Qwen-RobotWorld 소개
로봇을 학습시킬 때 가장 비싼 자원은 무엇일까요? GPU도, 모델 파라미터도 아닌 실제 세계의 경험입니다. 사람은 컵을 잡다가 떨어뜨리고, 물을 따르다 넘치는 과정을 일상에서 수없이 겪으며 물리 법칙을 체득하지만, 로봇은 이런 경험 하나하나를 사람이 직접 원격 조작(teleoperation)으로 수집하거나 실제 하드웨어를 위험하게 굴려가며 모아야 합니다. 비싸고, 느리고, 안전하지도 않습니다.
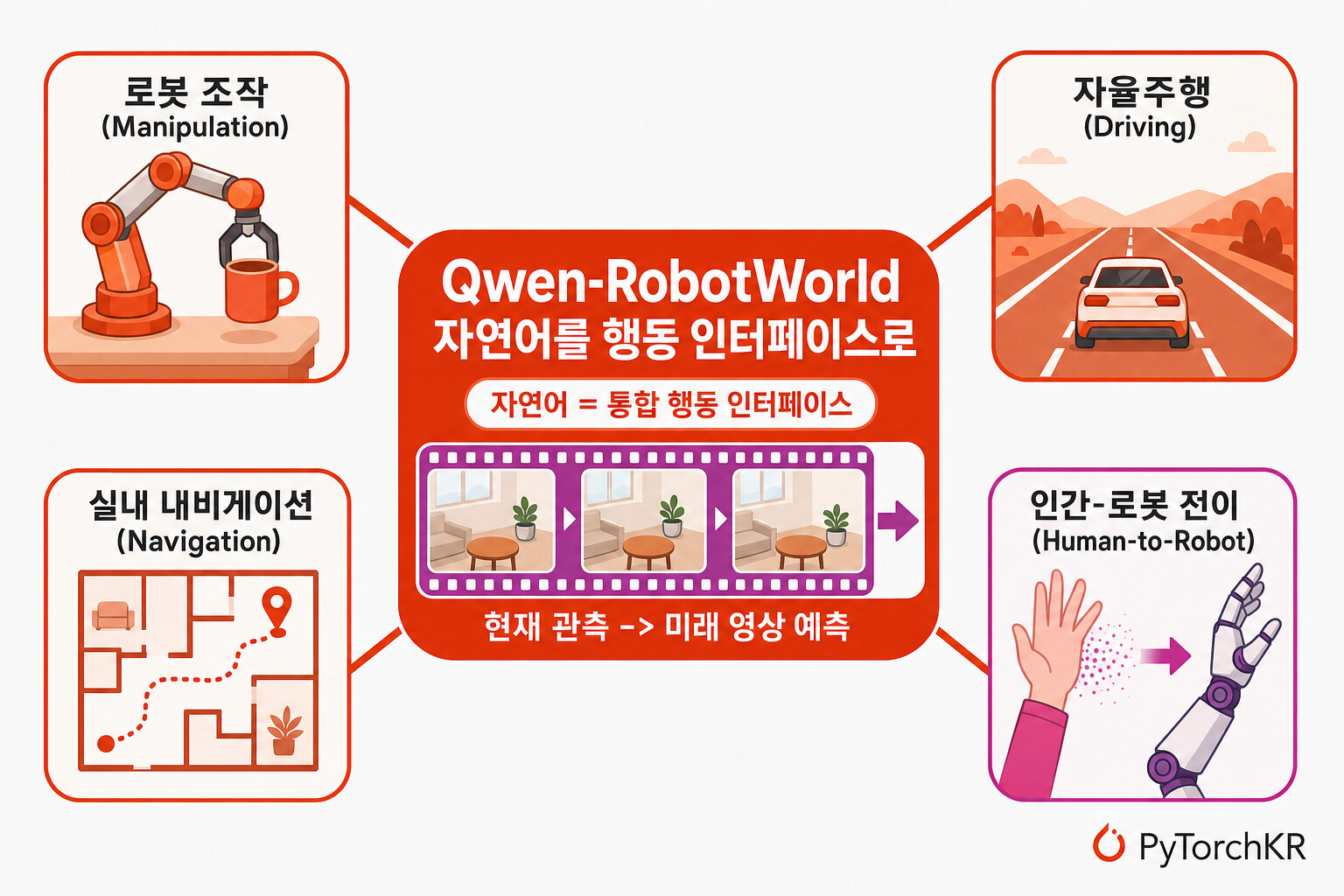
이 글에서 정리하는 Qwen-RobotWorld는 바로 이 문제를 정면으로 겨냥한 연구입니다. 이 연구는 "현재 관측과 자연어 명령이 주어졌을 때, 다음 순간 세계가 어떻게 보일지를 영상으로 예측하는" 언어 조건부 비디오 월드 모델(language-conditioned video world model)을 제안합니다. 핵심 발상은 단순하면서도 강력합니다. 로봇 조작, 자율주행, 실내 내비게이션처럼 서로 다른 영역의 행동을 모두 자연어라는 하나의 행동 인터페이스(unified action interface) 로 통일하여, 단일 모델이 여러 도메인의 물리 지식을 동시에 학습하도록 만든 것입니다.
월드 모델이란 무엇이고, 왜 중요한가
임바디드 지능(embodied intelligence), 즉 물리적 신체를 가진 에이전트가 환경을 지각하고 추론하며 행동하는 능력은 로봇 연구의 오랜 목표입니다. 문제는 앞서 말했듯 실제 환경에서 직접 학습하기가 비싸고 위험하다는 점입니다. 이에 대한 확장 가능한 대안이 바로 월드 모델(world model) 입니다. 월드 모델은 관측 데이터로부터 환경의 동역학(dynamics)을 학습하여, 에이전트가 실제 배치 없이도 행동을 익히고 다듬을 수 있는 상호작용형 학습 플랫폼 역할을 합니다.
월드 모델은 수학적으로 상태 전이 함수(state transition function) 로 형식화됩니다. 현재 상태 s_t 와 행동 a_t 가 주어졌을 때 다음 상태를 예측하는 함수입니다.
비디오 기반 월드 모델에서 상태 s_t 는 시각적 관측(영상 프레임 또는 그 잠재 표현)이고, 모델은 현재 관측과 행동 신호를 조건으로 미래의 시각적 궤적을 생성합니다. 여기서 행동 a_t 는 저수준 모터 명령일 수도, 고수준 웨이포인트 궤적일 수도, 자연어 명령일 수도 있습니다. 저자들은 이 중 "자연어가 가장 일반적이고 접근하기 쉬운 행동 표현" 이라고 강조합니다. "빨간 컵을 집어 선반에 올려라" 라는 한 문장의 명령은 전체 행동 시퀀스, 목표 상태, 물리적 제약을 로봇별 제어 인터페이스 없이도 암묵적으로 모두 담고 있기 때문입니다.
