
Perplexity의 Deep Research 소개
Perplexity가 OpenAI의 Deep Research와 유사한 기능을 출시했습니다. 기존에도 강력한 검색 및 질문 응답 기능을 제공하던 Perplexity가 이번에는 심층적인 연구와 분석까지 수행해주는 기능을 추가했습니다. 단순한 검색을 넘어 여러 소스를 분석하고 보고서까지 자동으로 생성하는 이 기능은 연구자, 마케터, 개발자 등 다양한 전문가들에게 큰 도움이 될 수 있습니다.
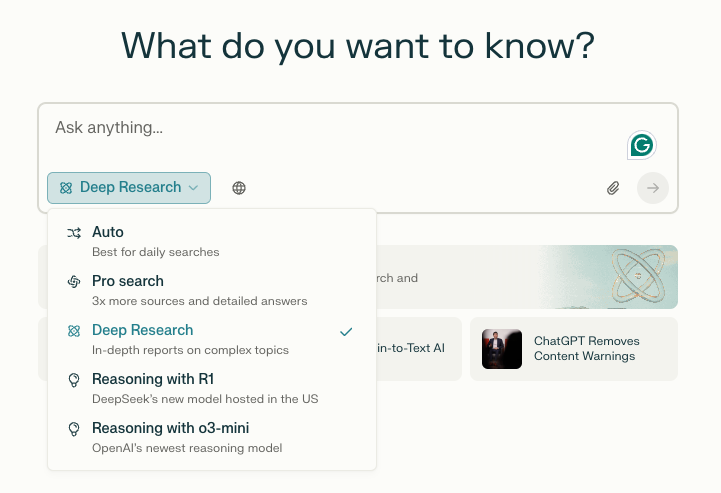
Perplexity Deep Research는 사용자가 질문을 입력하면 수십 개의 검색을 수행하고, 수백 개의 소스를 읽으며, 분석과 추론을 거쳐 종합적인 보고서를 생성하는 기능입니다. 이 과정은 보통 전문가가 몇 시간 동안 수행해야 하는 작업이지만, Deep Research는 단 몇 분 만에 이를 수행할 수 있습니다.
