
SurveyX 연구 소개
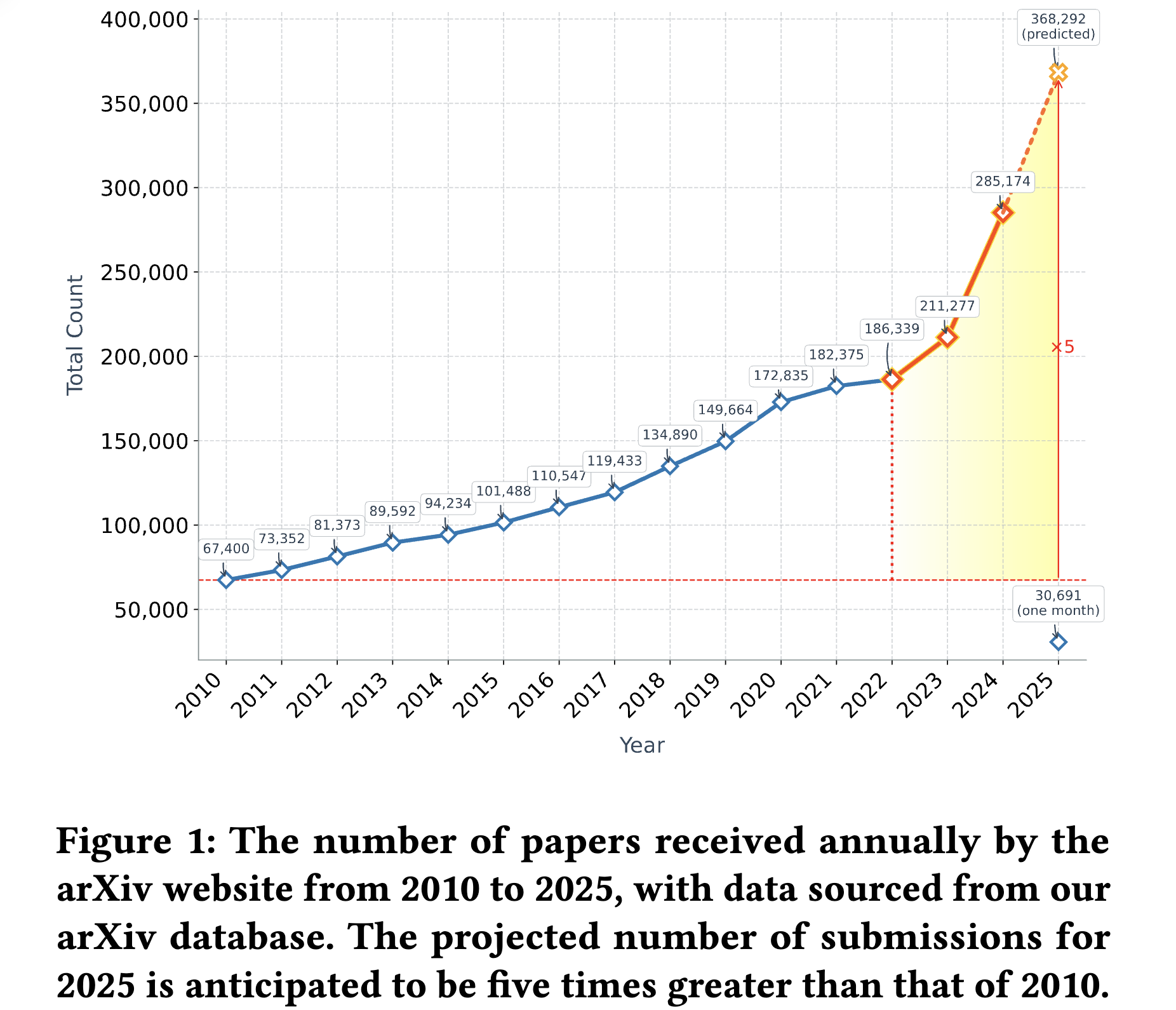
학술 연구의 양이 폭발적으로 증가하면서, 특정 분야의 연구 동향을 파악하는 것이 점점 어려워지고 있습니다. 최근 몇 년간 arXiv에 제출된 논문의 수가 급격히 증가했으며, 2025년에는 2010년 대비 5배 증가할 것으로 예상됩니다. 매일 수천 개의 논문이 arXiv에 업로드되는 상황에서, 연구자들이 이론적 배경과 최신 연구 동향을 파악하기 위해서는 효율적인 문헌 조사(survey)가 필수적입니다.
