이 글은 두 편의 Physical AI 서베이를 묶어 정리하는 시리즈의 1편입니다.
- 1편: LLM의 월드 지식에서 출발해 VLA, 월드 모델, 체화 에이전트로 이어지는 로드맵
- 2편: 물리를 이해하는 생성 모델과 월드 시뮬레이터
Physical AI란 무엇인가: 디지털 추론을 넘어 물리 세계로
스마트폰 속 챗봇에게 "유리컵은 떨어뜨리면 깨지나요?"라고 물으면 즉시 "네"라는 답이 돌아옵니다. 하지만 그 챗봇을 로봇 팔에 연결해 실제로 식탁 위 유리컵을 치우게 하면 상황은 전혀 달라집니다. 컵이 지금 어디에 있는지, 손잡이를 어느 각도로 잡아야 미끄러지지 않는지, 얼마나 힘을 줘야 들리면서도 깨지지 않는지는 "유리는 깨진다" 라는 언어 지식만으로는 알 수 없기 때문입니다.
오늘 정리할 서베이 A Survey of Physical AI: A History from ChatGPT to World Models and Embodied Agents 는 바로 이 간극을 다룹니다. Physical AI(물리 AI) 는 인공지능을 디지털 공간의 추론에서 끌어내어, 물리 세계에서의 지각(perception), 예측(prediction), 시뮬레이션(simulation), 계획(planning), 행동(action)으로 확장하려는 분야입니다. 이 서베이는 Northeastern University의 Haichao Zhang 등 여러 기관 연구진이 2026년 6월 공개한 정리 논문으로(아직 동료 평가 전 프리프린트입니다), 최근 빠르게 쏟아진 시각-언어 모델(VLM), 시각-언어-행동 모델(VLA), 월드 모델(World Model), 정책 학습(Policy Learning), 체화 에이전트(Embodied Agent) 연구를 하나의 로드맵으로 꿰는 것을 목표로 합니다.
기존의 Physical AI 정리들은 대개 로봇공학 중심(robotics-centric), 비전 중심(vision-centric), 또는 사이버 물리 시스템 관점에서 분야를 바라봤습니다. 이 서베이의 차별점은 분야를 LLM 기반 월드 지식(LLM-based World Knowledge) 이라는 렌즈로 다시 읽는다는 데 있습니다. 저자들은 "우리가 아는 한, 이것은 월드 지식을 중심에 둔 최초의 Physical AI 로드맵 서베이" 라고 주장합니다. 즉, 거대 언어 모델(LLM)이 대규모 사전학습을 통해 습득한 지식을 출발점으로 삼아, 그 지식이 어떻게 지각, 행동, 예측, 배포로 한 단계씩 더 물리 세계에 "발을 딛는지(grounding)"를 추적하는 구성입니다.
저자들은 네 가지 기여를 내세웁니다. (1) LLM 기반 월드 지식과 월드 모델 기반 예측 지식의 관점에서 Physical AI를 정식화한 점, (2) 언어로 매개된 사전 지식이 지각적, 행동 가능, 예측적, 배포 가능한 지능으로 바뀌는 인터페이스를 중심으로 최근 연구를 재조직한 점, (3) 월드 지식에서 체화된 행위(embodied agency)로 이어지는 계층적 로드맵을 제시한 점, (4) 조밀한 물리 표현, 언어-행동 그라운딩, 장기 월드 모델링, 시뮬레이션-현실 전이, 닫힌 루프 평가, 안전, 재현성 같은 배포 중심의 미해결 과제를 정리한 점입니다.
핵심 주장: LLM의 월드 지식은 유용하지만 "성기고 손실이 많다"
서베이의 출발점은 LLM이 단순한 텍스트 생성기가 아니라 범용 추론 엔진 이 되었다는 관찰입니다. GPT-4, Gemini, Claude 같은 모델은 대규모 사전학습 과정에서 세계에 대한 방대한 규칙성을 파라미터 안에 담습니다. 저자들은 이 월드 지식 을 단일한 저장소가 아니라 여섯 가지가 맞물린 사전 지식(prior)으로 봅니다.
