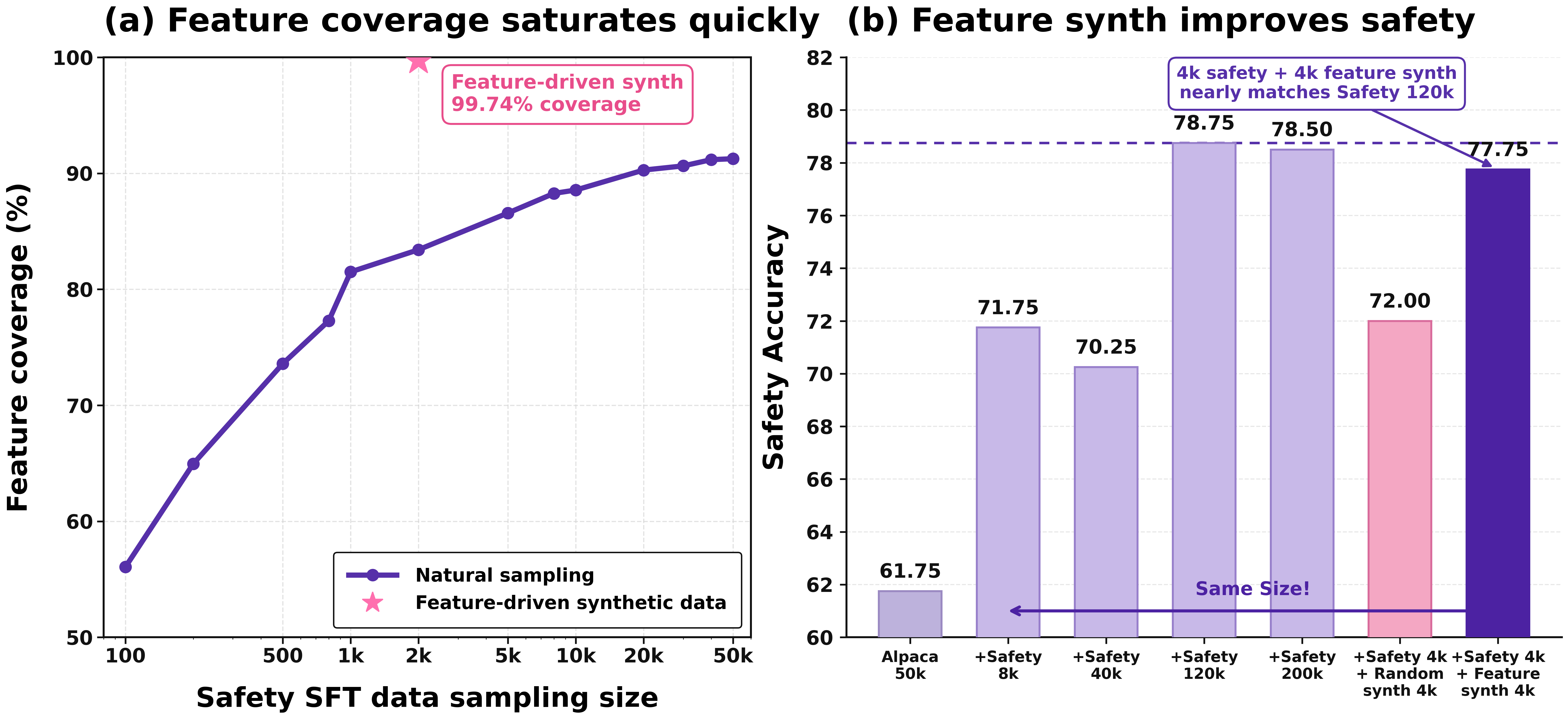
WildJailbreak 데이터셋을 기반으로 한 실험에서 특징 주도 합성은 2,779개 목표 특징 중 99.74%를 커버한 반면, 자연 샘플링이나 무작위 안전 관련 합성은 상당한 공백을 남겼습니다. 더욱 중요한 것은, 동일한 8K 예산에서 4K 실제 안전 데이터와 4K 특징 주도 합성 데이터를 결합하면 안전 정확도가 77.75%로, 무작위 합성을 사용한 72.00%에 비해 크게 향상된다는 점입니다. 놀랍게도 이 8K 결합 설정은 120K 안전 전용 설정의 성능에 근접하며, IFEval, TruthfulQA, MMLU, GSM8K 점수가 모든 비교 설정 중 가장 높아 안전성 개선이 일반 유용성 저하를 수반하지 않음을 보여줍니다.