SurveyX는 대규모 언어 모델(LLM)을 활용하여 자동으로 고품질의 학술 조사를 생성하는 시스템입니다. 기존의 자동화 시스템들이 가진 한계를 극복하고 인간 전문가 수준의 서베이를 생성하는 것을 목표로, 연구자들이 시간과 노력을 절약하면서도 더 정확한 정보를 얻을 수 있도록 돕는 것이 목표입니다. 이 연구에서는 자동화된 서베이 생성의 문제점과 이를 해결하기 위한 SurveyX의 핵심 기술을 설명합니다.
SurveyX 시스템 개요
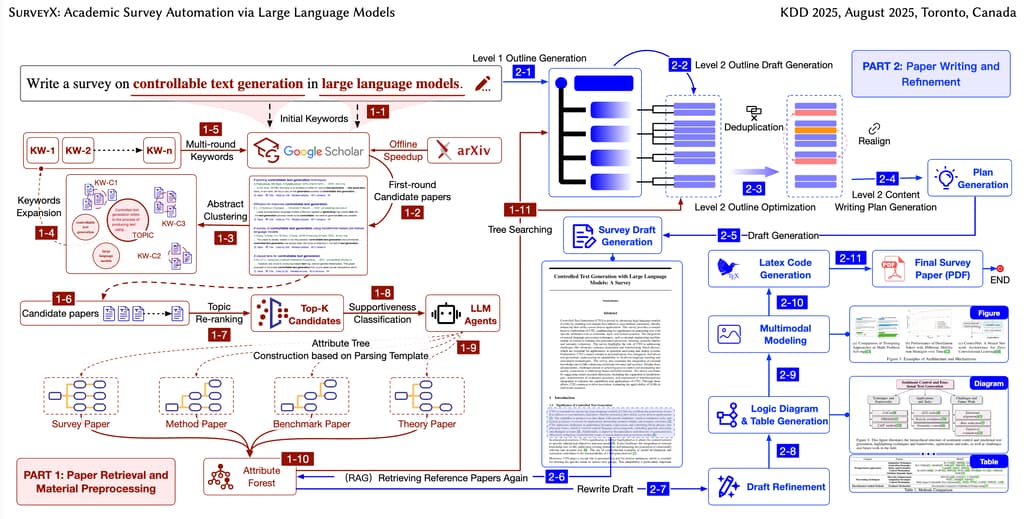
SurveyX는 대형 언어 모델(LLM)의 강력한 언어 생성 능력을 활용하여 자동으로 학술 서베이를 생성하는 시스템입니다. 기존 자동 서베이 생성 모델들은 LLM이 보유한 내부 지식을 바탕으로 서베이를 생성하는데, 이 방식은 최신 논문을 반영하지 못하거나 잘못된 인용이 포함될 가능성이 높았습니다. 또한, 기존 시스템은 논문의 주요 내용을 단순 요약하는 수준에 머물러 있어 논리적 연결성과 종합적인 분석 능력이 부족하다는 한계가 있었습니다. SurveyX는 이러한 문제를 해결하기 위해 효율적인 논문 검색, 전처리, 아웃라인 최적화, RAG 기반 본문 생성, 자동 인용 검증 등의 핵심 기술을 결합하여 더욱 정교한 자동 서베이 생성 시스템을 구축했습니다.
SurveyX의 핵심 아이디어는 크게 두 가지로 나눌 수 있습니다:
-
“AttributeTree” 기반 전처리 기법 도입: SurveyX에서는 최신 논문을 효과적으로 검색하고, 논문의 핵심 정보를 압축하여 제공하는 “AttributeTree” 기반의 전처리 기법을 도입했습니다. 이 방식을 통해 LLM이 제한된 컨텍스트 창 내에서 최대한 많은 유용한 정보를 활용할 수 있도록 하여, 더 정확하고 깊이 있는 서베이를 생성할 수 있도록 했습니다.
-
아웃라인 생성 시 “Outline Optimization” 기법 활용: 논문의 논리적 구조를 최적화하기 위해 “Outline Optimization” 기법을 활용하여, 보다 체계적인 아웃라인을 생성하는 것입니다. 이는 기존의 단순 텍스트 생성 방식과 달리, LLM이 생성한 아웃라인을 기반으로 체계적으로 내용을 확장하는 방식을 도입하여, 연구 간의 관계를 보다 명확하게 정리할 수 있도록 합니다.
