
들어가며 

DeepSeek에서 이번 주, 하루에 하나씩, 인프라와 관련한 GitHub 저장소를 공개하기로 하였습니다. 오늘은 DeepSeek-V3 및 DeepSeek-R1 모델 개발 시 사용했던 최적화 전략 및 코드들에 대한 저장소 3개를 한꺼번에 공개했습니다. 그 중 세번째로 학습 및 추론 시의 프로파일링 데이터를 살펴보겠습니다. ![]()
프로파일링 데이터 소개
DeepSeek AI가 자사의 학습 및 추론 프레임워크에서 수집한 프로파일링 데이터를 공개했습니다. PyTorch Profiler를 활용하여 수집한 이 데이터는 Chrome이나 Edge의 트레이싱 툴(chrome://tracing 또는 edge://tracing)에서 직접 확인할 수 있습니다. MoE(Mixture-of-Experts) 기반 모델을 사용한 학습 및 추론 과정에서 병렬화 전략이 어떻게 적용되고, 통신과 연산이 어떻게 겹쳐서 수행되는지 등을 분석하는데 유용합니다.
PyTorch Profiler를 사용해 수집한 이번 프로파일링 데이터에 포함된 주요 내용은 다음과 같습니다:
- 학습 프로파일링 데이터(train.json): DeepSeek AI의 DualPipe 프레임워크에서 MoE 기반 모델을 훈련할 때 발생하는 연산 및 통신 흐름 분석 자료
- 추론 과정의 Prefilling 단계(prefill.json): 입력(prompt) 처리를 위한 병렬화 및 연산-통신 오버랩(Overlapping) 전략 포함
- 추론 과정의 Decoding 단계(decode.json, 공개 예정): 디코딩 시점의 통신 및 연산 분배 방식
일반적으로 PyTorch Profiler를 사용하면 모델 내부의 연산 수행 시간과 CUDA 커널 호출 등의 정보를 볼 수 있지만, 대규모 모델의 분산 학습 및 추론 시에는 GPU 간 통신이 성능 병목이 되는 경우가 많습니다. 따라서, 단순한 연산 프로파일링만으로는 통신-연산 병목을 해결하기가 어렵습니다.
DeepSeek에서는 이러한 문제를 해결하기 위해 통신과 연산이 어떻게 겹치는지(Overlapping) 시각적으로 분석할 수 있도록 데이터를 제공합니다. 특히, 이번 주에 공개한 DualPipe나 DeepEP 등과 같이 DeepSeek AI의 최신 기술을 기반으로 한 병렬화 전략을 적용한 프로파일링 결과입니다. 실제 DeepSeek-V3/R1 모델의 배포 환경과 동일한 설정에서 수집된 데이터로, 실제 서비스 환경에서의 성능을 보다 정확하게 반영한다는 점에서 특징적입니다.
학습 프로파일링 (train.json)

DualPipe 프레임워크 기반으로 MoE 모델 훈련 시의 연산-통신 오버랩을 시각화한 데이터입니다. EP64, TP1 설정에서 4K 시퀀스 길이로 실험하였으며, MoE 레이어 4개를 포함한 한 쌍의 Forward 및 Backward Chunk 처리 흐름을 볼 수 있습니다. 단, 연산과 통신 오버랩의 순수한 성능 분석을 위해 PP(Pipeline Parallel) 통신은 포함하지 않았습니다.
추론 과정 (Inference) - Prefilling (prefill.json)
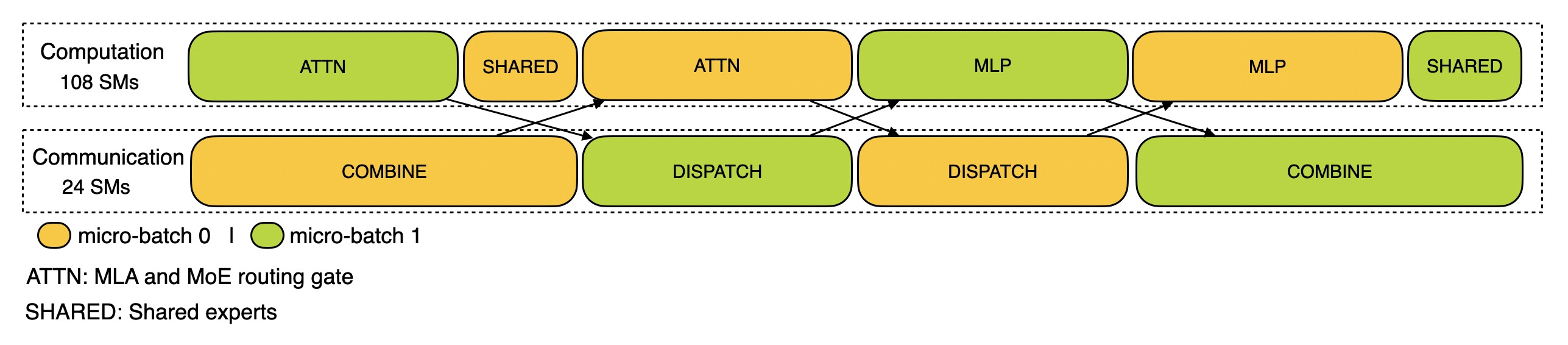
DeepSeek-V3/R1 실제 배포 환경과 동일한 설정(EP32, TP1, 4K Prompt Length, Batch Size 16K Tokens/GPU)에서 수집한 데이터입니다. 두 개의 마이크로 배치(micro-batches) 를 사용하여 연산과 All-to-All 통신을 겹치게 수행하였으며, 마이크로 배치 간의 Attention 연산 부하가 균형적으로 분배되도록 설계하였습니다. 실시간 추론 속도를 높이는 데 중요한 기법을 시각적으로 분석할 수 있습니다.