기존 접근의 두 갈래와 그 한계
현재 월드 모델 연구는 크게 두 진영으로 나뉘는데, 각각 분명한 한계를 안고 있습니다.
첫째, Sora 나 Veo 같은 범용 비디오 생성 모델 입니다. 이들은 인터넷 규모의 영상에서 풍부한 시각적 사전 지식(visual prior)을 학습하지만, 임바디드 물리를 정확히 모델링하지 못합니다. 접촉 동역학(contact dynamics), 강체(rigid body)의 구조적 제약, 행동과 결과 사이의 인과 관계처럼 물리적으로 그럴듯한 상태 전이에 필수적인 요소들을 놓치는 것입니다. 그래서 프레임 사이에서 물체가 녹아내리듯 형태가 무너지는(object deformation) 실패가 흔합니다.
둘째, Cosmos 류의 도메인 특화 임바디드 모델 입니다. 이들은 특정 시나리오(예: 탁상 조작 또는 주행)에 맞춰져 있고, 관절 각도나 웨이포인트 같은 로봇 특화 행동 표현에 의존합니다. 정확하긴 하지만 임바디먼트(embodiment) 유형이나 작업 범주를 넘어 일반화하지 못하므로, 범용 시뮬레이션 환경으로서의 활용도가 근본적으로 제한됩니다.
저자들의 통찰은 이 둘 사이의 간극이 공유된 언어 인터페이스 로 메워질 수 있다는 것입니다. 서로 다른 임바디드 도메인은 상호 보완적인 물리 지식을 제공합니다. 조작은 좁은 작업 공간에서 일어나는 정밀한 접촉 물리와 물체 상태 변화를, 자율주행은 자기 운동 시차(ego-motion parallax)를 통한 대규모 다중 에이전트 동역학과 3D 장면 기하를, 실내 내비게이션은 긴 시간 지평에 걸친 방 규모의 공간 추론을 가르칩니다. 이 도메인들이 ** 공통의 언어 인터페이스를 공유하기 때문에 함께 학습될 수 있고**, 각 도메인의 물리 지식이 서로 충돌하는 대신 보강하게 됩니다.
Qwen-Robot Suite 속에서 차지하는 위치

Qwen-RobotWorld는 단독 모델이 아니라 Qwen 팀이 공개한 Qwen-Robot Suite 의 한 축입니다. 이 스위트는 "보는 것과 행동하는 것은 다르다(seeing is not acting)" 는 문제 의식에서 출발합니다. Qwen-VL 같은 멀티모달 모델은 이미 복잡한 공간 관계를 파싱하고 "주방에 가서 빨간 컵을 찾아 선반에 올려라" 같은 계획을 언어로 세울 수 있지만, 그 계획을 실행하는 모터 명령을 만들어내지는 못합니다. 언어 명령과 물리적 행동 신호가 서로 다른 표현 공간에 살고 있다는 정렬(alignment) 문제입니다.
Qwen-Robot Suite는 이 간극을 세 개의 파운데이션 모델로 메웁니다.
- Qwen-RobotNav: 시각 언어 표현 공간을 이동(mobility) 행동으로 연결합니다. 명령 따르기, 물체 목표 내비게이션, 목표 추적, 자율주행 등 5개 내비게이션 작업군을 단일 가중치로 통합하며, 제어 가능한 관측 인코딩과 도구 인터페이스를 갖춰 에이전트 시스템의 빌딩 블록이 됩니다.
- Qwen-RobotManip: 시각 언어 표현 공간을 조작(manipulation) 행동으로 연결합니다. 정규 상태-행동 공간과 카메라 프레임 델타 포즈(delta pose)를 도입하여, 38{,}100 시간이 넘는 오픈소스 코퍼스 위에서 임바디먼트를 가로지르는 일관된 학습을 가능하게 합니다.
- Qwen-RobotWorld: 이 글의 주인공으로, 시각 언어 표현 공간을 ** 세계의 동역학** 으로 연결합니다.
세 모델 모두 언어 우선(language-first) 인터페이스를 노출하기 때문에, 범용 Qwen 모델이 이들을 물리 세계의 도구처럼 호출하여 하나의 에이전트 시스템으로 엮을 수 있습니다. 이 글에서는 세 모델 중 정식 기술 보고서가 공개된 Qwen-RobotWorld 를 중심으로 깊이 들여다보고, 마지막에 스위트 전체가 그리는 그림을 함께 살펴보겠습니다.
핵심 아이디어: 자연어를 통합 행동 인터페이스로
Qwen-RobotWorld의 가장 근본적인 기여는 행동-언어 매핑(action-language mapping) 프레임워크입니다. 보편적 임바디드 월드 모델을 만들 때 가장 큰 걸림돌은 데이터의 양이 아니라 ** 표현의 이질성(representational heterogeneity)** 입니다. 조작은 관절 각도로, 주행은 조향 명령으로, 내비게이션은 방향 벡터로 행동을 표현하는데, 이들은 서로 호환되지 않는 모달리티라서 순진하게 한데 모으면 시너지가 아니라 충돌이 발생합니다.
이 프레임워크는 모든 행동 신호를 공유된 자연어 공간 으로 투영하여 문제를 해결합니다. 그 결과 Franka 그리퍼의 영상, 자율주행 차량의 영상, 내비게이션 에이전트의 영상이 모두 동일한 언어 조건부 비디오 생성 작업 의 사례가 됩니다. 흥미로운 점은 언어 행동이 두 방향으로 모두 쓰일 수 있다는 것입니다. 상태 전이를 지배하는 명시적 입력 으로 모델의 조건 신호에 융합될 수도 있고, 생성된 영상으로부터 사후에 추론되어 행동 레이블로 쓰이는 ** 출력** 이 될 수도 있습니다. 이 유연성 덕분에 언어 조건부 월드 모델은 인터페이스 재설계 없이 임바디드 플랫폼을 가로지르는 보편적 시뮬레이션 백본이 됩니다.
다만 이 보편성은 주석 품질에 까다로운 요구를 부과합니다. 각 캡션이 완결적인 행동 명세 로 기능해야 하기 때문입니다. 즉 모델이 로봇 메타데이터나 자기수용감각(proprioceptive) 신호 없이 오직 s_t 와 a_t 만으로 s_{t+1} 을 예측할 수 있을 만큼 정밀해야 합니다. 이 요구를 충족하기 위한 계층적 주석 파이프라인은 뒤의 데이터 섹션에서 자세히 다룹니다.
