TabFM 소개
새로운 예측 문제를 만났을 때 우리는 보통 데이터를 정제하고, 어떤 특징(feature)을 만들지 고민하고, 모델을 여러 번 학습시키며 하이퍼파라미터를 조금씩 바꿔가는 지루한 과정을 반복합니다. 정작 문제의 본질을 파악하는 시간보다, 모델이 신호를 잡아내도록 데이터를 다듬는 부수적인 작업에 더 많은 시간을 쏟곤 합니다.
TabFM(Tabular Foundation Model)은 이 지루한 반복을 없애기 위해 Google Research가 공개한 표 형식 데이터(tabular data)를 위한 제로샷(zero-shot) 파운데이션 모델입니다. 표 형식 데이터의 분류(classification)와 회귀(regression) 작업을, 별도의 학습이나 하이퍼파라미터 탐색 없이 단 한 번의 순전파(single forward pass) 로 처리하는 것을 목표로 합니다. Google은 앞서 시계열 예측 분야에서 TimesFM으로 제로샷 접근의 가능성을 보여준 바 있는데, TabFM은 바로 그 제로샷 논리를 표 형식 데이터로 확장한 결과물입니다. 이 글에서는 TabFM이 어떤 문제를 어떻게 푸는지, 그 구조와 성능을 자세히 살펴봅니다.
표 형식 데이터와 기존 접근법의 한계
표 형식 데이터는 기업 데이터 인프라의 근간이며, 실무에서 쓰이는 예측형 머신러닝 응용의 상당 부분을 차지합니다. 고객 이탈 예측부터 금융 사기 탐지까지, 표에 담긴 행과 열을 다루는 분류와 회귀 작업은 어디에나 존재합니다. 오랫동안 이 영역은 AdaBoost, XGBoost, 랜덤 포레스트(Random Forest) 같은 트리 기반의 지도학습 알고리즘이 지배해 왔습니다. 이들은 정형 데이터에서 견고한 성능을 보여주었습니다.
하지만 이런 전통적인 모델을 실제로 배포하기까지의 과정에는 큰 병목이 있습니다. 새로운 데이터셋에 XGBoost 모델을 맞추는 일은 단순히 .fit() 한 번으로 끝나지 않습니다. 데이터 과학자는 원본 데이터에서 신뢰할 만한 신호를 뽑아내기 위해 광범위한 하이퍼파라미터 최적화(hyperparameter optimization)와 도메인 특화 특징 공학(feature engineering)에 수많은 시간을 투자해야 합니다. 즉, 모델을 배포할 때마다 매번 이 지루한 수작업을 되풀이해야 한다는 뜻입니다.
한편 최근 대형 언어 모델(Large Language Model, LLM)의 발전은 새로운 작업을 다루는 방식을 근본적으로 바꾸어 놓았습니다. LLM은 인컨텍스트 학습(In-Context Learning, ICL)을 통한 제로샷 예측의 강력함을 보여주었습니다. 이 기법은 사전 학습된 모델이 입력 컨텍스트에 예시와 지시를 제공하는 것만으로 새로운 작업을 학습하게 하며, 이 과정에서 모델의 가중치를 전혀 갱신하지 않습니다. 학생이 시험장에서 예제 문제 몇 개를 보고 곧바로 새 문제를 푸는 것과 비슷합니다.
발상의 전환: 표 예측을 인컨텍스트 학습 문제로
TabFM의 핵심 아이디어는 표 형식 데이터의 예측을 하나의 인컨텍스트 학습 문제로 재구성(reframing) 하는 것입니다. 데이터셋마다 모델을 새로 학습시키는 대신, TabFM은 과거의 학습 예시(training examples)와 예측하려는 테스트 행(test rows)을 통째로 하나의 프롬프트로 받아들입니다. 그리고 추론 시점(inference time)에 이 컨텍스트로부터 열과 행 사이의 관계를 직접 해석해 예측을 만들어 냅니다.
