이 글은 두 편의 Physical AI 서베이를 묶어 정리하는 시리즈의 2편입니다.
- 1편: LLM의 월드 지식에서 VLA, 월드 모델, 체화 에이전트까지
- 2편: 물리를 이해하는 생성 모델과 월드 시뮬레이터
픽셀의 사실성을 넘어: 물리 법칙을 이해하는 생성 모델
요즘 영상 생성 모델은 놀랍도록 사실적인 장면을 만들어 냅니다. 물 위로 튀어 오르는 물방울, 바람에 흩날리는 머리카락, 유리에 비친 반사까지 진짜처럼 보입니다. 그런데 그 영상 속에서 공이 물에 빠질 때 정말 제대로 빠지고 있을까요? 컵이 책상 모서리를 넘어가는데도 떨어지지 않거나, 손에서 놓은 물체가 옆으로 흘러가는 장면을 본 적이 있다면, 그것이 바로 이 서베이가 짚는 문제입니다.
오늘 정리할 서베이 Generative Physical AI in Vision: A Survey(arXiv 2501.10928, University of Western Australia 등)는 "물리적으로 그럴듯한 생성" 을 본격적으로 다룬 첫 정리 논문입니다. 이 서베이가 말하는 물리 인지 생성(Physics-Aware Generation) 이란, 이미지, 영상, 3D/4D 콘텐츠를 만들 때 단순히 보기 좋은 결과(visual fidelity)를 넘어 물리적 타당성(physical plausibility) 까지 확보하려는 컴퓨터 비전 생성 모델링을 가리킵니다. 저자들의 진단은 날카롭습니다. "현재의 최첨단 모델들은 주로 픽셀 공간에서의 시각적 사실성을 위해 최적화되어 있을 뿐, 개체나 개념 공간에서의 물리적 타당성을 위해 최적화되어 있지 않다."
