
RLHF Book 소개
RLHF Book은 인간 피드백 기반 강화학습(Reinforcement Learning from Human Feedback, RLHF)과 그 주변 기법들을 한 권의 오픈소스 교재 형태로 정리한 프로젝트입니다. ChatGPT 이후 폭발적으로 발전한 사후 학습(Post-training) 분야에서, 거부 샘플링(Rejection Sampling)처럼 산업계에서 널리 쓰이지만 정식 레퍼런스가 부족했던 기법들이나, 모델을 더 자연스럽게 만드는 캐릭터 학습(Character Training) 같은 기법은 오랫동안 공개된 연구 자료를 찾기 어려웠습니다. 저자인 Nathan Lambert는 Allen Institute for AI(AI2)에서 오픈 모델 분야의 최전선에서 일하며 축적한 지식을 정리해 누구나 읽을 수 있도록 공개하기로 결정하였고, 그 결과물이 바로 이 책입니다. 책은 AI가 만든 잡음(AI slop)이 넘쳐나는 시대에 신뢰할 수 있는 참고문헌(reference)을 정성스럽게 큐레이션하는 것을 중요한 목표로 두고 있어, 학습자가 출처를 따라가며 깊이 공부할 수 있도록 구성되어 있습니다.
이 책은 단순한 PDF 모음이 아니라 웹사이트(rlhfbook.com), 인쇄본(Manning, Amazon), 전자책(Kindle, EPUB), 강의 영상, 그리고 참조 구현 코드 라이브러리를 모두 포함하는 종합 학습 허브로 운영됩니다. 2024년 5월 처음 공개된 이후 지속적으로 업데이트되어 왔으며, 2026년 1월에는 Manning 출판본 구조에 맞춰 챕터를 대규모로 재편하고 코드 예제 라이브러리를 추가하였습니다. 또한 2026년 4월에는 인쇄본 출간을 앞두고 최종 편집 작업을 마무리하며, 수식과 용어 표현을 일관되게 다듬고 17장 제품(Product) 챕터를 확장하는 등 마무리 작업이 진행되었습니다. 변경 이력은 책의 홈페이지에 모두 공개되어 있어 어떤 시기에 어떤 내용이 추가되었는지 추적할 수 있습니다.
저자는 책 본문, 다이어그램, 코드 예제, 강의 슬라이드까지 모든 자료를 GitHub에 공개해 두었으며, 독자가 자신의 강의나 블로그, 발표 자료에 그대로 재사용할 수 있도록 다이어그램의 원본 파일(LaTeX/TikZ, Python 스크립트, YAML 명세)까지 함께 제공합니다. 코드 라이브러리는 PPO, REINFORCE, GRPO, RLOO 같은 정책 경사(Policy Gradient) 계열, ORM/PRM 같은 보상 모델(Reward Model) 학습, DPO 계열의 직접 정렬(Direct Alignment) 기법, 베스트 오브 N 거부 샘플링까지 RLHF의 핵심 알고리즘을 한곳에서 PyTorch 기반으로 비교 학습할 수 있게 해 줍니다.
RLHF Book의 구성과 챕터
책은 크게 사후 학습 파이프라인의 흐름을 따라 17개의 본 챕터와 4개의 부록으로 구성되어 있습니다. 도입부에서는 강화학습과 RLHF의 기본 개념을 정리하고, 이후 보상 모델, 정책 최적화, 직접 정렬, 추론(Reasoning) 학습, 도구 사용(Tool Use)으로 점차 확장되는 구조입니다. 각 챕터는 독립적인 Markdown 파일로 관리되며, 책 사이트와 PDF, EPUB이 같은 소스에서 빌드됩니다.
- 1장 Introduction: RLHF가 왜 필요한지, 사후 학습 전반에서 어떤 위치를 차지하는지 개관합니다.
- 2장 Related Works: InstructGPT, Anthropic의 Constitutional AI 등 RLHF의 직접적 원류가 되는 연구들을 정리합니다.
- 3장 Training Overview: 사전 학습부터 정렬까지 전체 학습 파이프라인을 한눈에 보여 줍니다.
