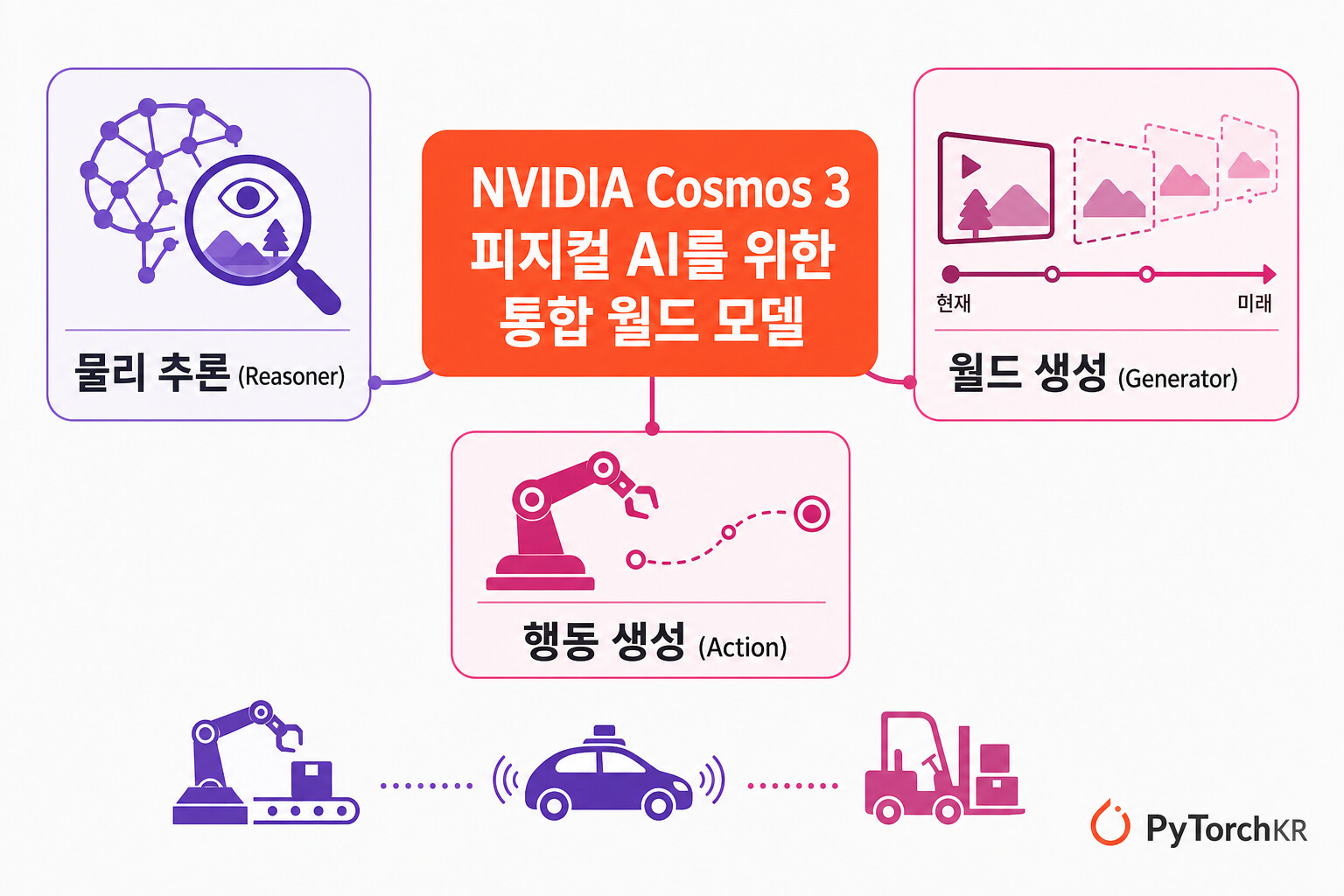
NVIDIA Cosmos 3 소개
로봇, 자율주행차, 스마트 공간처럼 물리 세계에서 직접 행동해야 하는 인공지능을 흔히 피지컬 AI(Physical AI) 라고 부릅니다. 이런 시스템은 화면 안에서 텍스트를 주고받는 데서 그치지 않고, 지금 눈앞에서 무슨 일이 벌어지고 있는지를 이해하고, 다음 순간 어떤 일이 벌어질지를 예측하며, 특정 환경과 신체(embodiment), 과제에 맞는 행동을 생성할 수 있어야 합니다. 문제는 이 세 가지 능력(이해, 예측, 행동)이 그동안 서로 다른 모델과 파이프라인으로 흩어져 있었다는 점입니다. 장면을 해석하는 비전 언어 모델, 미래 영상을 만들어내는 영상 생성 모델, 로봇의 동작을 출력하는 정책(policy) 모델을 따로 학습하고 따로 배포한 뒤, 그것들을 묶어 하나의 시스템으로 엮는 일은 개발자에게 적지 않은 부담이었습니다.
