들어가며 

DeepSeek에서 이번 주, 하루에 하나씩, 인프라와 관련한 GitHub 저장소를 공개하기로 하였습니다. FlashMLA는 그 첫번째 저장소로, Hopper Architecture에 최적화된 MLA(Muli-Head Latent Attention) 디코딩을 위한 FlashMLA 저장소를 공개했습니다. 매일 하나씩 살펴보겠습니다. ![]()
FlashMLA 소개
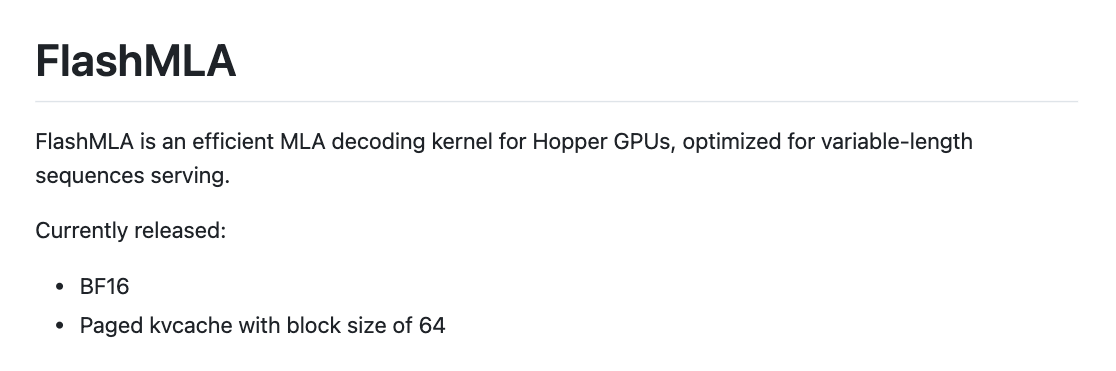
DeepSeek AI에서 공개한 FlashMLA는 Hopper GPU에 최적화된 MLA(Multi-Head Latent Attention) 디코딩을 위해 설계된 커널입니다. 일반적인 MLA 연산은 메모리 및 연산 성능을 극대화해야 하는데, FlashMLA는 이를 최적화하여 메모리 바운드 구성에서 3000 GB/s의 대역폭과 연산 바운드 구성에서 580 TFLOPs의 성능을 제공합니다.
FlashMLA는 가변 길이 시퀀스 처리에 강점을 가지며, BF16 연산과 Paged KVCache를 지원합니다. 높은 메모리 대역폭과 연산 성능을 요구하는 환경에서 최적의 성능을 보이는 것으로 알려져 있습니다. 특히, 가변 길이 시퀀스를 처리할 때 최적의 성능을 제공하도록 설계되었습니다. 기존 MLA 기법은 주로 고정 길이 시퀀스에서 성능을 극대화하는 반면, FlashMLA는 유연한 처리 방식을 채택하여 실시간 응용 환경에서 더 강점을 보입니다.
FlashMLA의 주요 특징들은 다음과 같습니다:
- BF16(BFloat16) 지원: 반정밀도 연산을 통해 성능과 메모리 사용량을 균형 있게 조정.
- Paged KVCache 지원: 64 블록 단위로 관리되는 효율적인 키-값 캐시 구조.
- CUDA 12.3 이상 및 PyTorch 2.0 이상 필요: 최신 GPU 소프트웨어 환경에서 동작.
설치 및 사용 방법
FlashMLA는 GitHub 저장소를 복제(clone)하여 설치 스크립트를 실행하여 설치합니다:
python setup.py install
FlashMLA는 PyTorch 환경에서 쉽게 사용할 수 있도록 제공됩니다. 핵심적인 MLA 연산을 수행하는 코드 예시는 다음과 같습니다:
from flash_mla import get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
for i in range(num_layers):
# ... 생략 ...
o_i, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, cache_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
)
# ... 생략 ...
위 코드에서는 get_mla_metadata() 를 이용해 MLA 연산을 위한 메타데이터를 생성하고, flash_mla_with_kvcache() 를 통해 최적화된 MLA 연산을 수행합니다.
참고
FlashMLA는 기존의 FlashAttention 2 & 3 (GitHub 링크) 및 Cutlass (GitHub 링크) 프로젝트에서 영감을 받아 개발하였습니다.
라이선스
이 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
 FlashMLA GitHub 저장소
FlashMLA GitHub 저장소
더 읽어보기
-
FlashAttention: GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention
-
Cutlass: GitHub - NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines
-
DeepSeek의 OpenInfra 소개 저장소: GitHub - deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation
-
Day 1. FlashMLA: FlashMLA: Hopper GPU를 위한 고성능 MLA 디코딩 커널 (feat. DeepSeek)
-
Day 2. DeepEP: DeepEP: 효율적인 Mixture-of-Experts 병렬 통신 라이브러리 (feat. DeepSeek)
-
Day 3. DeepGEMM: DeepGEMM: NVIDIA Hopper GPU에서 효율적인 FP8 연산을 위한 GEMM 커널 라이브러리 (feat. DeepSeek)
-
Day 4-1. EPLB: EPLB: MoE 모델에서 GPU들 간의 부하를 분배(Load Balancing)하는 라이브러리 (feat. DeepSeek)
-
Day 4-2. DualPipe: DualPipe: 양방향 파이프라인 병렬화 알고리즘 (feat. DeepSeek)
-
Day 4-3. 프로파일링 데이터: DeepSeek-V3/R1 모델 학습 및 추론 시 수집한 프로파일링 데이터 공개 (feat. DeepSeek)
-
Day 5. 3FS(Fire-Flyer File System): https://discuss.pytorch.kr/t/3fs-fire-flyer-file-system-feat-deepseek/6245
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()