| 훈련 데이터 | 안전 정확도 | IFEval | TruthfulQA |
|---|---|---|---|
| Alpaca 50k (일반 SFT만) | 61.75 | 51.94 | 56.80 |
| + Safety 8k | 71.75 | 53.05 | 57.11 |
| + Safety 120k | 78.75 | 48.06 | 54.80 |
| + Safety 4k + 무작위 합성 4k | 72.00 | 48.98 | 56.94 |
| + Safety 4k + 특징 주도 합성 4k | 77.75 | 53.23 | 57.32 |
이 결과는 안전 데이터를 단순히 더 많이 추가하는 것보다, 표현 수준에서 커버리지 공백을 타겟으로 하는 합성 데이터가 더 효율적임을 보여줍니다. 특징 주도 합성의 이점은 합성 데이터 자체가 아니라 특징을 타겟으로 한 구성 방식에서 비롯됩니다.
응용 4: 사후 훈련 최적화, SFT와 RL 모두에서
SASFT: 코드 전환 문제를 학습 시점에 해결하다
예상치 못한 코드 전환(Unexpected Code-Switching) 은 다국어 LLM이 의도하지 않은 언어로 갑자기 전환하는 현상으로, 낮은 빈도지만 실용적으로 중요한 실패 유형입니다. 표준 SFT는 타겟 응답을 모방하도록 유도하지만, 의도하지 않은 언어 전환에 대한 명시적 부정 신호를 제공하지 않습니다.
Qwen-Scope의 특징 분석 결과, 코드 전환이 시작되기 전 수십 개의 토큰에 걸쳐 특정 언어 특징의 사전 활성화 값이 점진적으로 증가한다는 패턴을 발견했습니다. 또한 해당 방향을 소거(ablation)하면 코드 전환 비율이 일관되게 감소하는 인과 관계를 확인했습니다.
이를 기반으로 Sparse Autoencoder 기반 지도 미세 조정(SASFT, Sparse Autoencoder-guided Supervised Fine-Tuning) 을 제안합니다. 학습 손실은 표준 교차 엔트로피에 언어별 특징 억제 보조 손실을 더한 형태입니다:
보조 손실 $\mathcal{L}_{\text{reduce}}$는 타겟 언어가 아닌 훈련 데이터에서 타겟 언어의 언어별 특징 활성화가 평균 기준치를 초과하는 양을 패널티로 부여합니다. 이를 통해 원치 않는 언어 방향을 파라미터 업데이트를 통해 내부화합니다.
Qwen3-1.7B, Qwen3-8B에 더해 Gemma-2 및 Llama-3.1 모델 패밀리에 대한 실험에서 SASFT는 기준선 대비 코드 전환 비율을 대부분의 설정에서 50% 이상 감소시켰으며, 일부 구성에서는 완전히 제거하는 데 성공했습니다. 예를 들어 Qwen3-1.7B에서 한국어 코드 전환 비율이 0.36%에서 0.00%로, 러시아어는 0.19%에서 0.03%로 감소했습니다. SFT+패널티 기법(언어 불일치 토큰에 대한 단순 패널티)과 비교해도 SASFT가 일관되게 더 강한 감소를 보입니다.
MMLU, HumanEval, MGSM, Flores, HellaSwag, LogiQA 등 6개 다국어 벤치마크에서의 성능은 SFT와 동등하거나 오히려 소폭 향상됩니다. 이는 원치 않는 언어 방향을 억제하는 것이 해당 언어 자체의 이해 및 생성 능력을 훼손하지 않음을 시사합니다.
