MAI 모델 패밀리 소개
2026년 6월 2일, Microsoft Build 2026 키노트에서 Microsoft AI(MAI)가 사내에서 직접 개발한 7종의 신규 모델을 한 번에 공개했습니다. 이 모델들은 이미지, 음성, 전사(transcription), 추론(reasoning), 코딩 이라는 5개 분야를 아우르며, 서로 독립된 제품이 아니라 같은 데이터 규율, 같은 인프라, 같은 평가 프레임워크를 공유하는 하나의 멀티모달 모델 패밀리(model family) 로 설계되었습니다. 발표를 이끈 Mustafa Suleyman과 MAI 팀은 이번 출시를 "모델 한 개"가 아니라 "지속적으로 더 나아지는 시스템"을 만드는 여정의 첫걸음으로 규정합니다.
이번 발표에서 가장 눈에 띄는 차별점은 모델의 벤치마크 점수 자체보다 어떻게 만들어졌는가에 있습니다. MAI 팀은 다른 연구소의 모델로부터 지식을 증류(distillation) 하지 않고, 깨끗하고 적절히 라이선스된 데이터만으로 바닥부터(from scratch) 학습했다는 점을 반복해서 강조합니다. 아키텍처부터 학습 파이프라인, 사후 학습(post-training)까지 모든 구성요소를 직접 만들었고, 자체 실리콘인 Maia 200 가속기와 모델을 함께 설계(co-design)해 학습과 추론 효율을 끌어올렸습니다. 이는 단순한 성능 경쟁을 넘어 "출처를 신뢰할 수 있고, 상업적으로 안전하게 프로덕션에 투입할 수 있는 모델"을 만들겠다는 선언에 가깝습니다.
또한 MAI는 이 모델들을 Azure Foundry와 자사 제품(PowerPoint, OneDrive, Copilot, Teams, GitHub, VS Code 등)에 통합하는 동시에, OpenRouter, Fireworks, Baseten 같은 개발자 플랫폼에도 폭넓게 배포합니다. 특히 개발자가 직접 모델의 가중치(weights)를 튜닝할 수 있다는 점이 처음으로 열렸습니다. 모델의 궁극적인 지향점은 MAI가 휴머니스트 초지능(Humanist Superintelligence) 이라 부르는 것으로, 사람과 조직을 대체하는 것이 아니라 돕도록 설계되고 끝까지 인간의 통제 아래 남는 AI를 의미합니다.
5개 분야 7종 모델 한눈에 보기
먼저 이번에 공개된 7종 모델을 분야별로 정리하면 다음과 같습니다.
| 분야 | 모델 | 크기/특징 | 핵심 지표 |
|---|---|---|---|
| 추론 | MAI-Thinking-1 | 35B 활성 / 약 1T 총 파라미터 희소 MoE, 256K 컨텍스트 | SWE-Bench Pro 52.8%, AIME 2025 97.0% |
| 코딩 | MAI-Code-1-Flash | 5B 파라미터, GitHub Copilot 통합 추론 효율형 | SWE-Bench Pro 51.2% (Haiku 4.5 대비 +16점) |
| 이미지 | MAI-Image-2.5 | 최고 충실도(fidelity) 생성, 정밀 편집 | Arena 이미지 편집 2위 |
| 이미지 | MAI-Image-2.5-Flash | 대규모 프로덕션용 고속, 저비용 | 이미지 출력 1M 토큰당 $19.50 |
| 전사 | MAI-Transcribe-1.5 | 43개 언어 SOTA 정확도, 배치 전사 | 1시간 오디오를 15초 이내 전사 |
| 음성 | MAI-Voice-2 | 15개 언어 표현형 음성 합성(한국어 포함) | 이전 버전 대비 72% 선호 |
| 음성 | MAI-Voice-2-Flash | 저지연 음성 에이전트용 고효율 | 최고 수준의 속도 대비 가치 |
이제 각 모델을 분야별로 자세히 살펴보겠습니다. 비교 대상으로 자주 등장하는 모델로는 Anthropic의 Claude Sonnet 4.6와 Opus 4.6, Haiku 4.5, Google의 Gemini 3 계열, 그리고 이미지 분야의 Nano Banana 2 등이 있습니다.
"힐 클라이밍 머신": 증류 없이 바닥부터 오르는 시스템
MAI 팀이 이번 발표 전반에서 사용하는 핵심 비유는 힐 클라이밍 머신(Hill-Climbing Machine) 입니다. 이는 한 번 잘 만든 모델이 아니라, 더 많은 연산, 더 좋은 데이터, 더 날카로운 평가를 반복적으로 투입할 때마다 능력이 꾸준히 그리고 안정적으로 올라가는 "조직과 시스템 자체"를 가리킵니다. 모델 개발을 시스템 수준의 최적화 문제로 보고, 데이터 파이프라인, 학습 인프라, 강화학습 환경과 보상, 평가 스위트, 안전 테스트를 모두 측정 가능하고 개선 가능한 형태로 묶어낸 것이 이 머신의 정체입니다.
이 철학은 세 가지 원칙으로 요약됩니다.