모델 아키텍처: Double-Stream MMDiT
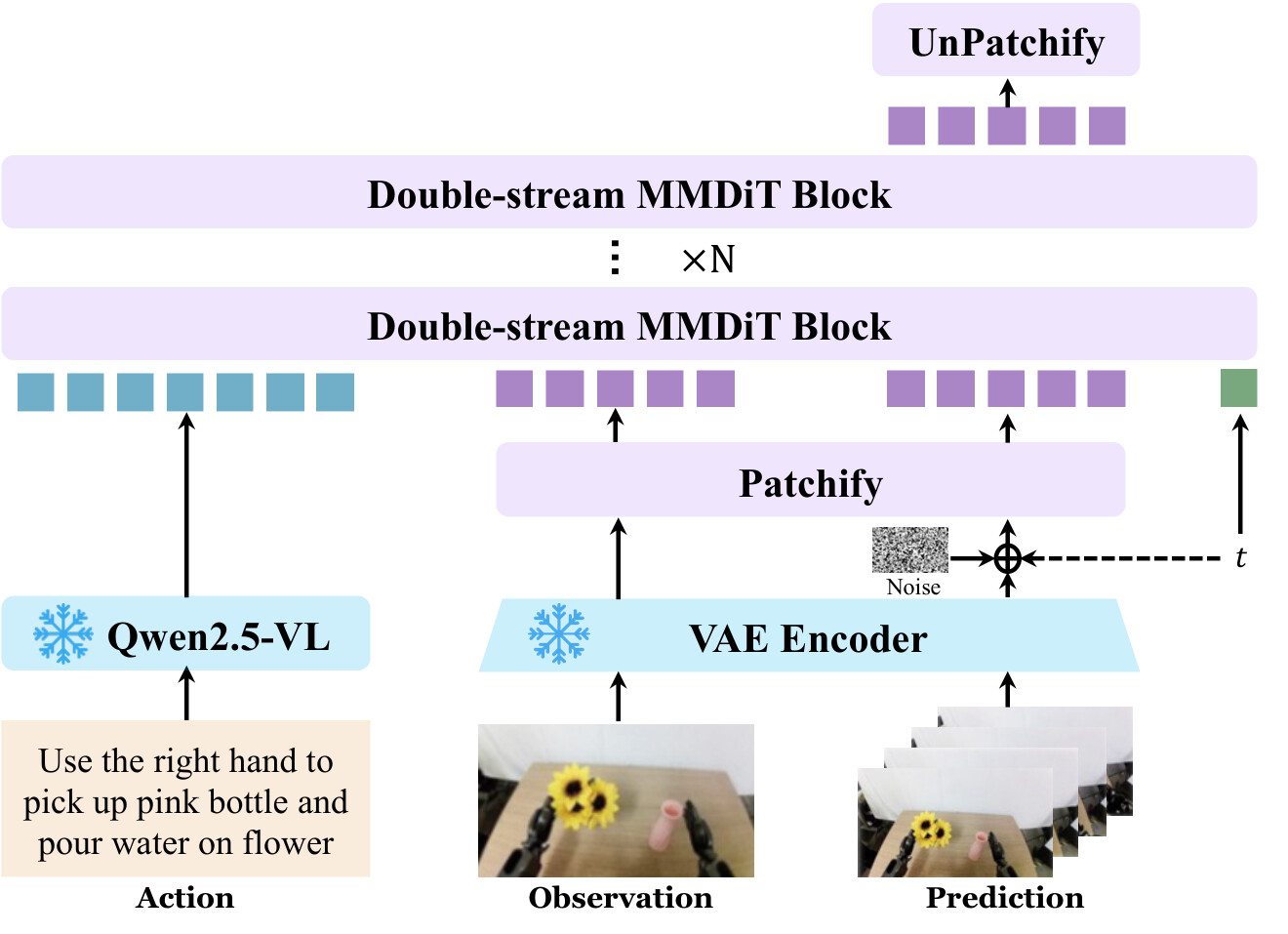
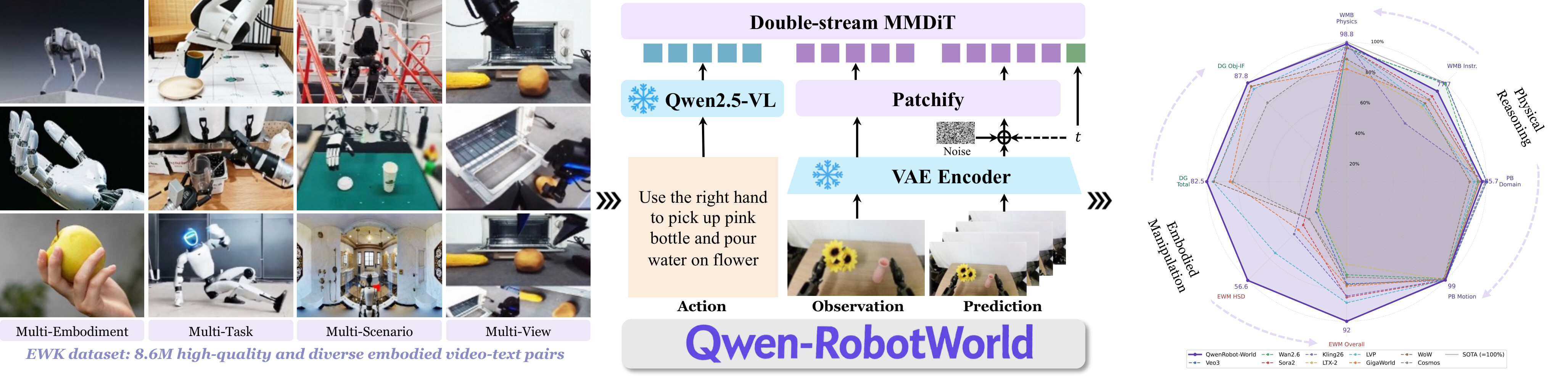
언어 조건부 상태 전이를 구현하기 위해, Qwen-RobotWorld는 이중 스트림 멀티모달 디퓨전 트랜스포머(Double-Stream MMDiT) 를 백본으로 채택합니다. 모델은 세 부분으로 구성됩니다. 행동 인코더 역할의 MLLM, 상태 인코더/디코더 역할의 VAE, 그리고 전이 함수 역할의 MMDiT입니다.
이해 스트림과 생성 스트림
MMDiT는 두 개의 스트림을 가집니다. 이해 스트림(understanding stream) 은 동결된(frozen) Qwen2.5-VL 인코더가 추출한 풍부한 의미 특징을 처리하며, 이는 행동 a_t 를 나타냅니다. ** 생성 스트림(generation stream)** 은 비디오 호환 VAE에서 나온 시각 잠재 표현(visual latent)을 처리하며, 이는 시각 상태 s_t 를 나타냅니다.