이 접근은 수작업 모델 학습, 하이퍼파라미터 튜닝, 복잡한 특징 공학의 필요성을 없앱니다. 사용자는 이전에 본 적 없는 표에 대해서도 단 한 번의 순전파로 높은 품질의 예측을 얻을 수 있습니다. 트리 모델이 "데이터셋마다 새로 훈련하는 도구"였다면, TabFM은 "새 표를 보여주기만 하면 바로 답을 내놓는 파운데이션 모델"인 셈입니다.
TabFM의 동작 원리
전통적인 머신러닝 패러다임은 주어진 데이터셋의 분포에 맞추어 모델 파라미터를 갱신하는 데 의존합니다. 반면 ICL 패러다임은 이 과정을 완전히 우회합니다. 새로운 작업마다 별도의 학습 단계를 거치는 대신, TabFM은 학습 예시와 테스트 행을 포함한 데이터셋 전체를 하나의 통합된 프롬프트로 받고, 추론 시점에 이 컨텍스트에서 열과 행의 관계를 곧바로 해석합니다.
그런데 ICL을 표 형식 데이터에 적용하는 일은 자연어를 토큰화하는 것만큼 단순하지 않습니다. 표준적인 언어 모델은 1차원의 순서 있는 시퀀스를 처리하지만, 표는 본질적으로 2차원이며 순서가 없습니다(orderless). 두 행이나 두 열을 서로 바꿔도 데이터가 담고 있는 의미는 달라지지 않습니다. 이 다양한 표 구조를 효과적으로 처리하면서도 확장 가능한 제로샷 예측을 가능하게 하기 위해, TabFM은 TabPFN과 TabICL의 강점을 결합한 새로운 하이브리드 구조를 설계했습니다.
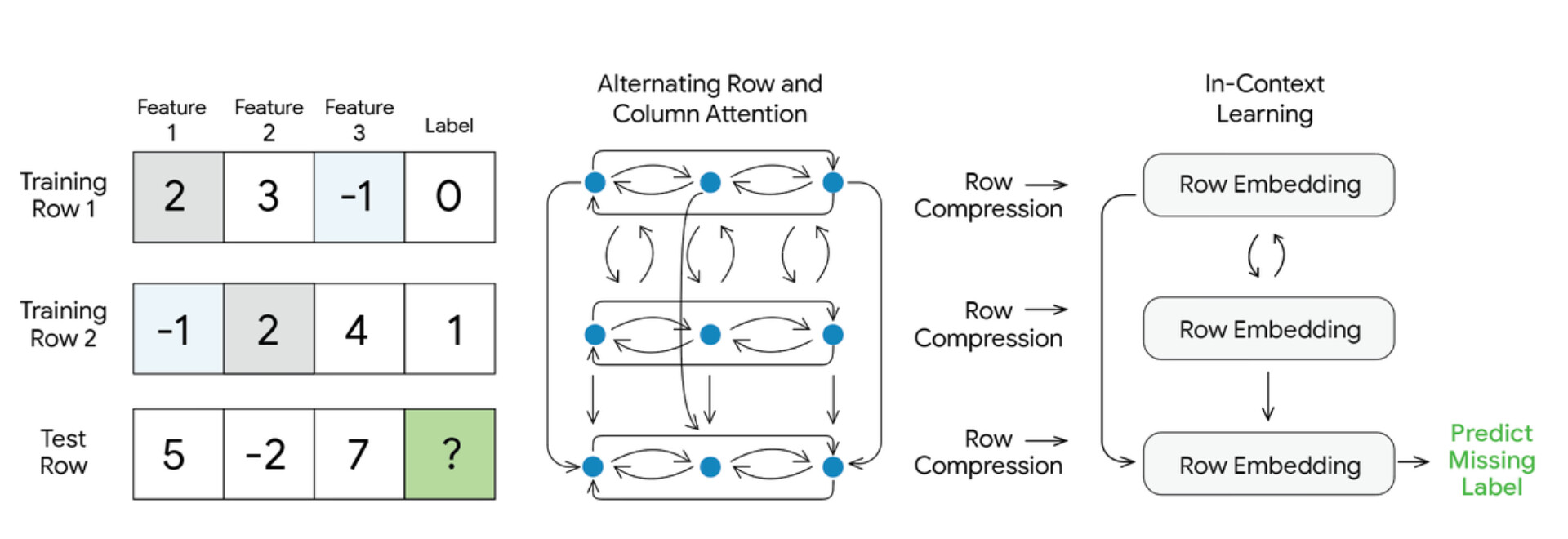
이 구조는 세 가지 핵심 메커니즘으로 이루어집니다.
