
VoxCPM 소개
VoxCPM은 OpenBMB에서 공개한 혁신적인 텍스트-음성 변환(TTS, Text-to-Speech) 모델로, 기존의 음성 합성 방식과 달리 '토크나이저(Tokenizer)'를 사용하지 않는 Tokenizer-Free 아키텍처를 채택했습니다. 0.5B(5억 개) 파라미터 규모의 소형 언어 모델(SLM)인 MiniCPM-4를 백본(Backbone)으로 사용하여, 텍스트의 문맥을 깊이 있게 이해하고 이에 맞는 자연스러운 운율과 감정을 담은 음성을 생성합니다.
이 모델은 약 180만 시간의 방대한 이중 언어(영어, 중국어) 데이터를 학습하여 개발되었으며, 단순히 텍스트를 읽는 것을 넘어 '문맥을 인지하는(Context-Aware)' 발화 능력을 갖췄습니다. 특히, 단 3초 정도의 짧은 참조 오디오만 있어도 화자의 목소리 톤, 억양, 감정 상태를 정교하게 모방하는 제로샷(Zero-shot) 음성 복제 성능이 탁월합니다.
기존의 TTS 모델들은 대부분 음성 파형을 코드북 인덱스와 같은 불연속적인 토큰(Discrete Token-Based)으로 변환한 후 언어 모델이 이를 예측하는 방식으로 구성되었습니다. 이 과정에서 정보의 양자화(Quantization) 손실이 발생하여, 미세한 감정 표현이나 자연스러운 호흡 처리에 한계가 있었습니다.
하지만, VoxCPM은 외부 음성 토크나이저를 제거하고, 연속적인 음향 특성(Continuous Acoustic Representation) 을 직접 다룹니다. 이를 통해 텍스트의 의미적 뉘앙스를 음성의 미세한 높낮이와 강세로 직관적으로 연결하며, 더욱 풍부하고 끊김 없는 발화 생성이 가능합니다.
VoxCPM의 주요 특징
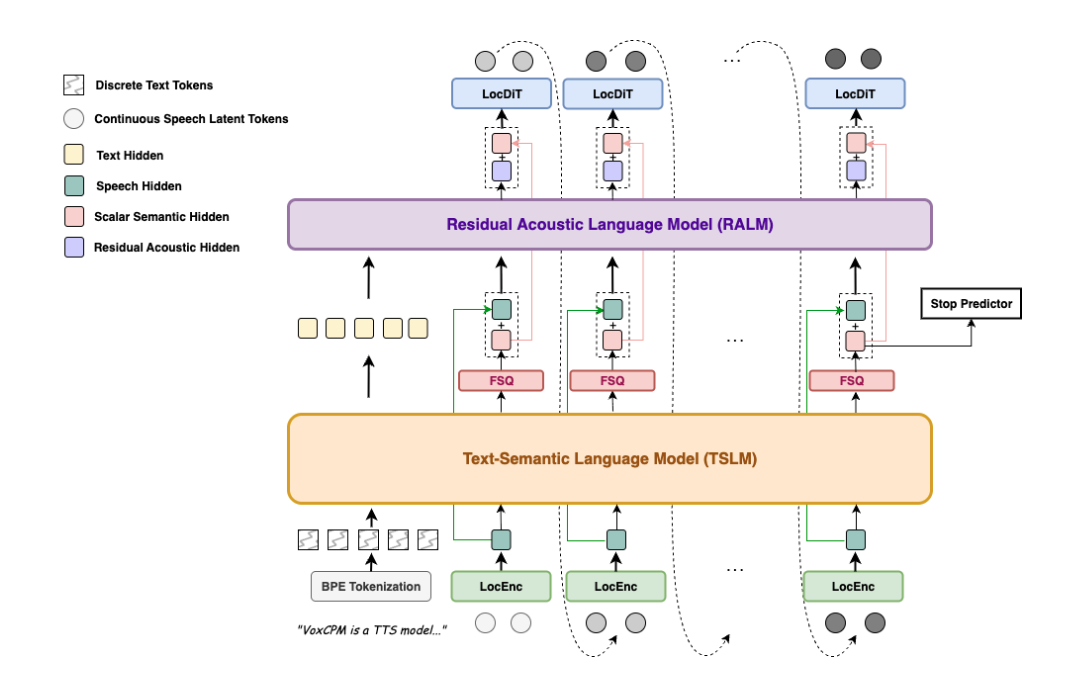
VoxCPM은 MiniCPM-4의 강력한 언어 이해 능력을 음성 생성에 전이(Transfer)시키는 독창적인 구조를 가지고 있습니다. VoxCPM의 모델 구조적인 특징은 다음과 같습니다:
-
계층적 의미-음향 모델링 (Hierarchical Semantic-Acoustic Modeling): 텍스트의 의미를 파악하는 언어 모델(Text-Semantic LM)과 세부적인 소리를 생성하는 음향 모델(Residual Acoustic Model)이 유기적으로 결합되어 있습니다.