이 간극은 단순한 미적 결함이 아닙니다. 로봇공학, 자율주행, 과학 시뮬레이션처럼 실제 물리 법칙을 지켜야 하는 응용에서는 치명적입니다. 그래서 생성 모델이 물리적 사실성과 동적 시뮬레이션을 통합해 가면, 이들이 월드 시뮬레이터(World Simulator) 로 기능할 잠재력이 커집니다. 1편에서 본 로드맵의 "예측과 시뮬레이션" 축을 가장 깊이 파고든 셈입니다.
특히 영상은 이 비전의 중심에 있습니다. 저자들의 표현으로 "영상은 세계의 암묵적 물리 모델(implicit physical model of the world)로 볼 수 있으며, 디지털 영역과 물리 영역을 잇고 실세계 의사결정의 길을 연다" 는 것입니다. OpenAI의 Sora, Google의 Veo2, Tencent의 Hunyuan, Kuaishou의 Kling, NVIDIA의 Cosmos 같은 대형 영상 모델이 이 흐름을 대표합니다.
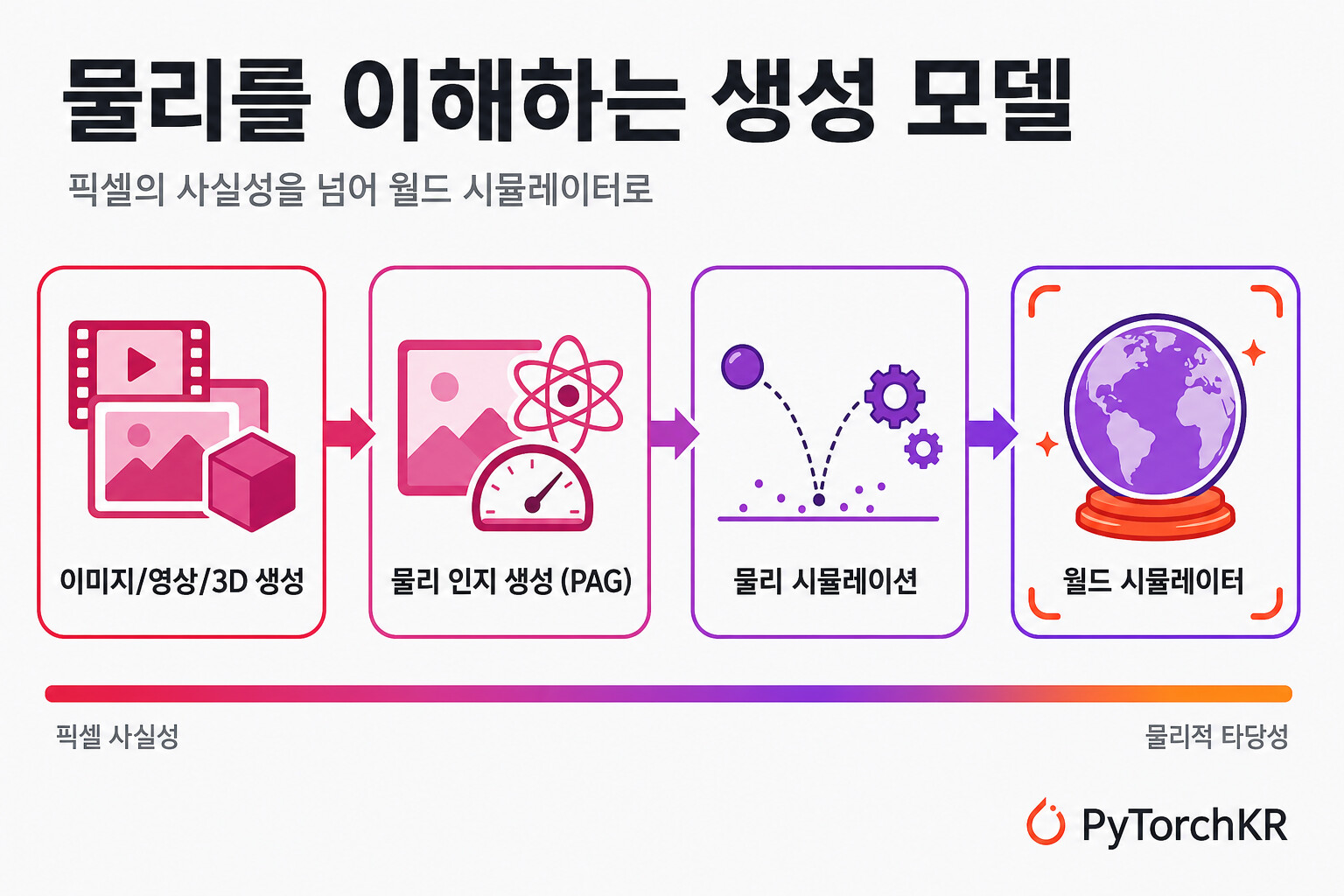
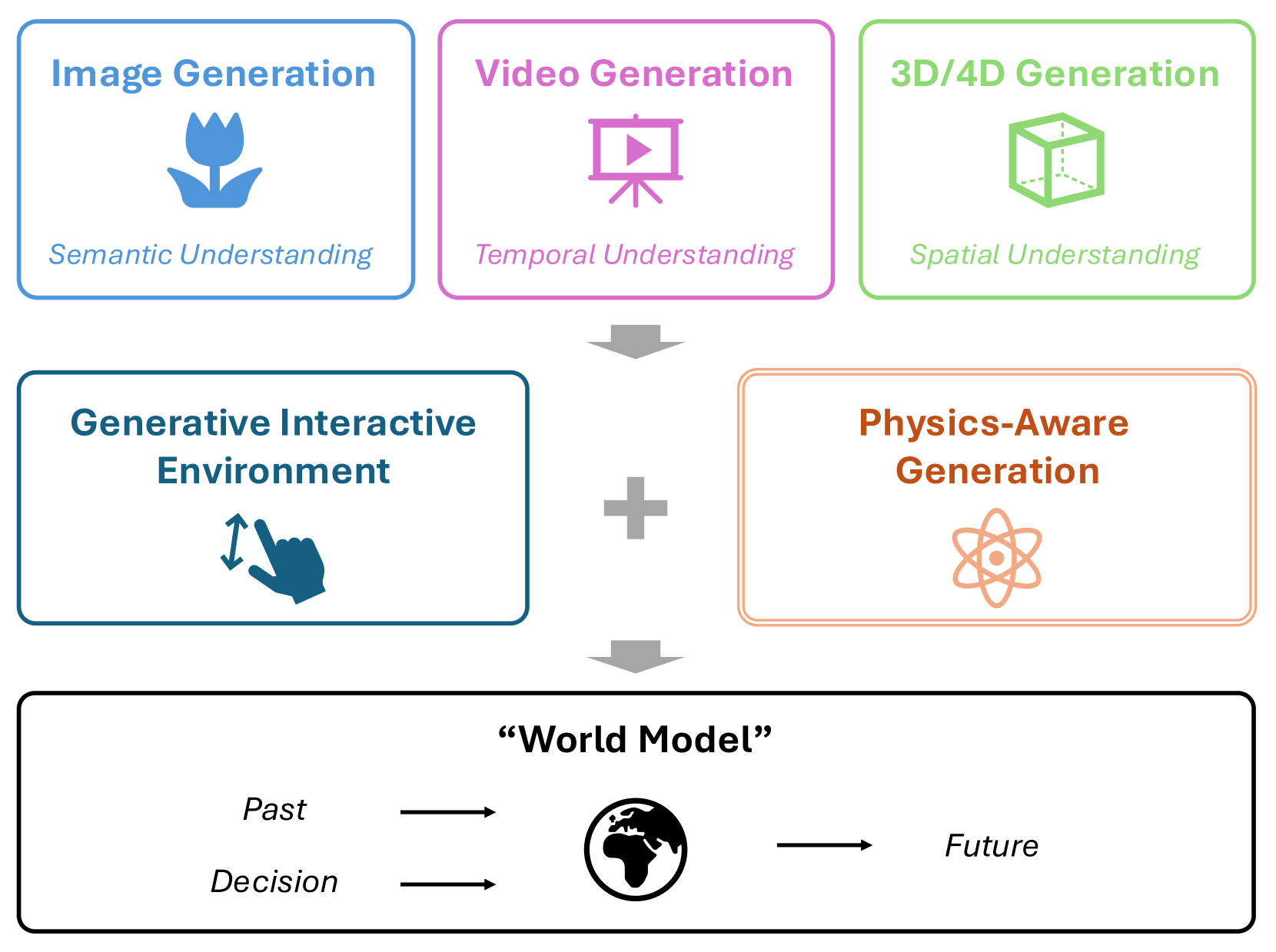
아래 그림은 서베이가 그리는 큰 그림입니다. 생성 AI는 이미지의 의미적 이해, 영상의 시간적 이해, 3D/4D의 공간적 이해를 거쳐, 상호작용성과 물리 인지 생성을 더하면서 과거와 결정으로부터 미래를 추론하는 "월드 모델" 로 수렴해 갑니다.