핵심은 두 스트림이 모든 층마다 결합 어텐션(joint attention)으로 상호작용 한다는 점입니다. 디노이징(denoising) 과정 전체에 걸쳐 양방향 교차 모달 융합이 일어나는 것입니다. 이는 마치 통역사 두 명이 회의 내내 한 문장씩 끝날 때마다 서로 귓속말로 맥락을 맞춰가며 번역하는 것과 비슷합니다. 언어 의미와 시각 상태가 마지막에 한 번 합쳐지는 것이 아니라, 처음부터 끝까지 60개 블록 전 구간에서 끊임없이 정보를 주고받습니다.
백본의 구체적 사양은 다음과 같습니다. 60개의 이중 스트림 블록, 어텐션 헤드 24 개(헤드 차원 128 ), 은닉 크기 3{,}072 , 패치 크기 2 \times 2 입니다. 전체 파라미터는 MLLM이 7\text{B} , VAE가 127\text{M} (인코더 54\text{M} + 디코더 73\text{M} ), MMDiT가 20\text{B} 입니다. 컨텍스트 길이는 최대 48{,}360 개의 비디오 토큰을 지원합니다. VAE로는 이미지와 비디오 모달리티를 모두 다루는 Wan-VAE 아키텍처를 사용합니다.
MLLM을 행동 인코더로 쓰는 이유
이 연구에서 가장 중요한 설계 결정은 행동 인코더로 T5 나 CLIP 같은 경량 텍스트 인코더 대신 완전한 멀티모달 LLM(Qwen2.5-VL) 을 쓴 것입니다. 저자들은 이 선택이 두 가지 결정적 이점을 준다고 설명합니다.
첫째, 깊은 언어 이해 입니다. MLLM은 복잡하고 합성적인(compositional) 명령을 정밀한 조건 신호로 정확히 파싱하여, 미세한 상태 전이를 제어할 수 있습니다. 둘째, ** 내재화된 세계 지식** 입니다. MLLM은 "로봇 팔은 고정된 링크 길이와 관절 제약을 가진 강체" 라는 사실을 이미 알고 있습니다. 이 지식이 물리적으로 그럴듯한 전이의 공간을 암묵적으로 제약합니다. T2I 공동 학습과 결합되면, 명시적인 기하 프롬프트 없이도 프레임 간 물체 변형 같은 흔한 실패 모드를 막아줍니다. 의미적 기반(semantic grounding)이 없는 모델이라면 그냥 픽셀의 통계적 패턴만 따라가다 물체를 뭉개버리는 지점에서, 이 모델은 "이건 강체니까 모양이 유지되어야 한다" 는 사전 지식으로 생성을 붙잡아 주는 셈입니다.
비대칭 3D RoPE
영상은 시간, 높이, 너비라는 세 축을 가집니다. 모델은 이를 독립적으로 인코딩하기 위해 3D 회전 위치 인코딩(3D RoPE) 을 사용하는데, 차원을 균등하게 배분하지 않고 비대칭으로 나눕니다. 시간 축에 16 차원, 높이와 너비에 각각 56 차원씩 할당하여 총 128 차원을 채웁니다(pe_axes_dim = [16, 56, 56]). 인접한 프레임은 서로 강하게 연관되어 있어 시간 축은 적은 차원으로 충분한 반면, 공간 축은 물체 위치와 장면 배치의 다양성이 훨씬 크기 때문에 더 많은 차원을 받는 것입니다. 추론 시 다양한 해상도와 길이로 일반화하기 위해 Scalable RoPE도 함께 적용합니다.
Scene2Robot: 인간 시연을 로봇 실행으로
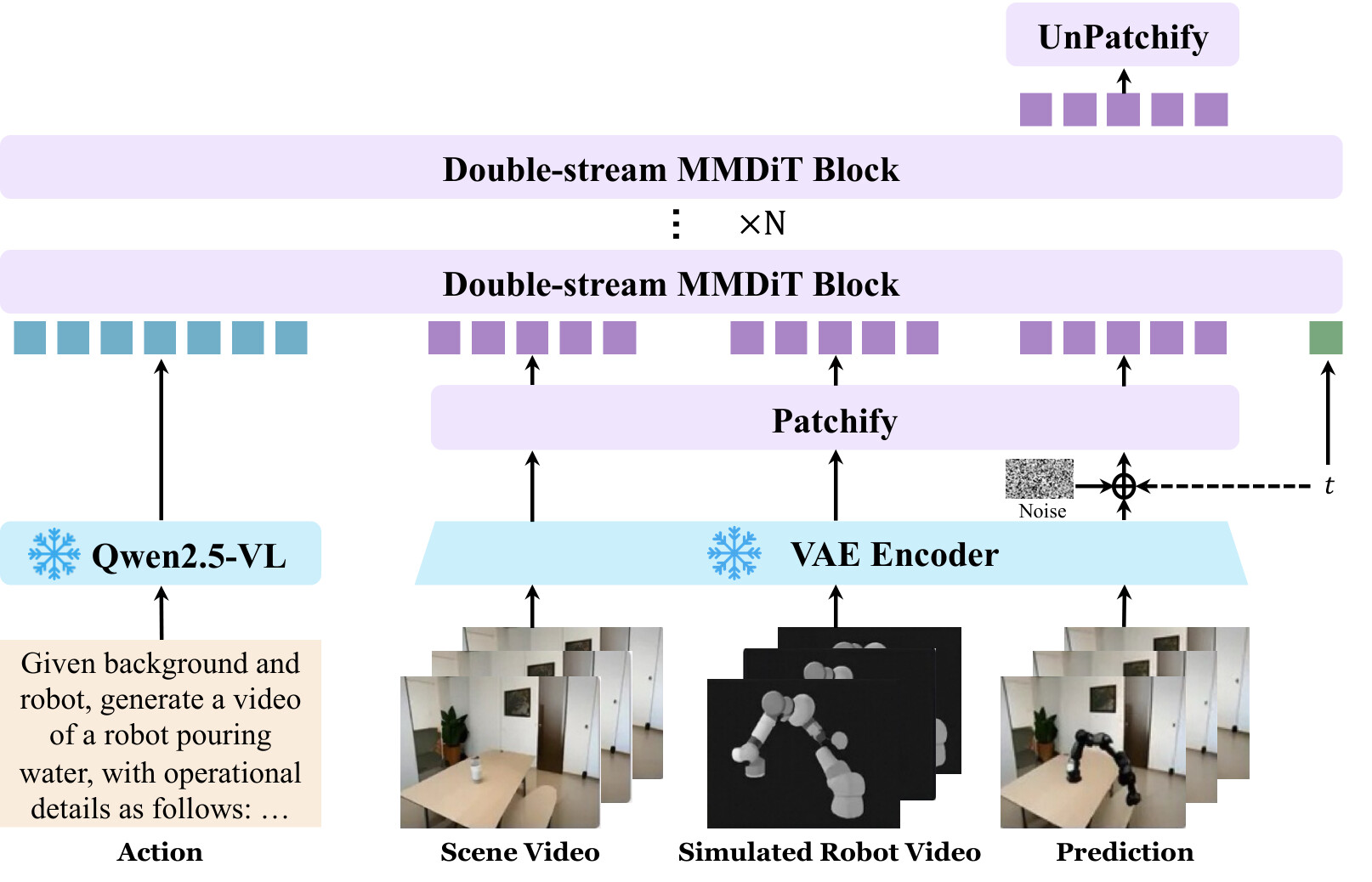
로봇 학습 데이터의 한계를 넘어서는 실용적 경로 중 하나가 인간 시연을 로봇 실행으로 번역 하는 것입니다. Qwen-RobotWorld는 동일한 MMDiT 백본을 재활용하여 교차 임바디먼트 비디오 편집을 수행하는 Scene2Robot 메커니즘을 설계했습니다. 아키텍처를 전혀 수정하지 않고, 입력 시퀀스를 세 개의 세그먼트로 확장하는 것이 전부입니다.
