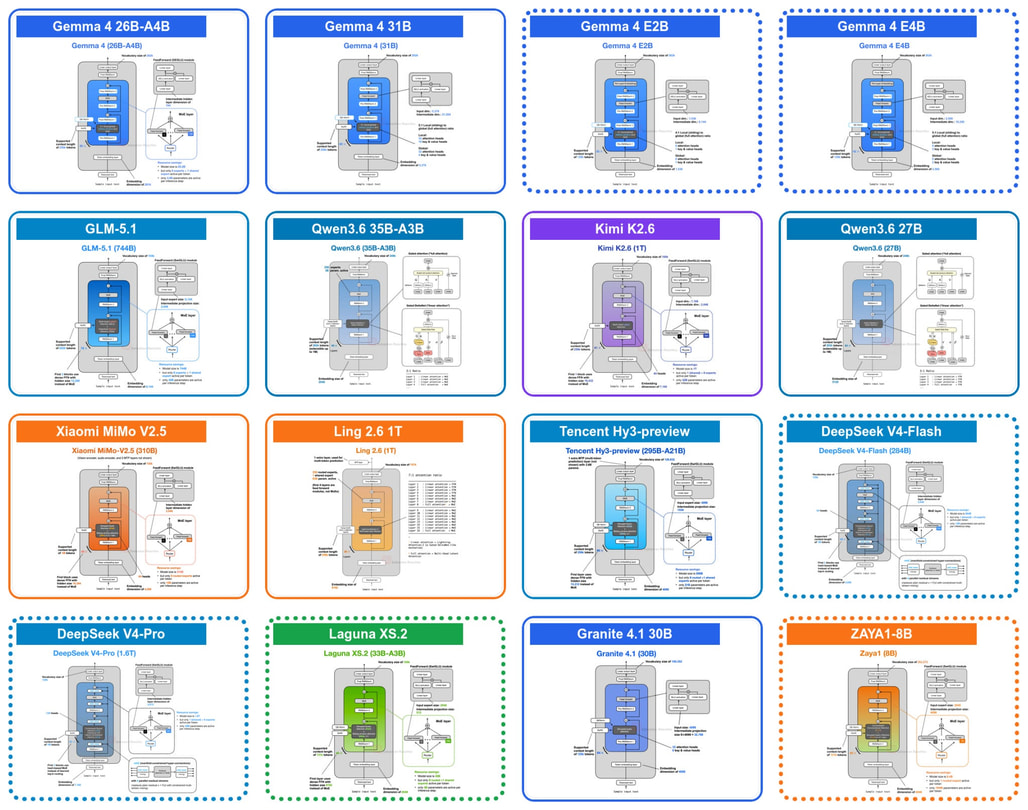
글을 시작하며: 왜 또 다시 아키텍처 이야기인가
Sebastian Raschka는 Build a Large Language Model (From Scratch) 시리즈로 잘 알려진 LLM 교육자이자 연구자입니다. 그가 자신의 뉴스레터 Ahead of AI에 정기적으로 정리하는 LLM 아키텍처 동향 글은, 신규 모델이 쏟아지는 가운데 "정확히 무엇이 새로운가"를 한 발 떨어져 바라볼 수 있게 해주는 거의 유일한 공개 자료에 가깝습니다. 이번 글에서 이전에 공개한 LLM 아키텍처 갤러리에 이어, 2026년 봄까지 공개된 최근 오픈웨이트 모델들의 아키텍처 변경점을, 그것도 모델 카드의 마케팅 문구가 아니라 트랜스포머 블록 안에서 실제로 무엇이 바뀌었는지에 집중하여 정리합니다.
이번 글을 관통하는 한 줄 주제는 다음과 같이 요약할 수 있습니다:
추론(reasoning) 모델과 에이전트 워크플로우의 등장으로 컨텍스트가 점점 더 길어지면서, KV 캐시 크기, 메모리 트래픽, 어텐션 계산 비용이 LLM 아키텍처 설계의 최대 제약 조건이 되었다.
그 결과 최근 발표된 아키텍처들은 모델 파라미터 수를 줄이는 대신, 긴 컨텍스트 추론 비용을 어떻게 낮출 것인가라는 동일한 문제를 서로 다른 각도에서 공략하고 있습니다.
원문에서 다루는 네 가지 모델과 그 핵심 기법은 다음과 같습니다:
-
Gemma 4 의 KV 공유(KV sharing)와 레이어별 임베딩(Per-Layer Embeddings, PLE)
-
Laguna XS.2 의 레이어별 어텐션 버지팅(layer-wise attention budgeting)
-
ZAYA1-8B 의 압축된 합성곱 어텐션(Compressed Convolutional Attention, CCA)
-
DeepSeek V4 의 매니폴드 제약 하이퍼 커넥션(manifold-constrained hyper-connections, mHC)과 압축 어텐션(CSA/HCA)
특히, 데이터셋, 학습 스케줄, RL 레시피, 벤치마크 표 같은 것은 의도적으로 제외하고, 오직 트랜스포머 블록, 잔차 스트림(residual stream), KV 캐시, 어텐션 연산 내부에서 무엇이 바뀌었는지에만 초점을 맞춥니다.
이 글을 읽기 위한 사전 지식으로는 어텐션 메커니즘과 GQA, MLA, sliding-window attention 같은 어텐션 변형들에 대한 개략적인 이해가 도움이 됩니다. Raschka는 동일 뉴스레터의 A Visual Guide to Attention Variants in Modern LLMs와 Understanding and Coding the KV Cache in LLMs from Scratch를 사전 참고 자료로 제시하는데, 본 글의 모든 새로운 기법은 결국 KV 캐시 절감이라는 동일한 출발점에서 파생되었기에 KV 캐시의 동작 원리를 우선 익혀두면 이해의 깊이가 크게 달라집니다.
Gemma 4: KV 공유와 레이어별 임베딩으로 작은 모델 살리기
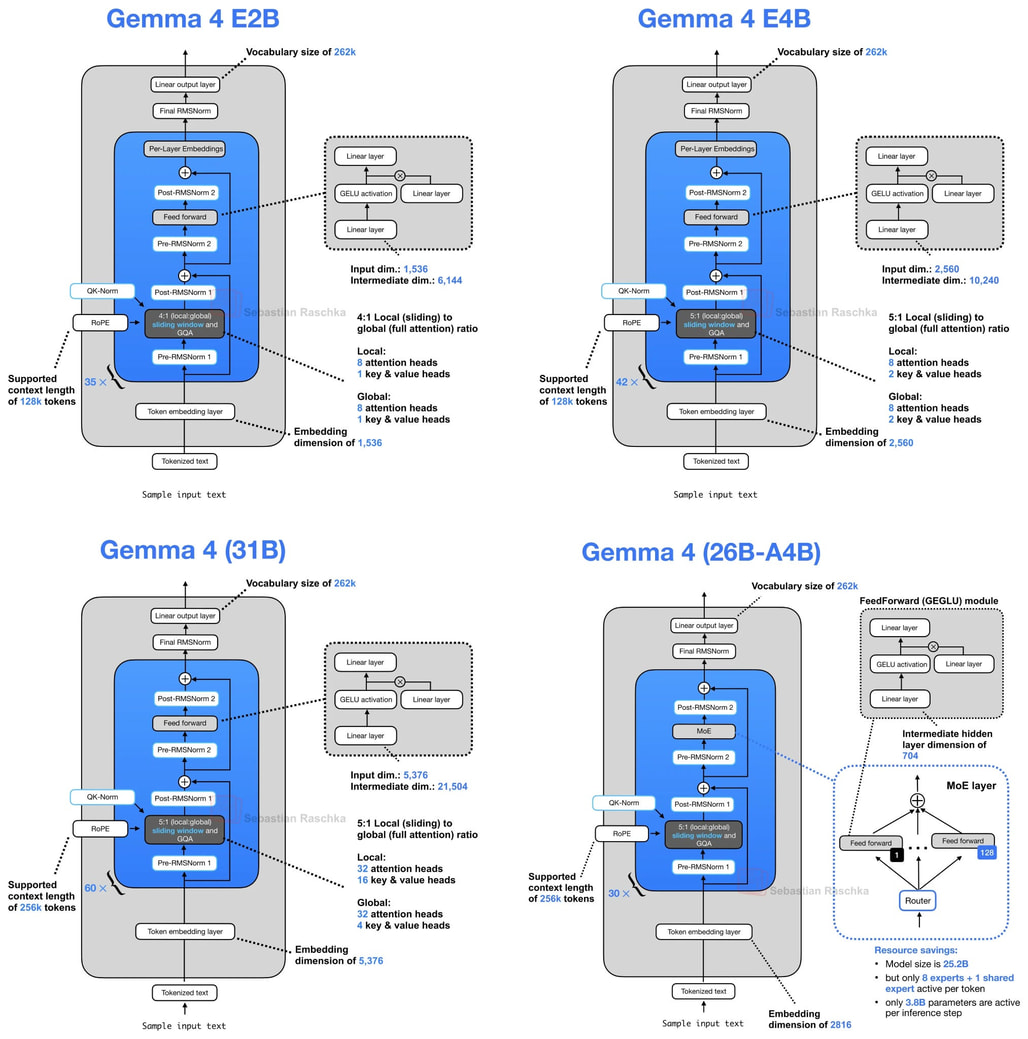
Google DeepMind가 공개한 Gemma 4 시리즈는 크게 세 갈래로 나뉩니다. 모바일과 IoT를 겨냥한 Gemma 4 E2B / E4B, 로컬 추론에 최적화된 Gemma 4 26B MoE, 그리고 후처리 학습(post-training)이 비교적 수월한 Gemma 4 31B 밀집(dense) 모델 입니다. 이 중 E2B와 E4B에서 새로 도입된 두 가지 효율 설계가 이번 글의 주제로, 각각 KV 캐시 크기와 파라미터 효율을 다른 방식으로 공략합니다.
크로스 레이어 KV 공유(Cross-Layer KV Sharing)
Gemma 4의 E2B / E4B 변형이 도입한 첫 번째 기법은 크로스 레이어 어텐션(Cross-Layer Attention) 입니다. 이 개념 자체는 Gemma 4가 처음 제안한 것은 아니며, NeurIPS 2024 논문 Reducing Transformer Key-Value Cache Size with Cross-Layer Attention에서 먼저 정식화되었습니다. 하지만 대규모 오픈웨이트 모델 중에서는 Gemma 4가 가장 눈에 띄는 적용 사례입니다.
먼저 배경부터 짚고 갑시다. 기존의 그룹 쿼리 어텐션(Grouped Query Attention, GQA) 은 같은 레이어 안에서 여러 쿼리 헤드가 K, V 헤드를 공유하여 KV 캐시 크기를 줄이는 기법입니다. Multi-Query Attention(MQA)은 그 극단으로 모든 쿼리 헤드가 단 하나의 K, V 헤드를 공유하는 경우에 해당합니다.
