
MOSS-TTS-Nano 소개
MOSS-TTS-Nano는 중국 푸단대학교(Fudan University) 자연어처리 연구실 산하의 OpenMOSS 팀과 모스 인공지능(MOSI.AI), 상하이 창즈 학원(Shanghai Innovation Institute)이 함께 공개한 초경량 다국어 음성 생성(Multilingual Tiny Speech Generation) 모델입니다. 이 모델은 0.1B(약 1억 개) 파라미터라는 매우 작은 규모를 유지하면서도 음성 복제(Voice Cloning)와 실시간 스트리밍 합성을 동시에 지원하도록 설계되었습니다. 가장 큰 차별점은 GPU 없이 일반 CPU만으로도 스트리밍 추론이 가능하다는 점이며, 4코어 CPU 환경에서도 실시간에 가까운 응답 속도를 확보할 수 있습니다. 이 덕분에 데스크톱 데모, 사내 웹 서비스, 임베디드 음성 에이전트, 로컬 보이스 봇 등 GPU 인프라가 부담스러운 환경에서도 부담 없이 적용할 수 있는 배포 친화적(Deployment-First) 모델로 자리매김합니다. 출력 품질 또한 단순한 토이 모델 수준을 넘어, 48kHz 스테레오(2-channel) 네이티브 출력으로 제품 통합에 충분한 음질을 제공합니다.
이 프로젝트는 단일 모델이 아니라 더 큰 MOSS-TTS Family의 일부로 공개되었습니다. MOSS-TTS Family는 8B 규모의 플래그십 MOSS-TTS, 멀티 화자 대화 생성을 위한 MOSS-TTSD, 텍스트 프롬프트만으로 음색을 설계하는 MOSS-VoiceGenerator, 환경음과 효과음을 만드는 MOSS-SoundEffect, 저지연 음성 에이전트를 위한 MOSS-TTS-Realtime 등으로 구성된 음성 및 사운드 생성 모델군입니다. MOSS-TTS-Nano는 그 중에서 가장 작고 가벼운 모델로, 동일한 가족 안에서 동일한 오디오 토크나이저(MOSS-Audio-Tokenizer)를 공유하며 실시간 배포 시나리오에 최적화되어 있습니다. 즉, 같은 토큰 표현을 공유하는 가족 안에서 “가장 작고 빠른 입구” 역할을 하도록 의도된 모델이라는 점이 핵심입니다.
기술적으로 MOSS-TTS-Nano는 순수 자기회귀(Pure Autoregressive) 구조의 오디오 토크나이저(Audio Tokenizer)와 LLM을 결합한 파이프라인을 기반으로 합니다. 입력된 텍스트와 짧은 참조 음성(Reference Audio)을 받아, LLM이 시간 순서대로 RVQ(Residual Vector Quantization) 오디오 토큰을 생성하고, 이를 디코더가 다시 48kHz 스테레오 파형으로 복원하는 구조입니다. 별도 미세조정(Fine-tuning) 없이 짧은 참조 음성만으로 음성 복제가 가능하며, 자동 청크 분할을 통해 긴 텍스트도 자연스럽게 합성할 수 있습니다.

유사한 오픈소스 TTS 모델과 MOSS-TTS-Nano의 비교
최근 1년 사이 오픈소스 TTS 진영에서는 “작은 모델, 빠른 추론, 다국어 음성 복제”를 동시에 노리는 흐름이 강해졌습니다. MOSS-TTS-Nano와 자주 비교되는 후보로는 NeuTTS Air, VoxCPM, OmniVoice, Qwen3-TTS 등이 있으며, 각각 강조하는 지점이 조금씩 다릅니다. MOSS-TTS-Nano는 그중에서도 “0.1B로 가능한 가장 작은 다국어 모델 중 하나”와 “네이티브 48kHz 스테레오 출력”, 그리고 “CPU 단독 실시간 스트리밍” 세 가지를 동시에 충족시키는 것이 특징입니다.