SAE 기반 강화학습: 희귀한 실패 유형에 명시적 훈련 신호를
무한 반복(Endless Repetition) 은 모델이 동일한 내용을 무한히 반복하는 저빈도 실패 유형입니다. 표준 온라인 강화학습은 롤아웃 분포에서 이러한 실패가 드물게 발생하기 때문에, 이를 수정하는 강한 학습 신호를 얻기 어렵습니다. 초기 접근으로 SAE 특징 조종을 통해 더 품질 높은 긍정 롤아웃을 생성하려 했으나, 다단계 추론이 필요한 과제에서 조종만으로는 정확한 응답을 생성하기에 부족하고 텍스트 유창성이 저하되는 문제가 있었습니다. 이에 전략을 전환하여 부정 샘플 생성에 집중했습니다. 바람직하지 않은 행동은 올바른 행동보다 유도하기 쉽고, 유창성이 떨어지더라도 모델이 피해야 할 패턴을 보여주는 데는 문제없기 때문입니다.
Qwen-Scope의 특징 분석을 통해 반복이 시작될 때 특정 SAE 특징의 활성화 값이 급격히 상승하고 지속적으로 높은 수준을 유지한다는 것을 발견했습니다. 양방향 조종 실험에서 이 특징들을 억제하면 반복 비율이 감소하고, 증폭하면 정상 샘플에서도 반복이 유도됨을 확인하여 인과 관계를 검증했습니다.
흥미롭게도, 이 반복 특징들은 사용자 질문을 그대로 반복하거나 객관식 선택지를 재현하는 등의 양성 반복 시나리오에서도 높은 활성화 값을 보입니다. 이는 반복 특징이 병리적 무한 반복에만 국한된 것이 아니라, 더 일반적인 반복 개념을 포착한다는 것을 의미합니다. 따라서 SASFT에서처럼 훈련 시 직접 특징을 억제하면 양성 반복 능력까지 저하될 위험이 있어, 추론 시 부정 샘플 생성에 SAE 조종을 활용하는 전략을 택했습니다.
이를 기반으로 DAPO(Direct Alignment from Preference Optimization) 프레임워크에 SAE 기반 희귀 부정 보강(Rare Negative Augmentation)을 통합합니다. 각 롤아웃 그룹에서 G-1개의 정상 출력과 함께, SAE 특징 조종으로 반복 행동을 유도한 1개의 부정 샘플을 그룹에 포함시킵니다. 이 조종된 롤아웃이 명시적 부정 훈련 신호를 제공합니다.
Qwen3-1.7B, Qwen3-8B, Qwen3-30B-A3B 세 모델 크기에 대한 실험에서 SAE 기반 강화학습은 훈련 초기부터 반복 비율이 급격히 하락하여 표준 강화학습 대비 훨씬 낮은 수준에 도달합니다. 표준 강화학습은 이 실패 유형에 대한 제한적인 개선만을 보이는 반면, SAE 기반 방법은 세 모델 크기 모두에서 일관되게 강한 감소를 달성합니다. MMLU, Flores, HellaSwag, IFEval, MGSM 등 일반 능력 벤치마크에서의 성능은 표준 강화학습과 대체로 동등하며, 특정 벤치마크에서는 소폭의 향상도 관찰됩니다.
사후 학습 더 알아보기
SASFT: Sparse Autoencoder-Guided Supervised Finetuning to Mitigate Unexpected Code-Switching in LLMs - Deng et al. (ICLR 2026)
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qwen-Scope로 시작하기: 코드 예시
SAE를 불러오고 잔차 스트림에서 특징 활성화를 추출하는 방법은 다음과 같습니다:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 기반 모델 로드
model_name = "Qwen/Qwen3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float32)
model.eval()
# 2. 특정 레이어의 SAE 로드
LAYER = 20 # 0–35 중 선택
sae = torch.load(f"layer{LAYER}.sae.pt", map_location="cpu")
W_enc = sae["W_enc"] # (65536, 4096)
b_enc = sae["b_enc"] # (65536,)
def get_feature_acts(residual: torch.Tensor) -> torch.Tensor:
"""residual: (..., 4096) → sparse feature activations (..., 65536)"""
pre_acts = residual @ W_enc.T + b_enc
topk_vals, topk_idx = pre_acts.topk(50, dim=-1)
acts = torch.zeros_like(pre_acts)
acts.scatter_(-1, topk_idx, topk_vals)
return acts
# 3. 잔차 스트림 후킹
captured = {}
def _hook(module, input, output):
hidden = output[0] if isinstance(output, tuple) else output
captured["residual"] = hidden.detach().cpu()
hook = model.model.layers[LAYER].register_forward_hook(_hook)
# 4. 특징 활성화 추출
text = "Tell me about recent advances in LLMs."