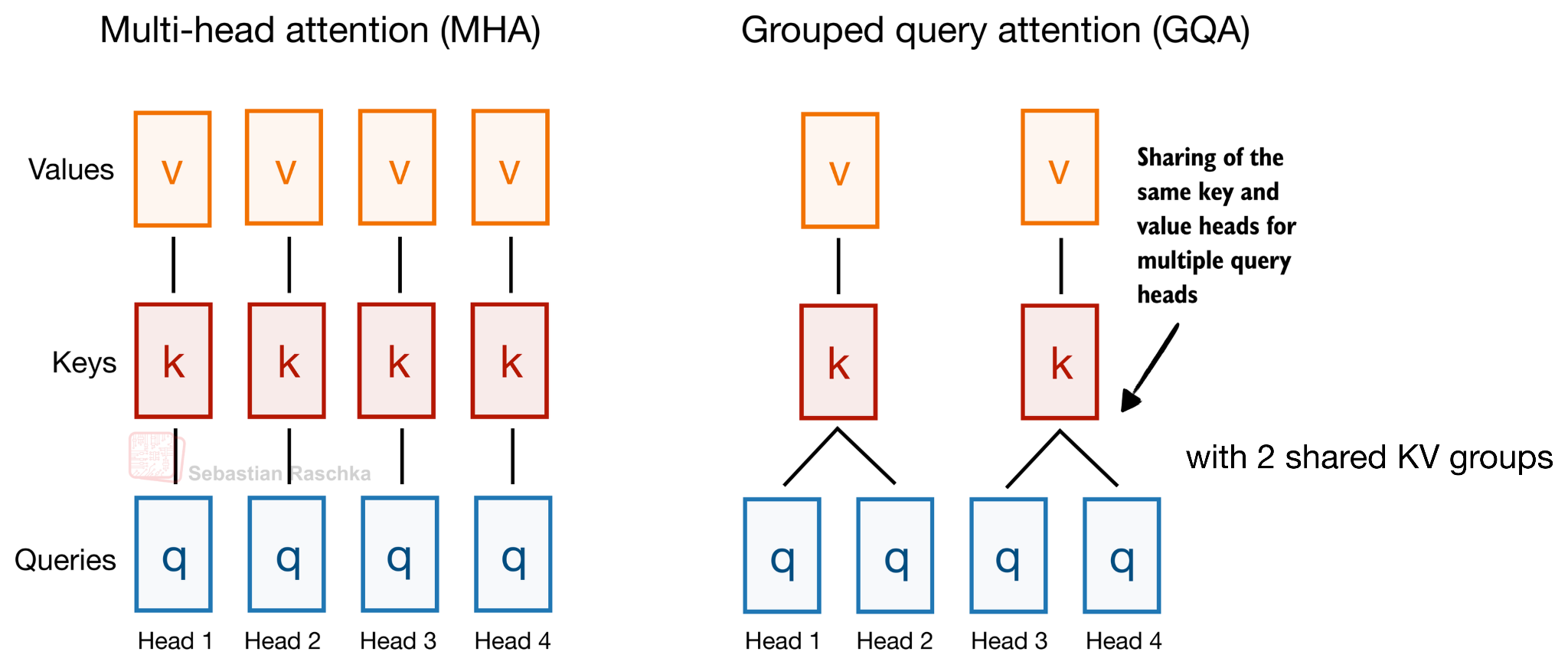
크로스 레이어 어텐션은 여기서 한 걸음 더 나아갑니다. 같은 레이어 내부에서의 KV 공유뿐 아니라, 레이어와 레이어 사이에서도 K, V 프로젝션을 공유 합니다. 즉, 어떤 레이어는 자기 K, V를 새로 계산하지 않고 이전 레이어의 K, V 텐서를 그대로 재사용합니다. 쿼리 프로젝션은 각 레이어가 독립적으로 가지므로 레이어별 어텐션 패턴은 유지되지만, 가장 비싸고 메모리를 많이 차지하는 KV 캐시는 여러 레이어에 걸쳐 재사용됩니다.
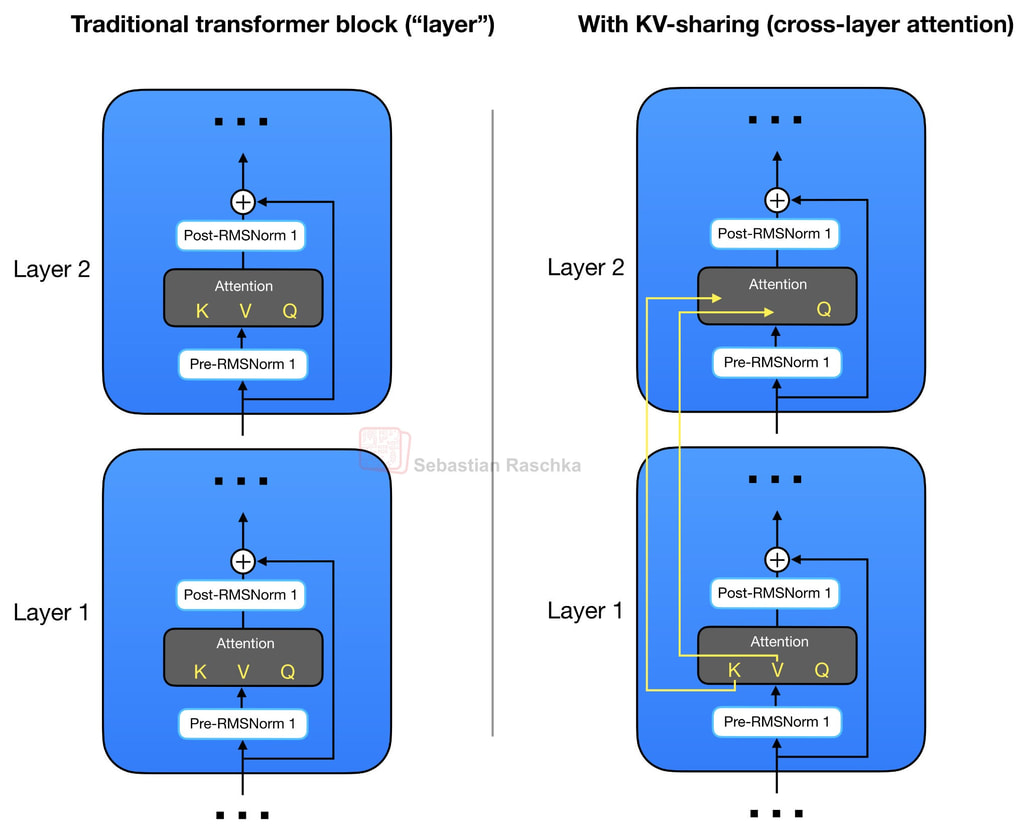
Gemma 4 E2B의 경우 35개 트랜스포머 레이어 중 앞쪽 15개 레이어만 자체 K, V를 계산하고, 나머지 20개 레이어는 같은 어텐션 유형(슬라이딩 윈도우 vs 풀 어텐션)을 가진 가장 가까운 이전 레이어의 K, V를 재사용합니다. E4B는 42 레이어 중 24 레이어가 자체 K, V를 계산하고, 18 레이어가 공유합니다. 또한 GQA(또는 MQA)와 슬라이딩 윈도우 어텐션을 4:1 비율로 섞어 쓴다는 점도 함께 알아두면 좋습니다.
효과는 얼마나 될까요? Raschka의 추산에 따르면 약 절반의 KV를 공유하므로 KV 캐시 크기가 대략 절반으로 줄어듭니다. E2B는 128K 컨텍스트에서 bfloat16 기준 약 2.7 GB, E4B는 약 6 GB의 KV 캐시 절감 효과가 있습니다.
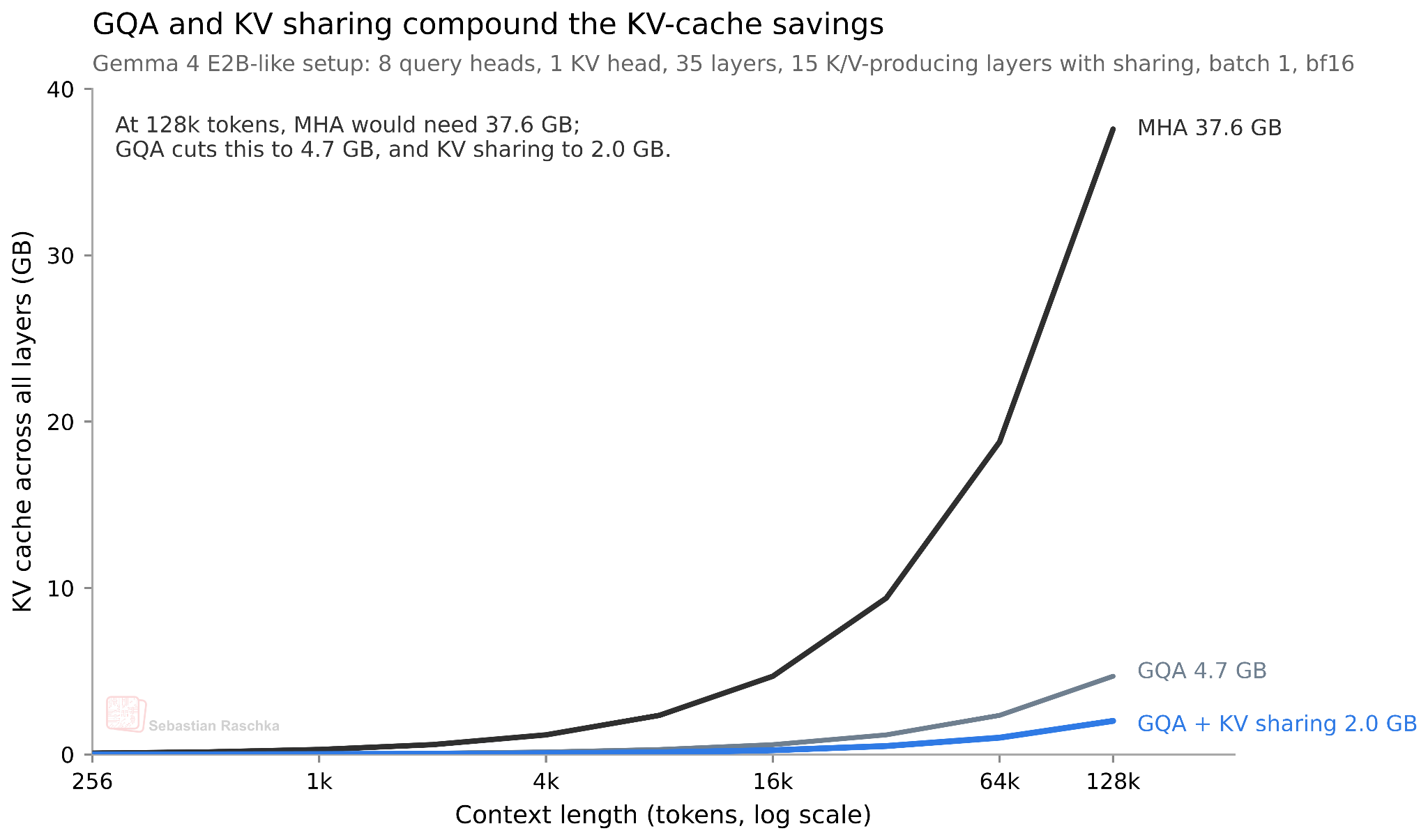
물론 단점이 없는 것은 아닙니다. KV 공유는 본질적으로 풀 KV 계산의 "근사(approximation)"이므로 모델 용량(capacity)을 줄이는 효과가 있습니다. 그러나 원 논문에 따르면 적어도 소형 모델에서는 그 영향이 미미한 것으로 보고되어 있습니다.