Perplexity의 Deep Research 주요 기능
- 고급 검색 및 분석: 검색과 코딩 기능을 활용해 문서를 읽고, 논리적으로 연구 계획을 수립하며, 필요한 정보를 선별
- 보고서 자동 생성: 검토한 자료를 바탕으로 체계적인 보고서를 작성
- PDF 및 공유 기능: 생성된 보고서를 PDF 또는 문서로 변환해 공유 가능
Deep Research는 단순한 질문 응답을 넘어서 재무, 마케팅, 기술 분석, 여행 계획, 건강 연구 등 다양한 분야에서 전문가 수준의 분석을 제공하는 것을 목표로 합니다.
Perplexity의 Deep Research 예시
금융 / Finance

마케팅 / Marketing
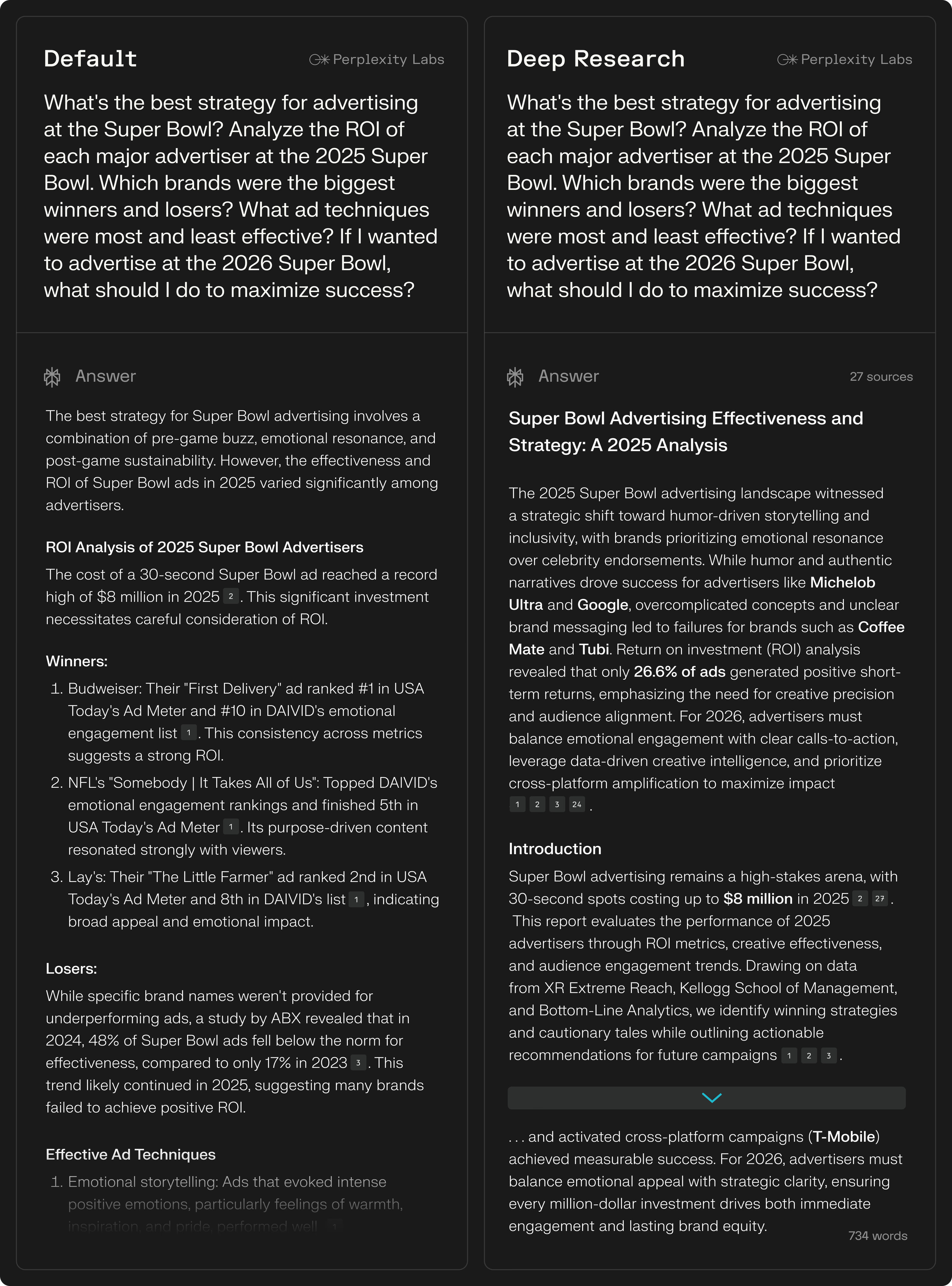
기술 / Technology
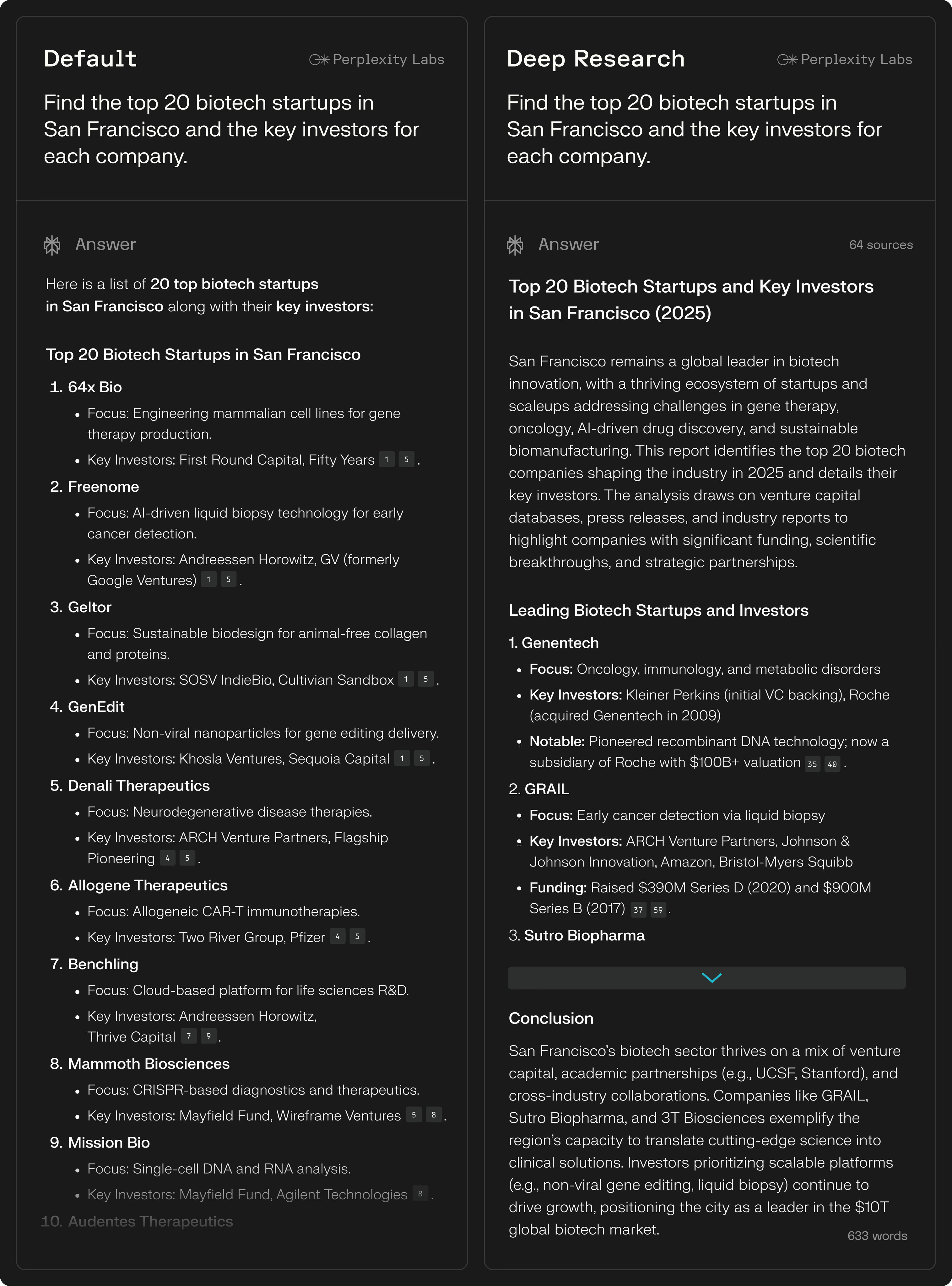
시사 / Current Affairs