행과 열을 번갈아 보는 교차 어텐션 (Alternating Row and Column Attention)
먼저 원본 표는 여러 층으로 쌓인 어텐션(attention) 모듈을 거칩니다. TabPFN과 유사하게, 이 단계는 열(특징)과 행(예시) 양쪽 방향으로 어텐션을 번갈아 적용합니다. 두 차원을 오가며 지속적으로 주의를 기울이면서, 모델은 복잡한 특징 간 상호작용과 의존 관계를 자연스럽게 포착하는 풍부한 표현(representation)을 학습합니다.
여기서 중요한 점은, 이 깊은 문맥화(contextualization)가 바로 데이터 과학자가 손수 해야 했던 특징 공학의 무거운 부담을 대신 짊어진다 는 것입니다. 어떤 열과 어떤 열을 조합해야 신호가 생기는지를 모델이 어텐션을 통해 스스로 찾아내므로, 사람이 미리 파생 변수를 만들어 줄 필요가 줄어듭니다.
Hugging Face 모델 카드에 공개된 세부 사항을 보면, 이 열 어텐션은 Set Transformer 계열의 구조를 씁니다. 각 셀(cell)을 푸리에 특징(Fourier features)과 그룹별 선형 투영으로 임베딩한 뒤, 유도 자기 어텐션(induced self-attention)을 통해 행 방향으로 집계합니다. 이는 표의 순서 없는 성질을 존중하면서도 열 전체의 통계적 관계를 담아내기 위한 설계입니다.
행 압축 (Row Compression)
교차 어텐션으로 문맥화가 끝나면, 각 행에 대해 서로 교차 참조된 풍부한 정보를 하나의 조밀한 벡터(dense vector) 로 압축합니다. 여러 개의 CLS 토큰이 행 단위 어텐션을 통해 한 행의 내용을 요약하며, 이때 위치 정보를 담기 위해 회전 위치 임베딩(Rotary Position Embedding, RoPE)을 사용합니다.
이 압축 단계는 다음 단계의 계산량을 결정하는 핵심입니다. 원본 표의 모든 셀을 그대로 다음 단계로 넘기는 대신, 행 하나를 벡터 하나로 요약해 두면 이후 연산이 다루어야 할 대상의 크기가 크게 줄어듭니다.
인컨텍스트 학습 트랜스포머 (ICL Transformer)
마지막으로, 전용 트랜스포머(Transformer)가 이 압축된 임베딩들의 시퀀스 위에서 동작합니다. TabICL의 효율적인 접근을 채택하여, 원본의 압축되지 않은 격자(grid) 전체가 아니라 압축된 행 벡터들에 대해서만 어텐션을 수행합니다. 덕분에 계산 비용이 급격히 줄어들며, 훨씬 큰 데이터셋에서도 예측 단계가 높은 계산 효율을 유지합니다.
구체적으로 이 부분은 24개 블록으로 이루어진 인과적(causal) 트랜스포머로, 학습 행들을 컨텍스트로 취급하고 테스트 행들에 대한 예측을 출력합니다. 학습 예시가 담긴 앞쪽 행들의 정보를 참고해 뒤쪽 테스트 행의 빈 라벨을 채우는 방식으로, 마치 언어 모델이 앞선 문맥을 보고 다음 토큰을 예측하는 것과 같은 흐름을 표 데이터에 그대로 옮겨 놓은 것입니다.
