
flash-moe 소개
대규모 언어 모델(LLM)을 로컬 하드웨어에서 실행하려면 일반적으로 고사양의 서버급 GPU나 전용 AI 가속기가 필요하다는 것이 오랜 통념이었습니다. 하지만 flash-moe 프로젝트는 이 통념에 정면으로 도전합니다. 이 프로젝트는 Python 기반 프레임워크를 전혀 사용하지 않고 순수 C, Objective-C, 그리고 Apple의 Metal GPU 프레임워크만으로, 무려 3970억 개(397B)의 파라미터를 가진 Mixture-of-Experts(MoE) 모델인 Qwen3.5-397B-A17B를 48GB 통합 메모리를 탑재한 MacBook Pro M3 Max에서 실행하는 데 성공했습니다.
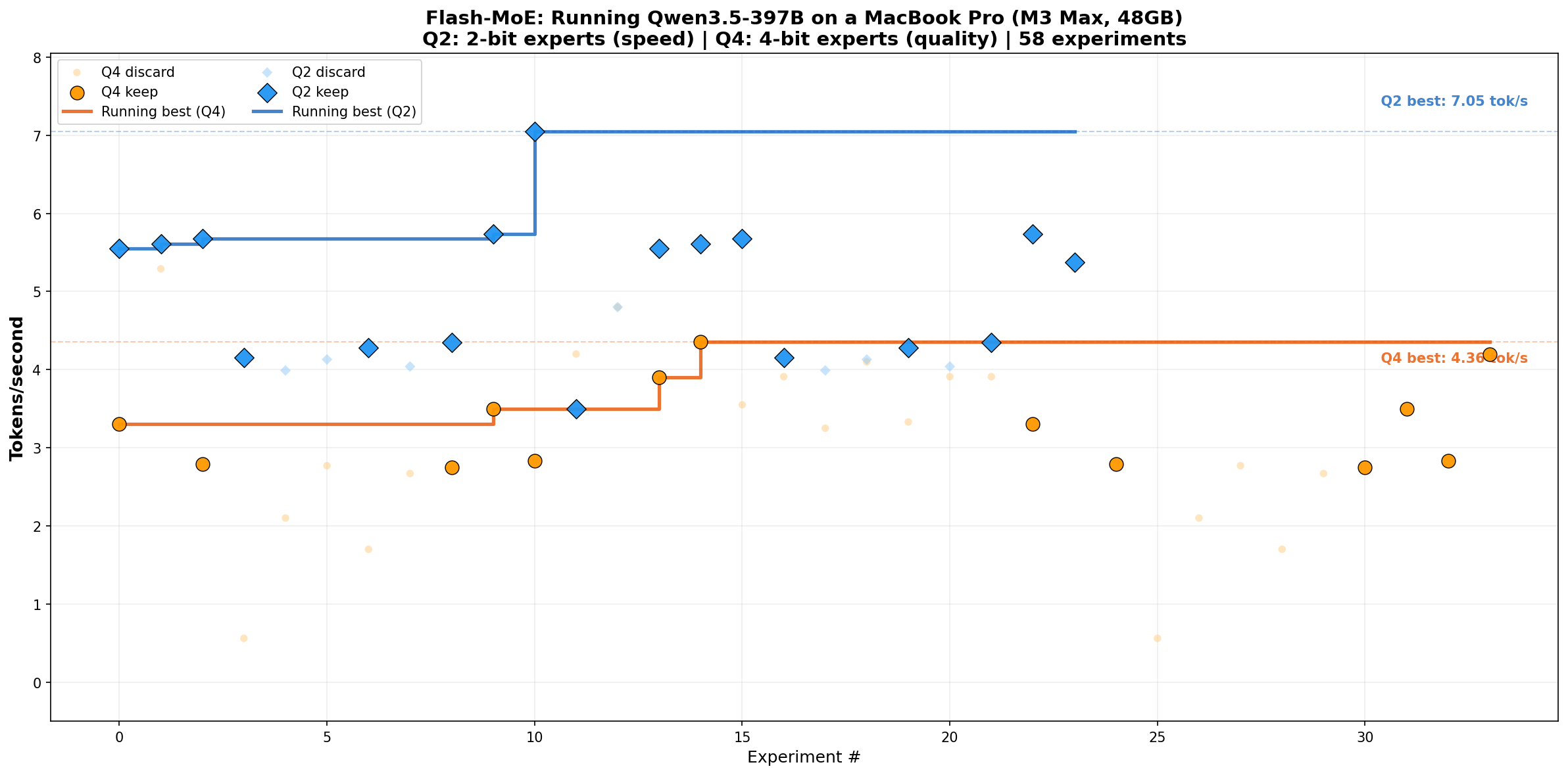
flash-moe는 vLLM, HuggingFace Transformers 등 Python 기반 추론 프레임워크에 대한 의존성을 완전히 배제하고, 손으로 직접 작성한 Metal 컴퓨트 파이프라인을 통해 209GB에 달하는 모델 가중치 전체를 SSD로부터 스트리밍 방식으로 처리합니다. 4-bit 양자화 설정에서 초당 4.36 토큰 이상의 속도를 기록하며, 완전한 JSON 호환 함수 호출(tool calling)까지 지원하는 수준의 출력 품질을 보여줍니다. 2-bit 양자화 설정에서는 초당 5.74 토큰까지 속도가 올라가지만, JSON 출력이 불안정해져 도구 호출에는 적합하지 않습니다.
이 프로젝트는 Apple Silicon의 독특한 하드웨어 특성, 특히 SSD DMA와 GPU 컴퓨트가 동일한 메모리 컨트롤러를 공유하는 통합 메모리 아키텍처에 대한 깊은 이해를 바탕으로 설계되었습니다. 단순히 모델을 실행하는 것을 넘어, 58회에 달하는 최적화 실험 결과를 논문 형태로 정리하여 GitHub 저장소에 공개했다는 점에서도 MoE 추론 최적화 연구에 있어 귀중한 자료가 됩니다.