- 의미적(semantic) 지식: 사물과 개념이 무엇인지
- 상식적(commonsense) 지식: 일상적으로 무엇이 보통 일어나는지
- 절차적(procedural) 지식: 어떤 일을 어떤 순서로 하는지
- 인과적(causal) 지식: 무엇이 무엇을 일으키는지
- 공간적(spatial) 지식: 사물들이 어떻게 배치되는지
- 어포던스(affordance) 지식: 손잡이는 당길 수 있고 컵은 쥘 수 있다는, 행동 가능성에 대한 지식
이 가운데 앞의 네 가지(의미적, 상식적, 절차적, 인과적)는 주로 LLM 파라미터 안에 규칙성으로 저장되며, 그 강도는 사전학습에서 얼마나 자주 노출되었는지에 비례합니다. 그래서 흔한 지식은 강하지만 희귀한 긴 꼬리(long-tail) 지식은 취약합니다. 반면 공간적, 어포던스 지식은 언어만으로는 부족해 흔히 외부 인식 모델이 보완합니다.
이런 지식 덕분에 LLM은 로봇의 고수준 계획자나 제어기로 직접 쓰이기 시작했습니다. 서베이는 그 쓰임을 네 가지로 정리합니다. 첫째는 과제 계획(task planning)으로, SayCan 은 LLM이 생성한 행동 후보들을 학습된 어포던스 값으로 걸러 물리적으로 불가능한 행동을 제거했고, Inner Monologue 는 환경 관찰을 다시 언어로 되먹여 닫힌 루프로 재계획하게 했습니다. 둘째는 스킬 및 코드 생성으로, Code as Policies 와 ProgPrompt 는 LLM에게 실행 가능한 로봇 프로그램(코드)을 짜게 했고, Voyager 는 스스로 열린 형태의 스킬 라이브러리를 쌓아 올리게 했습니다. 셋째는 목표 및 보상 지정으로, VoxPoser 는 언어 지시로부터 3차원 공간의 가치 맵(value map)을 합성해 사람이 일일이 보상 함수를 설계하는 부담을 줄였습니다. 넷째는 에이전트형 오케스트레이션으로, LLM이 도구와 하위 모듈을 다단계 과제에 걸쳐 조율하는 닫힌 루프 의사결정 엔진 역할을 합니다. 저자들의 표현으로 이런 쓰임은 LLM을 "Physical AI 파이프라인의 의미적, 절차적 골격" 으로 자리매김합니다.
그러나 여기서 서베이의 가장 핵심적인 주장이 등장합니다. 저자들의 표현을 그대로 옮기면, "언어로 매개된 지식은 기하(geometry), 운동(motion), 접촉(contact), 힘(force), 고주파 동역학(high-frequency dynamics), 장기 시간 변화(long-horizon temporal evolution)처럼 조밀한(dense) 물리 상태에 대해서는 성기고 손실이 많다(sparse and lossy)" 는 것입니다. 저자들은 이 근본 한계를 언어와 물리 사이의 추상화 간극(abstraction gap) 이라 부릅니다. 언어는 연속적인 물리 상태를 듬성듬성한 서술로 압축하면서 자세, 속도, 접촉, 변형, 불확실성, 신체 제약 같은 정보를 자주 누락하기 때문에, LLM의 사전 지식은 여전히 "언어적인(linguistic)" 상태에 머뭅니다.
이 한계는 곧바로 실패로 이어집니다. LLM은 존재하지 않는 물체를 있다고 환각하거나, 물리적으로 불가능한 계획을 제안하거나, 모든 행동이 성공한다고 가정해 버립니다. 앞서 든 유리컵 예시처럼, "유리는 깨지기 쉽고 손잡이는 당길 수 있다" 는 것을 아는 것과, "그 물체가 지금 거기에 실제로 있는지, 현재 배치에서 그 행동이 실현 가능한지" 를 판단하는 것은 전혀 다른 문제입니다. LLM-Modulo 나 PlanBench 계열 연구가 보여주듯, LLM은 여전히 신뢰할 만한 장기 계획에 어려움을 겪습니다. 결국 LLM의 월드 지식은 "무엇이 의미 있는 행동인지" 를 알려주는 출발점일 뿐, 그 자체로는 충분하지 않습니다.