| 항목 | MOSS-TTS-Nano | NeuTTS Air | VoxCPM | OmniVoice |
|---|---|---|---|---|
| 모델 크기 | 0.1B | 약 0.5B 급(Qwen 0.5B 기반) | 0.5B | 비공개 |
| 지원 언어 | 20개(중국어, 영어 포함) | 영어 중심 | 영어/중국어 | 600개 이상 |
| 출력 포맷 | 48kHz 스테레오 | 보컬 중심 | 고품질 | 다국어 음성 |
| 음성 복제 | 지원 (참조 음성 1개) | 3초 음성 | 지원 | 제로샷 |
| 실시간/CPU | CPU 스트리밍 가능 | On-device 강조 | GPU 권장 | GPU 권장 |
| 라이선스 | Apache-2.0 | 사용 조건 확인 필요 | 사용 조건 확인 필요 | 사용 조건 확인 필요 |
위 표는 각 프로젝트의 공식 README 및 게시 정보를 기준으로 정리한 것이며, 세부 수치는 버전에 따라 달라질 수 있습니다. MOSS-TTS-Nano의 강점은 동일한 토큰 표현을 사용하는 더 큰 형제 모델(MOSS-TTS, MOSS-TTSD 등)이 같은 생태계에 존재한다는 점이며, 이는 “나노 모델로 빠르게 프로토타이핑하고 필요 시 큰 모델로 옮겨 타는” 단계적 채택이 쉽다는 것을 의미합니다.
MOSS-TTS-Nano의 핵심 동작 원리
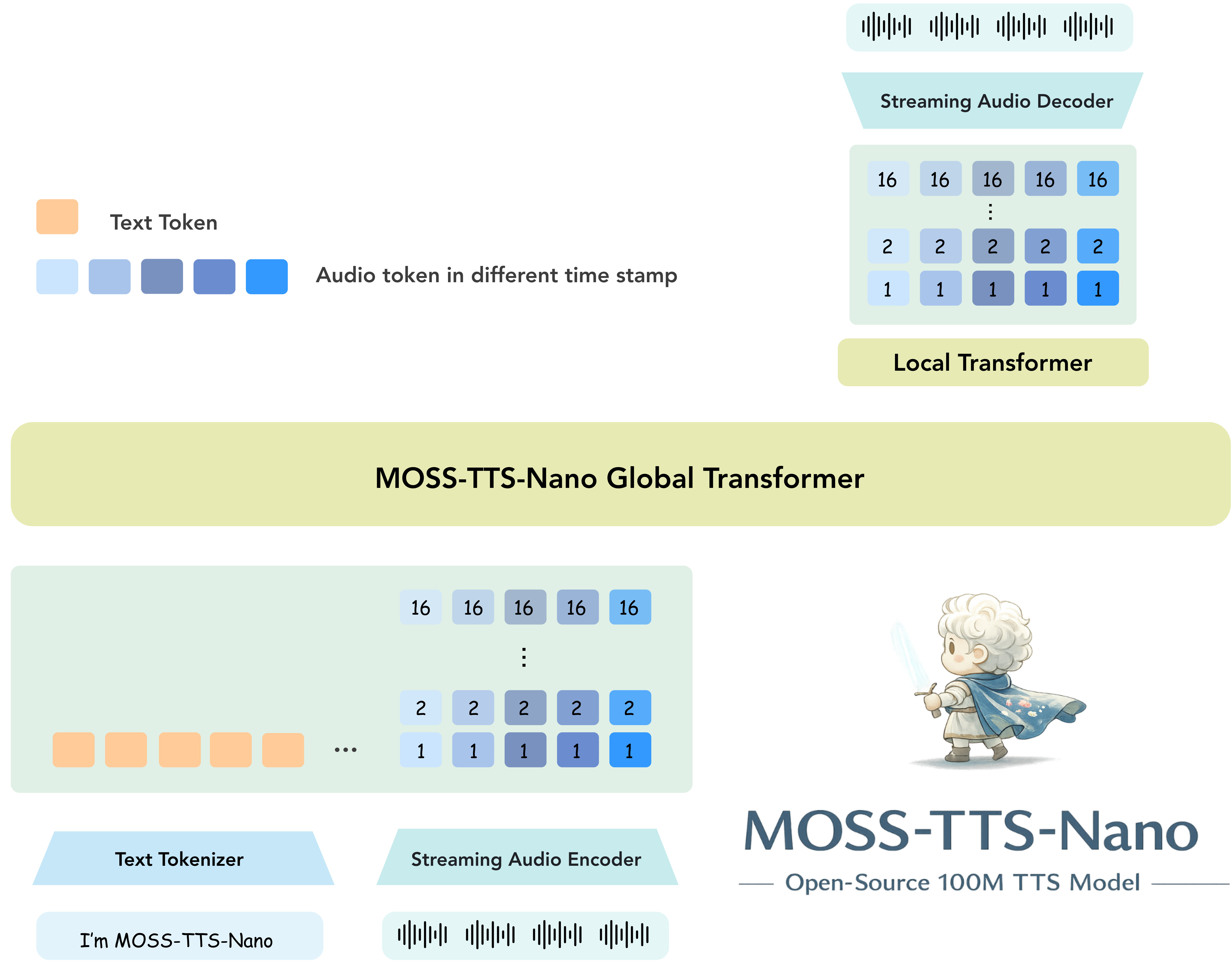
MOSS-TTS-Nano의 동작은 크게 두 단계로 나뉩니다. 첫 번째 단계는 오디오를 이산 토큰(Discrete Token)으로 표현하는 MOSS-Audio-Tokenizer-Nano이고, 두 번째 단계는 텍스트 입력과 참조 음성 토큰을 조건으로 새로운 오디오 토큰 시퀀스를 자기회귀적으로 예측하는 0.1B 규모의 LLM 백본입니다. 두 컴포넌트가 결합되어 “텍스트 → 오디오 토큰 → 48kHz 스테레오 파형”이라는 하나의 파이프라인을 구성합니다. 이는 최근 오픈소스 TTS의 표준에 가까워진 “토크나이저 + LLM” 패턴을 따르되, Nano급 자원 제약을 만족시키기 위해 토크나이저와 백본 모두를 의도적으로 작게 설계한 것이 특징입니다.