능력은 물려받는 것이 아니라 학습하는 것입니다 (Learned, not inherited): 다른 모델의 출력을 모방하는 증류는 빠르게 능력을 얻을 수 있지만, 교사 모델의 설계 선택에 종속되어 새로운 상황에 적응하는 조종성(steerability)이 부족해집니다. MAI-Thinking-1은 제3자 모델로부터의 증류 없이 학습해, 모델이 과제를 진짜로 익히도록 강제했습니다.
깨끗한 데이터 (Clean data): MAI-Thinking-1은 적절히 라이선스된 깨끗한 데이터로만 학습되었고, 사전 학습(pre-training) 단계에서 AI가 생성한 콘텐츠는 배제되었습니다. 무엇이 모델을 형성했는지 설명할 수 없으면 그 동작을 이해하거나 신뢰성 있게 개선할 수 없다는 판단입니다.
전 스택에 걸친 자립 (Self-sufficiency across the stack): 모델과 Microsoft 자체 가속기의 공동 설계부터 강화학습 프레임워크까지, 학습 인프라를 사내에서 직접 구축했습니다. 실제로 MAI-Thinking-1을 자사 Maia 200 칩에서 GB200과 정면 비교했을 때, end-to-end로 1.4배의 와트당 성능(performance-per-watt) 향상을 확인했다고 밝혔습니다. 이 규모에서는 모든 와트가 중요하며, 실리콘과 모델의 공동 설계가 효율의 핵심 우위라는 것입니다.
이러한 규율은 Microsoft가 이전에 공개한 소형 모델 Phi 계열에서 보여준 "데이터 품질 중심" 접근과도 맥이 닿아 있지만, 이번에는 프런티어급 대형 모델 전체를 자체 데이터와 인프라로 끌어올렸다는 점에서 규모가 다릅니다.
추론 분야: MAI-Thinking-1
MAI-Thinking-1은 Microsoft AI의 첫 추론(reasoning) 모델이자 텍스트 기반(foundation) 모델입니다. 흥미로운 점은 거대한 모델이 아니라 중간 체급(medium-sized) 모델이라는 것입니다. 기반 모델인 MAI-Base-1은 35B 활성(active), 약 1T 총(total) 파라미터의 희소 전문가 혼합(sparse Mixture of Experts, MoE) 구조로, 훨씬 큰 모델들보다 추론 시 차지하는 자원(inference footprint)이 작습니다. 그럼에도 SWE-Bench Pro에서 Claude Opus 4.6과 어깨를 나란히 합니다. 모델 크기는 고급 코딩 보조 기능을 어디에 배포할 수 있는지, 얼마나 자주 쓸 수 있는지, 일상 워크플로우로 들어올 수 있는지를 결정하기 때문에 이 체급에서의 성능은 실용적으로 중요합니다.
함께 공개된 기술 보고서에 따르면, MAI-Base-1은 Azure 플랫폼 내 Microsoft 운영 클러스터의 8,000개 GB200 GPU에서 사내 분산 학습 인프라로 바닥부터 사전 학습되었습니다. 주 사전 학습 단계에서 30조(30T) 토큰, 이어지는 중간 학습(mid-training)에서 추가로 3.55조 토큰을 사용했고, 중간 학습 이후 최대 256K 컨텍스트 길이에 도달했습니다.
아키텍처: 디코더 트랜스포머와 LatentMoE
MAI-Base-1은 디코더 전용(decoder-only) 트랜스포머로, 하드웨어와의 공동 최적화를 염두에 두고 설계되었습니다. 주요 특징은 다음과 같습니다.
- 주기적 로컬/글로벌 어텐션: Gemma 3의 설계를 따라 로컬 어텐션 5개 층마다 글로벌 어텐션 1개 층을 배치합니다. 로컬 층은 슬라이딩 윈도우 512에 회전 위치 인코딩(Rotary Position Embedding, RoPE)을 쓰고, 글로벌 층은 위치 인코딩을 쓰지 않습니다(NoPE). 이로써 학습 비용과 추론 시 KV 캐시 크기를 크게 줄입니다.
- 그룹 쿼리 어텐션(Grouped-Query Attention, GQA): 8개의 KV 헤드와 헤드당 차원 128을 사용하며, FlashAttention 계열과 Ulysses 방식의 컨텍스트 병렬화로 긴 컨텍스트를 효율적으로 처리합니다.
- 밀집 FFN과 MoE의 교차 배치: 각 블록에서 고희소(high-sparsity) MoE 층과 작은 밀집(dense) FFN을 번갈아 배치합니다. MoE는 NVIDIA의 LatentMoE 설계를 채택해, all-to-all 디스패치 전에 공유 다운프로젝션을 적용하고 압축된 표현을 기준으로 512개 전문가 중 8개를 softmax 게이팅으로 라우팅합니다. 활성/비활성 메모리를 일정하게 유지하기 위해 토큰을 버리지 않는 dropless MoE를 구현했습니다.
- 표준 구성요소: 입출력 양쪽에 RMSNorm, SwiGLU 활성, 입출력 임베딩 가중치 공유, 그리고
o200k_base토크나이저(어휘 크기 200,019)를 사용합니다.
강화학습(RL) 단계에서는 사고의 연쇄(Chain-of-Thought, CoT)를 과제별 피드백에 대해 학습시키고, 외부 도구를 사용하며, 사람의 선호와 안전 신호를 따르도록 가르칩니다. 추론 흔적(reasoning trace)에 대한 사전 노출 없이 바닥부터 추론하는 법을 배우며, STEM 추론, 에이전트 코딩 및 도구 사용, 유용성과 안전성이라는 세 가지 도메인별 전문가 모델을 각각 학습한 뒤 하나의 모델로 통합합니다.