-
FSQ (Finite Scalar Quantization): 연속적인 공간에서 안정적인 학습을 위해 FSQ 기법을 도입하여, 표현력(Expressivity)과 안정성(Stability) 사이의 균형을 맞췄습니다.
-
LocDiT (Local Diffusion Transformer): 고품질의 음성 잠재 벡터(Latent)를 생성하기 위해 확산(Diffusion) 기반의 디코더를 사용합니다.
이상과 같은 구조 덕분에, 다음과 같은 기능들을 지원할 수 있게 되었습니다:
-
문맥 인식 발화 (Context-Aware Expressiveness): 입력된 텍스트의 상황(슬픔, 기쁨, 비꼼 등)을 파악하여 적절한 어조를 자동으로 생성합니다. 별도의 프롬프트 없이도 텍스트 내용만으로 스타일을 조절합니다.
-
제로샷 음성 복제 (True-to-Life Voice Cloning): 매우 짧은 참조 오디오만으로도 대상 화자의 목소리 특징(음색, 리듬, 억양)을 즉시 복제합니다.
-
실시간 스트리밍 (Real-Time Streaming): 소비자용 GPU(예: RTX 4090)에서 실시간 처리 속도(RTF, Real-Time Factor) 0.17을 달성하여, 실시간 대화형 애플리케이션에 적용할 수 있습니다.
-
이중 언어 지원: 영어와 중국어에 최적화되어 있으며, 두 언어 간의 교차 언어(Cross-lingual) 복제도 지원합니다.
VoxCPM 설치 및 사용
VoxCPM은 파이썬 라이브러리로, pip를 사용하여 쉽게 설치하여 사용할 수 있습니다.
# pip를 사용한 설치
pip install voxcpm
# 또는, 소스 코드로부터 직접 설치
git clone https://github.com/OpenBMB/VoxCPM.git
cd VoxCPM
pip install -e .
설치 후에는 다음과 같은 Python 코드를 사용하여 기본적인 음성 생성(Text-to-Speech)이 가능합니다:
import soundfile as sf
from voxcpm import VoxCPM
# 모델 로드 (자동 다운로드)
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# 텍스트에서 음성 생성
wav = model.generate(
text="VoxCPM은 토크나이저 없이 작동하는 혁신적인 TTS 모델입니다.",
prompt_wav_path=None, # 음성 복제 시 참조 오디오 경로 입력
cfg_value=2.0, # 텍스트 충실도 조절 (높을수록 프롬프트 준수)
inference_timesteps=10 # 생성 단계 수 (높을수록 고품질)
)
# 결과 저장
sf.write("output.wav", wav, 16000)
또는, 참조 오디오 파일을 사용하여 해당 음성을 복제(Voice Cloning)할 수도 있습니다. 다음은 ref.wav 파일로부터 음성을 복제하는 CLI 기반의 명령 예시입니다.
# 참조 오디오(ref.wav)를 사용하여 텍스트 읽기
voxcpm --text "안녕하세요, 이 목소리는 복제된 목소리입니다." \
--prompt-audio ref.wav \
--prompt-text "참조 오디오의 대본을 여기에 적습니다." \
--output output_cloned.wav
라이선스
VoxCPM 프로젝트는 Apache License 2.0으로 공개 및 배포 되고 있습니다. 상업적 이용 및 수정 배포가 비교적 자유로운 오픈 소스 라이선스입니다.
 VoxCPM 프로젝트 홈페이지
VoxCPM 프로젝트 홈페이지
 VoxCPM 모델 기술 문서
VoxCPM 모델 기술 문서
 VoxCPM 프로젝트 GitHub 저장소
VoxCPM 프로젝트 GitHub 저장소
https://github.com/OpenBMB/VoxCPM
 VoxCPM 모델 다운로드
VoxCPM 모델 다운로드
 VoxCPM 모델 사용해보기
VoxCPM 모델 사용해보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()