World Action Model(WAM) 소개
지난 몇 년간 로봇 파운데이션 모델 연구의 중심에는 비전-언어-행동 모델(Vision-Language-Action, VLA) 이 있었습니다. VLA는 인터넷 규모의 이미지-텍스트 데이터로 사전학습한 비전-언어 모델(Vision-Language Model, VLM)을 가져와, 그 위에 로봇 행동을 생성하는 헤드를 붙여 미세조정하는 방식입니다. Pi-0가 정립하고 Pi-0.5가 다듬은 이 레시피는 NVIDIA GR00T를 비롯한 수많은 후속 연구로 이어졌습니다. 그러나 VLM 기반 VLA는 여전히 하나의 벽에 부딪힙니다. 언어와 픽셀을 실제 물리적 행동으로 연결하는 그라운딩(Grounding), 즉 "빨간 머그컵을 집어라"라는 명령을 그것을 실제로 수행하는 모터 명령으로 바꾸는 문제는 결국 제한된 로봇 데이터로부터 학습해야 하기 때문입니다.
이 글이 소개하는 World Action Model(WAM, 월드-액션 모델) 은 출발점을 바꾸는 접근입니다. VLM 대신, 대규모 영상으로 사전학습된 비디오 백본(Video Backbone) 을 정책의 출발점으로 삼습니다. 현대의 비디오 생성 모델은 텍스트 설명으로부터 영상을 만들어내도록 학습되며, 그 영상 안에는 손이 뻗어나가고 도구가 움직이고 물체가 조작되는 의도적 행동이 가득 담겨 있습니다. 즉 비디오 백본은 로봇 행동을 단 한 번도 보기 전에 이미 언어, 시각적 변화, 그럴듯한 물체 상호작용 사이의 유용한 연결을 인코딩하고 있다는 것이 핵심 직관입니다. 만약 이 사전 지식(prior)이 행동 생성으로 전이된다면, 남은 "영상에서 행동으로"의 간극은 "언어에서 행동으로"의 그라운딩을 처음부터 배우는 것보다 작을 수 있습니다.
이 글은 NVIDIA 시애틀 로보틱스 랩(Seattle Robotics Lab)의 Moritz Reuss가 작성한 현대 WAM 지형도입니다. 저자는 2025년 10월 자신의 State of VLA 글에서 WAM이 VLA의 작은 하위 분야에 불과하다고 적었지만, 그 후 몇 달 만에 상황이 빠르게 바뀌었다고 말합니다. 글 전체를 관통하는 중심 질문은 다음과 같습니다.
"이것은 연구와 산업에서의 진짜 패러다임 전환인가, 아니면 짧은 하이프 사이클인가? 그리고 레시피가 그렇게 잘 작동한다면, UniPi 같은 초기 논문 이후 WAM이 주류가 되기까지 왜 몇 년이나 걸렸는가?"
저자의 답은 분명합니다. "WAM은 VLM 기반 VLA와 나란히 로봇 파운데이션 모델의 두 번째 주요 레시피가 될 것" 이며, 다만 어떤 형태가 승리할지, 그리고 아키텍처와 파이프라인의 어느 부분이 실제로 중요한지는 아직 열린 문제라는 것입니다. 더 나아가 최종 승자는 순수한 VLA도 순수한 WAM도 아닌, 둘의 하이브리드일 가능성이 높다고 전망합니다.
이 글은 비교적 밀도 높은 로보틱스 용어를 다룹니다. 본문을 따라가기 전에 핵심 용어를 미리 정리하면 다음과 같습니다.
| 용어 | 풀이 |
|---|---|
| VLA (Vision-Language-Action) | 사전학습된 VLM 백본에서 출발해 시각 관측과 언어 명령으로부터 행동을 생성하도록 적응시킨 로봇 정책 |
| WAM (World-Action Model) | 사전학습된 월드 모델/비디오 백본에서 출발해 장면이 시간에 따라 어떻게 변하는지를 표현·예측하고 대응 행동을 내놓는 정책 |
| VLM (Vision-Language Model) | 이미지-텍스트(또는 영상-텍스트) 데이터로 사전학습되어 시각 입력에 기반한 언어 출력을 내는 모델 |
| 월드 모델 (World Model) | 현재 상태와 행동 추상화(언어, 로봇 행동, 잠재 행동 등)를 조건으로 미래 세계 상태를 예측하는 모델 |
| 그라운딩 (Grounding) | 언어 명령 같은 기호를 그것을 실제로 만족시키는 지각·운동 대상에 연결하는 것. "언어-행동 그라운딩"의 격차가 로봇 학습의 핵심 난제 |
| 역동역학 (Inverse Dynamics) | 현재 관측 o_t 와 미래 관측 o_{t+k} 가 주어졌을 때 그 전이를 만든 행동을 추론하는 것 |
| 공동 예측 (Joint Prediction) | 하나의 정책이 미래 관측과 행동을 동시에 예측하도록 학습하는 것 |
| 행동 청크 (Action Chunk) | 한 번의 정책 호출로 예측되는 짧은 구간 행동 시퀀스 a_{t:t+k} |
| MoT (Mixture-of-Transformers) | 비디오 전문가와 행동 전문가처럼 모달리티별 트랜스포머가 가중치는 분리하되 공유 어텐션으로 결합되는 구조 |
| DiT (Diffusion Transformer) | 디퓨전/플로우 매칭 모델 내부에서 이미지·영상·행동 토큰을 여러 단계로 디노이징하는 트랜스포머 백본 |
일반화 정책을 향한 두 갈래의 베팅
현재 로봇 파운데이션 모델 분야에는 표현(representation)을 두고 두 가지 큰 베팅이 공존합니다. 한쪽은 VLM 백본에서 출발하는 전통적 VLA 레시피로, Xiaomi Robotics, Being-H0.5 등 여러 팀의 공개 연구에서 나타납니다. 다른 한쪽은 사전학습된 비디오 백본을 일반화 조작(manipulation)의 새로운 경로로 사용하는 패러다임으로, NVIDIA의 DreamZero와 Cosmos Policy, Ant Group의 LingBot-VA, Rhoda AI의 DVA, Sereact의 Cortex 2.0, Mimic Robotics의 mimic-video까지 빠르게 확산되고 있습니다.

여기에 더해 Video Prediction Policy, Unified Video Action Model, Fast-WAM 같은 대학 연구실과 오픈 연구 그룹의 작업도 프런티어를 밀어붙이고 있습니다. 백본의 선택은 학습 레시피와 데이터 혼합부터 추론 최적화까지 전체 파이프라인에 영향을 미칩니다. 이 모델들을 대규모로 돌리는 비용을 고려하면, 대부분의 팀은 두 방향을 동시에 추구하기보다 하나(VLA 또는 WAM)를 먼저 우선해야 할 것입니다. 어느 길이 검증될지, 혹은 두 길이 수렴할지는 여전히 열려 있습니다.
WAM은 왜 매력적인가: 그라운딩 갭과 세 가지 가설
WAM이 왜 매력적인지 이해하려면, 먼저 WAM을 로보틱스 속 월드 모델(World Model)의 더 넓은 지형 안에 놓아 보는 것이 도움이 됩니다. 두 가지 기본 구성 요소를 떠올려 봅시다. 시각운동 정책(visuomotor policy) 은 현재 관측과 목표/명령을 로봇 행동으로 매핑합니다. 월드 모델 은 현재 상태와 행동 추상화로부터 미래의 시각적 또는 잠재 상태를 예측합니다. WAM은 정확히 이 둘이 겹치는 지점에 있습니다. 사전학습된 비디오/월드 모델 백본을 사전 지식으로 활용하면서, 미래 상태와 로봇 행동을 함께 예측하는 것입니다.
그라운딩 갭: VLA의 근본적 한계
WAM의 매력을 이해하려면 VLM 백본 위에 세워진 "고전적" VLA의 핵심 난제를 먼저 봐야 합니다. 첫 VLA의 동기는 VLM의 인터넷 규모 지식을 로보틱스에 활용하는 것이었습니다. VLM은 방대한 시각-텍스트 데이터로 학습되어 많은 시각 과제에서 뛰어난 제로샷 성능을 보입니다. VLA 레시피는 이 사전학습된 표현을 행동 생성에 맞게 적응시킵니다.
그러나 VLM 사전학습과 체화된 조작(embodied manipulation) 사이에는 큰 도메인 격차가 존재합니다. 여러 VLA 논문은 행동 학습 목적이 원래 VLM 목적과 크게 갈라질 때 사전학습된 VLM 능력이 퇴화하는 것을 관찰하거나, 이를 우회하도록 설계합니다. VLM2VLA는 이를 VLM에서 VLA로 전환하는 과정의 파국적 망각(Catastrophic Forgetting) 으로 직접 규정합니다. Knowledge Insulation은 유사한 발견을 보고하면서 문제를 아키텍처 차원으로 끌어올립니다. 플로우 매칭(flow matching) 행동 전문가의 그래디언트를 VLM 백본으로부터 격리하여 사전학습된 언어/시각 지식을 보존하고, 학습 수렴과 과제 성능, 언어 추종을 모두 개선한 것입니다. 이러한 해법에도 불구하고 핵심 난제는 남습니다. 제한된 로봇 데이터로부터 언어를 물리적 행동으로 그라운딩하는 문제입니다. 이는 자연스럽게 다음 질문으로 이어집니다. "애초에 언어가 세상의 시각적 변화로 어떻게 매핑되는지를 이미 표현하고 있는 백본에서 출발한다면 어떨까?"
WAM을 뒷받침하는 세 가지 핵심 가설
저자는 다음 세 가지를 결론이 아닌 가설 로 다룰 것을 권합니다. 여러 논문과 동료들과의 논의, 그리고 저자 자신의 관찰에서 반복적으로 등장하는 주장이지만, 아직 깨끗하게 통제된 비교로 검증된 것은 아닙니다.
미래의 세계 변화 예측은 필요한 행동 생성과 상관관계가 있다. 역동역학(Inverse Dynamics) 예측은 순수한 행동 생성보다 흔히 더 쉽습니다. 원하는 결과가 알려져 있다면, 그 결과를 만들어낸 행동을 추론하는 것이 명령과 현재 관측으로부터 행동을 직접 예측하는 것보다 보통 간단합니다. Pi-0.7의 시각적 서브골(visual-subgoal) 결과도 같은 방향을 가리킵니다. 정책에 원하는 미래 이미지가 주어지면 행동 예측이 더 직접적이 되고 학습이 더 빨리 수렴합니다.
비디오 사전학습은 언어와 물리적 변화 사이의 그라운딩을 제공한다. 비디오 모델은 텍스트 설명을 시각적 결과로 매핑하도록 학습됩니다. 이것이 로보틱스로 전이된다면, 로봇 시연만으로 배워야 하는 그라운딩의 양을 줄일 수 있습니다.
비디오 데이터는 로봇 정책을 정규화한다. 로봇 데이터셋은 웹 규모 영상에 비해 매우 작습니다. 비디오로 먼저 사전학습하거나 로봇 데이터와 함께 공동 학습(co-training)하면, 더 넓은 시각적 사전 지식이 과적합을 줄여줄 수 있습니다. DreamZero와 Fast-WAM은 모두 로봇 미세조정 중 행동 학습을 비디오 예측 목적과 함께 공동 학습할 때 WAM이 가장 좋은 성능을 낸다는 것을 보였습니다.
Veo 3.1 실험: 프런티어 비디오 모델은 로봇 조작을 얼마나 이해하고 있을까
행동 헤드를 붙이기 전, 현대 비디오 모델은 이미 얼마나 많은 것을 포착하고 있을까요? 저자 팀은 Google의 프런티어 비디오 생성 모델 Veo 3.1로 간단한 실험을 했습니다. DROID 셋업의 토스터 과제에서 가져온 단일 컨텍스트 프레임을 주고, 토스터 레버를 누르고(원본 DROID 시연과 일치하는 기준 과제) 그다음 왼쪽에 놓인 오렌지를 집으라고(시연을 넘어선 합성 확장) 프롬프트했습니다. 프롬프트 최적화 없는 원샷 시도였으며, 이 영상은 Veo의 사전학습 데이터에 포함되었을 가능성이 매우 낮지만 학습 셋을 직접 확인할 수는 없으므로 통제된 실험이 아니라 사전 지식에 대한 정성적 점검으로 보아야 합니다. 사용된 프롬프트는 다음과 같습니다.
"이 초기 프레임이 주어졌을 때, 로봇 팔이 토스터 레버를 누르는 영상을 생성하라. 그 과제를 마친 뒤 로봇은 토스터 왼쪽의 오렌지를 집고, 집은 후에 멈춰야 한다."

생성된 롤아웃은 로봇 정책으로 명시적으로 학습되지 않은 모델치고는 놀라울 만큼 좋았습니다. 움직임은 부드럽고 배경은 안정적이며 일관되고, 로봇은 두 목표 물체를 향해 그럴듯한 궤적을 따릅니다. 심지어 순서까지 지켜집니다. 레버를 끝낸 뒤 오렌지로 이동하는 것입니다. 한계도 똑같이 분명합니다. 모델은 토스터 레버를 끝까지 누르지 못하고 때로는 반대 동작(레버를 위로 당기기)을 시도하는 듯 보이며, 원본 DROID 셋업의 핀치 그리퍼가 네 손가락 손으로 변형됩니다. 이런 인공물은 모델이 특정 하드웨어를 충실히 모델링하기보다 광범위한 시각적 사전 지식을 사용하고 있음을 보여줍니다. 그럼에도 이 결과는 비디오 백본이 로보틱스에 매력적인 이유를 잘 보여줍니다. 아직 제어에 충분히 신뢰할 수준은 아니지만, 모델은 로봇-물체 상호작용이 어떻게 보여야 하는지에 대한 유용한 사전 지식을 가지고 있습니다. WAM 미세조정은 바로 이 제로샷 상상을 신뢰할 수 있는 제어로 바꾸려는 시도입니다.