대상 하드웨어 및 실행 결과
flash-moe가 테스트된 하드웨어 구성은 다음과 같습니다.
| 항목 | 사양 |
|---|---|
| 기기 | MacBook Pro (Apple M3 Max) |
| CPU | 16코어 (12 성능 + 4 효율) |
| GPU | 40코어 |
| 메모리 | 48GB 통합 메모리 (~400GB/s 대역폭) |
| SSD | Apple Fabric 1TB, 17.5 GB/s 순차 읽기 속도 |
| OS | macOS 26.2 (Darwin 25.2.0) |
이 환경에서의 성능 결과는 다음과 같습니다.
| 설정 | 토큰/초 | 품질 | 비고 |
|---|---|---|---|
| 4-bit 전문가, FMA 커널 | 4.36 | 우수 | 현재 최선. 전체 tool calling 지원. 209GB |
| 4-bit 전문가, 기본 | 3.90 | 우수 | FMA 커널 최적화 전 |
| 2-bit 전문가, OS 신뢰 | 5.74 | 양호* | 120GB. *JSON/tool calling 불안정 |
| 2-bit 단일 토큰 최대 | 7.05 | 양호* | 따뜻한 캐시 순간 최대값 |
2-bit 양자화의 경우 JSON 출력에서 "name" 대신 \name\ 형태가 생성되는 문제가 있어 tool calling이 불안정합니다. 프로덕션 환경에서는 4-bit 설정이 권장됩니다.
Qwen3.5-397B-A17B 모델 아키텍처
실행 대상 모델인 Qwen3.5-397B-A17B는 총 60개의 트랜스포머 레이어로 구성됩니다. 이 중 45개는 GatedDeltaNet(선형 어텐션) 레이어이며, 15개는 표준 전체 어텐션 레이어입니다. 각 레이어는 512개의 전문가(expert) 중 토큰당 K=4개가 활성화되는 MoE 구조를 가지며, 공유 전문가 1개가 추가됩니다. 숨겨진 차원(hidden dimension)은 4096입니다.