개념 정리: 시뮬레이션, 이해, 생성, 그리고 물리 인지 생성
본격적인 분류에 앞서, 서베이는 헷갈리기 쉬운 개념들을 형식적으로 구분합니다. 물리 시뮬레이션 모델을 물리 파라미터 \theta 를 가진 P_\theta, 생성 모델을 G 라 할 때 세 가지 기본 연산을 정의합니다.
- 물리 시뮬레이션(Physical Simulation, PS): P_\theta(X) \rightarrow X'. 물리 모델로 관찰 X 를 다음 상태 X' 로 진화시킵니다.
- 물리 이해(Physical Understanding, PU): X \rightarrow P_\theta. 영상 같은 관찰로부터 그 밑에 깔린 물리 모델이나 파라미터 \theta 를 역으로 추론합니다.
- 생성(Generation, G): G(X) \rightarrow X'. 입력 조건 X 로부터 새로운 콘텐츠 X' 를 만듭니다. 강한 물리 이해가 필요 없으면 이는 물리 비인지 생성(Physics-Unaware Generation, PUG) 입니다.
그리고 이 서베이의 골격인 물리 인지 생성(PAG) 은 "실세계 물리에 대한 강한 이해를 동반한 생성 과정" 으로 정의되며, 결정적으로 생성 모델이 명시적 물리 시뮬레이션을 쓰는지 여부 에 따라 두 갈래로 나뉩니다.
- PAG-E: 명시적 물리 시뮬레이션을 동반한(with explicit simulation) 물리 인지 생성
- PAG-I: 명시적 시뮬레이션 없이 암묵적 학습으로(implicit learning) 이루는 물리 인지 생성
서베이의 Table I은 이 개념들의 차이를 한눈에 보여 줍니다(✓ 예, ✗ 아니오, ∘ 선택).
| 구분 | PS | PU | G | PUG | PAG-E | PAG-I |
|---|---|---|---|---|---|---|
| 입력: 관찰 | ✓ | ✓ | ∘ | ∘ | ∘ | ∘ |
| 입력: 물리 | ✓ | ∘ | ∘ | ✗ | ∘ | ∘ |
| 출력: 관찰 | ✓ | ∘ | ✓ | ✓ | ✓ | ✓ |
| 출력: 물리 | ∘ | ✓ | ∘ | ✗ | ∘ | ∘ |
| 명시적 물리 모델 | ✓ | ✓ | ∘ | ✗ | ✓ | ✗ |
| 물리 세계 이해 | ✓ | ✓ | ∘ | ∘ | ✓ | ✓ |
핵심은 두 가지입니다. PAG-E와 PAG-I는 오직 "명시적 물리 모델" 행에서만 갈리고(✓ 대 ✗), 둘 다 "물리 세계 이해" 는 ✓라는 점입니다. 반대로 일반 생성에 가까운 PUG는 물리 입출력도, 명시적 모델도 없습니다.
한 가지 짚어둘 점은 이 서베이의 범위 제외 기준입니다. 저자들은 (1) 물리를 모델 구조의 사전 지식이나 귀납 편향으로 넣는 방식, 예를 들어 물리 정보 신경망(Physics-Informed Neural Networks, PINN), (2) 디블러링이나 디헤이징, 화질 개선 같은 이미지 처리 작업, (3) 물리 시뮬레이션을 다루더라도 순수 그래픽스 연구는 의도적으로 제외합니다. 초점은 어디까지나 "출력의 물리적 사실성" 에 있습니다.
생성 모델의 토대: GAN, 확산 모델, NeRF, 가우시안 스플래팅
물리 인지 생성을 이해하려면 그 토대가 되는 생성 모델들을 먼저 짚어야 합니다. 서베이는 도입부에서 VAE와 시각 자기회귀 모델(VAR)을 포함한 여러 생성 모델 계열을 언급한 뒤, 본문에서는 다음 네 가지를 자세히 다룹니다. 흥미롭게도 보통 렌더링/복원 기법으로 여겨지는 NeRF 와 가우시안 스플래팅(Gaussian Splatting) 을 넓은 의미의 생성 모델로 포함시킵니다.
- 생성적 적대 신경망(GAN): 생성자와 판별자가 미니맥스 게임을 벌이는 구조로, 확산 모델 이전까지 지배적인 생성 모델이었습니다(StyleGAN 계열).
- 확산 모델(Diffusion Model): 가우시안 노이즈를 점진적으로 더했다가(q(x_t \mid x_{t-1})) 신경망으로 거꾸로 제거하며(p_\theta(x_{t-1} \mid x_t)) 데이터를 생성합니다. GAN보다 학습이 안정적이지만 샘플링 효율은 낮습니다. DDIM, DPM-Solver 같은 가속 샘플러와 잠재 확산(latent diffusion), 분류자 유무 안내(classifier-free guidance)가 함께 발전했습니다.
- 신경 복사장(NeRF): 3차원 좌표 (x, y, z) 와 시선 방향 (\theta, \phi) 를 밀도 \sigma 와 색 c 로 매핑하는 MLP 기반 암묵적 표현입니다(PixelNeRF, MIP-NeRF, D-NeRF).
- 가우시안 스플래팅(GS): 장면을 평균 \mu_i, 공분산 \Sigma_i, 불투명도 \alpha_i 를 가진 수많은 3차원 가우시안 덩어리로 표현하는 명시적 복사장입니다. NeRF보다 빠르고 정확하며, 4D-GS, SplatterImage, LGM 등으로 확장됩니다.