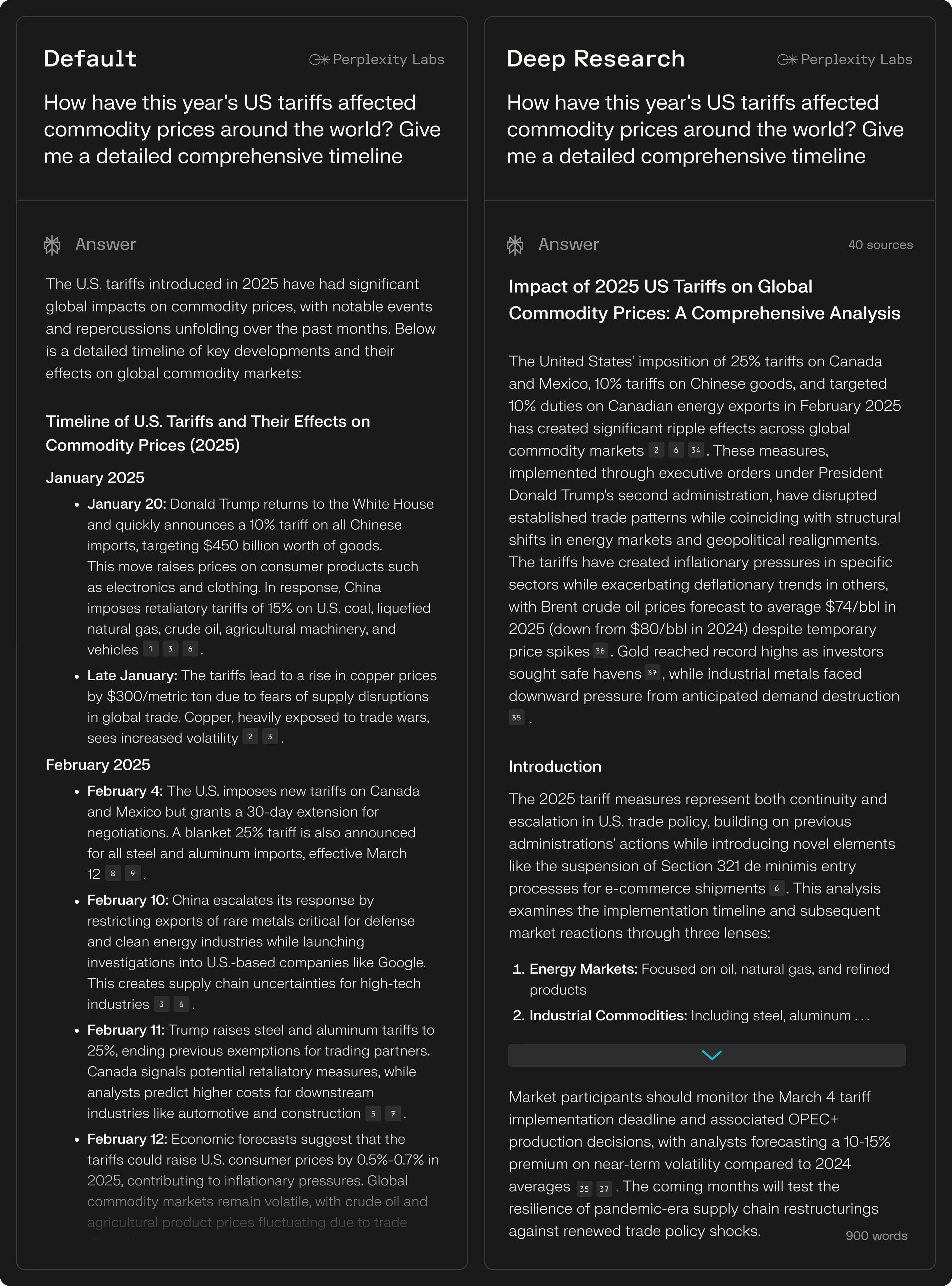
건강 / Health

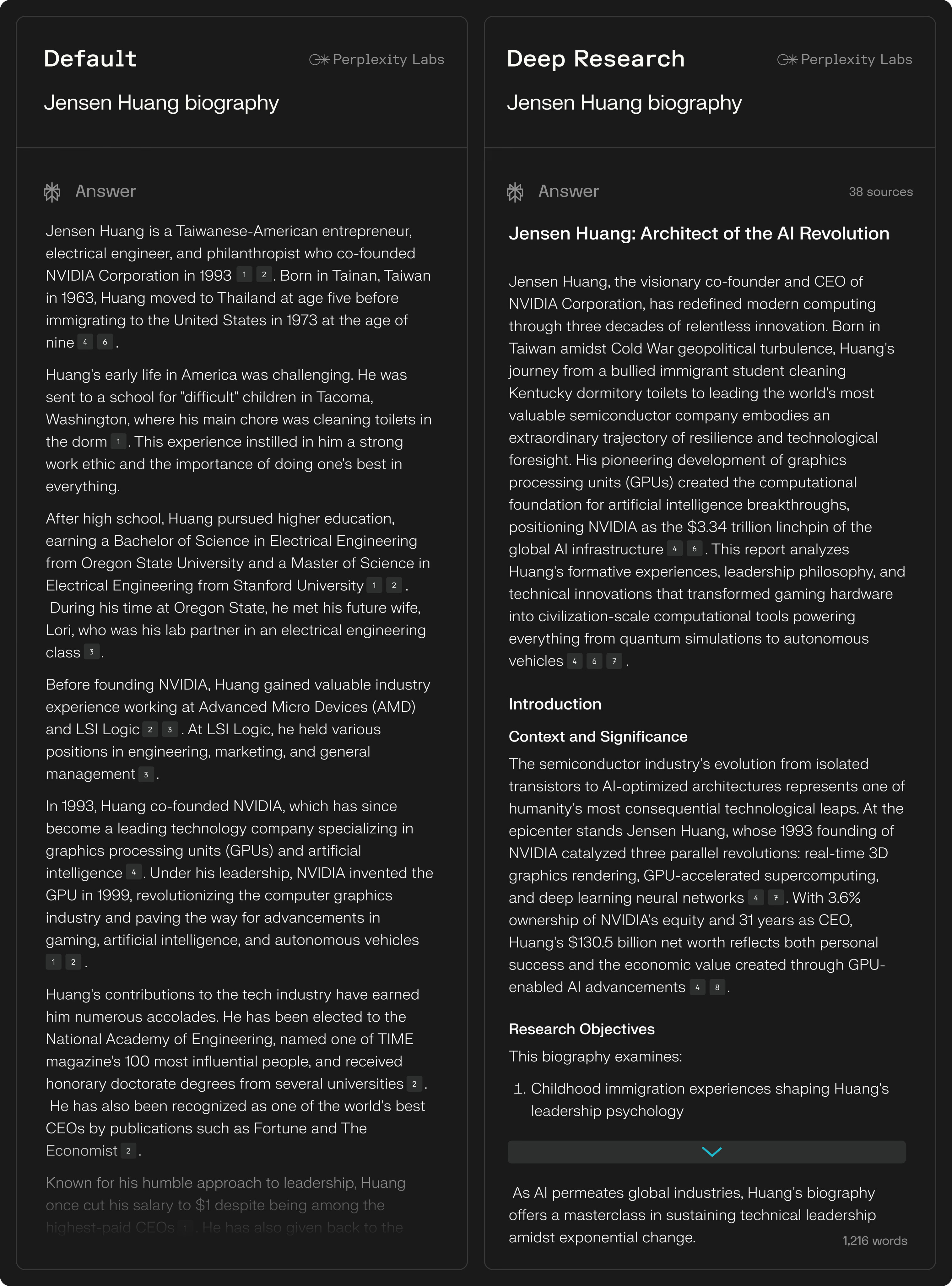
전기 / Biography
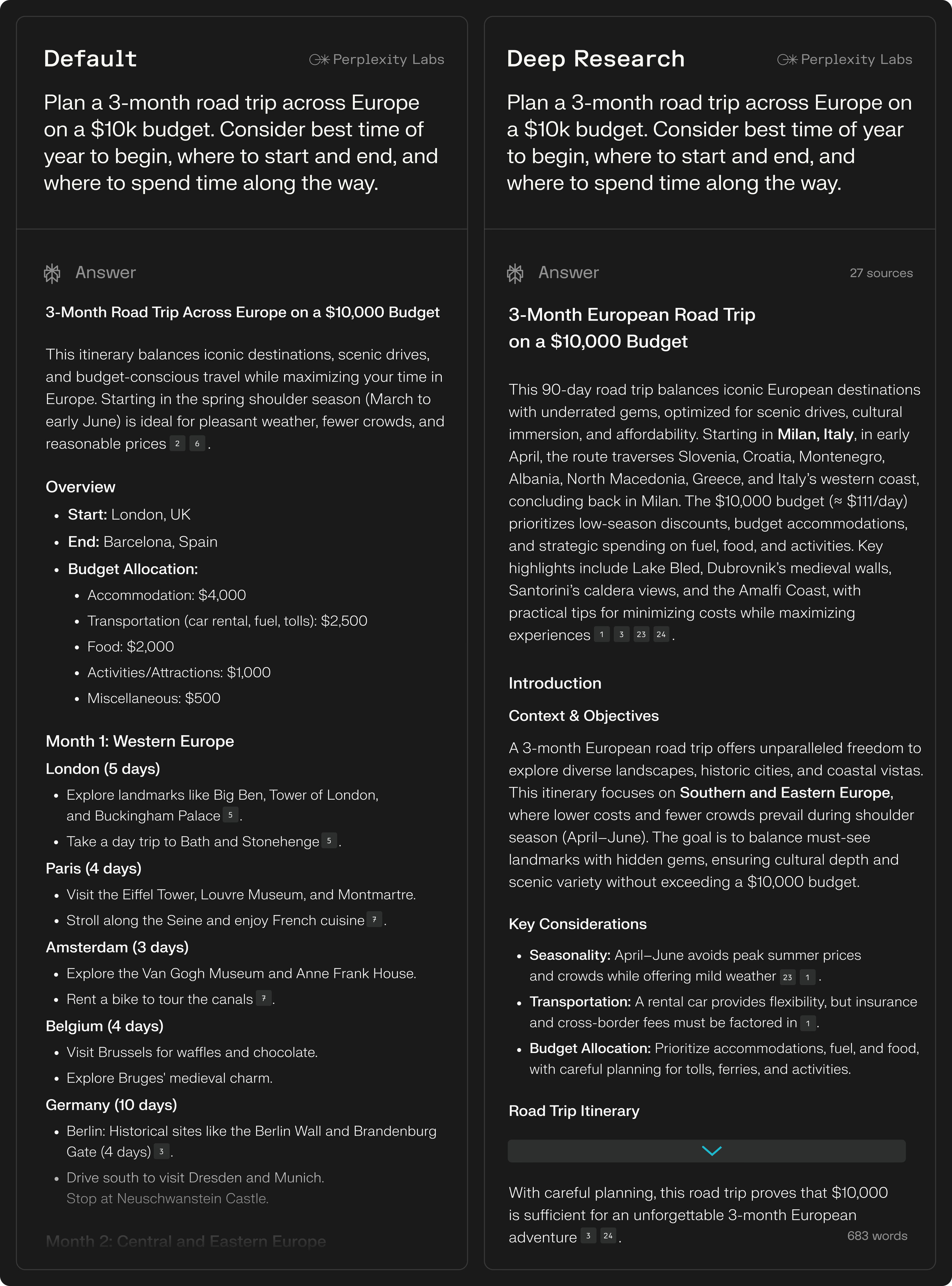
여행 / Travel
성능
Humanity’s Last Exam에서 21.1%의 정확도 기록
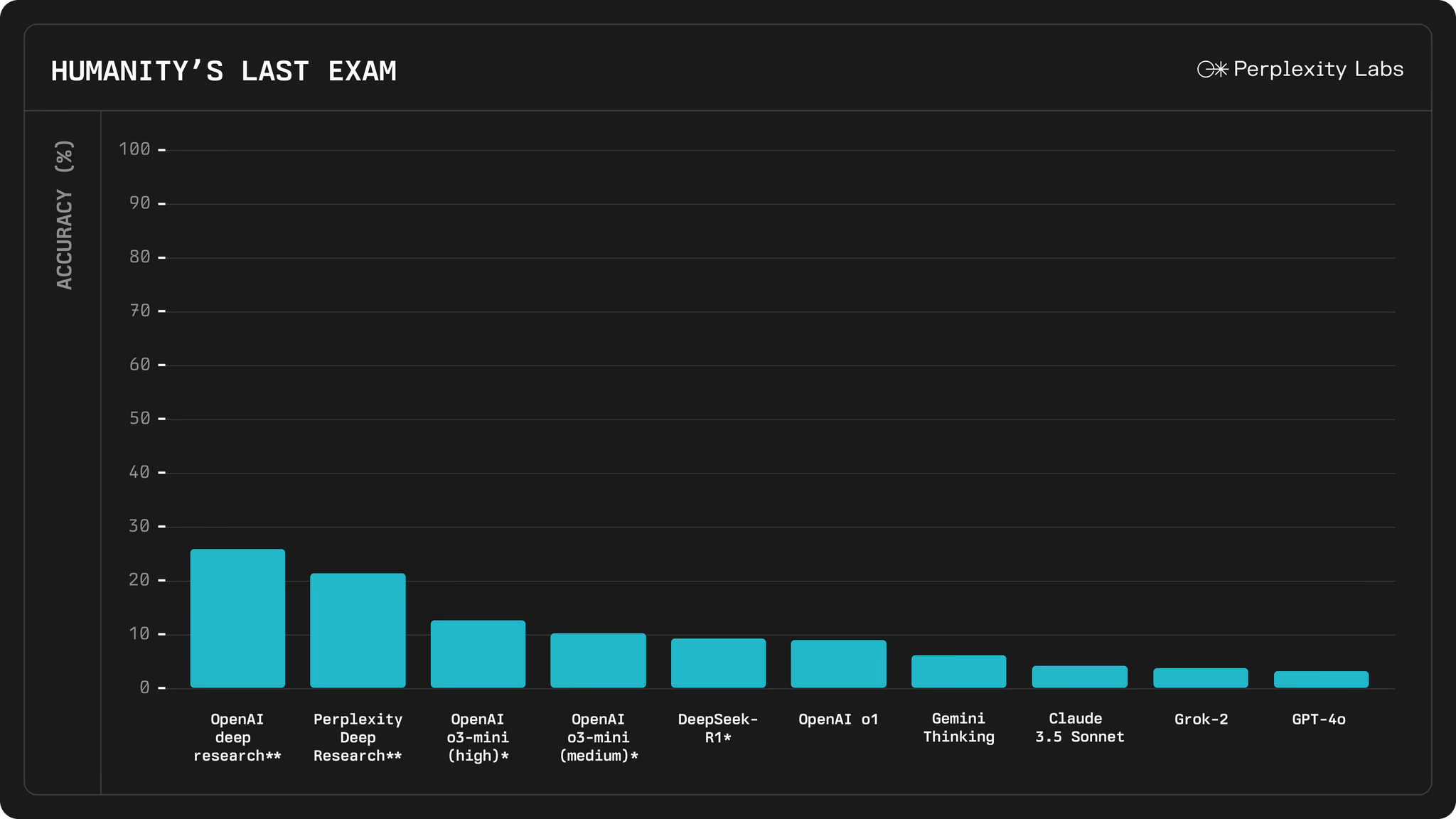
Humanity’s Last Exam은 100개 이상의 과목(수학, 과학, 역사, 문학 등)에 걸쳐 3,000개 이상의 질문으로 구성된 AI 평가 벤치마크입니다. 이 시험에서 Perplexity Deep Research는 21.1%의 정확도를 기록, 다음과 같은 주요 AI 모델보다 높은 성능을 보였습니다. 이는 광범위한 지식과 논리적 사고를 요구하는 복잡한 질문들에 대해 Perplexity가 뛰어난 분석 능력을 보여주었음을 의미합니다.