벤치마크: 체급을 뛰어넘는 성능
MAI-Thinking-1은 다음과 같은 공개 벤치마크 성적을 보고했습니다.
| 벤치마크 | 점수 | 의미 |
|---|---|---|
| SWE-Bench Pro | 52.8% | 가장 까다로운 코딩 벤치마크 중 하나에서 Opus 4.6과 동급 |
| AIME 2025 | 97.0% | 범용 수학 추론 능력의 핵심 지표 |
| AIME 2026 | 94.5% | 최신 수학 경시 문제에서도 강력한 일반화 |
| LiveCodeBench v6 | 87.7% | 경쟁 프로그래밍 수준의 코딩 능력 |
특히 어떤 벤치마크도 특정해 겨냥하지 않고, 증류 없이 자체 데이터와 보상, 평가 과정만으로 바닥부터 올라왔다는 점이 MAI 팀이 강조하는 부분입니다. 독립 평가 기관 Surge의 사람 평가자들은 블라인드 일대일 비교에서 전반적 품질 면에서 Sonnet 4.6보다 MAI-Thinking-1을 선호했습니다. MAI-Thinking-1은 Baseten을 통해 개발자에게 제공되며, 추론(reasoning) 모델의 흐름은 앞서 PyTorchKR에서 다룬 Google의 Gemini 2.5 "thinking" 모델 등과 함께 보면 맥락을 잡기 좋습니다.
코딩 분야: MAI-Code-1-Flash
MAI-Code-1-Flash는 추론 효율에 초점을 맞춘 에이전트 코딩 모델로, 단 5B 파라미터로 Claude Haiku 4.5와 비슷한 체급이지만 비용은 더 저렴합니다. 이 모델의 핵심 설계 철학은 "벤치마크가 아니라 개발자를 위해 만든다" 입니다. 코딩 모델은 개발자가 매일 쓰는 바로 그 환경에서 잘 동작할 때 가장 유용하기 때문에, MAI-Code-1-Flash는 프로덕션에서 실제 사용되는 GitHub Copilot 하네스(harness)로 직접 학습되었습니다. 덕분에 에이전트 코딩 과제에서 주변 도구 및 시스템과 상호작용하는 법을 익혀, 실제 Copilot 워크플로우에 특히 잘 맞습니다.
또 하나의 핵심은 적응형 솔루션 길이 제어(adaptive solution length control) 입니다. 간단한 요청에는 간결하게 답하고, 더 깊은 분석이나 광범위한 코드 변경이 필요한 문제에는 추론 예산(reasoning budget)을 더 씁니다. 그 결과 개발자는 유용한 출력을 더 빨리 보기 시작하고, MAI 팀은 더 어려운 문제를 최대 60% 더 적은 토큰으로 해결하는 사례를 관찰했습니다. 지연(latency)과 비용이 줄고, 토큰당 가치(return on token)가 올라가며, 대화형 워크플로우가 더 매끄럽게 느껴진다는 것입니다.
성능 면에서는 개발자가 실제로 쓰는 동일한 프로덕션 하네스로 Claude Haiku 4.5와 비교했습니다. MAI-Code-1-Flash는 SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, Terminal Bench 2의 네 가지 핵심 코딩 벤치마크 모두에서 Haiku 4.5를 앞섰고, 특히 다양한 실세계 과제로 구성된 SWE-Bench Pro에서 51.2% 대 35.2%로 16점 차이를 냈습니다. 더 똑똑할 뿐 아니라 더 가볍다는 점, 즉 정확도와 효율이 더 이상 트레이드오프가 아니라는 점을 보여주는 결과입니다. 이 모델은 오늘부터 VS Code의 기본 모델 중 하나로 약 10%의 개인 사용자에게 순차 적용되며, 모델 선택기에서 Auto를 고른 사용자에게 라우팅될 수 있습니다. 코딩 에이전트의 평가 방식 자체에 관심이 있다면 PyTorchKR의 Artificial Analysis 코딩 에이전트 벤치마크 정리도 함께 참고할 만합니다.