Physical AI 로드맵: 여섯 단계의 점진적 그라운딩
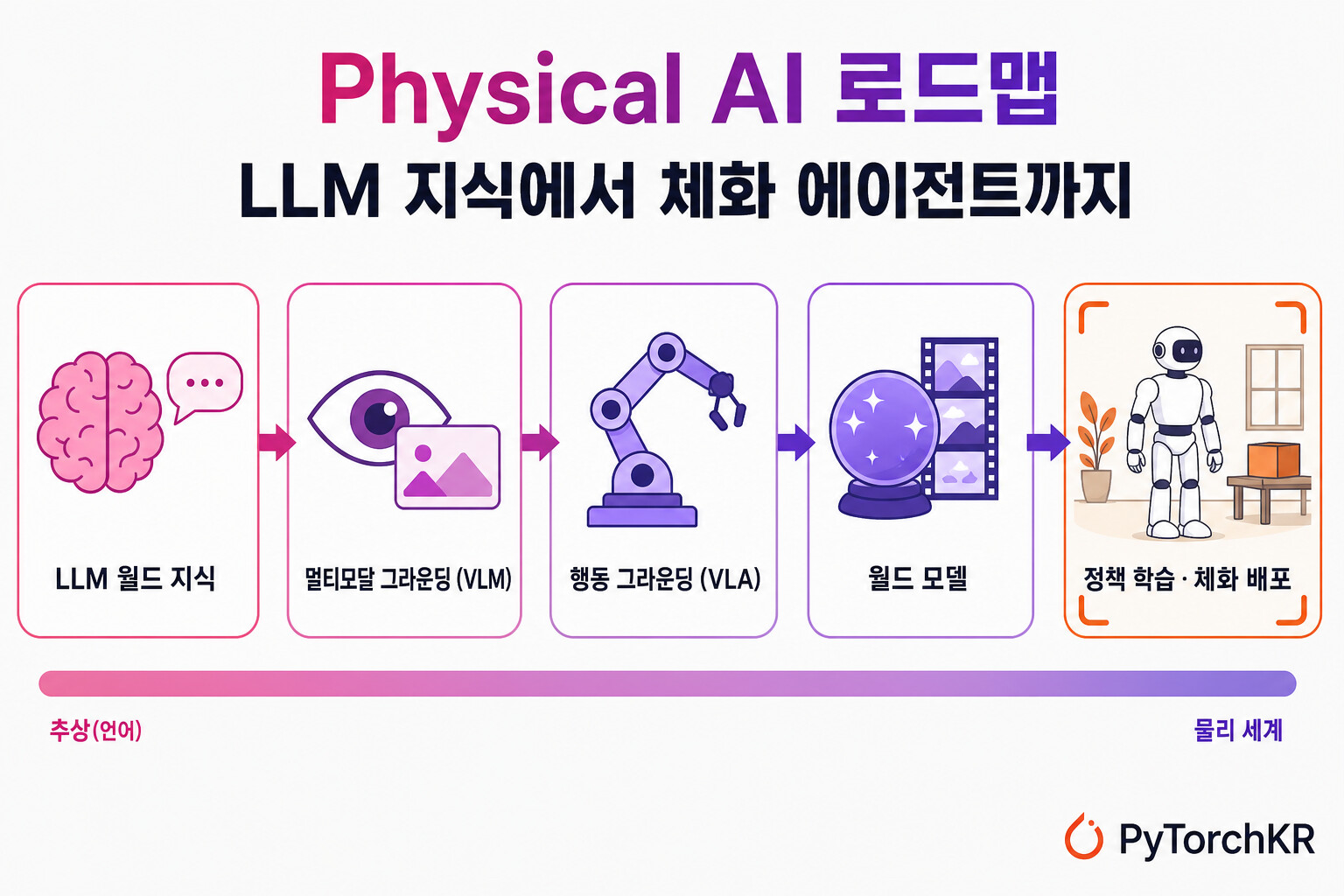
그렇다면 LLM의 추상적 지식을 어떻게 물리 세계에 발을 딛게 할 수 있을까요? 서베이는 이를 평면적인 분류가 아니라 하나의 로드맵으로 제시합니다. 저자들의 비교가 명료합니다. "평면적 분류라면 LLM, VLM, VLA, 월드 모델, 에이전트를 독립적인 가족으로 나열할 것이다. 우리의 관점은 대신 이들을 점진적으로 더 물리적으로 그라운딩되는 인터페이스로 본다. 언어 사전 지식이 지각으로, 지각과 언어가 행동으로 그라운딩되고, 행동은 결국 예측 모델과 닫힌 루프 배포로 뒷받침되어야 한다." 즉 Physical AI는 "어느 한 층이 아니라 이 층들의 조합에서 비로소 출현" 합니다.
아래는 원문의 핵심 그림으로, 이 로드맵을 한눈에 보여 줍니다. 왼쪽의 추상적 언어 지식에서 출발해 오른쪽의 물리 세계로 갈수록 그라운딩이 깊어지며, 각 단계 아래에는 대표 연구(앵커)가 표시되어 있습니다.

아래에서는 이 다섯 칸을 여섯 단계로 풀어, 각 단계가 무엇을 더하는지 살펴봅니다(그림에서는 정책 학습과 체화 배포가 한 칸으로 묶여 있습니다).