레이어별 임베딩(Per-Layer Embeddings, PLE)
E2B와 E4B는 KV 공유와는 별개로 두 번째 효율 설계인 레이어별 임베딩(Per-Layer Embeddings, PLE) 을 도입했습니다. KV 공유가 KV 캐시 크기를 줄이는 기법이라면, PLE는 파라미터 효율(parameter efficiency) 을 노립니다. 즉, 메인 트랜스포머 스택을 두껍게 만들지 않고도 토큰별 정보를 더 많이 담을 수 있게 하는 설계입니다.
이름의 "E"는 "effective"를 의미합니다. 가령 Gemma 4 E2B는 효율적 파라미터(effective parameter) 기준 2.3B이지만, 임베딩까지 포함하면 5.1B가 됩니다. E4B 역시 4.5B vs 8B 입니다. 메인 트랜스포머 스택의 계산량은 작은 쪽 숫자에 가깝고, 추가 용량은 임베딩 테이블에 저장된다는 발상입니다.
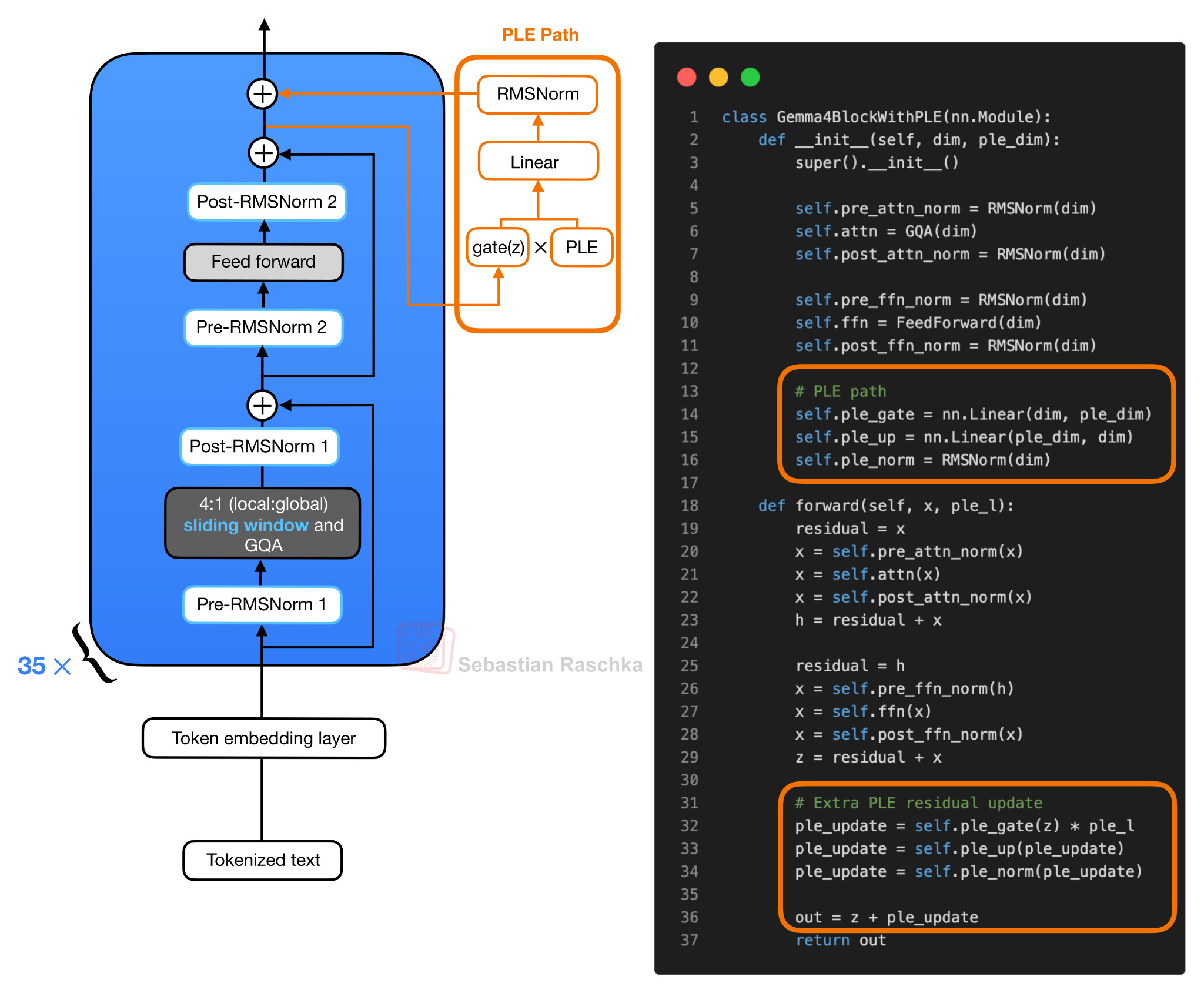
PLE 벡터는 트랜스포머 블록 바깥에서 미리 준비됩니다. 토큰 ID는 레이어별 임베딩 룩업을 거치고, 일반 토큰 임베딩은 동일한 PLE 공간으로 선형 투영됩니다. 이 둘이 합쳐지고 스케일·재구성되어 레이어 하나당 하나의 슬라이스를 가진 텐서로 만들어집니다.
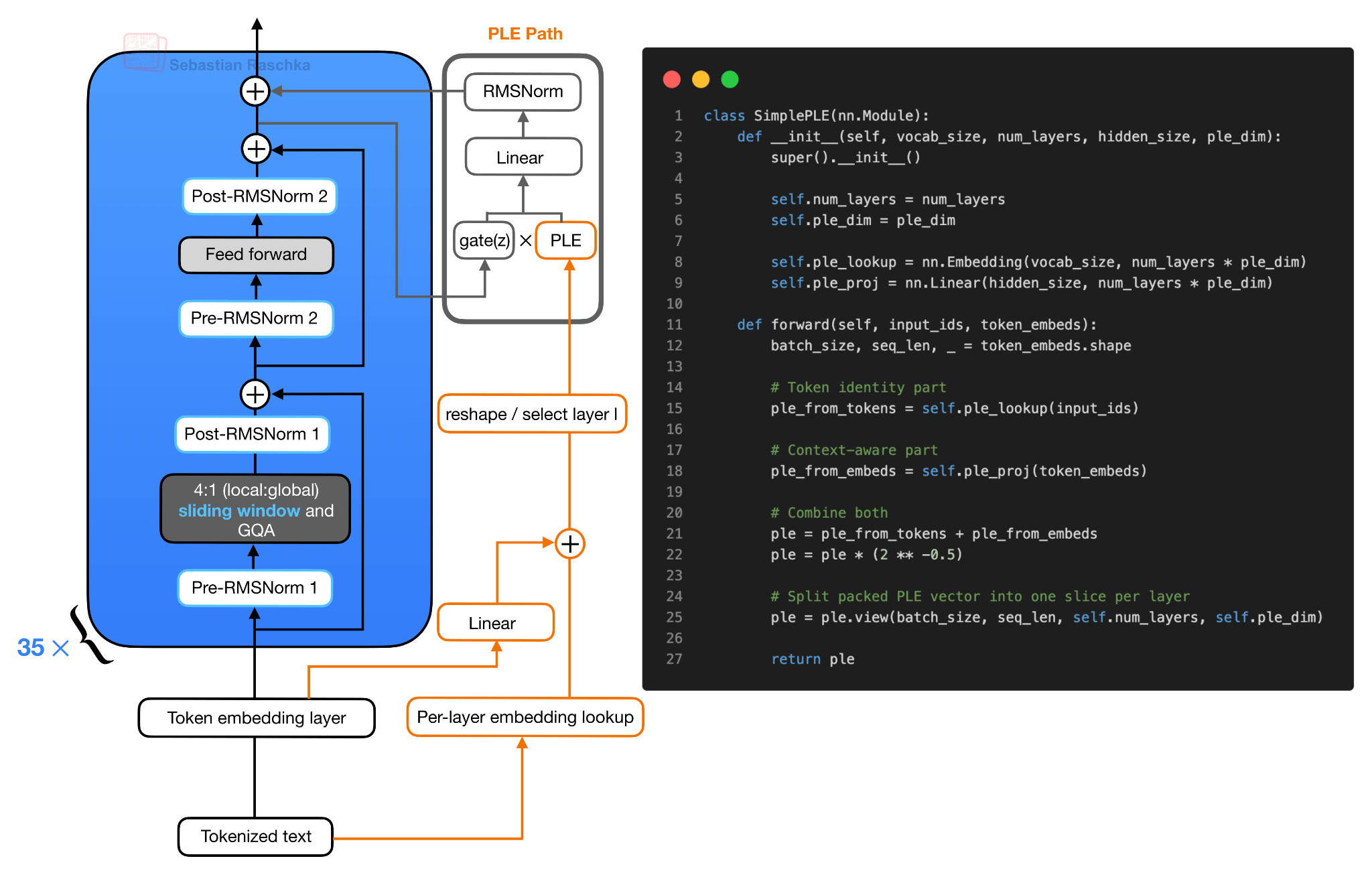
각 트랜스포머 블록은 어텐션 → 피드포워드 잔차 업데이트를 평소처럼 수행한 뒤, 그 결과 은닉 상태 $z$를 사용하여 자신의 PLE 벡터를 게이팅(gating)합니다. 게이팅된 PLE 벡터는 모델 은닉 크기로 다시 투영되고 정규화되어, 또 하나의 잔차 업데이트로 더해집니다. 즉, 어텐션과 FFN이라는 두 잔차 분기 옆에 작은 토큰별 임베딩 분기가 하나 더 붙는다 고 이해할 수 있습니다.
왜 단순히 모델을 더 작게 만들지 않고 PLE라는 복잡한 길을 택했을까요? Raschka의 설명은 분명합니다. 레이어 수나 은닉 차원, FFN 크기를 줄이면 메모리·지연시간은 줄지만 메인 연산을 담당하는 부분의 용량까지 함께 줄어듭니다. PLE는 비싼 트랜스포머 블록은 작은 "effective" 크기에 가깝게 유지하면서, 추가 용량을 룩업 기반의 저렴한 임베딩 테이블 에 저장합니다. 이 임베딩 테이블은 어텐션이나 FFN 가중치를 추가하는 것보다 훨씬 싸게 사용할 수 있고 캐시도 잘 됩니다.
PLE는 이론적으로는 대형 모델에도 적용 가능하지만, 대형 모델은 이미 충분한 용량을 가지고 있고 그 영역에서는 MoE 설계라는 더 확립된 대안이 있어 굳이 PLE를 추가할 동기는 약합니다.
Gemma 4 더 알아보기
LLMs from Scratch 저장소 - Gemma 4 E2B/E4B 구현
Reducing Transformer KV Cache Size with Cross-Layer Attention (Brandon et al., NeurIPS 2024)
Gemma 공식 페이지
Laguna XS.2: 레이어마다 다른 어텐션 예산 분배하기
Poolside는 코딩 응용에 특화된 LLM을 개발하는 유럽 기반 회사로, 첫 오픈웨이트 모델인 Laguna XS.2 를 공개했습니다. 모델 아키텍처 자체는 일견 매우 표준적입니다. 슬라이딩 윈도우 어텐션과 풀 어텐션이 섞여 있는 디코더 트랜스포머라는 구조는 이미 익숙합니다. 그러나 Raschka가 주목한 부분은 따로 있습니다. 바로 Layer-wise attention budgeting, 즉 레이어별 어텐션 예산 분배 입니다.