NVIDIA Cosmos 3는 이 세 가지를 하나의 오픈 파운데이션 모델 안에서 통합한 피지컬 AI 모델입니다. 물리 추론(physical reasoning), 월드 생성(world generation), 행동 생성(action generation) 을 단일 모델에서 처리하며, 텍스트와 이미지, 영상, 오디오, 행동(action) 시퀀스를 함께 입력받고 출력할 수 있는 옴니모달(omnimodal) 구조를 가집니다. 이전 Cosmos 릴리스가 월드 생성, 물리 이해, 제어된 장면 생성을 각각 별도의 모델로 다뤘던 것과 달리, Cosmos 3는 이를 하나의 아키텍처로 합쳐 비전 언어 모델, 영상 생성기, 월드 시뮬레이터, 월드 액션 모델을 사실상 하나의 틀 안에 포섭했습니다.
특히 주목할 점은 개방성입니다. NVIDIA는 2026년 5월 31일, 모델 체크포인트뿐 아니라 학습 스크립트, 배포 도구, 그리고 여섯 개의 합성 데이터셋까지 함께 공개하여 피지컬 AI 개발을 더 열린 형태로, 재현 가능한 형태로 만들고자 했습니다. 모델과 소스 코드는 비교적 관대한 OpenMDW-1.1 라이선스로 배포됩니다. 공개 직후 Cosmos 3는 월드 추론과 월드 생성을 아우르는 여덟 개 이상의 오픈 모델 리더보드에서 1위를 차지했는데, 연구를 이끈 Ming-Yu Liu는 이를 두고 "수개월의 작업 끝에 맞이한 순간이 비현실적으로 느껴진다" 고 밝히기도 했습니다.
하나의 모델, 두 개의 타워: Mixture-of-Transformers 아키텍처
Cosmos 3를 이해하는 출발점은 아키텍처입니다. 이 모델은 Mixture-of-Transformers(MoT) 구조 위에 두 개의 타워(tower) 를 세운 형태입니다. 하나는 세계를 이해하는 추론 타워(Reasoner tower), 다른 하나는 미래를 만들어내는 생성 타워(Generator tower) 입니다.
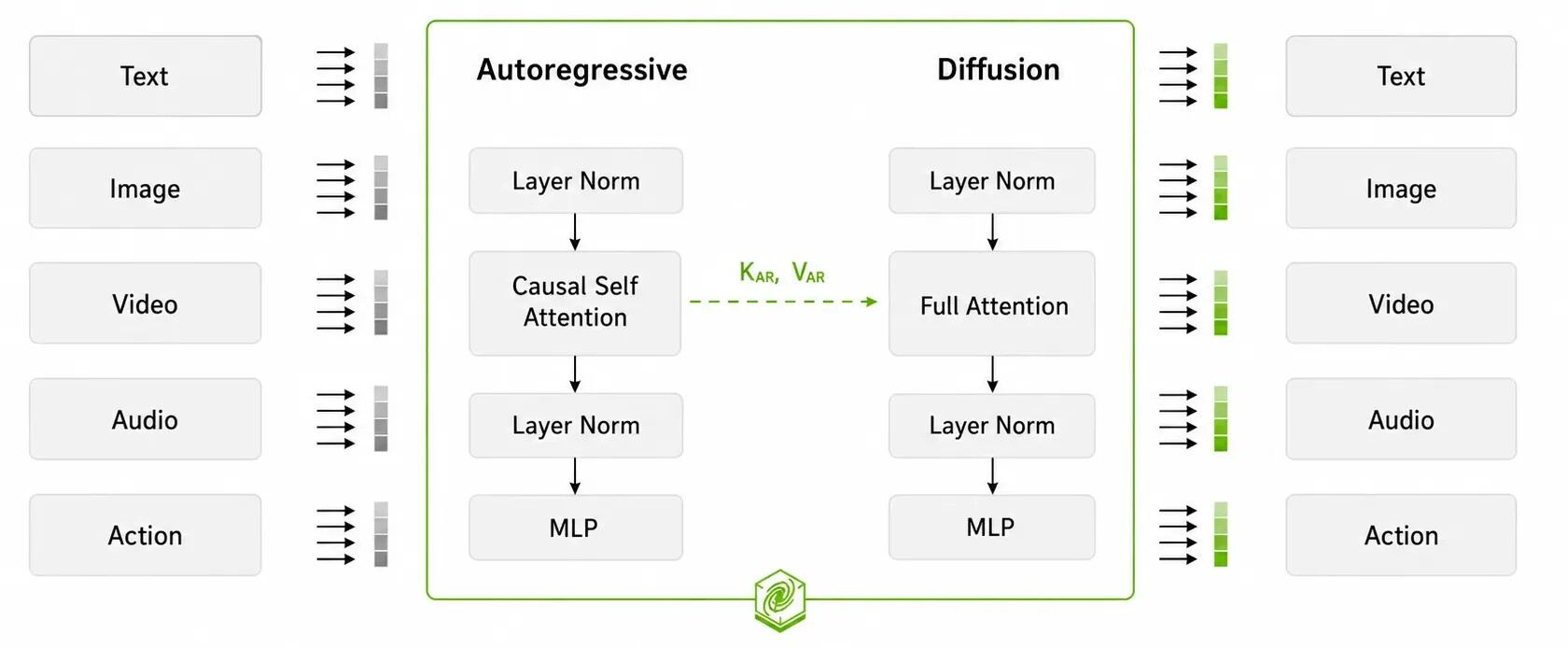
추론 타워 는 이미지와 영상, 텍스트 같은 멀티모달 관찰을 해석하는 비전 언어 모델(Vision-Language Model) 입니다. 이 타워는 자기회귀(Autoregressive, AR) 구조를 사용해 입력을 해석하고, 움직임과 물체 간 상호작용, 그 밖의 물리적 맥락을 이해합니다. 즉, 어떤 생성이 일어나기 전에 세계에 대해 먼저 추론하는 '두뇌' 역할을 맡습니다.