이 가운데 가우시안 스플래팅은 장면을 입자(particle)처럼 다루기 때문에 물리 시뮬레이션과 결합하기에 특히 자연스럽습니다. 뒤에서 보겠지만 PAG-E의 상당수가 가우시안을 시뮬레이션 요소로 재해석합니다.
물리 시뮬레이션의 구성 요소
명시적 시뮬레이션을 다루기 전에, 물리 시뮬레이션 자체가 어떤 요소들로 이뤄지는지 살펴볼 필요가 있습니다. 서베이는 이를 세 축으로 정리합니다.
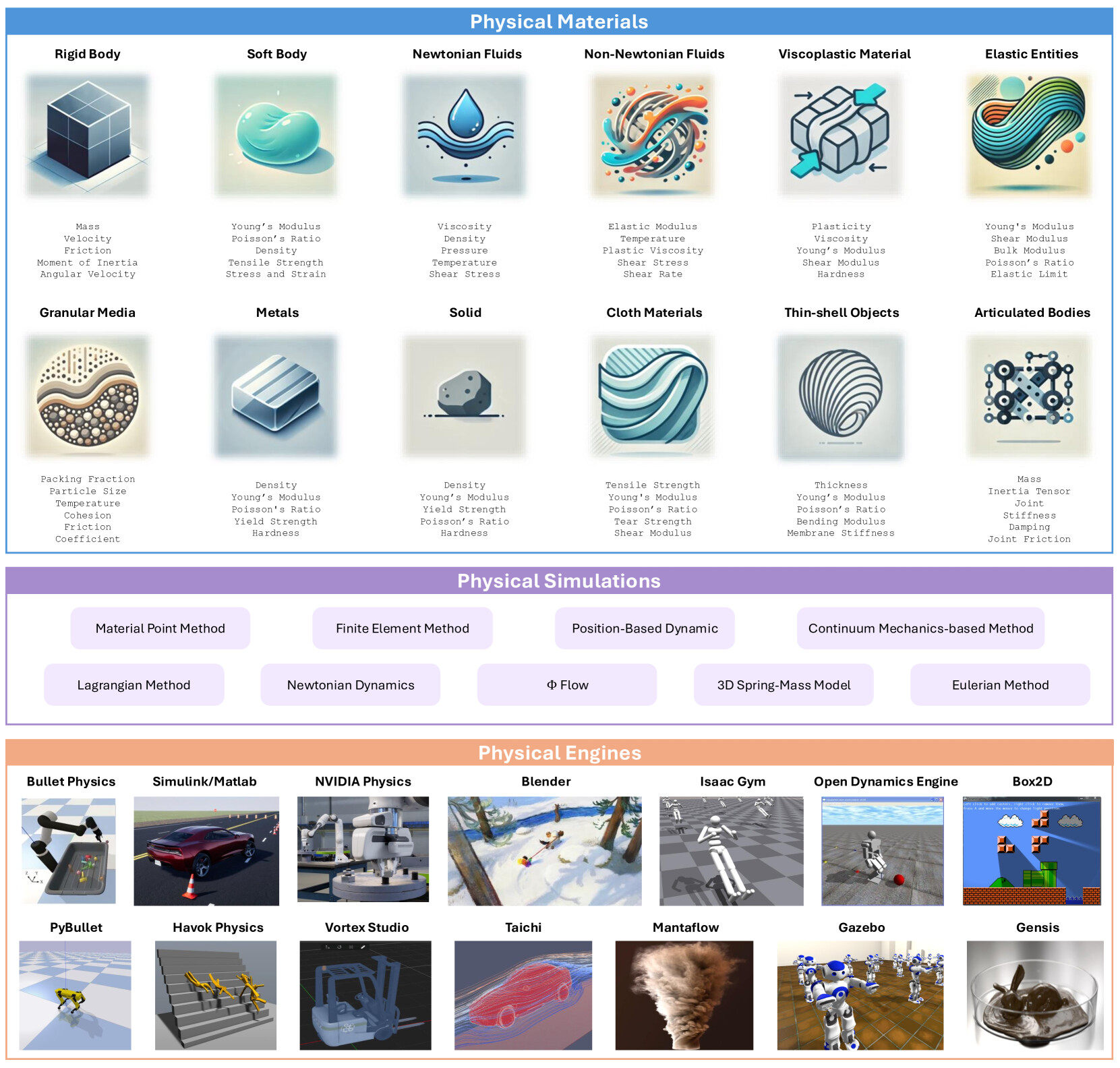
- 물리 재료(physical materials): 강체(rigid body), 연체(soft body), 뉴턴/비뉴턴 유체, 점소성(viscoplastic) 재료, 입상 매질(granular media), 금속, 천, 박막(thin-shell), 관절체(articulated body) 등 모델링 대상의 종류입니다. 각각 질량, 마찰, 영률(Young's modulus), 포아송 비 같은 서로 다른 속성으로 기술됩니다.
- 시뮬레이션 방법(simulation methods): 물질의 동역학을 물리 법칙 아래 계산하는 도구로, 물질점 방법(Material Point Method, MPM), 유한요소법(FEM), 위치 기반 동역학(Position-Based Dynamics), 라그랑주/오일러 방법 등이 있습니다.