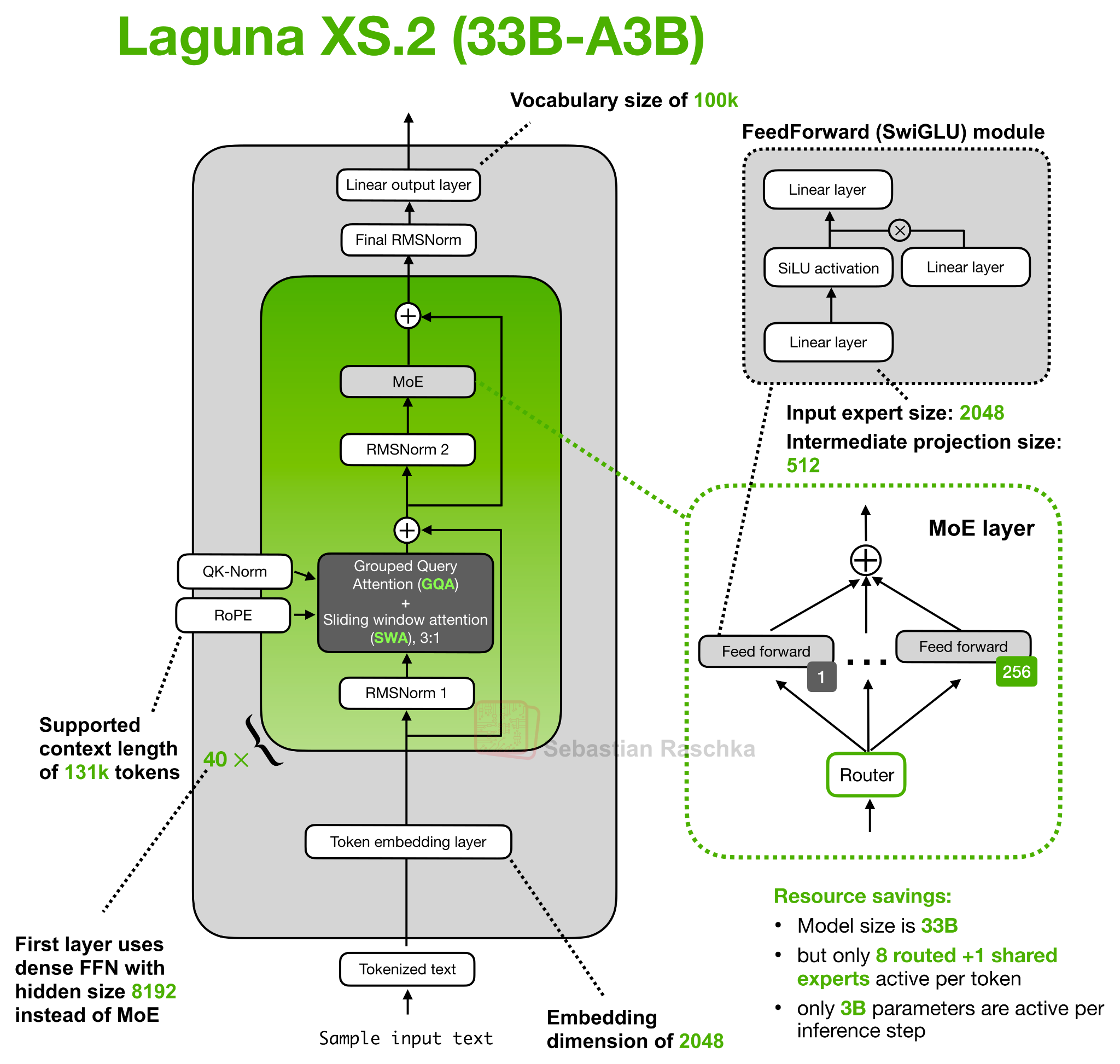
Laguna XS.2는 총 40개 레이어로 구성되며, 그중 30개가 슬라이딩 윈도우 어텐션(윈도우 크기 512 토큰), 나머지 10개가 글로벌/풀 어텐션 레이어입니다. 슬라이딩 윈도우 어텐션은 지역 컨텍스트만 다루기에 KV 캐시와 어텐션 계산이 저렴하고, 글로벌 어텐션은 비싸지만 컨텍스트 전체에 접근할 수 있다는 보완 관계입니다. 이 혼합 패턴 자체는 Gemma 4를 비롯한 여러 최근 아키텍처가 공유합니다.
새로운 점은 Hugging Face Hub의 config.json에 등장하는 num_attention_heads_per_layer 설정입니다. 이 옵션 덕분에 레이어마다 쿼리 헤드 수가 달라질 수 있으며, KV 캐시의 형상은 일정하게 유지됩니다.
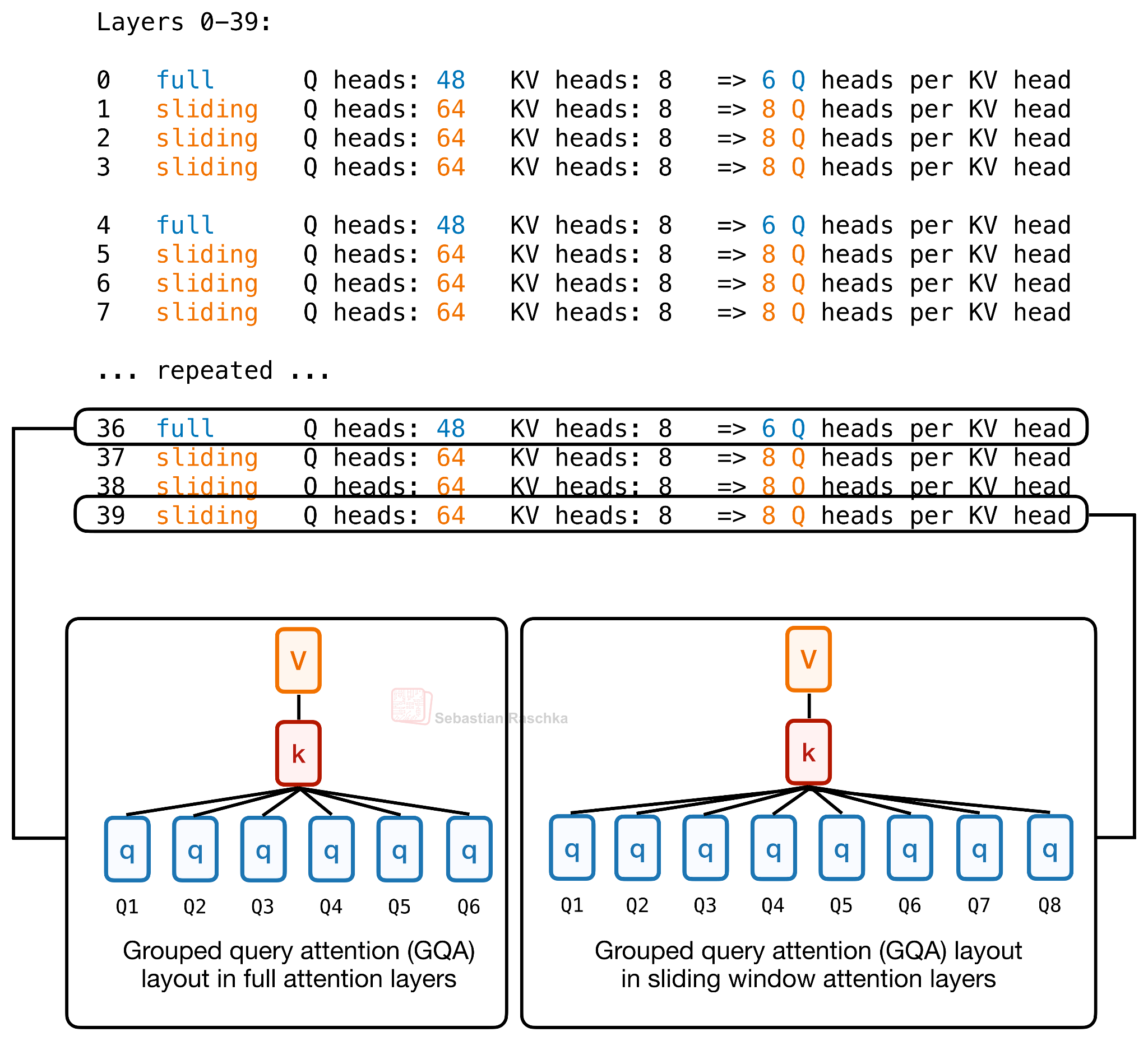
Laguna XS.2는 슬라이딩 윈도우 레이어에는 KV 헤드 1개당 쿼리 헤드 8개를, 풀 어텐션 레이어에는 KV 헤드 1개당 쿼리 헤드 6개를 할당합니다. KV 헤드는 양쪽 모두 8개로 고정됩니다. 즉, 계산 비용이 비싼 풀 어텐션 레이어에는 쿼리 헤드를 더 적게 주고, 상대적으로 저렴한 슬라이딩 윈도우 레이어에는 더 많은 쿼리 헤드를 할당 하여 전체 어텐션 예산을 효율적으로 배분합니다.
이 아이디어의 뿌리는 더 거슬러 올라갑니다. Apple이 2024년에 공개한 OpenELM에서 이미 레이어별로 어텐션과 FFN 크기를 다르게 가져가는 방식이 제시된 바 있습니다. Laguna XS.2는 이를 프로덕션급 오픈 모델에 도입한 가장 가시적인 사례 로 볼 수 있습니다.
