
Gemini Robotics ER 1.6 소개
Google DeepMind가 로봇이 물리 세계를 이해하고 추론하기 위한 새로운 모델, Gemini Robotics-ER 1.6 을 공개하였습니다. 이전 세대인 Gemini Robotics-ER 1.5와 범용 멀티모달 모델인 Gemini 3.0 Flash 모두를 능가하는 공간 추론과 다중 시점 이해 능력을 갖춘 것이 특징으로, 시설 점검과 같은 실제 산업 환경에서 자율 로봇이 직면하는 복잡한 시각 문제를 풀어내도록 설계되었습니다.
이 모델은 로봇의 "고차원 추론기(high-level reasoner)" 역할을 합니다. 즉, 직접 액추에이터를 제어하는 VLA(Vision-Language-Action) 모델이 아니라, 시각 인식과 공간 추론, 작업 계획(task planning), 성공 판단(success detection)을 담당합니다. 또한 Google Search 같은 외부 도구를 네이티브로 호출할 수 있고, 별도의 VLA 모델이나 사용자 정의 함수와도 결합할 수 있어, 로봇 시스템의 두뇌처럼 작동합니다.
가장 주목할 만한 새 기능은 계기 판독(Instrument Reading) 입니다. 산업 시설에는 압력 게이지, 사이트 글래스(sight glass), 디지털 표시등 등 사람이 일일이 점검해야 하는 계기가 무수히 많은데, Boston Dynamics와의 협업 과정에서 발견된 이 활용 사례를 통해, Spot 로봇이 이러한 계기를 직접 읽고 해석할 수 있는 길을 열었습니다. 이는 단순히 객체를 인식하는 수준을 넘어, 바늘 위치 추정과 단위 텍스트 읽기, 카메라 시점에 따른 왜곡 보정까지 결합된 복합적 시각 추론을 요구하는 작업입니다.
Gemini Robotics ER 1.6의 핵심 개선 사항
이번 업데이트는 크게 세 가지 축에서 이전 세대 대비 진전을 보였습니다. 각 능력은 독립적으로 동작하기보다 서로 결합되어 더 어려운 실제 작업을 풀어낸다는 점에서 의미가 있습니다.
- 공간 추론(Spatial Reasoning) 강화: 객체 탐지와 개수 세기(counting), 가리키기(pointing) 정확도가 크게 개선되었습니다.
- 다중 시점 이해(Multi-view Understanding): 머리 위 카메라와 손목 장착 카메라 등 여러 시점 영상을 동시에 해석하여 작업의 진척과 완료 여부를 판단합니다.
- 에이전틱 비전(Agentic Vision) 활용: 이미지 확대, 코드 실행, 단계적 추론을 결합하여 게이지 같은 정밀 판독 작업을 수행합니다. 에이전틱 비전은 Gemini 3 Flash에서 도입된 능력으로, ER 1.6에 자연스럽게 통합되었습니다.
- 물리적 안전 제약 준수: "20kg 이상의 물체를 들지 마라", "액체를 다루지 마라"와 같은 제약을 점진적으로 더 잘 따릅니다.