추론 과정 (Inference) - Decoding (decode.json)
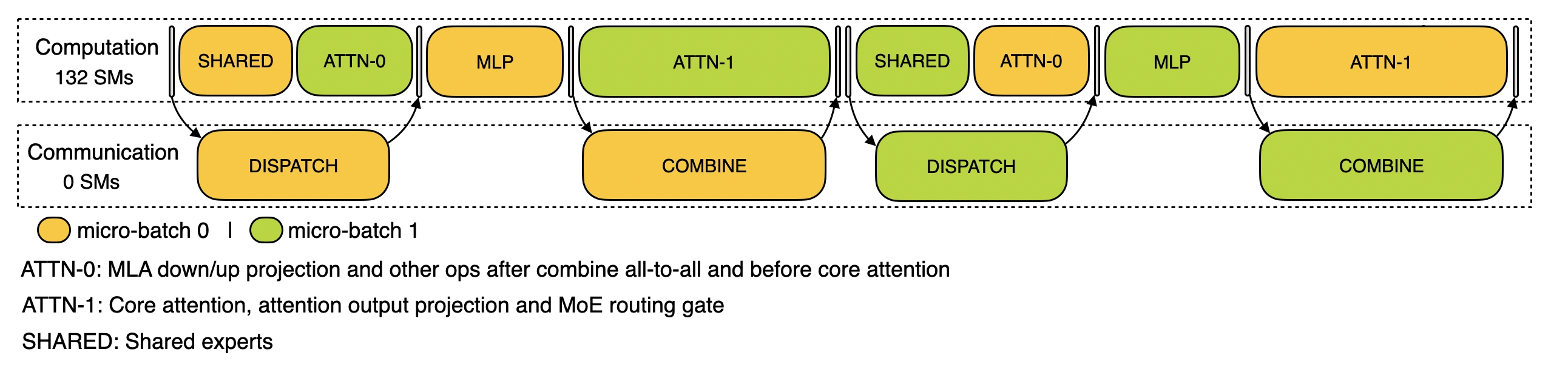
EP128, TP1, 4K Prompt Length, Batch Size 128 Requests/GPU 환경에서 수집한 데이터로, Prefilling과 마찬가지로 두 개의 마이크로 배치를 활용하여 연산-통신을 최적화하였습니다. RDMA(Remote Direct Memory Access)를 이용한 All-to-All 통신을 활용하여 GPU SM 점유율을 최소화하였습니다.
사용 방법
데이터 다운로드
해당 데이터는 JSON 포맷으로 제공되며, 아래 링크에서 다운로드할 수 있습니다.
- 학습 프로파일링 데이터 (train.json)
- Prefilling 프로파일링 데이터 (prefill.json)
- Decoding 프로파일링 데이터 (decode.json) (곧 공개)
Chrome/Edge 브라우저를 사용한 시각화
- Chrome은
chrome://tracing를, Edge에서는edge://tracing을 입력하여 Tracing 페이지를 엽니다. - “Load” 버튼을 클릭한 후, 위에서 다운로드한 JSON 파일을 불러옵니다.
- 시각적으로 연산과 통신이 어떻게 수행되는지 확인할 수 있습니다.
 학습/추론 시 프로파일링 데이터 GitHub 저장소
학습/추론 시 프로파일링 데이터 GitHub 저장소
더 읽어보기
-
PyToch Profiler Recipe: PyTorch 프로파일러(Profiler) — 파이토치 한국어 튜토리얼 (PyTorch tutorials in Korean)
-
DeepSeek의 OpenInfra 소개 저장소: GitHub - deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation
-
Day 1. FlashMLA: FlashMLA: Hopper GPU를 위한 고성능 MLA 디코딩 커널 (feat. DeepSeek)
-
Day 2. DeepEP: DeepEP: 효율적인 Mixture-of-Experts 병렬 통신 라이브러리 (feat. DeepSeek)
-
Day 3. DeepGEMM: DeepGEMM: NVIDIA Hopper GPU에서 효율적인 FP8 연산을 위한 GEMM 커널 라이브러리 (feat. DeepSeek)
-
Day 4-1. EPLB: EPLB: MoE 모델에서 GPU들 간의 부하를 분배(Load Balancing)하는 라이브러리 (feat. DeepSeek)
-
Day 4-2. DualPipe: DualPipe: 양방향 파이프라인 병렬화 알고리즘 (feat. DeepSeek)
-
Day 4-3. 프로파일링 데이터: DeepSeek-V3/R1 모델 학습 및 추론 시 수집한 프로파일링 데이터 공개 (feat. DeepSeek)
-
Day 5. 3FS(Fire-Flyer File System): https://discuss.pytorch.kr/t/3fs-fire-flyer-file-system-feat-deepseek/6245
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()