이 외에도 SurveyX는 Retrieval-Augmented Generation (RAG) 기반의 본문 생성 방식을 통해, 검색된 논문을 참고하여 LLM이 보다 신뢰할 수 있는 문장을 생성하도록 설계되었습니다. 또한, 자동 인용 검증 기능을 포함하여 잘못된 인용을 제거하고, 보다 정확한 참고 문헌을 포함할 수 있도록 했습니다. 마지막으로, 기존의 단순 텍스트 기반 서베이와 차별화된 표 및 그래프 자동 생성 기능을 추가하여 가독성을 높이는 것도 SurveyX의 중요한 특징입니다. 이러한 아이디어를 바탕으로 SurveyX는 기존 서베이 생성 방식보다 훨씬 더 신뢰성 있고 효율적인 학술 서베이를 생성할 수 있습니다.
SurveyX 시스템 구성
SurveyX의 전체 시스템은 크게 준비 단계(Preparation Phase) 및 생성 단계(Generation Phase)의 두 단계로 구성됩니다. 각 단계는 여러 개의 세부 프로세스로 나뉘며, 논문의 검색, 필터링, 전처리, 아웃라인 생성, 본문 작성, 후처리 등의 과정을 통해 서베이를 완성합니다.
-
준비 단계(Preparation Phase): 서베이 작성을 위한 논문을 수집하고 전처리하는 과정입니다. 이 단계에서 SurveyX는 온라인 및 오프라인 논문을 검색하여 관련 문서를 수집한 후, 필요한 논문만 선별하는 2단계 필터링을 수행합니다. 이후, 필터링된 논문의 핵심 정보를 “AttributeTree” 방식으로 전처리하여, LLM이 논문의 주요 내용을 쉽게 이해하고 활용할 수 있도록 최적화된 데이터 구조를 구축합니다.
-
생성 단계(Generation Phase): 전처리된 데이터를 바탕으로 서베이를 생성하는 과정입니다. 이 단계는 세 가지 주요 프로세스(Outline Generation, Content Generation, Post-Processing)로 구성됩니다. 먼저, Outline Optimization 기법을 이용해 논리적으로 정리된 아웃라인을 생성합니다. 이후, RAG 기반의 본문 생성 기법을 사용하여 논문에서 검색된 정보를 바탕으로 내용이 풍부한 서베이를 작성합니다. 마지막으로, 후처리(Post-Processing) 과정에서 자동 인용 검증을 수행하고, 가독성을 높이기 위해 표와 그래프를 추가합니다. 이를 통해, SurveyX는 단순히 논문을 요약하는 것이 아니라, 논문 간의 관계를 분석하고 논리적으로 정리하여, 보다 체계적인 서베이를 생성하는 것이 가능합니다.
SurveyX의 전체 파이프라인은 크게 논문 검색 및 필터링 → 속성 트리(전처리) 생성 → 아웃라인 최적화 → 본문 생성 → 후처리(인용 검증 및 시각적 자료 생성) 순으로 진행됩니다. 이러한 구성 방식은 기존 자동화 서베이 생성 시스템보다 더 높은 정확도와 논리성을 확보할 수 있도록 설계되었습니다.
각 단계를 세부적으로 살펴보면 다음과 같습니다:
논문 검색 및 전처리를 수행하는 준비 단계(Preparation Phase)
준비 단계(Preparation Phase)는 서베이 생성을 위한 핵심 자료를 수집하고 이를 효과적으로 활용할 수 있도록 전처리하는 단계입니다. 기존 자동 서베이 생성 방식은 대부분 LLM의 내부 지식에 의존하거나, 단순한 검색 결과를 그대로 활용하는 방식을 사용했습니다. 이러한 방식은 최신 연구를 반영하지 못하거나, 논문에서 필요한 정보를 효과적으로 추출하지 못해 서베이의 신뢰성과 정보 밀도가 낮아지는 문제를 초래했습니다. 또한, LLM이 직접 논문의 원문을 참조하는 방식은 컨텍스트 윈도우(context window) 한계로 인해 논문의 핵심 내용을 충분히 반영하지 못하는 문제를 일으켰습니다. 이를 해결하기 위해 SurveyX는 최신 논문을 신속하게 검색하고, 필요한 정보를 구조적으로 정리하여 LLM이 보다 효율적으로 활용할 수 있도록 하는 전처리 기법을 도입했습니다. 이 과정은 크게 (1) 논문 검색 및 필터링(References Acquisition)과 (2) 속성 트리(AttributeTree) 전처리의 두 단계로 구성됩니다.