Laguna XS.2 더 알아보기
Laguna XS.2 Hugging Face 모델
OpenELM (Apple, 2024)
Poolside 공식 사이트
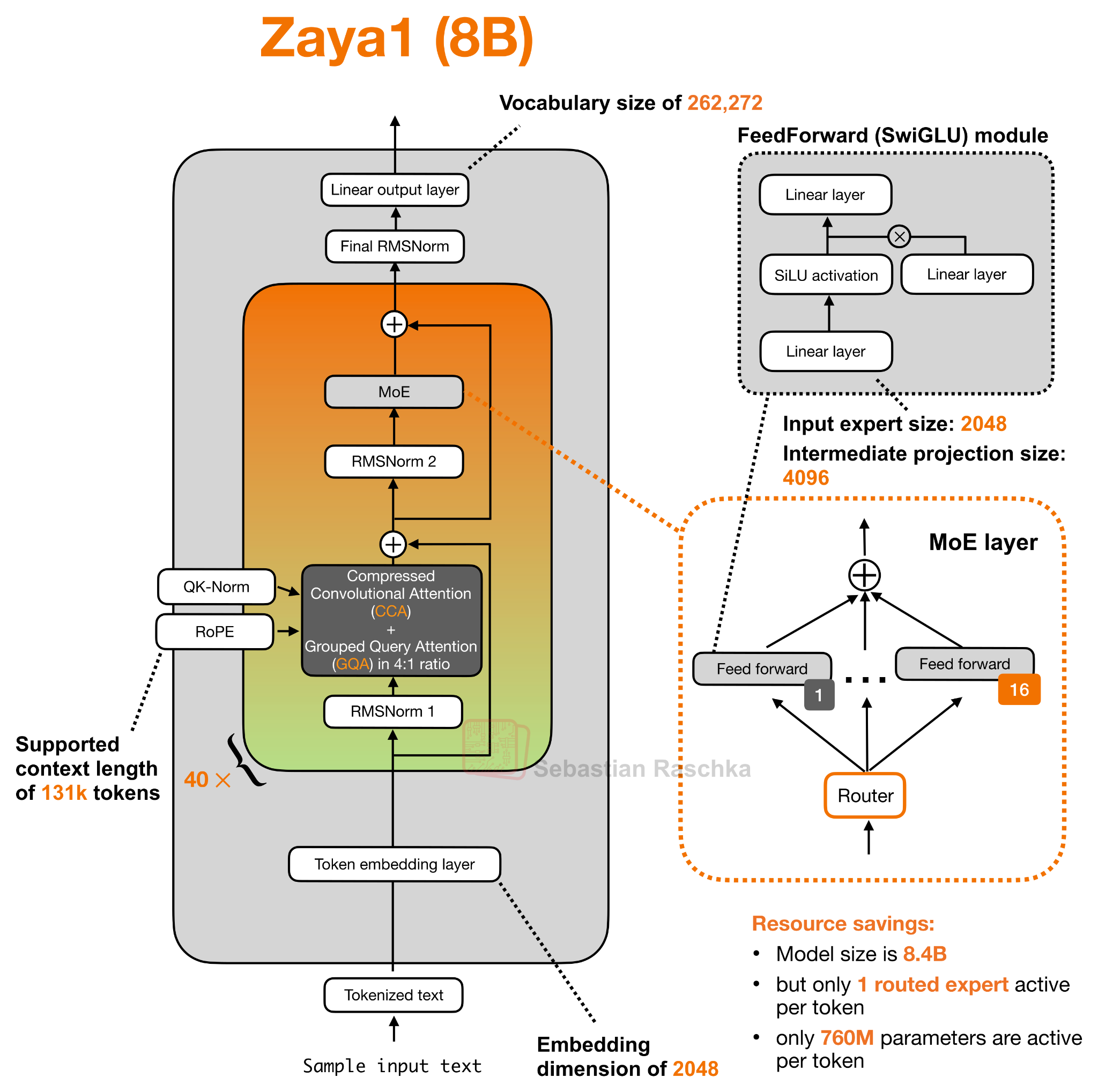
ZAYA1-8B: 압축된 잠재 공간 안에서 직접 어텐션 계산하기
Zyphra는 최근 공개한 ZAYA1-8B를 통해 또 하나의 흥미로운 사례를 보여줍니다. 흥미로운 부수적 사실 하나는, 이 모델이 NVIDIA GPU나 Google TPU가 아닌 AMD GPU 환경에서 학습 되었다는 점입니다. 그러나 본 글의 주제와 직접 연결되는 가장 중요한 변경점은 어텐션 메커니즘 자체에 있습니다.
ZAYA1-8B의 핵심 기법은 Compressed Convolutional Attention(CCA) 입니다. 이는 그룹 쿼리 어텐션(GQA)과 함께 4:1 패턴으로 사용되며, 일반적인 슬라이딩 윈도우 어텐션을 대체합니다.
MLA와 CCA의 결정적 차이
CCA는 그 정신에 있어 DeepSeek 모델들이 사용하는 Multi-head Latent Attention(MLA) 과 닮아 있습니다. 두 기법 모두 어텐션 블록 안에 압축된 잠재 표현(compressed latent representation) 을 도입하기 때문입니다. 그러나 그 잠재 공간을 활용하는 방식이 다릅니다.
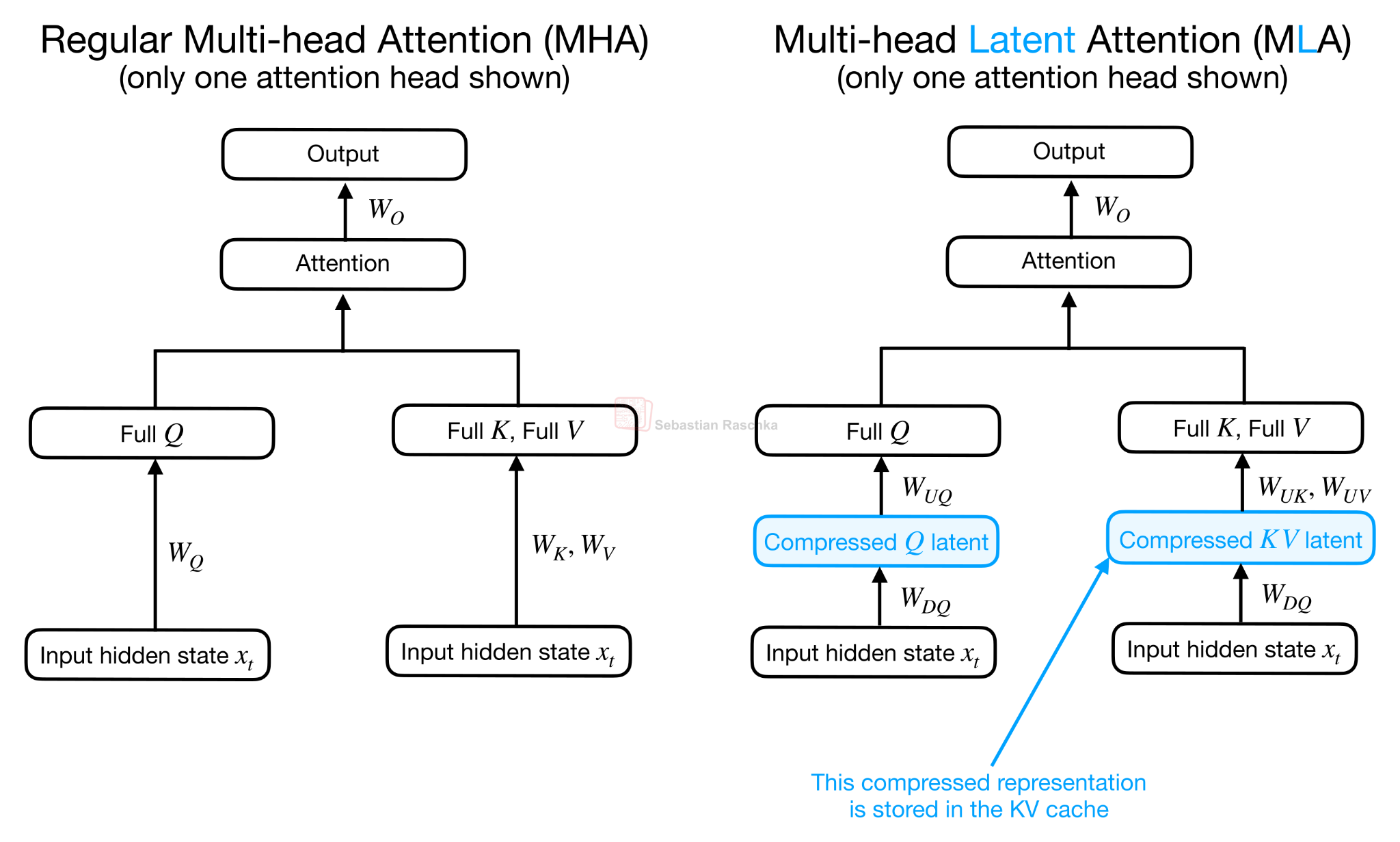
MLA는 잠재 표현을 주로 KV 캐시 절감용 으로 사용합니다. KV 텐서는 컴팩트하게 저장되지만, 실제 어텐션 계산을 위해서는 다시 어텐션 헤드 공간으로 투영(up-projection)됩니다. 반면 CCA는 다릅니다. Q, K, V 모두를 압축한 뒤, 어텐션 연산 자체를 압축된 잠재 공간에서 직접 수행 합니다. 결과적으로 압축된 어텐션 출력 벡터가 나오고, 이를 다시 원래 차원으로 업프로젝션합니다.
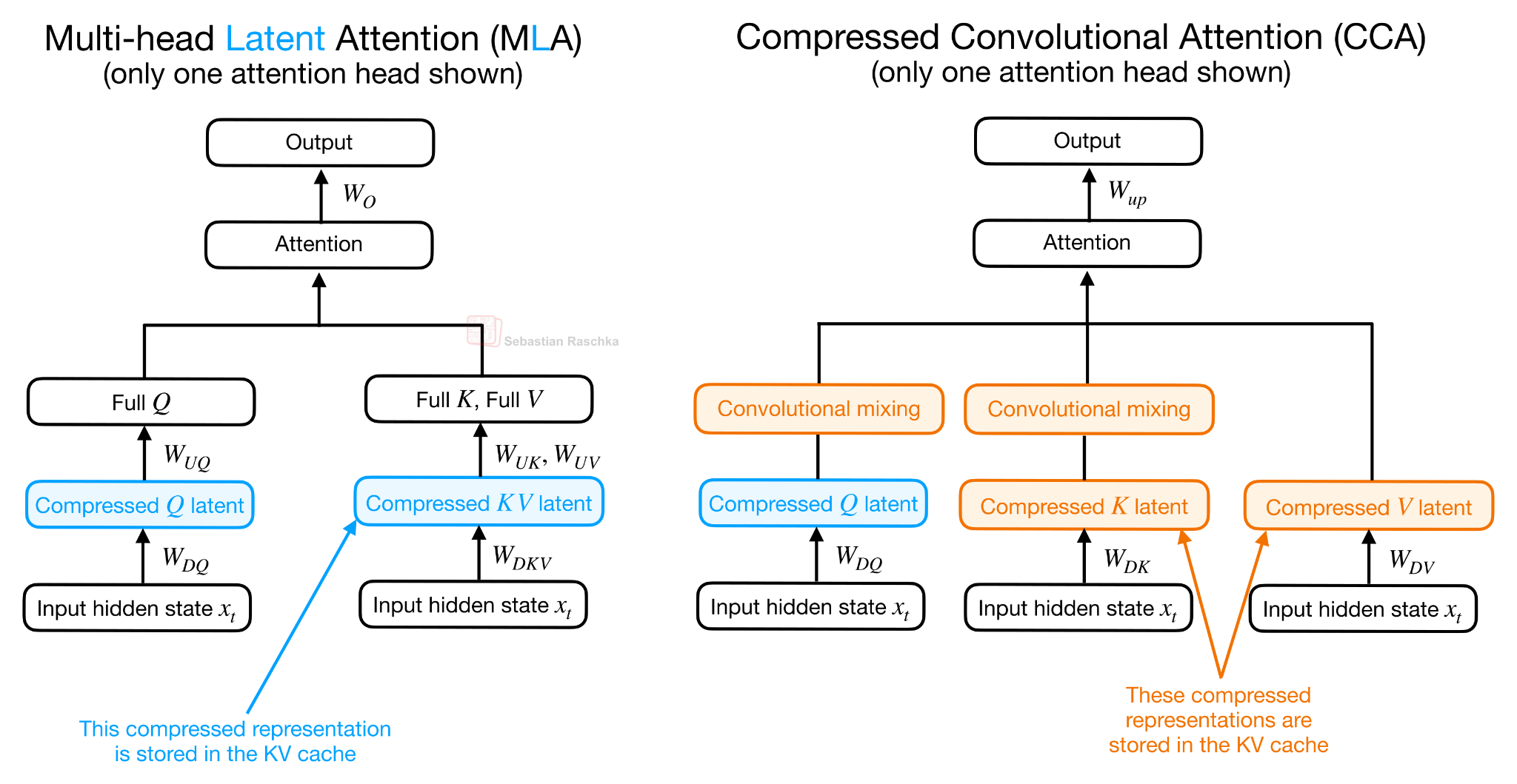
이 차이는 단순한 디테일이 아닙니다. MLA가 주로 KV 캐시 크기를 줄이는 데 집중한다면, CCA는 KV 캐시뿐 아니라 어텐션 FLOPs까지 절감 합니다. 특히 프리필(prefill)과 학습 단계에서 어텐션 계산 자체가 짧은 차원에서 일어나므로 전체 비용이 크게 줄어듭니다.