주요 하이퍼파라미터
모델의 규모를 한눈에 보면 다음과 같습니다.
| 파라미터 | 값 |
|---|---|
| 임베딩 차원 | 256 |
| 열 어텐션 블록 | 3 개 (헤드 4, 유도점 256) |
| 행 어텐션 블록 | 3 개 (헤드 8, CLS 토큰 8) |
| ICL 트랜스포머 블록 | 24 개 (헤드 8) |
| 피드포워드 배율 | 4 |
| 최대 클래스 수 | 10 |
| 활성화 함수 | SwiGLU |
| 푸리에 특징 | 32 개 주파수 |
대규모 합성 데이터로 학습하기
파운데이션 모델을 만드는 일반적인 방법은 고용량 신경망을 방대하고 다양한 데이터로 학습시키는 것입니다. 그런데 표 형식 머신러닝에는 근본적인 걸림돌이 하나 있습니다. 고품질이면서 다양한 표 데이터셋, 특히 실제 산업 현장의 데이터 분석을 반영하는 대규모 표는 오픈소스 세계에 극단적으로 희소 하다는 점입니다. 산업 현장의 표는 독점 스키마와 민감한 정보를 담고 있어, 광범위한 사전 학습에 사용하기 어렵습니다.
합성 표(synthetic table)는 원하는 만큼 얼마든지 크게 생성할 수 있기 때문에, 이 규모의 파운데이션 모델을 사전 학습시키는 사실상 유일한 선택지입니다. 그래서 TabFM은 수억 개의 합성 데이터셋 만으로 전적으로 학습됩니다. 이 데이터셋들은 다양한 무작위 함수를 포함하는 구조적 인과 모델(Structural Causal Model, SCM)을 사용해 동적으로 생성됩니다.
이 대규모 합성 생성은 실제 표 데이터에 흔히 나타나는 폭넓은 분포와 복잡한 특징 관계를 포착합니다. SCM이라는 사전(prior)이 인과 구조와 특징 간 관계에 대한 귀납적 편향(inductive bias)을 모델에 심어 주는 것입니다. 그 결과, 뒤에서 벤치마크로 확인하듯이 모델은 학습 중 한 번도 본 적 없는 실제 표에도 잘 일반화됩니다. 합성 데이터만으로 학습했지만 현실의 표를 잘 다루는, 다소 역설적으로 보이는 결과가 SCM 기반 데이터 생성의 힘을 보여줍니다.
성능 및 벤치마크
TabFM을 기존 최고 수준(state-of-the-art) 방법들과 엄밀하게 비교하기 위해, 연구팀은 TabArena에서 평가를 수행했습니다. TabArena는 정면 대결(head-to-head)의 승률을 바탕으로 Elo 점수를 계산하는, 계속 갱신되는 살아있는(living) 벤치마크 시스템입니다. 이 종합 평가는 700 개부터 150{,}000 개까지의 표본 크기를 갖는 38 개 분류 데이터셋과 13 개 회귀 데이터셋, 총 51 개 데이터셋에 걸쳐 있습니다.
연구팀은 두 가지 구성을 벤치마크했습니다.
- TabFM: 모델의 있는 그대로(out-of-the-box)의 능력을 나타냅니다. 예측은 단 한 번의 순전파로 생성되며, 어떤 튜닝이나 교차 검증(cross-validation)도 필요하지 않습니다.
- TabFM-Ensemble: 성능을 한 단계 더 끌어올린 구성입니다. 교차 특징(cross features)과 특이값 분해(Singular Value Decomposition, SVD) 특징을 추가로 사용하고, 비음수 최소제곱(non-negative least squares) 솔버로 32-way 앙상블의 최적 가중치를 계산합니다. 분류 작업에서는 여기에 플랫 스케일링(Platt scaling)을 보정 단계로 추가합니다.