- 장면 조건(Scene condition): 손을 마스킹 처리한 원본 인간 시연 영상으로, 외형과 공간 배치, 물체 상태 정보를 제공합니다.
- 로봇 참조(Robot reference): MuJoCo 로 렌더링한 시뮬레이션 로봇 실행 영상으로, 대상 임바디먼트의 운동학적 궤적과 형태를 공급합니다.
- 생성(Generation): 최종 사실적 로봇 실행 영상으로 디노이징될 노이즈 잠재 표현입니다.
세그먼트 (1)과 (2)는 첫 프레임 조건처럼 타임스텝 t=0 을 공유하며 손실 계산에서 제외되고, 오직 세그먼트 (3)만 학습 중 그래디언트를 받습니다. 3D RoPE가 각 세그먼트에 고유한 시간 인덱스 범위를 부여하여 세그먼트 간 시간 위치를 구분하고, 모든 MMDiT 블록의 결합 어텐션이 생성 토큰으로 하여금 세그먼트 (1)의 장면 외형, 세그먼트 (2)의 로봇 움직임, 그리고 이해 스트림의 언어 의미를 동시에 참조하게 합니다. 이 메커니즘은 학습 시에는 데이터 확장 엔진으로, 추론 시에는 인간을 로봇으로 옮기는 전이 도구로 작동하며, 14 개 로봇 형태로의 리타게팅을 지원합니다.
다중 시점 기하 일관 생성
단일 카메라 관측은 접촉과 공간의 결정적 세부를 필연적으로 가립니다. Qwen-RobotWorld는 메인 뷰, 손목 장착 뷰, 3인칭 뷰 등 2 에서 4 개의 동기화된 카메라 스트림을 생성하며, 모든 시점에서 물체의 정체성과 움직임이 기하적으로 일관됩니다. 학습 시에는 여러 카메라의 동기화된 프레임을 공간적으로 이어 붙여(spatial concatenation) 단일 입력으로 만들고, 모델이 모든 뷰를 동시에 생성하도록 합니다. 앞서 본 비대칭 3D RoPE가 공간 인코딩을 제공하고 어텐션 층이 자연스럽게 교차 시점 대응 관계를 수립하므로, 아키텍처 변경 없이 다중 시점 일관성이 확보됩니다. 이 교차 시점 일관성은 덤으로 기하 정규화(geometric regularizer) 역할까지 하여, 모델에게 물체의 형태와 깊이, 공간 배치를 가르칩니다.
데이터: Embodied World Knowledge
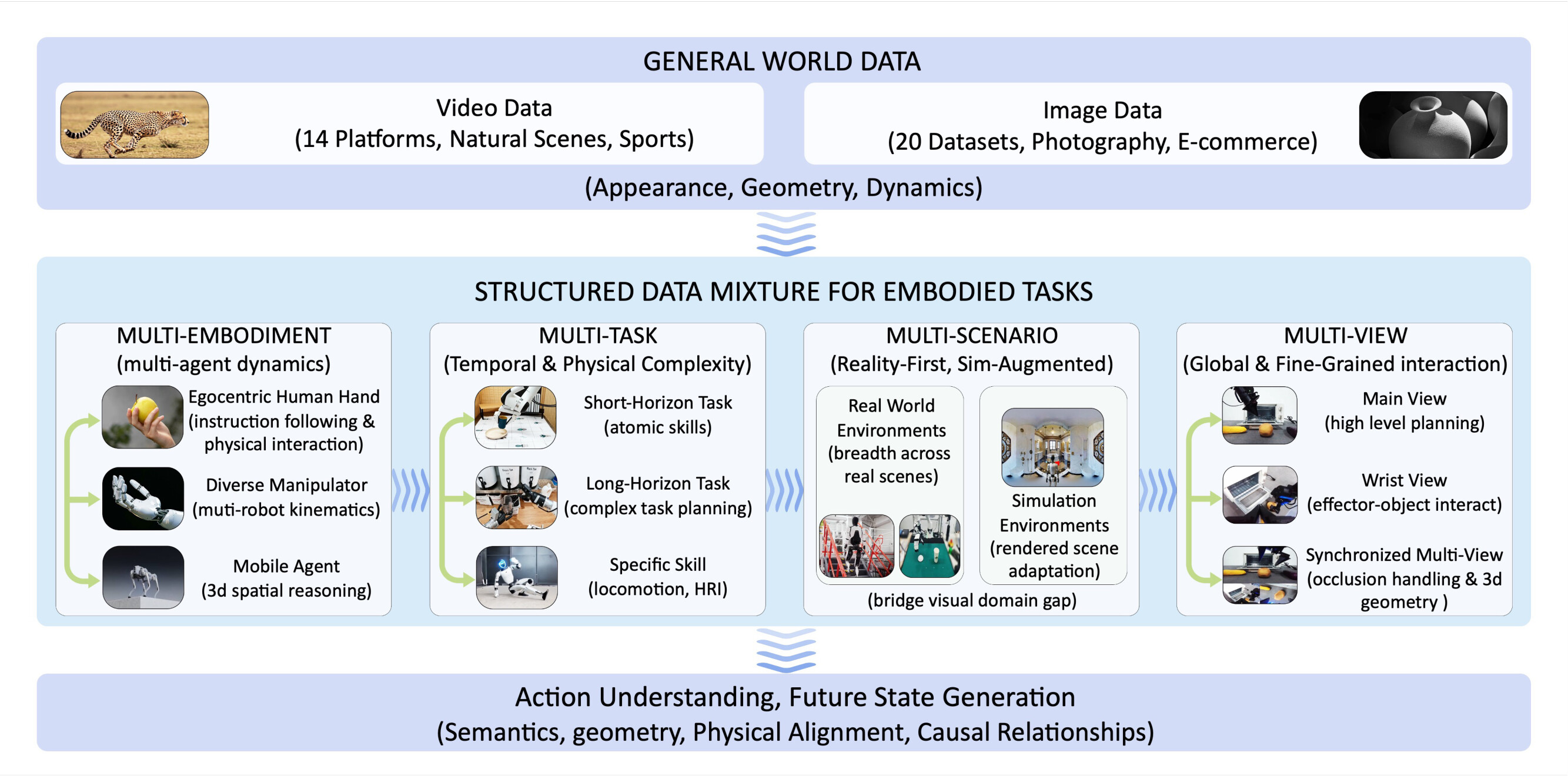
좋은 월드 모델은 좋은 데이터에서 나옵니다. 연구팀은 도메인을 가로질러 일반화하는 상태 전이 함수를 학습시키기 위해 Embodied World Knowledge(EWK) 데이터셋을 구축했습니다. 약 8.6\text{M} 개의 비디오-텍스트 쌍과 200\text{M} 개가 넘는 관측 프레임으로 이루어진 대규모 코퍼스입니다. 이 중 약 6\text{M} 개가 행동-언어 매핑으로 생성된 고품질 임바디드 쌍이고, 여기에 범용 영상 데이터(전체의 30\% )를 더했습니다.