- 4장 Instruction Tuning: 지시 조정(IFT/SFT)의 데이터 구성과 학습 방법을 다룹니다.
- 5장 Reward Models: 선호 보상 모델(Preference RM), 결과 보상 모델(ORM), 과정 보상 모델(PRM)을 비교합니다.
- 6장 Policy Gradients: PPO, REINFORCE, GRPO, RLOO, GSPO, CISPO, SAPO, DAPO 등 정책 경사 계열을 수식과 코드로 설명합니다.
- 7장 Reasoning: RLVR(Reinforcement Learning with Verifiable Rewards) 등 추론 능력 강화 기법을 다룹니다.
- 8장 Direct Alignment: DPO와 그 변종들을 한 챕터로 정리합니다.
- 9장 Rejection Sampling: 베스트 오브 N 거부 샘플링의 실용적 활용을 설명합니다.
- 10~12장 Preferences / Preference Data / Synthetic Data: 선호 데이터의 정의, 수집 절차, 합성 데이터 활용을 다룹니다.
- 13장 Tools: 도구 사용 학습 챕터입니다.
- 14장 Over-optimization: 보상 해킹(Reward Hacking), 보상 모델의 과최적화 문제를 다룹니다.
- 15장 Regularization: KL 정규화 등 안정적인 학습을 위한 기법들을 정리합니다.
- 16장 Evaluation: RLHF 모델의 평가 방법과 한계를 설명합니다.
- 17장 Product: 실제 제품에서의 RLHF 적용 사례와 고려 사항을 다룹니다.
- 부록 A~C: 용어 정의(Definitions), 스타일 가이드(Style), 실용 팁(Practical) 그리고 참고문헌을 모아 둡니다.
이러한 구성은 단순히 "RLHF란 무엇인가"를 설명하는 데 그치지 않고, 보상 모델 학습부터 정책 최적화, 합성 데이터 생성, 평가까지 사후 학습 파이프라인의 전체 단계를 다루기 때문에, 처음 입문하는 독자뿐 아니라 실제 모델을 학습하는 엔지니어가 참고서로 활용하기에도 적합합니다.
RLHF Book의 코드 라이브러리
code/ 디렉토리에는 책의 각 장과 직접 연결된 참조 구현이 PyTorch와 uv 기반으로 정리되어 있습니다. 정책 경사 구현은 Zafir Stojanovski의 policy-gradients 저장소를, 보상 모델 구현은 @myhott163com의 RLHF_ORM_PRM 저장소를 기반으로 하여 6장과 5장의 수식과 동일한 표기법으로 정리되어 있습니다. 즉, 책에서 보았던 수식 \mathcal{L}_\text{PPO} 나 GRPO의 어드밴티지(advantage) 정의가 코드 어디에 어떻게 구현되어 있는지를 1대1로 따라갈 수 있습니다.
설치는 uv만 있으면 매우 간단하며, Python 3.12 이상을 요구합니다.
# 저장소 클론 후
cd code/
uv sync
# (선택) Flash Attention 가속이 필요한 경우
uv sync --extra flash
학습 실행은 알고리즘별로 정의된 YAML 설정을 그대로 사용할 수 있습니다. 같은 절차적 추론(procedural reasoning) 태스크 위에서 알고리즘만 바꿔 가며 비교할 수 있도록 구성되어 있어, "이 데이터셋에서 PPO와 GRPO가 어떻게 다른가"를 한 환경에서 직접 측정할 수 있습니다.
# GRPO (6장)
uv run python -m policy_gradients.train --config policy_gradients/configs/grpo.yaml
# PPO with value function
uv run python -m policy_gradients.train --config policy_gradients/configs/ppo.yaml
# REINFORCE 베이스라인
uv run python -m policy_gradients.train --config policy_gradients/configs/reinforce.yaml
# RLOO (Leave-One-Out)
uv run python -m policy_gradients.train --config policy_gradients/configs/rloo.yaml
저자가 DGX Spark 환경에서 직접 실행한 학습 결과는 wandb 차트로 함께 공개되어 있어, 알고리즘별 학습 곡선의 형태와 안정성을 비교해 볼 수 있습니다.