생성 타워 는 미래의 관찰과 행동 시퀀스를 만들어냅니다. 이 타워는 디퓨전(diffusion) 기반 과정을 통해 추론 타워의 이해에 조건화된, 물리 법칙을 인식하는 영상과 행동을 생성합니다. 추론 타워는 단독으로 호출할 수 있지만, 생성 타워는 항상 두 타워를 함께 활성화하여 안내된(guided) 생성을 수행합니다.
두 모드는 같은 트랜스포머 아키텍처와 멀티모달 어텐션 레이어, 그리고 공간과 시간 구조를 함께 인코딩하는 통합 3D 회전 위치 임베딩(3D multi-dimensional rotary position embedding, mRoPE)을 공유합니다. 추론 모드에서는 언어와 시각 이해 토큰이 인과적 자기 어텐션(causal self-attention) 을 거쳐 다음 토큰을 예측하는 방식으로 지각과 계획, 월드 추론을 수행합니다. 생성 모드에서는 잡음이 섞인 이미지, 영상, 오디오, 행동 토큰을 풀 어텐션(full attention) 으로 노이즈 제거하여 여러 모달리티를 일관되게 함께 생성합니다.
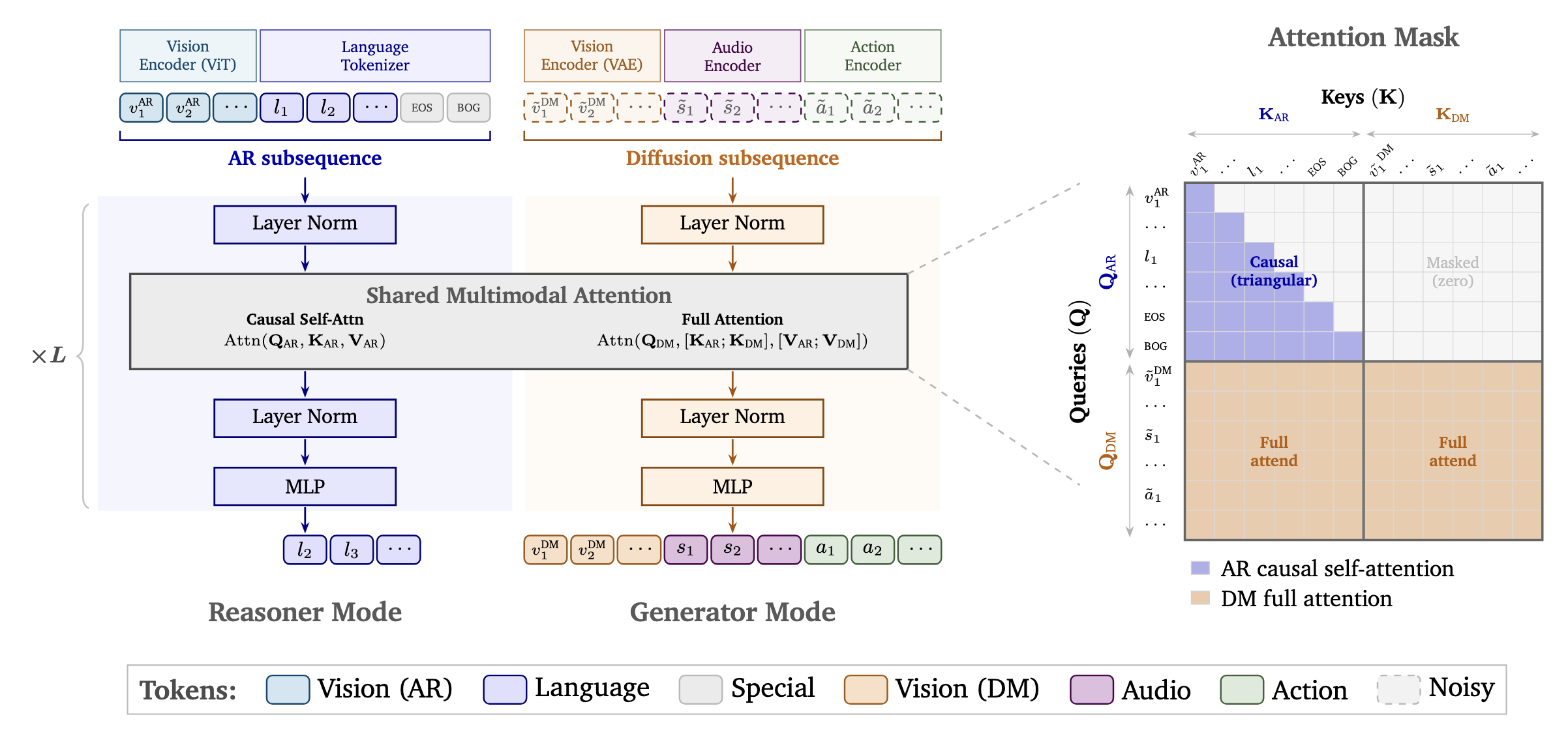
위 그림에서 볼 수 있듯, 추론 경로는 삼각형 형태의 인과적 마스크(causal triangular mask)로 과거 토큰만 보도록 제한되는 반면, 생성 경로는 풀 어텐션으로 모든 토큰을 참조합니다. 추론 타워에서 계산된 키와 값(K_{AR}, V_{AR})이 생성 타워로 단방향으로 흘러 들어가면서, 모델은 "먼저 이해하고, 그 이해에 기반해 생성한다"는 흐름을 자연스럽게 구현합니다. 이렇게 하나의 모델이 추론과 생성을 모두 담당하기 때문에, 여러 모델 사이의 오케스트레이션과 별도 추론 파이프라인이 사라지고 개발이 단순해집니다.
아키텍처 더 알아보기
Cosmos 3 Technical Report - "통합 MoT 아키텍처와 학습 방법의 상세 기술 보고서"
NVIDIA Cosmos Research Lab
GitHub Repository
두 개의 런타임 표면: Reasoner와 Generator
Cosmos 3는 사용자에게 두 개의 런타임 표면(runtime surface)을 노출합니다. 하나의 모델 안에 들어 있지만, 무엇을 입력하고 무엇을 출력하느냐에 따라 다른 얼굴을 보여주는 셈입니다.
| 표면 | 입력 | 출력 | 주요 활용 |
|---|---|---|---|