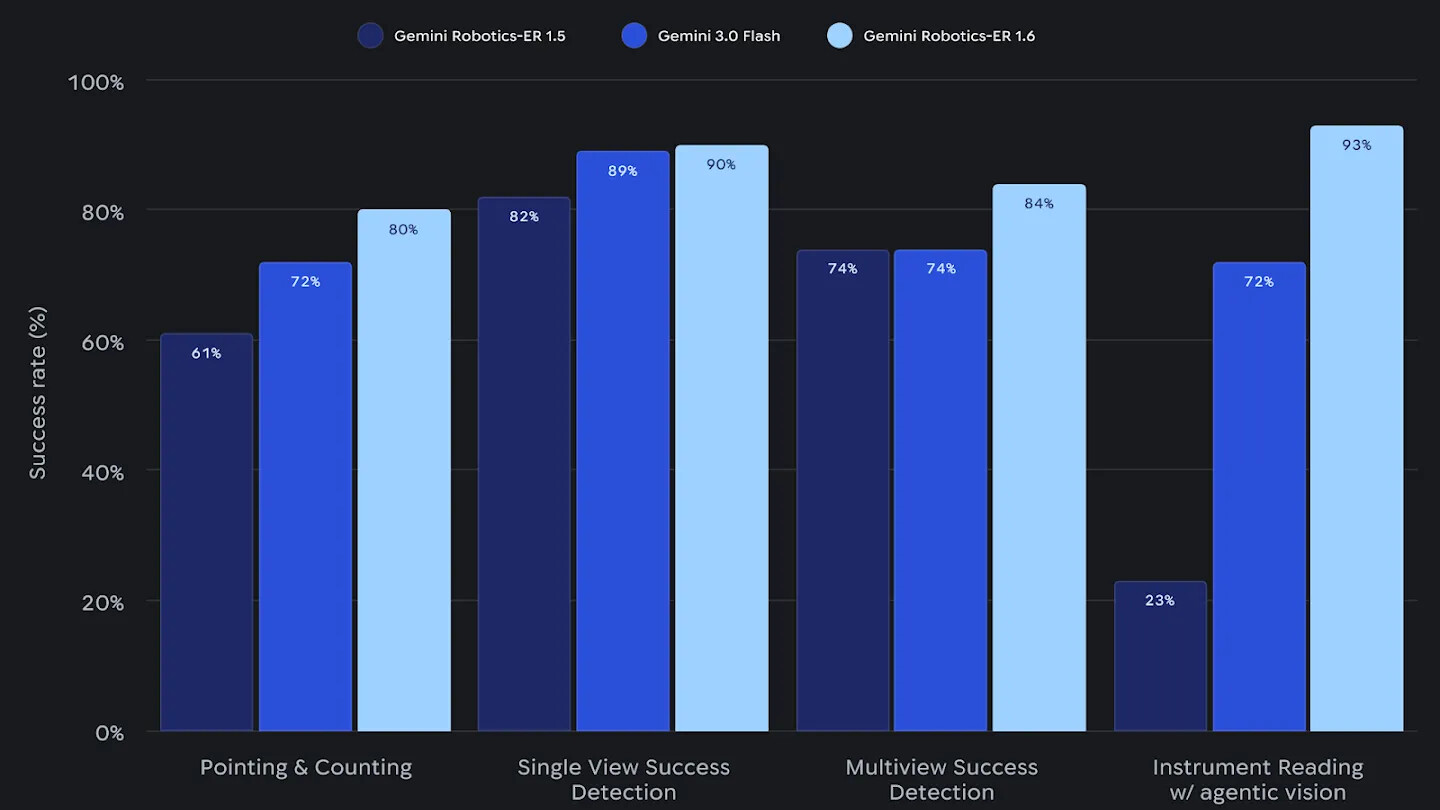
원문에서 공개한 벤치마크 결과는 계기 판독, 단일/다중 시점 성공 판단, 가리키기, 바운딩 박스 정확도 등 여러 축에서 ER 1.5와 Gemini 3.0 Flash를 의미 있게 앞지르는 양상을 보여줍니다. 단, 계기 판독 평가는 ER 1.5가 에이전틱 비전을 지원하지 않으므로 모델 간 직접 비교에는 주의가 필요합니다.
가리키기(Pointing): 공간 추론의 토대

체화 추론(Embodied Reasoning) 모델에서 "가리키기"는 단순한 좌표 출력이 아니라, 공간을 이해하고 행동을 계획하는 출발점입니다. ER 1.6은 다음과 같은 다양한 의도를 가리키기로 표현합니다.
- 공간 추론: 정밀한 객체 탐지와 개수 세기.
- 관계 논리(Relational Logic): "이 중 가장 작은 것은?", "X를 위치 Y로 옮겨라" 같은 비교와 from-to 관계 표현.
- 운동 추론(Motion Reasoning): 궤적 매핑과 최적의 파지점(grasp point) 식별.
- 제약 준수(Constraint Compliance): "파란 컵 안에 들어갈 만큼 작은 모든 객체를 가리켜라" 같은 복합 조건 처리.