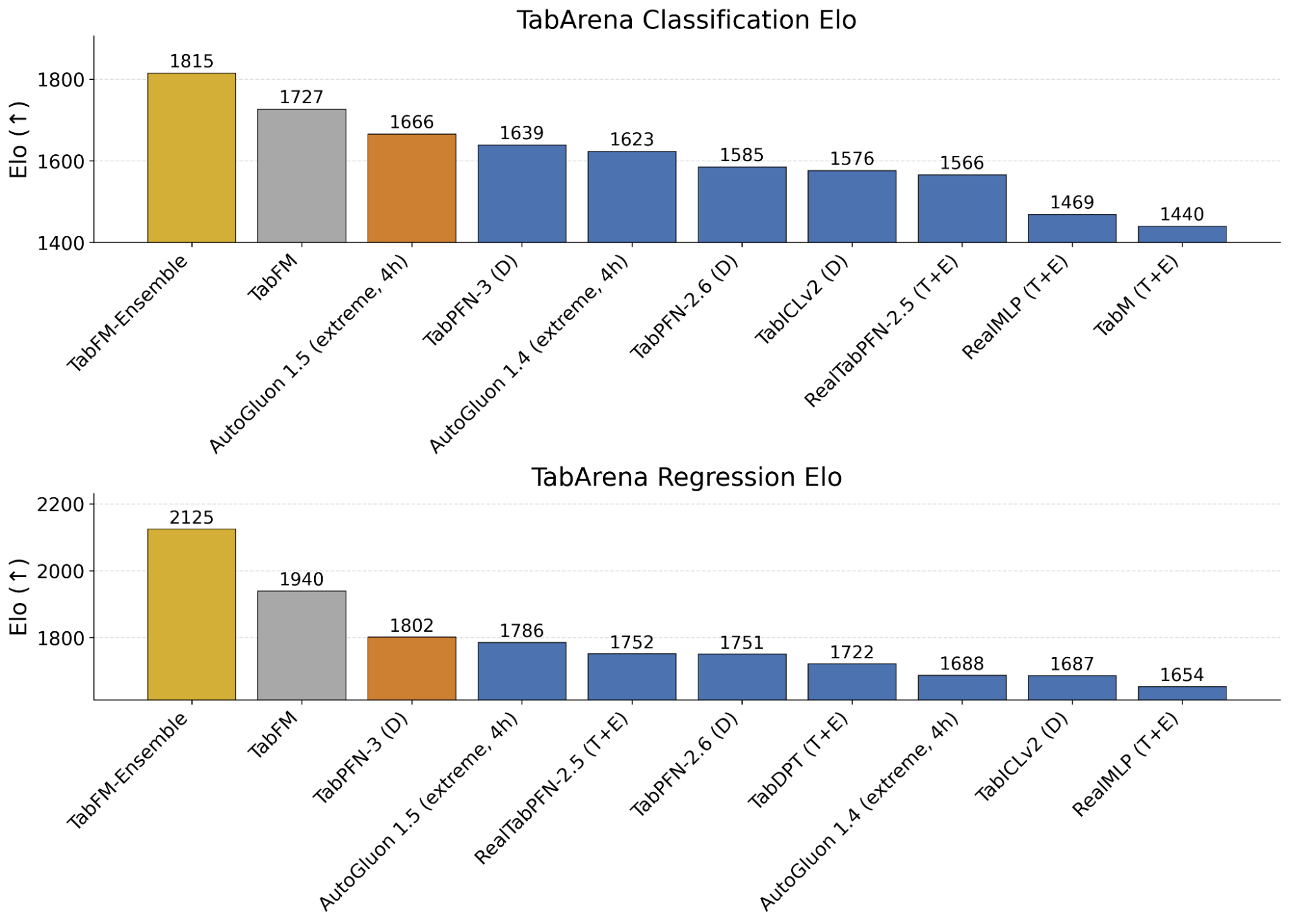
분류 성능
분류 벤치마크의 Elo 점수는 다음과 같습니다. 괄호 안의 표기에서 (D)는 기본 설정(Default), (T+E)는 튜닝과 앙상블(Tuned + Ensembled), (extreme, 4h)는 AutoGluon의 extreme 프리셋을 4 시간 예산으로 돌린 결과를 뜻합니다.