| Reasoner | 텍스트, 비전 | 텍스트 | 월드 이해, 그라운딩, 물리 추론, 과제 계획, 행동 예측, 체화 에이전트 추론 |
| Generator | 텍스트, 비전, 사운드, 행동 | 비전, 사운드, 행동 | 월드 생성, 월드 시뮬레이션, 미래 예측, 합성 데이터 생성, 정책 학습, 로봇 훈련 |
이 두 표면은 다시 세 가지 핵심 능력으로 정리할 수 있습니다.
-
월드 이해(World understanding): 영상과 이미지를 분석하여 캡션, 시간적 이벤트, 다음 행동, 공간 그라운딩, 물리적 타당성(physical plausibility), 인과적 결과를 도출합니다.
-
월드 생성(World generation): 텍스트, 이미지, 영상, 행동 입력으로부터 이미지와 영상, 동기화된 사운드, 그리고 행동에 조건화된 롤아웃(rollout)을 생성합니다.
-
행동 모델링(Action modeling): 로봇, 카메라 움직임, 자기중심(egocentric) 움직임, 자율주행 환경에서의 정책 행동, 역동역학(inverse dynamics), 순동역학(forward dynamics)을 예측합니다.
통합 아키텍처 덕분에 입력과 출력 모달리티를 유연하게 조합할 수 있습니다. 아래 표는 입력과 출력 조합이 어떤 응용으로 이어지는지를 정리한 것입니다.
| 입력 | 출력 | 응용 |
|---|---|---|
| 텍스트 | 이미지 | 물리적으로 타당한 이미지 생성 |
| 텍스트, 영상 | 영상 | 희귀 엣지 케이스 영상 데이터 생성을 위한 월드 모델 |
| 텍스트, 이미지 | 영상 | 예측을 위한 월드 모델 |
| 텍스트, 이미지, 영상 | 텍스트 | 추론을 위한 VLM |
| 행동, 영상, 텍스트 | 영상 | 행동 조건부 월드 모델 |
| 영상, 텍스트 | 영상, 행동 | 월드 액션 모델, 영상 액션 모델, 비전 언어 행동 모델, 로봇 학습용 정책 모델 |
여기서 마지막 행, 즉 영상과 텍스트를 입력받아 영상과 행동을 함께 출력하는 설정이 특히 흥미롭습니다. 이는 Google DeepMind의 Gemini Robotics ER이나 Gemini 기반 VLA처럼 최근 로봇 분야에서 주목받는 비전 언어 행동 모델(Vision-Language-Action, VLA) 의 역할을, 별도 모델 없이 같은 파운데이션 모델 안에서 수행한다는 의미입니다.