첫 번째 과정인 논문 검색 및 필터링 단계에서는 최대한 많은 관련 논문을 검색한 후, 서베이에 적합한 논문만을 선별하는 과정을 수행합니다. 기존 논문 검색 방식은 주로 키워드 검색을 활용하는데, 이는 연관성이 낮은 논문이 포함되거나 중요한 논문이 누락될 가능성이 큽니다. SurveyX는 이를 해결하기 위해 키워드 확장 알고리즘(Keyword Expansion Algorithm)을 적용하여 초기 검색 키워드를 확장하고, 보다 다양한 논문을 검색할 수 있도록 설계했습니다. 이후, 검색된 논문을 대상으로 2단계 필터링 기법을 적용합니다. 첫 번째 필터링 과정에서는 임베딩 모델을 활용하여 논문의 초록(abstract)과 주어진 연구 주제 간의 유사도를 계산하여, 주제와 관련성이 높은 논문만을 선택합니다. 두 번째 필터링 과정에서는 LLM을 활용하여 논문의 본문 내용을 분석하고, 보다 정밀한 의미적 필터링을 수행하여 최종적으로 서베이에 적합한 논문을 선별합니다. 이를 통해, SurveyX는 기존 방식보다 더 신뢰성 있고, 최신 연구 동향을 반영할 수 있는 논문을 효과적으로 수집할 수 있습니다.
두 번째 과정인 속성 트리(AttributeTree) 전처리 단계에서는, 검색된 논문을 LLM이 보다 효과적으로 활용할 수 있도록 정리하는 과정이 수행됩니다. 기존 자동 서베이 생성 방식에서는 논문의 원문을 직접 LLM에 입력하는 방식을 사용했지만, 이는 컨텍스트 윈도우 크기 제한으로 인해 LLM이 논문의 일부 정보만 활용하는 문제가 발생했습니다. SurveyX는 이러한 문제를 해결하기 위해, 논문의 주요 내용을 속성 트리(AttributeTree) 형태로 변환하여 요약하는 기법을 도입했습니다. 속성 트리는 논문의 핵심 내용을 구조적으로 정리한 데이터 구조로, 논문에 포함된 주요 개념, 연구 방법, 데이터셋, 실험 결과, 결론 등을 계층적으로 구성하여 LLM이 보다 효과적으로 참조할 수 있도록 합니다. 예를 들어, 기존 방식에서는 논문 원문을 그대로 제공해야 했지만, SurveyX에서는 속성 트리를 통해 “이 논문의 주요 기여는 무엇인가?”, “어떤 데이터셋을 사용했는가?”, “실험 결과는 어떤 의미를 가지는가?“와 같은 질문에 대한 핵심 정보를 효율적으로 제공할 수 있도록 정리합니다.
속성 트리(AttributeTree) 전처리 과정은 크게 두 가지 장점을 가집니다. 첫째, LLM이 제한된 컨텍스트 윈도우 내에서 더 많은 정보를 효과적으로 활용할 수 있도록 함으로써, 보다 정확하고 풍부한 내용을 포함할 수 있도록 합니다. 기존 방식에서는 긴 논문을 참조하는 것이 어려웠지만, 속성 트리를 이용하면 LLM이 논문의 핵심 내용을 한눈에 파악할 수 있어 정보 밀도가 높은 서베이를 생성할 수 있습니다. 둘째, 속성 트리는 논문 간의 비교 및 분석을 보다 쉽게 수행할 수 있도록 도와줍니다. 예를 들어, SurveyX는 속성 트리를 기반으로 “A 연구와 B 연구의 차이점”을 효과적으로 분석할 수 있으며, 이를 바탕으로 서베이에서 연구 간의 관계를 보다 명확하게 설명할 수 있습니다. 이러한 방식은 기존 자동화 서베이 생성 방식이 단순 요약 수준에 머물러 있었던 것과는 달리, 보다 체계적이고 논리적인 연구 분석을 가능하게 합니다.