로보틱스 월드 모델의 더 넓은 조망에 관심이 있으시다면, NTU의 서베이 "World Model for Robot Learning: A Comprehensive Survey"를 참고해주세요.
현대 WAM 이해하기: 세 가지 설계 축
VLM 기반 VLA가 "VLM 공동 학습 + 플로우 트랜스포머 행동 생성"으로 학습 레시피가 대체로 수렴한 것과 달리, WAM은 아직 여러 활발한 형태로 갈라지고 있습니다. 바로 이 점이 지금 이 분야를 흥미롭게 만드는 요소입니다. 어떤 설계 조합이 승리할지, 혹은 최고의 시스템이 여러 형태의 일부를 합칠지 아직 아무도 모릅니다. 저자는 이 설계 공간을 세 개의 축으로 정리합니다(완전히 독립적이지는 않습니다).
- 패러다임(Paradigm): 모델은 무엇을 예측하며, 예측된 영상은 어떻게 행동 생성에 사용되는가? (역동역학 vs 공동 예측 vs 표현 전용)
- 행동 통합(Action Integration): 행동은 실제로 어떻게 모델에 들어가는가? (기본 행동 토큰 vs 행동을 이미지로 vs 잠재 행동/계획)
- 아키텍처(Architecture): 구성 요소는 어떻게 결합되는가? (Mixture-of-Transformers vs 모놀리식 vs 계층형)
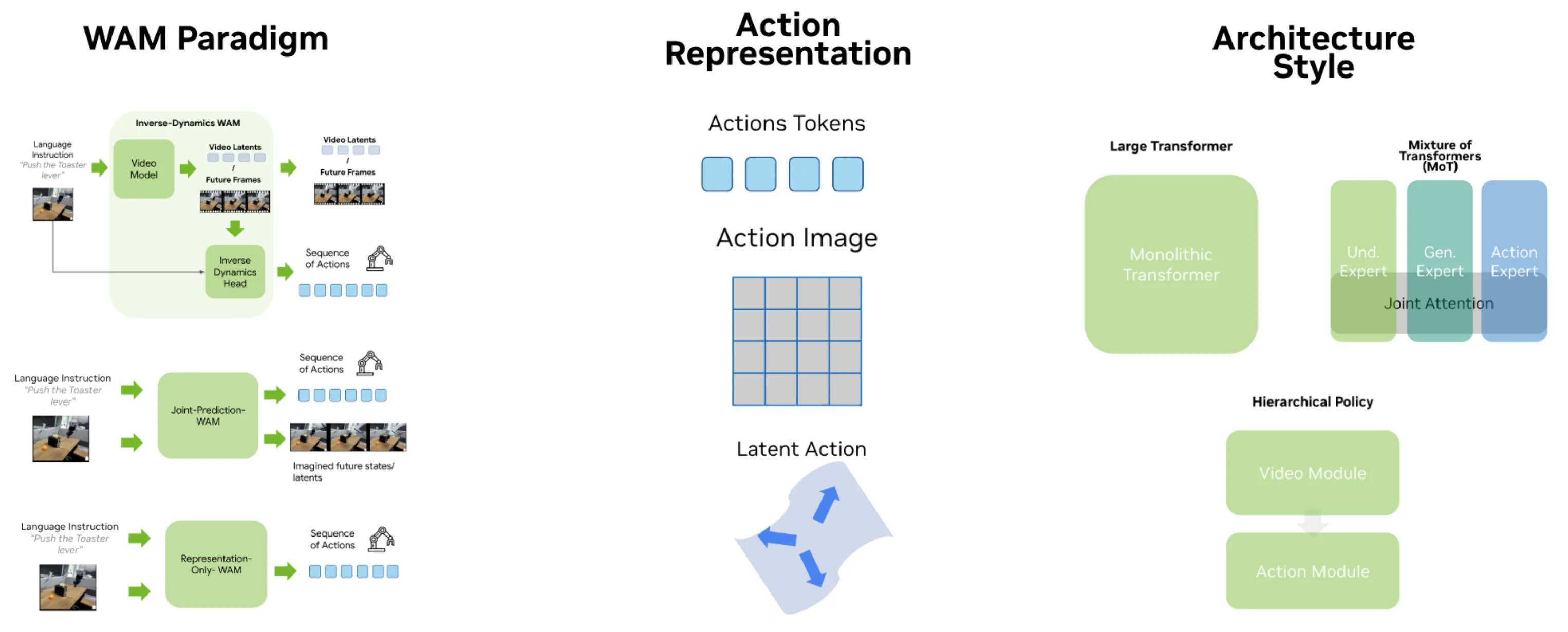
패러다임: 모델은 무엇을 예측하는가
첫 번째 축은 정책의 형태, 즉 모델이 무엇을 예측하고 예측된 영상이 어떻게 행동 생성에 쓰이는지입니다. 현대 WAM에서는 추론 경계에서 차이를 보이는 세 방향이 나타납니다. 역동역학, 공동 예측, 표현 전용 입니다.
역동역학: 미래를 예측한 뒤 행동을 추론

역동역학 셋업은 가장 이해하기 쉬운 WAM 레시피입니다. 먼저 미래를 상상한 뒤, 그 영상으로부터 가장 가능성 높은 행동을 예측합니다. 형식적으로는 현재 관측 o_t 와 미래 관측 o_{t+k} 가 주어졌을 때, 그 전이를 만들어낼 행동 시퀀스 a_{t:t+k} 를 추론하는 문제입니다. 이렇게 하면 어려운 언어 그라운딩 문제가 비디오 단계로 옮겨갑니다. 명령을 그럴듯한 시각적 변화로 번역하는 것입니다. 비디오 사전학습이 이 "언어에서 시각적 변화로"의 매핑을 이미 상당 부분 학습했으므로, 행동 헤드는 로봇 시연에서 모든 것을 배울 필요 없이 역동역학 문제에만 집중할 수 있다는 베팅입니다.
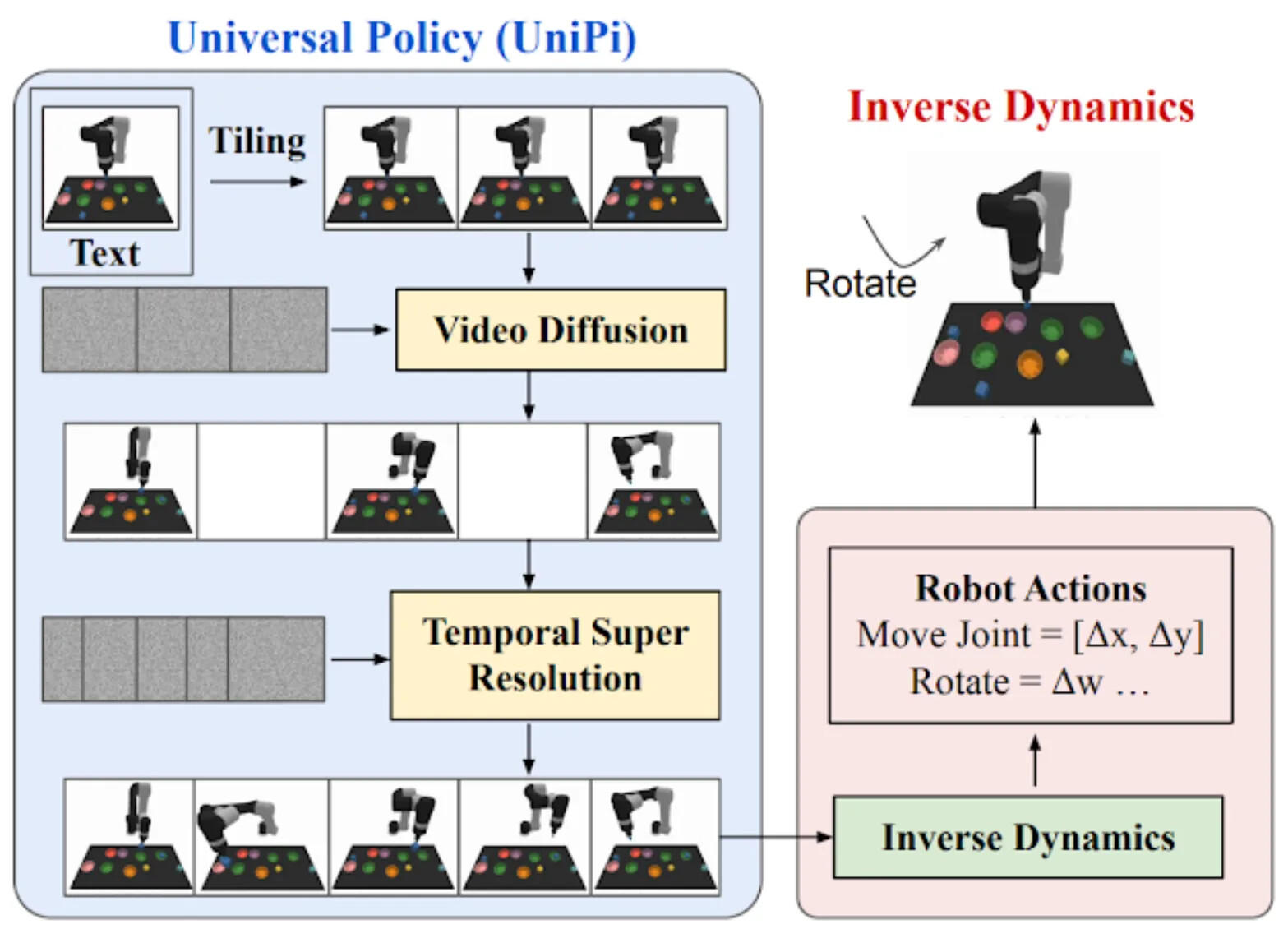
이 방향의 선구적 논문은 2023년의 UniPi입니다. 비디오 디퓨전을 로보틱스를 위한 고수준 계획으로 사용하고, 역동역학으로 저수준 제어를 복원하는 이 레시피를 명확히 실행한 첫 현대적 사례입니다. UniPi는 동시에 WAM이 주류가 되기까지 왜 몇 년이 더 걸렸는지도 보여줍니다. Imagen Video 시대의 CNN 기반 비디오 디퓨전 스택을 처음부터 사전학습해야 했고, 저자의 거친 추정으로 그 사전학습은 약 167 ZFLOP으로 대부분 로보틱스 연구실의 예산을 한참 벗어났습니다. 현대 역동역학 WAM은 오픈된 DiT(Diffusion Transformer) 기반 비디오 백본에서 출발해 미세조정하는 것으로 이 비용을 우회할 수 있습니다.
이 방향의 현대적 버전이 LingBot-VA입니다. 16,000시간의 교차 체화(cross-embodiment) 사전학습을 통해 Wan 2.2-5B를 로봇 비디오-행동 모델로 바꿉니다. UniPi와의 중요한 차이는 단순히 규모가 아닙니다. LingBot-VA는 인과적(causal)이며, 개방 루프 비디오 생성이 아니라 폐쇄 루프 롤아웃을 위해 긴 시각적 이력으로 학습됩니다. 또한 비디오와 행동을 위한 별도 전문가를 두고 각 레이어에서 공유 셀프 어텐션으로 결합하는 Mixture-of-Transformers(MoT) 아키텍처를 사용합니다.
| 설계 선택 | UniPi | LingBot-VA |
|---|---|---|
| 핵심 아이디어 | 미래 비디오 계획을 생성한 뒤 역동역학으로 행동 복원 | 폐쇄 루프 로봇 월드-액션 롤아웃을 위해 비디오 백본을 미세조정 |
| 백본 | CNN 기반 비디오 디퓨전(캐스케이드 U-Net), 처음부터 학습 | Wan 2.2-5B 잠재 DiT(오픈 가중치) |
| 잠재 비디오 VAE | 없음, 저해상도 RGB 미래를 직접 생성 | Wan 2.2-5B(공간 16×16, 시간 4× 압축) |
| 행동 전문가 | 별도 CNN 행동 헤드 | 공동 어텐션으로 결합된 MoT 행동 전문가 |
| 행동-비디오 결합 | 단방향: 비디오 먼저, 그다음 행동 | 양방향: 비디오가 행동을 조건화하고, 생성된 행동이 비디오를 조건화 |
| 로봇 학습 규모 | 작음, 시연 전용 | 16,000시간 교차 체화 월드-액션 사전학습 |
같은 주제의 변형이 여럿 있습니다. Video Prediction Policy, DiT4DiT, mimic-video는 최종 RGB 영상을 반드시 필요로 하지 않고, 비디오 모델의 중간 특징을 행동 디코더를 위한 예측 계획으로 사용합니다. 반면 DVA와 LingBot-VA는 생성·예측된 미래 롤아웃에 더 직접적으로 기댑니다. 어려운 점은 대부분의 논문이 비디오 백본을 바꾸고, 대규모 사전학습의 양이 제각각이며, 서로 다른 하이퍼파라미터를 튜닝하고 서로 다른 셋업에서 평가한다는 것입니다. 그래서 깨끗하게 통제된 비교가 거의 불가능합니다.