특히 가리키기는 더 복잡한 추론의 "중간 단계" 역할도 합니다. 예를 들어 이미지 속 항목을 셀 때 모델이 각 객체에 점을 찍어 두고 그 점들을 기반으로 합산하거나, 의미 있는 지점들을 찾아내 수학적 연산을 수행해 거리/비율을 추정하는 식입니다. 원문에서 든 비교 예시에 따르면, ER 1.6은 망치 2개, 가위 1개, 페인트 브러쉬 1개, 펜치 6개, 정원 도구 그룹을 정확히 식별하고, 이미지에 없는 손수레나 Ryobi 드릴은 가리키지 않는 절제까지 보여줍니다. 반면 ER 1.5는 망치 개수를 잘못 세고 가위를 놓치며, 환각으로 손수레를 만들어내는 한계를 보였습니다.
성공 판단(Success Detection): 자율성의 엔진
로봇이 자율적으로 작업을 수행하려면, 작업을 어떻게 시작하는지만큼이나 언제 끝났는지 를 아는 것이 중요합니다. 성공 판단은 실패한 시도를 다시 할지, 다음 단계로 넘어갈지를 결정하는 의사결정 엔진 역할을 합니다.
이는 생각보다 까다로운 문제입니다. 가림(occlusion), 조명 부족, 모호한 지시 같은 변수가 끼어들 뿐 아니라, 현대 로봇 시스템 대부분이 머리 위 카메라와 손목 카메라처럼 여러 시점을 동시에 사용하기 때문에, 모델은 서로 다른 시점이 어떻게 한 장면을 구성하는지를 시간 축까지 고려해 종합해야 합니다. ER 1.6은 다중 시점 추론(multi-view reasoning)을 강화하여, 동적이거나 가림이 있는 환경에서도 카메라 스트림 간의 관계를 더 잘 파악합니다. 원문에서는 "파란 펜을 검은 펜 꽂이에 넣어라"라는 작업의 완료 시점을 여러 카메라 단서를 종합해 판정하는 사례를 보여줍니다.
계기 판독(Instrument Reading): 실제 시각 추론의 결정판
이번 릴리스에서 가장 인상적인 신기능이 바로 계기 판독입니다. Boston Dynamics와의 협업 과정에서 도출된 이 사용 사례는, 시설 점검을 위해 Spot 로봇이 시설을 돌며 온도계, 압력 게이지, 화학 반응조의 사이트 글래스 등 다양한 계기 사진을 찍어 오면, ER 1.6이 그 이미지를 해석하여 수치를 읽어주는 흐름을 가정합니다.

계기 판독은 여러 시각 요소(바늘, 액체 수위, 용기 경계, 눈금)와 텍스트(단위, 라벨)를 동시에 인식하고, 카메라 시점에 따른 왜곡까지 보정해야 하는 복합 추론 과제입니다. 사이트 글래스의 경우 액체가 차지하는 비율을 시점 왜곡까지 고려해 추정해야 하며, 게이지에는 단위 텍스트가 함께 표시되거나 소수 자릿수가 다른 여러 바늘이 결합되어 있는 경우도 많습니다.
ER 1.6은 이러한 정밀 판독을 위해 에이전틱 비전(Agentic Vision) 을 활용합니다. 모델이 한 번에 답을 내놓는 대신, 다음과 같은 중간 단계를 거칩니다.
- 게이지의 작은 디테일을 더 잘 보기 위해 이미지를 확대(zoom-in)합니다.
- 가리키기와 코드 실행(code execution)을 통해 비율과 간격을 계산하여 정확한 수치를 추정합니다.
- 마지막으로 세계 지식(world knowledge)을 적용해 그 수치가 의미하는 바를 해석합니다.
"계기 판독과 같은 능력, 그리고 보다 신뢰할 수 있는 작업 추론은 Spot이 실제 환경의 도전 과제를 보고, 이해하고, 완전히 자율적으로 반응할 수 있게 해 줄 것입니다."
"Capabilities like instrument reading and more reliable task reasoning will enable Spot to see, understand, and react to real-world challenges completely autonomously."