"Convolutional"의 의미: 압축 후 보강하기
CCA의 이름에 "Convolutional"이 붙는 이유는 압축된 Q, K 표현 위에 합성곱 기반의 시퀀스 믹싱(convolutional mixing) 이 추가로 적용되기 때문입니다. 압축은 Q, K, V를 좁게 만들어 계산과 캐시는 절약하지만, 그만큼 어텐션의 표현력은 줄어들 수 있습니다. 합성곱 믹싱은 압축된 Q와 K 벡터에 지역 컨텍스트(local context) 를 더해주는 저렴한 보강 장치 역할을 합니다.
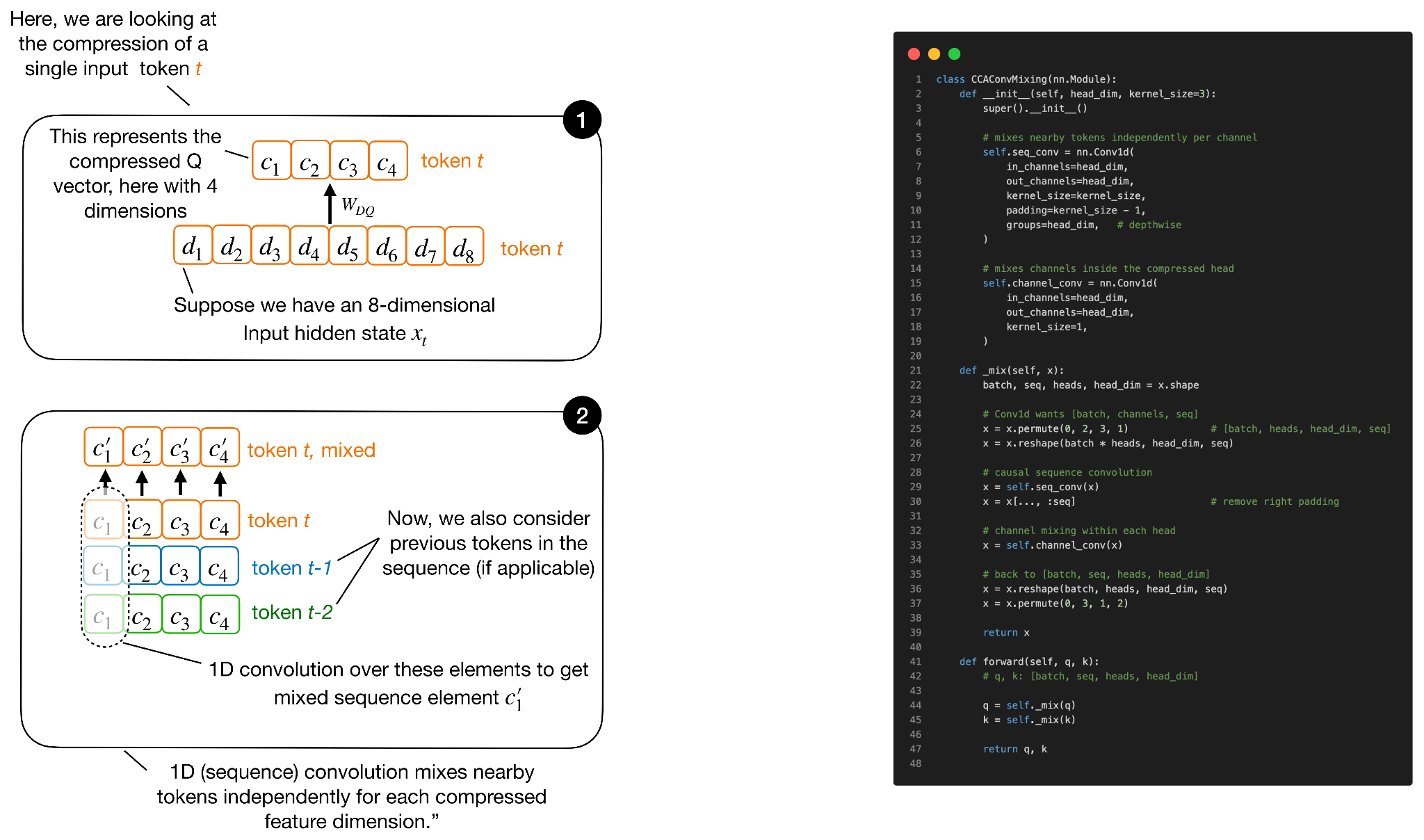
여기서 합성곱은 Q와 K에만 적용되고 V에는 적용되지 않는데, 이는 Q와 K가 어텐션 스코어를 결정하는 반면 V는 그 스코어로 평균되는 콘텐츠를 담기 때문입니다. 시퀀스 믹싱 외에 채널 믹싱(channel mixing) 컴포넌트도 추가되지만, 원리가 유사하므로 별도 도식은 생략합니다.
CCA는 ZAYA1-8B에 앞서 발표된 별도 논문 Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space에서 처음 제안되었습니다. 해당 논문의 자체 실험에 따르면 유사한 압축 비율에서 CCA가 MLA를 능가 한다고 보고됩니다. ZAYA1-8B는 이를 실제 대규모 모델에 적용한 첫 사례 중 하나입니다.
추가로 ZAYA1-8B는 매우 희소한(sparse) MoE 설계를 사용하여 토큰당 라우팅 전문가가 단 1개만 활성화되는 극단적인 구성을 채택하고 있습니다. 즉, 피드포워드 계산뿐 아니라 어텐션 연산 자체까지도 비용을 절감하려는 일관된 방향성을 보입니다.
ZAYA1-8B 더 알아보기
Compressed Convolutional Attention 논문
ZAYA1-8B 공식 블로그
ZAYA1-8B Hugging Face 모델
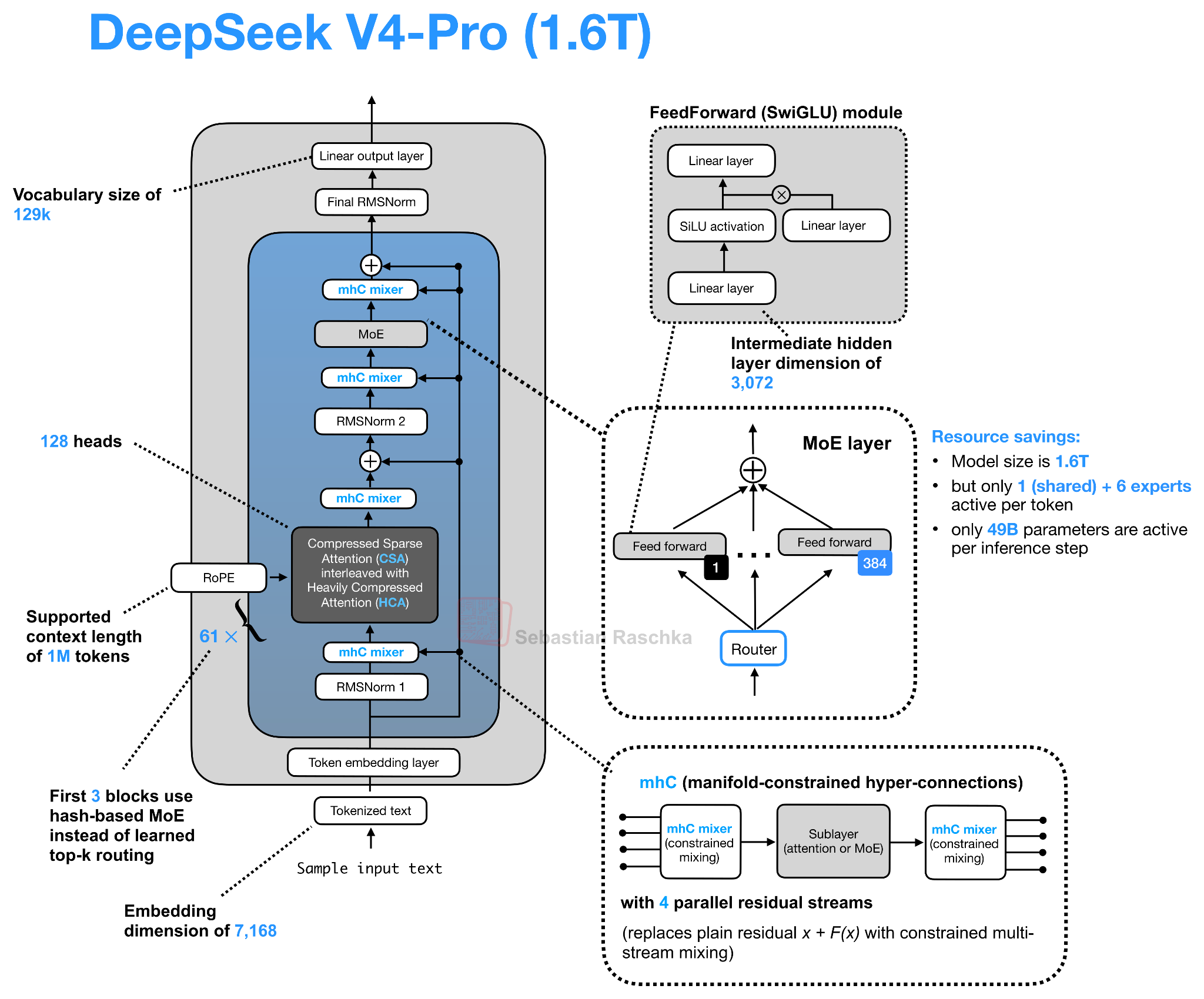
DeepSeek V4: mHC와 CSA/HCA로 1M 토큰까지 밀어붙이기
올해 가장 큰 화제를 모은 오픈웨이트 릴리즈는 단연 DeepSeek V4입니다. 모델 크기뿐 아니라 활성 파라미터 비율이 매우 낮은 극단적인 희소(MoE) 설계도 화제였습니다. 하지만 이번 글에서는 DeepSeek V4가 들고 온 두 가지 아키텍처 변경점만 집중적으로 다룹니다.
첫째는 잔차 경로(residual path)의 변화인 manifold-constrained hyper-connections(mHC) 이며, 둘째는 어텐션 경로의 변화인 Compressed Sparse Attention(CSA) 와 Heavily Compressed Attention(HCA) 의 하이브리드입니다.
Hyper-Connections: 잔차 스트림 넓히기
잔차 연결(residual connections)을 다루는 아키텍처 변경은 흔치 않습니다. 보통의 아키텍처 트윅은 어텐션 메커니즘, 정규화 레이어 위치, MoE 부분에 집중되니까요. 그래서 DeepSeek V4의 mHC는 다소 신선합니다.
mHC를 이해하려면 먼저 그 모태인 Hyper-Connections (Zhu et al., 2024)를 짚고 가야 합니다. 핵심 아이디어는 트랜스포머 블록 내부의 단일 잔차 스트림을 여러 개의 병렬 잔차 스트림으로 확장하고, 학습된 매핑(mapping)으로 그들을 섞는다 는 것입니다.