공동 예측: 비디오와 행동을 함께 학습
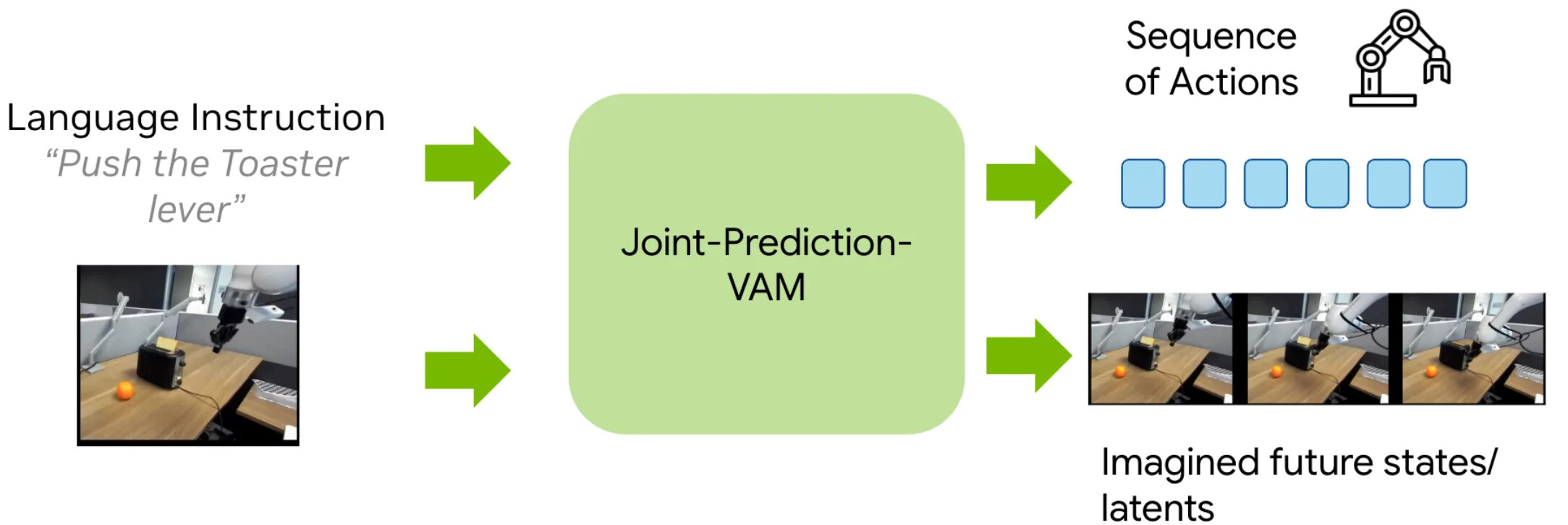
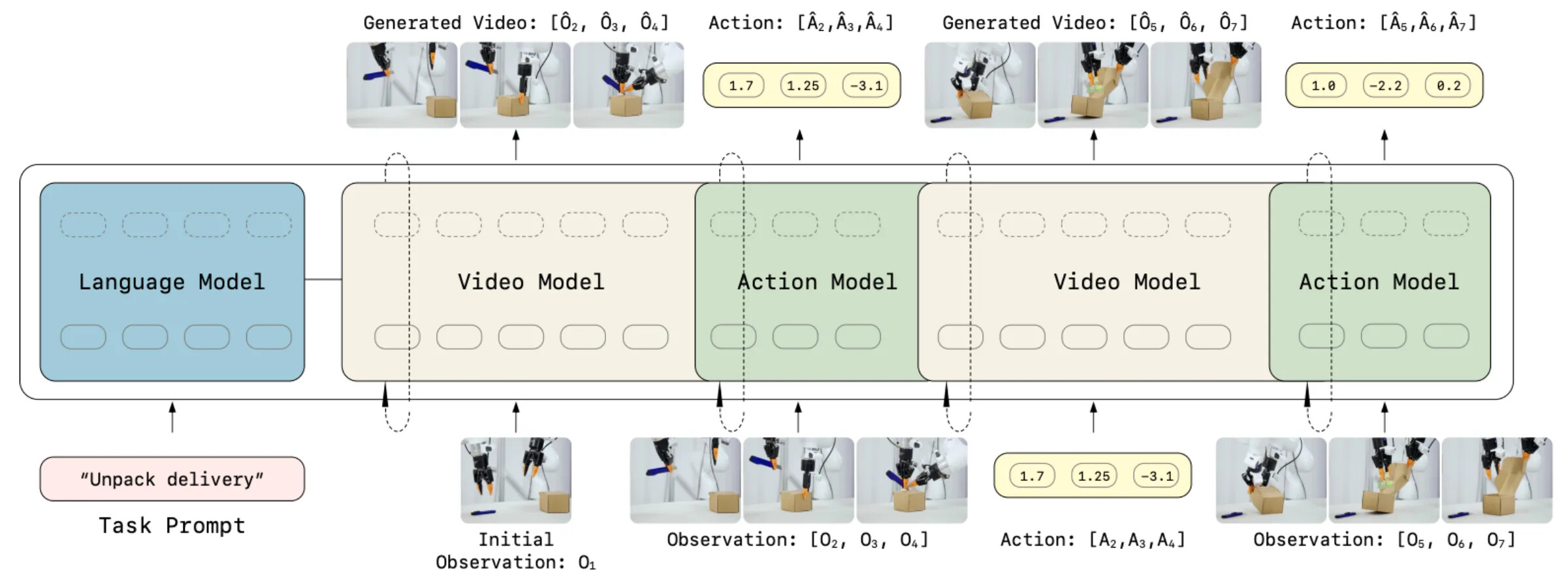
두 번째 형태는 공동 예측(joint prediction)입니다. 미래 영상을 먼저 생성한 뒤 행동을 디코딩하는 대신, 모델이 영상과 행동을 함께 예측합니다. 형식적으로는 현재 관측 o_t 와 언어 l_t 가 주어졌을 때, 하나의 정책 \pi(o_t, l_t) 가 미래 관측 o_{t+1:t+k} 와 행동 a_{t:t+k} 를 모두 예측하도록 학습합니다. 이것은 WAM 아이디어의 더 강하게 결합된 버전으로, 모델은 무엇이 일어나야 하는지와 그것을 어떻게 일으킬지를 같은 예측 단계에서 배우도록 강제됩니다.
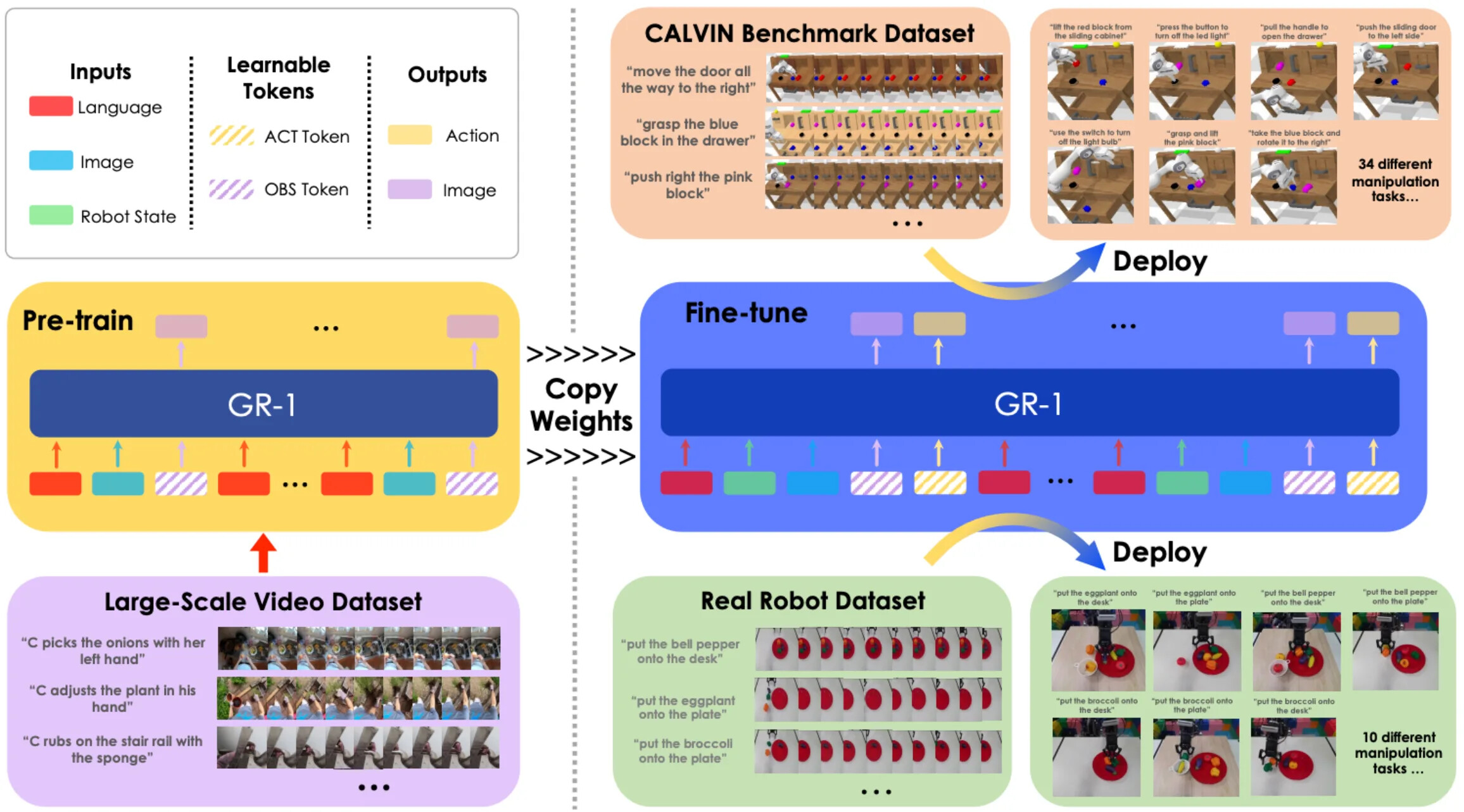
이 방향의 초기 기반 논문은 GR-1입니다. 대규모 영상으로 사전학습한 뒤 로컬 로봇 데이터셋에서 비디오와 행동 감독을 모두 사용해 미세조정했습니다. GPT-2 스타일 트랜스포머 정책을 인터넷 영상 예측으로 사전학습한 다음, 공동 비디오-행동 목적으로 로보틱스 데이터에 미세조정한 것입니다. R3M, Voltron 같은 이전 연구가 이미 영상과 언어가 로보틱스 표현 학습에 도움이 됨을 보였지만, GR-1은 단순하면서도 중요한 전환을 이뤘습니다. 영상을 이미지 수준의 시각 표현이 아니라 더 나은 정책 표현 을 학습하는 데 사용한 것입니다.
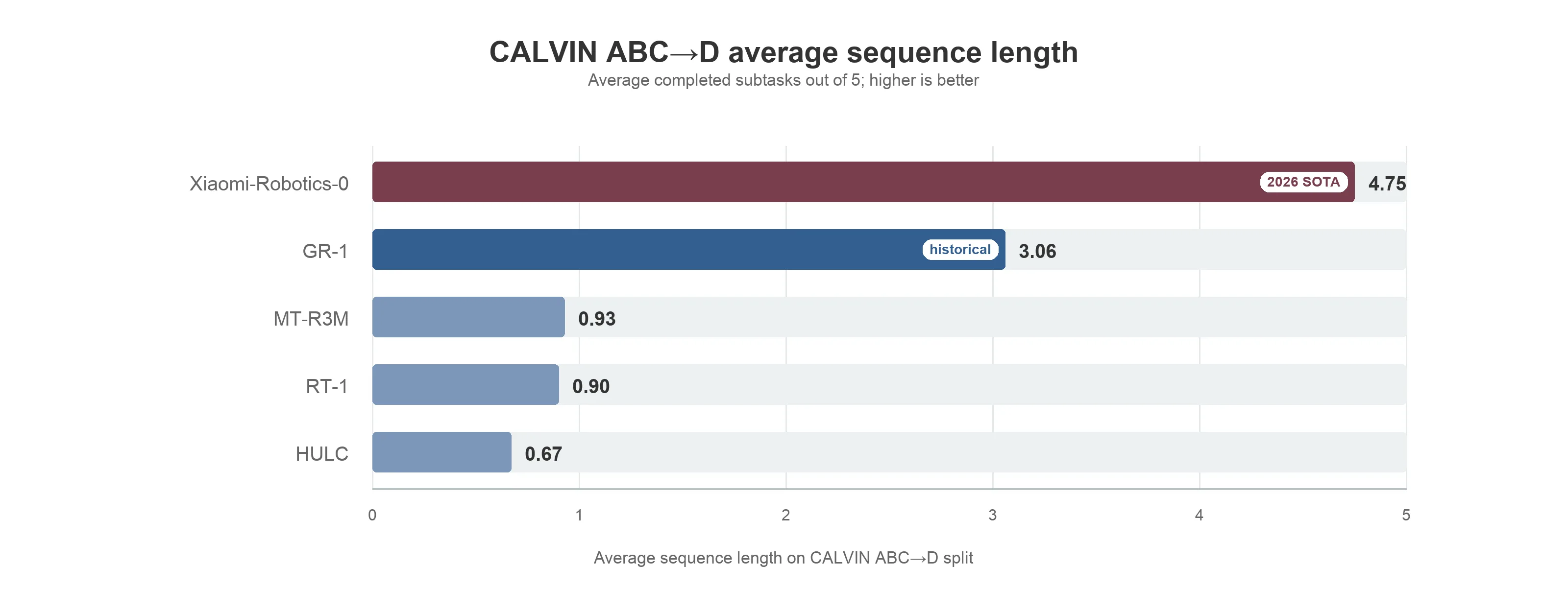
당시 CALVIN 결과는 유용한 시뮬레이션 증거였습니다. 더 어려운 ABC→D 분할에서 GR-1 표의 기존 방법들은 평균 시퀀스 길이 1.0 아래에 머물렀지만, GR-1은 3.06/5에 도달했습니다. 2026년 기준으로 이 수치는 낡았지만, 미래 시각 상태 예측이 더 나은 시각 인코더가 아니라 더 나은 정책 표현을 만들 수 있음을 보였다는 점에서 역사적으로 의미가 있습니다.