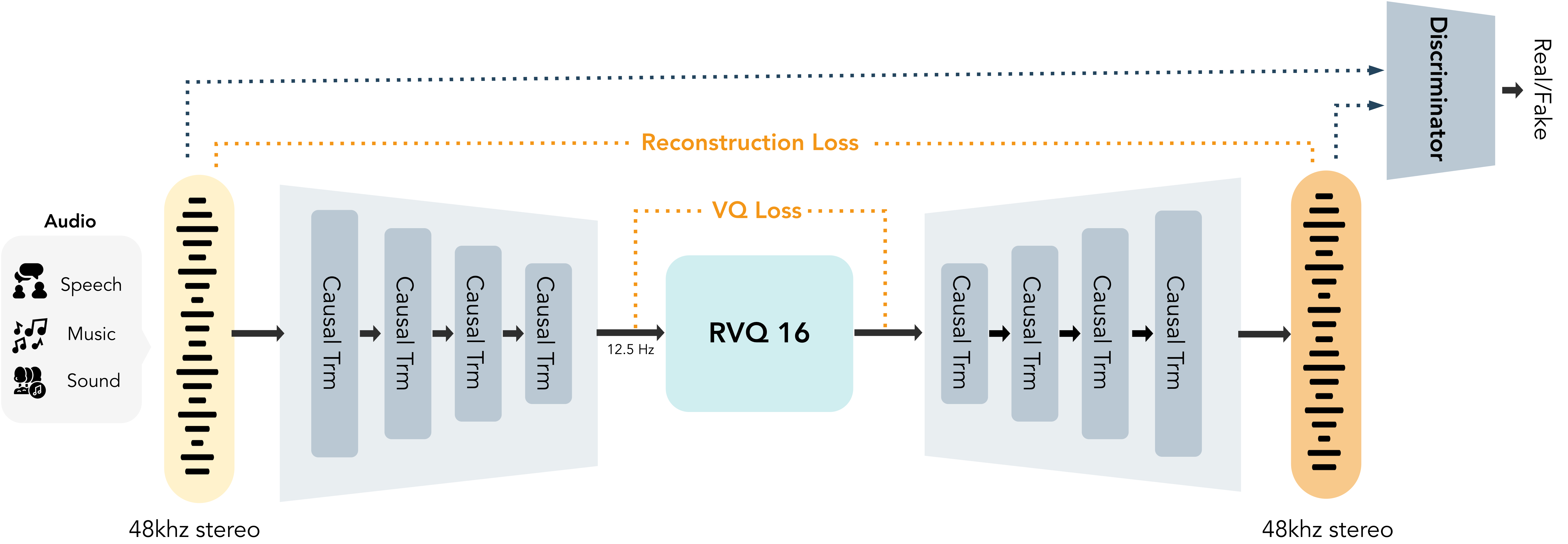
MOSS-Audio-Tokenizer-Nano의 구조 및 동작 방식
MOSS-Audio-Tokenizer-Nano는 약 2천만(20M) 파라미터 규모의 경량 오디오 토크나이저로, 전체 MOSS-TTS Family가 공유하는 오디오 표현 백본(Shared Audio Backbone) 역할을 수행합니다. 이 토크나이저는 “Cat(Causal Audio Tokenizer with Transformer)”이라는 CNN 없는 순수 인과(Causal) 트랜스포머 구조를 채택하며, 슬라이딩 윈도우 어텐션(Sliding-window Attention)을 가진 인과 트랜스포머 블록 12개로 인코더와 디코더가 각각 구성됩니다. 입력은 48kHz 스테레오 오디오이며, 출력은 12.5Hz로 압축된 RVQ 토큰 스트림입니다. RVQ 코드북은 16개 레이어로 구성되며, 사용하는 코드북 수에 따라 0.125kbps에서 2kbps까지 가변 비트레이트(Variable Bitrate)로 압축할 수 있어 품질과 토큰 수 사이의 트레이드오프를 유연하게 조정할 수 있습니다. 이러한 설계 덕분에 토큰 시퀀스 길이가 충분히 짧게 유지되어, 작은 LLM이 다루기에도 부담이 없어집니다.