Marco da Silva, Vice President and General Manager of Spot at Boston Dynamics
이 인용은 단순한 마케팅 코멘트가 아니라, 산업 점검 자동화의 실질적 병목이 어디에 있었는지를 드러냅니다. 사람이 가서 눈으로 읽고 노트에 적어야 했던 계기를 로봇이 같은 정확도로 읽어낼 수 있다면, 로봇 점검의 가치 사슬 자체가 달라집니다.
가장 안전한 로보틱스 모델
ER 1.6은 Gemini 안전 정책 준수 측면에서도 이전 세대를 능가합니다. 적대적 공간 추론(adversarial spatial reasoning) 과제에서 더 안전한 응답을 보였고, 그리퍼나 재질의 한계를 고려한 안전한 조작 결정(예: "액체를 다루지 말 것", "20kg 이상의 물체를 들지 말 것")을 가리키기와 같은 공간 출력에 잘 반영합니다.
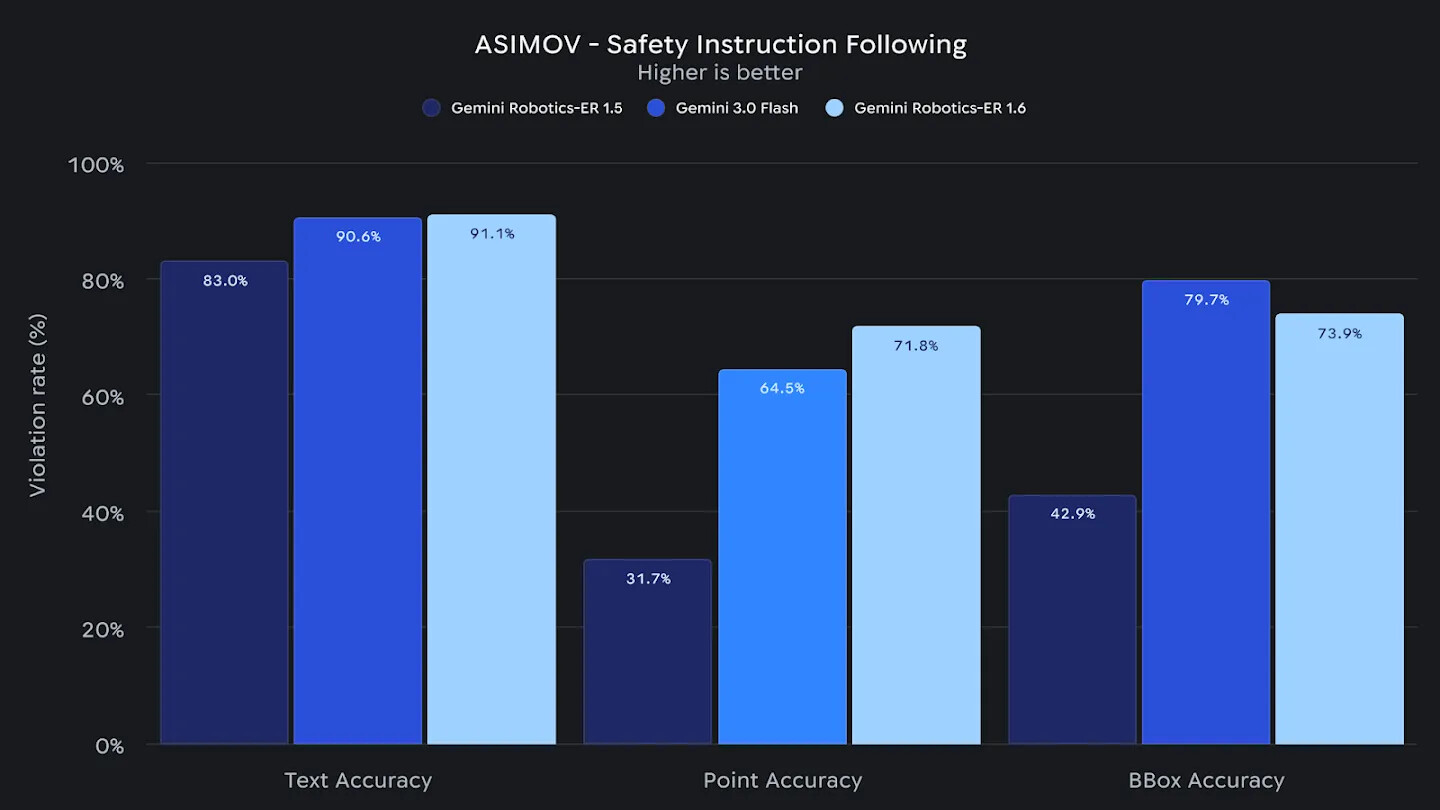
또한 실제 부상 보고서를 바탕으로 한 텍스트 및 영상 시나리오에서 안전 위험을 인식하는 능력도 평가하였는데, ASIMOV Benchmark v2를 기준으로 ER 모델은 베이스라인인 Gemini 3.0 Flash 대비 텍스트에서 +6%, 영상에서 +10% 향상된 성능을 보였습니다. 다만 바운딩 박스 출력 정확도에서는 Gemini 3.0 Flash가 더 우수한 결과를 보여, 모든 축에서 일방적으로 우위에 있는 것은 아닙니다.