- 물리 엔진(physics engines): 이를 실제로 구현한 기성 플랫폼으로 Bullet, MuJoCo 계열, NVIDIA PhysX, Blender, Isaac Gym, Genesis, Taichi 등이 있습니다.
한편 시뮬레이션에 쓸 물리 파라미터는 어떻게 얻을까요? 서베이는 세 가지 경로를 듭니다. (1) 전문가가 직접 정하는 수동 설정, (2) 시각 관찰로부터 데이터 기반으로 추론하는 자동 학습, (3) 멀티모달 LLM이 텍스트와 시각 정보로부터 재료와 그럴듯한 구성을 추론하는 LLM 기반 추론 입니다. 마지막 경로는 최근 들어 빠르게 늘고 있습니다.
명시적 시뮬레이션 기반 물리 인지 생성 (PAG-E)
PAG-E는 생성 과정 G 와 물리 시뮬레이션 P_\theta 가 어떻게 상호작용하는지에 따라 여섯 가지 패러다임 으로 나뉩니다. 아래 그림이 그 구조적 차이를 한눈에 보여줍니다. 한 논문이 여러 패러다임에 걸치기도 하며, 그럴 때는 가장 관련 깊은 하나로 분류합니다.
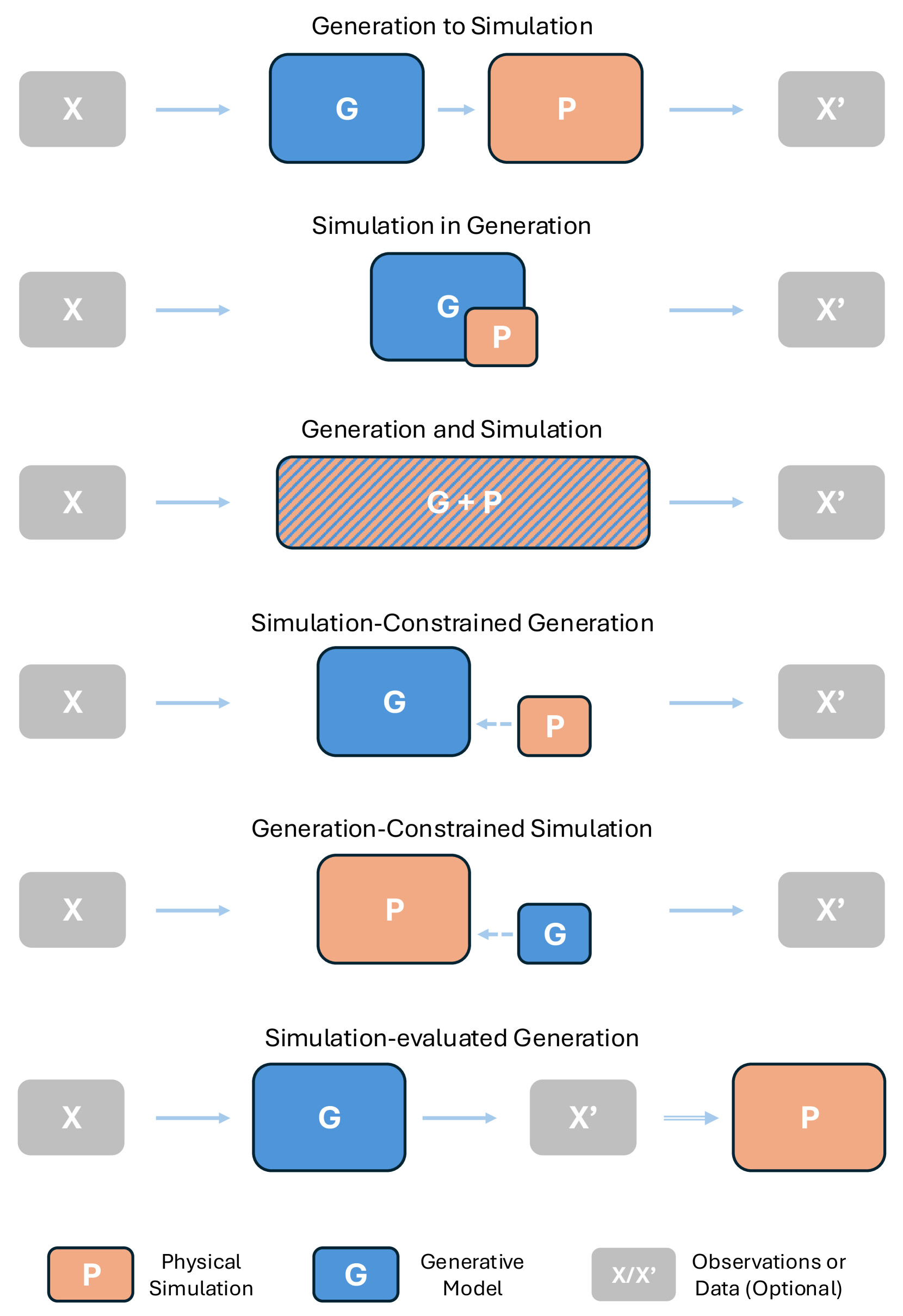
Gen-to-Sim (GtS): 생성 후 시뮬레이션
먼저 생성한 결과에 물리 속성을 사후에 입혀 시뮬레이션/상호작용이 가능하게 만드는 방식입니다(생성 다음에 시뮬레이션이 뒤따르는 순차 구성). 가장 활발한 갈래로, 네 가지 세부 아이디어가 있습니다. 첫째, NeRF를 시뮬레이션 요소로 바꾸는 흐름입니다. PIE-NeRF 는 NeRF 밀도장에 포아송 디스크 샘플링으로 입자를 뿌리고 보로노이로 묶어 시뮬레이션 요소를 만들며, Video2Game 은 단일 실세계 영상 하나를 상호작용 가능한 가상 환경으로 바꿉니다. 둘째, 가우시안 덩어리를 시뮬레이션 입자로 보는 흐름으로, PhysGaussian 은 가우시안 스플래팅에 물질점 방법을 적용해 응력과 변형을 추적하고, GASP 는 가우시안을 삼각 메시로 바꿔 MPM을 적용하며, Spring-Gau 는 앵커 점들을 스프링으로 이어 영상에서 강성과 감쇠를 학습합니다. 셋째, 물리 특징장 흐름으로, Feature Splatting 은 VLM의 의미 특징을 가우시안에 심어 언어 의미로부터 물질 속성을 부여하고, Phys4DGen 과 SimAnything 은 Segment Anything과 LLM으로 물체별 물리 속성을 추론합니다. 넷째, VR과 로봇 응용으로 VR-GS (실시간 물리 인지 VR 조작), LIVE-GS (GPT-4로 물리 속성 추론), DreMa (장면 복원과 시뮬레이션을 결합한 로봇용 객체 중심 월드 모델)가 있습니다.