1단계: LLM 기반 월드 지식
가장 아래층은 앞서 설명한 LLM의 언어 매개 사전 지식입니다. 이는 의미적, 절차적, 인과적 우선순위를 제공하는 풍부한 원천이지만, 조밀한 물리 상태를 직접 추정하지는 못합니다. 로드맵의 출발점이자 "결정적으로 중요하지만 그것만으로는 불충분한" 토대입니다.
2단계: 멀티모달 그라운딩 (VLM과 MLLM)
지식을 물리 세계로 데려오는 첫 번째 다리는 시각-언어 모델입니다. 이 흐름은 CLIP 같은 대조 학습(contrastive learning) 기반의 이미지-텍스트 정렬에서 시작해, Flamingo, BLIP-2, LLaVA 처럼 시각 인코더를 거대 언어 백본에 연결한 멀티모달 거대 언어 모델(MLLM)로 발전했습니다. 한발 더 나아가 SpatialVLM 과 RoboPoint 는 공간 추론과 공간적 어포던스 예측을, AffordanceLLM 과 ManipVQA 는 어포던스 그라운딩을, TimeChat 과 Grounded-VideoLLM 은 시간적, 영상 기반 그라운딩을 다룹니다.
하지만 여기에도 분명한 병목이 있습니다. 저자들은 이를 조밀한 물리 상태를 위한 언어 병목(language bottleneck) 이라 부릅니다. VLM은 물리적 이해를 결국 언어 출력으로 표현하기 때문에, 자세, 깊이, 운동, 접촉, 불확실성, 동역학 같은 정보를 텍스트로 인코딩하지 못합니다. 그래서 VLM은 "완전한 물리 월드 모델이 아니라 지각적 그라운딩 층" 에 머뭅니다. 그라운딩이 "물리적" 이라기보다 여전히 "의미적" 인 단계입니다.
3단계: 행동 그라운딩 (VLA)
다음 다리는 시각-언어-행동 모델, 곧 VLA 입니다. VLA는 시각 관찰, 신체 상태, 언어 목표를 입력받아 실행 가능한 행동으로 변환합니다. 멀티모달 추론과 체화된 제어 사이를 잇는 "행동을 향한 인터페이스" 인 셈입니다.
서베이는 VLA의 행동 표현을 크게 세 갈래로 정리합니다. 첫째, 행동을 언어처럼 토큰으로 다루는 계열입니다. PaLM-E 가 임베디드 멀티모달 언어 모델의 가능성을 연 뒤, RT-2 는 웹에서 학습한 지식을 로봇 제어로 전이하며 행동을 텍스트 토큰처럼 출력했고, OpenVLA 는 이를 오픈소스로 대규모 실제 로봇 시연 위에서 구현했습니다. FAST 는 고주파 행동 시퀀스를 주파수 공간에서 토큰화했습니다.
둘째, 연속적인 행동 청크(action chunk)나 확산/흐름(diffusion/flow) 기반 계열입니다. ACT 가 행동 청킹을 제안했고, \pi_0 는 흐름 매칭(flow matching) 기반의 범용 로봇 제어 VLA로 주목받았으며, 후속인 \pi_{0.5} 는 로봇 데이터, 웹 데이터, 의미 예측을 함께 쓰는 이종 공동 학습(heterogeneous co-training)을 도입했습니다. RDT-1B 는 양팔 조작을 위해 확산 모델을 대규모로 키웠습니다.
셋째, 공간적으로 구조화된 행동 계열로 SpatialVLA (자기중심 좌표의 적응적 3차원 행동 격자)와 3D-VLA (장면 공간에서 목표나 운동 프리미티브를 예측하는 3차원 상호작용 토큰)가 있습니다. 이 세 갈래를 키운 토대는 데이터 표준화였습니다. Open X-Embodiment (RT-X) 가 다양한 로봇 신체에 걸친 데이터를 하나의 형식으로 모았고, Octo 는 그 위에서 오픈 범용 정책을 제시했습니다.
최근에는 추론과 제어를 분리하는 하이브리드 구조가 두드러집니다. VLM이 지시, 물체 의미, 공간 관계, 과제 이력, 상식 사전 지식을 그라운딩하면, 별도의 행동 전문가가 이를 고주파 행동으로 변환하는 방식입니다(\pi_0 의 흐름 매칭 전문가, DexVLA 의 확산 전문가가 그 예입니다). GR00T N1 은 시각-언어 추론과 확산 트랜스포머 행동 생성기를 결합해 휴머노이드 제어를 노리고, TinyVLA나 SmolVLA는 실시간성을 위한 경량화를 추구합니다. 더 나아가 \pi^{*}_{0.6} 은 실제 배포에서 얻은 경험과 교정 개입으로 강화학습을 수행하고, MEM은 영상과 텍스트 기억을 더해 더 긴 시간 지평의 행동을 다룹니다.