이미지 분야: MAI-Image-2.5와 2.5-Flash
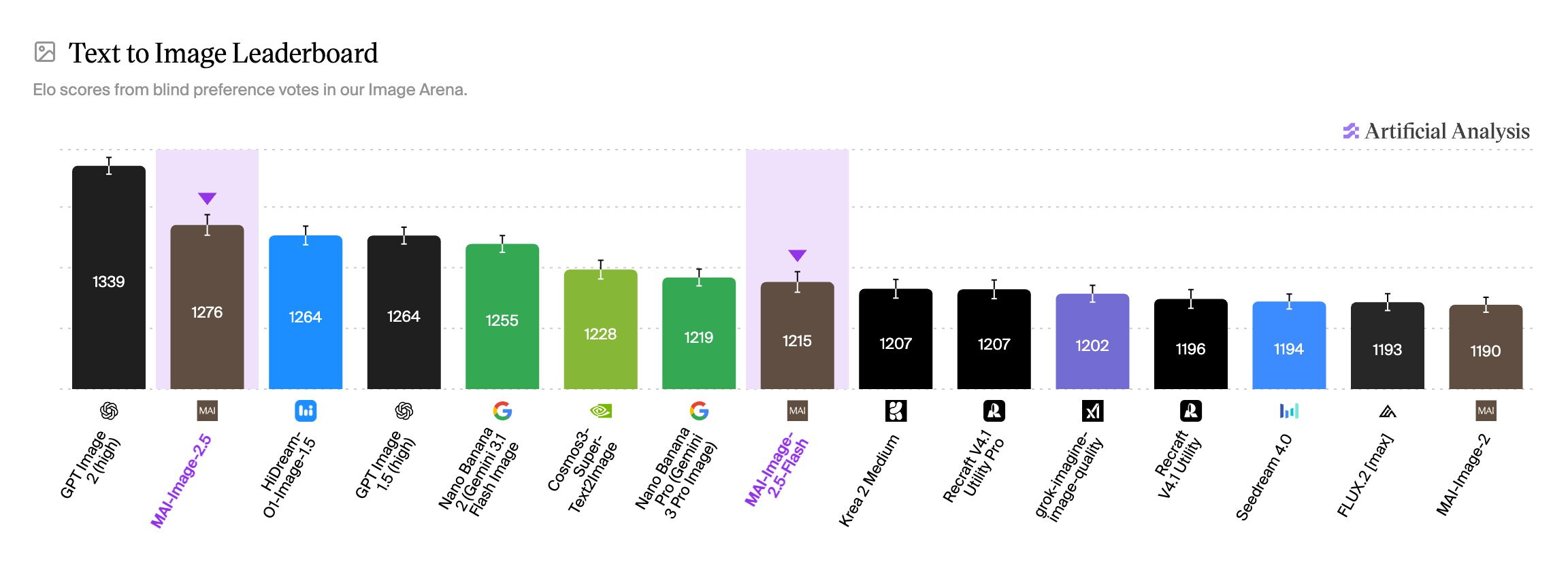
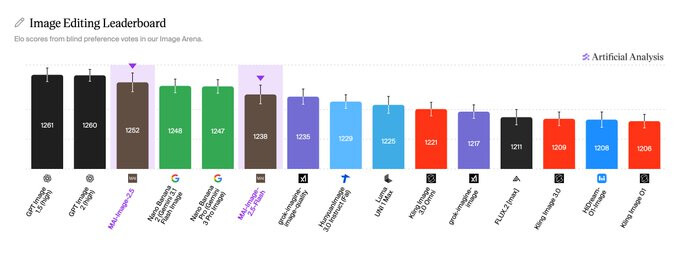
MAI-Image-2.5는 MAI의 가장 강력한 이미지 모델로, Arena 이미지 편집 리더보드에서 Nano Banana 2를 앞서며 2위로 데뷔했습니다. 고품질 생성과 정밀하고 제어 가능한 편집을 위해 만들어졌으며, 최고 충실도를 노리는 MAI-Image-2.5와 대규모 프로덕션 워크로드를 위한 고속, 저비용의 MAI-Image-2.5-Flash 두 가지로 출시됩니다.
주요 기능은 다음과 같습니다.
- 텍스트-이미지 품질의 비약: 프롬프트로부터 더 디테일하고 일관된 이미지를 생성하며, 텍스트 렌더링, 제품 이미지, 프롬프트 준수도가 향상되었습니다.
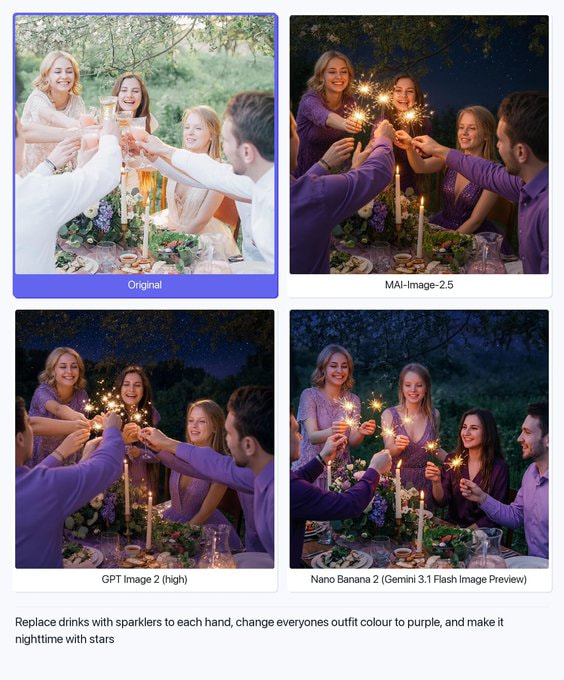
- 복잡한 시각적 추론: 장면 구조, 조명, 스케일, 공간 관계를 이해해, 예를 들어 객체를 추가할 때 올바른 원근과 그림자를 맞춰 이미지 맥락에 어울리는 편집을 합니다.
- 세밀한 편집 제어: 객체 교체, 텍스트 수정, 모션 블러 제거 같은 정밀하고 국소적인 편집을 나머지 부분을 바꾸지 않고 수행합니다.
- 얼굴 및 정체성 일관성: 포즈, 표정, 시점이 바뀌어도 알아볼 수 있는 인물의 정체성을 유지합니다.