결과적으로, 준비 단계(Preparation Phase)는 SurveyX의 서베이 품질을 결정짓는 중요한 과정으로, 기존 LLM 기반 서베이 생성 방식이 가진 문제점을 극복하고 최신 논문을 빠르고 정확하게 검색하며, 논문의 핵심 내용을 효과적으로 정리하여 LLM이 최적의 성능을 발휘할 수 있도록 지원하는 역할을 합니다. 이를 통해 SurveyX는 더 높은 신뢰성을 갖춘, 보다 풍부하고 체계적인 서베이를 자동으로 생성할 수 있도록 설계되었습니다.
서베이를 생성하는 생성 단계(Generation Phase)
생성 단계(Generation Phase)는 준비된 데이터를 활용하여 실제 서베이를 생성하는 단계입니다. 기존의 LLM 기반 자동 생성 방식은 논문을 단순 요약하는 수준에 머물러 있었으며, 논리적인 흐름이 부족하거나, 개별 연구 간의 관계를 효과적으로 정리하지 못하는 한계를 갖고 있었습니다. 또한, 생성된 텍스트의 신뢰성을 보장하기 어려웠으며, 잘못된 인용(hallucination) 문제도 자주 발생했습니다. 이러한 문제를 해결하기 위해, SurveyX는 서베이 작성 과정을 아웃라인 생성(Outline Generation), 본문 생성(Content Generation), 후처리(Post-Processing)의 세 가지 주요 단계로 나누어 보다 체계적이고 신뢰할 수 있는 학술 서베이를 생성할 수 있도록 설계되었습니다.
첫 번째 과정인 아웃라인 생성(Outline Generation) 단계에서는 LLM이 논리적인 서베이 구조를 자동으로 생성합니다. 기존 방식은 LLM이 내부 지식을 활용하여 무작위로 아웃라인을 생성했기 때문에, 논문의 흐름이 불규칙하거나 불필요한 반복이 발생하는 경우가 많았습니다. 이에 반해, SurveyX는 “Outline Optimization(아웃라인 최적화)” 기법을 도입하여 보다 체계적인 서베이 구조를 구성합니다. 이 과정에서는 1차 아웃라인(primary outline)과 2차 아웃라인(secondary outline)을 단계적으로 생성하는 방식을 채택합니다. 1차 아웃라인은 LLM이 일반적인 논문 구조(예: “Introduction”, “Background”, “Methods”, “Experiments”, “Conclusion”)를 기반으로 작성하며, 2차 아웃라인은 AttributeTree에서 추출된 논문의 핵심 정보를 참고하여 보다 세부적인 주제를 포함하는 방식으로 구성됩니다. 이를 통해, 논리적으로 일관된 서베이의 틀을 완성할 수 있으며, 연구 간의 연결성을 보다 명확하게 드러낼 수 있습니다.
두 번째 과정인 본문 생성(Content Generation) 단계에서는, SurveyX가 RAG(Retrieval-Augmented Generation) 기반 생성 방식을 활용하여 논문에서 검색된 정보를 바탕으로 보다 정확하고 신뢰할 수 있는 텍스트를 작성합니다. 기존 LLM 기반 서베이 생성 방식은 LLM이 내부 지식만을 활용하여 텍스트를 생성하는 방식이었기 때문에, 종종 잘못된 정보가 포함되거나, 최신 연구 동향을 반영하지 못하는 경우가 많았습니다. SurveyX는 이러한 문제를 해결하기 위해 논문 검색 단계에서 수집된 최신 연구 자료를 실시간으로 참조하며, AttributeTree 기반의 요약 데이터를 활용하여 보다 정보 밀도가 높은 서베이를 작성합니다. 또한, 본문 작성 과정에서 LLM이 다른 섹션에서 생성된 내용을 참고할 수 있도록 설계하여, 서베이 전반의 논리적 일관성을 유지할 수 있도록 했습니다.