| 모델 | Elo (↑) |
|---|---|
| TabFM-Ensemble | 1815 |
| TabFM | 1727 |
| AutoGluon 1.5 (extreme, 4h) | 1666 |
| TabPFN-3 (D) | 1639 |
| AutoGluon 1.4 (extreme, 4h) | 1623 |
| TabPFN-2.6 (D) | 1585 |
| TabICLv2 (D) | 1576 |
| RealTabPFN-2.5 (T+E) | 1566 |
| RealMLP (T+E) | 1469 |
| TabM (T+E) | 1440 |
주목할 점은, 튜닝조차 하지 않은 순수 TabFM(1727)이 4 시간 동안 정성껏 튜닝한 AutoGluon 1.5(1666)를 앞선다는 것입니다. 여기에 앙상블을 더한 TabFM-Ensemble은 1815 로 격차를 더 벌립니다.
회귀 성능
회귀 벤치마크에서는 그 격차가 더욱 두드러집니다.
| 모델 | Elo (↑) |
|---|---|
| TabFM-Ensemble | 2125 |
| TabFM | 1940 |
| TabPFN-3 (D) | 1802 |
| AutoGluon 1.5 (extreme, 4h) | 1786 |
| RealTabPFN-2.5 (T+E) | 1752 |
| TabPFN-2.6 (D) | 1751 |
| TabDPT (T+E) | 1722 |
| AutoGluon 1.4 (extreme, 4h) | 1688 |
| TabICLv2 (D) | 1687 |
| RealMLP (T+E) | 1654 |
회귀에서 TabFM은 단일 순전파만으로 1940 을 기록해, 차순위인 TabPFN-3(1802)을 크게 앞섭니다. TabFM-Ensemble은 2125 에 도달하여 다른 모든 방법과 큰 차이를 만듭니다. 정리하면, TabFM은 무겁게 튜닝된 업계 표준 지도학습 알고리즘을 분류와 회귀 양쪽에서 일관되게 능가합니다. 더 상세한 폴드(fold)별 지표와 특정 베이스라인 대비 정면 승률은 GitHub 저장소의 results/ 디렉토리에서 확인할 수 있습니다.
TabFM 설치 및 사용 방법
TabFM은 scikit-learn과 호환되는 인터페이스로 제공되어, 기존에 fit/predict 패턴에 익숙한 사용자라면 곧바로 사용할 수 있습니다. GitHub 저장소를 복제한 뒤 원하는 백엔드(JAX 또는 PyTorch)로 설치합니다. Python 3.11 이상이 필요합니다.
git clone https://github.com/google-research/tabfm.git
cd tabfm
# PyTorch 백엔드 (CPU/GPU)
pip install -e .[pytorch]
# 또는 JAX 백엔드 (CPU)
pip install -e .[jax]
# JAX 백엔드 (GPU)
pip install -e .[jax,cuda]
Hugging Face에 공개된 사전 학습 가중치는 라이브러리가 자동으로 내려받아 로딩합니다. 아래는 분류 예시입니다. 별도의 학습 없이 fit으로 컨텍스트를 준비하고, predict로 곧바로 예측을 얻습니다.
import numpy as np
import pandas as pd
from tabfm import TabFMClassifier, tabfm_v1_0_0_pytorch as tabfm_v1_0_0
# 사전 학습된 분류 모델 로딩
model = tabfm_v1_0_0.load(model_type="classification")
clf = TabFMClassifier(model=model)
# 수치형과 범주형이 섞인 데이터셋도 그대로 지원
X_train = pd.DataFrame({
"age": [25.0, 45.0, 35.0, 50.0],
"job": ["engineer", "manager", "engineer", "manager"],
"income": [80000, 120000, 90000, 130000],
})
y_train = np.array(["low_risk", "high_risk", "low_risk", "high_risk"])
X_test = pd.DataFrame({
"age": [30.0, 48.0],
"job": ["engineer", "manager"],
"income": [85000, 125000],
})
clf.fit(X_train, y_train) # 순서형 인코더와 스케일러 준비
predictions = clf.predict(X_test) # 클래스 예측
probabilities = clf.predict_proba(X_test) # 클래스 확률
회귀도 동일한 패턴으로, TabFMRegressor 와 model_type="regression" 을 사용합니다. classification/ 과 regression/ 두 개의 체크포인트가 별도로 제공되며, 분류는 최대 10 개 클래스까지 지원합니다. 실행 가능한 전체 예제는 저장소의 examples/ 폴더에서 볼 수 있습니다.