벤치마크에서 MAI-Image-2.5는 GPT-Image-1.5와 Nano Banana Pro 2K를 능가하는 Arena 점수를 기록하며 텍스트-이미지 3위, 이미지 편집 2위에 올랐습니다. 이전 버전인 MAI-Image-2 대비 전체 +75점 향상되었고, 텍스트 렌더링(+107점)과 카툰, 애니메이션, 판타지(+90점)에서 가장 큰 폭으로 개선되었습니다. 아래는 12개 편집 카테고리에서 블라인드 사람 선호 평가로 측정한 MAI-Image-2.5의 승률입니다.
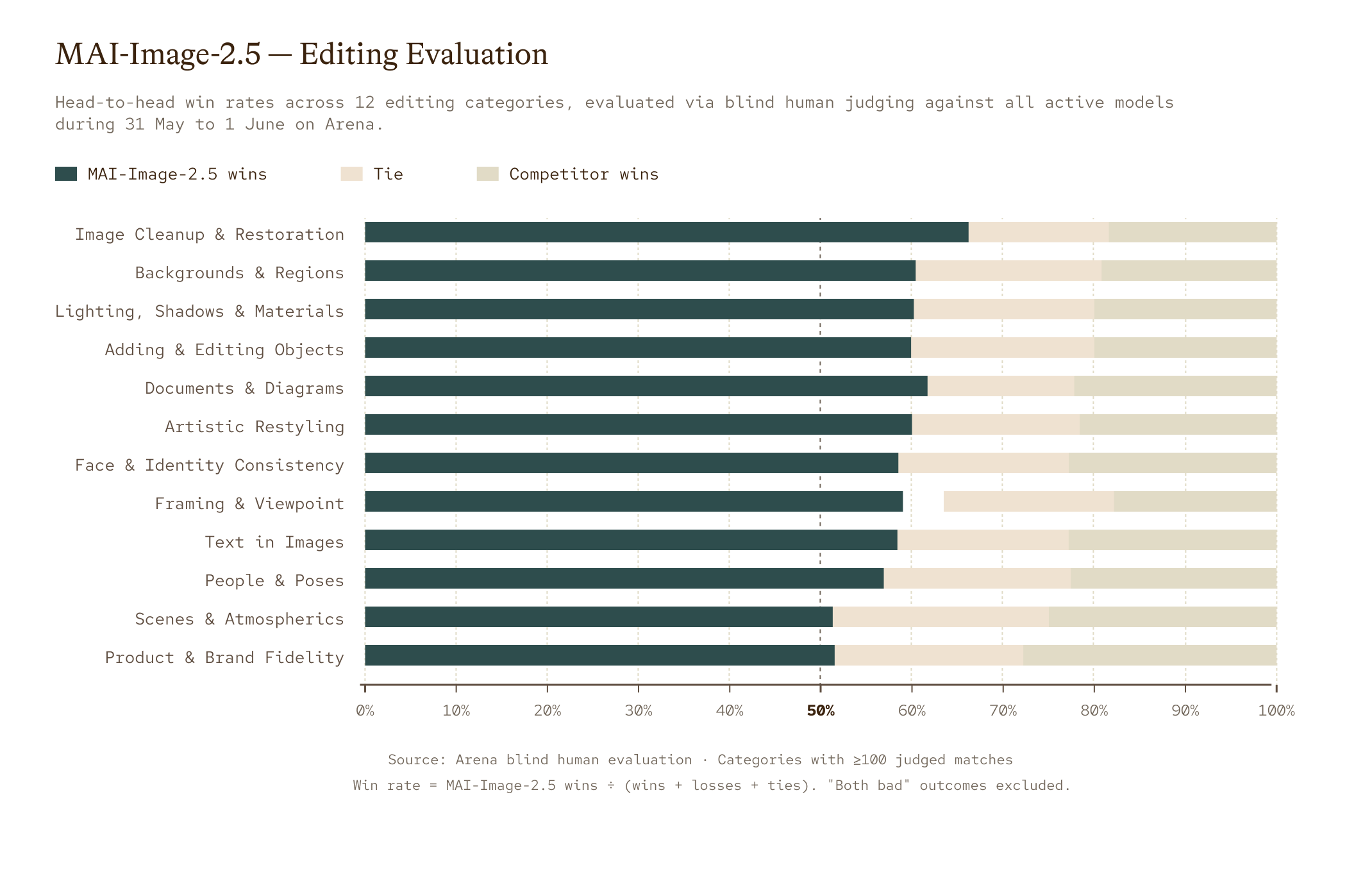
활용 측면에서 MAI-Image-2.5는 이미 PowerPoint에서 고품질 이미지 생성에 쓰이고 있고, OneDrive에는 정밀 편집 기능으로 순차 적용 중입니다. 가격은 Foundry 기준으로 MAI-Image-2.5가 텍스트 입력 1M 토큰당 $5, 이미지 입력 1M 토큰당 $8, 이미지 출력 1M 토큰당 $47이며, Flash는 각각 $1.75, $1.75, $19.50로 더 저렴합니다. 이미지 생성 및 편집 모델의 최근 흐름은 PyTorchKR의 Gemini 2.5 Flash Image(Nano Banana) 소개와 함께 보면 비교가 쉽습니다.