워크스테이션부터 데이터센터까지: 모델 패밀리
Cosmos 3는 단일 모델이 아니라 여러 체크포인트로 구성된 패밀리입니다. 16B 규모의 컴팩트 모델부터 64B 규모의 프론티어급 모델, 그리고 특정 과제에 특화된 변형까지 포함합니다.
| 모델 | 크기 | 주요 능력 |
|---|---|---|
| Cosmos3-Nano | 16B | 멀티모달 이해, 월드 시뮬레이션, 미래 예측, 행동 추론을 위한 컴팩트 옴니모달 월드 모델 |
| Cosmos3-Super | 64B | 고급 멀티모달 이해와 월드 시뮬레이션을 위한 프론티어급 옴니모달 월드 모델 |
| Cosmos3-Super-Text2Image | 64B | 고품질 텍스트-이미지 생성 |
| Cosmos3-Super-Image2Video | 64B | 시간적으로 일관된 이미지-영상 생성 |
| Cosmos3-Nano-Policy-DROID | 16B | DROID 매니퓰레이션과 제어를 위한 비전 언어 로봇 정책 |
두 핵심 모델의 성격은 분명하게 구분됩니다. Cosmos3-Nano 는 16B 파라미터의 컴팩트 버전으로, 효율적인 추론에 최적화되어 있습니다. NVIDIA RTX PRO 6000 GPU 같은 워크스테이션급 컴퓨팅에서 실시간 로보틱스 추론과 피지컬 AI 응용을 돌릴 수 있도록 설계되었습니다. 반면 Cosmos3-Super 는 64B 파라미터로 최대 품질과 능력을 목표로 하며, 가장 높은 벤치마크 점수를 내면서 NVIDIA Hopper와 NVIDIA Blackwell GPU 위에서의 데이터센터 배포를 겨냥합니다. 대규모 합성 데이터 생성과 고급 물리 추론 워크로드에 적합한 모델입니다.
영상과 행동을 함께 다루는 생성 설정
생성 타워는 다양한 해상도와 화면 비율, 프레임 레이트를 지원합니다. 영상은 256p, 480p, 720p 해상도에서 16:9부터 9:16까지의 비율로, 10에서 30 FPS의 프레임 레이트로, 5프레임에서 최대 300프레임까지 생성할 수 있습니다. 영상과 함께 생성되는 사운드는 48 kHz 스테레오 AAC로 출력되며, 영상 트랙에 muxing되어 하나의 MP4로 묶입니다.
행동(action)을 다룰 때는 신체(embodiment)에 따라 행동 차원(action dimension)이 달라집니다. 카메라 움직임은 9차원, 자율주행차는 9차원, 자기중심 움직임은 57차원, 단일 팔 로봇(DROID, UR, Fractal, Bridge, UMI)은 10차원, 양팔 로봇은 20차원, 휴머노이드 로봇(AgiBot)은 29차원으로 행동을 조건화합니다. 이렇게 여러 신체를 하나의 모델이 다룰 수 있다는 점은, NVIDIA가 앞서 공개한 휴머노이드 로봇 기반 모델 Isaac GR00T에서 이어지는 "신체 일반화(embodiment generalization)" 흐름과 맞닿아 있습니다.
생성기는 짧은 장면 설명을 조밀한 구조화 프롬프트로 확장하는 프롬프트 업샘플링(prompt upsampling) 도 지원합니다. 월드 생성 프롬프트는 300단어 미만으로 작성하는 것이 권장됩니다.
피지컬 AI를 위한 여섯 개의 오픈 데이터셋
Cosmos 3 릴리스의 또 다른 축은 데이터입니다. NVIDIA는 Hugging Face에 여섯 개의 합성 데이터 생성(Synthetic Data Generation, SDG) 데이터셋을 함께 공개했습니다. 이 데이터셋들은 로보틱스, 물리 시뮬레이션, 공간 추론, 인간 동작, 주행, 창고 환경을 아우르며, Cosmos 3뿐 아니라 다른 모델의 사후 학습(post-training)에도 사용할 수 있습니다.