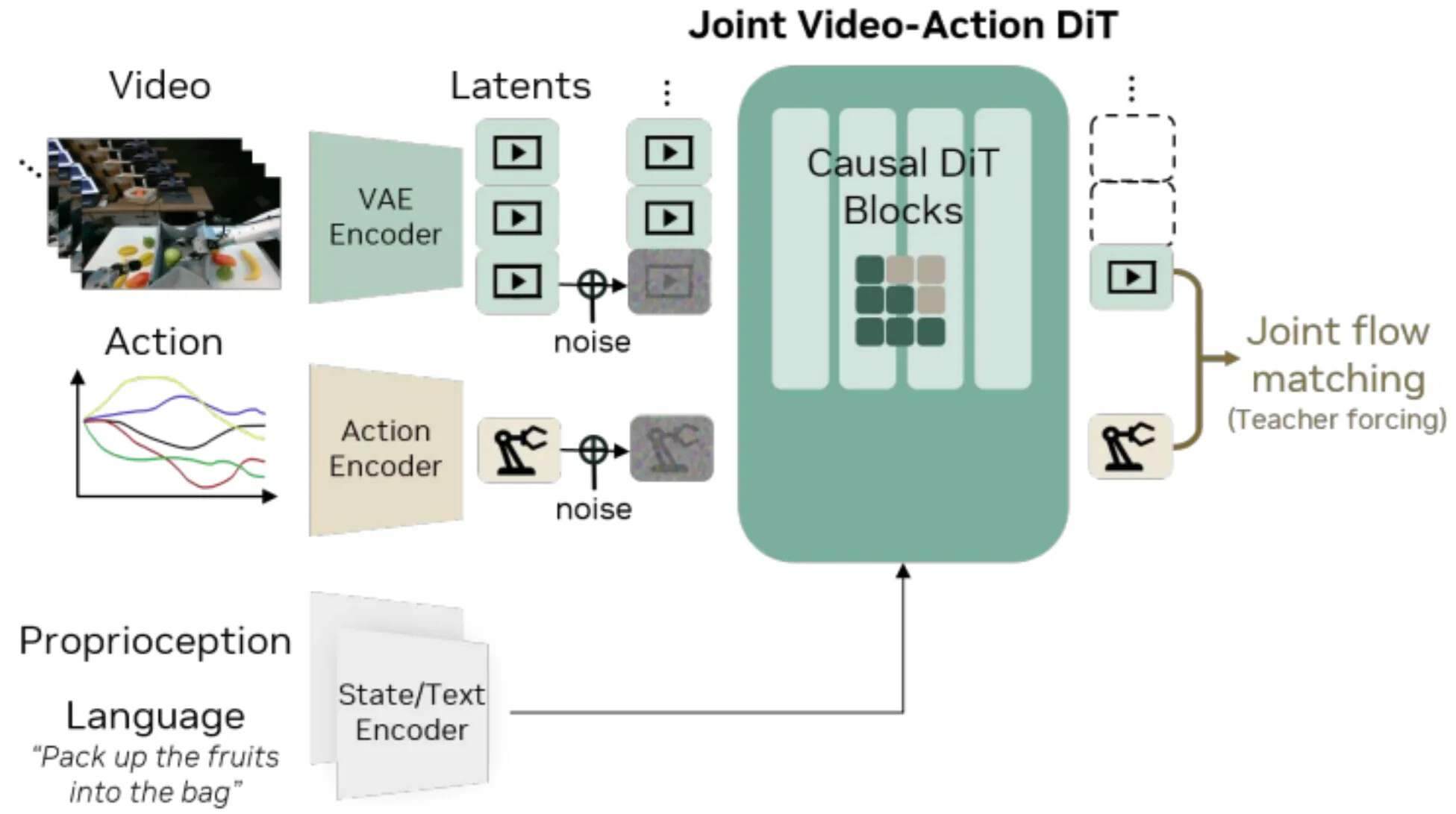
이 아이디어의 현대적 대규모 버전이 DreamZero입니다. 비디오 예측 헤드를 두른 작은 트랜스포머 정책을 학습하는 대신, Wan 2.1-I2V-14B-480P에서 출발해 비디오 디퓨전 백본을 공동 월드-액션 모델로 바꿉니다. 모델은 하나의 모놀리식 DiT 안에서 비디오 토큰과 행동 토큰을 함께 디노이징합니다. 별도의 역동역학 모듈이 없으며, 행동은 같은 디노이징 과정 안의 또 다른 생성 모달리티입니다.

DreamZero가 보고한 RoboArena 점수는 WAM에 대한 중요한 실세계 신호입니다. 대부분의 논문이 여전히 LIBERO 같은 시뮬레이션 벤치마크에 집중하는 가운데, RoboArena는 몇 안 되는 공개 실세계 개방형 평가입니다. 2026년 4월 스냅샷에서 DreamZero는 1750에 도달해 Pi-0.5의 1622를 넘어섰습니다. WAM이 더 나은 기본값이라는 증명은 아니지만, 그 잠재력에 대한 긍정적 신호입니다. 특히 흥미로운 점은 DreamZero가 추가적인 대규모 교차 체화 학습 단계 없이 DROID만으로 학습되었다는 사실입니다.
| 설계 선택 | GR-1 | DreamZero |
|---|---|---|
| 핵심 아이디어 | 행동을 배우며 미래 프레임 예측을 보조 목적으로 사용 | 하나의 비디오 디퓨전 백본에서 미래 비디오와 로봇 행동을 함께 디노이징 |
| 백본 | 비디오 예측 리드아웃 토큰을 가진 GPT-2 스타일 트랜스포머 | 로봇 제어에 적응시킨 Wan 2.1-I2V-14B-480P |
| 규모 | 약 21M 정책 파라미터, 사전학습 시각/언어 인코더는 분리 | 14B Wan 백본, 행동까지 엔드투엔드 튜닝 |
| 생성 목적 | 미래 비디오와 행동에 대한 L2 재구성 | 공동 미래 비디오-행동 생성을 위한 플로우/디노이징 |
| 언어 조건화 | CLIP | T5 계열 텍스트 인코더(Wan에서 상속) |
GR-2, Seer, PAD, UWM, UVA, DreamVLA 등이 이 넓은 공동 예측 흐름 주변에 자리합니다. PAD는 하나의 공동 디노이징 과정 안에서 미래 이미지 예측과 로봇 행동 생성을 함께 시도한 또 다른 초기 사례이고, UWM은 비디오와 행동에 독립적인 노이즈를 사용해 하나의 공동 트랜스포머 안에서 더 유연한 추론 모드를 지원합니다.
표현 전용: 추론 시 비디오 생성을 건너뛰기
세 번째 선택지는 비디오 백본을 순수하게 표현으로만 사용하고 추론 시 비디오 생성을 완전히 건너뛰는 것입니다. Fast-WAM이 좋은 예입니다. LingBot-VA와 유사한 Wan/MoT 스타일 셋업을 쓰면서, 16,000시간의 대규모 로봇 사전학습 없이도 시뮬레이션 벤치마크에서 그 성능에 근접합니다. 테스트 시 비디오 생성을 건너뛰므로 추론이 몇 배 빨라집니다. 다만 Fast-WAM은 표현 전용 가설을 뒷받침하는 몇 안 되는 공개 증거이며, 현재의 시뮬레이션 증거만으로는 이 아이디어를 완전히 확신하기 어렵다는 것이 저자의 입장입니다. 오늘날 대부분의 WAM은 추론 시 어떤 형태로든 비디오 생성을 유지하며 매우 느린데, Fast-WAM 같은 더 빠른 WAM은 앞으로 훨씬 큰 연구 영역이 될 것입니다.
행동 통합: 행동은 어떻게 모델에 들어가는가
비디오와 행동 예측을 어떻게 결합할지 논했으니, 이제 행동이 모델 내부에서 어떻게 표현되는지를 봅시다. 이 선택이 중요한 이유는 사전학습된 백본이 시각 토큰을 디노이징하는 법은 알지만 연속적인 로봇 행동은 모르기 때문입니다. 즉 실제적인 모달리티 불일치(modality mismatch)가 존재합니다.
기본 행동 토큰
가장 단순한 기본값은 연속 또는 이산 행동 토큰과 행동 헤드를 추가하여, 행동을 영상과 나란한 또 다른 모달리티로 다루는 것입니다. UniPi, GR-1, DreamZero, LingBot-VA, VPP, mimic-video, Fast-WAM이 모두 이 방식의 어떤 버전을 사용합니다. 위험은 모달리티 불일치입니다. 행동 청크는 백본이 사전학습한 시각 토큰과 다르므로, 모델은 행동 미세조정 중 자신의 표현을 적응시켜야 합니다.
행동을 이미지로
또 다른 선택지는 행동을 비디오 모델이 이미 아는 무언가로 바꾸는 것입니다. 새 행동 토큰이나 별도 행동 헤드 대신, 행동을 같은 생성 인터페이스 안의 시각적 타깃으로 인코딩하여 사전학습된 비디오 표현을 교란하지 않습니다.
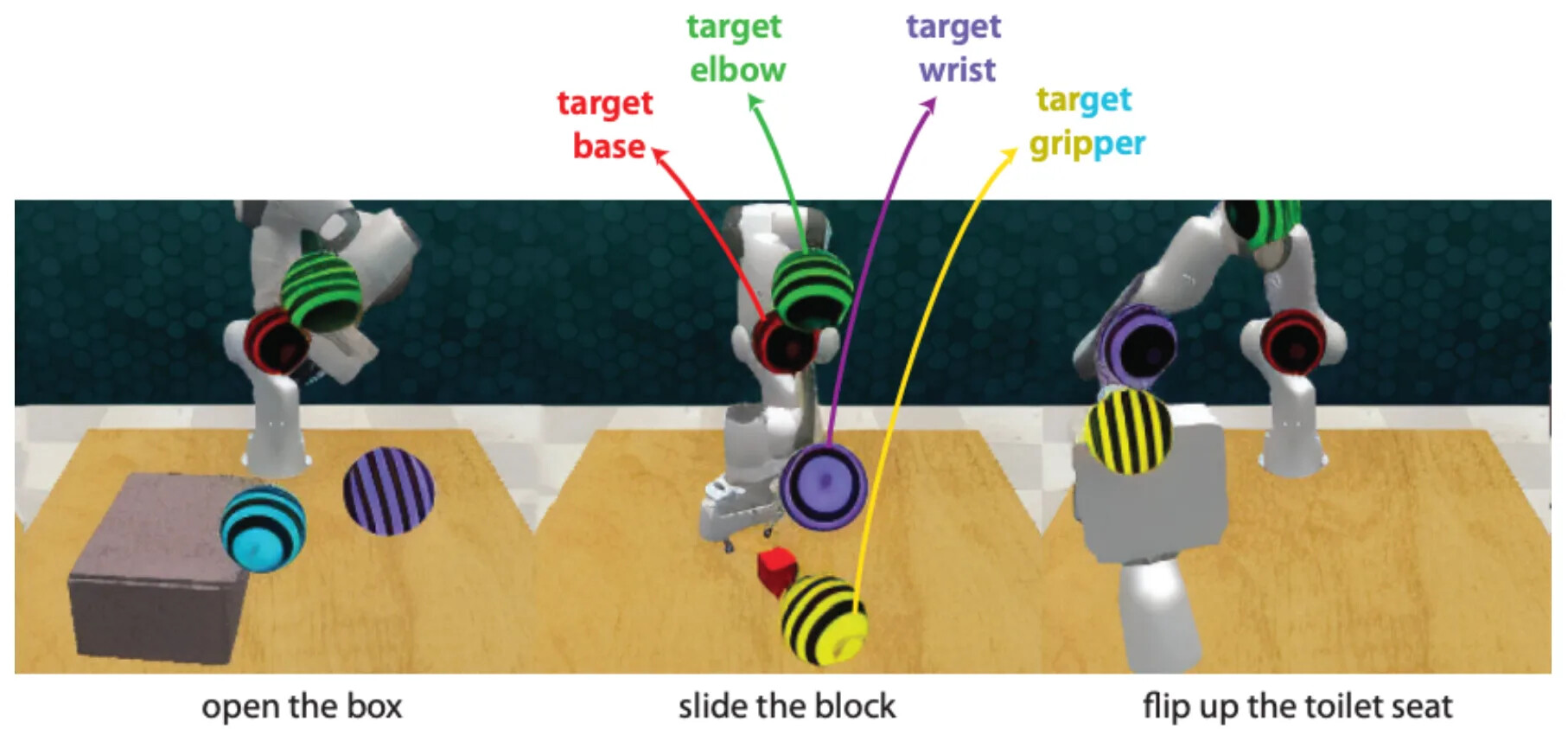
가장 가까운 초기 조상은 GENIMA입니다. GENIMA는 Stable Diffusion을 미세조정해 RGB 이미지 위에 관절 행동 타깃을 그리고, 컨트롤러로 그 시각적 타깃을 관절 위치 행동으로 매핑합니다. 흥미로운 부분은 인터페이스 선택입니다. 행동을 생성형 이미지 모델이 그릴 수 있는 무언가로 표현한 것입니다.