Sim-in-Gen (SiG): 생성 모델 안의 시뮬레이션
물리 시뮬레이션을 생성 모델의 핵심 하위 모듈로 통합합니다(시뮬레이션 모델이 생성 모델의 일부가 되는 구성). GPT4Motion 은 GPT-4가 프롬프트를 Blender 파이썬 스크립트로 바꿔 렌더링한 깊이/엣지 맵을 ControlNet 기반 Stable Diffusion에 입력하고, 비슷하게 AutoVFX 는 자연어 지시를 실행 가능한 코드로 바꿔 Blender 엔진에서 물리적으로 그럴듯한 영상 편집을 수행합니다. PhysGen 은 이미지에 사용자가 가한 힘과 토크를 받아 뉴턴 법칙으로 물리적으로 그럴듯한 영상을 만들며(물리 파라미터는 파운데이션 모델이 추론), 후속인 PhysAnimator 는 메시 복원과 시뮬레이션으로 스케치를 변형해 변형체 동역학까지 다룹니다. PhysDiff 는 확산의 각 노이즈 제거 단계마다 물리 시뮬레이터로 보정한 동작을 다시 샘플링에 되먹여 물리적으로 타당한 사람 동작을 생성합니다.
Gen-and-Sim (GnS): 생성과 시뮬레이션 동시 수행
생성과 시뮬레이션이 동시에, 또는 공유 모델을 통해 긴밀히 맞물려 일어납니다. PAC-NeRF 는 다시점 영상에서 기하와 물리 파라미터를 함께 추론하기 위해 오일러-라그랑주 혼합 표현(오일러 격자로 NeRF 기하 학습, 라그랑주 입자로 물리 파라미터 학습)을 쓰고, 후속인 iPAC-NeRF는 라그랑주 입자 최적화로 입자의 위치와 특징까지 직접 최적화합니다. PhysMotion 은 생성, 시뮬레이션, 다시 생성으로 이어지는 흐름으로 이미지를 영상으로 바꿉니다.
Sim-Constrained Gen (ScG): 시뮬레이션이 생성을 제약
시뮬레이션이 생성 모델의 학습에 제약이나 손실을 부과합니다. Atlas3D 는 스스로 설 수 있는 3D 모델을 위해 안정 평형 손실을, PhyRecon 은 미분 가능한 입자 기반 시뮬레이터를 손실로 씁니다. DiffuseBot 은 미분 가능한 물리 시뮬레이션으로 생성된 로봇 설계 중 성능 좋은 것을 걸러 샘플링 분포를 조정합니다. DSO 는 시뮬레이션으로 자립 안정성을 라벨링한 뒤 직접 선호 최적화(DPO)로 이미지-투-3D 모델을 미세조정합니다.
Gen-Constrained Sim (GcS): 생성이 시뮬레이션을 안내
반대로 생성 모델이 시뮬레이션의 사전 지식이나 안내 역할을 합니다. Physics3D 는 점수 증류 샘플링(Score Distillation Sampling, SDS)으로 물리 파라미터를 최적화하고, DreamPhysics 는 운동에 특화된 사전 지식을 더 잘 잡고 색 편향을 줄이기 위해 운동 증류 샘플링(Motion Distillation Sampling, MDS)을 제안합니다. PhysDreamer 는 점수 증류 대신, 이미지-투-비디오 모델이 만든 참조 영상과 시뮬레이션 렌더링의 시각적 유사도를 최대화해 영률(Young's modulus) 같은 파라미터를 추정합니다.
Sim-evaluated Gen (SeG): 시뮬레이션으로 평가되는 생성
마지막으로, 생성 결과가 시뮬레이션 환경에서의 배포를 목표로 하는 경우입니다. PhysPart 는 3D 프린팅이나 로봇 조작을 위해 끼워 맞춰지고 움직이는 교체 부품을 생성하며, PhyScene 은 체화 AI를 위한 상호작용 가능한 3D 장면을 물리 기반 안내로 생성합니다.