전사 분야: MAI-Transcribe-1.5
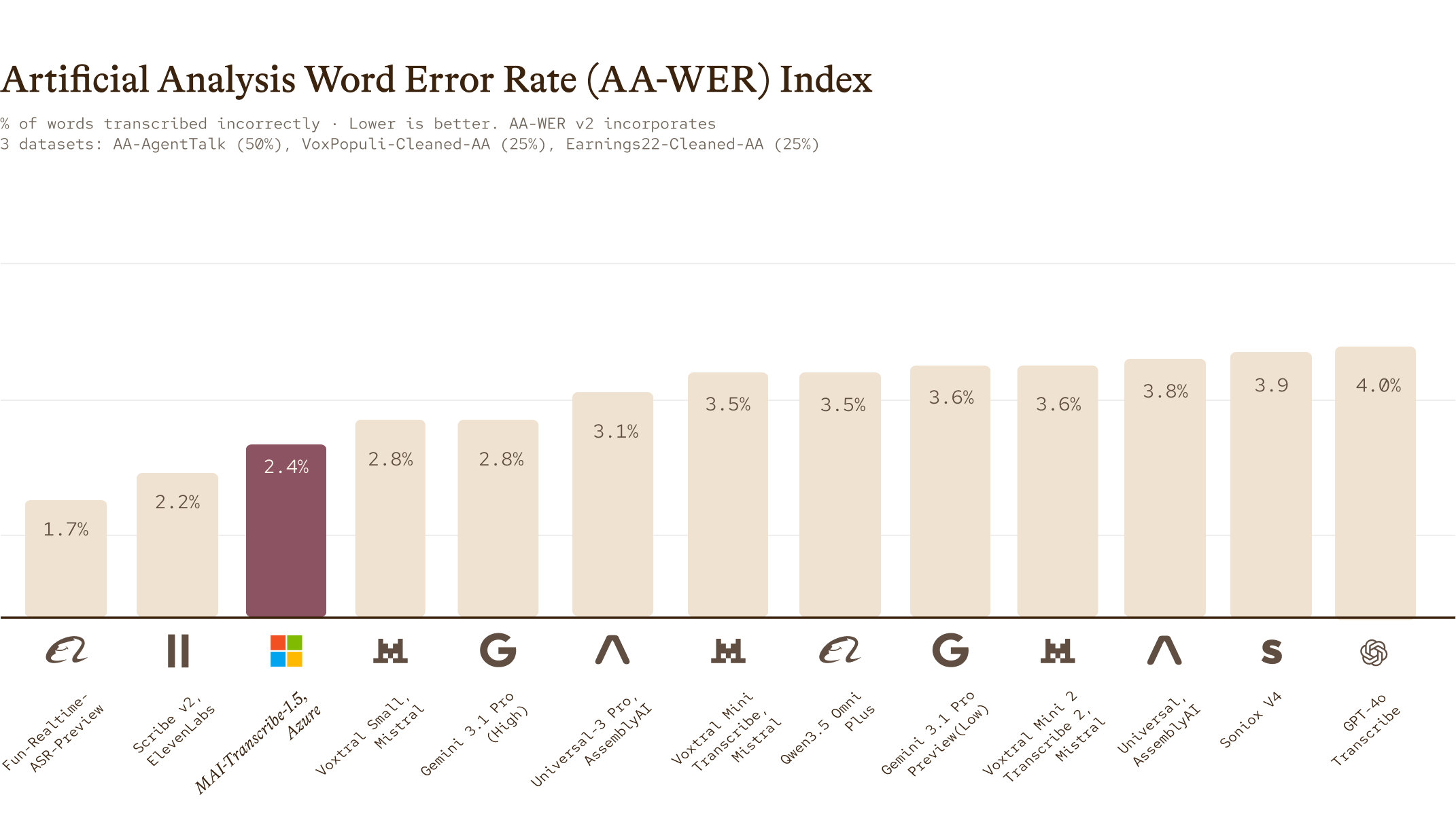
MAI-Transcribe-1.5는 MAI 팀이 "세계 최고"라고 자신하는 다국어 음성-텍스트(speech-to-text) 모델입니다. 표준 다국어 벤치마크인 FLEURS에서 43개 언어에 걸쳐 최고 수준의 단어 오류율(Word Error Rate, WER) 을 달성했고, 그중 18개 언어에서 1위를 기록하며 GPT-4o-Transcribe, Scribe v2, Gemini 3.1 Flash Lite를 앞섰습니다. 지원 언어는 이전 버전의 25개에서 18개를 더해 43개로 확장되었으면서도 정확도와 품질은 떨어지지 않았습니다.

속도 역시 강점입니다. MAI-Transcribe-1.5는 Artificial Analysis 리더보드에서 정확도 대비 속도(Accuracy x Speed) 부문 선두에 올랐고, 동급 정확도 모델보다 최대 5배 빠릅니다. 특히 긴 오디오에서 효과가 두드러져 1시간 분량 오디오를 15초 이내에 전사할 수 있습니다. WER 2.4%로 매우 경쟁이 치열한 공개 벤치마크에서 3위를 차지했습니다.