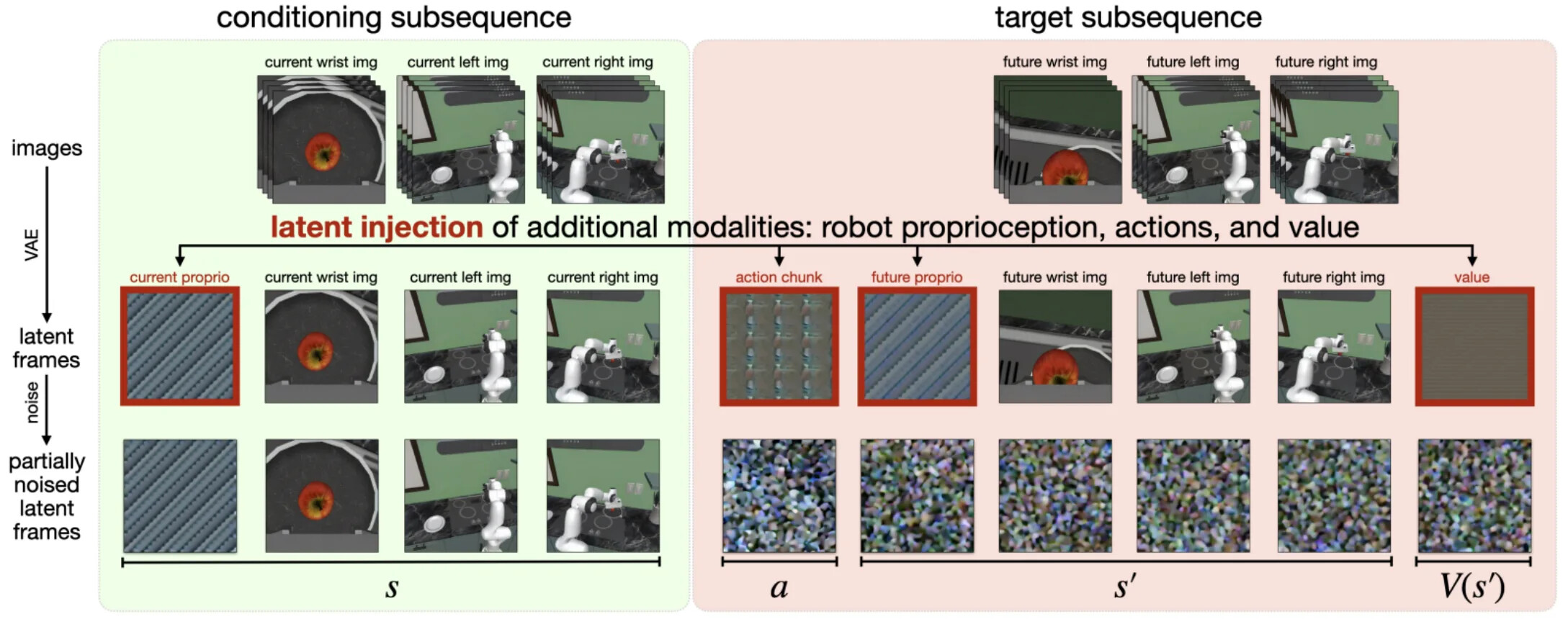
현대적 버전이 Cosmos Policy로, 행동을 합성 잠재 비디오 프레임으로 다룹니다. 별도 행동 디코더를 추가하는 대신 행동, 고유수용성(proprioception), 가치 타깃을 비디오 모델 자신의 디노이징 인터페이스 안의 가짜 프레임으로 인코딩하고, 추론 시 예측된 행동 이미지를 공간 차원으로 평균하여 행동 벡터로 디코딩합니다. 이 셋업은 사전학습된 비디오 백본을 그 고유한 비디오 디노이징 공간에 가깝게 유지하면서도 로봇 행동을 생성합니다.
잠재 행동과 계획
또 다른 선택지는 행동을 잠재 계획(latent plan)이나 잠재 행동(latent action)으로 압축하고 그것에 정책을 조건화하는 것입니다. 전체 비디오 예측은 비싸고, 대부분의 픽셀은 제어에 실제로 필요하지 않기 때문에 매력적입니다.
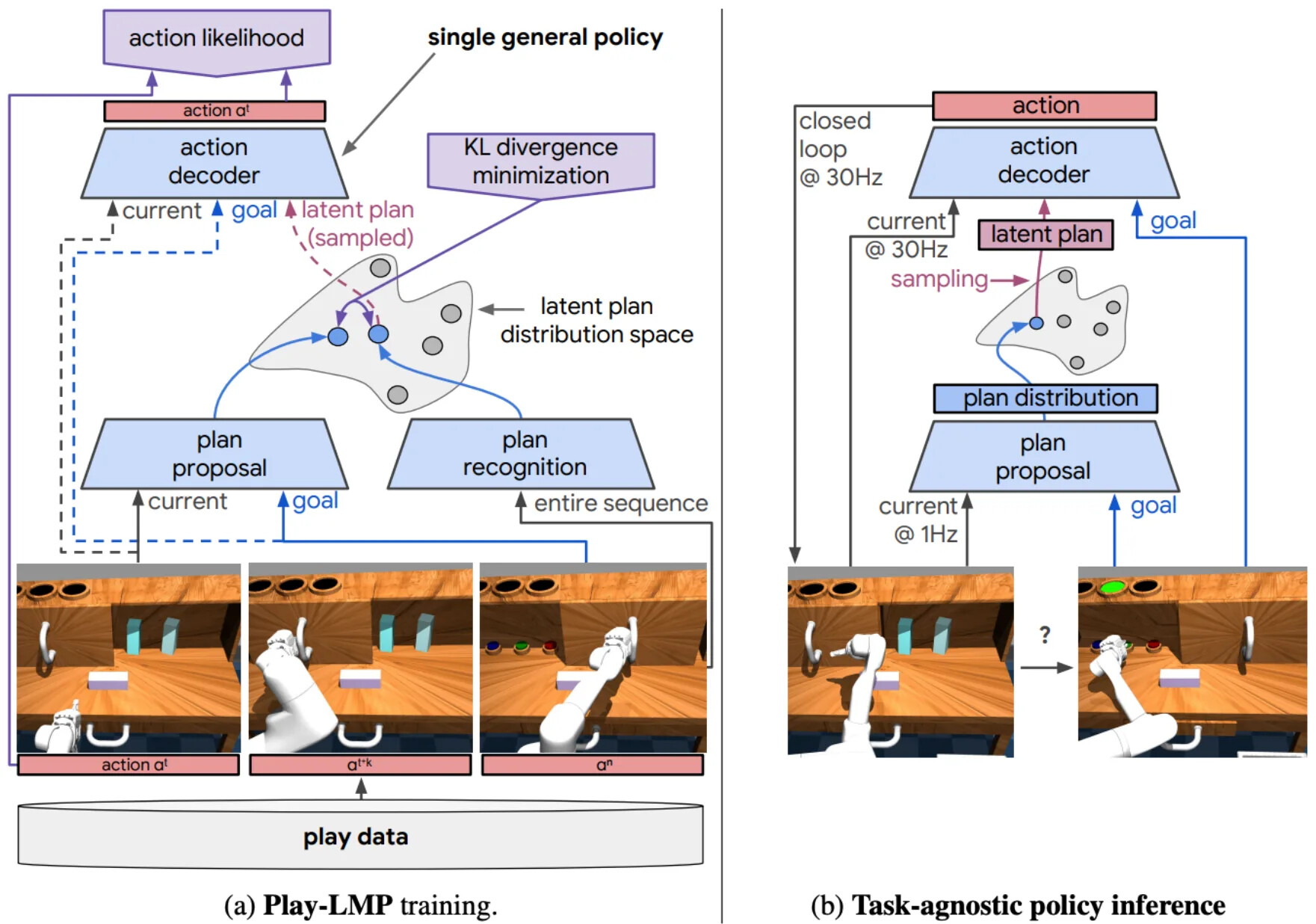
Play-LMP는 2019년에 이 아이디어를 개척했습니다. 사후(posterior) 네트워크가 짧은 궤적 윈도우를 잠재 계획으로 압축하고, 사전(prior) 네트워크가 현재 관측과 목표 이미지로부터 그 잠재 계획을 예측하도록 학습하며, 저수준 정책이 샘플된 계획을 행동으로 디코딩합니다. 현대의 잠재 행동 흐름은 규모와 데이터 소스를 바꿉니다. Genie는 잠재 행동 토큰을 레이블 없는 인터넷 영상에서 학습할 수 있음을 보였고, LAPA는 이런 잠재 행동 사전학습을 VLA 스타일 로봇 학습으로 밀어붙였습니다.
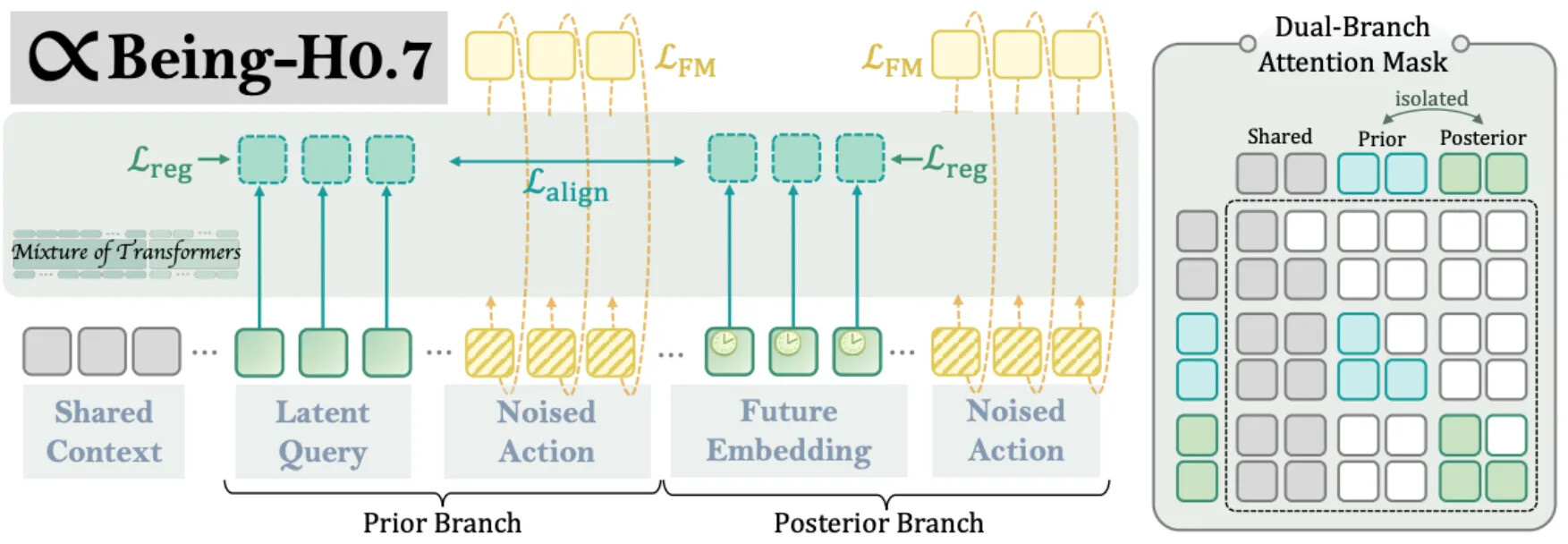
Being-H0.7은 원래 Play-LMP 아이디어의 현대 WAM 버전입니다. 사전/사후 잠재 계획 논리를 유지하되 파운데이션 모델 규모로 실행합니다. 사후 분기는 미래 관측에 접근해 동결된 V-JEPA 2.1 시각 인코더와 Perceiver 리샘플러로 인코딩한 뒤 K개의 미래 임베딩으로 압축하고, 사전 분기는 학습 가능한 잠재 쿼리로 그 미래 정보를 담은 잠재 상태를 맥락에서 맞추도록 학습합니다. 테스트 시에는 사후 분기를 제거하여, 전체 비디오 시퀀스를 다시 생성하도록 강제하는 대신 빠른 잠재 인터페이스를 정책에 제공합니다. Being-H0.7은 20만 시간의 1인칭 인간 영상과 1만 5천 시간의 로봇 시연으로 학습됩니다.
| 설계 선택 | Play-LMP | Being-H0.7 |
|---|---|---|
| 핵심 아이디어 | 짧은 로봇 행동 윈도우를 저수준 정책을 조건화하는 잠재 계획으로 압축 | 대규모 1인칭 영상과 로봇 시연에서 잠재 월드-액션 모델을 학습 |
| 데이터 소스 | 로봇 플레이/시연 궤적 | 20만 시간 1인칭 인간 영상 + 1만 5천 시간 로봇 시연 |
| 아키텍처 | 계층형 잠재 계획 정책, LSTM 저수준 디코더 | 잠재 월드-액션 모델링을 위한 대형 MoT 트랜스포머 |
| 정책 인터페이스 | 사전 계획 예측, 관측과 목표로 조건화된 저수준 정책이 실행 | 양쪽 분기 학습, 테스트 시 컴팩트 잠재 인터페이스로 사전 분기만 실행 |
핵심 차이는 잠재 변수 자체가 아닙니다. Play-LMP가 이미 사전/사후 잠재 계획의 핵심 아이디어를 가지고 있었고, Being-H0.7은 그 인터페이스를 현대 WAM/VLA 하이브리드 안에서 어떻게 확장할 수 있는지를 보여줍니다. 잠재 행동은 행동 조건부 월드 모델의 추상화로도 인기를 얻고 있는데, 대규모 1인칭 인간 영상에서 연속 잠재 행동을 학습하는 DreamDojo가 최근 예입니다. 역동역학과의 중요한 차이는 감독(supervision) 경로에 있습니다. 역동역학 WAM은 시각적 전이가 어떻게 모터 명령으로 매핑되는지를 배우기 위해 보통 짝지어진 비디오-행동 데이터를 필요로 합니다. 반면 잠재 행동 방법은 영상 자체에서 먼저 행동 추상화를 학습한 뒤, 그 추상화를 나중에 로봇 행동에 연결하려 합니다.
아키텍처: 계층형, 모놀리식, MoT 중 무엇인가
세 번째 축은 아키텍처, 즉 구성 요소가 구조적으로 어떻게 결합되는지입니다. 이는 앞의 두 축과 대체로 직교합니다. 역동역학은 계층형일 수도 MoT 스타일일 수도 있고, 공동 예측은 모놀리식일 수도 전문가 기반일 수도 있습니다.