MOSS-TTS-Nano의 LLM 백본과 Local Transformer 구조
LLM 백본 측면에서 MOSS-TTS-Nano는 RVQ 시간 지연(Temporal Delay) 기법 대신, 동일 시간 스텝에 정렬된 모든 RVQ 레이어의 임베딩을 합산해 단일 트랜스포머 백본에 입력하는 계층적 토큰 모델링(Hierarchical Token Modeling) 설계를 채택합니다. 이렇게 하면 백본은 한 시간 스텝당 하나의 글로벌 잠재 표현(Global Latent)만을 만들어내면 되고, 그 잠재 표현을 받아 “하나의 텍스트 또는 패드 토큰 + 16개의 RVQ 오디오 토큰”으로 이루어진 스텝 내 토큰 블록을 차례로 예측하는 역할은 가벼운 자기회귀 Local Transformer가 담당합니다. 백본은 시간 축의 의미를 유지하고, Local Transformer는 같은 시간 스텝 안에서의 정밀한 토큰 분포를 책임지는 식으로 역할이 분리됩니다. 이 설계 덕분에 백본 자체는 100M 수준으로 작게 유지하면서도, 16개 RVQ 코드북을 동시에 다루는 비교적 복잡한 토큰 분포를 안정적으로 학습할 수 있습니다.
MOSS-TTS-Nano의 주요 기능 요약
기능 측면에서 MOSS-TTS-Nano가 강조하는 항목은 다음과 같이 정리할 수 있습니다. 0.1B 파라미터의 작은 모델 크기, 48kHz 스테레오 네이티브 오디오 출력, 중국어와 영어를 포함한 20개 언어 지원, Audio Tokenizer와 LLM에 기반한 순수 자기회귀 아키텍처, 낮은 첫 음성 지연(Low First-token Latency)을 가지는 스트리밍 추론, 4코어 CPU에서도 동작하는 추론 효율, 자동 청크 분할을 통한 장문 입력 처리, 그리고 python infer.py/python app.py/패키지 CLI까지 제공하는 친화적인 배포 옵션입니다. 단순한 TTS 데모를 넘어, 음성 복제와 장문 합성, 로컬 웹 데모, HTTP 엔드포인트까지 한 번에 다루도록 구성되어 있다는 점이 실제 제품 통합 관점에서 유용합니다.
MOSS-TTS-Nano가 지원하는 20개 언어
MOSS-TTS-Nano는 현재 다음과 같이 20개 언어를 공식 지원합니다. 중국어(zh)와 영어(en)를 중심으로, 독일어(de), 스페인어(es), 프랑스어(fr), 일본어(ja), 이탈리아어(it), 헝가리어(hu), 한국어(ko), 러시아어(ru), 페르시아어(fa), 아랍어(ar), 폴란드어(pl), 포르투갈어(pt), 체코어(cs), 덴마크어(da), 스웨덴어(sv), 그리스어(el), 터키어(tr)까지 폭넓은 다국어 커버리지를 제공합니다. 음성 복제 모드에서도 동일한 모델이 다양한 언어의 참조 음성을 받아 합성할 수 있어, 다국어 콘텐츠를 다루는 서비스에 적합합니다.
MOSS-TTS-Nano 설치 및 사용법
MOSS-TTS-Nano는 깨끗한 Python 환경을 만든 뒤 저장소를 클론하여 editable 모드(pip install -e .)로 설치하는 방식을 권장합니다. 기본 설정으로 실행하면 Hugging Face Hub에서 OpenMOSS-Team/MOSS-TTS-Nano와 OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano를 자동으로 로드합니다. 다음은 conda 환경 기준의 설치 예시입니다.
conda create -n moss-tts-nano python=3.12 -y
conda activate moss-tts-nano
git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
cd MOSS-TTS-Nano
pip install -r requirements.txt
pip install -e .