엔터프라이즈에 특히 유용한 기능은 키워드 바이어싱(Keyword Biasing) 입니다. 사람 이름, 제품명, 의료 용어, 내부 약어처럼 사용자에게 가장 중요한 도메인 특화 단어들은 일반 전사 모델이 자주 틀리는 부분입니다. MAI-Transcribe-1.5는 사용자가 제공한 키워드 목록 쪽으로 예측을 편향시키되, 맹목적으로 끼워 맞추지 않고 공유된 맥락을 보고 언제 바이어싱을 적용할지 스스로 결정합니다. 이 기능을 쓰면 FLEURS 벤치마크에서 WER이 최대 30% 감소합니다. 예를 들어 키워드 바이어싱 없이 "Sean", "Oif", "Societal"로 잘못 전사되던 이름들이, "Aisling, Shaun, Xochitl, Søren, Niamh" 같은 키워드 목록을 주면 "Shaun", "Aoife", "Xochitl"처럼 정확히 인식됩니다.
MAI-Transcribe-1.5는 배치(batch) 전사 모델로, 이미 Copilot, Teams, GitHub, Dynamics 365 Contact Center에 통합되었고 Foundry에서도 제공됩니다. 향후 로드맵으로는 다중 화자 오디오에서 "누가 무엇을 말했는지" 구분하는 화자 분리(diarization), 실시간 전사를 위한 네이티브 스트리밍 API, 그리고 추가 언어 지원이 예고되어 있습니다. API 문서와 쿡북은 Azure 문서에서 확인할 수 있습니다.
음성 분야: MAI-Voice-2와 Voice-2-Flash
MAI-Voice-2는 MAI가 지금까지 만든 가장 표현력 있고 자연스러운 텍스트-음성(text-to-speech) 모델입니다. 충실도, 언어 커버리지, 화자 일관성, 감정 범위 등 프로덕션 음성 경험에 중요한 모든 차원에서 이전 버전을 크게 뛰어넘었습니다. 영어 전용이던 이전과 달리 15개 언어를 지원하며, 반가운 점은 그 목록에 한국어가 포함된다는 것입니다. (전체 지원 로케일: 영어(미국/호주), 이탈리아어, 프랑스어, 독일어, 힌디어, 스페인어(스페인/멕시코), 포르투갈어(브라질/포르투갈), 한국어, 중국어(간체), 터키어, 러시아어, 태국어, 네덜란드어, 루마니아어, 헝가리어.)
주요 기능은 다음과 같습니다.
- 세밀한 감정 제어:
sad,whispered,excited같은 감정 태그(emotion tag)로 발화의 정서를 조절합니다. - 제로샷 음성 프롬프팅: 5~60초 분량의 참조 오디오만으로 모든 지원 언어에서 화자의 목소리를 생성하며, 동의(consent) 가드레일이 내장되어 있습니다.
- 장시간 화자 일관성: 오디오북, 팟캐스트, 강의처럼 긴 콘텐츠에서도 안정적인 화자 정체성을 유지합니다.
- 코드 스위칭(Code-switching): 힌디어-영어, 스페인어-영어처럼 사람들이 일상에서 자연스럽게 언어를 섞는 방식을 문장 중간에도 운율과 화자 정체성을 잃지 않고 재현합니다.
성능 평가에서 MAI-Voice-2는 일대일 선호 테스트에서 이전 버전 MAI-Voice-1보다 72% 더 선호되었고, 화자 유사도 평가에서는 합성 음성이 같은 목소리의 실제 녹음과 구별되지 않는 수준에 도달했습니다. 함께 발표된 MAI-Voice-2-Flash 는 2026년의 화두인 초저지연 음성 에이전트(Voice Agent)를 위해 최고의 속도 대비 가치를 제공합니다.
안전 측면에서 음성 합성은 시스템 수준에서 동의가 강제되어, 프로덕션에서는 허가되고 라이선스된 목소리만 합성할 수 있으며 무단 음성 복제는 불가능합니다. 모든 출력에는 워터마크가 삽입됩니다. MAI-Voice-2는 Foundry와 OpenRouter에서 제공되며 VS Code와 Dynamics 365 Contact Center에 통합되고 있습니다. 온디바이스 다국어 TTS나 음성 복제의 흐름은 PyTorchKR의 Supertonic, NeuTTS Air, OpenAI.fm 소개 글과 비교해 보면 흥미롭습니다.
당신에게 맞춰지는 모델: Frontier Tuning과 RLE
MAI 팀은 모델 자체보다 "그 모델로 무엇을 할 수 있는가" 가 더 중요한 변화라고 말합니다. 그 중심에 있는 것이 Frontier Tuning입니다. 실제 업무 환경에서의 강화학습을 통해 AI가 특정 워크플로우의 세부 사항에 처음으로 완전히 적응할 수 있게 되었다는 것입니다.
이 구조에서 가장 가치 있는 데이터는 외부 데이터가 아니라 당신의 데이터, 즉 에이전트가 실제 업무를 완수하며 남긴 단계와 결정, 행동의 흔적입니다. MAI는 이를 학습시키는 공간을 강화학습 환경(Reinforcement Learning Environments, RLE) 이라 부르며, "오직 당신만 접근할 수 있는 AI 전용 훈련 체육관(training gym)"에 비유합니다. Frontier Tuning으로 당신은 당신의 데이터로, 당신의 환경 안에서, 당신이 통제하는 당신만의 모델을 만들게 되고, 조직의 노하우가 모델의 일부가 되면서도 그 소유권은 당신에게 남습니다.
