
들어가며 

DeepSeek에서 지난 월요일부터 금요일까지, 하루에 하나씩, 인프라와 관련한 GitHub 저장소를 공개했습니다. 어제(토요일)는 추가로 DeepSeek-V3/R1의 추론 시스템 개요(Inference System Overview)를 공개했는데요, 함께 살펴보시죠 ![]()
DeepSeek-V3/R1 추론 시스템 소개
DeepSeek-AI가 더 높은 처리량과 더 낮은 지연시간을 목표로 설계한 DeepSeek-V3/R1 모델의 추론 시스템 설계를 공개했습니다. 노드 간의 Expert Parallelism(EP)을 활용하여 GPU 간 작업을 효율적으로 분배하고, 통신과 연산을 중첩하는 기법을 적용하여 통신 오버헤드를 줄이는 설계를 기본적으로 수행하였습니다.
일반적인 병렬 구조는 시스템 복잡도를 증가시키며 다음과 같은 문제를 초래합니다:
-
노드 간 통신 증가: 통신과 계산을 효율적으로 오버랩(overlap)하지 않으면 지연시간이 증가할 수 있음
-
로드 밸런싱 필요성: 데이터 병렬 처리(DP)와 전문가 병렬 처리(EP) 간의 부하를 균형있게 분배하기 어려움
이러한 문제를 해결하기 위해, DeepSeek에서 도입한 방법들은 다음과 같습니다:
| 요소 | 기존 서빙 방식 | DeepSeek-V3/R1 |
|---|---|---|
| 병렬 처리 방식 | 기본적인 데이터 병렬 처리(DP) | 크로스-노드 Expert Parallelism (EP) 적용 |
| GPU 사용 방식 | 모든 GPU가 동일한 작업 수행 | 일부 GPU는 특정 전문가(Expert)만 처리 |
| 통신 최적화 | 기본적인 통신 방식 사용 | 통신-계산 중첩 기법 적용 |
| 로드 밸런싱 | DP 중심의 단순 로드 분배 | EP 및 DP의 부하를 최적화하는 로드 밸런싱 시스템 |
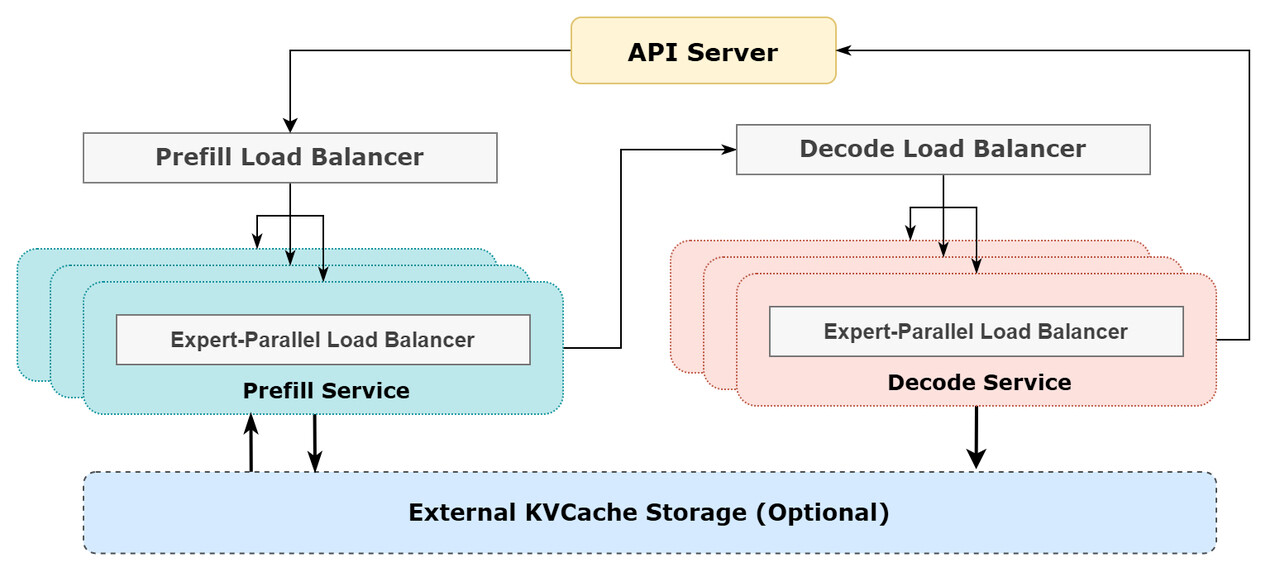
-
대규모 크로스-노드 Expert Parallelism (EP): DeepSeek-V3/R1은 256개의 전문가(Experts)를 포함하며, 한 레이어당 8개의 전문가만 활성화됩니다. 이를 활용하여 배치 크기를 대폭 늘리고, GPU 연산 효율을 극대화함으로써 처리량을 증가시키고 지연시간을 감소시킵니다. 특히, Prefill과 Decode 단계에서 서로 다른 병렬 방식 적용하였습니다.