세 번째 과정인 후처리(Post-Processing) 단계에서는, 자동 인용 검증 및 시각적 자료 추가를 통해 서베이의 품질을 한층 더 향상합니다. 기존 자동 생성 방식에서는 잘못된 인용(hallucinated citations) 문제가 자주 발생했으며, 텍스트 기반 서베이는 정보 전달력이 떨어지는 경우가 많았습니다. SurveyX는 RAG 기반의 재작성(Rewriting) 기법을 활용하여 생성된 문장을 다시 논문 데이터와 비교하여 인용 오류를 자동으로 수정하며, 불필요한 인용을 제거하고 보다 정확한 참고 문헌을 추가할 수 있도록 설계되었습니다. 또한, 표 및 그래프 생성 모듈을 추가하여 숫자 데이터나 연구 비교 결과를 시각적으로 표현함으로써, 보다 효과적인 정보 전달이 가능하도록 했습니다. 이를 통해, SurveyX는 기존 자동화 서베이 생성 방식보다 훨씬 더 신뢰할 수 있는 고품질의 학술 서베이를 생성할 수 있습니다.
실험 및 결과
실험 개요
SurveyX는 기존 자동 서베이 생성 시스템보다 높은 성능을 보이며, 이를 검증하기 위해 다양한 실험을 진행했습니다. 실험의 목표는 SurveyX가 생성한 서베이가 기존 시스템과 비교했을 때 얼마나 신뢰성 있고, 논리적으로 구조화되어 있으며, 정확한 인용을 포함하는지 평가하는 것입니다. 이를 위해, 연구팀은 자동 평가(Automated Evaluation)와 인간 평가(Human Evaluation)를 병행하여 종합적인 분석을 수행했습니다.
SurveyX의 성능을 정량적으로 평가하기 위해 총 세 가지 주요 평가 항목을 설정했습니다:
- 서베이 내용 품질(Content Quality)
- Coverage (포함도): 서베이가 해당 주제의 핵심 내용을 얼마나 충실하게 다루었는지를 평가합니다.
- Structure (구조적 완성도): 생성된 서베이의 논리적 구성과 일관성을 평가합니다.
- Relevance (연관성): 서베이가 특정 연구 주제와 얼마나 밀접한 관련이 있는지 측정합니다.
- Synthesis (정보 종합력): 개별 연구를 단순히 나열하는 것이 아니라, 연구 간의 관계를 분석하고 유의미한 통찰을 제공하는지를 평가합니다.
- Critical Analysis (비판적 분석): 서베이가 연구 결과에 대한 비판적 논의를 포함하고 있는지 여부를 측정합니다.
- 인용 품질(Citation Quality)
- Citation Recall (정확한 인용률): 서베이에 포함된 문장이 실제로 논문에서 확인 가능한지를 평가합니다.
- Citation Precision (불필요한 인용률): 잘못된 인용이 포함되어 있는지 확인하여, 서베이의 신뢰도를 측정합니다.
- Citation F1 Score: Recall과 Precision의 조화 평균을 통해 인용의 전반적인 품질을 평가합니다.
- 참고 문헌의 적절성(Reference Relevance)
- IoU (Insertion over Union): SurveyX가 검색한 논문과 인간 전문가가 수집한 논문이 얼마나 일치하는지를 측정합니다.
- Relevance_semantic (임베딩 기반 연관성 평가): 검색된 논문이 주제와 얼마나 밀접한 관련이 있는지 임베딩 모델을 활용하여 평가합니다.
- Relevance_LLM (LLM 기반 연관성 평가): LLM을 활용하여 검색된 논문의 중요도를 직접 분석합니다.