그럼에도 VLA에는 근본적인 빈자리가 있습니다. "행동을 예측할 뿐, 행동에 따라 세계가 어떻게 변할지에 대한 내부 예측 모델이 없다" 는 점입니다. 마찰, 순응성(compliance), 접촉 기하, 힘, 불확실성, 타이밍 같은 동역학을 모르면, 한 번의 행동은 그럴듯해 보여도 여러 단계가 쌓이면 오차가 누적됩니다.
4단계: 월드 모델, 예측의 기질
바로 이 빈자리를 채우는 것이 월드 모델 입니다. 서베이는 월드 지식과 월드 모델을 명확히 구분합니다. 정리하면 다음과 같습니다.
"LLM은 세계에 관한 지식(knowledge about the world)을 제공하고, 월드 모델은 세계 안에서 행동하기 위한 예측 메커니즘(predictive mechanisms for acting in the world)을 제공한다."
즉 LLM이 "어떤 행동이 의미 있는가" 를 말해 준다면, 월드 모델은 "행동하면 무슨 일이 일어날 것인가" 를 추정합니다. 서베이의 정의로는, 월드 모델은 현재 상태와 가능한 행동으로부터 미래의 관찰, 잠재 상태, 보상, 가치, 또는 행동의 결과를 예측하거나 시뮬레이션하는 모델입니다. 형식적으로는 현재 상태 s_t 와 행동 a_t 로부터 다음 상태나 관찰 s_{t+1} = f(s_t, a_t) 를, 때로는 보상 r_t 나 가치 V(s_t) 까지 예측합니다.

이 계보는 World Models(Ha & Schmidhuber), PlaNet 과 Dreamer, MuZero 같은 모델 기반 강화학습으로 거슬러 올라갑니다. 특히 MuZero는 관찰을 명시적으로 복원하지 않고도 가치, 보상, 정책 관련 양만 예측해 계획을 지원할 수 있음을 보였는데, 이는 픽셀을 그리지 않는 결정 중심(decision-centric) 월드 모델의 원형입니다.
서베이는 월드 모델을 예측 대상에 따라 세 갈래로 나눕니다.
- 영상 공간(video-space) 월드 모델: 미래의 시각 관찰을 직접 생성합니다. 자율주행 미래를 그리는 GAIA-1, 이종 데이터로 상호작용 가능한 실세계 시뮬레이터를 만든 UniSim, 라벨 없는 영상에서 생성형 상호작용 환경을 만든 Genie, 그리고 Physical AI를 겨냥한 월드 파운데이션 모델 Cosmos 가 여기 속합니다. 다만 "사진처럼 사실적인 영상 생성이 곧 물리적 정확성은 아니다" 라는 경고가 따릅니다. 생성된 롤아웃은 그럴듯해 보이면서도 물체 영속성(object permanence), 접촉 제약, 제어 가능성, 인과적 일관성을 위반할 수 있기 때문입니다.
- 잠재(latent) 월드 모델: 픽셀이 아니라 표현 공간에서 예측합니다. JEPA 계열, 특히 V-JEPA 2 는 행동 조건부 잠재 월드 모델을 후학습해 로봇 계획에 씁니다. 효율적이고 과제와 더 밀접한 표현을 학습합니다.
- 상호작용/행동 조건부(interactive/action-conditioned) 월드 모델: 후보 행동에 따른 반사실적(counterfactual) 미래를 추정합니다. 체화 에이전트에 가장 직접적으로 관련된 갈래입니다.
5단계와 6단계: 정책 학습과 체화 배포
마지막으로 정책 학습은 지각, 추론, 예측을 실제 행동으로 변환합니다. 학습된 정책, 행동 전문가(action expert), 확산/흐름 정책, 제어기가 여기 해당합니다. 형식적으로 정책은 관찰 o_t 에 대해 행동 분포 \pi(a_t \mid o_t) 를 내놓습니다.