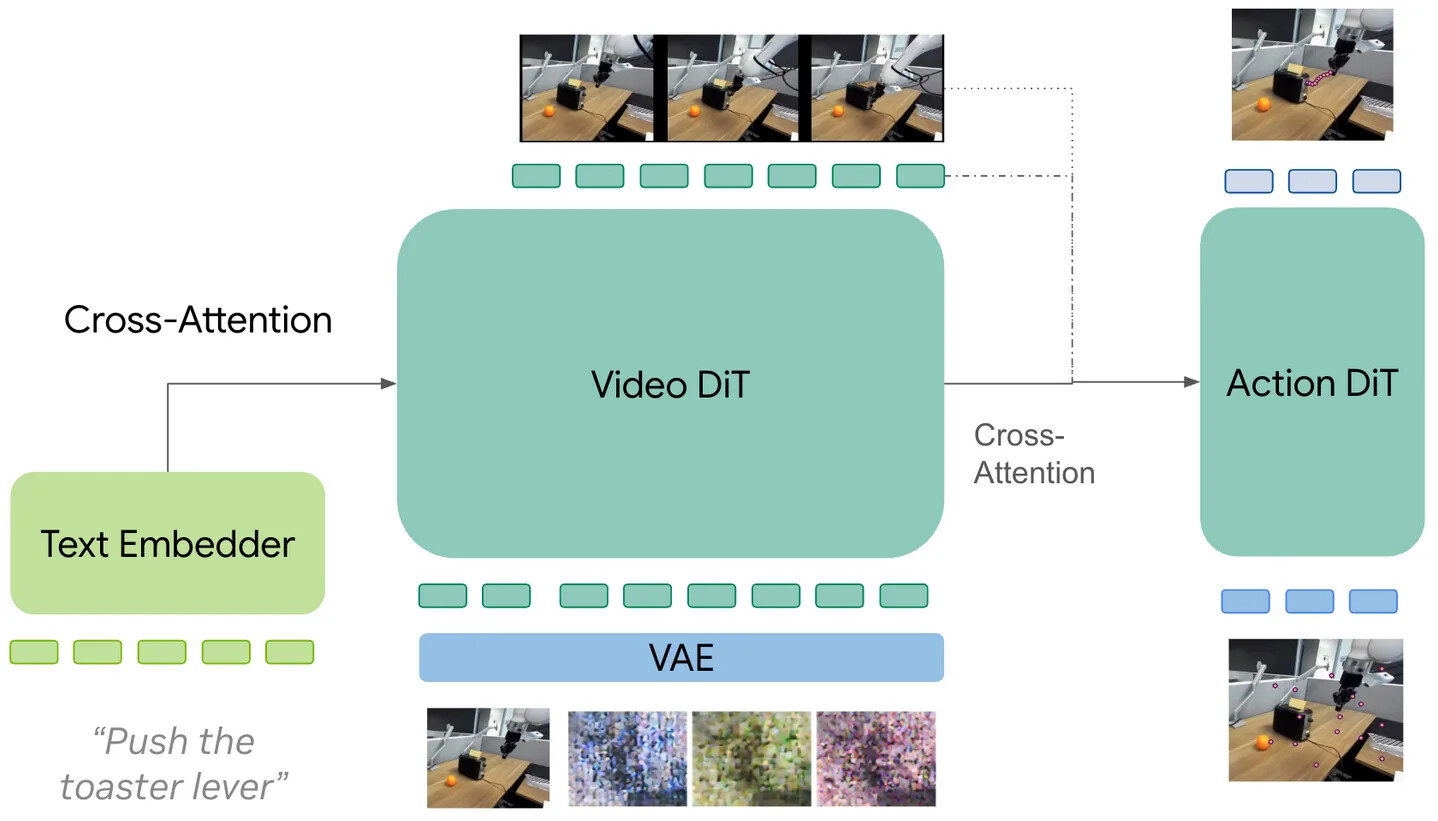
계층형(Hierarchical) 은 행동 헤드가 완전히 모듈식이라 가장 유연합니다. 단순 CNN 회귀기(UniPi)부터 완전한 VLA 스택(Pi-0.7)까지 무엇이든 될 수 있고, VPP와 mimic-video가 전체 RGB 롤아웃 대신 중간 비디오 특징을 넘기며 그 사이에 위치합니다. 단점은 비디오와 행동 단계 사이의 약한 결합으로, 정보가 한 방향으로만 흐릅니다. 그래서 비디오와 행동이 서로 강하게 영향을 줘야 하는 경우에는 덜 자연스럽습니다.
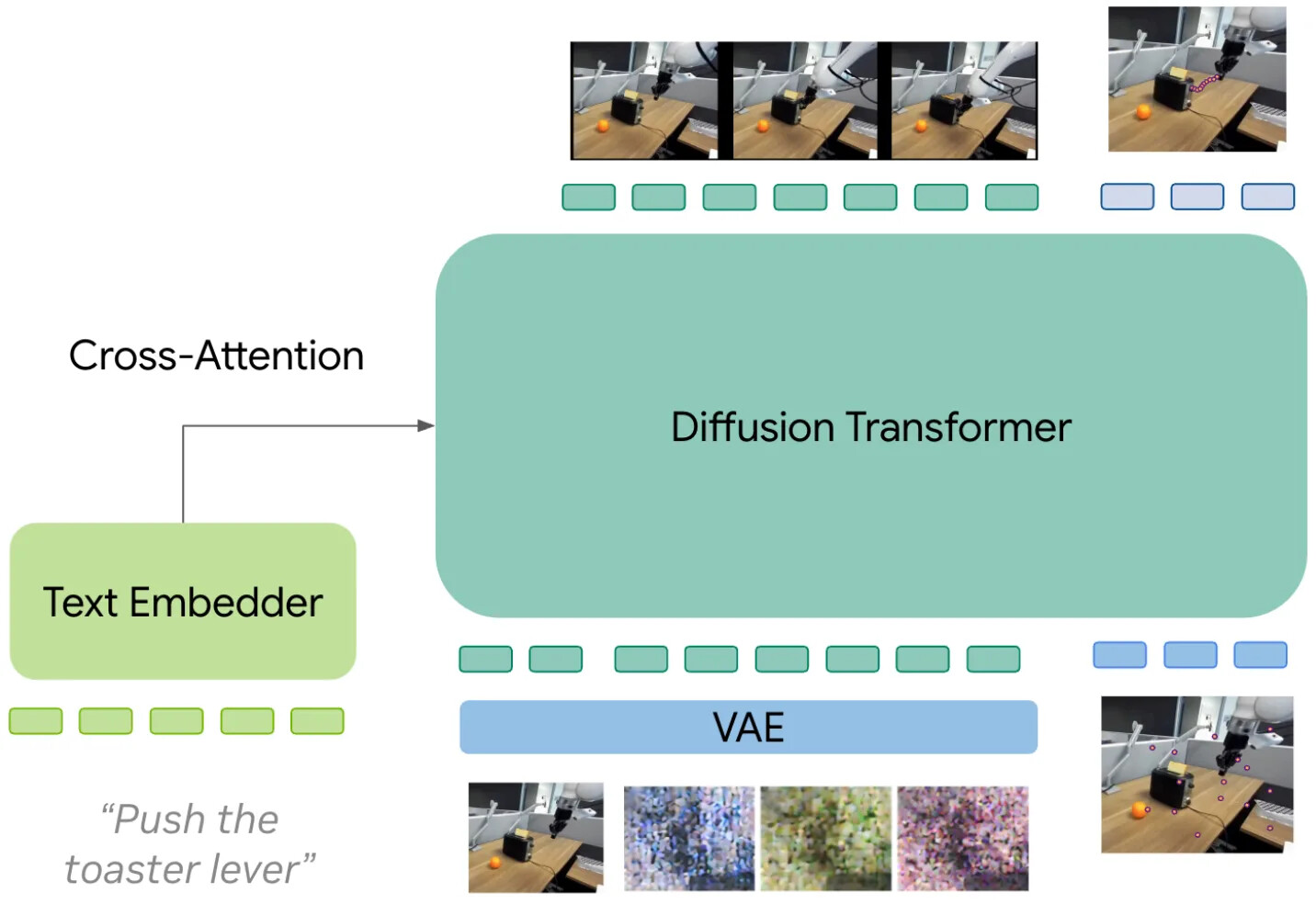
모놀리식 트랜스포머(Monolithic Transformer) 는 DreamZero처럼 비디오와 행동 디노이징을 같은 스택에 넣어 두 스트림 사이에 강한 결합을 제공합니다. 행동과 영상이 이미 같은 잠재 공간에 사는 Cosmos Policy 같은 "행동을 이미지로" 셋업에 자연스럽게 들어맞습니다. 위험은 이중 최적화입니다. 같은 모델 가중치가 조밀한 시각 토큰과 훨씬 희소한 행동 타깃을 모두 다뤄야 합니다.
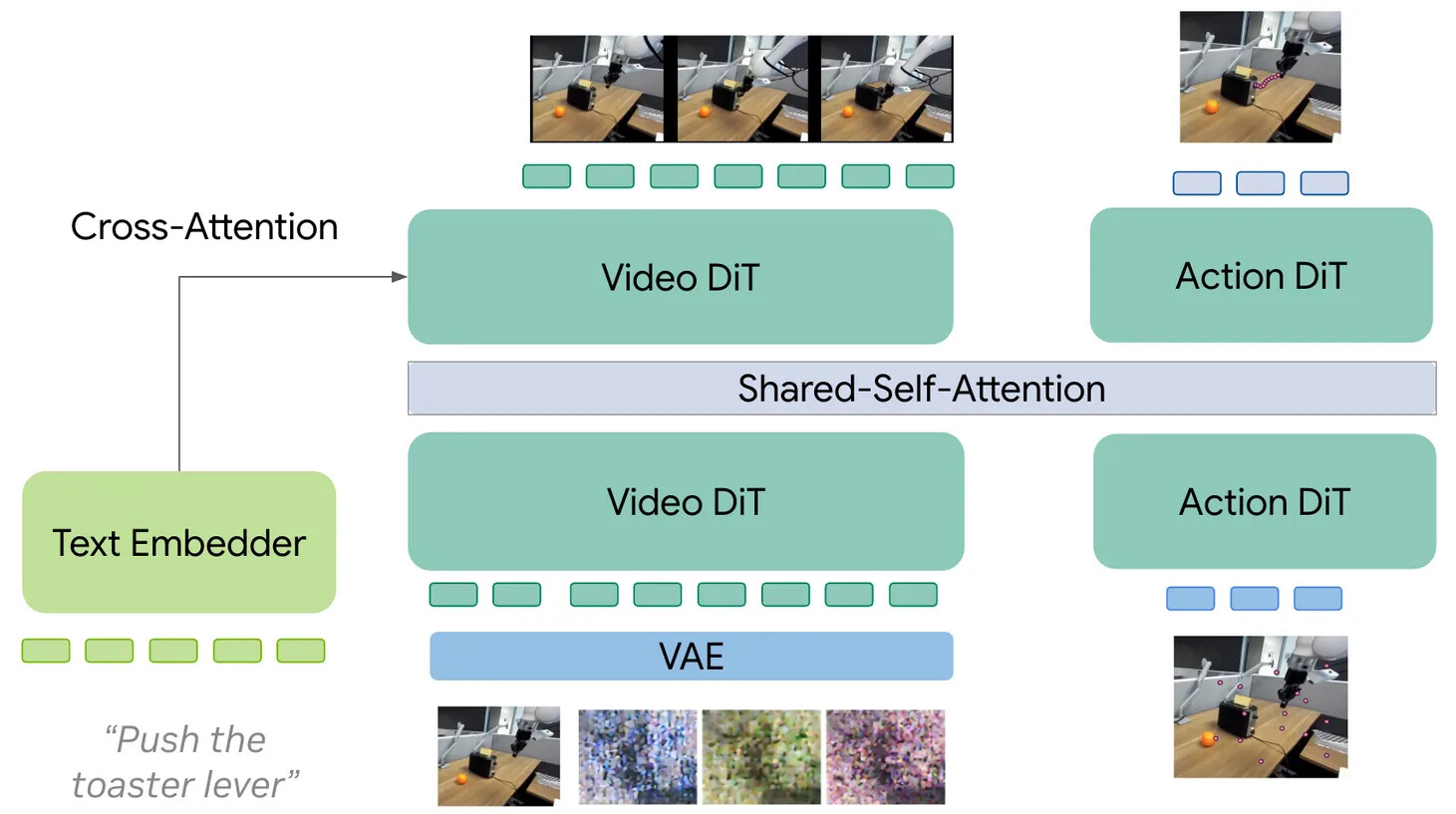
Mixture-of-Transformers(MoT) 는 현재의 기본값으로, 현대 VLA(Pi-0, Pi-0.5)와 LingBot-VA, Fast-WAM 같은 최근 WAM에 모두 쓰입니다. 모달리티별 파라미터가 표현을 분리하면서도 공유 어텐션이 비디오와 행동의 정보 교환을 허용합니다. 저자는 모듈성과 결합 사이의 실용적 타협이라는 이유로 MoT 스타일 설계가 WAM에서도 지배적 아키텍처가 될 것으로 추측합니다.
WAM은 왜 지금 떠올랐는가
저자의 짧은 답은 "아이디어는 새롭지 않았지만, 사전학습된 비디오 모델 같은 필요한 도구가 마침내 따라잡았기 때문"입니다. 초기 형태들(역동역학의 UniPi, 공동 예측의 GR-1, 잠재 추상화의 Play-LMP)은 올바른 아이디어를 가졌지만 도구가 제한적이었습니다. 작은 백본, 약한 비디오 데이터, 공개된 비디오 파운데이션 모델의 부재, 현대 행동 청크 정책에 비해 잘 작동하지 않던 스텝별 행동 헤드 등입니다.