생성 문서 예시

| 제목 (한국어 / 영어) | 키워드 |
|---|---|
| BERT에서 GPT-4까지: 사전 학습된 언어 모델의 아키텍처 혁신에 대한 연구 / From BERT to GPT-4: A Survey of Architectural Innovations in Pre-trained Language Models | Transformer, BERT, GPT-3, self-attention, masked language modeling, cross-lingual transfer, model scaling |
| 비지도 학습 기반 다국어 단어 임베딩 정렬: 기법 및 응용 / Unsupervised Cross-Lingual Word Embedding Alignment: Techniques and Applications | low-resource NLP, few-shot learning, data augmentation, unsupervised alignment, synthetic corpora, NLLB, zero-shot transfer |
| 비전-언어 사전 학습: 아키텍처, 벤치마크 및 최신 트렌드 / Vision-Language Pre-training: Architectures, Benchmarks, and Emerging Trends | multimodal learning, CLIP, Whisper, cross-modal retrieval, modality fusion, video-language models, contrastive learning |
| 대규모 자연어 처리 모델의 효율적 압축 기법 리뷰 / Efficient NLP at Scale: A Review of Model Compression Techniques | model compression, knowledge distillation, pruning, quantization, TinyBERT, edge computing, latency-accuracy tradeoff |
| 도메인 특화 NLP: 의료, 법률, 금융 분야 모델 적응 / Domain-Specific NLP: Adapting Models for Healthcare, Law, and Finance | domain adaptation, BioBERT, legal NLP, clinical text analysis, privacy-preserving NLP, terminology extraction, few-shot domain transfer |
| 대규모 언어 모델의 어텐션 헤드 분석 / Attention Heads of Large Language Models: A Survey | attention head, attention mechanism, large language model, LLM, transformer architecture, neural networks, natural language processing |
| 대규모 언어 모델의 제어 가능한 텍스트 생성 연구 / Controllable Text Generation for Large Language Models: A Survey | controlled text generation, text generation, large language model, LLM, natural language processing |
| 대규모 언어 모델 평가에 관한 연구 / A Survey on Evaluation of Large Language Models | evaluation of large language models, large language models assessment, natural language processing, AI model evaluation |
| 생성적 정보 추출을 위한 대규모 언어 모델 연구 / Large Language Models for Generative Information Extraction: A Survey | information extraction, large language models, LLM, natural language processing, generative AI, text mining |
| 대규모 언어 모델의 내부 일관성과 자체 피드백 / Internal Consistency and Self-Feedback of LLM | Internal consistency, self feedback, large language model, LLM, natural language processing, model evaluation, AI reliability |
| 다중 에이전트 오프라인 강화 학습 연구 / Review of Multi-Agent Offline Reinforcement Learning | multi agent, offline policy, reinforcement learning, decentralized learning, cooperative agents, policy optimization |
| 대규모 언어 모델의 추론 능력 연구 / Reasoning of Large Language Models: A Survey | reasoning of large language models, large language models, LLM, natural language processing, AI reasoning, transformer models |
| 계산 복잡도의 위계 정리: 시간-공간 절충에서 오라클 분리까지 / Hierarchy Theorems in Computational Complexity: From Time-Space Tradeoffs to Oracle Separations | P vs NP, NP-completeness, polynomial hierarchy, space complexity, oracle separation, Cook-Levin theorem |
| 양자 회로의 고전적 시뮬레이션: 복잡성 장벽 및 의미 / Classical Simulation of Quantum Circuits: Complexity Barriers and Implications | BQP, quantum supremacy, Shor's algorithm, post-quantum cryptography, QMA, hidden subgroup problem |
| 커널화: 이론, 기법, 한계 / Kernelization: Theory, Techniques, and Limits | fixed-parameter tractable (FPT), kernelization, treewidth, W-hierarchy, ETH (Exponential Time Hypothesis), parameterized reduction |
| 일관성 모델과 분산 데이터베이스: ACID에서 NewSQL까지 / Consistency Models in Distributed Databases: From ACID to NewSQL | CAP theorem, ACID vs BASE, Paxos/Raft, Spanner, NewSQL, sharding, linearizability |
| AI 기반 자율 관리 데이터베이스 연구 / Self-Driving Databases: A Survey of AI-Powered Autonomous Management | autonomous databases, learned indexes, query optimization, Oracle AutoML, workload forecasting, anomaly detection |
| AI를 위한 벡터 데이터베이스: 효율적 유사 검색 및 검색 증강 생성 / Vector Databases for AI: Efficient Similarity Search and Retrieval-Augmented Generation | vector database, FAISS, Milvus, ANN search, embedding indexing, RAG (Retrieval-Augmented Generation), HNSW |
| 플로우 배터리에 대한 연구 / A Survey on Flow Batteries | battery electrolyte formulation |