그리고 이 모든 것이 모여 체화 에이전트 로 배포됩니다. 체화 에이전트는 단일 행동 모델이 아니라, 지시를 파싱하고, 과제 구조를 추론하고, 물체와 상태를 그라운딩하고, 행동과 궤적을 고른 뒤, 실행하고, 검증하고, 실패를 복구하는 전체 시스템입니다. 여기서 고수준 모듈은 언어, 상징적 상태, 물체 관계, 키포인트 제약, 가치 맵, 로봇 프로그램 같은 표현 위에서 동작하고, 저수준 모듈은 운동 프리미티브, 파지 계획기, 시각운동 정책, 제어기를 실행합니다. 그래서 "모듈 사이에 어떤 정보를 넘길지, 불확실성을 어떻게 다룰지, 언제 실행을 멈추고 다시 계획할지" 를 정하는 인터페이스 설계가 핵심이 됩니다(VoxPoser, OK-Robot, ReKep 처럼 가치 맵이나 키포인트 제약을 인터페이스로 쓰는 시도가 그 예입니다). Gemini Robotics, GR00T N1, \pi 계열 같은 제품 수준의 통합 스택이 등장하면서, 저자들은 "Physical AI가 제품 수준의 시스템 범주가 되어 가고 있다" 고 진단합니다.
평가와 배포: 닫힌 루프가 필요한 이유
서베이가 거듭 강조하는 실용적 메시지는 평가 방식 에 관한 것입니다. 정적인 입력에 대한 오프라인 정확도, 즉 열린 루프(open-loop) 정확도는 위험할 정도로 낙관적인 그림을 그립니다. 행동이 한 번에 그치지 않고 연쇄될 때, 작은 오차는 누적되고(compounding error), 모델이 분포를 벗어난 상태에 들어가면 회복하지 못하기 때문입니다. 저자들의 표현으로는, 열린 루프 정확도는 "누적 오차, 빈약한 회복 능력, 상태 이탈에 대한 민감성을 숨길 수 있다" 고 합니다.
그래서 필요한 것이 닫힌 루프 평가(closed-loop evaluation) 입니다. 관찰하고, 실행하고, 검증하고, 다시 계획하는 순환 속에서 예측이 실제로 물리 세계의 진전을 이끄는지를 봐야 한다는 것입니다. 저자들은 "Physical AI의 진전은 시스템 중심 평가(system-centric evaluation), 즉 정적 입력으로 무엇을 예측하는가가 아니라 세계 안에서 무엇을 신뢰성 있게 해내는가로 비교해야 한다" 고 못박습니다. 평가 지표로는 과제 완수율뿐 아니라 실패 유형, 사람의 개입 횟수, 강건성, 일반화가 함께 보고되어야 합니다.
서베이는 로드맵 단계별로 평가 벤치마크도 정리합니다. LLM의 물리 지식은 PHYBench, PhySense, PhysToolBench, SeePhys 로, VLM의 그라운딩과 물리 추론은 BLINK, Video-MME, PhysBench, QuantiPhy로, VLA의 행동 예측은 LIBERO 와 LIBERO-Pro로, 월드 모델은 영상/잠재/행동 조건부 예측과 계획으로, 체화 에이전트는 BEHAVIOR, EmbodiedBench, RoboSuite, RoboCasa 같은 닫힌 루프/시뮬레이터 환경으로 평가합니다. 단계마다 측정 대상이 달라지므로, 어느 한 점수만으로는 시스템 전체의 신뢰성을 말할 수 없다는 것이 핵심입니다.
흥미롭게도 서베이는 실패 위치로 원인을 역추적하는 디버깅 관점도 제시합니다. 행동 이전 에 실패하면 월드 지식이나 지각의 문제, 행동 도중 에 실패하면 행동 표현이나 신체 전이나 제어기의 문제, 여러 단계 뒤 에 실패하면 월드 모델이나 누적 오차나 기억/복구의 문제, 그리고 시뮬레이션에서는 되는데 실제에서 실패 하면 시뮬레이션-현실 전이(sim-to-real)나 센싱/보정/지연의 문제로 좁혀 볼 수 있다는 것입니다.
남은 과제와 향후 방향
서베이는 로드맵의 각 이음매에서 발생하는 "인터페이스 불일치" 를 네 가지 과제로 정리합니다.