4-bit 양자화된 모든 전문가 가중치의 총 용량은 209GB로, 이를 MacBook Pro의 48GB 통합 메모리에 모두 올리는 것은 물리적으로 불가능합니다. flash-moe는 이 근본적인 문제를 SSD로부터의 온디맨드(on-demand) 스트리밍 방식으로 해결합니다.
핵심 최적화 기술
SSD 전문가 스트리밍과 "OS 신뢰" 원칙
flash-moe의 가장 핵심적인 아이디어는 전문가 가중치(209GB)를 SSD로부터 병렬 pread() 시스템 콜과 GCD(Grand Central Dispatch) 디스패치 그룹을 이용하여 온디맨드로 읽는 것입니다. 각 레이어에서 K=4개의 활성 전문가만 로드하며 각 전문가의 크기는 약 6.75MB입니다. OS 페이지 캐시가 표준 LRU 방식으로 전문가 데이터 캐싱을 전담하는데, 이를 "Trust the OS(OS를 신뢰하라)" 원칙이라 부릅니다.
이 아이디어는 Apple의 "LLM in a Flash" 논문에서 영감을 받았습니다. 흥미롭게도 Metal LRU 캐시, malloc 캐시, LZ4 압축 캐시 등 직접 구현한 모든 커스텀 캐싱 방법이 GPU 메모리 압박이나 추가 오버헤드로 인해 OS 페이지 캐시보다 성능이 낮았습니다. OS 페이지 캐시는 별도 구현 없이도 약 71%의 캐시 히트율을 자연스럽게 달성합니다.
FMA 최적화 역양자화 커널
4-bit 역양자화된 행렬-벡터 곱셈의 내부 루프 연산을 수학적으로 재배열하는 기법입니다. 기존의 (nibble * scale + bias) * x 연산을 fma(nibble, scale*x, bias*x) 형태로 변환하여, scale*x와 bias*x를 미리 계산해두면 GPU의 FMA(Fused Multiply-Add) 유닛이 역양자화와 곱셈을 단 한 번의 명령어로 처리할 수 있습니다. 이 간단한 수학적 변환만으로 단순 구현 대비 12% 속도 향상이 가능합니다.
손으로 작성한 Metal 컴퓨트 셰이더
GPU 연산에는 다음과 같은 커스텀 Metal 커널이 사용됩니다. 각 커널은 타일링, SIMD 리덕션, 공유 입력 캐시 등 하드웨어 특성을 최대한 활용하는 방향으로 수동 최적화되었습니다.
- 4-bit 및 2-bit 역양자화 행렬-벡터 곱셈 (FMA 최적화 포함)
- 퓨즈된 SwiGLU 활성화 함수
- RMS 정규화 (두 단계: 제곱합 리덕션 + 적용)
- 전체 어텐션 레이어를 위한 배치 GPU 어텐션 (Q@K^T → 소프트맥스 → scores@V)
- GPU RoPE (Q 역인터리브 및 K 정규화와 퓨즈)
- MoE 결합 + 잔차 연결 + 시그모이드 게이트 (퓨즈된 단일 커널)
지연 GPU 전문가 실행 (Deferred CMD3)
전문가 순방향 패스(CMD3)는 결과를 기다리지 않고 비동기적으로 제출됩니다. GPU가 이를 처리하는 동안 CPU는 다음 레이어를 준비합니다. 결합 커널, 잔차 연결, 정규화까지 모두 GPU에서 처리하며, 그 결과가 다음 레이어의 어텐션 프로젝션으로 직접 연결됩니다.
Accelerate BLAS를 이용한 선형 어텐션 가속
GatedDeltaNet 레이어의 점화식(recurrence)은 Apple의 Accelerate 프레임워크에 포함된 cblas_sscal, cblas_sgemv, cblas_sger를 이용하여 64개 헤드 × 128×128 상태 행렬 업데이트를 처리합니다. 스칼라 코드 대비 무려 64% 빠른 성능을 제공합니다.