첫째, 비디오 백본이 훨씬 강해졌습니다. Wan과 Cosmos 같은 DiT 기반 모델이 더 나은 시간적 압축, 플로우 매칭 목적, 잘 큐레이션된 웹 규모 비디오 데이터로 이전 CNN 기반 스택을 대체했습니다. 둘째, 그 백본들이 공개되었습니다. 연구자는 이제 전체 사전학습 비용을 직접 치르는 대신 강력한 사전학습 비디오 모델을 미세조정할 수 있습니다. 셋째, 행동 쪽이 따라잡았습니다. 현대 시스템은 작은 스텝별 MLP 헤드 대신 트랜스포머나 플로우 매칭 헤드로 행동 청크를 예측합니다. 그래서 WAM이 이제는 더 나은 브랜딩을 입힌 옛 아이디어가 아니라 진짜 레시피처럼 보이는 것입니다.
WAM 비교 표
아래 표는 앞에서 다룬 모델들을 여러 설계 결정에 따라 분류합니다. WAM 공간은 빠르게 움직이므로 선별된 일부일 뿐입니다.
| 모델 | 패러다임 | 행동 통합 | 백본 | 아키텍처 | 연도 |
|---|---|---|---|---|---|
| Play-LMP | (pre-WAM) | 잠재 계획 | Transformer + LSTM | 계층형 | 2019 |
| UniPi | 역동역학 | 기본 행동 토큰 | CNN 비디오 디퓨전(1.7B) | 계층형 | 2023 |
| GR-1 | 공동 예측 | 기본 행동 토큰 | Transformer(scratch) | 통합 트랜스포머 | 2024 |
| GENIMA | 역동역학 | 행동을 이미지로 | Stable Diffusion / ControlNet | 계층형 | 2024 |
| Seer | 역동역학 | 기본 행동 토큰 | 시각/행동 토큰 위 Transformer | 통합 트랜스포머 | 2025 |
| VPP | 역동역학 | 기본 행동 토큰 | Stable Video Diffusion | 계층형 | 2025 |
| mimic-video | 역동역학 | 기본 행동 토큰 | Video Diff(Cosmos) | 계층형 | 2025 |
| DreamZero | 공동 예측 | 기본 행동 토큰 | Video Diff(Wan 14B) | 모놀리식 DiT | 2026 |
| LingBot-VA | 역동역학 | 기본 행동 토큰 | Video Diff(Wan 2.2-5B) | MoT | 2026 |
| Cosmos Policy | 공동 예측 | 행동을 이미지로 | Video Diff(Cosmos) | 모놀리식 DiT | 2026 |
| Being-H0.7 | 공동 예측(잠재) | 잠재 계획/행동 | MoT transformer | MoT | 2026 |
| Fast-WAM | 표현 전용 | 기본 행동 토큰 | Video Diff(Wan 5.5B) | MoT | 2026 |
역동역학과 잠재 행동 더 알아보기
Video Prediction Policy - ICML 2025, 예측 시각 표현으로 행동을 조건화하는 일반화 로봇 정책
Latent Action Pretraining from Videos(LAPA) - 레이블 없는 영상에서 잠재 행동을 학습
Genie: Generative Interactive Environments - ICML 2024, 인터넷 영상에서 잠재 행동 토큰을 학습
NVIDIA Cosmos 3: 물리 추론과 월드 생성, 행동 생성을 하나로 통합한 피지컬 AI 오픈 모델
실전 고려사항: 비디오 사전 지식의 비용과 추론 속도
강한 비디오 사전 지식은 일부 상황에서 로보틱스 데이터 요구량을 줄여줄 수 있고, Wan 같은 현대 비디오 모델을 쓰면 강한 제로샷 성능까지 얻을 수 있습니다. 그러나 실전에서 이것은 흔히 로봇 데이터 효율을 연산 비용과 맞바꾸는 거래 입니다. 저자는 이를 거칠게 비교하기 위해 조밀 트랜스포머 하한 추정 C_{\text{train}} \approx 6 \times N \times T($N$은 학습 가능 파라미터, $T$는 처리 토큰 수)를 사용하고, 결과를 ZFLOP(1\text{ ZFLOP} = 10^{21} FLOP) 단위로 보고합니다(정밀한 예산이 아니라 논문 간 대략적 비교로 보아야 합니다).
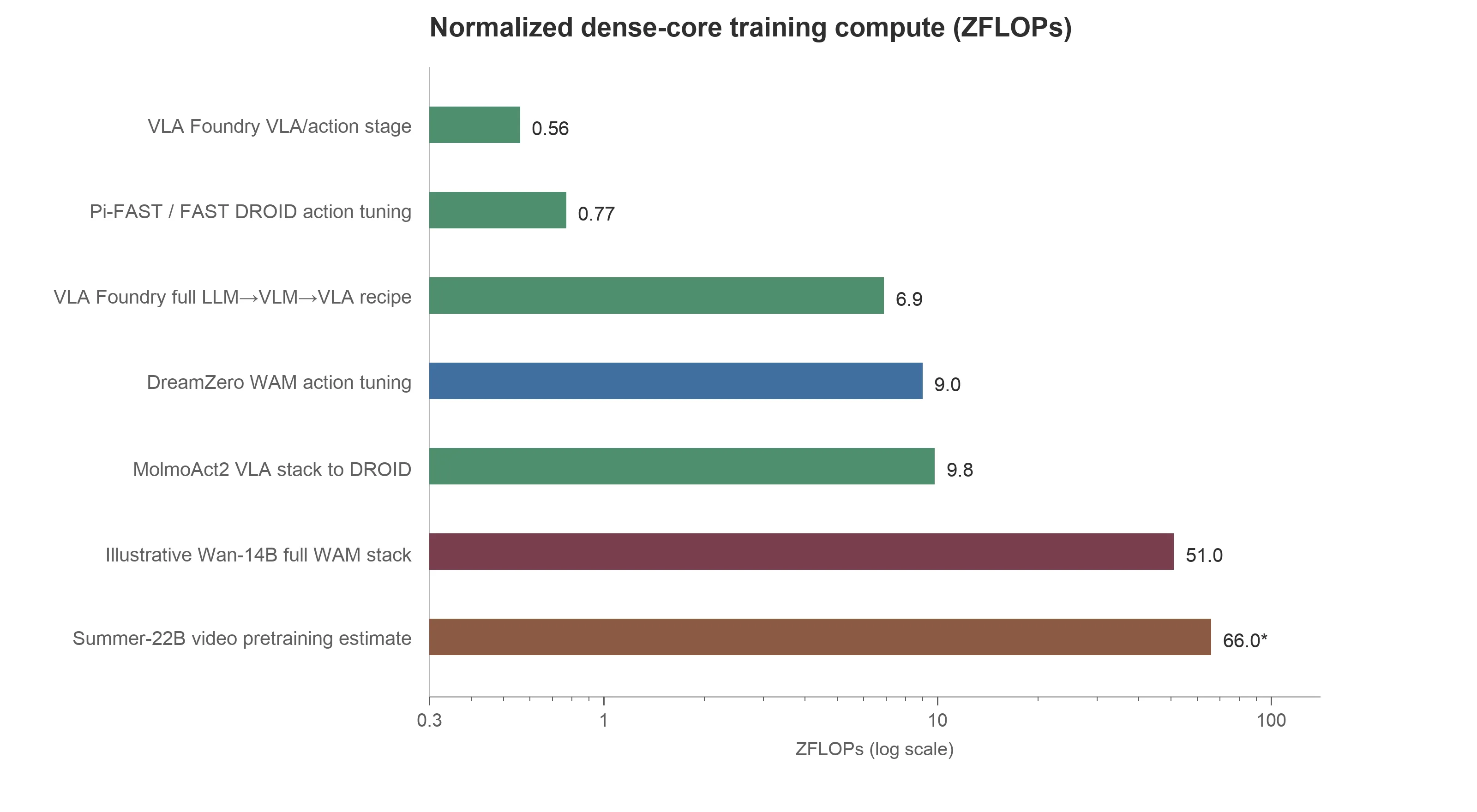
VLM 기반 VLA는 학습의 두 단계 모두에서 더 저렴한데, 시퀀스가 더 짧기 때문입니다. VLA는 한두 장의 이미지와 텍스트를 인코딩한 뒤 텍스트나 짧은 행동 토큰 시퀀스를 예측합니다. 반면 WAM은 비디오 잠재 토큰 시퀀스에 행동 토큰을 더해 예측하는데, 비디오 토큰 시퀀스는 VLA 시퀀스보다 흔히 약 10배 길어 같은 데이터셋으로 학습해도 기본 VLA 학습보다 비쌉니다.
| 비교 항목 | 무엇을 세는가 | 추정 연산량 |
|---|---|---|
| VLA Foundry 소형 from-scratch 레시피 | 언어 사전학습 + VLM 학습 + VLA/행동 학습 전체(1~2B 오픈 레시피) | 약 6.9 ZFLOP |
| DreamZero WAM 행동 튜닝 | 사전학습된 Wan-14B 비디오 백본의 다운스트림 적응만 | 약 8.6~9.0 ZFLOP |
| MolmoAct2 VLA 스택 to DROID | Molmo2-ER에서 DROID 체크포인트까지의 보고된 전체 | 약 9.8 ZFLOP 상당 |
| Summer-22B 비디오 사전학습 | 22B 모델을 약 500B 비디오 토큰으로 from-scratch 학습 | 약 66 ZFLOP |
| 예시 Wan-14B 풀 WAM 스택 | Wan 규모 비디오 사전학습 + DreamZero식 행동 튜닝 | 약 51 ZFLOP |
| UniPi from-scratch 비디오 사전학습 | Imagen Video 시대 CNN 비디오 디퓨전을 처음부터 학습 | 약 167 ZFLOP |
여기서 핵심 통찰이 드러납니다. DreamZero의 행동 튜닝 자체는 약 9 ZFLOP(약 8,400 H100-시간, 1\text{ ZFLOP} \approx 936 H100-시간)으로, 이는 Wan 백본을 만드는 비용이 아니라 그 위에 행동을 입히는 다운스트림 적응 비용일 뿐입니다. 만약 비디오 백본을 처음부터 학습해야 한다면, Summer-22B 규모의 비디오 사전학습은 약 66 ZFLOP이며 이를 Wan의 14B 크기로 줄여도 비디오 모델과 WAM 단계를 합쳐 약 51 ZFLOP에 이릅니다. 효율적인 VLA Foundry 레시피의 6.9 ZFLOP과 비교하면 약 7.4배의 격차 입니다. UniPi처럼 비디오 파운데이션 모델을 처음부터 사전학습해야 했던 초기 WAM이 약 167 ZFLOP으로 대부분의 로보틱스 연구실에 사실상 금지된 비용이었던 것과 같은 맥락이며, 현대 WAM이 Wan 같은 오픈 사전학습 비디오 모델에서 출발해 이 10^{23} FLOP 규모의 사전학습 단계를 건너뛸 수 있게 된 것이 결정적 변화입니다.
총 FLOP을 넘어 하드웨어와 엔지니어링 장벽도 있습니다. 약 8k 토큰 행동 튜닝 시퀀스를 다루는 14B 모델은 상당한 GPU 메모리와 고속 인터커넥트를 갖춘 다중 노드 셋업을 요구하며, 성공적인 비디오 모델 학습은 견고한 데이터 필터링, 캡셔닝, 비디오 디코딩, 잠재 전처리, 분산 I/O, 긴 시퀀스 DiT 인프라에 의존합니다. 같은 논증의 데이터 품질 버전도 있습니다. DreamZero는 더 강한 비디오 생성이 더 강한 정책 성능으로 이어진다고 주장하므로, WAM은 연산뿐 아니라 비디오 데이터 품질에도 굶주린 모델입니다. 필터링, 캡셔닝, 잠재 표현, 생성 사전학습이 모두 정책 레시피의 일부가 됩니다. 반면 VLM4VLA는 VLM 초기화가 from-scratch 대비 도움이 되지만 일반적 VLM 능력은 다운스트림 VLA 성능을 잘 예측하지 못하며, VLA에는 공간(spatial) 목적이 다른 시각 능력보다 훨씬 중요하다고 보고합니다.
추론 속도: 실시간 제어의 걸림돌
전반적으로 VLM 기반 VLA도 항상 빠른 것은 아니지만, 테스트 시 비디오 생성을 하는 기본 WAM 셋업은 더욱 느려질 수 있습니다. Fast-WAM의 대표값을 보면, 전체 비디오 생성을 동반하는 두 가지 일반적 WAM 추론 모드(공동 예측, 역동역학)는 행동 청크당 590ms에서 800ms가 걸리는 반면 Pi-0.5는 약 190ms입니다. 즉 추론 시점에 3~4배 느려지는 것 으로, 실시간 제어에 큰 영향을 줍니다. DreamZero 논문이 보인 방법이나 Fast-WAM처럼 비디오 생성을 완전히 건너뛰는 접근으로 속도를 높일 수 있지만, 대형 GPU 없이 이 모델들을 로컬에서 돌리는 것은 여전히 어렵습니다.
현대 VLA 베이스라인이 여전히 중요한 이유
현대 VLM 기반 VLA도 빠르게 개선되었고, 가장 강력한 베이스라인은 이제 네 가지 아이디어를 결합합니다. 이산 행동 토큰화, VLM을 보존하는 공동 학습, 격리된 행동 헤드, 그리고 훨씬 넓은 데이터 혼합입니다. 비디오 백본이 더 나은 기본값이라는 어떤 주장도 이 현재의 SOTA 레시피를 이겨야 합니다.