-
Embodied robot scenes: 다양한 환경에서 휴머노이드 로봇이 매니퓰레이션 과제를 수행하는 체화 로봇 장면
-
Physical interaction scenes: 철구가 물체를 때리거나 도미노가 쓰러지는 등의 물리 상호작용 장면. 물체별 속도, 질량중심 변위, 프레임별 시맨틱 분할 같은 정답(ground-truth) 물리 주석을 포함
-
Spatial reasoning: 주방, 복도, 사무실 등의 장면과 "커피 테이블이 소파에서 얼마나 떨어져 있나?" 같은 질문-답변 쌍
-
Digital human scenes: 다양한 외형과 동작, 조명, 카메라 움직임을 가진 디지털 휴먼 장면
-
Autonomous driving scenarios: 자율주행차의 자기 시점에서 다양한 날씨와 조명, 차선 변경, 보행자 상호작용을 담은 주행 장면
-
Warehouse operations scenes: 지게차가 움직이거나 사람과 충돌하는 등 여러 카메라 각도의 창고 장면
이 가운데 공간 추론(Spatial Reasoning) 데이터셋은 구성이 특히 풍부합니다. 아래 그림처럼 시뮬레이션 기반 장면(Simulation Grounded Scenes), 공간 과제 분류(Metric Geometry, Spatial Frame, Physical Semantics, Actionable Grounding, Viewpoint Dynamics, Embodied Composition), 그리고 질문-답변 통계로 구성되어 있으며, 5,500개 이상의 장면과 32개의 공간 과제, 538K개의 질문-답변 쌍, 68K개의 카메라를 포함합니다.

평가: 사람이 검증하는 품질과 리더보드 성능
사람이 평가하는 영상 품질, HUE 벤치마크
생성 모델이 발전할수록 기존 자동 평가 지표만으로는 모델 간 차이를 가려내기가 어려워집니다. 최첨단(SOTA) 영상 생성 모델들이 자동 리더보드를 포화시키면서, 릴리스 사이의 점수 차이가 의미 있는 비교를 하기에는 너무 좁아지는 문제가 생기기 때문입니다. NVIDIA는 이를 해결하기 위해 NVIDIA Cosmos Human Evaluation(HUE) 프레임워크를 함께 내놓았습니다.
HUE의 핵심 아이디어는 주관적 채점을 객관적 사실 검증으로 바꾸는 것입니다. 생성된 각 영상을 원자적 이진 검증(atomic binary verification) 으로 분해하여, 시맨틱 정렬(semantic alignment), 물리 법칙(physical laws), 기하 추론(geometric reasoning), 시각적 무결성(visual integrity)이라는 네 가지 차원에 걸쳐 "예/아니오"로 답할 수 있는 단일 사실 질문(single-fact yes/no questions)으로 나눕니다. 이 질문들은 로보틱스, 자율주행차, 물리를 포함한 일곱 개 피지컬 AI 도메인에 걸쳐 VLM 파이프라인으로 생성되고 인간 전문가가 다듬은 뒤, Hugging Face에 오픈소스로 공개되었습니다.
여덟 개 이상의 리더보드에서 입증된 성능
Cosmos 3는 추론과 생성 양쪽에서 폭넓게 평가되었습니다. 추론 벤치마크에서는 Cosmos 3 Super가 32B 티어, Cosmos 3 Nano가 8B 티어에서 VANTAGE-Bench를 선도합니다. VANTAGE-Bench는 창고와 교통, 스마트 공간 등 실세계 고정 카메라 영상에서 비전 언어 모델을 평가하는 최초의 공개 벤치마크입니다. 또한 교통 영상에서 이상 이벤트를 탐지하고 추론하는 Traffic Anomaly Reasoning(TAR) 리더보드는 AI City Challenge 2026 Track 3의 공식 리더보드이기도 합니다.
생성 벤치마크에서 Cosmos 3는 여러 공개 리더보드에서 오픈소스 SOTA를 기록했습니다.
-
Artificial Analysis: 텍스트, 이미지, 영상 생성 모델을 순위화하는 벤치마킹 플랫폼으로, Cosmos 3는 Text to Image 리더보드와 Image to Video(오디오 없음) 리더보드에서 선도적인 오픈소스 모델입니다.
-
R-Bench: 로봇 영상 생성에서 영상 기반 월드 모델을 평가하는 벤치마크로, 구조적 일관성과 물리적 타당성, 실행 완결성 같은 하위 지표로 과제 완수와 시각 품질을 평가합니다.
-
PAI-Bench: 로보틱스, 자율주행차, 물리 상식 등의 도메인에 걸쳐 영상 이해와 영상 생성을 함께 평가하는 통합 피지컬 AI 벤치마크입니다.
-
Physics-IQ: 생성 영상 모델이 단순히 시각적 사실성을 달성하는 데 그치지 않고 실제로 물리 원리를 이해하는지를 검증하는, 실세계 영상 기반 벤치마크입니다.