레이어당 파이프라인 상세 구조
4-bit 설정에서 레이어당 평균 처리 시간은 4.28ms이며, 파이프라인은 다음과 같이 직렬로 구성됩니다.
이전 CMD3 실행(GPU 비동기)
→ CMD1: 어텐션 프로젝션 + GatedDeltaNet [평균 1.22ms, GPU]
→ CPU: 결과 플러시 [0.01ms]
→ CMD2: o_proj + 정규화 + 라우팅 + 공유 [0.55ms, GPU]
→ CPU: 소프트맥스 + topK 라우팅 [0.003ms]
→ I/O: 병렬 pread K=4 전문가 로드 [2.41ms, SSD]
→ CMD3: 전문가 순방향 + 결합 + 정규화 [0.04ms 인코딩, 지연 실행]
Apple Silicon에서 SSD DMA와 GPU 컴퓨트는 동일한 메모리 컨트롤러를 공유하므로 수익성 있게 오버랩할 수 없습니다. GPU의 역양자화 커널은 약 418 GiB/s의 대역폭을 포화 상태로 사용하는데, 소량의 SSD DMA 백그라운드 작업만으로도 메모리 컨트롤러 경합을 통해 GPU 지연 스파이크가 불균형적으로 발생합니다. 이 직렬 파이프라인(GPU → SSD → GPU)이 현재 하드웨어에서 최적입니다.
시도했으나 효과가 없었던 최적화 58가지
프로젝트의 실험 로그(results.tsv)에는 58개의 최적화 시도 결과가 기록되어 있습니다. 주요 실패 사례는 다음과 같으며, 이는 MoE 추론 연구자들에게 매우 귀중한 자료입니다.
| 시도 | 결과 | 이유 |
|---|---|---|
| LZ4 전문가 압축 | -13% 성능 저하 | 압축 해제 오버헤드 > 캐시 절약 |
| F_RDADVISE 프리페치 | 성능 변화 없음 | Apple Silicon에서 SSD DMA가 GPU 성능 73% 저하 |
| 시간적 전문가 예측 | -18% 성능 저하 | 25% 적중률로 SSD 대역폭만 낭비 |
| MLP 라우팅 예측기 | 31% 정확도 | 시간적 기준선보다 나쁨 |
| GPU LUT 역양자화 커널 | -2% | 간접 레지스터 접근이 직렬화됨 |
| mmap 전문가 파일 | 5배 느림 | 콜드 데이터의 페이지 폴트 오버헤드 |
| 스핀 폴 GPU 대기 | -23% | CPU 열 발생이 GPU와 경쟁 |
| 투기적 조기 라우팅 | -38% | 캐시 오염 + 오버헤드 |
| 투기적 디코딩 | 성능 변화 없음 | MoE에서 I/O는 토큰별로 스케일되어 밀집 모델과 다름 |
flash-moe 빠른 시작
cd metal_infer
make
# 4-bit 추론 (packed_experts/ 디렉터리 필요)
./infer --prompt "Explain quantum computing" --tokens 100
# 2-bit 추론 (빠르지만 tool calling 불안정)
./infer --prompt "Explain quantum computing" --tokens 100 --2bit
# tool calling 지원 대화형 채팅
./chat
# 레이어별 타이밍 분석
./infer --prompt "Hello" --tokens 20 --timing
 flash-moe 프로젝트 GitHub 저장소
flash-moe 프로젝트 GitHub 저장소
더 읽어보기
-
mlx-vlm: M5와 같은 Apple Silicon에 최적화된 MLX 기반 시각-언어 모델(VLM) 추론 및 파인튜닝 도구
-
MoD(Mixture-of-Depths): Transformer 기반 언어 모델 연산 최적화를 위한 접근법, 그리고 MoDE(MoD+MoE)
-
Cactus: 스마트폰, 웨어러블 기기 등에서의 On-Device AI를 위한 고성능 추론 엔진 및 커널 라이브러리
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()