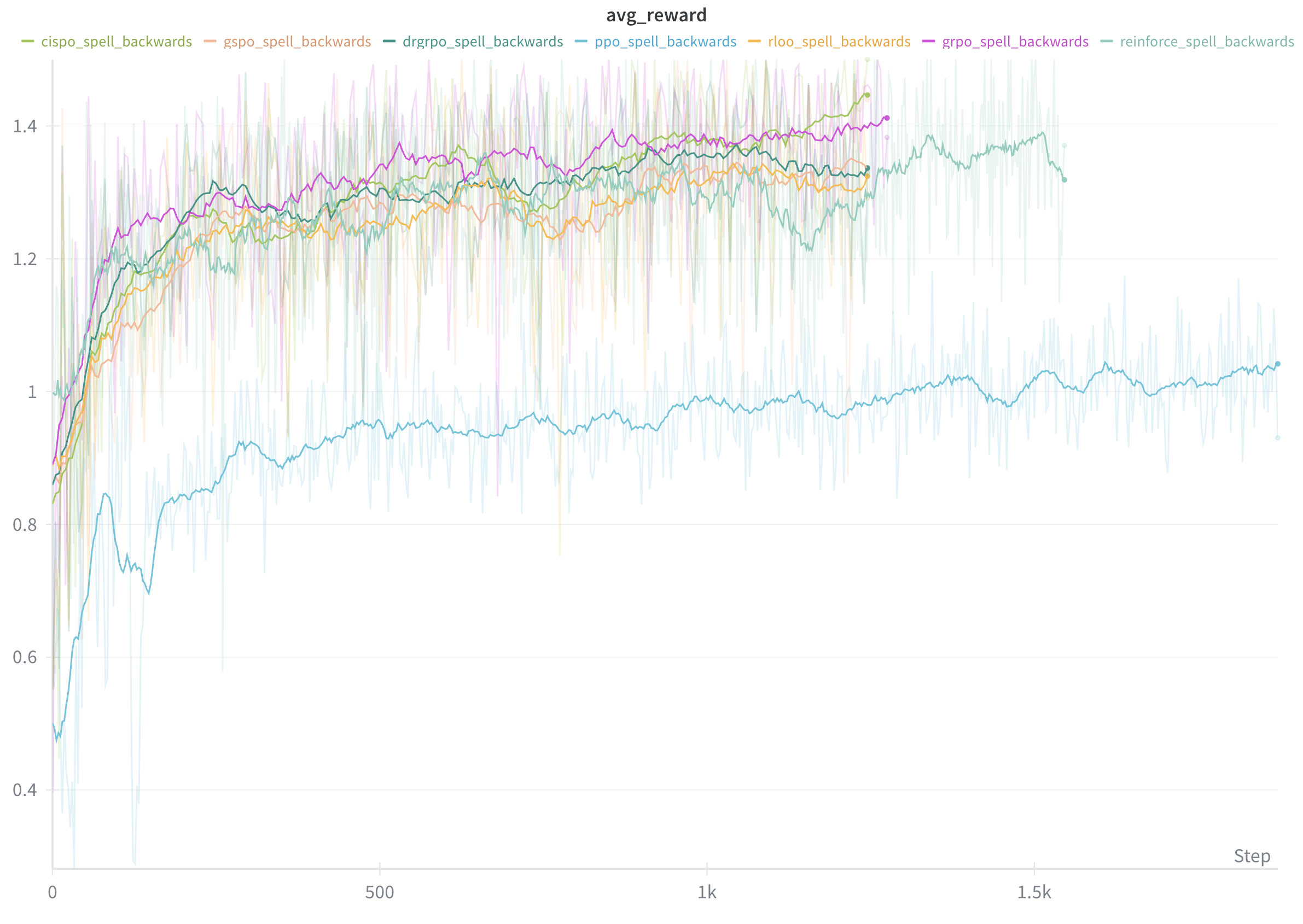
코드 라이브러리는 정책 경사뿐 아니라 다음과 같은 RLHF 핵심 모듈을 함께 제공합니다.