-
RoboLab: 과제 일반화 로봇 정책을 평가하는 시뮬레이션 벤치마크입니다.
자신의 데이터로 적응시키기: 학습 레시피
Cosmos 3 릴리스의 중심에는 완전히 공개된 학습 레시피가 있습니다. 모델 체크포인트를 넘어, 새로운 도메인과 신체, 데이터셋에 Cosmos 3를 적응시키기 위한 코드와 설정(config), 워크플로우가 함께 제공됩니다.
지도 미세조정(Supervised Fine-Tuning, SFT) 사후 학습 은 개발자가 자신의 데이터에 맞춰 Cosmos 3를 적응시킬 수 있게 합니다. 공개된 레시피에는 커스텀 영상 데이터셋을 위한 비전 생성 사후 학습과, 로보틱스 및 피지컬 AI 워크플로우를 위한 행동 중심 레시피가 포함됩니다. 이를 통해 로보틱스, 자율주행, 창고 자동화 전반에서 자신의 목표 도메인에 맞게 모델을 커스터마이즈할 수 있습니다. 사후 학습 코드와 설정은 GitHub에 공개되어 있습니다.
행동 사후 학습(Action post-training) 은 순동역학, 역동역학, 정책 생성을 포함한 행동 인식 피지컬 AI 응용을 위해 Cosmos 3를 적응시킵니다. 로봇 응용에서는 로봇 행동에 조건화된 미래 관찰 생성, 관찰된 시연 뒤에 숨은 행동 추론, 현재 관찰과 과제 프롬프트로부터 행동 시퀀스 예측이라는 여러 워크플로우를 다룹니다. 이 점이 Cosmos 3를 월드 액션 모델링과 정책 학습을 위한 강력한 기반으로 만듭니다.
직접 써보기: 코드와 NIM 배포
코드로 시작하기
Cosmos 3는 연구와 프로덕션 두 경로를 모두 제공합니다. 생성기는 연구와 모델 개발용으로 Diffusers를, 프로덕션 추론용으로 vLLM-Omni를 사용하고, 추론기는 Transformers와 OpenAI 호환 서빙을 위한 vLLM을 사용합니다. 아래는 Diffusers로 생성기를 불러오는 예시입니다. 코드 내 주석은 원문 그대로 유지했습니다.
import torch
from diffusers import Cosmos3OmniPipeline
from diffusers.utils import export_to_video
pipe = Cosmos3OmniPipeline.from_pretrained(
"nvidia/Cosmos3-Nano", torch_dtype=torch.bfloat16
)
pipe.to("cuda")
추론기는 Qwen3-VL 호환 메시지 규약을 따라 이미지와 영상 입력을 처리합니다. 텍스트와 비전 요청에는 다음과 같은 기본 메시지 형태를 사용합니다.
[
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "video_url", "video_url": "https://example.com/video.mp4"},
{"type": "text", "text": "List the notable events with approximate timestamps."}
]
}
]
명시적인 추론(reasoning)을 원할 때는 사용자 프롬프트에 다음 형식 지시를 덧붙입니다. 모델은 <think> 태그 안에 사고 과정을 쓰고 그 뒤에 최종 답을 출력합니다.
Answer the question using the following format:
<think>
Your reasoning.
</think>
Write your final answer immediately after the </think> tag.
NIM 마이크로서비스로 배포하기
Cosmos 3 모델은 최적화된 프로덕션 배포를 위해 NVIDIA NIM 마이크로서비스로도 제공됩니다. NIM은 모델을 최적화된 추론 런타임과 함께 패키징하여, 서빙 인프라를 수동으로 튜닝하지 않고도 높은 성능을 낼 수 있게 합니다. 공개 시점 기준으로 추론 능력을 제공하는 Cosmos 3 Reasoner NIM이 먼저 제공되며, 전체 생성 능력을 제공하는 Cosmos 3 Generator NIM이 뒤이어 공개될 예정입니다.
추론 가속을 위해 다음과 같은 최적화가 적용되었습니다.
-
양자화(Quantization): Cosmos 3 NIM은 BF16, FP8, NVFP4 양자화 체크포인트를 선택할 수 있습니다. NVFP4 양자화는 모델의 수치 정밀도를 BF16에서 4비트 부동소수점으로 낮춰 최대 2배의 추론 속도 향상을 달성합니다.
-
vLLM: 연속 배칭(continuous batching), 페이지드 어텐션(paged attention), 텐서 병렬화 같은 기법으로 LLM을 효율적으로 서빙하는 오픈소스 추론 엔진입니다. Cosmos 3 Reasoner NIM 서빙 스택은 vLLM 위에 구축되어 기존 서빙 방식보다 높은 처리량을 냅니다. Cosmos 3 Nano는 vLLM-omni와 NVIDIA Dynamo로 곧장 실행할 수 있습니다.