- Prefill 단계: 4개 노드 단위로 32개의 전문가 배치 (EP32, DP32)
- Decode 단계: 18개 노드 단위로 32개의 전문가 배치 (EP144, DP144)
-
통신연산 중첩 기법: 크로스-노드 EP 구조는 큰 통신 비용을 발생시키므로, 이를 줄이기 위해 이중 배치(overlapping dual-batch) 전략을 적용하였습니다. 먼저, Prefill 단계에서는 마이크로배치를 2개로 나누어 교차 실행하고, 이 때 한 마이크로배치의 통신이 진행될 때 다른 마이크로배치의 계산이 수행되도록 설계하였습니다. 이후, Decode 단계에서는 어텐션(attention) 연산을 2단계로 나누고 5단계 파이프라인을 적용하여, 불균형한 실행 시간을 해결하였습니다.
-
로드 밸런싱 최적화: 병렬 처리를 효과적으로 활용하려면 각 GPU의 부하가 균형있게 잡혀야 합니다. 이를 위해 세 가지 로드 밸런싱 기법을 적용하였습니다:
- Prefill Load Balancer: 요청 수 및 시퀀스 길이가 DP 인스턴스마다 달라 불균형이 발생하는 문제를 해결하기 위해, 각 GPU가 균일한 양의 core-attention 연산 및 input 토큰을 처리하도록 분배합니다.
- Decode Load Balancer: 시퀀스 길이가 다르면 KVCache 사용량이 불균형해지는 문제가 발생합니다. 이를 해결하기 위해 KVCache 사용량을 균등화하여 연산 부하를 분산합니다.
- Expert-Parallel Load Balancer: MoE(Mixture of Experts) 모델 내 일부 전문가가 높은 부하를 가지는 경향이 발생하는 경우, 이를 해결하기 위해 각 GPU의 전문가 연산 부하를 균등하게 배분하여, 발생하는 처리 부하의 최대치를 감소시킵니다.
성능 및 비용 분석
1. 추론 성능
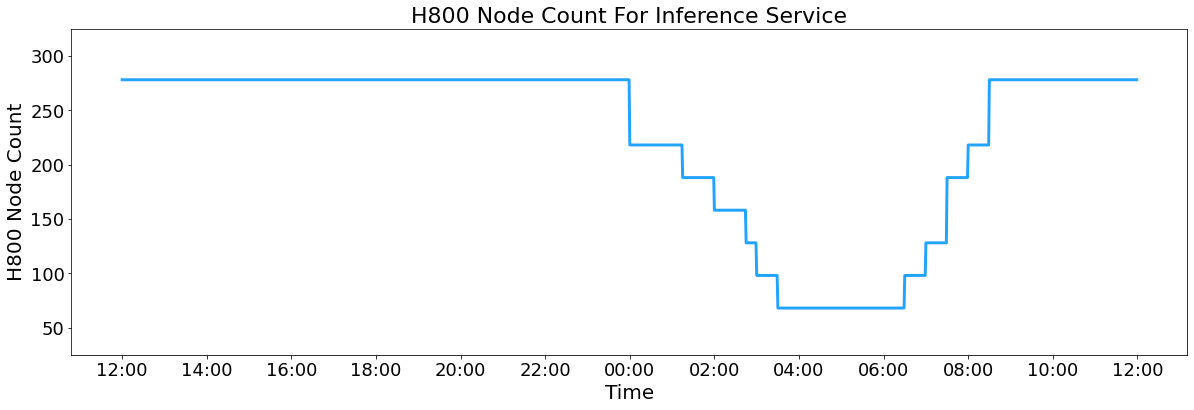
모든 DeepSeek-V3/R1 추론 서비스는 NVIDIA H800 GPU에서 실행됩니다. 이 때, FP8 포맷을 사용하여 행렬 연산 및 데이터 전송을 최적화하고, 핵심 MLA 연산 및 병합 전송은 BF16 포맷으로 진행합니다. 지난 2025년 2월 27일(UTC+8 기준) 정오(12:00)부터 28일 정오(12:00)까지 24시간 동안의 처리량을 살펴보면 다음과 같습니다:
-
총 입력 토큰: 6,080억 토큰 (이 중 56.3%에 해당하는 3,420억개는 KVCache 활용)
-
총 출력 토큰: 1,680억 토큰
-
평균 출력 속도: 초당 20~22 토큰
-
H800 노드별 평균 처리량 :
- Prefill: 초당 73,700 토큰
- Decode: 초당 14,800 토큰
2. 비용 및 수익 분석
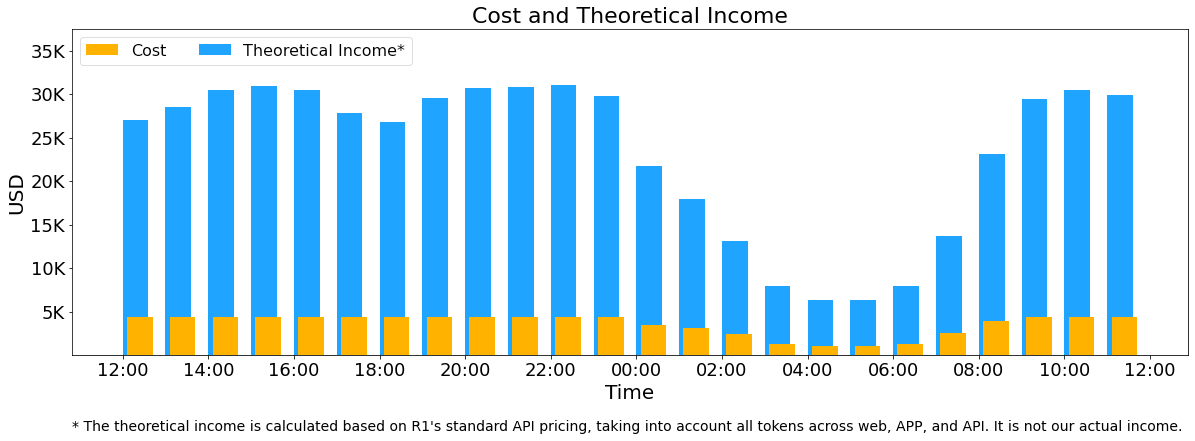
서비스 운영을 위한 총 GPU 사용량은 다음과 같습니다:
-