만약 WeTextProcessing 설치가 실패한다면 동일 환경에서 다음과 같이 수동 설치할 수 있습니다.
conda install -c conda-forge pynini=2.1.6.post1 -y
pip install git+https://github.com/WhizZest/WeTextProcessing.git
가장 권장되는 사용 방식은 짧은 참조 음성을 사용하는 보이스 클론(Voice Clone) 모드입니다. 다음 명령은 assets/audio/zh_1.wav를 음색 레퍼런스로 삼아 새로운 중국어 문장을 합성하고, 결과를 generated_audio/infer_output.wav에 기록합니다.
python infer.py \
--prompt-audio-path assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
브라우저 기반 데모를 띄우고 싶다면 FastAPI 기반 로컬 데모인 app.py를 그대로 실행할 수 있습니다. 실행 후 http://127.0.0.1:18083에 접속하면 됩니다.
python app.py
pip install -e . 이후에는 패키지 CLI 명령어인 moss-tts-nano generate도 사용할 수 있습니다. 이는 infer.py와 동일한 합성을 더 친숙한 옵션 이름(--prompt-speech, --text-file)으로 호출할 수 있게 해 주며, 기본 출력은 generated_audio/moss_tts_nano_output.wav입니다.
moss-tts-nano generate \
--prompt-speech assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
웹 데모와 동일한 인터페이스를 패키지 CLI 명령으로 띄우려면 moss-tts-nano serve를 사용합니다. 이 명령은 app.py로 위임되며, 모델을 메모리에 상주시킨 상태로 브라우저 데모와 HTTP 생성 엔드포인트를 함께 제공합니다.
moss-tts-nano serve
MOSS-TTS Family에서의 위치

MOSS-TTS-Nano를 이해할 때는 단독 모델로 보기보다, 동일한 오디오 토크나이저를 공유하는 MOSS-TTS Family 안에서의 “가장 작은 입구”로 보는 것이 자연스럽습니다. 가족 안에는 8B 규모로 고품질 제로샷 보이스 클론과 장문 합성을 담당하는 플래그십 MOSS-TTS, 1.7B 규모의 경량 변형인 MOSS-TTS-Local-Transformer, 다중 화자 장문 대화 합성을 위한 MOSS-TTSD-v1.0, 텍스트 프롬프트 기반 보이스 디자인을 다루는 MOSS-VoiceGenerator, 환경음과 효과음을 다루는 MOSS-SoundEffect, 저지연 음성 에이전트를 위한 MOSS-TTS-Realtime이 포함됩니다. 동일한 토큰 공간을 공유하기 때문에 추후 동일 워크플로 안에서 모델 크기와 용도를 바꿔 가며 실험하기에 유리한 구조입니다.
MOSS-TTS-Nano 라이선스
MOSS-TTS-Nano 프로젝트는 Apache-2.0 라이선스으로 공개되어 있어, 개인 및 상업적 목적으로 비교적 자유롭게 사용, 수정, 재배포할 수 있습니다. 다만 저작권 및 라이선스 표기와 면책 조항은 그대로 유지해야 하며, 모델 가중치는 별도의 Hugging Face 및 ModelScope 페이지에서 제공되므로 각 페이지의 모델 라이선스도 함께 확인할 것을 권장합니다.
 MOSS-TTS-Nano 데모 페이지
MOSS-TTS-Nano 데모 페이지
MOSS-TTS-Nano Hugging Face Space 데모
 MOSS-TTS Technical Report 논문
MOSS-TTS Technical Report 논문
 MOSS-TTS-Nano 프로젝트 GitHub 저장소
MOSS-TTS-Nano 프로젝트 GitHub 저장소
 MOSS-TTS-Nano 모델 다운로드
MOSS-TTS-Nano 모델 다운로드
MOSS-Audio-Tokenizer-Nano 모델 다운로드
더 읽어보기
-
Qwen3-TTS: 500만 시간의 학습 데이터, 12Hz 초저지연 토크나이저로 완성한 오픈소스 Omni-Audio 모델
-
NeuTTS Air: 3초 분량의 음성만으로 음성 복제가 가능한, On-Device TTS(Text-to-Speech) 모델
-
VoxCPM: 토크나이저 없이 작동하는, 0.5B 규모의 고품질 AI 음성 생성 및 복제를 위한 영어/중국어 TTS 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()