명시적 시뮬레이션 없는 물리 인지 생성 (PAG-I)
PAG-I는 명시적 시뮬레이터에 기대지 않고도 물리 인지를 드러내는 연구들입니다. 서베이는 이를 다섯 갈래로 정리합니다.
대형 영상 모델에서 창발하는 물리 인지
Sora, OpenSora, CogVideoX, Cosmos 처럼 인터넷 규모의 영상으로 학습한 모델은 일관된 물체 상호작용과 사실적인 운동 같은 창발적(emergent) 물리 추론을 보입니다. 다만 이 암묵적 추론은 "아직 초기 단계" 입니다. 벤치마크 PhyGenBench 는 모델들이 "기본적인 물리 법칙조차 정확히 표현하는 데 어려움을 겪는다" 고 보고합니다.
특히 한 가지 결과는 곱씹어 볼 만합니다. Kang 등 의 연구에 따르면, 모델과 데이터셋 크기를 키우는 것만으로는 분포 밖(out-of-distribution) 물리 일반화가 개선되지 않았습니다. 저자들의 표현으로 "현재 모델들은 일반적인 물리 규칙을 추상화하기보다 주로 매우 유사한 학습 예시의 존재에 의존하며, 이는 완전한 물리 인지 생성 모델을 위한 더 표적화된 방법이 필요함을 시사한다" 는 것입니다. 즉 더 많은 데이터가 곧 더 나은 물리 이해는 아닙니다.
NVIDIA의 Cosmos 플랫폼은 이 흐름에서 특히 주목받습니다. 영상 데이터 파이프라인, 토크나이저, 사전/사후 학습 모델을 묶은 오픈소스 도구로, 트랜스포머 기반 확산 및 자기회귀 월드 파운데이션 모델을 제공하며 로봇 조작, 카메라 제어, 자율주행에 미세조정할 수 있습니다. 동반 모델 Cosmos-Reason1 은 공간, 시간, 기초 물리라는 3 개 대분류와 16 개 세부 범주로 이루어진 물리 상식 온톨로지를 정의하고, 이진 2828 개와 객관식 2909 개를 합쳐 5737 개 문항을 모았습니다(그중 604 개는 426 개 영상과 연결됩니다). 또 다른 변형인 Cosmos-Transfer1 은 분할, 깊이, 엣지 맵 같은 공간 입력으로 월드 생성을 제어하는 ControlNet류 구조를 더합니다.
LLM과 물리가 풍부한 데이터에서 오는 물리 인지
PhyT2V 는 LLM으로 프롬프트를 반복 정제해(물체와 물리 규칙을 추출하고, 생성 영상을 캡션으로 기술한 뒤, 불일치를 비교/교정) 물리 인지를 끌어올립니다. 비슷하게 VideoAgent 는 로봇을 위한 시각 계획을 만들고, 자기 조건부 일관성과 사전학습된 VLM의 피드백으로 생성 영상을 다듬습니다. 데이터 측면에서는 WISA 가 동역학, 열역학, 광학에 걸친 17 가지 물리 현상의 영상 약 32{,}000 개로 구성된 WISA-32K 를 모아 물리 속성 임베딩, 물리 전문가 혼합(mixture-of-physical-experts), 물리 분류기로 영상 모델을 학습시킵니다. PISA 는 실제 361 개와 Kubric 엔진으로 만든 합성 60 개의 물체 낙하 영상으로, 분할/광학 흐름/깊이의 정렬을 보상으로 삼는 객체 보상 최적화 사후 학습을 수행합니다.
생성형 상호작용 동역학과 운동 제어
단일 이미지에서 스펙트럼 볼륨을 거쳐 조밀한 장기 픽셀 궤적을 만드는 Generative Image Dynamics, 운동 궤적을 조건으로 주는 Motion Prompting, 광학 흐름 추정기의 기울기로 확산을 제어하는 Motion Guidance 등이 이 갈래에 속합니다. 더 나아가 CoCoGen 은 다르시 흐름(Darcy Flow)이나 버거스 방정식(Burgers Equation) 같은 물리 도메인 데이터를, 이산화된 편미분방정식 정보를 샘플링에 주입하며 생성합니다.
물리 인지를 어떻게 평가하는가
물리 인지 생성에서 평가는 그 자체로 까다로운 연구 주제입니다. FID, CLIP Similarity, Inception Score, FVD 같은 표준 지표는 시각적/의미적 정렬에 치우쳐 있어 물리 법칙 위반을 잡아내지 못합니다. 아래 그림은 물리 인지가 나쁜 영상과 좋은 영상을 나란히 보여 주는데, 픽셀 품질만으로는 이 차이를 구분하기 어렵다는 점을 직관적으로 드러냅니다.

그래서 물리 인지를 직접 겨냥한 벤치마크들이 등장했습니다.
- PhyBench: 텍스트-투-이미지 물리 상식 벤치마크로, 역학/광학/열/물질 속성 4 개 유형, 31 개 물리 시나리오에 걸친 700 개 프롬프트로 구성됩니다. GPT-4o 기반 자동 평가자 PhyEvaler 가 장면 정확도와 물리적 정확성을 채점합니다.
- PhyGenBench: 텍스트-투-비디오 물리 상식 벤치마크로, 같은 4 개 도메인에 걸친 27 개 물리 법칙, 160 개 프롬프트를 다룹니다(평가자 PhyGenEval).