| 배터리 전해질 조성 연구 / Research on Battery Electrolyte Formulation | flow batteries |
(사용자 요청에 따른) 생성 문서 예시
| 제목 (한국어 / 영어) | 키워드 |
|---|---|
| 생각하고 그려라! 이해하고 생성할 수 있는 비전-MLLM에 대한 연구 / Think and Draw! A survey on Vision-MLLMs that can understand and generate | vision-language models, multimodal learning, generative AI |
| 대화 이해를 위한 새로운 의도 탐지 및 발견 연구 / A Survey of new intent detection and discovery for Conversational Understanding | Out-of-domain Detection, New Intent Discovery, Generalized Category Discovery |
| 의료 영상에서 Segment Anything Model (SAM) 연구: 비전 기반 모델의 발전 / A Survey of Segment Anything Model (SAM) in Medical Imaging: Advances in Vision Foundation Models | Segment Anything Model (SAM), Medical Image Segmentation, Vision Foundation Models, Prompt Engineering, Efficient Fine-Tuning |
| 의료 개체 및 관계의 공동 추출 연구 / A Survey of joint extraction of medical entities and relations | Medical Entity Recognition, Joint Extraction, Relation Extraction, Biomedical Text Mining, Deep Learning |
| 대규모 언어 모델을 위한 강화 학습: 방법론, 도전 과제 및 응용 / Reinforcement Learning for Large Language Models: Methods, Challenges, and Applications | Large Language Models, Reinforcement Learning, RLHF, Reward Modeling, AI Alignment, Fine-Tuning, Prompt Optimization, Self-Supervised Learning, Model-based RL, Meta-Reinforcement Learning, AI Agents, Multi-Agent Reinforcement Learning (MARL), Curriculum Learning, Few-Shot Learning, Continual Learning, Adaptive Learning, Human-in-the-Loop Learning |
| 대규모 언어 모델의 추론을 위한 프로세스 보상 모델 / Process Reward Models for LLM Reasoning | Process Reward Model, Reasoning, Large Language Model |
| 강유전체성과 스커미온, 교대자기 및 페로밸리를 결합한 새로운 다중강유전체 / Novel Multiferroics coupling ferroelectricity with Skyrmion, altermagnetism or Ferrovalley | Multiferroic, Skyrmion, altermagnetism, Ferrovalley, ferroelectricity |
| 사후 진단을 위한 심장 마커 CKMB와 LDH의 비교 연구 / Comparative study of cardiac markers CKMB and LDH in pericardial fluid for postmortem diagnosis | Forensic medicine, Postmortem diagnosis, Sample timing, Cardiac muscle fibers, Myocardial infarction |
| 하이브리드 인간-인공지능에 대한 다차원적 관점: 대규모 언어 모델 시대의 기회와 도전 / A Multi-dimensional Perspective on Hybrid Human-Artificial Intelligence: Opportunities and Challenges in the Era of Large Language Models | Hybrid Human-Artificial Intelligence, Large Language Models, Deep Learning, Reinforcement learning |
| 임상 예측을 위한 다중 모달 시계열 데이터 융합 연구 / Multimodal fusion with Multimodal Temporal Data for Clinical prediction | Multimodal temporal data, Deep learning in healthcare, Clinical decision support systems (CDSS), Temporal alignment, Uncertainty quantification, Reinforcement learning in medicine, Medical image sequence analysis, Interpretable machine learning |
| 단위 테스트 케이스 생성 연구 / A Survey on Unit Test Case Generation | Unit Test, Unit Testing, Large Language Model |
| 포화된 이미지에 대한 블라인드 이미지 복원의 강건성 향상 / Enhancing Blind Image Deblurring Robustness Against Saturated Images | Blind Deblurring, Impulse Noise Detection, Non-convex Optimization, Saturated Images |
| 문서 이해를 위한 다중 모달 대규모 언어 모델 연구 / Document Understanding with Multi-modal Large Language Model: A Survey | Document Understanding, Multi-modal Large Language, Document AI, Document VQA |
| 대규모 언어 모델에서 발생하는 새로운 능력: 연구 개요 / Emergent Abilities in Large Language Models: a Survey | Large Language Models, Emergent Abilities |
| 딥러닝을 활용한 우울증 인식: 다중 모달 접근 방식 리뷰 / Deep learning for depression recognition with multimodal: A Review | Depression, Multimodal methods, Emotion recognition, Deep learning, Unimodal methods, Psychological abnormalities |
 SurveyX 홈페이지
SurveyX 홈페이지
 SurveyX 논문, SurveyX: Academic Survey Automation via Large Language
SurveyX 논문, SurveyX: Academic Survey Automation via Large Language
Models
 SurveyX GitHub 저장소
SurveyX GitHub 저장소
(코드 X, 생성 문서 저장용)
https://github.com/IAAR-Shanghai/SurveyX
더 읽어보기
-
Google, 과학 연구 과정에서 연구자를 돕는 'AI 공동연구자(AI Co-Scientist)' 공개 (feat. Gemini 2.0)
-
OpenAI의 Deep Research를 오픈소스로 재현한 3가지 프로젝트 소개 (feat. Hugging Face, Jina AI, Firecrawl)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()