실제 성과도 제시되었습니다. Microsoft 내부에서 Excel용으로 튜닝한 MAI 모델은 GPT-5.4 수준의 품질을 내면서 최대 10배 더 효율적이었고, McKinsey의 까다로운 엔터프라이즈 기준에 맞춰 튜닝했을 때는 테스트한 모든 모델 중 가장 높은 승률을 기록하면서 비용은 약 10배 낮았습니다. MAI는 이를 두고, 공유 모델에서 지능을 "임대"하는 방식과 달리 당신이 만든 RLE와 모델이 곧 당신의 해자(moat)가 된다고 표현합니다.
메이요 클리닉과의 헬스케어 프런티어 협업
특히 민감하고 중요한 영역에서는 더 깊은 협력이 필요하다는 인식 아래, Microsoft는 Mayo Clinic과 헬스케어용 프런티어 AI 모델을 공동 개발한다고 발표했습니다. 이 모델은 메이요 클리닉의 세계적 임상 전문성, 비식별화된 임상 데이터, 종단적(longitudinal) 인사이트와 Microsoft의 기반 AI 역량을 결합해, 오늘날의 범용 시스템이 도달할 수 없는 수준의 폭넓은 임상 추론을 목표로 합니다.
모델은 먼저 메이요 클리닉 자체 환경에 배포되어 더 이르고 정확한 진단과 치료 계획 수립을 돕고, 검증을 거친 뒤 Azure Foundry를 통해 다른 기관에도 제공될 예정입니다. 중요한 점은 이 모델의 소유권이 메이요 클리닉에 있다는 것으로, 환자 신뢰와 임상적 엄밀성, 안전, 그리고 임상 데이터에 대한 책임 있는 관리라는 양측의 약속을 강조합니다.
가격, 접근성, 그리고 안전
이번 모델 패밀리는 Azure Foundry와 Microsoft 자사 제품에 통합되는 동시에, 개발자를 위해 OpenRouter, Fireworks, Baseten에서도 제공됩니다. 앞서 언급했듯 개발자가 처음으로 모델 가중치를 직접 튜닝할 수 있게 되었으며, MAI Playground에서 모델들을 바로 체험해 볼 수 있습니다.
안전과 보안은 전 모델에 처음부터 내장되었습니다. 음성 모델은 무단 복제에 대한 보호 장치를 포함하고 모든 출력에 워터마크를 넣으며, 과도한 거부(over-refusal)를 줄이고 장애를 가진 사람을 포함한 표현(representation)을 개선했습니다. 다만 이미지 모델은 다른 모든 이미지 모델과 마찬가지로 학습 데이터의 편향을 반영하거나 그럴듯하지만 부정확한 시각적 디테일을 만들 수 있으므로, 신원, 법률, 의료, 금융, 뉴스 관련 맥락에서는 사용 전에 반드시 검토가 필요합니다. MAI는 투명성을 위해 상세한 기술 보고서와 안전 보고서를 함께 공개했습니다.
마치며: 휴머니스트 초지능을 향하여
MAI 팀은 이번 발표를 단순한 7종 모델 출시가 아니라, 제1원리(first principles)에 기반해 장기적 역량에 집중하는 연구소와 새로운 튜닝, 소유 방식을 함께 제시하는 "AI의 다음 단계"로 규정합니다. 그 궁극적 목표인 휴머니스트 초지능(Humanist Superintelligence)은 사람과 조직을 대체하는 것이 아니라 돕도록 설계된 고도의 AI 시스템을 뜻합니다. 이런 시스템은 어디까지나 인간의 의도에 의해 형성되고, 인간의 감독을 받으며, 인간의 목표에 종속되는 도구로 남아야 한다는 것이 MAI의 입장입니다.
증류에 기대지 않고 깨끗한 데이터로 바닥부터 올라온 모델, 자체 실리콘과의 공동 설계, 그리고 사용자가 소유하고 통제하는 튜닝 방식이라는 세 축은, 성능 경쟁 일변도의 흐름 속에서 "신뢰할 수 있고 통제 가능한 AI"라는 다른 좌표를 제시합니다. 이 힐 클라이밍 머신이 앞으로의 연산과 역량 확장 속에서 실제로 얼마나 꾸준히 정상을 향해 오를지 지켜볼 만합니다.
 Building a hill-climbing machine 소개 블로그
Building a hill-climbing machine 소개 블로그
 Microsoft Build 2026 MAI 키노트 전문
Microsoft Build 2026 MAI 키노트 전문
더 읽어보기
-
Gemini 2.5 Flash Image (a.k.a. Nano-Banana): 구글의 차세대 이미지 생성 / 편집 모델
-
Google DeepMind, LWM(Large World Model)으로 진화하는 가장 지능적인 Gemini 3 출시
-
Microsoft, Phi-3 모델들을 개선한 Phi-3.5 모델 시리즈 공개 (+ Phi-3.5-MoE-instruct)
-
Supertonic: ONNX 런타임 기반의 초경량 온디바이스 다국어 TTS 시스템 (feat. Supertone AI)
-
NeuTTS Air: 3초 분량의 음성만으로 음성 복제가 가능한, On-Device TTS(Text-to-Speech) 모델
-
Artificial Analysis가 공개한 코딩 에이전트 벤치마크: 모델 + 하네스의 조합으로 평가한 벤치마크 결과
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()