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
model(**inputs)
hook.remove()
feature_acts = get_feature_acts(captured["residual"])
print(f"Active features: {(feature_acts > 0).sum().item()}")
HuggingFace 모델 카드에서 더 상세한 사용 예시와 조종 코드를 확인할 수 있습니다.
Qwen-Scope가 열어가는 해석 가능성 연구의 새 지평
Qwen-Scope의 가장 중요한 기여는 SAE가 사후 분석 도구에서 벗어나 모델 개발의 재사용 가능한 표현 수준 인터페이스로 자리매김할 수 있음을 실증적으로 보여준 것입니다. 동일한 SAE 특징 집합이 모델 행동 진단, 출력 조종, 평가 데이터 분석, 데이터 구성 안내, 사후 훈련 개선이라는 다섯 가지 서로 다른 목적에 재사용됩니다. 이는 해석 가능성 연구가 단순한 학문적 관찰을 넘어 실제 모델 개발 사이클에 통합될 수 있는 가능성을 보여줍니다.
Qwen-Scope 팀이 제시하는 앞으로의 연구 방향은 다음과 같습니다.
추론 모델 해석 가능성: 긴 사고의 사슬(Chain-of-Thought) 추론을 사용하는 모델에서, 단일 순전파 분석만으로는 부족할 수 있습니다. 어떤 SAE 특징이 추론 분기에 걸쳐 나타나는지, 어떤 단계가 인과적으로 중요한지를 분석하는 연구가 필요합니다. 특히 DeepSeek-R1이나 QwQ와 같이 긴 추론 체인을 생성하는 모델에서 내부 추론 과정을 해석하는 것이 주요 연구 과제입니다.
내부 기반 모니터링과 감사: SAE 특징이 속임수, 숨겨진 목표, 탈옥 취약성, 환각 등 출력만으로는 탐지하기 어려운 위험에 대한 경량 내부 신호를 제공할 수 있는지 탐구합니다. 활성화 추가(Activation Steering) 연구에서 얻은 통찰을 실시간 안전 모니터링에 적용할 가능성이 있습니다.
모델 비교 분석(Model Diffing): 파인튜닝, 강화학습 등 개입 전후의 모델 내부를 비교하여 어떤 SAE 특징이 변화하는지, 사후 훈련이 활성화 공간에 어떤 흔적을 남기는지 분석합니다. 이는 RLHF나 DPO 같은 정렬 방법의 내부 메커니즘을 더 깊이 이해하는 데 기여할 수 있습니다.
해석 가능성 주도 제어와 훈련: SAE 특징을 제어 손잡이(control knob)로 활용하는 연구를 확장합니다. 추론 시 증폭 또는 억제, SFT에서 보조 신호, RL에서 희귀 부정 예시 구성 등 다양한 방식으로 해석 가능한 방향이 훈련 파이프라인에 통합될 수 있습니다.
데이터 중심 해석 가능성: SAE 특징을 활용하여 커버리지가 낮은 행동을 식별하고, 예시 우선순위화, 합성 데이터 생성 안내, 바람직하지 않은 행동의 영향력 있는 데이터 귀인 등 데이터 중심 워크플로를 지원합니다.
라이선스
Qwen-Scope 컬렉션 페이지에서 개별 모델의 라이선스를 확인하시기 바랍니다. Qwen3 및 Qwen3.5 시리즈 모델은 Apache License 2.0으로 배포되어, 연구 목적은 물론 상업적 용도로도 자유롭게 사용 및 수정이 가능합니다.
 Qwen-Scope 기술 보고서
Qwen-Scope 기술 보고서
 Qwen-Scope HuggingFace 컬렉션
Qwen-Scope HuggingFace 컬렉션
 Qwen-Scope 대화형 탐색 데모 (QwenScope Space)
Qwen-Scope 대화형 탐색 데모 (QwenScope Space)
더 읽어보기
-
LLM 내부의 감정 개념과 기능적 감정: Claude Sonnet 4.5의 감정 표상이 협박, 보상 해킹, 아부에 미치는 인과적 영향 (feat. Anthropic)
-
Anthropic, Claude 모델의 가치 체계 및 동작 원리를 정리한 '헌법(Constitution)' 공개
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()