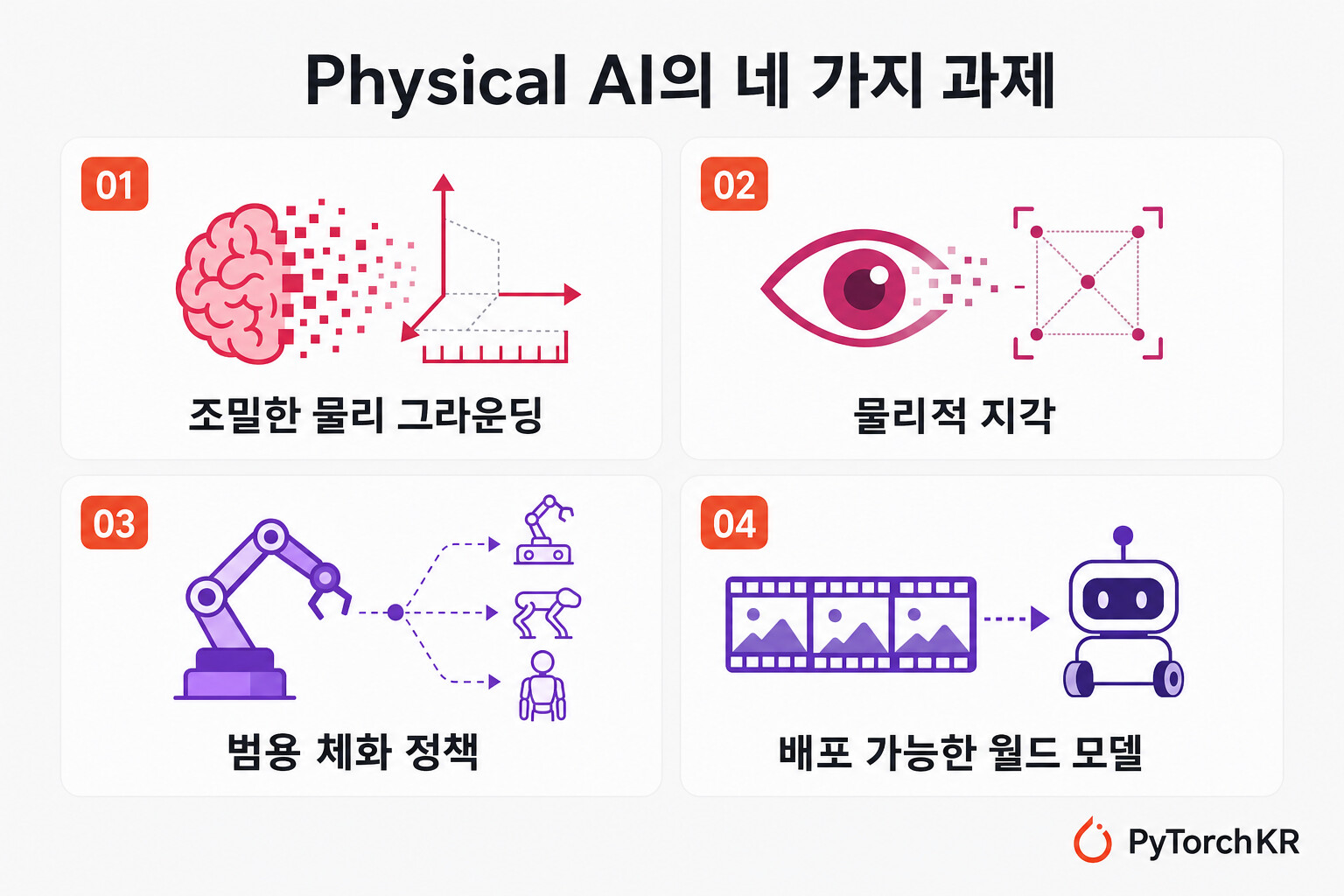
- 암묵적 월드 지식에서 조밀한 물리 그라운딩으로: LLM의 사전 지식은 언어로 매개되어 있어 미터 단위의 물리 상태로 변환하기 어렵습니다. 의미적, 절차적, 인과적 사전 지식을 기하, 운동, 접촉, 힘, 불확실성, 시간 동역학으로 추출하고 정렬하고 그라운딩하는 일이 과제입니다.
- 멀티모달 그라운딩에서 물리적 지각으로: VLM은 조밀한 물리 상태 대신 의미적 서술을 출력합니다. 공간적, 시간적, 어포던스 인지적이며 정량적이고 행동과 관련된 그라운딩이 필요합니다.
- VLA에서 범용 체화 정책으로: 세 가지 병목이 끈질깁니다. (a) 신체마다 행동 공간이 제각각이고(토큰, 말단장치 자세, 궤적, 청크, 연속 제어), (b) 로봇 데이터는 언어/비전 데이터보다 훨씬 작고 이질적이며, (c) 모방 학습으로 훈련된 정책은 분포 변화에 취약하고 회복 능력이 부족합니다. 확장 가능한 행동 표현, 신체 간 전이, 기억과 LLM 에이전트와 월드 모델로 보강된 정책이 방향으로 제시됩니다.