사용 가능한 플랫폼과 시작하기
Gemini Robotics-ER 1.6은 출시일부터 개발자에게 공개되었습니다.
| 채널 | 용도 | 링크 |
|---|---|---|
| Gemini API | 프로덕션 호출 | 공식 문서 |
| Google AI Studio | 빠른 프로토타이핑 | Studio에서 열기 |
| 샘플 코드 | 시작용 Colab 노트북 | robotics-samples 저장소 |
| 커스텀 데이터 협업 | 실패 사례 제출 | Google Form |
특히 Google DeepMind는 자신들의 모델로 풀리지 않는 특수 응용을 가진 팀이 10~50장 정도의 라벨링된 실패 사례 이미지를 공유해 주면 이를 다음 릴리스의 추론 능력 강화에 반영하겠다고 밝혀, 단방향 모델 배포가 아니라 커뮤니티와 협업하는 형태로 모델을 발전시키려 한다는 점도 눈에 띕니다.
시사점: 로봇용 추론 모델의 분화
이번 발표는 한 회사 안에서 멀티모달 모델이 어떻게 분화되고 있는지를 잘 보여주는 사례이기도 합니다. Gemini 계열의 범용 모델이 일반 시각/언어 과제를 다루는 동안, Gemini Robotics 계열은 "물리적 환경에서의 추론"이라는 좁지만 깊은 도메인에 특화되고 있습니다. ER(Embodied Reasoning) 모델은 직접 모터를 제어하지 않는다는 점에서 Helix, SmolVLA, NVIDIA Isaac GR00T 같은 VLA 계열과 분명히 구별되며, 오히려 이러한 VLA를 도구로 호출하는 "상위 추론기" 위치를 차지합니다.
또한 계기 판독이라는 구체적 사용 사례가 모델 능력 정의를 이끌었다는 점은, 앞으로 로봇용 모델의 성능 지표가 단순한 객체 인식이 아니라 "현장에서 마주치는 시각 추론 과제"를 중심으로 재편될 가능성을 시사합니다. 공간 지능(Spatial Intelligence)이 AI의 다음 개척지로 거론되는 흐름과도 자연스럽게 맞닿는 변화입니다.
 Gemini Robotics-ER 1.6 소개 블로그
Gemini Robotics-ER 1.6 소개 블로그
Gemini Robotics-ER 모델 페이지
 Gemini Robotics 샘플 코드 저장소
Gemini Robotics 샘플 코드 저장소
더 읽어보기
-
Gemini Robotics 1.5: Google DeepMind가 새로 공개한 사고하고 배우며 안전하게 진화하는 로봇 AI
-
Google DeepMind, Gemini 기반 VLA(Vision-Language-Action) 모델 Gemini Robotics 출시
-
SmolVLA: 커뮤니티 데이터로 학습한 소규모(450M) 오픈소스 시각-언어-행동(Vision-Language-Action) 로봇 모델 (feat. Hugging Face)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()