SimpleQA 벤치마크에서 93.9%의 정확도 달성
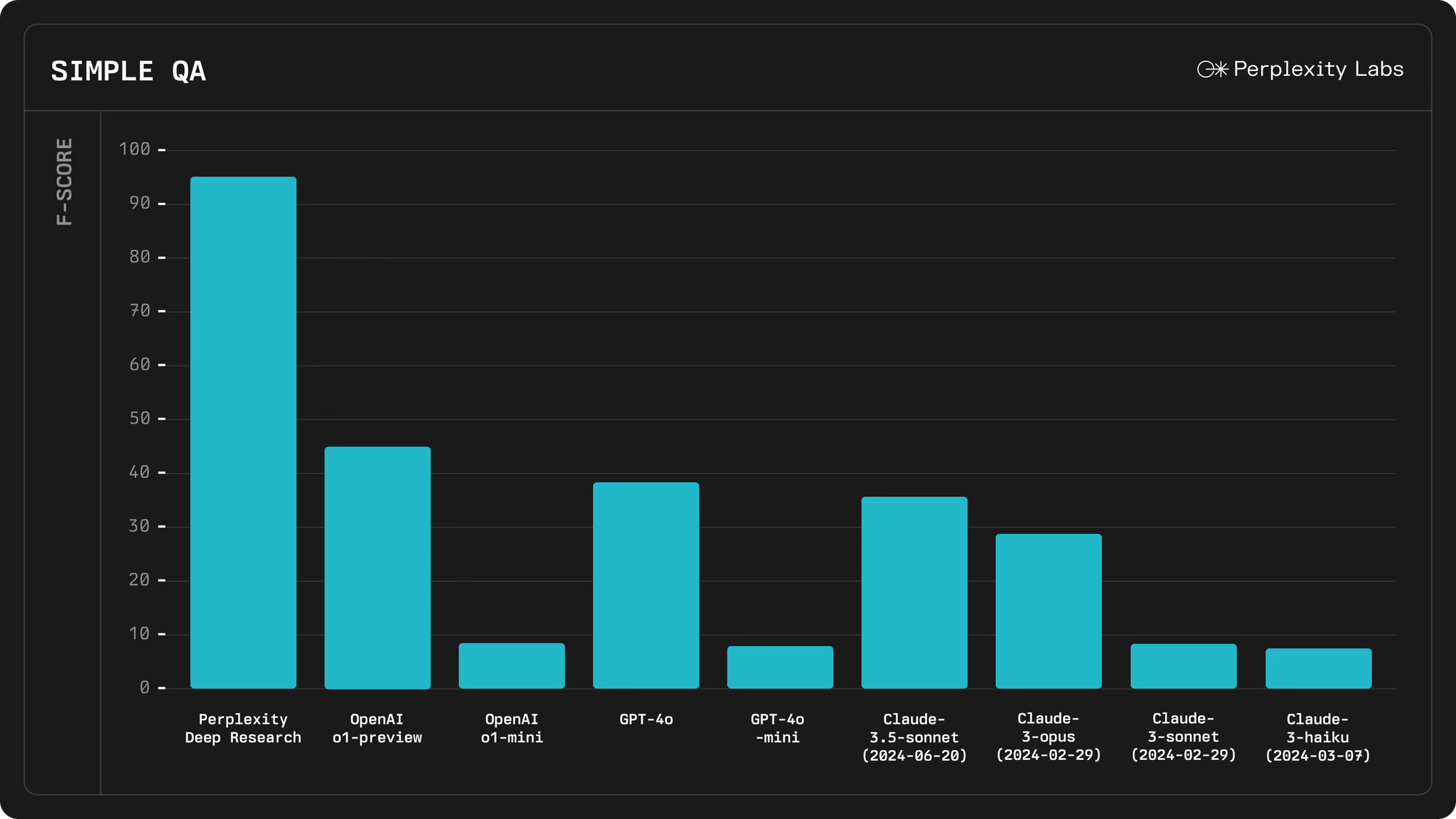
SimpleQA는 사실 확인(Factuality) 능력을 평가하는 대표적인 AI 벤치마크입니다. Perplexity Deep Research는 93.9%의 정확도로 업계 최고 수준의 AI 모델을 능가하는 성과를 기록했습니다. 이는 단순한 검색을 넘어 신뢰할 수 있는 정보를 정확하게 추출하고, 이를 기반으로 응답을 생성하는 능력이 뛰어나다는 것을 보여줍니다.
