들어가며 

DeepSeek에서 이번 주, 하루에 하나씩, 인프라와 관련한 GitHub 저장소를 공개하기로 하였습니다. 오늘은 DeepSeek-V3 및 DeepSeek-R1 모델 개발 시 사용했던 최적화 전략 및 코드들에 대한 저장소 3개를 한꺼번에 공개했습니다. 그 중 두번째로 DualPipe 저장소를 살펴보겠습니다. ![]()
DualPipe 소개
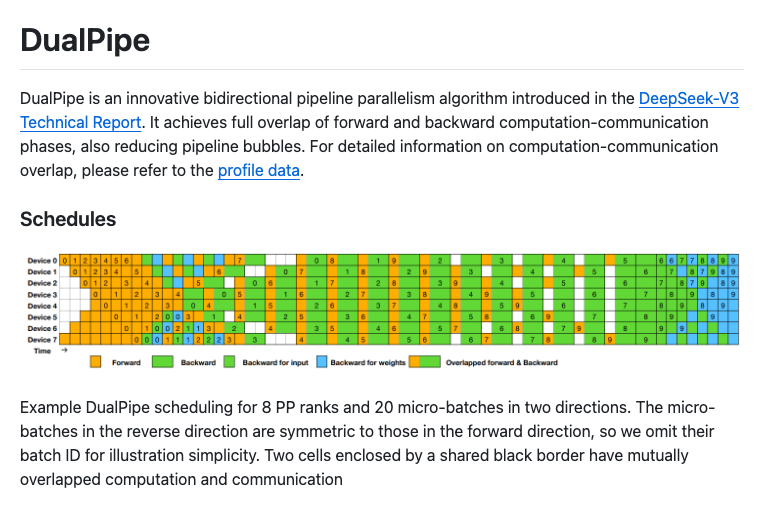
DeepSeek AI가 제안한 DualPipe는 DeepSeek-V3 Technical Report에서 소개되었으며, 파이프라인 병렬화에서 연산-통신 단계를 완전히 겹치게 하여 성능을 극대화하는 알고리즘입니다. 기존 방식보다 파이프라인 버블을 줄이고, 메모리 효율을 개선하는 것이 특징입니다.
DualPipe를 사용하면 병렬 학습에서 한 단계의 계산이 완료되기 전에 다음 단계가 시작되지 않아 발생하는 비효율적인 유휴 시간을 뜻하는 '파이프라인 버블(Pipeline Bubble)'을 최소화할 수 있으며, 모델의 훈련 속도를 향상시키고, 메모리 사용량을 효율적으로 관리할 수 있습니다. 이는 특히 대규모 분산 학습에서 중요한 요소입니다.

기존의 1F1B(1 Forward 1 Backward) 및 ZB1P(Zero Bubble 1 Pipeline) 방식과 비교했을 때, 연산과 통신이 완전히 겹치도록 설계되어 더 나은 성능을 보이는 것이 특징으로, 다음 표와 같이 비교해볼 수 있습니다:
| 방법 | 버블 크기 | 파라미터 사용량 | 활성화 메모리 |
|---|---|---|---|
| 1F1B | (PP-1)(𝐹+𝐵) | 1× | PP |
| ZB1P | (PP-1)(𝐹+𝐵-2𝑊) | 1× | PP |
| DualPipe | (PP/2-1)(𝐹&𝐵+𝐵-3𝑊) | 2× | PP+1 |
• 𝐹: 순전파(Forward) 실행 시간
• 𝐵: 역전파(Backward) 실행 시간
• 𝑊: 가중치에 대한 역전파 실행 시간
• 𝐹&𝐵: 서로 겹치는 순전파와 역전파 실행 시간
위 표에서 알 수 있듯이, DualPipe는 기존 방법보다 파이프라인 버블을 줄이면서도 메모리 사용량을 효율적으로 관리 할 수 있도록 설계되었습니다.
DualPipe의 주요 특징
-
연산-통신 겹침(Computation-Communication Overlap): 순전파와 역전파 단계가 동시에 실행되도록 하여, 병렬 학습 시 계산 리소스를 최대한 활용할 수 있도록 합니다.
-
파이프라인 버블 감소: 기존 방식 대비 계산 공백을 줄여 모델 훈련 시간을 단축합니다.
-
메모리 사용 최적화: ZB1P 방식보다 더 적은 메모리를 사용하면서도 비슷한 성능을 유지합니다.
-
PyTorch 2.0 이상 지원: 최신 PyTorch 환경에서 실행할 수 있도록 설계되었습니다.
단, DualPipe를 실제 응용에서 사용하기 위해서는 overlapped_forward_backward() 메서드를 사용하려는 각 모델에 맞게 구현해야 합니다. 즉, DualPipe의 성능을 활용하려면, 모델 구조와 요구 사항에 맞춰 사용자 정의 설정이 필요합니다.
라이선스
DualPipe 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
 DualPipe 라이브러리 GitHub 저장소
DualPipe 라이브러리 GitHub 저장소
https://github.com/deepseek-ai/DualPipe
더 읽어보기
-
DeepSeek의 OpenInfra 소개 저장소: GitHub - deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation
-
Day 1. FlashMLA: FlashMLA: Hopper GPU를 위한 고성능 MLA 디코딩 커널 (feat. DeepSeek)
-
Day 2. DeepEP: DeepEP: 효율적인 Mixture-of-Experts 병렬 통신 라이브러리 (feat. DeepSeek)
-
Day 3. DeepGEMM: DeepGEMM: NVIDIA Hopper GPU에서 효율적인 FP8 연산을 위한 GEMM 커널 라이브러리 (feat. DeepSeek)
-
Day 4-1. EPLB: EPLB: MoE 모델에서 GPU들 간의 부하를 분배(Load Balancing)하는 라이브러리 (feat. DeepSeek)
-
Day 4-2. DualPipe: DualPipe: 양방향 파이프라인 병렬화 알고리즘 (feat. DeepSeek)
-
Day 4-3. 프로파일링 데이터: DeepSeek-V3/R1 모델 학습 및 추론 시 수집한 프로파일링 데이터 공개 (feat. DeepSeek)
-
Day 5. 3FS(Fire-Flyer File System): 3FS(Fire-Flyer File System), 고성능 분산 파일 시스템 (feat. DeepSeek)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()