한계점 및 향후 전망
TabFM은 강력하지만 몇 가지 명확한 제약을 함께 안고 있습니다. 첫째, 분류는 최대 10 개 클래스 까지만 지원합니다. 이는 완화할 수 있는 설정이 아니라 아키텍처 상의 고정된 한계입니다. 둘째, 모든 학습 행을 컨텍스트로 전달하는 구조이므로 메모리 사용량이 학습 행 수에 비례 해 증가합니다. 셋째, 최대 500 개 특징까지의 표에 최적화되어 있어, 열이 매우 많은 넓은 표에서는 성능이 저하될 수 있습니다. 넷째, 모든 데이터셋에서 작업 특화로 미세조정(fine-tuning)된 모델과 동등한 성능을 보장하지는 않습니다. 또한 이름 그대로 표 형식 데이터 전용 모델이므로, 이미지, 오디오, 원시 텍스트나 그래프, 시퀀스 같은 비정형 또는 비표(non-tabular) 데이터에는 적합하지 않습니다.
또한 TabFM은 전적으로 합성 데이터로만 학습되었기 때문에, 특정 실제 도메인이나 소수 집단, 분포의 경계 사례에 대한 성능은 아직 충분히 검증되지 않았습니다. 고위험(high-stakes) 환경에 배포하기 전에는 사용자의 실제 사용 사례를 대표하는 검증 데이터로 반드시 성능을 확인하는 것이 바람직합니다. 참고로 이 프로젝트는 정식으로 지원되는 Google 제품이 아니며, 소스 코드는 Apache 2.0 라이선스이지만 모델 가중치는 비상업 라이선스(TabFM Non-Commercial License v1.0)로 배포됩니다.
이런 한계에도 불구하고, TabFM은 표 형식 머신러닝의 작업 흐름을 근본적으로 바꿀 잠재력을 지니고 있습니다. 시계열 예측에서 TimesFM이 보여준 제로샷 접근을 표 데이터로 확장한 이 흐름은, "데이터셋마다 새로 훈련한다"는 오랜 관행을 "사전 학습된 모델에 표를 보여주기만 하면 된다"는 방향으로 옮겨 놓습니다. Google은 이를 실무에 더 가깝게 가져오기 위해 TabFM을 Google BigQuery에 직접 통합하고 있으며, 앞으로 사용자는 머신러닝 전문 지식 없이도 간단한 AI.PREDICT SQL 명령만으로 고급 회귀와 분류를 수행할 수 있게 될 예정입니다. 트리 기반 모델이 오래 지켜온 이 영역에서, 파운데이션 모델이 어디까지 표준을 다시 쓸 수 있을지 지켜볼 만합니다.
 Introducing TabFM 소개 블로그
Introducing TabFM 소개 블로그
 TabFM GitHub 저장소
TabFM GitHub 저장소
 google/tabfm-1.0.0-pytorch (Hugging Face)
google/tabfm-1.0.0-pytorch (Hugging Face)
 TabArena 리더보드
TabArena 리더보드
더 읽어보기
-
DataFlow📜: 데이터 중심 AI를 위한, LLM 기반 통합 데이터 준비 및 워크플로우 자동화 프레임워크 기술 문서 리뷰
-
대규모 언어 모델(LLM) 기반 합성 데이터(Synthetic Data)의 생성, 큐레이션 및 평가에 대한 종합적인 연구(Survey)
-
DPO로 텍스트 퇴화 줄이기: 모델의 실패 출력을 거부 쌍으로 쓰는 방법에 대한 연구 (feat. DharmaOCR)
-
RAG-Anything: 텍스트, 이미지, 표, 수식을 아우르는 멀티모달 올인원 RAG 프레임워크 (feat. HKUDS)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! 텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다.
로 보내드립니다! 텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()