4개 임바디드 도메인
EWK는 서로 다른 물리적 변이의 원천을 겨냥한 4개 축으로 조직됩니다.
- 조작(Manipulation, 약 5.9\text{M} 샘플): 핵심 임바디드 기반을 제공합니다. EgoHOD, EPIC-Kitchens 같은 인간 손 영상부터 Bridge V2, RH20T, Droid, Agibot-World, 그리고 내부 데이터인 Qwen-Aloha까지, 20 종이 넘는 로봇 형태와 1{,}300 개 이상의 기술을 아우릅니다.
- 자율주행(약 200\text{K} 샘플): Waymo, NVIDIA PhysicalAI-AD, Bench2Drive, Sekai에서 대규모 자기 운동과 다중 에이전트 동역학을 공급합니다.
- 실내 내비게이션(6\text{K}+ 에피소드): VLNVerse의 언어 유도 에피소드로 방 규모 공간 추론을 제공합니다.
- 인간에서 로봇으로 옮기는 전이(Human-to-Robot Transfer): MANO 기반 인간-로봇 파이프라인으로 14 개 로봇 형태에 걸친 교차 임바디먼트 비디오 편집 데이터를 만듭니다.
이 도메인들은 다시 다중 임바디먼트, 다중 작업, 다중 시나리오(현실 우선, 시뮬레이션 보강), 다중 시점이라는 네 갈래로 교차 분류됩니다. 특히 약 1.6\text{M} 개의 임바디드 샘플이 2 에서 4 개 시점을 이어 붙인 형태를 포함합니다.
계층적 5단계 주석 파이프라인
앞서 말한 "캡션이 완결적 행동 명세여야 한다" 는 요구를 충족하기 위해, 연구팀은 5단계의 점진적 주석 프레임워크를 설계했습니다. 앞 세 층은 각 시각 상태 전이를 해석 가능한 구성 요소로 분해하는 구조화된 사고 사슬(chain-of-thought)을 형성합니다.
- 작업 목표 층(Task Goal): s_t 와 s_{t+1} 사이에서 무엇이 바뀌어야 하는지, 즉 전이의 고수준 의도를 추론합니다.
- 행동 세부 층(Action Detail): 행동을 시공간 궤적, 미시 행동, 속도, 힘으로 분해하며, 시점 정보(메인 뷰, 손목 뷰, 외부 뷰 등)를 반드시 명시합니다.
- 물리 피드백 층(Physical Feedback): 물체 변위, 변형, 접촉 상태 변화 등 행동이 환경에 미친 관측 가능한 결과를 기술하여, 각 전이를 검증 가능한 물리적 결과에 기반시킵니다.
이 분석을 토대로 두 가지 입도(granularity)의 설명이 생성됩니다. 50 에서 100 단어로 시점, 에이전트, 행동, 피드백을 모두 명세하는 포괄적 설명(Comprehensive), 그리고 15 에서 30 단어로 핵심 요소만 남긴 ** 간결한 설명(Concise)** 입니다. 학습 시 두 설명을 50\% 씩 동일 확률로 샘플링하므로, 모델은 상세한 궤적 명세와 짧은 작업 수준 명령을 모두 처리하는 법을 배웁니다. 여기에 작업 인식 시간 분할(각 샘플이 완결된 상태 전이를 담도록)과 네 가지 품질 통제 원칙(행동 초점, 시점 정의, 객관성, 물리적 검증 가능성)이 더해져 캡션의 정밀도를 끌어올립니다.
학습: General에서 Expert로
데이터와 아키텍처가 준비되면, 이제 이를 어떻게 학습시킬지가 관건입니다. Qwen-RobotWorld는 범용에서 전문가로 가는 점진적 커리큘럼(general-to-expert progressive curriculum) 을 따릅니다. 일반 장면 생성과 로봇 조작 예측을 단일 자연어 인터페이스 아래 동일한 조건부 비디오 생성 작업 으로 통일하고, 학습 내내 두 데이터 영역 모두에서 그래디언트를 받게 하는 것이 핵심입니다.
사전 학습: 범용 세계의 토대
사전 학습 단계에서는 14 개 고품질 영상 플랫폼에서 수집한 200\text{M}+ 개의 실세계 관측 샘플로 도메인 무관 세계 사전 지식(물체 운동, 조명 변화, 충돌 동역학)을 내재화합니다. 여기에 Ego4D, EPIC-Kitchen 같은 1인칭 손 조작 데이터를 더합니다. 인간 시연은 범용과 임바디드 사이의 자연스러운 다리 역할을 합니다. 일상적 인간 행동에서 잡기와 도구 사용을 배우면, 그 행동 사전 지식과 어포던스(affordance) 이해가 이후 로봇 조작으로 직접 전이되기 때문입니다.
이 단계의 또 다른 핵심은 T2I, T2V, TI2V 작업의 공동 학습 입니다. 특히 T2I(텍스트-이미지) 작업은 범용 이미지 데이터에서 선명한 시각 표현을 학습하는 ** 시각 품질 앵커(visual quality anchor)** 로 기능합니다. 마치 화가가 정물 데생으로 형태를 정확히 익힌 뒤 그 감각을 동영상 작업에 그대로 가져가듯, T2I가 익힌 물체 형태 지식이 공유 백본을 통해 비디오 생성으로 자동 전이되어 변형과 정체성 불일치를 막습니다.