- **VideoPhy**와 VideoPhy2: 고체-고체, 고체-유체, 유체-유체 상호작용을 다루며, VideoPhy는 688 개 캡션과 12 개 모델(CogVideoX, OpenSora 같은 공개 모델과 Pika, Gen-2 같은 비공개 모델)에 대한 사람 평가에서 대부분의 모델이 물리적 일관성에 실패함을 보였습니다. VideoPhy2는 행동 중심으로 197 개 실세계 행동, 3{,}940 개 프롬프트, 5 점 리커트 척도로 확장됩니다.
- Physics-IQ: 시각 조건부 벤치마크로, 396 개 실세계 고해상도 영상에서 조건 구간을 주고 이후 5 초를 예측하게 합니다(고체 역학, 유체, 열역학, 광학, 자기).
- PisaBench: 단일 공중 이미지에서 물체의 자유 낙하를 예측하며, 궤적 L_2 오차, 샴퍼 거리(Chamfer Distance), IoU로 운동/형태/공간 일관성을 평가합니다.
- PhyCoBench: 중력, 충돌, 진동, 마찰, 유체, 포물선 운동, 회전 7 개 범주, 120 개 프롬프트로 물리적 일관성을 평가합니다.
표준 지표가 부족한 이유는 분명합니다. FID나 IS는 분포 수준의 사실성만 보고, FVD는 비교할 참조 영상 데이터셋이 필요한데 새로 생성한 장면에는 그런 정답이 없기 때문입니다. 그래서 평가 지표는 크게 세 부류로 나뉩니다. 가장 신뢰할 수 있지만 비용이 큰 사람 평가, 확장성은 좋지만 평가자 자신의 물리 이해가 또 다른 미해결 문제인 VLM 기반 평가, 그리고 정밀하고 재현 가능하지만 대개 짝지어진 실세계 정답 영상이 필요한 자동 정량 평가 입니다. 자동 평가는 운동을 보는 궤적 L_2 거리, 형태를 보는 샴퍼 거리(Chamfer Distance), 공간 일관성을 보는 IoU와 가중 IoU, 그리고 평균 제곱 오차(MSE) 같은 지표로 구체화됩니다.
논의와 향후 방향
서베이는 끝맺으며 두 가지 중요한 구분을 제시합니다. 첫째, 의미 인지(semantic awareness) 와 물리 인지(physical awareness) 의 구분입니다. 의미 인지가 "무엇이 어디에 있는가" 라는 정적 매핑이라면, 물리 인지는 "어떻게, 왜" 라는 동적이고 예측적인 상호작용을 다룹니다. 바로 이 동적/예측적 성격 때문에 "영상의 시간 모델링" 이 특히 중요해집니다. 둘째, 기하 인지(geometry awareness)와 물리 인지의 구분입니다. 기하가 모양, 크기, 자세, 깊이 같은 외재적 구조라면, 물리는 물체가 법칙 아래 어떻게 움직이고 변형되고 상호작용하는지의 내재적 행동입니다. 이 둘을 모두 통합해야 지각하면서 동시에 상호작용하는 체화 모델이 가능합니다.
향후 방향으로는 (1) 생성 콘텐츠를 물리 엔진에 직접 배포하거나 체화 에이전트를 평가자로 쓰는 더 나은 물리 인지 평가, (2) 명시적 물리 법칙으로 입출력 경로를 해석하는 설명 가능성, (3) 여러 인식 파운데이션 모델의 통합, 대규모 합성 데이터와 미분 가능한 물리를 활용한 물리 유도 사전학습, 자기지도 물리 학습을 아우르는 물리 증강 파운데이션 모델, (4) 미분 가능한 시간 논리나 상징 그래프/온톨로지로 합성적 추론을 강화하는 신경-상징 하이브리드, (5) "폭우 뒤 가파른 산의 산사태를 시뮬레이션하라" 같은 고수준 프롬프트를 완전히 상호작용 가능한 물리 일관 환경으로 바꾸는 생성형 시뮬레이션 엔진(예: Genesis), 그리고 (6) 물리적으로 사실적인 합성 데이터로 시뮬레이션-현실 전이를 개선하고 VLA 모델에 물리 추론을 주입하는 로봇/체화 AI 응용이 제시됩니다. 응용 범위도 로봇과 자율주행을 넘어, 조직의 물리적 성질을 재현해 수술 훈련과 계획을 돕는 의료, 충실도와 해상도가 중요한 기후 모델링, 그리고 VR과 3D 프린팅까지 확장됩니다.
1편에서 본 로드맵의 언어로 옮기면, 이 서베이는 "월드 모델" 단계를 생성 모델의 관점에서 가장 구체적으로 해부한 작업입니다. 물리적으로 그럴듯한 영상을 만드는 능력은 곧 "행동하면 무슨 일이 일어날지" 를 예측하는 능력의 한 형태이며, 이것이 LLM의 월드 지식과 결합될 때 진정한 월드 시뮬레이터에 한 걸음 더 다가서게 됩니다.
 Generative Physical AI in Vision: A Survey 논문
Generative Physical AI in Vision: A Survey 논문
Physics-Aware Generation 정리 목록
더 읽어보기
-
Physical AI 서베이 연구 살펴보기 1편: LLM 월드 지식에서 VLA와 월드 모델, 체화 에이전트까지
-
World Action Model의 부상: 비디오 백본으로 로봇 정책을 학습하는 두 번째 레시피 (feat. NVIDIA)
-
[GN⁺] VC가 예측하는 2026년 로보틱스 및 피지컬 AI 분야에서의 6가지 투자 전망 (feat. Bessemer Venture Partners)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()