- policy_gradients/: PPO, REINFORCE, GRPO, RLOO, Dr. GRPO, GSPO, CISPO, SAPO, DAPO 등 정책 경사 계열의 구현이 모두 같은 인터페이스로 정리되어 있습니다.
- reward_models/: 결과 보상 모델(Outcome Reward Model)과 과정 보상 모델(Process Reward Model)의 미니멀 구현이 포함되어 있어, 보상 모델이 실제로 어떻게 학습되는지 코드 수준에서 확인할 수 있습니다.
- direct_alignment/: DPO와 그 변종(IPO, KTO 등 책에서 다루는 변종들)의 손실 함수와 학습 루프를 비교 학습할 수 있습니다.
- rejection_sampling/: 베스트 오브 N 거부 샘플링의 표준 구현으로, 책의 9장과 직접 연결됩니다.
RLHF Book의 다이어그램과 강의 자료
diagrams/ 디렉토리에는 책에 사용된 모든 다이어그램의 원본이 들어 있습니다. Python 생성 스크립트와 LaTeX/TikZ 소스, YAML 명세가 함께 제공되며, make all 명령으로 다시 빌드할 수 있도록 정리되어 있습니다. 저자는 이 다이어그램들을 발표 자료, 블로그 글, 강의 슬라이드 등 다양한 용도로 자유롭게 재사용할 것을 권장하고 있어, 강의를 준비하는 연구자나 강연자가 책의 도식을 그대로 활용하기 좋습니다.
teach/ 디렉토리에는 강의용 자료가 모여 있고, 별도로 강의 영상 시리즈가 공개되어 있어 책의 내용을 영상으로 따라가며 학습할 수 있습니다. 영상은 책의 챕터 구성과 거의 일치하기 때문에 텍스트 학습과 영상 학습을 병행하기에 적합합니다.
책 인쇄본과 온라인판
전체 내용은 rlhfbook.com에서 무료로 읽을 수 있으며, 동일한 소스로 빌드된 인쇄본이 Manning과 Amazon을 통해 판매됩니다. 책의 본문은 Pandoc 템플릿을 사용해 HTML, PDF, EPUB으로 동시에 빌드되며, 로컬에서도 다음 명령으로 직접 빌드할 수 있습니다.
make html # HTML 사이트 빌드
make pdf # PDF 빌드 (LaTeX 필요)
저자는 이 프로젝트와 함께 arXiv에 2504.12501 논문도 공개해 두었으며, 학술적 인용이 필요한 경우 책 본문 또는 해당 논문을 함께 참고할 수 있습니다.
라이선스
이 프로젝트는 두 개의 라이선스로 분리되어 공개됩니다. 코드(code/ 및 빌드 스크립트)는 MIT 라이선스로 자유롭게 사용할 수 있으며, 책의 본문(book/chapters/)은 CC-BY-NC-SA-4.0 라이선스로 공개되어 있어 비상업적 목적에 한해 출처를 표시하고 동일 라이선스로 공유한다는 조건에서 자유롭게 활용할 수 있습니다. 본문을 상업적으로 활용하려는 경우 별도의 허락이 필요하므로, 사내 자료나 유료 강의에 본문 일부를 인용할 때는 이 점을 유의해야 합니다.
 RLHF Book 공식 홈페이지
RLHF Book 공식 홈페이지
 RLHF Book 강의 페이지
RLHF Book 강의 페이지
 RLHF Book 관련 논문 (arXiv)
RLHF Book 관련 논문 (arXiv)
 RLHF Book 프로젝트 GitHub 저장소
RLHF Book 프로젝트 GitHub 저장소
더 읽어보기
-
OAT 🌾: 대규모 언어 모델(LLM)의 온라인 정렬을 위한 연구 친화적 프레임워크 (Online Alignment Toolkit for LLMs)
-
[Deep Research] 강화학습의 개념과 주요 기법 분석, LLM에서의 활용 및 발전 방향에 대한 보고서
-
ART(Agent Reinforcement Trainer), Agent를 위한 강화학습 트레이너 프로젝트 (feat. OpenPipe)
-
Open-AgentRL: LLM 에이전트 강화를 위한 통합 오픈소스 프레임워크 (feat. RLAnything & DemyAgent)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()