지도 미세조정: 임바디드 전문화
지도 미세조정(SFT) 단계는 모든 학습 배치에 범용 세계 데이터를 계속 포함시키면서 임바디드 전문성을 점진적으로 심화합니다. 임바디드와 범용의 비율은 70\% 대 30\% 로 유지되며, 임바디드 데이터는 4단계 혼합 스케줄로 도입됩니다.
- 단일 시점 조작: 핵심 조작 물리를 학습합니다.
- 다중 시점 확장: 손목 뷰와 3인칭 뷰를 늘려 시점 범위를 넓힙니다.
- 다중 시점 이어 붙이기: 여러 카메라의 동기화 프레임을 한 입력으로 만들어 교차 시점 기하 일관성을 강제합니다.
- 복잡한 교차 도메인 작업: 물 따르기, 접기, 양팔 협응 같은 고난도 작업과 긴 시간 지평 데이터를 보충합니다.
임바디드 데이터 내부에서는 물리적 기반의 깊이를 확보하기 위해 조작이 약 90\% 의 샘플링 가중치를 차지하고, 다중 시점 이어 붙이기와 내비게이션/주행 데이터가 각각 약 5\% 를 받아 폭을 더합니다. 학습 목표로는 플로우 매칭(flow matching) 을 채택했으며, 인프라는 Megatron-LM 위에서 하이브리드 병렬화와 선택적 활성화 재계산(selective activation recomputation)으로 메모리와 처리량의 균형을 맞췄습니다.
실험 결과 및 성능 분석
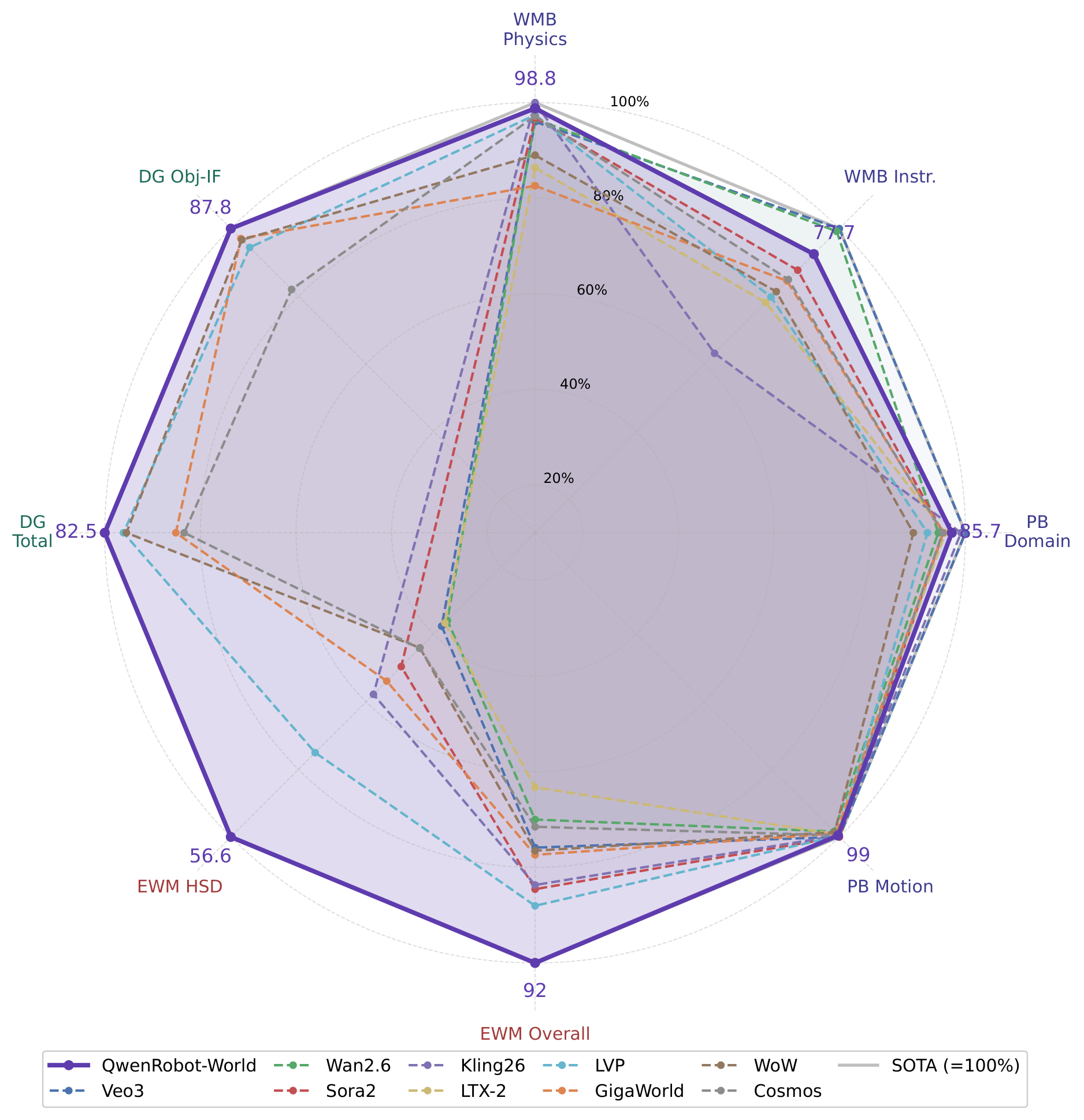
그렇다면 이 모델은 실제로 얼마나 잘 작동할까요? 연구팀은 범용 비디오 생성 모델(Sora2, Veo3, Wan2.6, Kling, LTX-2)과 임바디드 월드 모델(Cosmos, WoW, LVP, Vidar, GigaWorld)을 상대로 4개 벤치마크에서 평가했습니다.
EWMBench: 임바디드 모션 충실도
EWMBench는 장면 일관성, 모션 충실도 등 임바디드 월드 모델의 핵심 능력을 평가합니다. Qwen-RobotWorld는 종합 점수 4.60 으로 1위 를 차지했으며, 이는 2위 LVP의 4.05 보다 0.55 점 앞선 결과입니다. 특히 모션 충실도를 재는 HSD 지표에서 0.566 을 기록하여 차순위 대비 약 33\% 높았고, 장면 일관성도 0.914 로 최고치를 보였으며 논리 제약 만족도는 완벽한 1.000 이었습니다.