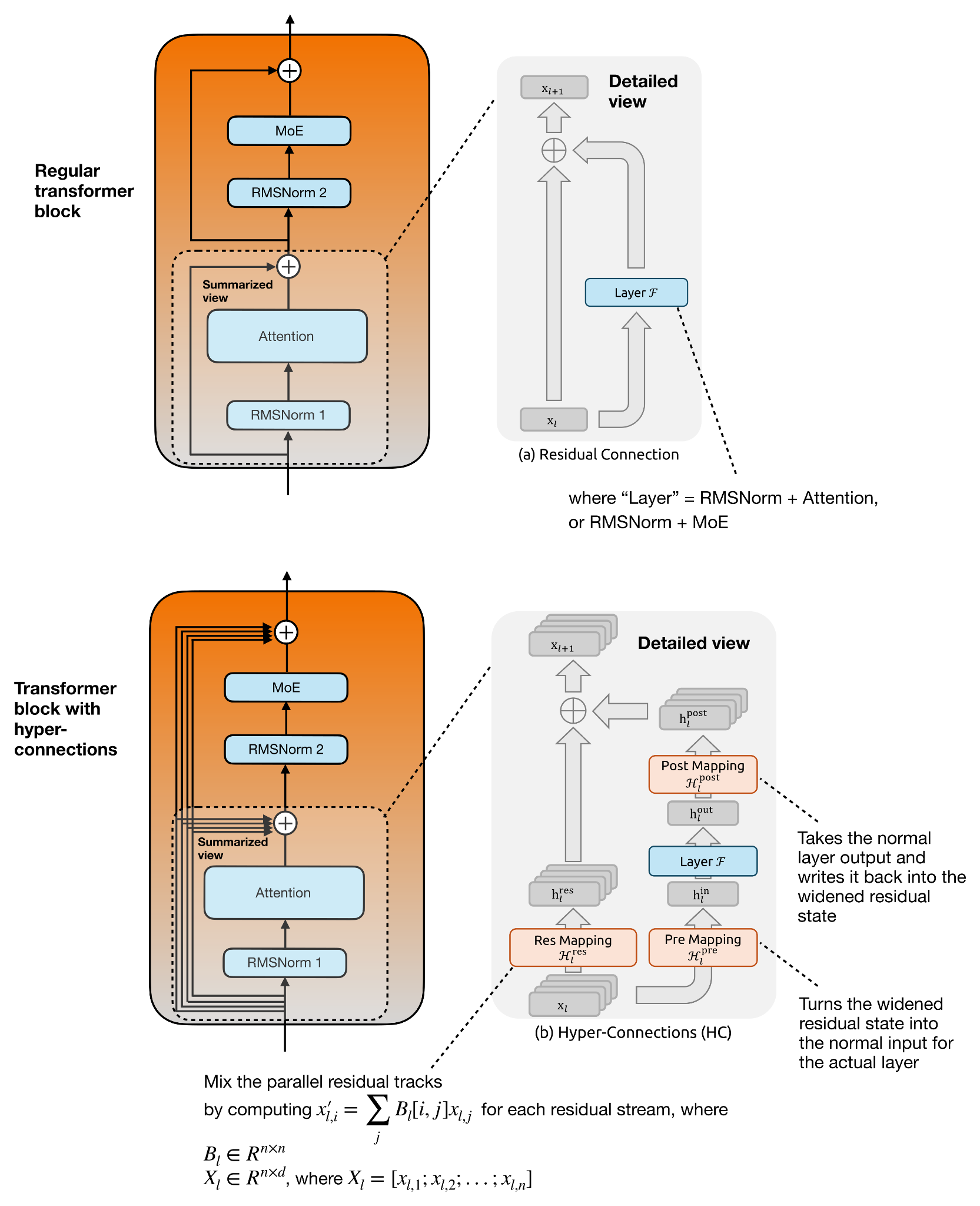
어텐션이나 MoE 레이어는 여전히 일반 은닉 크기에서 동작하므로, Hyper-Connections는 다음 세 가지 매핑을 추가합니다.
Pre Mapping: 병렬 잔차 스트림들을 하나의 일반 은닉 벡터로 합쳐 레이어 입력으로 전달
Post Mapping: 레이어 출력을 다시 병렬 잔차 스트림들에 분배
Res Mapping: 잔차 스트림들 사이를 가로지르며 정보를 섞는 선형 변환
Hyper-Connections의 추가 비용은 매우 작습니다. 잔차 스트림 차원 n(DeepSeek V4의 경우 n=4)은 어텐션이나 FFN의 거대한 은닉 차원에 비해 훨씬 작으므로, FLOPs로 본 오버헤드는 거의 측정 불가능한 수준입니다. 7B OLMo MoE 실험에서 토큰당 FLOPs가 13.36G에서 13.38G로 변화하는 정도였습니다. 반면 이득은 모델 품질의 일관된 개선이며, 베이스라인 성능에 도달하기까지 학습 토큰을 절반 정도만 사용 한 사례도 보고됩니다.
물론 FLOPs만 보는 것은 다소 단순화된 시각입니다. 확장된 잔차 상태를 저장하고 메모리에서 이동시키고 섞는 비용은 별도이며, 이 부분에서는 메모리 트래픽이 더 부담이 될 수 있습니다. DeepSeek V4가 효율성을 최우선으로 두는 모델인 만큼, 그럼에도 충분한 가치가 있다고 판단한 것으로 보입니다.
매니폴드 제약: 그냥 넓히는 것을 넘어 안정시키기
기본 Hyper-Connections에서 mHC로의 진화 포인트는 단 한 가지입니다. 잔차 매핑들이 더 이상 자유롭지 않고, 매니폴드(manifold) 제약을 받습니다.
원본 HC에서 Res Mapping은 자유로운 학습 행렬이라 깊은 모델에서 여러 매핑이 쌓이면 신호가 예측 불가능하게 증폭되거나 사라질 수 있습니다. mHC에서는 이 잔차 매핑을 이중 확률 행렬(doubly stochastic matrices)의 매니폴드 로 투영합니다. 즉, 모든 항목은 음이 아니고, 각 행과 열의 합이 1이 됩니다. 결과적으로 잔차 믹싱은 정보를 안정적으로 재분배(redistribution)하는 역할에 가까워집니다. Pre Mapping과 Post Mapping도 비음수이며 유계(bounded)로 제약되어, 확장된 잔차 상태를 읽고 쓸 때 신호가 상쇄되는 일을 막습니다.

mHC: Manifold-Constrained Hyper-Connections 논문은 27B 파라미터 모델 실험에서 최적화된 구현(퓨전, 재계산, 파이프라인 스케줄링 적용) 기준 n=4 일 때 단일 스트림 베이스라인 대비 약 6.7%의 추가 학습 시간 만으로 모든 트랜스포머 블록에 mHC를 도입할 수 있었다고 보고합니다.
CSA와 HCA: 토큰 단위가 아니라 시퀀스 단위로 압축하기
DeepSeek V4의 두 번째 큰 변화는 어텐션 쪽에 있습니다. 매우 긴 컨텍스트에서는 어텐션 스코어 계산뿐 아니라 시퀀스 길이에 비례해 커지는 KV 캐시 자체가 부담입니다. DeepSeek V4는 이 문제를 두 가지 압축 어텐션의 하이브리드 로 풉니다. 바로 Compressed Sparse Attention(CSA) 와 Heavily Compressed Attention(HCA) 입니다.
여기서 결정적인 차이는 압축의 축 입니다. DeepSeek V2/V3가 사용하던 MLA 스타일 압축은 토큰별 KV 표현 차원을 압축 합니다. 즉, 토큰마다 잠재 KV 엔트리가 여전히 하나씩 존재하지만 그 표현 자체가 작습니다. 반면 CSA와 HCA는 시퀀스 차원을 압축 합니다. 이전 토큰 하나마다 KV 엔트리를 하나씩 보관하지 않고, 여러 토큰을 묶어 더 적은 수의 압축된 KV 엔트리로 요약합니다. 결과적으로 캐시 자체의 길이가 짧아집니다.
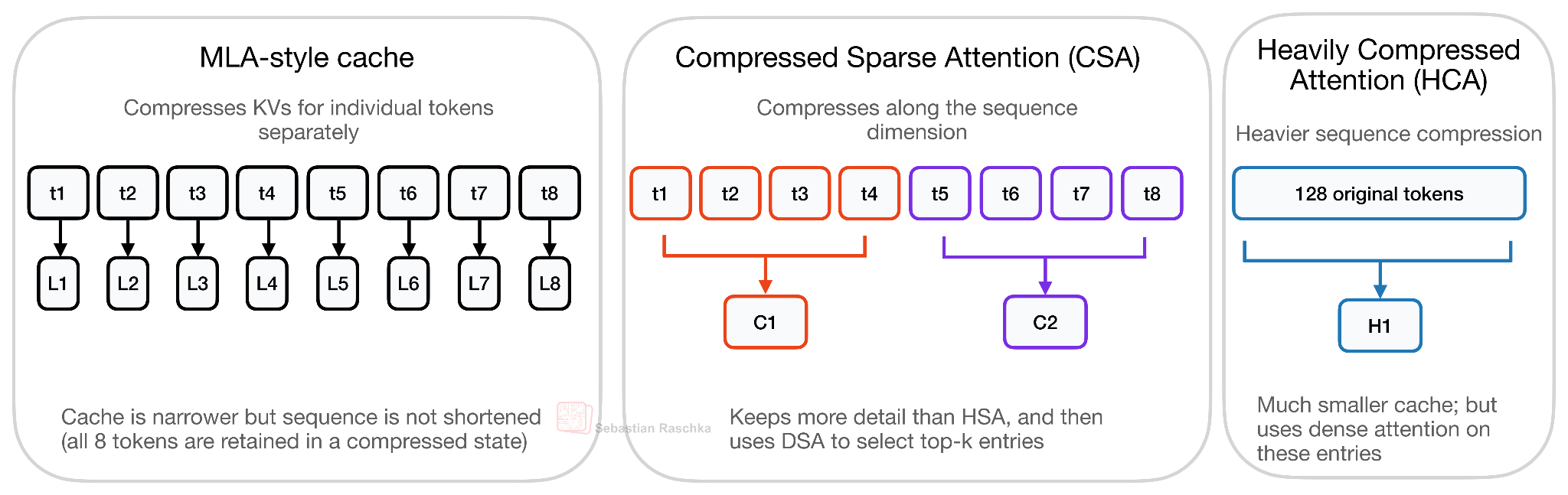
이 트레이드오프는 더 공격적이라, 압축이 지나치게 강하면 모델 품질이 떨어질 위험이 있습니다. 그래서 DeepSeek V4는 하나의 압축 방식에 의존하지 않고 두 방식을 교차(interleave) 합니다.
CSA (Compressed Sparse Attention): 비교적 가벼운 압축 비율 m=4 와 DeepSeek Sparse Attention(DSA) 스타일의 top-k 선택기를 결합합니다. 즉, 압축된 히스토리 블록 중 일부만 희소 선택하여 어텐션을 수행합니다.
HCA (Heavily Compressed Attention): 훨씬 강한 압축 비율 m'=128 을 사용하여 128개 토큰을 단 하나의 압축 KV 엔트리로 묶습니다. 대신 그 짧아진 캐시 위에서 밀집 어텐션(dense attention) 을 수행할 수 있어, 글로벌 커버리지를 저렴하게 확보합니다.
양쪽 모두 최근 토큰에 대한 비압축 정보는 별도의 128 토큰 슬라이딩 윈도우 분기 로 유지합니다. CSA는 디테일을 더 살리되 희소하게, HCA는 디테일을 줄이되 밀집하게 사용한다는 보완 관계입니다.