- 월드 모델에서 배포 가능한 Physical AI로: "영상 생성이 곧 월드 모델링은 아니다" 라는 명제가 핵심입니다. 행동 조건부이고, 시간적으로 일관되며, 제어 가능하고, 물리적으로 그럴듯한 예측이 요구됩니다. 효율(잠재 공간)과 충실도(픽셀 공간) 사이의 균형, 그리고 시뮬레이션-현실 전이, 노이즈/지연에 대한 강건성, 안전, 닫힌 루프 복구, 재현 가능한 평가가 함께 풀려야 합니다.
여기에 더해, 닫힌 형태이거나 부분적으로만 공개된 최전선 시스템(GPT-4와 Claude는 닫힘, Gemini Robotics 계열은 닫히거나 일부만 공개, Cosmos와 GR00T N1은 부분 공개, \pi 계열은 부분 공개)이 늘면서 재현이 어려워지는 점도 과제입니다. 문제는 단순한 재현성만이 아닙니다. 이런 시스템은 여러 로드맵 단계를 하나의 제품 스택으로 합치기 때문에, 강한 물리 추론처럼 보이는 결과가 LLM 사전 지식 덕분인지, 지각 모듈, 행동 정책, 검색 시스템, 시뮬레이터, 또는 사람 피드백 파이프라인 덕분인지 분리해 내기(ablation, 기여 분석) 어렵습니다. 자율주행, 체화 비서, 산업 자동화, 인간-로봇 상호작용처럼 안전이 핵심인 영역에서는 이런 불투명성이 특히 부담이 됩니다.
결론: 지식과 예측의 결합
이 서베이의 가장 큰 기여는 새로운 모델이 아니라 하나의 관점 입니다. Physical AI를 LLM의 월드 지식이라는 렌즈로 다시 읽으면, 흩어져 보이던 VLM, VLA, 월드 모델, 정책 학습, 체화 에이전트가 "언어로 매개된 사전 지식이 어떻게 지각적이고, 행동 가능하고, 예측적이고, 배포 가능한 형태로 한 단계씩 그라운딩되는가" 라는 하나의 이야기로 꿰어집니다.
저자들은 이를 기존 서베이들과 대비해 보입니다. 넓은 Physical AI 개관, 비전 중심의 생성 물리 AI 정리, VLA/로봇 파운데이션 모델 연구, 월드 모델 중심 연구는 각각 한두 축에서만 깊이가 있을 뿐입니다. 예를 들어 VLA 연구는 행동 그라운딩에, 월드 모델 연구는 예측에 강하지만 나머지는 얕습니다. 이 서베이는 LLM 월드 지식, VLA 행동 그라운딩, 월드 모델, 폐쇄형 시스템이라는 네 축을 한 로드맵 위에서 함께 다루려 한다는 점에서 차별화를 주장합니다.
핵심 통찰을 한 문장으로 줄이면 이렇습니다. LLM은 세계에 관한 지식을 주지만, 세계 안에서 행동하려면 무슨 일이 일어날지 예측하는 월드 모델이 필요하며, 진정한 Physical AI는 이 둘이 결합되고 닫힌 루프로 검증될 때 비로소 출현합니다. 시리즈 2편에서는 이 로드맵의 한 축인 "예측과 시뮬레이션" 을 가장 깊이 파고든 또 다른 서베이를 통해, 물리 법칙을 이해하는 생성 모델 과 "월드 시뮬레이터" 라는 비전을 자세히 살펴보겠습니다.
 A Survey of Physical AI: A History from ChatGPT to World Models and Embodied Agents 논문
A Survey of Physical AI: A History from ChatGPT to World Models and Embodied Agents 논문
https://www.preprints.org/manuscript/202606.0173/v1
 Awesome-Physical-AI GitHub 저장소
Awesome-Physical-AI GitHub 저장소
https://github.com/Hai-chao-Zhang/Awesome-Physical-AI
더 읽어보기
-
World Action Model의 부상: 비디오 백본으로 로봇 정책을 학습하는 두 번째 레시피 (feat. NVIDIA)
-
[GN⁺] VC가 예측하는 2026년 로보틱스 및 피지컬 AI 분야에서의 6가지 투자 전망 (feat. Bessemer Venture Partners)
![]() 이 글은 2편 중 1편입니다. Physical AI 서베이 연구 살펴보기 2편: 물리를 이해하는 생성 모델과 월드 시뮬레이터로 이어집니다.
이 글은 2편 중 1편입니다. Physical AI 서베이 연구 살펴보기 2편: 물리를 이해하는 생성 모델과 월드 시뮬레이터로 이어집니다.