DreamGen Bench: 합성적 일반화
DreamGen Bench는 세 가지 로봇 임바디먼트 부분집합에 걸쳐 명령 따르기와 물리 정렬을 평가합니다. Qwen-RobotWorld는 총점 4.952 로 1위 를 기록했으며, 특히 객체 수준 합성 일반화(GR1-Object IF 0.878 )에서 두드러졌습니다. 키워드 하나만 바뀌어도 그에 맞는 다른 물체를 정확히 다루는 능력이 정량 지표로 확인된 것입니다.
WorldModelBench: 물리 추론
WorldModelBench는 뉴턴 법칙, 질량 보존, 유체 역학, 중력 등 물리 법칙 준수와 명령 따르기를 봅니다. Qwen-RobotWorld는 총점 8.99 로 오픈소스 모델 중 1위(전체 3위) 를 달성했으며, 폐쇄형 모델인 Wan2.6(9.27 )과 Veo3 바로 뒤를 이었습니다. 주목할 점은 네 가지 물리 범주 전반에서 ** 완벽한 물리 준수 점수 1.00** 을 기록하여 선도적 폐쇄형 모델과 동등한 수준을 보였다는 것입니다. 명령 따르기도 2.33/3.0 으로 강했습니다. 저자들은 전체 1위와의 상식(common-sense) 점수 격차를 "우리 모델의 더 낮은 출력 해상도에 기인" 한다고 솔직하게 설명합니다.
PBench: 물리 행동 평가
PBench에서도 Qwen-RobotWorld는 0.804 로 모든 오픈소스 모델을 앞섰습니다. 도메인 이해는 0.857 로 전체 3위, 모션 부드러움은 0.990 으로 오픈소스 중 2위였습니다. 물리 시나리오 전반에서 일관된 시간적 정합성을 반영하는 결과입니다.
제로샷 강건성: RoboTwin-IF
정량 점수만으로는 명령 불일치, 교차 시점 비일관성, 일반적 시각 열화라는 세 가지 실패 원인이 뒤섞일 수 있습니다. 이를 분리하기 위해 연구팀은 Unitree G1 작업 4종에서 LVP, Cosmos2.5-14B와 나란히 제로샷 비교를 수행했습니다. Qwen-RobotWorld는 올바른 물체/행동 대응과 깔끔한 목표 완수를 더 일관되게 유지했고, 다중 시점 궤적의 정합성도 지켰습니다. 반면 LVP는 불완전한 작업 실행을, Cosmos2.5-14B는 복잡한 경우에서 명령과 결과 사이의 약한 정렬을 더 자주 보였습니다.
특히 인상적인 것은 RoboTwin-IF(Instruction Following) 벤치마크 결과입니다. 이는 RoboTwin 시뮬레이터 위에 새로 구성한 복잡한 작업들로 이루어진 신규 벤치마크인데, Qwen-RobotWorld는 학습 중 오픈소스 RoboTwin 데이터를 소량만 섞었음에도 강한 제로샷 성능과 안정적인 다중 시점 일관성을 보였습니다. 모델의 향상이 몇몇 정성적 사례에 국한되지 않고, 더 도전적인 미지의 임바디드 작업으로 일반화됨을 시사하는 결과입니다.
한계점과 Qwen-Robot Suite가 그리는 그림
Qwen-RobotWorld가 완성형은 아닙니다. 저자들이 직접 짚은 가장 분명한 한계는 출력 해상도 입니다. 앞서 WorldModelBench의 상식 점수 격차가 낮은 해상도에서 비롯된다고 밝혔듯, 생성 영상의 해상도는 아직 폐쇄형 최상위 모델에 못 미칩니다. 다만 저자들은 이 해상도가 "하류 로봇 제어 작업에는 충분" 하다고 덧붙입니다. 또한 보고서의 실험은 월드 모델 자체의 생성 품질에 집중되어 있고, 초록이 제시한 세 가지 응용 방향, 즉 정책 학습 증강을 위한 합성 데이터 엔진, 정책 평가를 위한 가상 환경, 하류 로봇 제어를 위한 행동 계획 신호 는 작업별 적응이 더해질 때 본격화되는 미래 과제로 남아 있습니다.
이 지점에서 Qwen-Robot Suite 전체의 그림이 의미를 갖습니다. 세 모델(Nav, Manip, World)이 모두 언어 우선 인터페이스를 노출하기 때문에, 범용 Qwen 모델이 이들을 물리 세계의 도구로 조합할 수 있습니다. 실제로 Qwen 팀은 Qwen-RobotClaw 라는 로봇 에이전트 하니스를 통해, Qwen VLM 에이전트가 스위트 모델들을 도구처럼 호출하면서 긴 시간 지평 작업에 필요한 컨텍스트와 메모리를 관리하도록 했습니다. 예컨대 고수준 계획자인 Qwen-3.5가 복잡한 지시를 원자적 하위 작업들로 분해하면 Qwen-RobotManip이 저수준 실행을 맡고, 실행이 멈추면 계획자가 새 하위 작업을 발령해 실패-재시도 루프에서 회복하는 식입니다. 이는 마치 숙련된 현장 감독(범용 LLM)이 전문 작업자(스위트 모델)에게 한 번에 하나의 단순한 단계를 지시하며 복잡한 작업을 완수하게 하는 분업과 같습니다.
Qwen-RobotWorld가 던지는 더 큰 메시지는 이것입니다. 강력한 멀티모달 이해에서 출발하여, 시각 언어 표현 공간을 각 유형의 물리적 행동으로 연결하고, 학습을 확장하며, 일반화를 요구하면, "어디로든 갈 수 있고, 무엇이든 할 수 있으며, 다음에 무슨 일이 벌어질지 내다보는" 물리 에이전트로 가는 길이 점점 분명해진다는 것입니다. 자연어를 보편적 행동 인터페이스로 삼아 조작, 주행, 내비게이션, 인간-로봇 전이를 하나의 백본 아래 통합한 이 연구는, 지각적으로 강력할 뿐 아니라 하류 로봇 학습과 제어에 기능적으로 유용한 임바디드 월드 모델을 향한 실용적 토대라 할 수 있습니다.
 Qwen-RobotWorld Technical Report 논문
Qwen-RobotWorld Technical Report 논문
We introduce Qwen-RobotWorld, a language-conditioned video world model for embodied intelligence. With natural language as a unified action interface, it predicts physically grounded future visual trajectories from current observations across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer.
Qwen-RobotWorld 소개 블로그
Qwen-Robot Suite 소개 블로그
더 읽어보기
-
Physical AI 연구 한 번에 살펴보기 1편: LLM 월드 지식에서 VLA와 월드 모델, 체화 에이전트까지
-
World Action Model의 부상: 비디오 백본으로 로봇 정책을 학습하는 두 번째 레시피 (feat. NVIDIA)
-
RUM(Robot Utility Models): 다양한 환경 및 물체에서 학습한, Zero-Shot 배포가 가능한 로봇 모델🤖
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()