빠른 실행 속도 – 대부분의 연구 작업을 3분 이내 완료
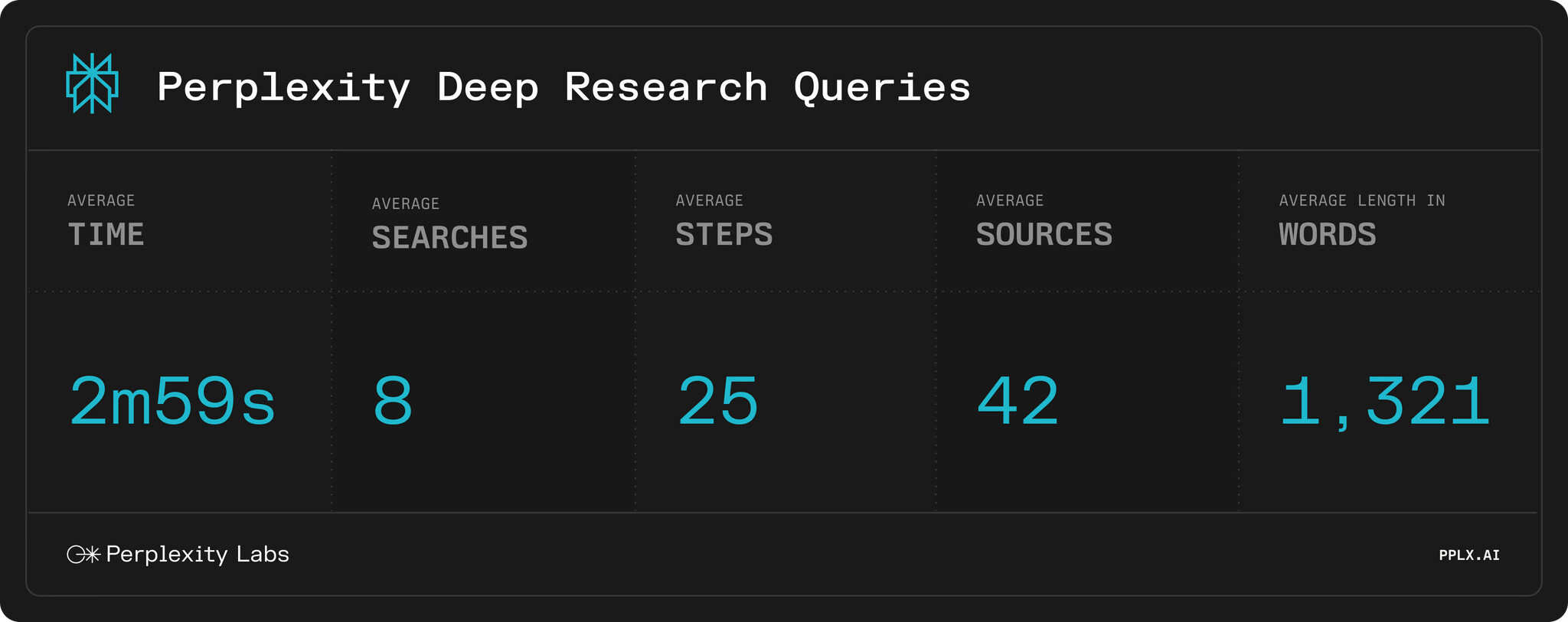
Deep Research는 높은 정확도를 자랑하면서도, 연구 및 보고서 작성 속도가 매우 빠릅니다. 대부분의 연구 질문에 대해 3분 이내에 종합적인 보고서를 생성했으며, 향후 더 빠른 속도를 목표로 개선 작업 진행 중입니다. 이는 단순한 AI 검색 엔진이 아닌, 전문가 수준의 분석을 자동으로 수행하는 도구로 활용할 수 있음을 의미합니다.
 Perplexity에서 Deep Research 사용해보기
Perplexity에서 Deep Research 사용해보기
https://www.perplexity.ai/?model_id=deep_research
 Perplexity의 Deep Research 기능 출시 블로그
Perplexity의 Deep Research 기능 출시 블로그
https://www.perplexity.ai/hub/blog/introducing-perplexity-deep-research
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()