피크 시점: 278개 노드 (각 노드당 8개의 H800 GPU 탑재)
-
평균 사용량: 226.75개 노드
-
GPU 임대 비용: 시간 당 $2/시간 기준, 하루 총 비용: $87,072
-
"이론적" 수익 (DeepSeek-R1 가격 기준):
- 입력 토큰: $0.14/M (Cache hit), $0.55/M (Cache miss)
- 출력 토큰: $2.19/M
- 총 이론적 수익 : $562,027
- 이론적 수익률 : 545%
-
하지만, 실제 수익은 다음 이유로 이보다 낮음:
- DeepSeek-V3의 가격이 R1보다 저렴
- 일부 서비스는 무료 제공됨 (웹 및 앱)
- 야간 할인 요금 적용
결론
DeepSeek-V3/R1의 추론 시스템은 대규모 전문가 병렬 처리(EP), 통신-계산 중첩, 로드 밸런싱을 활용하여 성능을 최적화한 것이 특징입니다.
특히, H800 GPU 클러스터를 최대한 활용하면서도 비용을 절감하는 전략을 통해, 수익성 높은 운영이 가능하도록 설계되었습니다.
이러한 접근 방식은 다른 대형 AI 서빙 시스템에서도 참고할 만한 사례이며, 추론 최적화 및 비용 절감이 필요한 기업이나 연구자들에게 많은 인사이트를 줄 수 있을 것입니다.
 DeepSeek-V3/R1 추론 시스템 개요 문서 보기
DeepSeek-V3/R1 추론 시스템 개요 문서 보기
더 읽어보기
-
DeepSeek의 OpenInfra 소개 저장소: GitHub - deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation
-
Day 1. FlashMLA: FlashMLA: Hopper GPU를 위한 고성능 MLA 디코딩 커널 (feat. DeepSeek)
-
Day 2. DeepEP: DeepEP: 효율적인 Mixture-of-Experts 병렬 통신 라이브러리 (feat. DeepSeek)
-
Day 3. DeepGEMM: DeepGEMM: NVIDIA Hopper GPU에서 효율적인 FP8 연산을 위한 GEMM 커널 라이브러리 (feat. DeepSeek)
-
Day 4-1. EPLB: EPLB: MoE 모델에서 GPU들 간의 부하를 분배(Load Balancing)하는 라이브러리 (feat. DeepSeek)
-
Day 4-2. DualPipe: DualPipe: 양방향 파이프라인 병렬화 알고리즘 (feat. DeepSeek)
-
Day 4-3. 프로파일링 데이터: DeepSeek-V3/R1 모델 학습 및 추론 시 수집한 프로파일링 데이터 공개 (feat. DeepSeek)
-
Day 5. 3FS(Fire-Flyer File System): 3FS(Fire-Flyer File System), 고성능 분산 파일 시스템 (feat. DeepSeek)
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()