-
효율적 영상 샘플링(Efficient Video Sampling, EVS): 추론 중 VLM에 입력되는 영상 토큰 수를 줄여 속도를 높이는 기법입니다. EVS는 청크(chunk) 단위로 작동하여 각 프레임에서 가장 고유한 청크만 유지하고 나머지는 가지치기하며, 작은 GPU일수록 더 큰 이득을 봅니다.
NGC API 키가 있다면 다음 명령으로 Cosmos 3 Nano Reasoner NIM을 내려받아 실행할 수 있습니다. Super 모델을 쓰려면 NIM_MODEL_SIZE=super 로 지정합니다.
docker run --gpus=all \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_MODEL_SIZE=nano \
-p 8000:8000 \
nvcr.io/nim/nvidia/cosmos3-reasoner:latest
한계와 책임 있는 사용
Cosmos 3는 길거나 고해상도이거나 물리적으로 복잡한 출력에서 아티팩트를 만들어낼 수 있습니다. 흔한 실패 양상으로는 시간적 비일관성, 불안정한 카메라나 물체 움직임, 부정확한 사운드와 영상 정렬, 불완전한 행동 상태 일관성, 물체 변형(object morphing), 부정확한 3D 구조, 비현실적인 물리 동역학 등이 있습니다. 따라서 물리적으로 근거 있는 시뮬레이션이나 안전이 중요한 제어, 복잡한 다중 에이전트 행동이 필요한 응용에서는 배포 전에 추가 검증과 가드레일, 시스템 차원의 안전 분석이 반드시 필요합니다. 모델은 cosmos_guardrail 같은 안전 장치와 함께 사용하도록 설계되어 있습니다.
Cosmos 생태계
Cosmos 3는 단일 모델을 넘어 학습과 데이터 큐레이션, 평가를 아우르는 생태계의 일부입니다.
| 프로젝트 | 역할 |
|---|---|
| Cosmos Framework | 월드 모델의 학습과 서빙을 위한 엔드투엔드 피지컬 AI 프레임워크 |
| Cosmos Curator | 처리, 주석, 필터링, 중복 제거를 다루는 분산 피지컬 AI 데이터 큐레이션 시스템 |
| Cosmos Evaluator | 월드 생성과 월드 추론 출력을 위한 자동 피지컬 AI 평가 시스템 |
의미와 전망
Cosmos 3가 보여주는 가장 큰 변화는 "이해하는 모델"과 "생성하는 모델"의 경계가 점점 흐려지고 있다는 점입니다. 그동안 피지컬 AI 시스템은 인식, 예측, 제어를 각기 다른 모델로 쌓아 올린 파이프라인이었지만, Cosmos 3는 이 세 단계를 하나의 옴니모달 월드 모델 안으로 끌어들였습니다. 이는 소프트웨어정책연구소(SPRi)의 피지컬 AI 보고서나 2026년 로보틱스 투자 전망에서 공통적으로 지적하는, 월드 모델을 중심으로 한 피지컬 AI의 부상이라는 흐름과도 맞닿아 있습니다.
특히 NVIDIA가 모델 가중치뿐 아니라 학습 레시피와 데이터셋, 평가 프레임워크까지 OpenMDW 라이선스로 함께 공개했다는 점은, 그동안 사내 데이터와 닫힌 시뮬레이터에 의존하던 로보틱스 연구의 진입 장벽을 낮출 가능성이 있습니다. 물론 한계 항목에서 밝힌 것처럼 안전이 중요한 영역에서는 여전히 별도의 검증이 필요하지만, 워크스테이션급 GPU에서 돌아가는 16B Nano 모델이 함께 제공된다는 점은 개인 연구자와 소규모 팀에게도 현실적인 출발점이 될 수 있습니다.
커뮤니티 참여
Cosmos 팀은 GitHub과 Discord를 통해 이슈 제보와 기여, 토론을 받고 있습니다. NVIDIA Omniverse Discord에서 Cosmos 생태계에 대한 질문과 피드백을 주고받을 수 있습니다.
라이선스
NVIDIA Cosmos의 소스 코드와 모델은 OpenMDW-1.1 라이선스로 배포됩니다. 별도의 커스텀 라이선스가 필요하면 NVIDIA(cosmos-license@nvidia.com)에 문의할 수 있습니다. 다만 이 프로젝트는 추가적인 서드파티 오픈소스 프로젝트를 내려받아 설치할 수 있으므로, 사용 전에 해당 프로젝트들의 라이선스 조건도 함께 확인하는 것이 좋습니다.
 NVIDIA Cosmos 3 소개 블로그
NVIDIA Cosmos 3 소개 블로그
 NVIDIA Cosmos GitHub 저장소
NVIDIA Cosmos GitHub 저장소
 NVIDIA Cosmos 3 Hugging Face 컬렉션
NVIDIA Cosmos 3 Hugging Face 컬렉션
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()