VLA 아키텍처는 하나의 기본 셋업으로 수렴했습니다. 비전에서 Transfusion이 도입하고 로보틱스에서 Pi-0가 대중화한 MoT 레시피입니다. 바뀐 것은 주로 학습 레시피입니다. 첫째, 많은 현대 VLA는 FAST나 BEAST 같은 이산 토크나이저로 행동을 VLM이 배울 수 있는 새로운 종류의 언어로 표현합니다. VLM은 교차 엔트로피 손실로 이산 다음 토큰 예측을 사전학습하는 반면 로봇 행동은 보통 플로우 매칭으로 모델링되는 연속 공간에 살기 때문에, 플로우 매칭 목적으로 VLM을 순진하게 미세조정하면 사전학습된 언어/시각 능력의 파국적 망각이 일어납니다. 이산 행동 토큰화 공동 학습은, 흔히 플로우 매칭 헤드의 격리된 그래디언트와 결합되어 이 문제를 우회합니다. VLM은 선호하는 이산 공간에 가깝게 머무르며 체화 제어에 유용한 표현을 배우고, 플로우 매칭 헤드는 그 특징에 조건화되어 자신의 행동 예측을 수행합니다. 테스트 시점에는 별도 행동 헤드를 가진 시스템이 느린 자기회귀(autoregressive) 행동 토큰 예측 경로를 버리고 행동 헤드가 직접 일하게 할 수 있습니다.
이 파국적 망각 문제의 영향을 직관적으로 보려면 RoboArena 스냅샷을 다시 봅시다. Pi-FAST는 Pi-0-DROID와 같은 백본을 쓰지만 플로우 컴포넌트 없이 이산 FAST 토큰으로 행동을 생성합니다. 둘 다 DROID에 미세조정되었는데, Pi-FAST는 1592점에 도달하고 Pi-0은 1475점에 그칩니다. 이는 이산 행동 레시피가 원래 Pi-0의 플로우 기반 셋업보다 더 유용한 사전학습 능력을 보존할 수 있다는 견해를 뒷받침합니다. 둘째, Pi-0.5 스타일 시스템은 VLM 데이터와 로보틱스 데이터를 공동 학습하면서 VLM과 행동 컴포넌트 사이의 그래디언트를 격리해 더 빠르고 안정적인 수렴을 얻습니다. Pi-0.5는 RoboArena에서 Pi-FAST와 Pi-0을 모두 넉넉한 차이로 앞섭니다(1622 vs 1592 vs 1475).
이런 레시피 개선에도 VLA는 여전히 그라운딩 벽에 부딪힙니다. 언어는 행동의 목표를 표현하기에 충분히 명세적이지 않은 방식입니다. 어수선한 장면에서 텍스트 명령은 관련 물체 인스턴스나 원하는 물리적 상태를 거의 특정하지 못하므로, 정책은 배경 물체 같은 가짜 상관관계나 데이터셋 편향에 과적합할 수 있습니다. Pi-0.7이 보고한 언어 전용 프롬프팅과 목표 이미지 조건화 사이의 격차는 이 견해를 뒷받침합니다. 시각적 서브골이 언어 추종을 개선하고 학습을 더 빨리 수렴시키는 것입니다. 같은 RoboArena 스냅샷에서 DreamZero가 기록한 1750점도 비디오/이미지 목표 사전 지식이 이런 종류의 문제에 도움이 될 수 있다는 또 다른 논거입니다. 그래서 현재 WAM과 VLA 사이에 진짜 승자는 없으며, 과연 언젠가 하나가 나올지도 의문입니다. Zhang et al.의 첫 비교는 LingBot-VA, Cosmos Policy, Pi-0.5를 매칭된 교란 아래 LIBERO-Plus와 RoboTwin 2.0-Plus에서 벤치마크했는데, WAM이 VLA 베이스라인의 넓은 학습 데이터 혼합 없이도 강한 견고성에 도달할 수 있음을 보였습니다. 다만 이 비교는 시뮬레이션 환경에 한정되며 실세계 일반화는 다루지 않습니다.
두 갈래의 길은 사실 하나인가: 하이브리드의 부상
열린 질문은 장기적으로 두 경로가 과연 구분된 채로 남을 것인가입니다. 일부 최근 VLA는 더 나은 목표 추종을 위해 이미 월드 모델 스타일 컴포넌트를 사용하고(Pi-0.7), 많은 최근 WAM은 행동 전문가를 위해 VLA의 MoT 레시피를 빌려옵니다. 로봇 파운데이션 모델의 미래는 둘의 혼합으로 보입니다.

이 방향의 첫 신호는 Motus와 BagelVLA 같은 최근 연구에서 이미 나타납니다. 언어와 영상 중 무엇이 로보틱스의 주 표현이어야 하는지 결정하는 대신, 모든 것을 하나의 모델로 학습합니다.
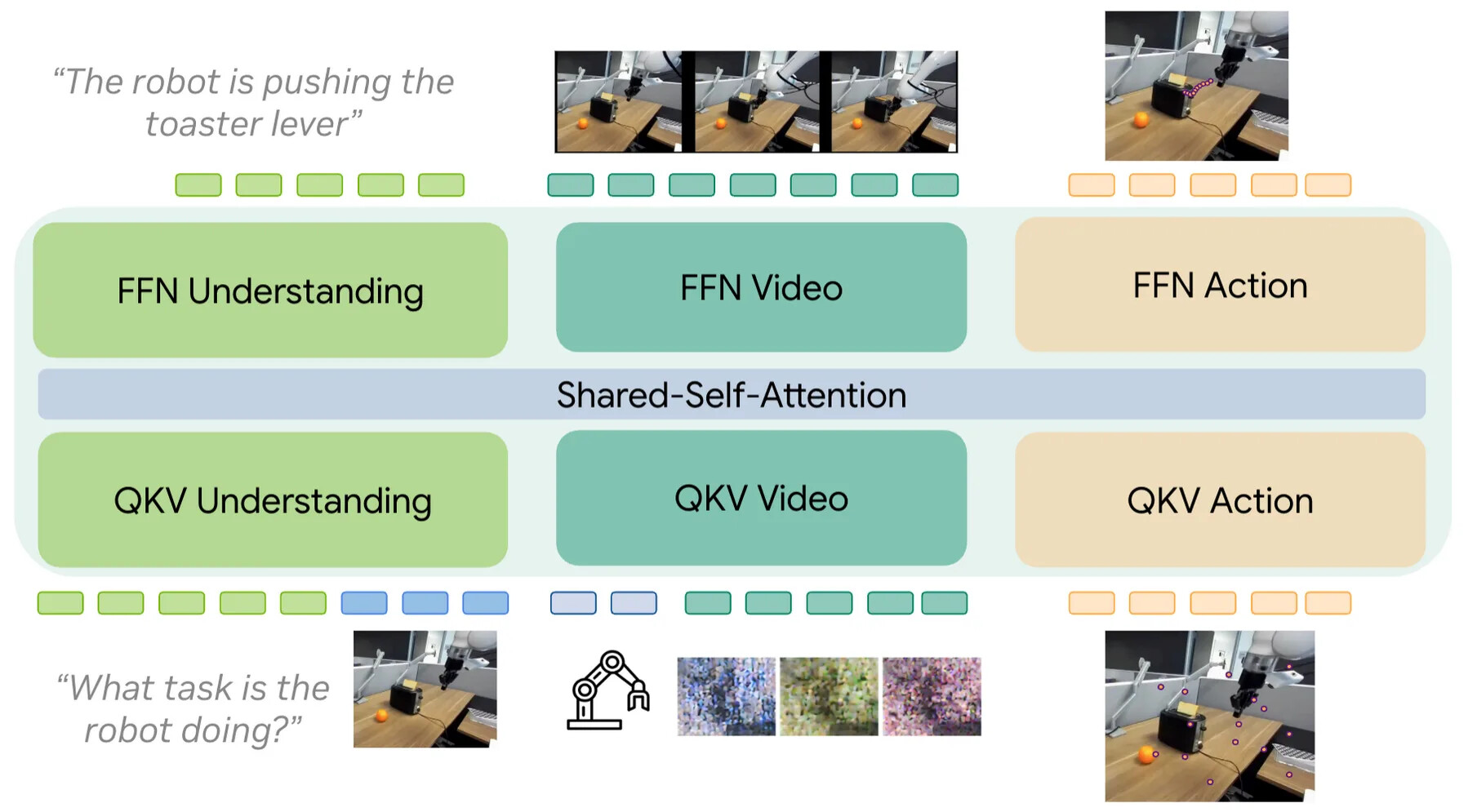
이해/VLM 컴포넌트, 비디오 생성 컴포넌트, 행동 전문가 각각이 특화된 가중치를 가지면서 공유 셀프 어텐션으로 정보를 교환하는 구조입니다. 이 하이브리드의 계층형 버전은 Physical Intelligence의 Pi-0.7에도 나타납니다. 행동 전문가가 BAGEL 기반 월드 모델이 테스트 시 생성한 시각적 서브골에 조건화되는 조종 가능한(steerable) VLA입니다. 고수준 정책이 서브태스크 명령을 내고, 월드 모델이 그 명령을 서브골 이미지로 바꾸며, 행동 전문가가 현재 관측과 그 서브골에 조건화되어 실행합니다. 보고된 절제 실험은 월드 모델 서브골을 추가하면 복잡한 참조 과제에서 명령 추종이 개선되고, 일부 데이터셋 편향을 깨는 과제에는 필수적임을 보여줍니다.
Sereact의 Cortex 2.0은 이 하이브리드 방향을 가리키는 또 다른 스타트업 사례입니다. 시각 잠재 공간에서 후보 미래 궤적을 생성하고, 예상 진행도, 위험, 효율로 점수를 매긴 뒤, 가장 높은 점수의 롤아웃에 실행을 조건화하는 월드 모델을 더합니다. 이는 WAM 스타일의 예지(foresight)가 배포된 조작 시스템 안의 계획 레이어가 되고 있다는 산업적 신호입니다. Being-H0.7은 파운데이션 모델 하이브리드의 가장 좋은 예로, 사전학습된 VLA Being-H0.5 위에 세워진 잠재 계획 스타일 WAM/VLA이며 InternVL3.5를 이해 전문가로, Qwen3를 행동 전문가로, V-JEPA 2 시각 인코더를 사용합니다.
네 번째 길: 로보틱스 우선 파운데이션 모델
네 번째 가능성은 로보틱스 우선 파운데이션 모델(Robotics-First Foundation Model, RFFM) 입니다. 웹 VLM이나 비디오 생성기에서 출발해 나중에 행동을 붙이는 대신, 체화, 행동, 접촉이 풍부한 상호작용, 체화된 기억 같은 로보틱스 난제를 중심으로 설계된 대형 트랜스포머입니다. 저자가 아는 가장 깔끔한 예는 Generalist AI의 GEN-1으로, 50만 시간의 UMI 스타일 웨어러블 데이터로 사전학습된 대형 로봇 행동 모델입니다. 이 방향의 핵심 문제는 접근성입니다. 자금이 풍부한 스타트업과 대기업 밖에서는 이런 대규모 인간/로봇 데이터에 접근할 수 있는 곳이 거의 없어, 대규모 오픈소스 로보틱스 데이터가 나오기 전까지 커뮤니티에는 막혀 있는 경로입니다.
직교하는 방향으로 주목할 만한 것은 V-JEPA 2 같은 잠재 월드 모델입니다. 사전학습된 잠재 공간 안에서 영상으로부터 직접 잠재 동역학을 학습하여, 디퓨전 기반 비디오 생성보다 더 저렴한 롤아웃과 빠른 추론, 깔끔한 계획 신호를 약속합니다. 이 방향의 첫 WAM인 VLA-JEPA나 Being-H0.7이 유망한 성능을 보고하고 있습니다.
맺으며: WAM은 어디에 서 있는가
WAM은 로봇 파운데이션 모델의 핵심 연구 하위 분야가 될 것입니다. VLA가 대체로 공유된 레시피(VLM 백본, 플로우 매칭을 갖춘 그래디언트 격리 행동 전문가, 넓은 웹/로보틱스 혼합 공동 학습)로 수렴한 반면, WAM은 여전히 탐색 단계에 있습니다. 논문마다 비디오 백본, 정책 형태, 학습 레시피, 평가 셋업이 크게 다릅니다. 그 연구 다양성은 젊은 분야에 건강하지만, 무엇이 가장 잘 작동하는지는 아직 아무도 모릅니다. 저자는 세 가지 결론으로 글을 정리합니다.
명령에서 동작까지의 간극은 여전히 열려 있습니다. 이산 행동 토큰화, VLM 보존 공동 학습, 넓은 데이터 혼합을 갖춘 현대 VLA도 이를 완전히 닫지 못합니다. WAM은 이 간극을 영상 쪽에서 공략하겠다고 약속하지만, 현재 결과가 그것을 풀었음을 보이지는 못합니다.
로봇 벤치마킹은 여전히 핵심 과제입니다. 현대 VLA와 WAM 벤치마킹은 해결되지 않았습니다. 좋은 점수를 받으려면 제대로 된 정책 일반화가 필요하도록 벤치마크 해킹을 어렵게 만드는 RoboLab이나 MolmoSpaces 같은 벤치마크가 더 필요합니다.
다음 세대 로봇 파운데이션 모델은 WAM+VLA 하이브리드일 가능성이 높습니다. Pi-0.7의 BAGEL 서브골, Cortex 2.0의 예지 기반 계획, Being-H0.7의 잠재 사전/사후 다리, Motus와 BagelVLA 스타일 하이브리드가 이미 VLA와 WAM의 사고를 합치고 있습니다. 더 많고 더 좋은 오픈소스 로보틱스 데이터에 접근하게 되면, 처음부터 학습된 첫 로봇 파운데이션 모델도 또 다른 유력한 베팅입니다.
 Pretrained to Imagine, Fine-Tuned to Act 원문 블로그
Pretrained to Imagine, Fine-Tuned to Act 원문 블로그
더 읽어보기
-
Google DeepMind, Gemini 기반 VLA(Vision-Language-Action) 모델 Gemini Robotics 출시
-
SmolVLA: 커뮤니티 데이터로 학습한 소규모(450M) 오픈소스 시각-언어-행동(Vision-Language-Action) 로봇 모델 (feat. Hugging Face)
-
gWorld: Trillion Labs가 공개한, 실행 가능한 코드로 모바일 세상을 시뮬레이션하는 생성형 월드 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()