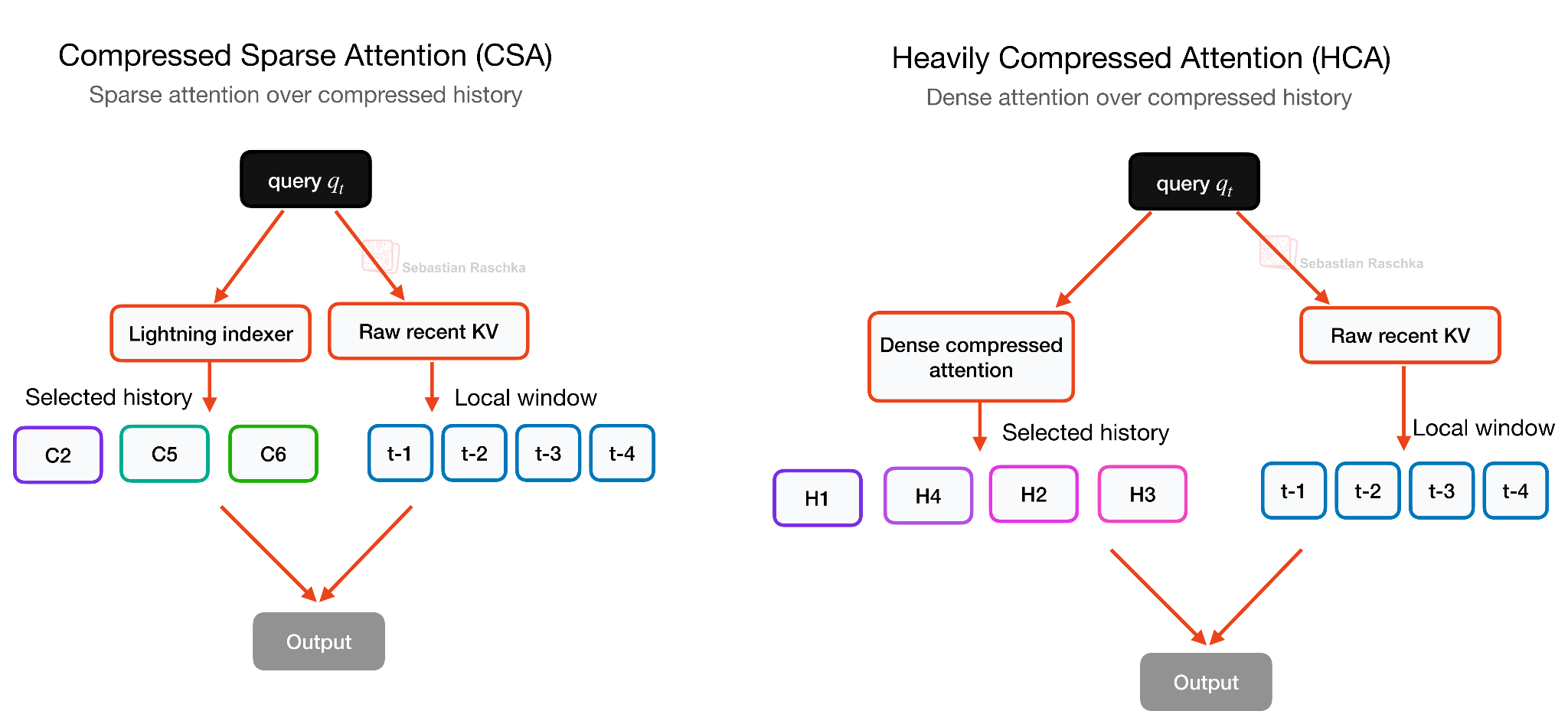
성과 수치는 인상적입니다. DeepSeek V4 페이퍼에 따르면 1M 토큰 컨텍스트에서 DeepSeek V4-Pro는 DeepSeek V3.2(MLA + DSA 사용) 대비 단일 토큰 추론 FLOPs의 27%, KV 캐시 크기의 10%만 사용 합니다. 더 가벼운 DeepSeek V4-Flash는 FLOPs 10%, KV 캐시 7%로 더 극단적인 수치를 보고합니다.

Raschka는 한 가지 단서를 답니다. CSA/HCA가 MLA보다 "일반적으로 더 좋다"고 단정하기에는 이르다 는 것입니다. 논문에는 ablation study가 없고, 보고된 강력한 결과들은 mHC, Muon 기반 최적화, 데이터 품질 개선 등 DeepSeek V4의 전체 레시피가 함께 작동한 결과이기 때문입니다. 현 시점에서 CSA/HCA는 대형 플래그십에서 모델 품질을 비교적 잘 보존하는 효율 중심의 긴 컨텍스트 설계 정도로 평가하는 것이 안전합니다.
DeepSeek V4 / mHC / CSA / HCA 더 알아보기
mHC: Manifold-Constrained Hyper-Connections (DeepSeek, 2025)
Hyper-Connections (Zhu et al., 2024)
A Visual Guide to Attention Variants in Modern LLMs (Sebastian Raschka)
Understanding and Coding the KV Cache in LLMs from Scratch
큰 그림: 트랜스포머는 여전히 진화 중이지만, 그 결은 분명하다
네 개의 모델, 네 개의 기법이지만 큰 줄기에서 보면 한 방향을 가리키고 있습니다. 총 파라미터 수를 줄이는 대신, 긴 컨텍스트 추론 비용을 낮춘다.
Gemma 4: 크로스 레이어 KV 공유로 KV 캐시 메모리를 줄이고, 레이어별 임베딩으로 용량을 추가합니다.
Laguna XS.2: 레이어마다 어텐션 용량을 다르게 배분하여 비싼 풀 어텐션 레이어를 가볍게 만듭니다.
ZAYA1-8B: 어텐션 자체를 압축된 잠재 공간 안으로 옮기고, 합성곱으로 표현력을 보강합니다.
DeepSeek V4: 잔차 스트림 자체를 매니폴드 제약 하에 넓히고, 시퀀스 차원으로 KV 캐시를 압축합니다.
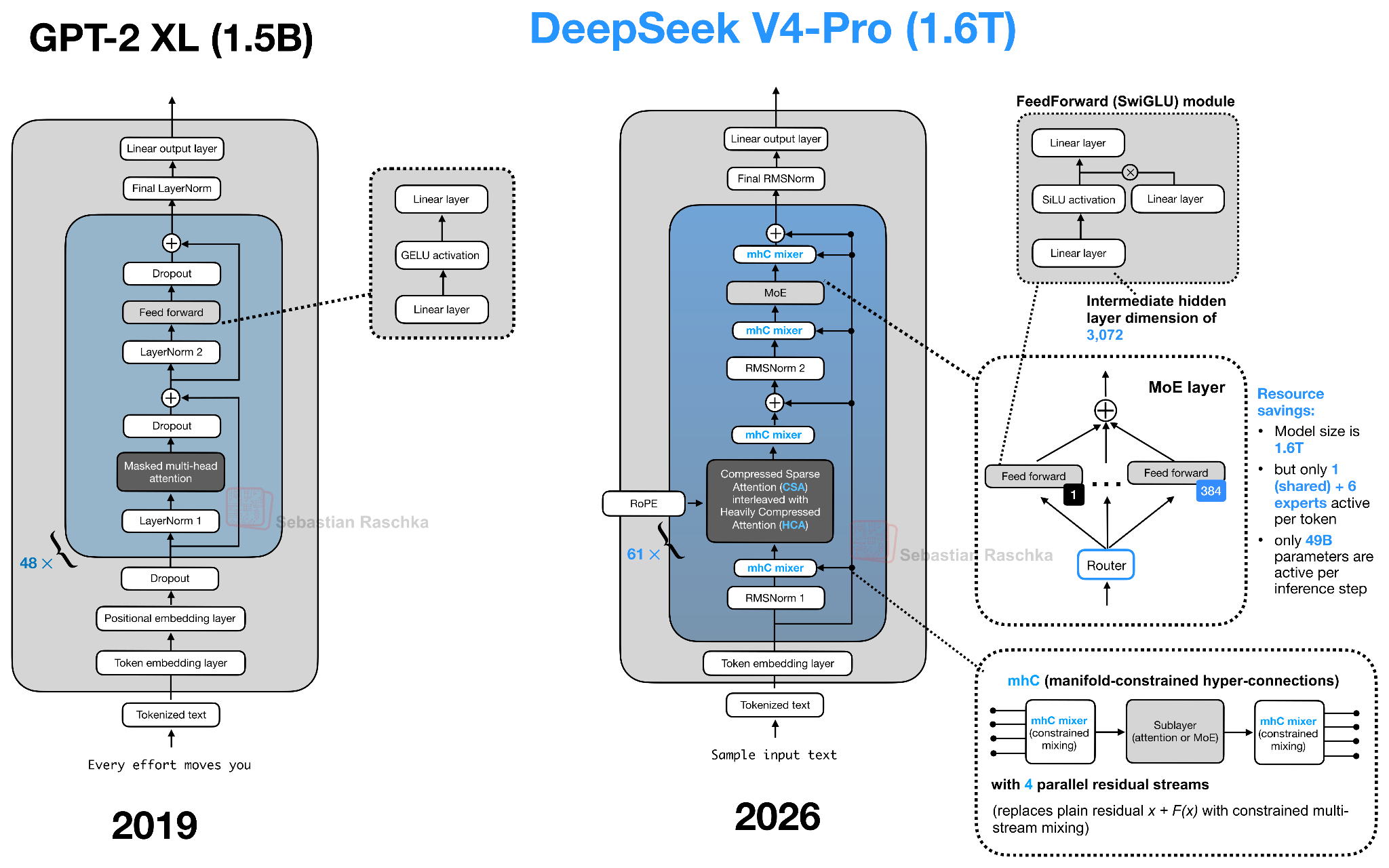
Raschka의 마지막 정리는 이 글의 메시지를 잘 압축합니다. 트랜스포머 블록은 여전히 진화 중이지만, 그 진화는 매우 표적화된(targeted) 방향으로 일어나고 있다. GPT 디코더 전용 트랜스포머라는 기본 레시피는 그대로지만, 거의 모든 구성 요소가 더 긴 컨텍스트와 더 효율적인 추론을 위해 업그레이드되거나 교체되고 있습니다. 모델 품질을 결정하는 큰 변수는 여전히 데이터 품질·수량과 학습 레시피 라는 점은 변하지 않았습니다.
부작용도 분명합니다. 기본 트랜스포머 블록은 PyTorch로 50~100줄 정도면 구현 가능했지만, 위에 소개한 어텐션 변형들을 모두 포함하면 코드 복잡도가 10배 가까이로 늘어납니다. DeepSeek V4의 소스 코드를 처음 보는 학습자에게 그 전체를 한 번에 이해시키는 것은 거의 불가능에 가까운 일이 되었습니다. 그래서 Raschka는 글의 마지막에 익숙한 조언을 다시 남깁니다. "한 번에 하나씩 배우자(one architecture at a time)."
 Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention 원문
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention 원문
 Sebastian Raschka의 LLM Architecture Gallery
Sebastian Raschka의 LLM Architecture Gallery
 LLMs from Scratch GitHub 저장소
LLMs from Scratch GitHub 저장소
더 읽어보기
-
Keras의 창시자 프랑수아 숄레(François Chollet)의 베스트셀러 Deep Learning with Python 3판이 무료 온라인 공개
-
LLM Internals: 토크나이저부터 Flash Attention까지, LLM 내부 구조를 단계별로 학습하는 오픈소스 교육 자료
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()